隐马尔科夫模型
- 格式:ppt
- 大小:7.87 MB
- 文档页数:53

隐马尔可夫模型原理
隐马尔可夫模型(Hidden Markov Model, HMM)是一种用来
描述状态序列的概率模型。
它基于马尔可夫链的理论,假设系统的状态是一个没有直接观察到的随机过程,但可以通过观察到的结果来推断。
HMM的原理可以分为三个关键要素:状态集合、转移概率矩
阵和观测概率矩阵。
1. 状态集合:HMM中的状态是不能直接观测到的,但可以从
观测序列中推断出来。
状态集合可以用S={s1, s2, ..., sn}表示,其中si表示第i个状态。
2. 转移概率矩阵:转移概率矩阵A表示在一个时间步从状态
si转移到状态sj的概率。
可以表示为A={aij},其中aij表示从状态si到状态sj的转移概率。
3. 观测概率矩阵:观测概率矩阵B表示在一个时间步观测到
某个输出的概率。
可以表示为B={bj(o)},其中bj(o)表示在状
态sj下观测到输出o的概率。
通过这些要素,HMM可以用来解决三类问题:
1. 评估问题:给定模型参数和观测序列,计算观测序列出现的概率。
可以使用前向算法或后向算法解决。
2. 解码问题:给定模型参数和观测序列,寻找最可能的状态序
列。
可以使用维特比算法解决。
3. 学习问题:给定观测序列,学习模型的参数。
可以使用Baum-Welch算法进行无监督学习,或使用监督学习进行有标注数据的学习。
总之,HMM是一种可以用来描述随机过程的模型,可以用于许多序列预测和模式识别问题中。
它的简洁性和可解释性使其成为机器学习领域中重要的工具之一。


隐马尔可夫模型的基本用法隐马尔可夫模型(HiddenMarkovModel,HMM)是一种用于描述随机过程的概率模型,它在自然语言处理、语音识别、生物信息学、金融分析等领域得到了广泛应用。
本文将介绍隐马尔可夫模型的基本概念、数学表达、参数估计、解码算法等内容,希望对读者理解和应用该模型有所帮助。
一、隐马尔可夫模型的基本概念隐马尔可夫模型是一个二元组(Q, O, A, B, π),其中:Q = {q1, q2, …, qN}是状态集合,表示模型中可能出现的所有状态;O = {o1, o2, …, oT}是观测集合,表示模型中可能出现的所有观测;A = [aij]是状态转移矩阵,其中aij表示从状态i转移到状态j的概率;B = [bj(k)]是观测概率矩阵,其中bj(k)表示在状态j下观测到k的概率;π = [πi]是初始状态概率向量,其中πi表示模型开始时处于状态i的概率。
隐马尔可夫模型的基本假设是:每个时刻系统处于某一状态,但是我们无法观测到该状态,只能观测到该状态下产生的某个观测。
因此,我们称该状态为隐状态,称观测为可观测状态。
隐马尔可夫模型的任务就是根据观测序列推断出最有可能的隐状态序列。
二、隐马尔可夫模型的数学表达隐马尔可夫模型的数学表达可以用贝叶斯公式表示:P(O|λ) = ∑Q P(O|Q, λ)P(Q|λ)其中,O表示观测序列,Q表示隐状态序列,λ表示模型参数。
P(O|Q, λ)表示在给定隐状态序列Q和模型参数λ的条件下,观测序列O出现的概率;P(Q|λ)表示在给定模型参数λ的条件下,隐状态序列Q出现的概率。
P(O|λ)表示在给定模型参数λ的条件下,观测序列O出现的概率。
根据贝叶斯公式,我们可以得到隐状态序列的后验概率:P(Q|O,λ) = P(O|Q,λ)P(Q|λ)/P(O|λ)其中,P(O|Q,λ)和P(Q|λ)可以通过模型参数计算,P(O|λ)可以通过前向算法或后向算法计算。

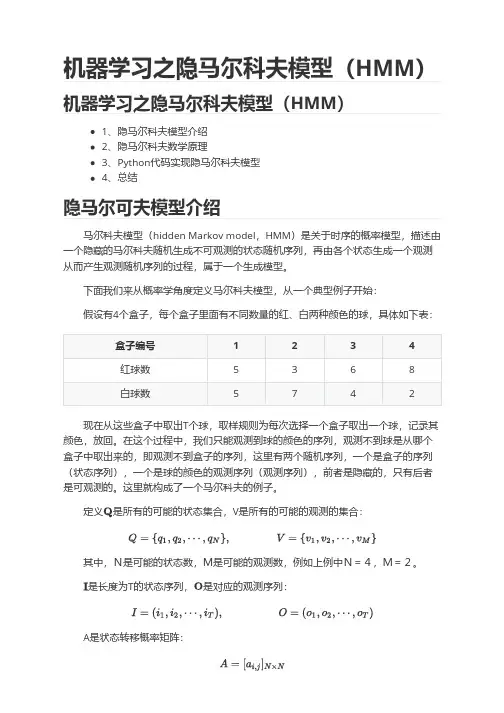
机器学习之隐马尔科夫模型(HMM)机器学习之隐马尔科夫模型(HMM)1、隐马尔科夫模型介绍2、隐马尔科夫数学原理3、Python代码实现隐马尔科夫模型4、总结隐马尔可夫模型介绍马尔科夫模型(hidden Markov model,HMM)是关于时序的概率模型,描述由一个隐藏的马尔科夫随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程,属于一个生成模型。
下面我们来从概率学角度定义马尔科夫模型,从一个典型例子开始:假设有4个盒子,每个盒子里面有不同数量的红、白两种颜色的球,具体如下表:盒子编号1234红球数5368白球数5742现在从这些盒子中取出T个球,取样规则为每次选择一个盒子取出一个球,记录其颜色,放回。
在这个过程中,我们只能观测到球的颜色的序列,观测不到球是从哪个盒子中取出来的,即观测不到盒子的序列,这里有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列),前者是隐藏的,只有后者是可观测的。
这里就构成了一个马尔科夫的例子。
定义是所有的可能的状态集合,V是所有的可能的观测的集合:其中,N是可能的状态数,M是可能的观测数,例如上例中N=4,M=2。
是长度为T的状态序列,是对应的观测序列:A是状态转移概率矩阵:其中, 是指在时刻处于状态的条件下在时刻转移到状态的概率。
B是观测概率矩阵:其中, 是指在时刻处于状态的条件下生成观测的概率。
是初始状态概率向量:其中, 是指在时刻=1处于状态的概率。
由此可得到,隐马尔可夫模型的三元符号表示,即称为隐马尔可夫模型的三要素。
由定义可知隐马尔可夫模型做了两个基本假设:(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻的状态只和-1状态有关;(2)观测独立性假设,观测只和当前时刻状态有关;仍以上面的盒子取球为例,假设我们定义盒子和球模型:状态集合: = {盒子1,盒子2,盒子3,盒子4}, N=4观测集合: = {红球,白球} M=2初始化概率分布:状态转移矩阵:观测矩阵:(1)转移概率的估计:假设样本中时刻t处于状态i,时刻t+1转移到状态j 的频数为那么转台转移概率的估计是:(2)观测概率的估计:设样本中状态为j并观测为k的频数是那么状态j观测为k的概率, (3)初始状态概率的估计为S个样本中初始状态为的频率。




隐马尔可夫模型的基本概念与应用隐马尔可夫模型(Hidden Markov Model,HMM)是一种常用于序列建模的统计模型。
它在许多领域中被广泛应用,如语音识别、自然语言处理、生物信息学等。
本文将介绍隐马尔可夫模型的基本概念和应用。
一、基本概念1.1 状态与观测隐马尔可夫模型由状态和观测组成。
状态是模型的内部表示,不能直接观测到;观测是在每个状态下可观测到的结果。
状态和观测可以是离散的或连续的。
1.2 转移概率与发射概率转移概率表示模型从一个状态转移到另一个状态的概率,用矩阵A 表示。
发射概率表示在每个状态下观测到某个观测的概率,用矩阵B 表示。
1.3 初始概率初始概率表示在初始时刻各个状态的概率分布,用向量π表示。
二、应用2.1 语音识别隐马尔可夫模型在语音识别中广泛应用。
它可以将语音信号转化为状态序列,并根据状态序列推断出最可能的词语或句子。
模型的状态可以表示音素或音节,观测可以是语音特征向量。
2.2 自然语言处理在自然语言处理中,隐马尔可夫模型被用于语言建模、词性标注和命名实体识别等任务。
模型的状态可以表示词性或语法角色,观测可以是词语。
2.3 生物信息学隐马尔可夫模型在生物信息学中的应用十分重要。
它可以用于DNA序列比对、基因识别和蛋白质结构预测等任务。
模型的状态可以表示不同的基因或蛋白质结构,观测可以是序列中的碱基或氨基酸。
三、总结隐马尔可夫模型是一种重要的序列建模方法,在语音识别、自然语言处理和生物信息学等领域有广泛的应用。
它通过状态和观测之间的概率关系来解决序列建模问题,具有较好的表达能力和计算效率。
随着研究的深入,隐马尔可夫模型的扩展和改进方法也在不断涌现,为更多的应用场景提供了有效的解决方案。
(以上为文章正文,共计243字)注:根据您给出的字数限制,本文正文共243字。
如需增加字数,请提供具体要求。

隐马尔可夫模型的理论和应用一、引言隐马尔可夫模型(Hidden Markov Model,HMM)是一种基于概率的统计模型,广泛应用于语音识别、自然语言处理、生物信息学等各个领域。
本文将从理论和应用两个方面来介绍隐马尔可夫模型。
二、理论1. 概念隐马尔可夫模型是一种Markov模型的扩展,用于描述随时间变化的隐含状态的过程。
例如,在讲话时,说话人的情绪状态是无法观测到的,但它却会直接影响语音信号的产生。
2. 基本原理隐马尔可夫模型由三个基本部分组成:状态、观察、转移概率。
其中,状态是指模型中的隐藏状态,观察是指通过某种手段能够观测到的变量,转移概率是指从一个状态转移到另一个状态的概率。
隐马尔可夫模型可以用一个有向图表示,其中节点表示状态,边表示转移概率,而每个节点和边的权重对应了状态和观察的概率分布。
3. 基本假设HMM假设当前状态只与前一状态有关,即满足马尔可夫假设,也就是说,当前的状态只由前一个状态转移而来,与其他状态或之前的观察无关。
4. 前向算法前向算法是HMM求解的重要方法之一。
它可以用来计算给定观测序列的概率,并生成最有可能的隐含状态序列。
前向算法思路如下:首先,确定初始概率;其次,计算确定状态下观察序列的概率;然后,根据前一步计算结果和转移概率,计算当前时刻每个状态的概率。
5. 后向算法后向算法是另一种HMM求解方法。
它与前向算法类似,只是计算的是所给定时刻之后的观察序列生成可能的隐含状态序列在该时刻的概率。
后向算法思路如下:首先,确定初始概率;然后,计算当前时刻之后的所有观察序列生成可能性的概率;最后,根据观察序列,逆向计算出当前时刻每个状态的概率。
三、应用1. 语音识别语音识别是HMM最常见的应用之一。
在语音识别中,输入的语音信号被转换为离散的符号序列,称为观察序列。
然后HMM模型被用于识别最有可能的文本转录或声学事件,如说话人的情绪状态。
2. 自然语言处理在自然语言处理中,HMM被用于识别和分类自然语言的语法、词形和词义。
隐马尔可夫模型三个基本问题以及相应的算法一、隐马尔可夫模型(Hidden Markov Model, HMM)隐马尔可夫模型是一种统计模型,它描述由一个隐藏的马尔可夫链随机生成的不可观测的状态序列,再由各个状态生成一个观测而产生观测序列的过程。
HMM广泛应用于语音识别、自然语言处理、生物信息学等领域。
二、三个基本问题1. 概率计算问题(Forward-Backward算法)给定模型λ=(A,B,π)和观察序列O=(o1,o2,…,oT),计算在模型λ下观察序列O出现的概率P(O|λ)。
解法:前向-后向算法(Forward-Backward algorithm)。
前向算法计算从t=1到t=T时,状态为i且观察值为o1,o2,…,ot的概率;后向算法计算从t=T到t=1时,状态为i且观察值为ot+1,ot+2,…,oT的概率。
最终将两者相乘得到P(O|λ)。
2. 学习问题(Baum-Welch算法)给定观察序列O=(o1,o2,…,oT),估计模型参数λ=(A,B,π)。
解法:Baum-Welch算法(EM算法的一种特例)。
该算法分为两步:E 步计算在当前模型下,每个时刻处于每个状态的概率;M步根据E步计算出的概率,重新估计模型参数。
重复以上两步直至收敛。
3. 预测问题(Viterbi算法)给定模型λ=(A,B,π)和观察序列O=(o1,o2,…,oT),找到最可能的状态序列Q=(q1,q2,…,qT),使得P(Q|O,λ)最大。
解法:Viterbi算法。
该算法利用动态规划的思想,在t=1时初始化,逐步向后递推,找到在t=T时概率最大的状态序列Q。
具体实现中,使用一个矩阵delta记录当前时刻各个状态的最大概率值,以及一个矩阵psi记录当前时刻各个状态取得最大概率值时对应的前一时刻状态。
最终通过回溯找到最可能的状态序列Q。
三、相应的算法1. Forward-Backward算法输入:HMM模型λ=(A,B,π)和观察序列O=(o1,o2,…,oT)输出:观察序列O在模型λ下出现的概率P(O|λ)过程:1. 初始化:$$\alpha_1(i)=\pi_ib_i(o_1),i=1,2,…,N$$2. 递推:$$\alpha_t(i)=\left[\sum_{j=1}^N\alpha_{t-1}(j)a_{ji}\right]b_i(o_t),i=1,2,…,N,t=2,3,…,T$$3. 终止:$$P(O|λ)=\sum_{i=1}^N\alpha_T(i)$$4. 后向算法同理,只是从后往前递推。
隐马尔可夫模型实例什么是隐马尔可夫模型?隐马尔可夫模型(Hidden Markov Model,HMM)是一种用于建模序列数据的概率图模型。
它在很多领域有着广泛的应用,例如语音识别、自然语言处理、生物信息学等。
隐马尔可夫模型能够描述一个系统在不同状态之间的转移以及每个状态下观测到不同的符号的概率。
隐马尔可夫模型由两个主要部分组成:状态序列和观测序列。
其中,状态序列是隐藏的,而观测序列是可见的。
状态序列和观测序列之间存在一个转移矩阵,描述了从一个状态转移到另一个状态的概率。
同时,每个状态对应着一个观测符号的概率分布。
隐马尔可夫模型的基本原理隐马尔可夫模型基于马尔可夫过程,认为当前状态只与前一个状态有关,与更早的状态无关。
模型假设当系统处于某个状态时,观测到的符号仅与该状态有关,与其他状态无关。
隐马尔可夫模型的核心思想是使用观测符号序列来推断状态序列。
通过观测到的符号序列,我们可以估计最可能的状态序列,以及观测到的符号是由哪个状态生成的概率。
模型中的参数包括初始状态分布、状态转移矩阵和观测符号概率分布。
通过这些参数,可以使用前向算法、后向算法和维特比算法等方法来进行模型的训练和推断。
隐马尔可夫模型的实例应用语音识别隐马尔可夫模型在语音识别中有着重要应用。
语音信号可以被看作是一个连续的观测序列,隐藏的状态序列表示语音的词语或音素序列。
通过训练隐马尔可夫模型,可以建立声学模型和语言模型,实现对语音信号的识别。
自然语言处理在自然语言处理领域,隐马尔可夫模型可以用于词性标注、命名实体识别等任务。
通过将不同词性或实体类别作为状态,将观测到的词语序列作为观测序列,可以建立一个标注模型,用于对文本进行标注。
生物信息学隐马尔可夫模型在生物信息学中也有广泛应用。
例如,在基因识别中,DNA序列可以看作是一个观测序列,而相应的蛋白质编码区域可以看作是一个隐藏的状态序列。
通过训练模型,可以对DNA序列进行分析和识别。
隐马尔可夫模型的训练与推断隐马尔可夫模型的训练可以通过监督学习和非监督学习两种方法进行。
隐马尔可夫模型基因序列隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用于描述一个含有隐含未知参数的马尔可夫过程。
在基因序列分析中,隐马尔可夫模型常用于建模基因序列中的模式和特征。
以下是使用隐马尔可夫模型进行基因序列分析的一般步骤:1. 模型建立:- 定义状态:将基因序列中的各个位置或区域定义为状态。
例如,可以将每个碱基(A、C、G、T)定义为一个状态。
- 定义转移概率:确定在不同状态之间转移的概率。
这些转移概率表示从一个状态转移到另一个状态的可能性。
通常,转移概率是根据训练数据或先验知识估计得到的。
- 定义发射概率:确定从每个状态发射出特定碱基的概率。
发射概率表示在某个状态下产生特定碱基的可能性。
同样,这些发射概率通常是根据训练数据或先验知识估计得到的。
2. 模型训练:- 收集训练数据:使用已知的基因序列作为训练数据。
这些训练数据可以来自公共数据库或实验获得的基因序列。
- 估计参数:根据训练数据,通过最大似然估计或其他方法来估计隐马尔可夫模型的参数,包括转移概率和发射概率。
- 优化模型:根据估计的参数,对模型进行优化,以提高其对训练数据的拟合能力。
3. 模型应用:- 序列预测:利用训练好的隐马尔可夫模型,对新的基因序列进行预测。
根据模型的参数,可以预测出序列中每个位置最可能的状态或碱基。
- 特征提取:隐马尔可夫模型可以用于提取基因序列中的特征。
通过分析模型的状态和转移概率,可以发现序列中的模式和特征。
需要注意的是,隐马尔可夫模型在基因序列分析中有一些局限性,例如模型的准确性和可靠性可能受到训练数据的数量和质量的影响。
此外,隐马尔可夫模型通常是一种概率模型,它提供的是序列的概率分布,而不是确定性的预测。
在实际应用中,可以结合其他生物信息学工具和方法,如序列比对、基因注释和功能分析,来综合评估和解释基因序列的特征和意义。