实验二.天气决策树
- 格式:ppt
- 大小:271.00 KB
- 文档页数:12

ID3算法是一种用于构建决策树的经典机器学习算法,它可以根据给定的数据集,自动构建出一个决策树模型,用于对未知数据进行分类。
在实际应用中,ID3算法被广泛应用于各种领域,包括天气预测和决策制定。
本文将以天气和是否适合打球这一主题为例,具体介绍ID3算法对于天气-打球关系的决策树。
1. 背景介绍天气对于人们的日常生活有着重要的影响,尤其是对于室外活动,比如打球。
在实际生活中,人们往往会根据当天的天气情况来决定是否适合进行打球活动。
而要根据天气来进行决策,就需要建立一个天气-打球的决策模型。
而ID3算法正是用来构建这样的决策模型的利器。
2. 数据采集为了构建天气-打球的决策树模型,首先需要收集一定量的天气相关数据和打球相关数据。
可以记录每天的天气情况(如晴天、阴天、下雨)、温度、湿度等天气指标,以及当天是否适合进行打球活动(是/否)。
通过收集大量的这样的数据,就可以构建出一个合适的数据集。
3. 分析数据在收集到足够的数据后,就可以开始分析这些数据,寻找天气与打球之间的关系。
ID3算法的核心思想是选择最佳的属性来进行划分,以便对数据进行分类。
在本例中,可以将天气指标(如晴天、阴天、下雨)作为属性,将打球活动(是/否)作为分类结果,然后根据ID3算法来选择最佳的属性进行数据划分,从而构建出决策树模型。
4. 构建决策树在进行数据分析后,就可以利用ID3算法来构建天气-打球的决策树。
ID3算法通过计算信息增益来确定最佳的属性,然后进行递归地对数据进行划分,直到构建出完整的决策树模型。
在这个过程中,ID3算法会根据不同的属性值来确定最佳的决策点,从而使得对于未知天气情况的打球决策变得更加准确。
5. 评估和优化构建出决策树模型后,还需要对模型进行评估和优化。
可以利用交叉验证等方法来检验模型的准确性,并根据验证结果对模型进行调整和优化。
这一步骤是非常重要的,可以帮助进一步提高决策树模型的预测能力。
6. 应用和推广构建出决策树模型后,可以将其应用到实际的天气预测和打球决策中。

决策树的三种算法一、决策树算法的简单介绍决策树算法就像是一个超级智能的树状决策指南。
你可以把它想象成一棵倒着长的树,树根在上面,树枝和树叶在下面。
它的任务呢,就是根据不同的条件来做出各种决策。
比如说,你想决定今天穿什么衣服,天气就是一个条件,如果天气冷,你可能就选择穿厚衣服;如果天气热,那薄衣服就比较合适啦。
决策树算法在很多地方都超级有用,像预测一个人会不会买某个商品,或者判断一个邮件是不是垃圾邮件之类的。
二、决策树的三种算法1. ID3算法这个算法就像是一个很会找重点的小机灵鬼。
它主要是根据信息增益来构建决策树的。
啥是信息增益呢?就是通过计算某个属性带来的信息量的增加。
比如说,在判断一个水果是苹果还是香蕉的时候,颜色这个属性可能就有很大的信息增益。
如果一个水果是红色的,那它是苹果的可能性就比较大。
ID3算法会优先选择信息增益大的属性来作为树的节点,这样就能更快更准地做出决策啦。
不过呢,这个算法也有个小缺点,就是它比较容易对噪声数据敏感,就像一个很敏感的小娃娃,稍微有点风吹草动就可能受到影响。
2. C4.5算法C4.5算法就像是ID3算法的升级版。
它在ID3算法的基础上做了一些改进。
它不仅仅考虑信息增益,还考虑了信息增益率。
这就好比是一个更加全面考虑的智者。
通过考虑信息增益率,它能够更好地处理那些属性值比较多的情况。
比如说,在一个数据集中有一个属性有很多很多不同的值,C4.5算法就能比ID3算法更好地处理这种情况,不会轻易地被这种复杂情况给弄晕。
而且C4.5算法还能够处理连续的属性值,这就像是它多了一项特殊的技能,让它在更多的情况下都能发挥作用。
3. CART算法CART算法又有自己的特点。
它使用的是基尼系数来选择属性进行划分。
基尼系数就像是一个衡量公平性的小尺子,在决策树这里,它是用来衡量数据的纯度的。
如果基尼系数越小,说明数据越纯,就越容易做出准确的决策。
CART算法既可以用于分类问题,就像前面说的判断水果是苹果还是香蕉这种,也可以用于回归问题,比如预测房价之类的。

人工智能决策树例题经典案例一、经典案例:天气预测决策树在天气预测中有广泛应用,下面是一个关于是否适宜进行户外运动的示例:1. 数据收集:- 温度:高(>30℃)/中(20℃-30℃)/低(<20℃)- 降水:是/否- 风力:高/中/低- 天气状况:晴朗/多云/阴天/雨/暴雨- 应该户外运动:是/否2. 构建决策树:- 根据温度将数据分为三个分支:高温、中温、低温- 在每个分支中,继续根据降水、风力和天气状况进行划分,最终得到是否适宜户外运动的决策3. 决策树示例:温度/ / \高温中温低温/ | | \ |降水无降水风力适宜/ \ | | / \是否高中低| |不适宜适宜- 如果温度是高温且有降水,则不适宜户外运动- 如果温度是高温且无降水,则根据风力判断,如果风力是高,则不适宜户外运动,如果风力是中或低,则适宜户外运动 - 如果温度是中温,则不论降水和风力如何,都适宜户外运动- 如果温度是低温,则需要考虑风力,如果风力是高,则适宜户外运动,如果风力是中或低,则不适宜户外运动4. 参考内容:决策树的构建和应用:决策树通过对输入特征进行划分,构建了一棵树形结构,用于解决分类或回归问题。
构建决策树主要包括数据预处理、特征选择、划分策略和停止条件等步骤。
特征选择可以使用信息增益、基尼指数等算法,划分策略可以使用二叉划分或多叉划分,停止条件可以是叶子节点纯度达到一定阈值或达到预定的树深度。
决策树的应用包括数据分类、特征选择和预测等任务。
天气预测案例中的决策树:将天气预测问题转化为分类问题,通过构建决策树,可以得到识别是否适宜户外运动的规则。
决策树的决策路径可以用流程图或树状图表示,帮助理解和解释决策过程。
决策树的节点表示特征值,分支表示判断条件,叶子节点表示分类结果。
决策树的生成算法可以基于启发式规则或数学模型,如ID3、C4.5、CART等。
决策树的优缺点:决策树具有可解释性强、易于理解和实现、能处理非线性关系等优点。

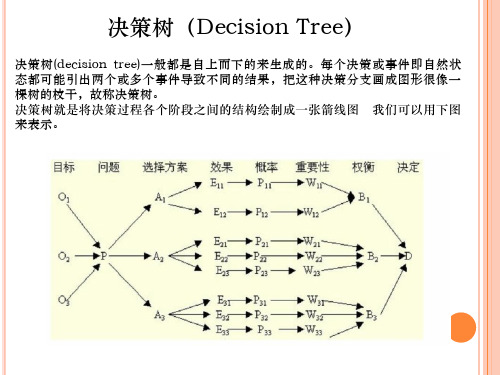
决策树实验一、实验原理决策树是一个类似于流程图的树结构,其中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输入,而每个树叶结点代表类或类分布。
数的最顶层结点是根结点。
一棵典型的决策树如图1所示。
它表示概念buys_computer,它预测顾客是否可能购买计算机。
内部结点用矩形表示,而树叶结点用椭圆表示。
为了对未知的样本分类,样本的属性值在决策树上测试。
决策树从根到叶结点的一条路径就对应着一条合取规则,因此决策树容易转化成分类规则。
图1ID3算法:■决策树中每一个非叶结点对应着一个非类别属性,树枝代表这个属性的值。
一个叶结点代表从树根到叶结点之间的路径对应的记录所属的类别属性值。
■每一个非叶结点都将与属性中具有最大信息量的非类别属性相关联。
■采用信息增益来选择能够最好地将样本分类的属性。
信息增益基于信息论中熵的概念。
ID3总是选择具有最高信息增益(或最大熵压缩)的属性作为当前结点的测试属性。
该属性使得对结果划分中的样本分类所需的信息量最小,并反映划分的最小随机性或“不纯性”。
二、算法伪代码算法Decision_Tree(data,AttributeName)输入由离散值属性描述的训练样本集data;候选属性集合AttributeName。
输出一棵决策树。
(1)创建节点N;(2)If samples 都在同一类C中then(3)返回N作为叶节点,以类C标记;(4)If attribute_list为空then(5)返回N作为叶节点,以samples 中最普遍的类标记;//多数表决(6)选择attribute_list 中具有最高信息增益的属性test_attribute;(7)以test_attribute 标记节点N;(8)For each test_attribute 的已知值v //划分samples(9)由节点N分出一个对应test_attribute=v的分支;(10令S v为samples中test_attribute=v 的样本集合;//一个划分块(11)If S v为空then(12)加上一个叶节点,以samples中最普遍的类标记;(13)Else 加入一个由Decision_Tree(Sv,attribute_list-test_attribute)返回节点值。

决策树是一种常用的机器学习算法,用于分类和回归问题。
其中,信息增益是用来衡量在特征选择过程中一个特征对于分类结果的重要程度。
下面是一个关于信息增益的例题:
假设我们有一个数据集,其中包含以下属性和对应的分类结果:
-属性A:天气(晴天、多云、雨天)
-属性B:温度(高、中、低)
-属性C:湿度(高、中、低)
-分类结果:是否玩球(是、否)
我们的目标是利用决策树算法来构建一个分类模型,判断在给定的天气、温度和湿度条件下,是否适合玩球。
现在,我们要确定在构建决策树时,首先选择哪个属性作为根节点。
我们可以通过计算每个属性的信息增益来进行比较。
首先,计算整个数据集的经验熵(Ent(D)):
Ent(D) = -p(yes) * log2(p(yes)) - p(no) * log2(p(no))
然后,计算属性 A 的信息增益(Gain(A)):
Gain(A) = Ent(D) - p(sunny) * Ent(D_sunny) - p(overcast) * Ent(D_overcast) - p(rainy) * Ent(D_rainy)
其中,D_sunny、D_overcast、D_rainy 分别表示在天气为晴天、多云和雨天时的样本子集,而Ent(D_sunny)、Ent(D_overcast)、Ent(D_rainy) 分别表示这些子集的经验熵。
接着,计算属性 B 和属性 C 的信息增益,依此类推。
最后,比较不同属性的信息增益,选择信息增益最大的属性作为根节点,继续构建决策树。
通过计算每个属性的信息增益,我们可以确定构建决策树时的特征选择顺序,以及每个节点的划分规则,从而实现对新样本进行分类预测。
决策树过拟合例子
以下是 9 条关于决策树过拟合例子:
1. 你看哈,就像预测天气的时候,决策树可能会过度依赖某一天的特殊情况,比如突然下了一场特别大的暴雨,然后就把这个当成常态啦!这不是就过拟合了嘛。
2. 想想选水果那事儿,决策树可能因为某个苹果上有个小小的斑点就判定它是坏的,而忽略了其他好的地方呀,这不就是过拟合了嘛!
3. 嘿,就比如判断一个人爱不爱运动,决策树如果因为这个人某一天跑了个步,就说他超级爱运动,这是不是很不准确,明显过拟合啦!
4. 哎呀呀,在预测股票走势的时候,要是决策树仅凭某几次特殊的波动就得出很离谱的结论,这可咋整,不就是过拟合了嘛。
5. 你想想,用决策树预测学生的成绩,如果因为一次考试超常发挥就觉得会一直这么好,那可不行呀,过拟合啦!
6. 就像判断一种食物好不好吃,决策树不能因为你某一顿特别饿的时候觉得好吃,就一直说好吃呀,这不是过拟合了是啥。
7. 哟呵,判断一部电影好不好看,要是决策树因为你在心情特别好的时候看觉得好,就一直这么认为,这也太容易过拟合啦!
8. 就说判断一个地方适不适合居住,决策树可不能因为你某一次偶然的喜欢就认定啦,这不是妥妥的过拟合嘛。
9. 最后呀,我觉得决策树过拟合真的是要很小心呢,不然得出的结果可就太不靠谱啦!。