实验6 基因芯片数据处理分析与GO分析
- 格式:pdf
- 大小:2.25 MB
- 文档页数:21
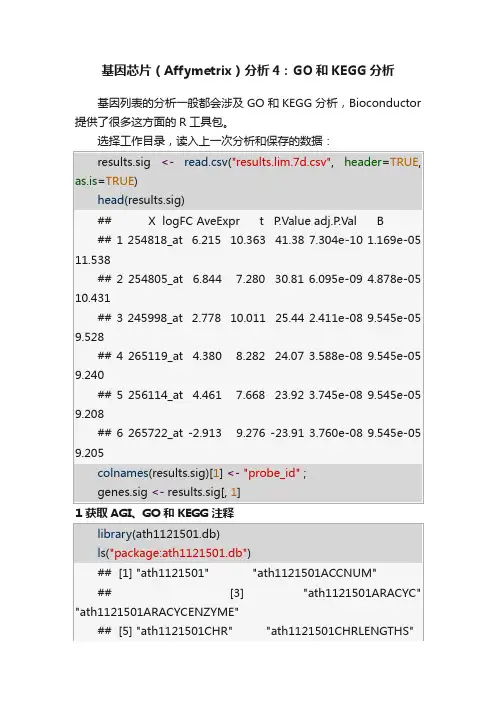
基因芯片(Affymetrix)分析4:GO和KEGG分析基因列表的分析一般都会涉及GO和KEGG分析,Bioconductor 提供了很多这方面的R工具包。
选择工作目录,读入上一次分析和保存的数据:1 获取AGI、GO和KEGG注释ath1121501GO为拟南芥基因的GO数据库,ath1121501PATH 为KEGG pathway数据库。
但不是每一个基因(probeset)都有GO 或KEGG注释,哪些基因有注释可以用mappedkeys函数获得:有PATH注释的probesets只有3018个,而有GO注释的有2万多个。
通过ath1121501XXXX获得的数据是AnnotationDbi软件包定义的ProbeAnnDbBimap类型数据,它们可以用as.list转成列表形式。
列表内每一个基因的注释内容也是列表形式:转换成列表类型的ProbeAnnDbBimap数据仍然是列表,但PATH和ACCNUM数据是二级列表(列表下只有一级列表),而GO 数据是三级列表(列表下还有两级的列表)。
所以得先编写get.GO函数,它把as.list产生的GO三级列表转成二级结构,和AGI和KEGG 的列表类似,方便后面的统一处理:使用这个函数和下列代码就可以获得AGI、GO和KEGG注释:上面代码有两点要注意:•switch()函数使用。
switch()是非常神奇的条件转向开关函数,它的参数(列表)可以是各种类型,变量、表达式、函数等都可以使用。
•列表到数据框类型数据的转换,我们使用了plyr软件包的llply 和ldply函数。
plyr是很著名的软件包,用于数据糅合。
这不属于本节的讨论范围,先不介绍,请自行学习使用。
由于探针id是唯一的,上面的代码用它作为关键字糅合数据。
得到的结果是数据框:这样每一个探针都得到了对应的AGI、GO和KEGG途径注释(如果有)。
其他类型数据如Pubmed ID可以使用类似方法获得,但编程之前得先了解它们的数据结构,最直接的方法就是使用head,summary和str等函数查看。

基因表达谱芯片的数据分析基因芯片数据分析就是对从基因芯片高密度杂交点阵图中提取的杂交点荧光强度信号进行的定量分析,通过有效数据的筛选和相关基因表达谱的聚类,最终整合杂交点的生物学信息,发现基因的表达谱与功能可能存在的联系。
然而每次实验都产生海量数据,如何解读芯片上成千上万个基因点的杂交信息,将无机的信息数据与有机的生命活动联系起来,阐释生命特征和规律以及基因的功能,是生物信息学研究的重要课题[1]。
基因芯片的数据分析方法从机器学习的角度可分为监督分析和非监督分析,假如分类还没有形成,非监督分析和聚类方法是恰当的分析方法;假如分类已经存在,则监督分析和判别方法就比非监督分析和聚类方法更有效率。
根据研究目的的不同[2,3],我们对基因芯片数据分析方法分类如下。
(1)差异基因表达分析:基因芯片可用于监测基因在不同组织样品中的表达差异,例如在正常细胞和肿瘤细胞中;(2)聚类分析:分析基因或样本之间的相互关系,使用的统计方法主要是聚类分析;(3)判别分析:以某些在不同样品中表达差异显著的基因作为模版,通过判别分析就可建立有效的疾病诊断方法。
1 差异基因表达分析(difference expression, DE)对于使用参照实验设计进行的重复实验,可以对2样本的基因表达数据进行差异基因表达分析,具体方法包括倍数分析、t检验、方差分析等。
1.1倍数变化(fold change, FC)倍数分析是最早应用于基因芯片数据分析的方法[4],该方法是通过对基因芯片的ratio值从大到小排序,ratio 是cy3/cy5的比值,又称R/G值。
一般0.5-2.0范围内的基因不存在显著表达差异,该范围之外则认为基因的表达出现显著改变。
由于实验条件的不同,此阈值范围会根据可信区间应有所调整[5,6]。
处理后得到的信息再根据不同要求以各种形式输出,如柱形图、饼形图、点图等。
该方法的优点是需要的芯片少,节约研究成本;缺点是结论过于简单,很难发现更高层次功能的线索;除了有非常显著的倍数变化的基因外,其它变化小的基因的可靠性就值得怀疑了;这种方法对于预实验或实验初筛是可行的[7]。

生物信息学讲义——基因芯片数据分析生物信息学是指运用计算机技术和统计学方法来解析和理解生物领域的大规模生物数据的学科。
基因芯片数据分析是生物信息学研究的一个重要方向,通过对基因芯片数据进行分析,可以揭示基因在生物过程中的功能和调节机制。
本讲义将介绍基因芯片数据的分析方法和应用。
一、基因芯片数据的获取与处理基因芯片是一种用于检测和测量基因表达水平的高通量技术,可以同时检测上千个基因的表达情况。
获取基因芯片数据的第一步是进行基因芯片实验,如DNA芯片实验或RNA芯片实验。
实验得到的数据一般为原始强度值或信号强度值。
接下来,需要对这些原始数据进行预处理,包括背景校正、归一化和过滤噪声等步骤,以消除实验误差和提高数据质量。
二、基因表达分析基因芯片数据的最主要应用之一是进行基因表达分析。
基因表达分析可以揭示在不同条件下基因的表达模式和差异表达基因。
常用的基因表达分析方法包括差异表达分析、聚类分析和差异共表达网络分析等。
差异表达分析常用来寻找在不同条件下表达差异显著的基因,如差异表达基因的筛选和注释;聚类分析可以将表达模式相似的基因分为一组,如聚类分析可以将不同样本中的基因按照表达模式进行分类;差异共表达网络分析可以找到一组在差异表达样本中共同表达的基因,揭示潜在的功能模块。
三、功能富集分析对差异表达基因进行功能富集分析可以帮助我们理解这些基因的生物学功能和参与的生物过程。
功能富集分析可以通过对差异表达基因进行GO(Gene Ontology)注释,找到在特定条件下富集的生物学过程、分子功能和细胞组分等。
另外,功能富集分析还可以进行KEGG(Kyoto Encyclopedia of Genes and Genomes)富集分析,找到差异表达基因在代谢通路和信号传导通路中的富集情况。
四、基因调控网络分析基因调控网络分析可以帮助我们揭示基因间的调控关系和寻找关键调控基因。
基因调控网络是基于差异表达数据构建的,它可以包括转录因子-靶基因调控网络和miRNA-mRNA调控网络等。

免疫学中基因芯片的应用及数据分析方法基因芯片是一种新型的生物技术工具,它被广泛运用于生物学研究、医学诊断以及农业等领域。
在免疫学研究中,基因芯片可以用来分析基因表达,研究免疫系统的生物学和病理生理学,以及开发新的免疫疗法。
本文将探讨免疫学中基因芯片的应用及数据分析方法。
一、基因芯片在免疫学研究中的应用基因芯片技术基于DNA序列互补的原理,可以同时探测几千个基因在不同生理和病理条件下的表达水平。
在免疫学研究中,基因芯片技术可以用来研究免疫系统中与疾病相关的基因表达变化,为免疫治疗的开发提供重要的信息。
1. 免疫系统基因表达谱的分析免疫系统是一种复杂的网络,包括免疫细胞、激素和细胞因子等多种成分。
在不同生理和病理条件下,免疫系统中的基因表达模式会发生变化,这些变化与多种疾病的发生和发展密切相关。
利用基因芯片技术可以对免疫系统中的基因表达谱进行全面的分析,从而发现与免疫系统相关的新的治疗靶点。
2. 免疫治疗的监测免疫治疗是一种新兴的治疗模式,包括肿瘤免疫治疗、自身免疫病治疗以及感染病治疗等。
基因芯片技术可以用来监测免疫治疗的效果,并评估治疗的预后。
例如,利用基因芯片技术可以分析免疫治疗后T细胞的基因表达谱,从而预测治疗是否成功。
3. 病原体识别和分析免疫系统的主要功能是识别和清除病原体,基因芯片技术可以用来识别和分析各种病原体的基因表达模式,从而发现新的病原体治疗靶点,为针对性治疗提供依据。
二、基因芯片数据分析方法基因芯片技术可以同时测量成千上万个基因的表达水平,产生的数据量很大,数据分析也是一个复杂的过程。
一般情况下,基因芯片数据分析包括数据预处理、差异基因筛选、聚类分析、生物学意义的解释等几个步骤。
1. 数据预处理数据预处理指的是原始的基因芯片数据清洗与归一化的过程,这是数据分析的关键步骤。
数据预处理的目的是剔除芯片噪声、基准样本处理、将不同芯片数据进行标准化处理,提高数据质量和可靠性,为后续分析打下基础。

基因芯片检测原理及简要过程1.样本准备:首先需要从目标生物体中获得样本,可以是DNA、RNA或蛋白质。
样本处理的方式根据研究目的不同而不同,可能需要提取DNA或RNA,并对其进行纯化和扩增。
2.样本标记:为了将样本引入芯片中进行检测,样本需要与荧光标记物结合。
在样本处理过程中,可以使用反应物来标记样本中的基因或序列。
标记物的选择基于实验设计和研究目的。
3.杂交:标记的样本与芯片上的核酸探针进行杂交反应。
核酸探针是单链DNA分子,具有与目标样本中的DNA互补的序列。
这种杂交反应是通过将样本和核酸探针同时加入一个反应混合物中,使它们相互结合。
4.洗涤:经过杂交反应后,需要对芯片进行洗涤以去除未结合的标记物和杂交物。
这个过程是为了减少背景信号,提高检测的特异性和灵敏度。
5.扫描:在洗涤后,芯片被放入一台专门的扫描仪中,这个扫描仪使用激光或LED光源来激发标记物的荧光信号。
随后,该信号被检测并记录下来。
6.数据分析:通过扫描仪获得的数据可以用来分析芯片上的每个探针的荧光强度。
根据荧光强度的变化,可以推断出样本中的基因表达和变异情况。
通常使用的数据分析方法包括基因差异分析、聚类分析、富集分析和通路分析等。
总结起来,基因芯片检测是一种高通量的基因分析技术,可以同时检测数以千计的基因或序列,用于揭示基因表达和变异的情况。
其基本原理是通过将样本与芯片上的核酸探针进行杂交,再通过标记物的荧光信号检测和数据分析,得出样本中的基因信息。
这项技术已经广泛应用于基因组学、遗传学、癌症研究等领域,促进了对基因功能和疾病机制的理解。

基因芯片数据处理流程与分析介绍关键词:基因芯片数据处理当人类基因体定序计划的重要里程碑完成之后,生命科学正式迈入了一个后基因体时代,基因芯片(microarray)的出现让研究人员得以宏观的视野来探讨分子机转。
不过分析是相当复杂的学问,正因为基因芯片成千上万的信息使得分析数据量庞大,更需要应用到生物统计与生物信息相关软件的协助。
要取得一完整的数据结果,除了前端的实验设计与操作的无暇外,如何以精确的分析取得可信数据,运筹帷幄于方寸之间,更是画龙点睛的关键。
基因芯片的应用基因芯片可以同时针对生物体内数以千计的基因进行表现量分析,对于科学研究者而言,不论是细胞的生命周期、生化调控路径、蛋白质交互作用关系等等研究,或是药物研发中对于药物作用目标基因的筛选,到临床的疾病诊断预测,都为基因芯片可以发挥功用的范畴。
基因表现图谱抓取了时间点当下所有的动态基因表现情形,将所有的探针所代表的基因与荧光强度转换成基本数据(raw data)后,仿如尚未解密前的达文西密码,隐藏的奥秘由丝丝的线索串联绵延,有待专家抽丝剥茧,如剥洋葱般从外而内层层解析出数千数万数据下的隐晦含义。
要获得有意义的分析结果,恐怕不能如泼墨画般洒脱随兴所致。
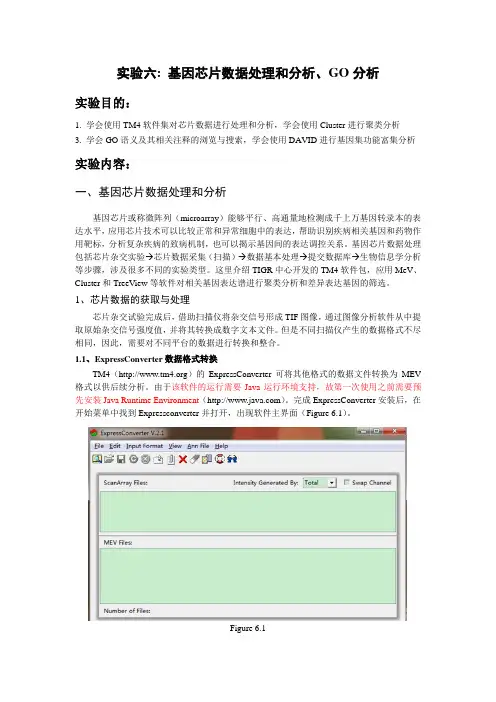
从raw data取得后,需要一连贯的分析流程(图一),经过许多统计方法,才能条清理明的将raw data整理出一初步的分析数据,当处理到取得实验组除以对照组的对数值后(Iog2 ratio),大约完成初步的统计工作,可进展到下一步的进阶分析阶段。
Rosetta profile error model calculation2Sqweeze replicated probes^Normalize intensities (exclude flagged ^nd wontroldata) with median scaling"Basic statistic plot and Pearson correlationcoefficient^Combine tech nicar repeatPairwise ratid calculation图一、整体分析流程。


GO 分析Gene Ontology可分为分子功能(Molecular Function),生物过程(biologicalprocess)和细胞组成(cellularcomponent)三个部分。
蛋白质或者基因可以通过ID对应或者序列注释的方法找到与之对应的GO号,而GO号可对于到Term,即功能类别或者细胞定位。
功能富集分析: 功能富集需要有一个参考数据集,通过该项分析可以找出在统计上显著富集的GOTerm。
该功能或者定位有可能与研究的目前有关。
GO功能分类是在某一功能层次上统计蛋白或者基因的数目或组成,往往是在GO的第二层次。
此外也有研究都挑选一些Term,而后统计直接对应到该Term的基因或蛋白数。
结果一般以柱状图或者饼图表示。
1.GO分析根据挑选出的差异基因,计算这些差异基因同GO 分类中某(几)个特定的分支的超几何分布关系,GO 分析会对每个有差异基因存在的GO 返回一个p-value,小的p 值表示差异基因在该GO 中出现了富集。
GO分析对实验结果有提示的作用,通过差异基因的GO分析,可以找到富集差异基因的GO分类条目,寻找不同样品的差异基因可能和哪些基因功能的改变有关。
2.Pathway分析根据挑选出的差异基因,计算这些差异基因同Pathway 的超几何分布关系,Pathway 分析会对每个有差异基因存在的pathway返回一个p-value,小的p 值表示差异基因在该pathway 中出现了富集。
Pathway分析对实验结果有提示的作用,通过差异基因的Pathway 分析,可以找到富集差异基因的Pathway条目,寻找不同样品的差异基因可能和哪些细胞通路的改变有关。
与GO 分析不同,pathway分析的结果更显得间接,这是因为,pathway 是蛋白质之间的相互作用,pathway 的变化可以由参与这条pathway 途径的蛋白的表达量或者蛋白的活性改变而引起。


生物信息学在基因芯片数据功能分析中的应用2009-4-29随着人类基因组计划(Human Genome Project)即全部核苷酸测序的即将完成,人类基因组研究的重心逐渐进入后基因组时代(PostgenomeEra),向基因的功能及基因的多样性倾斜。
通过对个体在不同生长发育阶段或不同生理状态下大量基因表达的平行分析,研究相应基因在生物体内的功能,阐明不同层次多基因协同作用的机理,进而在人类重大疾病如癌症、心血管疾病的发病机理、诊断治疗、药物开发等方面的研究发挥巨大的作用。
它将大大推动人类结构基因组及功能基因组的各项基因组研究计划。
生物信息学在基因组学中发挥着重大的作用,而另一项崭新的技术——基因芯片已经成为大规模探索和提取生物分子信息的强有力手段,将在后基因组研究中发挥突出的作用。
基因芯片与生物信息学是相辅相成的,基因芯片技术本身是为了解决如何快速获得庞大遗传信息而发展起来的,可以为生物信息学研究提供必需的数据库,同时基因芯片的数据分析也极大地依赖于生物信息学,因此两者的结合给分子生物学研究提供了一条快捷通道。
本文介绍了几种常用的基因功能分析方法和工具:一、GO基因本体论分类法最先出现的芯片数据基因功能分析法是GO分类法。
Gene Ontology(GO,即基因本体论)数据库是一个较大的公开的生物分类学网络资源的一部分,它包含38675个Entrez Gene注释基因中的17348个,并把它们的功能分为三类:分子功能,生物学过程和细胞组分。
在每一个分类中,都提供一个描述功能信息的分级结构。
这样,GO中每一个分类术语都以一种被称为定向非循环图表(DAGs)的结构组织起来。
研究者可以通过GO分类号和各种GO数据库相关分析工具将分类与具体基因联系起来,从而对这个基因的功能进行描述。
在芯片的数据分析中,研究者可以找出哪些变化基因属于一个共同的GO功能分支,并用统计学方法检定结果是否具有统计学意义,从而得出变化基因主要参与了哪些生物功能。
实验6基因芯片数据处理分析与GO分析实验背景:基因芯片技术是通过检测靶基因在不同样本中的表达量差异,并分析其生物信息学特性,来揭示基因调控网络与疾病发生发展的过程的一种高通量技术。
基因芯片数据处理和分析是基因芯片研究的关键步骤之一、通过对基因芯片数据进行预处理、差异分析、聚类分析等,可以获得与研究目标相关的基因列表,并进一步进行GO(Gene Ontology)的功能富集分析,揭示差异表达基因的功能特性。
实验目的:通过基因芯片数据处理分析和GO功能富集分析,获得与研究目标相关的差异表达基因,并揭示其在生物学功能、分子过程和细胞组分方面的富集情况,为后续的生物学实验和机制研究提供理论依据。
实验步骤:1.基因芯片数据的预处理:包括数据导入、数据清洗、标准化和基因注释等。
首先,将基因芯片数据导入到数据分析软件中,然后针对数据质量进行清洗,剔除异常值和低质量的基因。
接下来,对基因表达谱数据进行归一化处理,保证不同芯片之间的数据可比性。
最后,对基因进行注释,将基因名与其对应的功能注释进行关联。
2.差异分析:通过比较不同组别之间的基因表达差异,筛选出差异表达基因。
差异分析方法包括t检验、方差分析等。
根据统计学中的显著性水平,设定p值的阈值,将差异表达基因筛选出来。
3.聚类分析:将差异表达基因按照其表达谱进行聚类分析,可将具有相似表达模式的基因聚集在一起。
常用的聚类方法包括层次聚类和K均值聚类等。
实验结果与分析:通过基因芯片数据处理和分析,我们得到了与研究目标相关的差异表达基因。
结合GO分析的结果,我们可以进一步了解这些差异表达基因在生物学功能、分子过程和细胞组分方面的富集情况。
例如,在生物学过程方面,我们可以得知这些基因是否与细胞增殖、凋亡、信号传导等生物学过程相关;在分子功能方面,我们可以了解这些基因是否具有催化活性、结合能力等分子功能特性;在细胞组分方面,我们可以了解这些基因在细胞核、细胞质、细胞膜等细胞组分的分布情况。
基因芯片数据分析技术与应用研究随着生物技术的发展和进步,基因芯片技术已成为现代生物学研究中不可或缺的工具。
基因芯片通过大规模并行的方式,可以快速、准确地分析数万至数百万个基因在不同条件下的表达水平,从而帮助研究人员深入了解生物基因调控和功能。
本文将探讨基因芯片数据分析技术的原理、方法和应用领域,并对其研究前景进行展望。
基因芯片数据分析技术的原理主要基于DNA杂交和荧光标记。
首先,将待测DNA样本通过逆转录反应转录为cDNA,并使用荧光标记技术标记。
然后,将cDNA与基因芯片上的探针进行杂交反应,荧光信号的强度反映了相应基因的表达水平。
最后,使用激光和探测器对芯片上的荧光信号进行扫描和检测,得到基因表达谱。
基因芯片数据分析技术的方法包括预处理、差异基因分析、功能注释和生物网络分析。
首先,在预处理阶段,需要对从芯片扫描得到的原始数据进行噪声去除、背景校正和数据正规化等处理,以获得准确可靠的实验数据。
接下来,通过比较不同样本之间的基因表达差异,可以筛选出具有显著差异表达的基因,帮助研究人员了解不同样本之间的生物学差异和变化。
然后,可以进行功能注释,将差异表达的基因与已知的基因注释数据库进行比较,探索其潜在的功能和调控机制。
最后,将差异基因与生物网络进行关联分析,揭示基因之间的相互作用和功能调控网络,深入理解生物系统的复杂性。
基因芯片数据分析技术在许多领域都有广泛的应用。
首先,基因表达谱的分析可帮助研究人员研究与疾病相关的基因和通路,为疾病的预防和治疗提供新的靶点和策略。
例如,在癌症研究中,基因芯片数据分析已经帮助揭示了肿瘤发生发展的分子机制,并为个体化治疗提供了有力支持。
其次,基因芯片技术也在农业和农村发展中发挥重要作用。
通过分析作物基因表达谱,可以研究作物与环境的适应性和抗性,以提高作物产量和品质,促进农业可持续发展。
此外,基因芯片数据分析还在药物研发、生物工程和环境科学等领域发挥着重要作用。
随着生物信息学的发展,基因芯片数据分析技术也在不断发展和改进。
基因芯片小知识(二)数据分析发送生信到本公众号(freescience联盟)后台,查看系列相关文章~提取生物样品的mRNA并反转录成cDNA,同时用荧光素或同位素标记。
在液相中与基因芯片上的探针杂交,经洗膜后用图像扫描仪捕获芯片上的荧光或同位素信号,由此获得的图像就是基因芯片的原始数据(raw data),也叫探针水平数据。
获取探针水平的数据是芯片数据处理的第一步,然后需要对其进行预处理(pre-processing),以获得基因表达数据(gene expression data)。
基因表达数据通常用矩阵形式表示,称为基因表达矩阵。
基因表达矩阵的每一行代表一个基因的表达量,一列代表一个样本的所有基因的表达情况。
一背景(background)处理背景处理即过滤芯片杂交信号中属于非特异性的背景噪音部分。
一般以图像处理软件对芯片划格后,每个杂交点周围区域各像素吸光度的平均值作为背景。
但此法存在芯片不同区域背景扣减不均匀的缺点,同时会使1%~5%的点产生无意义的负值。
也可利用芯片最低信号强度的点(代表非特异性的样本与探针结合值)或综合整个芯片非杂交点背景所得的平均值做为背景。
Brown等提出利用整个芯片杂交点外的平均吸光度值作为背景的best-fit方法,使该问题得到较好的解决,并有效地提高了处理数据的质量。
背景处理之后,我们可以将芯片数据以矩阵的格式输出。
二数据筛选经过背景校正后的芯片数据中可能会产生负值,显然负值是没有生物学意义的。
数据集中还可能包括一些单个异常大(或小)的峰(谷)信号,它们被认为是随机噪声。
另外,对于负值和噪声信号,通常的处理方法就是将其去除。
然而,数据的缺失(除了上述原因会造成数据缺失以外,扫描的过程中也可能会产生缺失)对后续的统计分析(尤其是层式聚类和主成分分析)有致命的影响,所以在进行分析前需要数据筛选。
数据筛选的步骤是先筛选点样,然后是数据标准化、截断异常值,最后筛选基因。
基因芯片及其数据分析基因芯片(gene chip)是一种高通量的基因表达分析工具,也被称为基因表达芯片或基因表达板。
它可以同时检测和分析数以万计的基因,以了解基因在细胞或组织中的表达情况。
基因芯片的制备过程包括两个主要步骤:生物实验和芯片制造。
首先,采集感兴趣的生物样本,例如人体组织或细胞。
然后,从这些样本中提取RNA或DNA,将其转录为互补DNA(cDNA),并进行标记。
接着,将这些标记的cDNA片段加入芯片上的特定位置,称为探针。
这些探针是经过设计和合成的特定序列,可以与目标基因或RNA分子特异性结合。
在数据分析方面,基因芯片的分析流程包括数据预处理、差异分析和功能注释等步骤。
数据预处理主要是对原始芯片数据进行质量控制、标准化和归一化等处理,以消除技术偏差和样本间的差异。
差异分析是通过比较不同处理组的表达谱,找到差异表达的基因或通路,从而揭示不同条件下基因表达的变化。
功能注释是将识别出的差异基因进行生物学功能描述,包括基因本体论(Gene Ontology)、通路富集分析等,从而理解这些基因的生物学意义和参与的生物过程。
基因芯片的应用非常广泛。
在生物医学研究中,它常被用于筛选差异表达的基因,发现与特定疾病相关的生物标志物,探寻病理生理过程中的致病机制等。
例如,通过对癌症患者和正常人组织样本的基因芯片分析,可以发现不同癌症类型的分子标记物,用于早期诊断和治疗监测。
此外,基因芯片还被广泛应用于农业、食品安全、环境监测等领域,用于研究植物生长发育、种子品质、环境胁迫等相关问题。
然而,基因芯片的数据分析也面临一些挑战。
首先,由于芯片技术的快速发展,数据量急剧增加。
如何高效地处理和存储这些庞大的数据成为一个问题。
其次,芯片技术本身存在一定的误差和噪音,如何准确地分析和解释数据结果也是一个难题。
此外,芯片分析常常需要结合其他实验验证结果,以确认差异表达基因的生物学意义。
总的来说,基因芯片及其数据分析是现代生物学和医学研究中的重要工具。
基因表达芯片数据的预处理和分析基因表达芯片是一种目前广泛应用于生物医学研究中的技术,它可以帮助研究人员在分子水平上对细胞、组织、器官及其疾病发生机制进行深入研究,从而为疾病的诊断、治疗和药物研发等领域提供有力的支持。
基因表达芯片所涉及的数据处理步骤较多,其中预处理和分析是其中最为基础和关键的两个环节。
本文将从这两个方面详细阐述基因表达芯片数据的预处理和分析。
一、基因表达芯片数据的预处理预处理部分主要包括质量控制、数据归一化和拼接等步骤。
具体介绍如下:1、质量控制质量控制是基因表达芯片数据预处理中非常重要的一步,它的目的是检查芯片实验结果的质量。
通过质量控制可以发现数据中的异常现象,包括低质量的样品、芯片实验中的坏控制等。
一旦发现问题,需要对其进行相应的策略处理,以确保测量结果的正确性和准确性。
2、数据归一化数据归一化是指将不同富集度的探测物本底进行标准化处理,以能够在同一芯片上比较不同样品的水平。
目前普遍使用的归一化方法有MAS5、RMA、GCRMA 和Ebtiseh等。
其中MAS5方法独立于信号内容以及噪声分布,不需要对数据做任何假设。
RMA方法适用于多共同贡献的基因表达的依赖性模型。
GCRMA方法基于模型的切断比值方法,可以有效消除芯片噪声的影响。
Ebtiseh方法可以充分利用芯片的信息,并通过最佳阈值确定最佳归一化方案。
3、拼接拼接是指将一组芯片测量数据进行合并,形成一个较大的数据矩阵。
拼接的目的是将不同个体、不同时间点的基因表达芯片测量结果进行统一处理,为后续的差异分析和数据挖掘提供支持。
二、基因表达芯片数据的分析基因表达芯片数据分析主要包括差异分析、功能分析和网络分析等步骤。
具体介绍如下:1、差异分析差异分析是指比较两组或多组样品之间的基因表达水平差异。
差异分析的主要方法有t检验、方差分析、多重比较法、基因表达芯片的类别分析以及机器学习算法。
通过差异分析可以找到与疾病有关的不同表达基因。