隐马尔科夫模型(原理图解)
- 格式:pptx
- 大小:1.88 MB
- 文档页数:23



隐马尔可夫模型(一)——马尔可夫模型马尔可夫模型(Markov Model)描述了一类随机变量随时间而变化的随机函数。
考察一个状态序列(此时随机变量为状态值),这些状态并不是相互独立的,每个状态的值依赖于序列中此状态之前的状态。
数学描述:一个系统由N个状态S= {s1,s2,...s n},随着时间的推移,该系统从一个状态转换成另一个状态。
Q= {q1,q2,...q n}为一个状态序列,q i∈S,在t时刻的状态为q t,对该系统的描述要给出当前时刻t所处的状态s t,和之前的状态s1,s2,...s t, 则t时刻位于状态q t的概率为:P(q t=s t|q1=s1,q2=s2,...q t-1=s t-1)。
这样的模型叫马尔可夫模型。
特殊状态下,当前时刻的状态只决定于前一时刻的状态叫一阶马尔可夫模型,即P(q t=s i|q1=s1,q2=s2,...q t-1=s j) =P(q t=s i|q t-1=s j)。
状态之间的转化表示为a ij,a ij=P(q t=s j|q t-1=s i),其表示由状态i转移到状态j的概率。
其必须满足两个条件: 1.a ij≥ 0 2.=1对于有N个状态的一阶马尔科夫模型,每个状态可以转移到另一个状态(包括自己),则共有N2次状态转移,可以用状态转移矩阵表示。
例如:一段文字中名词、动词、形容词出现的情况可以用有3个状态的y一阶马尔科夫模型M 表示:状态s1:名词状态s2:动词状态s3:形容词状态转移矩阵: s1 s2 s3A=则状态序列O=“名动形名”(假定第一个词为名词)的概率为:P(O|M) = P(s1,s2,s3,s4} = P(s1)*p(s2|s1)p(s3|s2)p(s1|s3)=p(s1)*a12*a23*a31=1*0.5*0.2*0.4=0.04在马尔可夫模型中,每一个状态都是可观察的序列,是状态关于时间的随机过程,也成为可视马尔可夫模型(Visible Markov Model,VMM)。

HMM隐马尔可夫模型在自然语言处理中的应用隐马尔可夫模型(Hidden Markov Model,HMM)是自然语言处理中常用的一种概率统计模型,它广泛应用于语音识别、文本分类、机器翻译等领域。
本文将从HMM的基本原理、应用场景和实现方法三个方面,探讨HMM在自然语言处理中的应用。
一、HMM的基本原理HMM是一种二元组( $λ=(A,B)$),其中$A$是状态转移矩阵,$B$是观测概率矩阵。
在HMM中,状态具有时序关系,每个时刻处于某一状态,所取得的观测值与状态相关。
具体来说,可以用以下参数描述HMM模型:- 隐藏状态集合$S={s_1,s_2,...,s_N}$:表示模型所有可能的状态。
- 观测符号集合$V={v_1,v_2,...,v_M}$:表示模型所有可能的观测符号。
- 初始状态分布$\pi={\pi (i)}$:表示最初处于各个状态的概率集合。
- 状态转移矩阵$A={a_{ij}}$:表示从$i$状态转移到$j$状态的概率矩阵。
- 观测概率矩阵$B={b_j(k)}$:表示处于$j$状态时,观测到$k$符号的概率。
HMM的主要任务是在给定观测符号序列下,求出最有可能的对应状态序列。
这个任务可以通过HMM的三种基本问题求解。
- 状态序列概率问题:已知模型参数和观测符号序列,求得该观测符号序列下各个状态序列的概率。
- 观测符号序列概率问题:已知模型参数和状态序列,求得该状态序列下观测符号序列的概率。
- 状态序列预测问题:已知模型参数和观测符号序列,求得使得观测符号序列概率最大的对应状态序列。
二、HMM的应用场景1. 语音识别语音识别是指将语音信号转化成文字的过程,它是自然语言处理的关键技术之一。
HMM在语音识别领域具有广泛应用,主要用于建立声学模型和语言模型。
其中,声学模型描述语音信号的产生模型,是从语音输入信号中提取特征的模型,而语言模型描述语言的组织方式,是指给定一个句子的前提下,下一个字或单词出现的可能性。
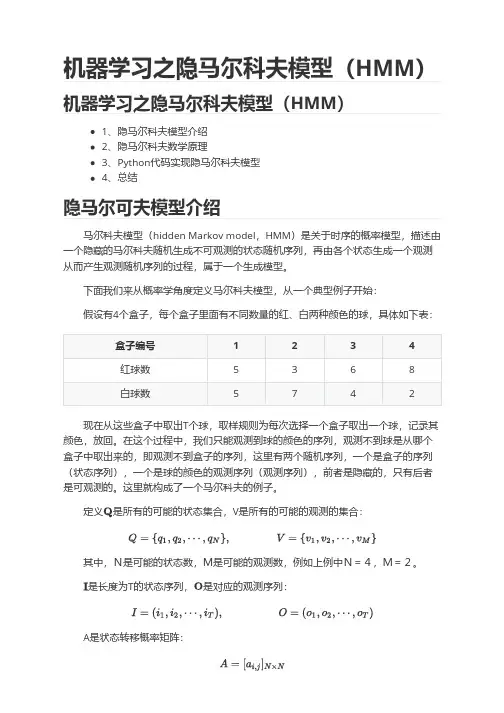
机器学习之隐马尔科夫模型(HMM)机器学习之隐马尔科夫模型(HMM)1、隐马尔科夫模型介绍2、隐马尔科夫数学原理3、Python代码实现隐马尔科夫模型4、总结隐马尔可夫模型介绍马尔科夫模型(hidden Markov model,HMM)是关于时序的概率模型,描述由一个隐藏的马尔科夫随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程,属于一个生成模型。
下面我们来从概率学角度定义马尔科夫模型,从一个典型例子开始:假设有4个盒子,每个盒子里面有不同数量的红、白两种颜色的球,具体如下表:盒子编号1234红球数5368白球数5742现在从这些盒子中取出T个球,取样规则为每次选择一个盒子取出一个球,记录其颜色,放回。
在这个过程中,我们只能观测到球的颜色的序列,观测不到球是从哪个盒子中取出来的,即观测不到盒子的序列,这里有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列),前者是隐藏的,只有后者是可观测的。
这里就构成了一个马尔科夫的例子。
定义是所有的可能的状态集合,V是所有的可能的观测的集合:其中,N是可能的状态数,M是可能的观测数,例如上例中N=4,M=2。
是长度为T的状态序列,是对应的观测序列:A是状态转移概率矩阵:其中, 是指在时刻处于状态的条件下在时刻转移到状态的概率。
B是观测概率矩阵:其中, 是指在时刻处于状态的条件下生成观测的概率。
是初始状态概率向量:其中, 是指在时刻=1处于状态的概率。
由此可得到,隐马尔可夫模型的三元符号表示,即称为隐马尔可夫模型的三要素。
由定义可知隐马尔可夫模型做了两个基本假设:(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻的状态只和-1状态有关;(2)观测独立性假设,观测只和当前时刻状态有关;仍以上面的盒子取球为例,假设我们定义盒子和球模型:状态集合: = {盒子1,盒子2,盒子3,盒子4}, N=4观测集合: = {红球,白球} M=2初始化概率分布:状态转移矩阵:观测矩阵:(1)转移概率的估计:假设样本中时刻t处于状态i,时刻t+1转移到状态j 的频数为那么转台转移概率的估计是:(2)观测概率的估计:设样本中状态为j并观测为k的频数是那么状态j观测为k的概率, (3)初始状态概率的估计为S个样本中初始状态为的频率。


多变量隐马尔可夫模型多变量隐马尔可夫模型(Multivariate Hidden Markov Model,简称MHMM)是一种常用的统计模型,用于描述多个随机变量之间的概率关系。
它是隐马尔可夫模型(Hidden Markov Model,简称HMM)在多维空间中的扩展,广泛应用于语音识别、自然语言处理、生物信息学等领域。
隐马尔可夫模型是一种用来描述状态序列和观测序列之间关系的概率模型。
在传统的HMM中,观测序列是一维的,即每个时刻只观测到一个状态。
而在多变量隐马尔可夫模型中,观测序列是多维的,即每个时刻观测到多个状态。
这种模型能够更准确地捕捉到多个变量之间的相关性,提高模型的表达能力和预测准确度。
在多变量隐马尔可夫模型中,有两个基本假设:观测序列和状态序列之间的条件独立性假设,以及状态转移概率和观测概率的马尔可夫性假设。
根据这两个假设,可以通过对观测序列的统计推断来估计模型的参数,进而进行状态预测和序列生成。
多变量隐马尔可夫模型由三个要素组成:初始状态概率向量、状态转移矩阵和观测概率矩阵。
初始状态概率向量表示模型在初始时刻各个状态的概率分布;状态转移矩阵表示模型在各个时刻状态之间转移的概率;观测概率矩阵表示模型在各个状态下观测到各个观测值的概率分布。
通过这些要素,可以计算出给定观测序列的概率,进而进行状态预测和序列生成。
在实际应用中,多变量隐马尔可夫模型常用于语音识别和自然语言处理。
在语音识别中,观测序列可以表示为一段语音信号的频谱特征序列,状态序列可以表示为对应的语音单元序列(如音素或音节);在自然语言处理中,观测序列可以表示为一段文本的词向量序列,状态序列可以表示为对应的词性序列。
通过训练多变量隐马尔可夫模型,可以提高语音识别和自然语言处理的准确性和效率。
多变量隐马尔可夫模型是一种强大的统计模型,能够描述多个随机变量之间的概率关系。
它在语音识别、自然语言处理、生物信息学等领域有着广泛的应用。
马尔科夫过程马尔科夫过程可以看做是一个自动机,以一定的概率在各个状态之间跳转。
考虑一个系统,在每个时刻都可能处于N个状态中的一个,N个状态集合是{S1,S2,S3,...S N}。
我们如今用q1,q2,q3,…q n来表示系统在t=1,2,3,…n时刻下的状态。
在t=1时,系统所在的状态q取决于一个初始概率分布PI,PI(S N)表示t=1时系统状态为S N的概率。
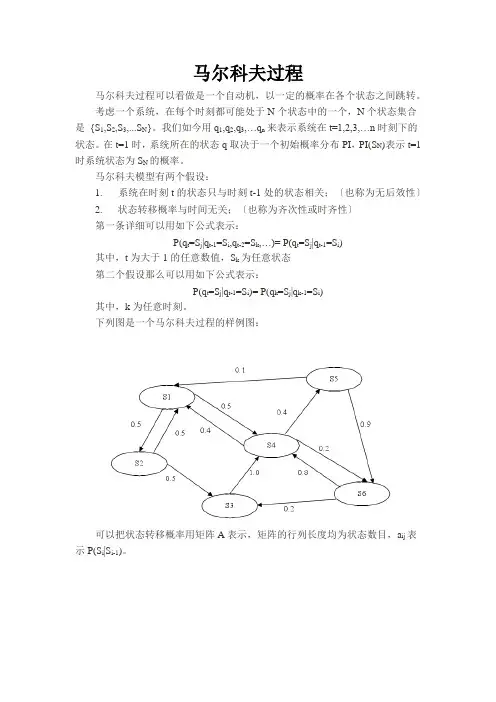
马尔科夫模型有两个假设:1. 系统在时刻t的状态只与时刻t-1处的状态相关;〔也称为无后效性〕2. 状态转移概率与时间无关;〔也称为齐次性或时齐性〕第一条详细可以用如下公式表示:P(q t=S j|q t-1=S i,q t-2=S k,…)= P(q t=S j|q t-1=S i)其中,t为大于1的任意数值,S k为任意状态第二个假设那么可以用如下公式表示:P(q t=S j|q t-1=S i)= P(q k=S j|q k-1=S i)其中,k为任意时刻。
下列图是一个马尔科夫过程的样例图:可以把状态转移概率用矩阵A表示,矩阵的行列长度均为状态数目,a ij表示P(S i|S i-1)。
隐马尔科夫过程与马尔科夫相比,隐马尔科夫模型那么是双重随机过程,不仅状态转移之间是个随机事件,状态和输出之间也是一个随机过程,如下列图所示:此图是从别处找来的,可能符号与我之前描绘马尔科夫时不同,相信大家也能理解。
该图分为上下两行,上面那行就是一个马尔科夫转移过程,下面这一行那么是输出,即我们可以观察到的值,如今,我们将上面那行的马尔科夫转移过程中的状态称为隐藏状态,下面的观察到的值称为观察状态,观察状态的集合表示为O={O1,O2,O3,…O M}。
相应的,隐马尔科夫也比马尔科夫多了一个假设,即输出仅与当前状态有关,可以用如下公式表示:P(O1,O2,…,O t|S1,S2,…,S t)=P(O1|S1)*P(O2|S2)*...*P(O t|S t) 其中,O1,O2,…,O t为从时刻1到时刻t的观测状态序列,S1,S2,…,S t那么为隐藏状态序列。


自然语言处理实验报告课程:自然语言处理系别:软件工程专业:年级:学号:姓名:指导教师:实验一隐马尔可夫模型与序列标注实验一、实验目的1掌握隐马尔可夫模型原理和序列标注2使用隐马尔可夫模型预测序列标注二、实验原理1.隐马尔可夫模型隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。
所以,隐马尔可夫模型是一个双重随机过程----具有一定状态数的隐马尔可夫链和显示随机函数集。
2. 使用隐马尔可夫模型做预测需要的处理步骤收集数据:可以使用任何方法。
比如股票预测问题,我们可以收集股票的历史数据。
数据预处理:收集完的数据,我们要进行预处理,将这些所有收集的信息按照一定规则整理出来,从原始数据中提取有用的列,并做异常值处理操作。
样本生成:根据收集的数据生成样本。
训练模型:根据训练集,估计模型参数。
序列预测并分析结果:使用模型对测试集数据进行序列标注,计算准确率,进行误差分析,可以进行可视化。
三、实验数据收集1.训练数据由于训练数据需要进行大量标注工作,所以训练数据选择了现有的已标注的人民日报1998语料库。
所有文章都已分词完毕,如:1998,瞩目中华。
新的机遇和挑战,催人进取;新的目标和征途,催人奋发。
英雄的中国人民在以江泽民同志为核心的党中央坚强领导和党的十五大精神指引下,更高地举起邓小平理论的伟大旗帜,团结一致,扎实工作,奋勇前进,一定能够创造出更加辉煌的业绩!2.测试数据测试数据使用搜狗实验室的新闻数据集,由于该数据集也是没有标注的数据集,所以手动标注了少量用于测试。
四、实验环境1.Python3.7和JDK1.8五、实验步骤1.数据收集及数据预处理训练数据使用人民日报1998语料库,所以不需要进行太多预处理,主要是测试数据集,我们使用搜狗实验室的新闻数据集,以下是收集和处理过程。
数据分析中的马尔可夫链和隐马尔可夫模型数据分析是当今信息时代中一项重要的技术,通过对海量的数据进行统计和分析,可以从中挖掘出有用的信息和规律,对各个领域产生积极的影响。
而在数据分析中,马尔可夫链和隐马尔可夫模型是两个常用的工具,具有很高的应用价值。
一、马尔可夫链马尔可夫链(Markov chain)是一种随机过程,具有"无记忆性"的特点。
它的特殊之处在于,当前状态只与前一个状态相关,与更早的各个状态无关。
这种特性使马尔可夫链可以被广泛应用于许多领域,如自然语言处理、金融市场预测、天气预测等。
在数据分析中,马尔可夫链可以用来建模和预测一系列随机事件的发展趋势。
通过观察历史数据,我们可以计算不同状态之间的转移概率,然后利用这些转移概率进行状态预测。
以天气预测为例,我们可以根据历史数据得到不同天气状态之间的转移概率,从而预测未来几天的天气情况。
二、隐马尔可夫模型隐马尔可夫模型(Hidden Markov Model,HMM)是马尔可夫链的扩展形式。
在隐马尔可夫模型中,系统的状态是隐含的,我们只能通过观察到的一系列输出来推测系统的状态。
隐马尔可夫模型在很多领域中都有广泛的应用,尤其是语音识别、自然语言处理、生物信息学等方面。
以语音识别为例,输入的语音信号是可观察的输出,而对应的语音识别结果是隐藏的状态。
通过对大量的语音数据进行训练,我们可以得到不同状态之间的转移概率和观测概率,从而在实时的语音输入中进行识别和预测。
三、马尔可夫链和隐马尔可夫模型的应用案例1. 金融市场预测马尔可夫链和隐马尔可夫模型可以应用于金融市场的预测。
通过建立模型,我们可以根据历史数据预测未来的市场状态。
例如,在股票交易中,我们可以根据过去的价格走势来预测未来的股价涨跌情况,以辅助决策。
2. 自然语言处理在自然语言处理领域,马尔可夫链和隐马尔可夫模型经常被用来进行文本生成、机器翻译等任务。
通过对大量文本数据的学习,我们可以构建一个语言模型,用于生成符合语法和语义规则的句子。
隐马尔可夫模型基因序列隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用于描述一个含有隐含未知参数的马尔可夫过程。
在基因序列分析中,隐马尔可夫模型常用于建模基因序列中的模式和特征。
以下是使用隐马尔可夫模型进行基因序列分析的一般步骤:1. 模型建立:- 定义状态:将基因序列中的各个位置或区域定义为状态。
例如,可以将每个碱基(A、C、G、T)定义为一个状态。
- 定义转移概率:确定在不同状态之间转移的概率。
这些转移概率表示从一个状态转移到另一个状态的可能性。
通常,转移概率是根据训练数据或先验知识估计得到的。
- 定义发射概率:确定从每个状态发射出特定碱基的概率。
发射概率表示在某个状态下产生特定碱基的可能性。
同样,这些发射概率通常是根据训练数据或先验知识估计得到的。
2. 模型训练:- 收集训练数据:使用已知的基因序列作为训练数据。
这些训练数据可以来自公共数据库或实验获得的基因序列。
- 估计参数:根据训练数据,通过最大似然估计或其他方法来估计隐马尔可夫模型的参数,包括转移概率和发射概率。
- 优化模型:根据估计的参数,对模型进行优化,以提高其对训练数据的拟合能力。
3. 模型应用:- 序列预测:利用训练好的隐马尔可夫模型,对新的基因序列进行预测。
根据模型的参数,可以预测出序列中每个位置最可能的状态或碱基。
- 特征提取:隐马尔可夫模型可以用于提取基因序列中的特征。
通过分析模型的状态和转移概率,可以发现序列中的模式和特征。
需要注意的是,隐马尔可夫模型在基因序列分析中有一些局限性,例如模型的准确性和可靠性可能受到训练数据的数量和质量的影响。
此外,隐马尔可夫模型通常是一种概率模型,它提供的是序列的概率分布,而不是确定性的预测。
在实际应用中,可以结合其他生物信息学工具和方法,如序列比对、基因注释和功能分析,来综合评估和解释基因序列的特征和意义。