数学建模培训--人工神经网络(2)
- 格式:doc
- 大小:490.50 KB
- 文档页数:32





人工神经网络与数学建模曾黄麟随着人们从研究内容到研究方法经历的发展与变化,在对于高层次智能行为的研究中,大多数研究不仅集中于知识表示和符号推理,而是更加重视知识与大量观察和实验数据的处理、归纳、分类相联系,这就是数据挖掘。
数学建模就是从大量数据中利用某些方法,寻找该系统或事件的内在规律,建立该系统或事件的数据之间的联系,并用一种数学描述其输入与输出之间的关系,这种关系就是数学模型。
一个系统的内在联系是通过数据、图表、图像、图形、公式、方程、网络结构等形式来体现的,所以,在某种程度上可以说,数据、图表、图像、图形、公式、方程、网络结构等都是该系统的模型表达,这种表达就是相似系统的概念。
因此,数学建模就是由一种系统的模型表达转换为系统的另一种模型表达。
人工神经网络数学建模就是用人工神经网络的结构形式来代替实际物理系统模型。
人工神经网络是以工程技术手段模拟人脑神经系统的结构和功能为特征,通过大量的非线性并行处理器来模拟人脑中众多的神经元之间的突触行为,企图在一定程度上实现人脑形象思维、分布式记忆、自学习自组织的功能。
人工神经网络理论(ANN,artificial neural networks)的概念早在40年代就由美国心理学家 McCulloch 和数理逻辑学家Pitts提出了M-P模型。
1949 年美国心理学家Hebb 根据心理学中条件反射的机理,提出了神经元之间连接变化的规则,即Hebb规则。
50年代Rosenblatt提出的感知器模型、60年代Widrow 提出的自适应线性神经网络,以及80年代Hopfield,、Rumelharth等人富有开创性的研究工作,有力地推动了人工神经网络研究的迅速发展。
大脑是由大量的神经细胞和神经元组成的,每个神经元可以当成是一个小的信息处理单元,这些神经元按照某种方式互相连接起来构成一个复杂的大脑神经网络。
人工神经网络方法企图模拟人类的形象直觉思维,通过由大量的简单模拟神经元实现一种非线性网络,用神经网络本身结构表达输入与输出关联知识的隐函数编码,并通过学习或自适应使网络利用非线性映射的思想对信息能够并行处理。



数学建模培训人工神经网络(2)数学建模培训--人工神经网络(2)常用的人工神经网络案例1感知器网络matlab上机实验例1.1用newp函数设计一个单输出和一个神经元的感知器神经网络,输出的最小值和最大值为?0,2?。
>>net=newp([02],1);可以用下面语句去观测分解成了一个什么样的神经网络。
>>inputweights=net.inputweights{1,1}inputweights=delays:0initfcn:'initzero'learn:1learnfcn:'learnp'learnparam:[]size:[11]userdata:[1x1struct]weightfcn:'dotprod'weightparam:[1x1struct]从中可以看到,缺省的学习函数为learnp,网络输入给hardlim传递函数的量为数量积dotprod,即输入量和权值矩阵的乘积,然后再加上阈值。
缺省的初始化函数为initzero,即权值的初始值置为0。
同样地,>>biases=net.biases{1,1}biases=initfcn:'initzero'learn:1learnfcn:'learnp'learnparam:[]size:1userdata:[1x1struct]基准1.2设计一个输入为二维向量的感知器网络,其边界值已定。
>>net=newp([-22;-22],1);和上面的例子一样,权值和阈值的初始值为0。
如果不敢预置为0,则必须单独分解成。
例如,两个权值和阈值分别为[-11]和1,应用如下语句:>>net.iw{1,1}=[-11];>>net.b{1,1}=[1];应用领域下面语句检验一下:>>net.iw{1,1}ans=-11>>net.b{1,1}ans=1下面来看这个感知器网络对两个输出信号的输入如何,两个信号分别坐落于感知器两个边界。

第1章人工神经网络简介1.1 引言现代计算机有很强的计算和信息处理能力,但是它对于模式识别、感知和在复杂环境中作决策等问题的处理能力却远远不如人,特别是它只能按人事先编好的程序机械地执行,缺乏向环境学习、适应环境的能力。
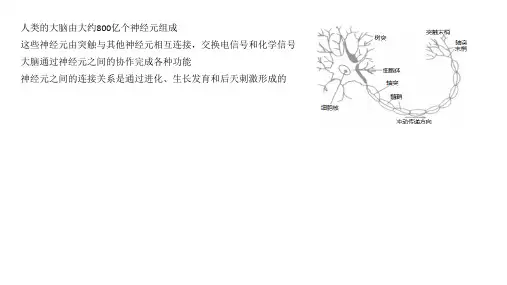
人们早已知道人脑的工作方式与现在的计算机是不同的,人脑是由极大量基本单元(神经元,见图2.1)经过复杂的互相连接而成的一种高度复杂的、非线性的、并行处理的信息处理系统。
单个神经元的反应速度比计算机的基本单元——逻辑门——低5~6个数量级。
由于人脑的神经元数量巨大,每个神经元可与几千个其他神经元连接,对许多问题的处理速度比计算机快得多。
图1.1神经元构成示意图因此,人们利用大脑的组织结构和运行机制的特点,从模仿人脑智能的角度出发,来探寻新的信息表示、存储和处理方式,设计全新的计算机处理结构模型,构造了一种更接近人类智能的信息处理系统,即人们目前正在研究的人工神经网络(Artificial Neural Networks,简称NN)系统。
简而言之,所谓NN就是模仿人脑工作方式而设计的一种机器,它可用电子或光电元件实现,也可用软件进行计算机仿真。
自从上世纪40年代初,美国McCulloch和Pitts从信息处理的角度,研究神经细胞行为的数学模型表达,提出了二值神经元模型以来,人们对神经网络进行了大量的研究。
其中经历了40年代末心理学家Hebb提出著名的Hebb学习规则[1],50年代Rosenblatt提出的感知机模型(Perceptron)[2],60年代神经网络的研究的低潮,80年代提出的一种新的神经网络HNN[3]和Boltzmann机[4]等一系列的过程。
目前,神经网络的发展非常迅速,从理论上对它的计算能力、对任意连续函数的逼近能力、学习理论以及动态网络的稳定性分析上都取得了丰硕的成果。
特别是在应用上已迅速扩展到许多重要领域[5, 6]。
如模式识别与图像处理中的手写体字符识别,语音识别,人脸识别,基因序列分析,医学疾病的识别,油气藏检测,加速器故障检测,电机故障检测,图像压缩和还原;控制及优化方面的化工过程控制,机械手运动控制,运载体轨迹控制等;金融中的股票市场预测,有价证券管理,借贷风险管理,信用卡欺骗检测;通信中的回声抵消,路由选择,自适应均衡,导航等方面。
常用的人工神经网络案例1 感知器网络MatLab上机实验例1.1用newp函数设计一个单输入和一个神经元的感知器神经网络,输入的最小0,2。
值和最大值为[]>> net=newp([0 2],1);可以用下面语句来观察生成了一个什么样的神经网络。
>> inputweights = net.inputWeights{1,1}inputweights =delays: 0initFcn: 'initzero'learn: 1learnFcn: 'learnp'learnParam: []size: [1 1]userdata: [1x1 struct]weightFcn: 'dotprod'weightParam: [1x1 struct]从中可以看到,缺省的学习函数为learnp,网络输入给hardlim传递函数的量为数量积dotprod,即输入量和权值矩阵的乘积,然后再加上阈值。
缺省的初始化函数为initzero,即权值的初始值置为0。
同样地,>> biases = net.biases{1,1}biases =initFcn: 'initzero'learn: 1learnFcn: 'learnp'learnParam: []size: 1userdata: [1x1 struct]设计一个输入为二维向量的感知器网络,其边界值已定。
>> net = newp([-2 2;-2 2],1);和上面的例子一样,权值和阈值的初始值为0。
如果不想预置为0,则必须单独生成。
例如,两个权值和阈值分别为[-1 1]和1,应用如下语句:>> net.IW{1,1}=[-1 1];>> net.b{1,1}=[1];应用下面语句验证一下:>> net.IW{1,1}ans =-1 1>> net.b{1,1}ans =1下面来看这个感知器网络对两个输入信号的输出如何,两个信号分别位于感知器两个边界。
第一个输入信号:>> P1=[1;1];>> a1=sim(net,P1)a1 =1第二个输入信号:>> P2=[1;-1];>> a2=sim(net,P2)a2 =由此看出,输出是正确的,感知器为输入信号进行了正确的分类。
若将两个输入信号组成一个数列,则输出量也为一个数列。
>> P3={[1;1],[1;-1]};>> a3=sim(net,P3)a3 =[1] [0]首先有newp函数生成一个神经网络。
>> net = newp([-2 2;-2 2],1);其权值为:>> wts = net.IW{1,1}wts =0 0其阈值为:>> bias = net.b{1,1}bias =改变权值和阈值:>> net.IW{1,1}=[3,4];>> net.b{1,1}=[5];检查权值和阈值,确实已经改变了:>> wts=net.IW{1,1}wts =3 4>> bias=net.b{1,1}bias =5然后应用init来复原权值和阈值。
>> net=init(net);>> wts = net.IW{1,1}wts =0 0>> bias=net.b{1,1}bias =由此可见,应用init可以复原感知器初始值。
例1.4应用init改变网络输入的权值和阈值为随机数。
>> net.inputweights{1,1}.initFcn='rands';>> net.biases{1,1}.initFcn='rands';>> net=init(net);下面验证一下权值和阈值:>> wts = net.IW{1,1}wts =0.8116 -0.7460>> bias=net.b{1,1}bias =0.6294例1.5假设一个二维向量输入的感知器神经网络,其输入和期望值样本为:112,02p t ⎡⎤==⎢⎥⎣⎦、221,12p t ⎡⎤==⎢⎥-⎣⎦、332,02p t -⎡⎤==⎢⎥⎣⎦、441,11p t -⎡⎤==⎢⎥⎣⎦首先,生成一个感知器网络,然后利用train 函数进行训练>> net = newp([-2 2;-2 2],1);>> net.trainParam.epochs=1; %设置最大迭代次数>> p=[2 1 -2 -1;2 -2 2 1]; %样本>> t=[0 1 0 1]; %导师信号>> net = train(net,p,t);>> w=net.IW{1,1}w =-3 -1>> b=net.b{1,1}b =对输入向量进行仿真验证>> sim(net,p)ans =0 0 1 1可见,网络仿真结果没有达到期望值,通过调整训练最大次数可以看其结果。
>> net.trainParam.epochs=20;>> net = train(net,p,t);>> sim(net,p)ans =0 1 0 1因此训练是成功的,训练规则具有一定的收敛性,并且能够达到精度。
例1.6设计一个二输入感知器神经网络,将五个输入向量分为两类。
P=[-0.5 -0.5 0.5 -0.1;-0.5 0.5 -0.5 1.0]T=[1 1 0 0]首先,应用newp构造一个神经元感知器神经网络,然后利用plotpv画出输入向量图,与期望值1对应的输入向量用“+”表示,与期望值0对应的输入向量用“o”表示。
>> P=[-0.5 -0.5 0.5 -0.1;-0.5 0.5 -0.5 1.0];>> T=[1 1 0 0];>> net = newp([-1 1;-1 1],1);>> plotpv(P,T);>> p=[0.7;1.2];>>net=train(net,P,T);>> a=sim(net,p)a =>> plotpv(p,a);>> hold on>> plotpv(P,T);>> plotpc(net.IW{1,1},net.b{1,1})>> hold off由此可见,感知器网络能够做到对输入向量进行正确分类,同时验证了网络的可行性。
例1.7含有奇异样本的输入向量和期望输出如下:P=[-0.5 -0.5 0.3 -0.1 -40;-0.5 0.5 -0.5 1 50]T=[1 1 0 0 1]首先,应用newp构造一个神经元感知器神经网络,然后利用plotpv画出输入向量图。
>> net=newp([-40 -0.5;-0.5 50],1);>> plotpv(P,T);>> net=train(net,P,T);>> hold on>> plotpc(net.IW{1,1},net.b{1,1}) >> hold off为了使图形清晰,我们修改坐标值放大部分图形。
>> axis([-2 2 -2 2]);由此可见,网络对于输入向量可以做到正确分类,缺点就是样本存在奇异性的情况下训练时间大大增加了。
>> P=[-0.5 -0.5 0.3 -0.1 -40;-0.5 0.5 -0.5 1 50];>> T=[1 1 0 0 1];>> net=newp([-40 -0.5;-0.5 50],1);>> net.inputWeights{1,1}.learnFcn='learnpn';>> net.biases{1,1}.learnFcn='learnpn';>> net=train(net,P,T);>> plotpv(P,T);>> hold on;>> plotpc(net.IW{1,1},net.b{1,1});>> hold off>> axis([-2 2 -2 2])例1.8单层感知器的一个致命弱点就是输入向量必须是线性可分的。
如果输入向量线性可分,感知器可以给出正确的分类结果。
而对于线性不可分的输入向量,感知器就不能对输入向量进行正确分类。
构造五组输入样本P,T是期望输出。
>> P=[-0.5 -0.5 0.3 -0.1 -0.8;-0.5 0.5 -0.5 1.0 0.0];>> T=[1 1 0 0 0];>> plotpv(P,T);>> net = newp(minmax(P),1); >> net = train(net,P,T);>> hold on;>> plotpc(net.IW{1,1},net.b{1,1}); >> hold off不能对其分类,此结果恰恰证明了前面所述的结论。
2 线性神经网络MatLab上机实验例2.1假设输入和期望输出为:>> P=[1 2 3]>> T=[2.0 4.2 5.9]设计网络:>> net = newlind(P,T);通过对输入量进行仿真:>> O=sim(net,P)O =2.0833 4.0333 5.9833可见,网络的输出已经非常接近期望的输出值。
例2.2假设输入和期望输出为:>> P=[2 1 -2 -1;2 -2 2 1];>> T=[0 1 0 1];设计网络:>> net = newlin(minmax(P),1); 训练网络:>> net.trainParam.goal=0.1;>> net = train(net,P,T);>> net.IW{1,1}ans =-0.0615 -0.2194>> net.b{1,1}ans =0.5899网路仿真:>> O=sim(net,P)O =0.0282 0.9672 0.2741 0.4320>> err=T-Oerr =-0.0282 0.0328 -0.2741 0.5680>> mse(err)ans =0.0999例2.3为了测定刀具的磨损速度,做这样的实验:经过一定时间(如每隔一小时),测量一次试根据上面的实验数据建立一个大体合适的神经网络。