昆明理工大学 天气决策树
- 格式:doc
- 大小:336.50 KB
- 文档页数:17

课程设计任务书课程名称:水文统计及水文分析计算课程设计题目:大跌水水电站径流和洪水分析南安河水库设计洪水计算学院:电力工程学院专业:水文水资源工程年级:2015学生姓名:指导教师:张代青日期:2017.4.25教务处制课程设计任务书电力工程学院学院水文与水资源工程专业2015 年级学生姓名:课程设计题目:大跌水水电站径流和洪水分析、南安河水库设计洪水计算课程设计主要内容:大跌水水电站径流和洪水分析径流分析:依据电站引水口处实测径流资料,进行统计特性分析,绘制频率曲线,确定统计参数、设计代表年年径流量及其年内分配,并作出旬平均流量保证曲线,求得保证出力。
洪水分析:依据电站引水口处实测洪峰流量资料,进行统计特性分析,绘制频率曲线,确定统计参数、设计及校核洪峰流量值。
南安河水库设计洪水计算设计暴雨计算:利用《云南省暴雨径流差算图表》中暴雨区划图及分区综合表,进行设计点暴雨量、面暴雨量及雨型计算,求得设计面暴雨量及其时程分配。
产流计算:利用《云南省暴雨径流差算图表》中产流系数分区图进行产流计算,求得逐时净雨量过程。
汇流计算:利用《云南省暴雨径流差算图表》中汇流系数分区图进行汇流计算,求得瞬时单位线、时段单位线及设计洪水过程。
设计指导教师(签字):教学基层组织负责人(签字):2017年4 月25 日目录课程设计任务书 (I)课程设计任务书 (1)课程设计指导书1 (3)课程设计指导书2 (5)水文统计及水文分析计算课程设计 (7)1-1. 大跌水水电站径流和洪水分析 (7)1-1-1流域概况 (7)1-1-2气象特征 (7)1-1-3 水文资料 (8)1-1-4 其它相关参数 (12)1-2.径流分析 (12)1-2-1 设计年径流及其经验频率计算、统计参数估算 (12)1-2-2 P-Ⅲ曲线计算及绘制 (20)1-2-3 设计代表年年平均流量的确定及典型年的选择 (23)1-2-4典型代表年年内分配计算 (23)1-2-5 旬平均流量保证率计算及曲线绘制 (25)1-2-6设计旬平均流量的确定及保证出力的计算 (26)1-3.洪水分析 (31)1-3-1大跌水电站引水口处洪峰流量资料1.75 (31)1-3-2 洪峰流量经验频率及统计参数估计 (31)1-3-3 洪峰P-Ⅲ曲线计算及绘制 (35)1-3-4设计洪峰流量的确定 (35)1-4 结论 (36)二、南安河水库设计洪水计算 (37)2-1.南安河水库基本资料 (37)2-1-1 基本情况 (37)2-1-2 水库基本资料 (37)2-2.设计暴雨计算 (39)2-2-2 各种历时设计和校核点、面暴雨量计算 (41)2-2-3 设计与校核暴雨雨型计算 (48)2-3.产流计算 (51)2-4.汇流计算 (53)2-4-1 瞬时单位线参数m1、n、k值求取 (54)2-4-2 S(t)曲线计算及一小时时段单位线计算 (54)2-4-3设计和校核洪水过程线计算 (58)2-5结论 (64)课程设计指导书11 课程设计题目大跌水水电站径流和洪水分析(有长期实测径流资料)2 课程设计主要内容(1)径流分析依据电站引水口处实测径流资料进行统计特性分析,绘制频率曲线,确定统计参数、各指定频率、设计代表年的年径流量及其年内分配,并作出旬平均流量和旬平均出力保证率曲线,求出保证出力;(2)洪水分析依据设计流域电站引水口处实测洪峰流量资料,进行统计特性分析,绘制频率曲线,确定各指定频率的年最大洪峰流量。


决策树算法在天气评估中的应用决策树(Decision Tree)是一种基于树结构的机器学习算法,能够通过对数据集中特征进行分析和划分,生成一系列的决策规则。
决策树算法在天气评估中有着广泛的应用。
本文将从天气预测和气象灾害评估两个方面介绍决策树算法在天气评估中的应用。
天气预测是利用历史气象数据和其他相关数据来预测未来一段时间内的天气状况。
决策树算法可以通过对历史气象数据的分析和挖掘,找出影响天气变化的主要特征和规律,从而建立预测模型。
决策树算法的优势在于能够直观地呈现特征之间的关系,从而帮助分析师和气象学家理解和解释预测结果。
同时,决策树算法还能够自动地进行特征选择和模型构建,减少了人工干预的需求。
在天气预测中,决策树算法的一个常见应用是对降水概率的预测。
降水概率是一个重要的气象指标,能够帮助人们做出合理的活动安排。
通过对历史气象数据进行分析,决策树算法可以找出与降水概率相关的特征,如温度、湿度、风速等,然后根据这些特征构建预测模型。
通过这个模型,人们可以根据这些特征的观测值来推断当天的降水概率。
这对于农业、交通等领域的决策制定者是非常有帮助的。
另一个应用是天气类型的识别。
不同的天气类型具有不同的气象特征,通过对这些特征的分析和挖掘,决策树算法可以识别出相同类型的天气。
例如,可以利用决策树算法将晴天、阴天、多云、雨天等不同的天气类型进行分类,并根据这些分类结果进行天气评估和预测。
这对于气象观测和预报工作是非常重要的,可以帮助气象学家更好地理解和分析气象现象,提高预报准确率。
除了天气预测,决策树算法还可以应用于气象灾害评估。
气象灾害是指由气象原因引起的灾害,如台风、暴雨、干旱等。
通过对历史气象数据和气象灾害数据的分析,决策树算法可以找出导致气象灾害发生的主要原因和规律。
例如,可以利用决策树算法找出导致台风发生的主要气象特征,如海洋温度、气压梯度、风速等,并建立预测模型。
通过这个模型,可以预测出未来一段时间内发生台风的可能性,并提前采取措施来减少灾害造成的损失。
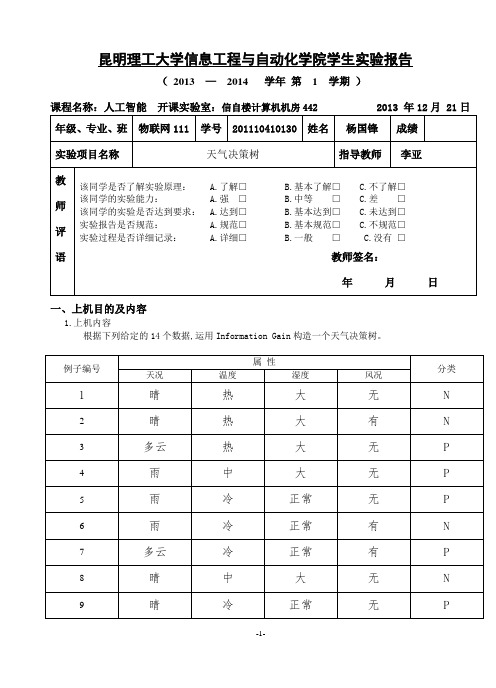
昆明理工大学信息工程与自动化学院学生实验报告(2013 —2014 学年第 1 学期)课程名称:人工智能开课实验室:信自楼计算机机房442 2013 年12月 21日一、上机目的及内容1.上机内容根据下列给定的14个数据,运用Information Gain构造一个天气决策树。
2.上机目的(1)学习用Information Gain 构造决策树的方法; (2)在给定的例子上,构造出正确的决策树; (3)理解并掌握构造决策树的技术要点。
二、实验原理及基本技术路线图(方框原理图或程序流程图)(1)设计并实现程序,构造出正确的决策树; 问题分许:天况——晴、雨、多云 温度——热、中、冷 湿度——大、正常 风况——有、无首先我们要根据每个属性来算出信息增益,接下来我们根据信息增益最大的来进行划分。
选择一个属性,根据该Information Gain 把数据分割为K 份。
分许如下:数据集计算IG划分数据集(2)主要函数流程图:(Basefun 流程图三、所用仪器、材料(设备名称、型号、规格等或使用软件)1台PC及VISUAL C++6.0软件四、实验方法、步骤(或:程序代码或操作过程)Main.cpp:#include <fstream>#include <iostream>#include <list>#include <sstream>#include <string>#include <vector>#include "AttributeValue.h"#include "DataPoint.h"#include "DataSet.h"DataPoint processLine(std::string const& sLine){std::istringstream isLine(sLine, std::istringstream::in);std::vector<AttributeValue> attributes;// TODO: need to handle beginning and ending empty spaces.while( isLine.good() ){std::string rawfield;isLine >> rawfield;attributes.push_back( AttributeValue( rawfield ) );}AttributeValue v = attributes.back();attributes.pop_back();bool type = v.GetType();return DataPoint(attributes, type);}void main(){std::ifstream ifs("in.txt", std::ifstream::in);DataSet initDataset;while( ifs.good() ){// TODO: need to handle empty lines.std::string sLine;std::getline(ifs, sLine);initDataset.addDataPoint( processLine(sLine) );}std::list<DataSet> processQ;std::vector<DataSet> finishedDataSet;processQ.push_back(initDataset);while ( processQ.size() > 0 ){std::vector<DataSet> splittedDataSets;DataSet dataset = processQ.front();dataset.splitDataSet(splittedDataSets);processQ.pop_front();for (int i=0; i<splittedDataSets.size(); ++i){float prob = splittedDataSets[i].getPositiveProb();if (prob == 0.0 || prob == 1.0){finishedDataSet.push_back(splittedDataSets[i]);}else{processQ.push_back(splittedDataSets[i]);}}}std::cout << "The dicision tree is:" << std::endl;for (int i = 0; i < finishedDataSet.size(); ++i){finishedDataSet[i].display();}}Attributevalue.cpp:#include "AttributeValue.h"#include "base.h"AttributeValue::AttributeValue(std::string const& instring): m_value(instring){}bool AttributeValue::GetType(){if (m_value == "P"){return true;}else if (m_value == "N"){return false;}else{throw DataErrException();}}Basefun.cpp:#include <math.h>float log2 (float x){return 1.0 / log10(2) * log10(x);}float calEntropy(float prob){float sum=0;if (prob == 0 || prob == 1){return 0;}sum -= prob * log2(prob);sum -= (1 - prob) * log2 ( 1 - prob );return sum;}Datapiont.cpp:#include <iostream>#include "DataPoint.h"DataPoint::DataPoint(std::vector<AttributeValue> const& attributes, bool type) : m_type(type){for (int i=0; i<attributes.size(); ++i){m_attributes.push_back( attributes[i] );}}void DataPoint::display(){for (int i=0; i<m_attributes.size(); ++i){std::cout << "\t" << m_attributes[i].getValue();}if (true == m_type){std::cout << "\tP";}else{std::cout << "\tN";}std::cout << std::endl;}Dataset.cpp:#include <iostream>#include <map>#include "base.h"#include "DataSet.h"void SplitAttributeValue::display(){std::cout << "\tSplit attribute ID(" << m_attributeIndex << ")\t";std::cout << "Split attribute value(" << m_v.getValue() << ")" << std::endl;}void DataSet::addDataPoint(DataPoint const& datapoint){m_data.push_back(datapoint);}float DataSet::getPositiveProb(){float nPositive = 0;for(int i=0; i<m_data.size(); ++i){if ( m_data[i].isPositive() ){nPositive++;}}return nPositive / m_data.size();}struct Stat{int nPos;int nNeg;int id;};void DataSet::splitDataSet(std::vector<DataSet>& splittedSets){// find all available splitting attributesint nAttributes = m_data[0].getNAttributes();int i, j;std::vector<bool> splittingAttributeBV;splittingAttributeBV.resize(nAttributes);for (i=0; i<nAttributes; ++i){splittingAttributeBV[i] = true;}for (i=0; i<m_splitAttributes.size(); ++i){splittingAttributeBV[ m_splitAttributes[i].getAttributeIndex() ] = false;}std::vector<int> splittingAttributeIds;for (i=0; i<nAttributes; ++i){if (true == splittingAttributeBV[i]){splittingAttributeIds.push_back(i);}}typedef std::map<AttributeValue, Stat, AttributeValueCmp> AttributeValueStat;typedef std::map<AttributeValue, Stat, AttributeValueCmp>::iterator AttributeValueStat_iterator;typedef std::map<AttributeValue, Stat, AttributeValueCmp>::const_iterator AttributeValueStat_const_iterator; // go through data once, and collect needed statistics to calculate entropystd::vector< AttributeValueStat > splittingStats;splittingStats.resize( splittingAttributeIds.size() );for (i=0; i<m_data.size(); ++i){for (j=0; j<splittingAttributeIds.size(); ++j){AttributeValue const& v = m_data[i].getAttribute(splittingAttributeIds[j]);AttributeValueStat_iterator it = splittingStats[j].find(v);if ( splittingStats[j].end() == it ){Stat stat;if ( m_data[i].isPositive() ){stat.nPos = 1;stat.nNeg = 0;stat.id = 0;}else{stat.nPos = 0;stat.nNeg = 1;stat.id = 0;}splittingStats[j].insert(std::pair<AttributeValue, Stat>(v, stat));}else{if ( m_data[i].isPositive() ){it->second.nPos++;}else{it->second.nNeg++;}}}}// display collected statisticsfor (j=0; j<splittingAttributeIds.size(); ++j){std::cout << "Attribute(" << splittingAttributeIds[j] << "):" << std::endl;std::cout << "\tValue \t nPos \t nNeg" << std::endl;for (AttributeValueStat_const_iterator it = splittingStats[j].begin();it != splittingStats[j].end(); ++it){std::cout << "\t" << it->first.getValue() << " \t " << it->second.nPos << " \t " << it->second.nNeg << std::endl;}}// find splitting attributefloat minEntropy = 0.0;int splitAttributeId = -1;for (j=0; j<splittingStats.size(); ++j){int n = m_data.size();float entropy = 0.0;for (AttributeValueStat_iterator it = splittingStats[j].begin();it != splittingStats[j].end(); ++it){int nSamples = it->second.nPos + it->second.nNeg;float p = it->second.nPos;p /= nSamples;entropy += calEntropy(p) * nSamples / n;}if (entropy < minEntropy || -1 == splitAttributeId){minEntropy = entropy;splitAttributeId = j;}}std::cout << "Split at attribute(" << splittingAttributeIds[splitAttributeId] << ")" << std::endl << std::endl;// splitint attrId = splittingAttributeIds[splitAttributeId];AttributeValueStat const& attVStat = splittingStats[splitAttributeId];splittedSets.clear();int k = 0;for (AttributeValueStat_iterator it = splittingStats[splitAttributeId].begin();it != splittingStats[splitAttributeId].end(); ++it){it->second.id = k++;}splittedSets.resize( k);for (i=0; i<k; ++i){for (j=0; j<m_splitAttributes.size(); ++j){splittedSets[i].m_splitAttributes.push_back( m_splitAttributes[j] );}}for (AttributeValueStat_iterator itt = splittingStats[splitAttributeId].begin();itt != splittingStats[splitAttributeId].end(); ++itt){splittedSets[itt->second.id].m_splitAttributes.push_back(SplitAttributeValue(itt->first, attrId));}for (i=0; i<m_data.size(); ++i){AttributeValue const& v = m_data[i].getAttribute(attrId);AttributeValueStat_const_iterator it = attVStat.find(v);if ( attVStat.end() != it ){splittedSets[it->second.id].addDataPoint(m_data[i]);}else{throw DataErrException();}}}void DataSet::display(){int i;std::cout << "Dataset(" << this << ")" << std::endl;for (i=0; i<m_splitAttributes.size(); ++i){m_splitAttributes[i].display();}std::cout << "Data:" << std::endl;for (i=0; i<m_data.size(); ++i){m_data[i].display();}std::cout << std::endl;}五、实验过程原始记录( 测试数据、图表、计算等)六、实验结果、分析和结论首先我们要对问题进行分许,考虑到几个属性:天况——晴、雨、多云;温度——热、中、冷;湿度——大、正常;风况——有、无;然后我们要根据每个属性来算出信息增益,接下来我们根据信息增益最大的来进行划分。
昆明理工大学信息工程与自动化学院学生实验报告(—学年第1学期)课程名称:人工智能开课实验室:信自楼504 年12月 24日一、上机目的及内容1.上机内容根据下列给定的14个数据,运用Information Gain构造一个天气决策树。
2.上机目的(1)学习用Information Gain构造决策树的方法;(2)在给定的例子上,构造出正确的决策树;(3)理解并掌握构造决策树的技术要点。
二、实验原理及基本技术路线图(方框原理图或程序流程图)(1)设计并实现程序,构造出正确的决策树;(2)对所设计的算法采用大O符号进行时间复杂性和空间复杂性分析;实验考虑到几个属性:天况——晴、雨、多云;温度——热、中、冷;湿度——大、正常;风况——有、无;然后根据每个属性来算出信息增益,接下来我们根据信息增益最大的来进行划分。
根据问题设计算法,建立数据结构,设计需要用的类,然后通过编程实现问题求解。
了解和求解最大信息增益和最小熵选择平均熵最小的属性作为根节点,用同样的方法选择其他节点直至形成整个决策树。
dataset 就是具体的划分过程,首先找到可用的划分项目,再第一次划分之后再相关的数据来计算熵。
Main函数流程图Dataset函数主要流程图Basefun函数流程图Attributevalue函数流程图Datapiont函数流程图三、所用仪器、材料(设备名称、型号、规格等或使用软件)1台PC及VISUAL C++6.0软件四、实验方法、步骤(或:程序代码或操作过程)源代码:main函数:#include <fstream>#include <iostream>#include <list>#include <sstream>#include <string>#include <vector>#include "AttributeValue.h"#include "DataPoint.h"#include "DataSet.h"DataPoint processLine(std::string const& sLine){std::istringstream isLine(sLine, std::istringstream::in);std::vector<AttributeValue> attributes;// TODO: need to handle beginning and ending empty spaces.while( isLine.good() ){std::string rawfield;isLine >> rawfield;attributes.push_back( AttributeValue( rawfield ) );}AttributeValue v = attributes.back();attributes.pop_back();bool type = v.GetType();return DataPoint(attributes, type);}void main(){std::ifstream ifs("tree.txt", std::ifstream::in);DataSet initDataset;while( ifs.good() ){// TODO: need to handle empty lines.std::string sLine;std::getline(ifs, sLine);initDataset.addDataPoint( processLine(sLine) );}std::list<DataSet> processQ;std::vector<DataSet> finishedDataSet;processQ.push_back(initDataset);while ( processQ.size() > 0 ){std::vector<DataSet> splittedDataSets;DataSet dataset = processQ.front();dataset.splitDataSet(splittedDataSets);processQ.pop_front();for (int i=0; i<splittedDataSets.size(); ++i){float prob = splittedDataSets[i].getPositiveProb();if (prob == 0.0 || prob == 1.0){finishedDataSet.push_back(splittedDataSets[i]);}else{processQ.push_back(splittedDataSets[i]);}}}std::cout << "The dicision tree is:" << std::endl;for (int i = 0; i < finishedDataSet.size(); ++i){finishedDataSet[i].display();}}DataSet函数:#include <iostream>#include <map>#include "base.h"#include "DataSet.h"void SplitAttributeValue::display(){std::cout << "\tSplit attribute ID(" << m_attributeIndex << ")\t";std::cout << "Split attribute value(" << m_v.getValue() << ")" << std::endl; }void DataSet::addDataPoint(DataPoint const& datapoint){m_data.push_back(datapoint);}float DataSet::getPositiveProb(){float nPositive = 0;for(int i=0; i<m_data.size(); ++i){if ( m_data[i].isPositive() ){nPositive++;}}return nPositive / m_data.size();}struct Stat{int nPos;int nNeg;int id;};void DataSet::splitDataSet(std::vector<DataSet>& splittedSets){// find all available splitting attributesint nAttributes = m_data[0].getNAttributes();int i, j;std::vector<bool> splittingAttributeBV;splittingAttributeBV.resize(nAttributes);for (i=0; i<nAttributes; ++i){splittingAttributeBV[i] = true;}for (i=0; i<m_splitAttributes.size(); ++i){splittingAttributeBV[ m_splitAttributes[i].getAttributeIndex() ] = false;}std::vector<int> splittingAttributeIds;for (i=0; i<nAttributes; ++i){if (true == splittingAttributeBV[i]){splittingAttributeIds.push_back(i);}}typedef std::map<AttributeV alue, Stat, AttributeValueCmp> AttributeValueStat;typedef std::map<AttributeV alue, Stat, AttributeValueCmp>::iterator AttributeValueStat_iterator;typedef std::map<AttributeValue, Stat, AttributeValueCmp>::const_iterator AttributeValueStat_const_iterator;// go through data once, and collect needed statistics to calculate entropystd::vector< AttributeValueStat > splittingStats;splittingStats.resize( splittingAttributeIds.size() );for (i=0; i<m_data.size(); ++i){for (j=0; j<splittingAttributeIds.size(); ++j){AttributeValue const& v = m_data[i].getAttribute(splittingAttributeIds[j]);AttributeValueStat_iterator it = splittingStats[j].find(v);if ( splittingStats[j].end() == it ){Stat stat;if ( m_data[i].isPositive() ){stat.nPos = 1;stat.nNeg = 0;stat.id = 0;}else{stat.nPos = 0;stat.nNeg = 1;stat.id = 0;}splittingStats[j].insert(std::pair<AttributeValue, Stat>(v, stat));}else{if ( m_data[i].isPositive() ){it->second.nPos++;}else{it->second.nNeg++;}}}}// display collected statisticsfor (j=0; j<splittingAttributeIds.size(); ++j){std::cout << "Attribute(" << splittingAttributeIds[j] << "):" << std::endl;std::cout << "\tValue \t nPos \t nNeg" << std::endl;for (AttributeValueStat_const_iterator it = splittingStats[j].begin();it != splittingStats[j].end(); ++it){std::cout << "\t" << it->first.getValue() << " \t " << it->second.nPos << " \t " <<it->second.nNeg << std::endl;}}// find splitting attributefloat minEntropy = 0.0;int splitAttributeId = -1;for (j=0; j<splittingStats.size(); ++j){int n = m_data.size();float entropy = 0.0;for (AttributeValueStat_iterator it = splittingStats[j].begin();it != splittingStats[j].end(); ++it){int nSamples = it->second.nPos + it->second.nNeg;float p = it->second.nPos;p /= nSamples;entropy += calEntropy(p) * nSamples / n;}if (entropy < minEntropy || -1 == splitAttributeId){minEntropy = entropy;splitAttributeId = j;}}std::cout << "Split at attribute(" << splittingAttributeIds[splitAttributeId] << ")" << std::endl << std::endl;// splitint attrId = splittingAttributeIds[splitAttributeId];AttributeValueStat const& attVStat = splittingStats[splitAttributeId];splittedSets.clear();int k = 0;for (AttributeValueStat_iterator it = splittingStats[splitAttributeId].begin();it != splittingStats[splitAttributeId].end(); ++it){it->second.id = k++;}splittedSets.resize( k);for (i=0; i<k; ++i){for (j=0; j<m_splitAttributes.size(); ++j){splittedSets[i].m_splitAttributes.push_back( m_splitAttributes[j] );}}for (AttributeValueStat_iterator itt = splittingStats[splitAttributeId].begin();itt != splittingStats[splitAttributeId].end(); ++itt){splittedSets[itt->second.id].m_splitAttributes.push_back(SplitAttributeValue(itt->first, attrId));}for (i=0; i<m_data.size(); ++i){AttributeValue const& v = m_data[i].getAttribute(attrId);AttributeValueStat_const_iterator it = attVStat.find(v);if ( attVStat.end() != it ){splittedSets[it->second.id].addDataPoint(m_data[i]);}else{throw DataErrException();}}}void DataSet::display(){int i;std::cout << "Dataset(" << this << ")" << std::endl;for (i=0; i<m_splitAttributes.size(); ++i){m_splitAttributes[i].display();}std::cout << "Data:" << std::endl;for (i=0; i<m_data.size(); ++i){m_data[i].display();}std::cout << std::endl;}DataPoint函数:#include <math.h>float log2 (float x){return 1.0 / log10(2) * log10(x);}float calEntropy(float prob){float sum=0;if (prob == 0 || prob == 1){return 0;}sum -= prob * log2(prob);sum -= (1 - prob) * log2 ( 1 - prob );return sum;}Basefun函数:#include <math.h>float log2 (float x){return 1.0 / log10(2) * log10(x);}float calEntropy(float prob){float sum=0;if (prob == 0 || prob == 1){return 0;}sum -= prob * log2(prob);sum -= (1 - prob) * log2 ( 1 - prob );return sum;}AttributeValue函数:#include "AttributeValue.h"#include "base.h"AttributeValue::AttributeValue(std::string const& instring) : m_value(instring){}bool AttributeValue::GetType()if (m_value == "P"){return true;}else if (m_value == "N"){return false;}else{throw DataErrException();}}AttributeValue头文件:#ifndef ATTRIBUTE_V ALUE_H_#define A TTRIBUTE_V ALUE_H_#include <string>class AttributeValue{public:AttributeValue(std::string const& instring);bool GetType();std::string const& getValue() const{return m_value;}private:std::string m_value;};struct AttributeValueCmp{bool operator() (AttributeValue const& lhs, AttributeValue const& rhs) const {return lhs.getValue() < rhs.getValue();}};#endifBase头文件:class DataErrException : public std::exception{float calEntropy(float prob);DataPoint头文件:#ifndef DATA_POINT_H_#define DATA_POINT_H_#include <vector>#include "AttributeValue.h"class DataPoint{public:DataPoint(std::vector<AttributeValue> const& attributes, bool type);bool isPositive(){return m_type;}int getNAttributes(){return m_attributes.size();}AttributeValue const& getAttribute(int index){return m_attributes[index];}void display();private:std::vector<AttributeValue> m_attributes;bool m_type;};#endifDataSet头文件:#include <map>#include <utility>#include "DataPoint.h"class SplitAttributeValue{public:SplitAttributeValue(AttributeValue v, int id): m_v(v), m_attributeIndex(id){}int getAttributeIndex(){return m_attributeIndex;}void display();private:int m_attributeIndex;AttributeValue m_v;};class DataSet{public:void addDataPoint(DataPoint const& datapoint);float getPositiveProb();void splitDataSet(std::vector<DataSet>& splittedSets);void display();private:std::vector<SplitAttributeValue> m_splitAttributes;std::vector<DataPoint> m_data;};五、实验过程原始记录( 测试数据、图表、计算等)六、实验结果、分析和结论(误差分析与数据处理、成果总结等。