完全信息静态博弈及其纳什均衡解
- 格式:docx
- 大小:150.00 KB
- 文档页数:9


大学老师上课点名现象的博弈分析摘要:大学老师上课点名是日常教学过程中很常见的现象。
本文试图通过给定不同的假设条件,用博弈论的基本原理构造出不同的模型,对学生与学生之间、老师与学生间的博弈行为进行分析。
关键词:模型、博弈行为、博弈分析在大学教育中,老师点名被普遍当作是保证学生出勤率督促学生学习的有效方式。
分析老师和学生作为不同的决策主体如何对点名做出反应并判断二者在不同决策下获得的支付(收益),对于改进点名的效率,理解学生的行为模式进而更好地完成教学工作无疑具有重要意义。
一、博弈模型原理概述本文使用的模型主要应用以下博弈论原理:(一)完全信息静态博弈完全信息静态博弈指的是各博弈方同时决策,且所有博弈方对博弈中的各种情况下的策略及其得益都完全了解。
“完全信息”指的是每个参与人对所有其他参与人的特征(包括战略空间、.支付函数等)有完全的了解,“‘静态”指的是所有参与人同时选择行动且只选择一次。
“同时行动”在这里是一个信息概念而非日历上的时间概念:只要每个参与人在选择自己的行动时不知道其他参与人的选择,我们就说他们在同时行动。
(二)纳什均衡在博弈G=﹛S1,…,S n:μ1,…,μn﹜中,如果由各个博弈方的各一个策略组成的某个策论组合(s1*,…,s n*)中,任一博弈方i的策略s i*,都是对其余博弈方策略的组合(s1*,…s i-1*,s i+1*,…,s n*)的最佳对策,也即μi(s1*,…s i-1*,s i*,s i+1*,…,s n*)≥μi(s1*,…s i-1*,s ij*,s i+1*,…,s n*)对任意s ij∈S i都成立,则称(s1*,…,s n*)为G的一个纳什均衡。
(三)混合战略混合战略是指博弈的参与者以一定的概率去选择某种战略。
这类博弈虽然在一次操作中有输有赢,但将这个博弈多次重复进行,可以研究各个战略应赋予多大的概率,能获得最大的期望(平均)收益。
(四)动态博弈动态博弈(dynamic game)是指参与人的行动有先后顺序,而且行动在后者可以观察到行动在先者的选择,并据此作出相应的选择。

第三章完全信息静态博弈及其纳什均衡解1.完全信息静态博弈定义 3.1.完全信息静态博弈。
完全信息静态是指,博弈中的参与人同时采取行动,或者尽管参与人行动的采取有先后顺序,但后行动的人在行动时不知道先采取行动的人采取的是什么行动;同时博弈参与人的策略空间及策略组合下的支付是博弈中所有参与人的“公共知识”。
两个特点:(1)静态;(2)完全信息。
完全信息静态博弈例子。
例1:锤子-剪刀-布例2:交通行驶非“完全信息静态博弈”例子:英式拍卖——动态博弈;第一密封价格及第二密封价格拍卖——不完全信息博弈。
2.纳什均衡及其判定定义3.2 纳什均衡。
在一个n人博弈的标准式G={S1,S2,…,S n; u1,u2,…,u n}中,一个策略组合{s1*,s2*,…,s n*},若满足u i(s1*,…,s i*,…s n*)≥u i(s1*,…s i,…,s n*)(i=1…n),则称这个策略组合为{s1*,s2*,…,s n*}为该博弈G的一个纳什均衡。
某策略组合是纳什均衡指的是,在该策略组合上任何一个参与人的收益在其他人策略不改变的情况下都至少是弱优的。
特点:(1)每个人没有单独改变策略的动机;(2)局部最优。
纳什均衡判定方法:用定义来判定:某点是均衡看它是否符合纳什均衡的定义。
求解纳什均衡的方法:(2)用定义来求解(3)对于策略空间为连续的博弈,用求极值的方法来求得。
3.纳什均衡存在定理:(纳什)定理3.1.在一个n人博弈的标准式G={S1,S2,…,S n; u1,u2,…,u n}中,如果n是有限的,且对每个i, S i是有限的,则博弈至少存在一个纳什均衡。
这里的均衡可能包含混合策略均衡。
证明:略例子3:囚徒困境的均衡例1:“锤子-剪刀-布”的均衡?4.混合策略与混合策略的均衡纯策略与混合策略概念。
定义.3.3.一个策略是纯策略指的是参与人策略空间中的某个确定策略;而一个混合策略是参与人策略空间上的一个概率分布,一般地,某个人i的策略空间为{s i1,s i2,…,s ik},则参与人i在策略空间上的一个概率分布p i=(p i1,p i2,…,p ik)构成他的一个混合策略,其中p i1+p i2+…+p ik=1。




完全信息静态博弈论模型引言:博弈论是研究决策制定者在不同利益冲突场景下的行为和策略选择的数学模型。
在博弈论中,静态博弈是指参与者在同一时间点做出决策的情况。
完全信息表示每个参与者对于其他参与者的行为和策略选择都有完全的了解。
本文将介绍完全信息静态博弈论模型的基本概念、解决方法以及应用领域。
一、基本概念1.1 参与者完全信息静态博弈中,有两个或多个参与者,每个参与者可以是个体、团体或国家等。
参与者通过制定决策来追求自身的利益。
1.2 策略每个参与者在博弈中可以选择的行动方案称为策略。
策略可以是纯策略,即只选择一个确定的行动;也可以是混合策略,即以一定概率选择不同的行动。
1.3 支付函数支付函数是衡量参与者在不同策略组合下所获得效用或利益的函数。
支付函数可以表示为参与者的收益、成本或效用。
1.4 纳什均衡纳什均衡是指在博弈中,每个参与者选择的策略组合使得没有参与者有动机改变自己的策略。
换言之,每个参与者都在给定其他参与者的策略下做出最优的决策。
二、解决方法2.1 支付矩阵为了描述参与者之间的策略选择和支付函数之间的关系,可以使用支付矩阵。
支付矩阵是一个二维矩阵,行表示一个参与者的策略选择,列表示其他参与者的策略选择,每个元素表示对应策略组合下的支付函数。
2.2 最优响应最优响应是指在其他参与者的策略下,参与者能够选择的最优策略。
通过计算每个参与者的最优响应,可以找到纳什均衡。
2.3 前瞻性在完全信息静态博弈中,参与者可以通过推断其他参与者的策略和支付函数来做出决策。
前瞻性是指参与者能够预测其他参与者的行为并做出相应的反应。
三、应用领域完全信息静态博弈论模型广泛应用于经济学、政治学、生物学等领域。
3.1 经济学博弈论在经济学中有广泛应用,如市场竞争、定价策略、拍卖等。
完全信息静态博弈模型可以帮助分析参与者的决策行为,预测市场的走势和结果。
3.2 政治学在政治学中,博弈论可以用于分析选举、政策制定和国际关系等问题。
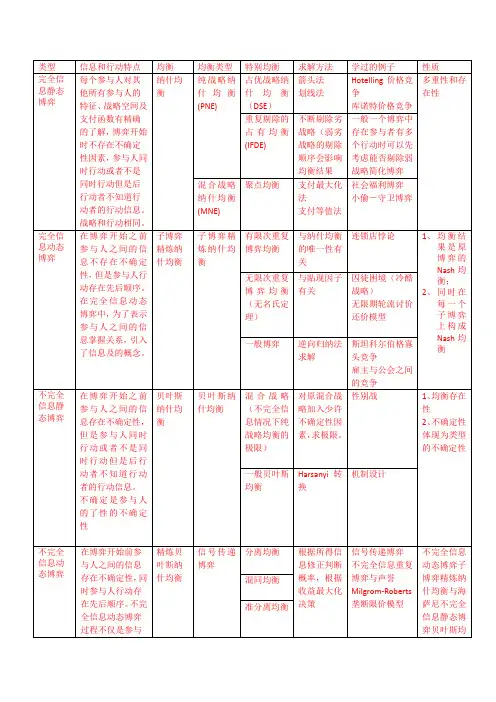


1第四章 完全信息动态博弈及其均衡解1.完全且完美信息动态博弈完全信息博弈指的是参与者的收益是共同知识。
完全且完美信息动态博弈指的是:博弈中的每一步中参与人都知道这一步之前博弈进行的整个过程。
因此,我完全且完美信息动态博弈的特点:(1)行动是顺序发生的;(2)下一步行动选择之前所有以前的行动都可以被观察到;(3)每一可能的行动组合下的参与人的收益都是公共知识。
而不完美信息博弈指的是,在某一步参与人不知道以往博弈所进行的历史或者没有观察到以往的所有行动。
例4.1.我们来考虑这样一个动态博弈: 假定甲在开采一个价值4万元的金矿时需要1万元资金,乙有1万元资金。
甲向乙借钱来开金矿。
在这个博弈的第一阶段,甲向乙承诺: 如果乙借钱给他的话,那么他就会将采到的金子与乙对半分成,即(2,3)——乙得到2万元的金子,同时收回自己的1万元投资。
对于甲的承诺,乙如果不借钱给甲的话,那么博弈到此为止,双方收益为(0,1)。
如果乙借钱给甲的话,那么博弈进入第二个阶段。
在第二阶段中,若甲遵守他的承诺,分给乙一半的金子,这样两人的收益为(2,3),其中1万元为投资成本。
〖JP3〗然而,若甲违背自己的承诺,博弈就会进入到第三个阶段: 如果乙同甲打官司,那么由于打官司费时费力, 两个人的收益为(0,1);若乙不打官司,那么两个人的收益就为(5,0)。
参见图1。
乙借 不借甲分 不分 (0,1)乙 乙 (2,3) 打官司 不打官司(1,2) (5,0)图1. 借钱博弈的博弈树2.逆向归纳法与子博弈纳什均衡解逆向归纳法(Backward induction )又称逆推法,是指这样一种动态博弈求解方法:从博弈的最后一步开始,计算最后一步的参与人的最优行动,逐步逆推到博弈开始时进行第一步的参与人的最优行动,从而确定每个参与人的最优行动。
在动态博弈中逆向归纳法能够进行的前提:参与人是理性的——任何一步参与人都选择甲乙2最优策略;理性是公共知识——参与人选择最优策略是其他人所能够预测的。
在完全且完美信息动态博弈中逆向归纳法能够求得子博弈精炼纳什解。
乙借 ╳ 不借甲分 ╳ 不分 (0,1)乙 乙 (2,3) 打官司 ╳ 不打官司(1,2) (5,0)图2. 借钱博弈的逆向归纳法的求解过程在例4.1中这样一个动态博弈,用逆向归纳法,我们就可以推知,如果甲做出“不分”的选择,那么乙一定会选择“打”官司。
因为对于乙而言,打官司的收益为1,不打官司的收益是0,所以,作为一个理性人,乙一定会选择打官司。
而如果甲知道在“不分”的情况下乙必定选择“打官司”,那么甲就一定会选择“分”一半的金子给乙,因为对甲而言,“分”的收益是2,“不分”的收益是0。
所以,甲的承诺是可置信的。
而对于乙来说,他会选择“借”,因为“借”的收益是3,“不借”的收益是1。
因此,该博弈最终的子博弈精炼纳什均衡点就是(2,3)。
例4.2.斯坦克尔伯模型。
两个厂商垄断某个市场,其中厂商1处于支配地位,它先行动,然后从属企业2后行动。
假定市场需求函数为p=a-Q 。
厂商的单位产品的成本c 。
这些是企业1和2的公共知识。
问:厂商1和2是如何决定的它们的生产产量的。
假定厂商1和2所决定的产量分别为q 1,q 2。
我们用逆向归纳法来求解。
企业2后行动,对于企业1的任何行动,即任意给定的产量,企业2确定产量以使利润最大,即使L 2=p ×q 2-c ×q 2最大。
假定企业1决定的产量为q 1,因为:L 2=p ×q 2-c ×q 2=(a-q 1-q 2)×q 2-c ×q 2由dL 2/dq 2=0:q 1-2q 2=a-c (1)甲乙即:q2=(q1-a+c)/2企业1先行动,它能够预知企业2的最优化行为,即在它的最优产量q1给定的情况下,企业将按照q2=(q1-a+c)/2进行决策。
这样,企业的利润函数为:L1=p×q1-c×q1=(a-q1-q2)×q1-c×q1=(a-q1-q2)×q1-c×q1而q2是q1如下的函数:q2=(q1-a+c)/2由dL1/dq1=0:q1*=(a-c)/2于是,q2*=(a-c)/4因此,((a-c)/2,(a-c)/4)为逆向归纳法解。
该解被称为子博弈精炼纳什均衡解。
此时总产量为q2=3(a-c)/4,价格为(a+3c)/4企业1的利润L1=(a-c)2/8企业2的利润为L2=(a-c)2/16请读者与古诺均衡解进行比较。
3.动态博弈中的威胁与承诺为了实现最大利益,使博弈在博弈参与人所希望的策略组合上实现,在他人作出行动之前的每一步参与人都会向对方可能做出某种威胁或承诺,希望对方做出或者不做出某个行动。
而通过逆向归纳法我们能够区别动态博弈中威胁或承诺是否可信。
例4.1:甲向乙承诺:借钱给我,我赚钱后将分给你。
甲的承诺是可信的。
乙威胁甲:若你不分给我,我将起诉你。
乙的威胁也是可信的。
之所以发生威胁与承诺的言语现象,是因为轮到他人行动的时候,参与人只能通过言语而影响他人的行动从而实现自己希望的结果。
甲之所以承诺,是因为他希望乙能够“借钱”给他。
同样,而乙之所以进行威胁,是因为他借钱之后,希望甲能够连本带利将钱给乙。
当然,在博弈论中因为参与人是理性人,威胁与承诺是否可置信能够被确认。
这样任何威胁与承诺都是没有意义的:若是不可置信,它是公共知识,又何必做这样的威胁或承诺;若是可置信的,因为该博弈是完全且完美信息博弈,做出这样的威胁与承诺也是无益的。
但是在实际生活中,做出这样的威胁与承诺是有意义的,因为,人们不一定认为对方是完全理性人,而认为会发生某种“偏离”:或者会受言语的影响,而“忘记”应该按照计算的行动进行,或者相信了对方的承诺或威胁而改变了原来的行动选择;等等。
4.理性的困境:蜈蚣博弈与最后通牒博弈3逆向归纳法是从动态博弈的最后一步往回推,以求解动态博弈的均衡结果。
它是完全归纳推理,其推理是演绎的,即结论是必然的。
逆向归纳法在逻辑上是严密的,然而它存在着“困境”。
逆向归纳法的逻辑严密性毋庸置疑。
然而,当我们分析一个特殊的博弈——蜈蚣博弈——的时候,一个违背直觉的悖论出现了,这个悖论被认为是对逆向归纳法的挑战。
蜈蚣博弈(centipede game)为罗森塔尔(R.Rosenthal)在1981年提出,我们这里采取的是奥曼(Aumann,1998)论文中的形式1。
安娜鲍伯安娜鲍伯安娜鲍伯2n+22n+12 1 43 2n 2 n-11 4 3 6 2n-12 n+2图 8-2 蜈蚣博弈这个博弈有两个参与人,安娜和鲍伯。
该博弈从安娜开始,她有两个策略“合作”和“不合作”,若她选择“不合作”,博弈即刻终止,安娜得到2,鲍伯得到1;若她选择“合作”,那么博弈继续进行,由鲍伯开始选择。
鲍伯同样有“合作”和“不合作”两种策略。
在这第二轮选择中,若鲍伯选择“不合作”,博弈终止,选择“合作”,博弈继续进行……在这个博弈最后一轮,即第2n轮,若鲍伯选择“不合作”,他所得2n+1,安娜得2n-1;若他选择“合作”,鲍伯得2n+1安娜得2n+2。
因这个博弈树形状像蜈蚣,因而被称为蜈蚣博弈。
在这里我们假定了,总的步数2n是一个双方都知道的有限数。
严格地说,我们假定了,该博弈的总步数2n为双方的公共知识(common knowledge)。
我们用逆向归纳法来分析这个博弈的结果:在最后一步,鲍伯在“合作”与“不合作”中进行选择时,因为“不合作”带给他的好处是2n+2,而“合作”的好处是2n+1,选择“不合作”的好处大于“合作”的好处,鲍伯应当选择“不合作”。
在倒数第二步,安娜这样想,选择“不合作”的好处是2n;而选择“合作”,在下一步鲍伯肯定会选择“不合作”,此时她的好处将是2n-1,因此在这倒数第二步安娜的理性选择“不合作”……通过这样的分析,在这个博弈的第一步安娜的理性的选择是“不合作”。
这样,这个博弈的结果是,在博弈的第一步安娜选择“不合作”,博弈即终止。
这一点构成蜈蚣博弈的完美纳什均衡点。
在这个点上,安娜得到支付2,而鲍伯得到支付1。
这样的结果是反直觉的:最大化自己支付的理性人其所得是不合理的。
从这个博弈树来看,若他们均选择“合作”,双方的支付将会很高。
但根据逆向归纳法,这个结果达不到。
在这个博弈中,每个人考虑到未来他人不合作,自己先采取不合作。
因在最后一步理性的参与人必定采取不合作,每个人的考虑是有逻辑基础的。
于是,一个违反直觉的糟糕结果便出现了。
这便是动态不合作。
对于蜈蚣博弈的这个逆向归纳法解,博弈论专家中存在赞成和反对两种观点。
著名的博弈论专家奥曼(R.J. Aumann)认为,如果“策略人是理性的”是双方的公共知识,逆向归纳法的解必然要达到。
英国伦敦经济学院的宾谟(K.Binmore)教授则认为,在蜈蚣博弈的开始存在混合策略的可能,即在博弈的开始安娜有采取“合作”的非零概率,而轮到鲍伯,他同样有采取“合1Aumann, R.J. Note on the centipede Game[J]. Games and Economic Behavior,1998, vol23,pp97-105.4作”策略的非零概率。
因此,在宾谟看来,该博弈终止于第一步不是必然的。
2本人认为,在最后一步鲍伯合作的概率必然为0,逆推到第一步,安娜的合作概率也必然为0。
这样,宾谟试图通过引进混合策略均衡以作为这个博弈的替代性的解是行不通的。
逆向归纳法悖论依然存在。
最后通牒博弈。
参与人1和2分一笔钱,如100元,1提出分配方案,2表决。
如果参与人1所提出的分配方案得到参与人2的同意,就按照该分配方案分配;如果参与者2拒绝,双方都将一无所获。
逆向归纳法解:6.完全非完美信息动态博弈博弈的扩展式表达囚徒1合作不合作囚徒2 囚徒2合作不合作合作不合作(3,3)(4,1)(1,4)(2,2)6.子博弈纳什均衡解与进化稳定策略在博弈论、行为生态学及演化心理学中,演化稳定策略ESS是一个这样的策略,一旦它被给定环境中的参与人群体采用,它不能被任何其他可能的策略所侵略。
一个ESS是纳什均衡的精炼。
它是演化稳定的纳什均衡:一旦它在一个种群中得到确认,自然选择本身足以放防止变异的可能策略侵略成功。
演化稳定策略在博弈论证是一个中心概念,它由John Maynard Smith和George R. Price在1973首先给出,并被用于人类学、演化心理学、哲学和政治科学之中。
进化稳定策略依赖于侵略的概念。
一个X-策略参与人的群体被Y策略的参与人所造访。
如果新的参与人使用Y策略比X-策略的参与人得分更高,他被认为是侵略的。
假定参与人能够选额和变换策略,这会导致原来的种群开始走向Y策略。