基因芯片数据处理流程与分析介绍
- 格式:docx
- 大小:324.56 KB
- 文档页数:8

基因芯片数据预处理过程
基因芯片数据预处理是指对原始基因芯片数据进行处理、清洗和标准化的过程。
下面是基因芯片数据预处理的主要步骤:
1. 数据导入和存储:将基因芯片数据从原始格式导入到计算机中,并确定存储格式,如矩阵形式。
2. 数据清洗:去除无效数据、缺失数据、异常值和重复数据,以确保数据的质量和一致性。
3. 数据标准化:由于基因芯片数据通常具有不同的量级和分布,需要对数据进行标准化,以便在后续的分析中比较和综合不同样本或基因的表达数据。
常用的标准化方法有Z-score标准化
和最大最小值归一化等。
4. 数据变换:对数据进行变换,以满足统计分析的假设前提。
常见的变换方法包括对数变换、幂变换和Box-Cox变换等。
5. 数据分割:将数据按照实验组和对照组分割,以便在差异分析中进行比较。
6. 批次效应校正:由于实验过程中可能存在批次效应,即同一批次下的样本可能具有相似的表达模式,因此需要对数据进行批次效应校正,以消除批次效应对差异分析的影响。
7. 基因筛选:基因芯片数据通常包含大量的基因,为了减少多重比较问题和提高模型的可解释性,需要对基因进行筛选,选
择具有显著差异表达的基因进行后续分析。
8. 数据集成和整合:将不同芯片平台或实验中得到的数据进行整合,以增加样本量和数据的可靠性。
以上是基因芯片数据预处理的一般步骤,根据具体的研究目的和数据特点,可能还会有其他特定的处理方法。

基因芯片检测流程基因芯片检测是一种高通量的基因分析技术,可以同时检测大量基因的表达水平或基因组的变异情况。
该技术的流程主要包括样本准备、芯片处理、数据分析和结果解读等步骤。
首先,样本准备是基因芯片检测的关键步骤。
样本可以是组织、细胞、血液等。
首先,需要提取样本中的总RNA,然后利用逆转录酶将RNA转录成cDNA,并标记上荧光染料。
这一步骤可以通过不同的实验方法进行,如全基因组扩增、dscDNA合成等。
随后,将标记好的cDNA与芯片上的探针进行杂交反应。
其次,芯片处理是对标记好的cDNA进行杂交的步骤。
将标记好的cDNA溶液滴在芯片上,并利用温度控制设备进行加热、冷却等环境控制,促进标记物与芯片上的探针结合。
芯片上的探针可以是单链DNA、RNA或寡核苷酸等,可以选择特定的探针来检测特定基因。
然后,进行数据分析是基因芯片检测的重要步骤。
通过激光扫描芯片上的标记物,可以获取荧光强度信号。
这些信号表示了样本特定基因的表达水平。
通过对比不同样本之间的信号差异,可以分析某个基因在不同样本中的表达差异。
数据分析可以使用各种统计学方法和生物信息学工具进行,常用的包括聚类分析、差异表达分析、富集分析等。
最后,基因芯片检测的结果解读是整个流程的最终目标。
数据分析得到了许多的基因表达信息和差异表达基因,需要对这些数据进行解读和分析。
通过比对已有的数据库和研究结果,可以找出与特定疾病或生理过程相关的重要基因。
进一步的实验验证可以进一步证实芯片分析结果的可靠性。
综上所述,基因芯片检测流程是一个复杂且关键的分子生物学技术。
通过样本准备、芯片处理、数据分析和结果解读等步骤,可以对大量基因进行快速、高通量的检测和分析。
基因芯片检测在疾病诊断、生物学研究等领域具有重要的应用价值。

生物信息学讲义——基因芯片数据分析生物信息学是指运用计算机技术和统计学方法来解析和理解生物领域的大规模生物数据的学科。
基因芯片数据分析是生物信息学研究的一个重要方向,通过对基因芯片数据进行分析,可以揭示基因在生物过程中的功能和调节机制。
本讲义将介绍基因芯片数据的分析方法和应用。
一、基因芯片数据的获取与处理基因芯片是一种用于检测和测量基因表达水平的高通量技术,可以同时检测上千个基因的表达情况。
获取基因芯片数据的第一步是进行基因芯片实验,如DNA芯片实验或RNA芯片实验。
实验得到的数据一般为原始强度值或信号强度值。
接下来,需要对这些原始数据进行预处理,包括背景校正、归一化和过滤噪声等步骤,以消除实验误差和提高数据质量。
二、基因表达分析基因芯片数据的最主要应用之一是进行基因表达分析。
基因表达分析可以揭示在不同条件下基因的表达模式和差异表达基因。
常用的基因表达分析方法包括差异表达分析、聚类分析和差异共表达网络分析等。
差异表达分析常用来寻找在不同条件下表达差异显著的基因,如差异表达基因的筛选和注释;聚类分析可以将表达模式相似的基因分为一组,如聚类分析可以将不同样本中的基因按照表达模式进行分类;差异共表达网络分析可以找到一组在差异表达样本中共同表达的基因,揭示潜在的功能模块。
三、功能富集分析对差异表达基因进行功能富集分析可以帮助我们理解这些基因的生物学功能和参与的生物过程。
功能富集分析可以通过对差异表达基因进行GO(Gene Ontology)注释,找到在特定条件下富集的生物学过程、分子功能和细胞组分等。
另外,功能富集分析还可以进行KEGG(Kyoto Encyclopedia of Genes and Genomes)富集分析,找到差异表达基因在代谢通路和信号传导通路中的富集情况。
四、基因调控网络分析基因调控网络分析可以帮助我们揭示基因间的调控关系和寻找关键调控基因。
基因调控网络是基于差异表达数据构建的,它可以包括转录因子-靶基因调控网络和miRNA-mRNA调控网络等。

免疫学中基因芯片的应用及数据分析方法基因芯片是一种新型的生物技术工具,它被广泛运用于生物学研究、医学诊断以及农业等领域。
在免疫学研究中,基因芯片可以用来分析基因表达,研究免疫系统的生物学和病理生理学,以及开发新的免疫疗法。
本文将探讨免疫学中基因芯片的应用及数据分析方法。
一、基因芯片在免疫学研究中的应用基因芯片技术基于DNA序列互补的原理,可以同时探测几千个基因在不同生理和病理条件下的表达水平。
在免疫学研究中,基因芯片技术可以用来研究免疫系统中与疾病相关的基因表达变化,为免疫治疗的开发提供重要的信息。
1. 免疫系统基因表达谱的分析免疫系统是一种复杂的网络,包括免疫细胞、激素和细胞因子等多种成分。
在不同生理和病理条件下,免疫系统中的基因表达模式会发生变化,这些变化与多种疾病的发生和发展密切相关。
利用基因芯片技术可以对免疫系统中的基因表达谱进行全面的分析,从而发现与免疫系统相关的新的治疗靶点。
2. 免疫治疗的监测免疫治疗是一种新兴的治疗模式,包括肿瘤免疫治疗、自身免疫病治疗以及感染病治疗等。
基因芯片技术可以用来监测免疫治疗的效果,并评估治疗的预后。
例如,利用基因芯片技术可以分析免疫治疗后T细胞的基因表达谱,从而预测治疗是否成功。
3. 病原体识别和分析免疫系统的主要功能是识别和清除病原体,基因芯片技术可以用来识别和分析各种病原体的基因表达模式,从而发现新的病原体治疗靶点,为针对性治疗提供依据。
二、基因芯片数据分析方法基因芯片技术可以同时测量成千上万个基因的表达水平,产生的数据量很大,数据分析也是一个复杂的过程。
一般情况下,基因芯片数据分析包括数据预处理、差异基因筛选、聚类分析、生物学意义的解释等几个步骤。
1. 数据预处理数据预处理指的是原始的基因芯片数据清洗与归一化的过程,这是数据分析的关键步骤。
数据预处理的目的是剔除芯片噪声、基准样本处理、将不同芯片数据进行标准化处理,提高数据质量和可靠性,为后续分析打下基础。

基因芯片检测原理及简要过程1.样本准备:首先需要从目标生物体中获得样本,可以是DNA、RNA或蛋白质。
样本处理的方式根据研究目的不同而不同,可能需要提取DNA或RNA,并对其进行纯化和扩增。
2.样本标记:为了将样本引入芯片中进行检测,样本需要与荧光标记物结合。
在样本处理过程中,可以使用反应物来标记样本中的基因或序列。
标记物的选择基于实验设计和研究目的。
3.杂交:标记的样本与芯片上的核酸探针进行杂交反应。
核酸探针是单链DNA分子,具有与目标样本中的DNA互补的序列。
这种杂交反应是通过将样本和核酸探针同时加入一个反应混合物中,使它们相互结合。
4.洗涤:经过杂交反应后,需要对芯片进行洗涤以去除未结合的标记物和杂交物。
这个过程是为了减少背景信号,提高检测的特异性和灵敏度。
5.扫描:在洗涤后,芯片被放入一台专门的扫描仪中,这个扫描仪使用激光或LED光源来激发标记物的荧光信号。
随后,该信号被检测并记录下来。
6.数据分析:通过扫描仪获得的数据可以用来分析芯片上的每个探针的荧光强度。
根据荧光强度的变化,可以推断出样本中的基因表达和变异情况。
通常使用的数据分析方法包括基因差异分析、聚类分析、富集分析和通路分析等。
总结起来,基因芯片检测是一种高通量的基因分析技术,可以同时检测数以千计的基因或序列,用于揭示基因表达和变异的情况。
其基本原理是通过将样本与芯片上的核酸探针进行杂交,再通过标记物的荧光信号检测和数据分析,得出样本中的基因信息。
这项技术已经广泛应用于基因组学、遗传学、癌症研究等领域,促进了对基因功能和疾病机制的理解。
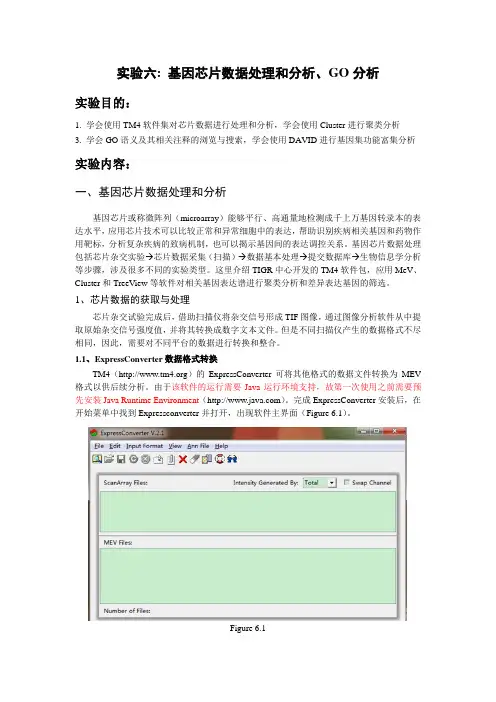

基因芯片数据处理流程与分析介绍关键词:基因芯片数据处理当人类基因体定序计划的重要里程碑完成之后,生命科学正式迈入了一个后基因体时代,基因芯片(microarray) 的出现让研究人员得以宏观的视野来探讨分子机转。
不过分析是相当复杂的学问,正因为基因芯片成千上万的信息使得分析数据量庞大,更需要应用到生物统计与生物信息相关软件的协助。
要取得一完整的数据结果,除了前端的实验设计与操作的无暇外,如何以精确的分析取得可信数据,运筹帷幄于方寸之间,更是画龙点睛的关键。
基因芯片的应用基因芯片可以同时针对生物体内数以千计的基因进行表现量分析,对于科学研究者而言,不论是细胞的生命周期、生化调控路径、蛋白质交互作用关系等等研究,或是药物研发中对于药物作用目标基因的筛选,到临床的疾病诊断预测,都为基因芯片可以发挥功用的范畴。
基因表现图谱抓取了时间点当下所有的动态基因表现情形,将所有的探针所代表的基因与荧光强度转换成基本数据(raw data) 后,仿如尚未解密前的达文西密码,隐藏的奥秘由丝丝的线索串联绵延,有待专家抽丝剥茧,如剥洋葱般从外而内层层解析出数千数万数据下的隐晦含义。
要获得有意义的分析结果,恐怕不能如泼墨画般洒脱随兴所致。
从raw data 取得后,需要一连贯的分析流程(图一),经过许多统计方法,才能条清理明的将raw data 整理出一初步的分析数据,当处理到取得实验组除以对照组的对数值后(log2 ratio),大约完成初步的统计工作,可进展到下一步的进阶分析阶段。
图一、整体分析流程。
基本上raw data 取得后,将经过从最上到下的一连串分析流程。
(1) Rosetta 软件会透过统计的model,给予不同的权重来评估数据的可信度,譬如一些实验操作的误差或是样品制备与处理上的瑕疵等,可已经过Rosetta error model 的修正而提高数据的可信值;(2) 移除重复出现的探针数据;(3) 移除flagged 数据,并以中位数对荧光强度的数据进行标准化(Normalized) 的校正;(4) Pearson correlation coefficient (得到R 值) 目的在比较技术性重复下的相似性,R 值越高表示两芯片结果越近似。


生物信息学讲义——基因芯片数据分析资料基因芯片是一种高通量的技术,可以用于同时检测和量化数以千计的基因在一个样本中的表达水平。
通过分析基因芯片数据,我们可以获得大量的基因表达信息,并进一步了解基因在不同条件和疾病状态下的调控和功能。
下面是一份关于基因芯片数据分析的讲义。
一、基因芯片数据的处理与预处理1.数据获取与质控-从基因芯片实验中获取原始数据(CEL文件)。
-进行质控,包括检查芯片质量、样本质量和数据质量。
2.数据预处理-背景校正:去除背景信号,减小非特异性杂音。
-样本标准化:对样本间进行标准化处理,消除技术变异和样本间差异。
-基因过滤:去除低表达和不变的基因,减少多重检验问题。
二、差异基因分析1.统计分析-基于统计学的差异表达分析方法,如t检验、方差分析(ANOVA)等。
-根据差异分析结果,获取差异表达的基因列表。
2.功能注释与生物学解释-对差异表达的基因进行功能注释,包括富集分析、通路分析和基因功能类别分析等。
-通过生物学数据库查询和文献阅读,解释差异表达基因的生物学意义和可能的调控机制。
三、基因共表达网络分析1.相关性分析-计算基因间的相关系数,筛选出相关性较高的基因对。
-构建基因共表达网络,通过网络可视化方式展示基因间的关系。
2.模块发现和功能注释-使用聚类算法将基因分组成不同的模块,每个模块表示一组具有相似表达模式的基因。
-对每个模块进行功能注释,了解模块内基因的共同功能或通路。
四、基因云图和热图分析1.基因云图-使用基因注释信息和基因表达水平,绘制基因表达的云图。
-通过颜色和大小表示基因的表达水平、功能注释等信息。
2.热图分析-根据基因表达水平计算基因间的相似性,将相似性转换为颜色,绘制热图。
-热图可用于显示基因表达模式的相似性和差异。
五、整合分析与生物信息学工具1.基因集富集分析-将差异表达的基因列表输入基因富集分析工具,寻找与特定通路、功能或疾病相关的基因集。
2.数据可视化工具- 使用生物信息学工具和软件,如R、Bioconductor、Cytoscape等,进行数据可视化和交互式分析。

基因芯片的操作流程及步骤基因芯片是一种用于检测和分析基因表达的高通量技术。
它能够同时检测上万个基因,在生物医学研究、生物工程和临床诊断等领域具有重要的应用价值。
基因芯片的操作流程主要包括前处理、杂交、显像和数据分析等步骤。
下面是详细的操作流程及各步骤的介绍。
1.前处理:a.提取RNA:从细胞或组织中提取总RNA,可以使用常规的酚/氯仿法或者商业化的RNA提取试剂盒等方法。
b.反转录:使用反转录酶将RNA逆转录成cDNA,以便进一步扩增和检测。
这一步骤可以使用随机引物或专用的引物结合反转录酶进行。
2.样品标记:a.样品标记:将cDNA样品标记为荧光基团,例如使用荧光染料dCTP 或其他标记物。
b.去除杂交物:通过水解或其他方法去除未反应的标记试剂,并纯化标记后的cDNA样品。
3.制备探针:a.设计探针:选择适当的探针序列,通常是与待检测基因的特定片段互补的DNA片段,用于检测基因表达。
b.生产探针:使用DNA合成技术或PCR等方法合成大量的探针,通常是固定在玻片上的寡核苷酸序列。
4.杂交:a.样品混合:将标记后的cDNA样品与探针混合,可以加入包含缓冲液、杂交解聚剂等的杂交液。
b.杂交反应:在恒温条件下,将混合物进行杂交反应,使探针与标记的cDNA靶标发生互补反应,形成探针-靶标复合物。
5.洗涤:a.洗涤:使用一系列含有不同浓度盐或洗涤缓冲液的溶液,去除没有结合的或非特异结合的探针-靶标复合物。
b.除去二级结构和非特异结合:使用高盐浓度的洗涤缓冲液或其他特定条件洗涤,去除可能形成的非特异结合和二级结构。
6.显像:a.扫描:使用光学设备测量芯片上的荧光强度,将探针-靶标复合物的检测结果转化为数字信号。
b.校准:对每个荧光信号进行校准,以消除技术偏差和背景噪声。
7.数据分析:a.数据提取:将荧光强度数据转化为基因表达的相对量,通常是使用专门的数据分析软件进行。
b.统计分析:使用统计学方法对基因表达数据进行分析,包括聚类分析、差异表达分析和信号通路分析等。

基因芯片数据预处理过程一、引言基因芯片是一种高通量的生物技术工具,可以用于同时检测和分析大量基因的表达水平、突变状态或基因组的DNA甲基化等信息。
然而,原始的基因芯片数据常常存在噪音干扰、背景信号、批次效应等问题,因此需要进行预处理以提高数据质量和可靠性。
本文将介绍基因芯片数据预处理的一般过程。
二、数据质量控制基因芯片数据预处理的第一步是对数据进行质量控制。
这包括对原始数据进行质量评估、样本间和芯片间的一致性检验、检测异常值和缺失值等。
通过这些步骤可以排除数据中的异常样本或异常数据点,保证后续分析的准确性和可靠性。
三、背景校正和归一化基因芯片数据中常常包含了背景信号,这是由芯片材料、杂交实验等因素引起的非特异性信号。
为了排除这些背景信号的影响,需要进行背景校正。
常用的方法有全局背景校正和局部背景校正。
全局背景校正是通过对所有探针的背景信号进行估计和减法来实现的,而局部背景校正则是根据每个探针的邻近探针计算出背景信号并进行减法。
背景校正后,还需要进行归一化处理,以消除不同芯片、批次和实验之间的技术差异。
常用的归一化方法有全局归一化和局部归一化。
四、探针注释和基因表达估计基因芯片中的探针与具体基因之间的关系需要进行注释,以确定每个探针对应的基因。
注释的过程可以借助公开数据库和基因注释软件来实现。
完成注释后,可以通过一定的统计模型和算法来估计基因的表达水平。
常用的方法有基于强度的表达估计和基于比例的表达估计。
五、差异分析和功能富集基因芯片数据预处理后,可以进行差异分析来寻找在不同样本或条件下表达差异显著的基因。
差异分析的方法有很多,包括t检验、方差分析、贝叶斯方法等。
差异分析得到的显著差异基因可以进一步进行功能富集分析,以了解这些基因在生物学功能和通路上的富集情况。
六、数据可视化和结果解释基因芯片数据预处理的最后一步是将结果进行可视化展示,并进行解释和分析。
通过数据可视化可以直观地了解数据的分布、差异和模式,辅助研究人员进行结果解释和进一步的研究设计。
基于生物信息学的基因芯片数据分析技术研究随着生物技术的进步,生命科学研究中的基因芯片数据越来越多,也越来越复杂,对于如何较好地分析这些数据,成为了当前生物信息学研究的一个重要课题。
本文将结合实际案例,探讨基于生物信息学的基因芯片数据分析技术研究。
1. 基因芯片技术简介基因芯片是一种高通量的检测方法,也称为基因表达谱(gene expression profiling)技术。
它可以同时检测成千上万个基因的表达水平,从而揭示基因表达与疾病、发育等生物过程之间的联系。
基因芯片的数据量巨大,分析也越来越复杂,因此需要借助生物信息学的方法来进行数据处理和分析。
2. 基因芯片数据分析流程基因芯片数据分析的基本流程包括预处理(preprocessing)、差异分析(differential analysis)、聚类分析(clustering analysis)和富集分析(enrichment analysis)四个部分。
2.1 预处理预处理是指通过对原始数据的质控、标准化和筛选,减少噪声、消除实验误差和归一化处理等,从而得到高质量的数据。
具体预处理步骤包括芯片图像分析、原始数据提取、背景校正、数据标准化、基因过滤、批次效应调整等。
2.2 差异分析差异分析是指比较不同实验组的基因表达差异,从而确定与特定现象有关的基因。
通常采用的方法包括t检验、方差分析、t-test、SAM等,差异分析后得到的结果通常以p值和折叠变化(fold changes)为标准。
2.3 聚类分析聚类分析是指将相似的样本或基因聚集在一起,从而揭示样本或基因在表达模式上的共性和差异。
主要方法包括层次聚类(hierarchical clustering)和K-means聚类等。
聚类分析后,可以通过热图(heatmap)和散点图(scatter plot)等方式可视化聚类结果。
2.4 富集分析富集分析是指对差异基因的功能和通路进行注释和分析,从而了解这些基因参与的生物过程、疾病和代谢通路等。
基因芯片(Affymetrix)分析2:芯片数据预处理基因芯片技术的特点是使用寡聚核苷酸探针检测基因。
前一节使用ReadAffy函数读取CEL文件获得的数据是探针水平的(probe level),即杂交信号,而芯片数据预处理的目的是将杂交信号转成表达数据(即表达水平数据,expression level data)。
存储探针水平数据的是AffyBatch类对象,而表达水平数据为ExpressionSet类对象。
基因芯片探针水平数据处理的R软件包有affy, affyPLM, affycomp, gcrma等,这些软件包都很有用。
如果没有安装可以通过运行下面R语句安装:Affy芯片数据的预处理一般有三个步骤:•背景处理(background adjustment)•归一化处理(normalization,或称为“标准化处理”)•汇总(summarization)。
最后一步获取表达水平数据。
需要说明的是,每个步骤都有很多不同的处理方法(算法),选择不同的处理方法对最终结果有非常大的影响。
选择哪种方法是仁者见仁智者见智,不同档次的杂志或编辑可能有不同的偏好。
1 需要了解的一点Affy芯片基础知识Affy基因芯片的探针长度为25个碱基,每个mRNA用11~20个探针去检测,检测同一个mRNA的一组探针称为probe sets。
由于探针长度较短,为保证杂交的特异性,affy公司为每个基因设计了两类探针,一类探针的序列与基因完全匹配,称为perfect match(PM)probes,另一类为不匹配的探针,称为mismatch (MM)probes。
PM和MM探针序列除第13个碱基外完全一样,在MM中把PM的第13个碱基换成了互补碱基。
PM和MM探针成对出现。
我们先使用前一节的方法载入数据并修改芯片名称:用pm和mm函数可查看每个探针的检测情况:上面显示的列名称就是探针的名称。
而基因名称用probeset名称表示:名称映射时会看到。
实验6基因芯片数据处理分析与GO分析实验背景:基因芯片技术是通过检测靶基因在不同样本中的表达量差异,并分析其生物信息学特性,来揭示基因调控网络与疾病发生发展的过程的一种高通量技术。
基因芯片数据处理和分析是基因芯片研究的关键步骤之一、通过对基因芯片数据进行预处理、差异分析、聚类分析等,可以获得与研究目标相关的基因列表,并进一步进行GO(Gene Ontology)的功能富集分析,揭示差异表达基因的功能特性。
实验目的:通过基因芯片数据处理分析和GO功能富集分析,获得与研究目标相关的差异表达基因,并揭示其在生物学功能、分子过程和细胞组分方面的富集情况,为后续的生物学实验和机制研究提供理论依据。
实验步骤:1.基因芯片数据的预处理:包括数据导入、数据清洗、标准化和基因注释等。
首先,将基因芯片数据导入到数据分析软件中,然后针对数据质量进行清洗,剔除异常值和低质量的基因。
接下来,对基因表达谱数据进行归一化处理,保证不同芯片之间的数据可比性。
最后,对基因进行注释,将基因名与其对应的功能注释进行关联。
2.差异分析:通过比较不同组别之间的基因表达差异,筛选出差异表达基因。
差异分析方法包括t检验、方差分析等。
根据统计学中的显著性水平,设定p值的阈值,将差异表达基因筛选出来。
3.聚类分析:将差异表达基因按照其表达谱进行聚类分析,可将具有相似表达模式的基因聚集在一起。
常用的聚类方法包括层次聚类和K均值聚类等。
实验结果与分析:通过基因芯片数据处理和分析,我们得到了与研究目标相关的差异表达基因。
结合GO分析的结果,我们可以进一步了解这些差异表达基因在生物学功能、分子过程和细胞组分方面的富集情况。
例如,在生物学过程方面,我们可以得知这些基因是否与细胞增殖、凋亡、信号传导等生物学过程相关;在分子功能方面,我们可以了解这些基因是否具有催化活性、结合能力等分子功能特性;在细胞组分方面,我们可以了解这些基因在细胞核、细胞质、细胞膜等细胞组分的分布情况。
生物信息学中的基因芯片分析方法研究一、概述近年来,随着生物学研究的深入,生物信息学作为一个新兴的交叉学科蓬勃发展。
基因芯片作为其中一个主要的成果,一直被广泛应用于生物分子的大规模检测中。
基因芯片能够同时检测几千种甚至上万种基因表达,是高通量生物实验的重要手段。
同时,对于寻找基因与疾病、生理过程的关系,或筛选药物靶点等方面也有重要价值。
基因芯片分析方法是生物信息学中的一个重要内容。
本文将就该研究领域,对常用的基因芯片分析方法进行详细探讨。
二、基因芯片分析中的基本流程基因芯片分析需要依靠一些特定的生物信息学软件和数据库,其基本的分析流程如下:1. 数据预处理芯片数据预处理分为参数和无参数两个部分。
其中,参数方法的处理包括:背景校正、归一化、过滤、标准化等;而无参数方法的处理步骤一般包括去除基因的技术重复,样本的重复,检验异常点等。
2. 差异分析常见的差异分析方法包括:T检验、方差分析、Wilcoxon秩和检验和Kruskal-Wallis H检验等方法。
通过差异分析进一步筛选候选的基因,并对其进行进一步分析与研究。
3. 生物信息学分析生物信息学分析主要包括:生物信息学数据库(如GO、KEGG、DAVID等)分析,寻找差异比较显著的生物通路等。
4. 数据可视化通过图表等方式将生物数据可视化处理,帮助更好地理解数据的分析结果。
三、基因芯片分析方法在基因芯片数据分析过程中,会使用到很多不同的算法分析方法。
下列方法仅代表了其中的一部分。
1. T检验T检验是基因芯片分析中常用的统计分析方法之一。
通过T检验,可以得出检测样本的平均值之间是否存在显著性差异。
2. ANOVA方差分析(ANOVA)是基因芯片分析中常用的数据分析方法。
通过方差分析,可以得出样本之间的差异是否显著,并确定哪些基因是具有显著差异的。
3. PCA主成分分析(PCA)是一种多元统计学方法。
可以通过寻找样本间变化的主要方向,将高维数据降维,从而更好地比较不同样本之间的差异。
基因芯片数据处理流程与分析介绍
关键词:基因芯片数据处理
当人类基因体定序计划的重要里程碑完成之后,生命科学正式迈入了一个后基因体时代,基因芯片(microarray) 的出现让研究人员得以宏观的视野来探讨分子机转。
不过分析是相当复杂的学问,正因为基因芯片成千上万的信息使得分析数据量庞大,更需要应用到生物统计与生物信息相关软件的协助。
要取得一完整的数据结果,除了前端的实验设计与操作的无暇外,如何以精确的分析取得可信数据,运筹帷幄于方寸之间,更是画龙点睛的关键。
基因芯片的应用
基因芯片可以同时针对生物体内数以千计的基因进行表现量分析,对于科学研究者而言,不论是细胞的生命周期、生化调控路径、蛋白质交互作用关系等等研究,或是药物研发中对于药物作用目标基因的筛选,到临床的疾病诊断预测,都为基因芯片可以发挥功用的范畴。
基因表现图谱抓取了时间点当下所有的动态基因表现情形,将所有的探针所代表的基因与荧光强度转换成基本数据(raw data) 后,仿如尚未解密前的达文西密码,隐藏的奥秘由丝丝的线索串联绵延,有待专家抽丝剥茧,如剥洋葱般从外而内层层解析出数千数万数据下的隐晦含义。
要获得有意义的分析结果,恐怕不能如泼墨画般洒脱随兴所致。
从raw data 取得后,需要一连贯的分析流程(图一),经过许多统计方法,才能条清理明的将raw data 整理出一初步的分析数据,当处理到取得实验组除以对照组的对数值后(log2 ratio),大约完成初步的统计工作,可进展到下一步的进阶分析阶段。
图一、整体分析流程。
基本上raw data 取得后,将经过从最上到下的一连串分析流程。
(1) Rosetta 软件会透过统计的model,给予不同的权重来评估数据的可信度,譬如一些实验操作的误差或是样品制备与处理上的瑕疵等,可已经过Rosetta error model 的修正而提高数据的可信值;(2) 移除重复出现的探针数据;(3) 移除flagged 数据,并以中位数对荧光强度的数据进行标准化(Normalized) 的校正;(4) Pearson correlation coefficient (得到R 值) 目的在比较技术性重复下的相似性,R 值越高表示两芯片结果越近似。
当R 值超过0.975,我们才将此次的实验结果视为可信,才继续后面的分析流程;(5) 将技术性重复芯片间的数据进行平均,取得一平均之后的数据;(6) 将实验组除以对照组的荧光表现强度差异数据,取对数值(log2 ratio) 进行计算。
找寻差异表现基因
实验组与对照组比较后的数据,最重要的就是要找出显著的差异表现基因,因为这些正是条件改变后而受到调控的目标基因,透过差异表现基因的加以分析,背后所隐藏的生物意义才能如拨云见日般的被发掘出来。
一般根据以下两种条件来筛选出差异表现基因:(i) 荧光表现强度差异达2 倍变化(fold change 增加2 倍或减少2倍) 的基因。
而我们通常会取对数(log2) 来做fold change 数值的转换,所以看的是log2 ≧1 或≦-1 的差异表现基因;(ii) 显著值低于0.05 (p 值< 0.05) 的基因。
当这两种条件都符合的情况下所交集出来的基因群,才是显著性高且稳定的差异表现基因。
进阶分析案例
以目前华联生技的最新服务报告里,将主动提供下列几种进阶分析服务于报告中供您使用参考。
首先,为确认control 组与treatment 组各自芯片实验间的质量一致性,先以主成分分析(Principle Component Analysis, PCA) 将芯片数万点的信息简化成几个低维度的分析数据,以归纳出彼此的群落分布,藉以比对各自的近似关系。
从结果可以看到control 组与treatment 组经过主成分分析后,显示出两组各自间的结果是相近似的(图二),代表这次实验的设计与芯片结果是可信的,值得往下做进阶分析。
图二、主成分分析control 组与treatment 组间的芯片结果。
用主成分1 (Comp. 1) 和2 (Comp. 2) 便可以将两组间的数据归纳出显著的各自群落。
代表两组各自的结果相近似。
接着以Hierarchical Clustering (丛聚法) 搭配Pearson correlation 找出各基因彼此间的
近似关系。
如此将control 组与treatment 组的差异表现基因做分群,划分出treatment 组经过处理后,对照control 组而呈现下调(Down-regulated) 或者上调(Up-regulated) 基因群(图三)。
图三、丛聚法分析将差异表现基因做分群。
以treatment 组(T-1、T-2、T-3、T-4) 对应control 组(C-1、C-2、C-3、C-4) 后的分析下,基因表现呈现下调(Down-regulated) 与上调(Up-regulated) 的分类结果。
进阶分析服务方面,提供Gene Ontology (GO, 基因功能分类) 和Pathways analysis (讯息传递路径分析) 的进阶分析。
于GO 的分析,在于将差异表现基因群做功能上的分类,可依功能分类推敲出所处的情况在何种状态,譬如:细胞增生、受损、凋亡或发炎等等。
而讯息传递路径分析则从基因上下游的牵连性来探讨受调控后的影响关系。
使用的是Gene Set Enrichment Analysis (GSEA) 工具,将差异表现基因导入后,再选择所需要的分析服务,可获取所需的相关信息(图四)。
图四、GSEA 提供的进阶分析服务。
c2 - 为pathway analysis 的分析数据库,c5 - 为GO 分析数据库。
挑选出差异表现基因后,透过GSEA 分析工具,可依需求选择所要的进阶分析。
讯息传递路径的进阶分析,帮助研究者探讨调控基因间的上下游关系,除可厘清其脉络以了解完整的影响关系;此外,借着交互间的讯息传递网络,像剥洋葱般从外而内的解开网络关联路径,才有机会往内更深入找出最重要的上游调控基因,找到这些最关键的基因,才有机会发现药物影响或受外在环境刺激下影响主要的目标基因。
借着目标基因的找寻,有助于新药的开发或者新生物标记基因(biomarker) 的找寻。
所提供的服务报告里,会提供最显着的几个讯息传递路径及所有参与其中的差异表现基因,以Excel 文件将相关信息做整合,让客户能简单明了的撷取所需信息加以应用。
此外也可以从GSEA 所分析的结果,利用其他的图表数据库,如:KEGG (图五)、BioCarta、Signaling gateway、GenMAPP (请见参考文献) 等等,画出图像化的链接图表。
图五、讯息传递路径分析。
利用GSEA 的分析,可利用KEGG 数据库,制作出讯息传递路径相连关系的图表。
而GO 的进阶分析,在于从功能的分门别类里找出整体趋势的走向,如:细胞面临压力的刺激下,一些相关的功能群组会被调控以因应环境的变化,抵抗压力的迫害;当压力过大,细胞调适不过来,细胞即启动”我投降,不玩了!” 的自动凋亡机制(apoptosis),此时可发现apoptosis 相关的功能群组特别显著;若压力的程度再大一些,大到如土石流般无力招架,则细胞可能就因而坏死(necrosis),导致细胞碎裂,于是细胞内的物质外露,如细胞介素(cytokine) 等等,造成其他邻近细胞受到影响,便引起发炎反应,于是从GO 类别可以看到细胞坏死或发炎相关的功能群组被大量调控显著增加。
提供的报告里会列出最显著的几个GO 分类以及有影响作用的基因,并提供链接,将以上信息整合到Excel 文件,让研究者可以进一步探索里面的信息(图六)。
图六、GO 功能分类列表。
提供显著功能列表及其信息,并提供链接到其他数据库作更多
探索搜寻。
除了上述的两种进阶分析在服务报告会主动提供。
我们还提供其他的进阶分析方法,依研究者的兴趣与需求自行选择。
由于基因的功能最多是由蛋白质来完成,因此探讨蛋白质的生理功能即是一门重要的课题。
从一开始的酵母菌双杂交系统(Yeast two hybrid system)、荧光共振能量转移(Fluorescence resonance energy transfer, FRET)、以及共同免疫沉淀法
(co-immunoprecipitation assay, Co-IP),就是探讨蛋白质-蛋白质或蛋白质-DNA 交互作用关系的研究策略。
现在透过microarray 与数据库(如IncAct, 见文献参考) 的发展,便可以利用数据库来探讨蛋白质间之交互作用关连性(protein-protein interaction, PPI),并进一步整合出其联络网(PPI networks),可从蛋白质的角度探讨出有别于基因表达层面的生物意义(图七)。
图七、PPI 的作用网络关系,以图示呈现彼此间的关联与亲缘远近关系。
可找出影响的最上层的目标蛋白质,可回溯出对应的基因。
结论
华联还提供研究者更多的服务的内容,期望能以高质量的服务规格满足您各式各样的需求与标准。
此外,华联的网站设计也做了更新,以更贴切用户使用上的便利。
此外也不定期发布有关技术开发与产品发表的讯息,通过网站就就可以知晓,期能更有效的辅助研究。
参考文献:
1.KEGG: http://www.genome.jp/kegg/
2.BioCarta:
3.Signaling gateway: /
4.GenMAPP: /
5.IntAct: /intact/。