SAS学习系列10. 合并数据集
- 格式:docx
- 大小:288.32 KB
- 文档页数:11

SAS编程中SET命令的常用用法By 木杉2007/5/22 一、读入数据集:从现有的数据集读入数据(obs) ,下例中set将work.a的所有记录写入work.new ;其作用相当于复制数据集a:data new ;set a ;run;二、合并数据集:1、一个set的应用,纵向合并数据集:a) 2个数据集的字段完全相同的情况下:数据集a:数据集b:data new1 ;set a b ;by custid;run;运行结果:数据集new1b) 2个数据集的字段不完全相同的情况下:数据集a:数据集b:data new2 ;set a b ;by custid;run;运行结果:数据集new2c) 2个数据集的字段完全不同的情况下:数据集a:数据集b:data new3 ;set a b ;run;运行结果:数据集new32、两个set的应用:用2个set进行数据集的拼接时,新生产数据集(new)的记录条数为2个数据集的最小值;a) 当2个数据集的字段都不相同情况下:新生产的数据集包含2个set数据集的所有变量,第2个set数据集(b)的变量排在第1个数据集(a)的右边,如下例:数据集a:数据集b:data new;set a;set b;run;运行结果:数据集newb) 当2个数据集有相同字段(custid)情况下:第2个数据集(b)custid的值覆盖第1个数据集(a)custid的值,新生产数据集new2一共包含2条记录,如下例:数据集a:数据集b:data new2;set a;set b;run;运行结果:数据集new2三、Set命令的常用options :程序举例使用数据集:Data work.bbb;Input custid brand fee;Cards;1000123 1 3001000124 2 2001000134 3 5001000139 2 1001000213 3 200;Run;运行结果:Data c;Input custid brand fee ;Cards;1000126 1 9001000125 2 8001000127 1 2001000128 2 300;Run;运行结果:1、Keep的使用:仅把keep选定的变量写入新生成的数据集。

应用》在线开放课程《实用医学统计学与SAS遨游自由王国—SAS数据集创建与合并主要内容●SAS临时性数据集、永久性数据集●SAS数据集创建●SAS数据集合并SAS临时性数据集、永久性数据集●临时性数据集(Temporary dataset):文件放在资源管理器的work子目录下,SAS系统关闭,自动删除。
其作用是避免计算机资源消耗。
●永久性数据集(Permanent dataset):文件放在经过Libname定义的永久性数据集目录下永久保留,SAS系统即使关闭,仍然保留。
Libname库名‘数据集存放的路径’;data 库名.数据集名;例:libname abc‘d:\data\’;data abc.a;数据集和变量名的命名规则SAS数据集只能以英文字母开头,而不能以数字和中文字开头,也不允许出现空格和特殊字符(如:@、#、$和_),整个数据集名不能超过32个字符。
SAS 的变量名命名规则同上。
4SAS临时性数据集、永久性数据集程序演示SAS数据集创建●用Input和Cards语句创建数据集●将Excel文件中的数据转换成SAS数据集●SAS数据集子集化●SAS数据集纵向(Set语句)和横向(Merge语句)合并用Input和Cards语句创建数据集data a;input x@@;cards;1 2 3 4;run;@@:横行录入符号;如果是“input x;”,程序只将数据行的第1列读给x变量,但是“input x@@;”可以将数据行中的所有数据由第1行开始,由左向右、由上而下一次读入。
SAS程序演示将Excel文件中的数据转换成SAS数据集下拉菜单:文件数据导入SAS程序演示●根据需要,将原SAS数据集的记录或变量减少的过程 记录子集化(IF语句、OBS、FIRSTOBS选项)变量子集化(DROP和KEEP语句)SAS程序演示Set语句具有将两个以上的SAS数据集纵向合并work..a work.bset 纵向合并SAS程序演示●Merge 语句具有将两个以上的SAS 数据集横向合并●特别之处:两数据集子集需要唯一的联系变量(如ID 号);合并之前需要按联系变量排序。

数据合并方法1. 引言在数据处理和分析的过程中,常常需要合并不同来源、不同格式的数据。
数据合并是将多个数据集合并为一个数据集的过程,它能够提供更全面、更准确的信息,为后续的分析和决策提供支持。
本文将介绍数据合并的方法和技巧,帮助读者更好地进行数据合并操作。
2. 数据合并的常用方法数据合并的常用方法包括连接(Join)、追加(Append)、堆叠(Stack)等。
下面将逐一介绍这些方法。
2.1 连接(Join)连接是将两个或多个数据集按照某个共同的列进行合并的方法。
连接操作可以分为内连接、左连接、右连接和外连接等。
•内连接(Inner Join):只保留两个数据集中共同存在的行。
即只保留两个数据集中共同满足连接条件的行。
•左连接(Left Join):保留左侧数据集中的所有行,同时将右侧数据集中与左侧数据集满足连接条件的行合并。
•右连接(Right Join):保留右侧数据集中的所有行,同时将左侧数据集中与右侧数据集满足连接条件的行合并。
•外连接(Full Outer Join):保留两个数据集中的所有行,如果某一行在另一个数据集中没有对应的匹配行,则用空值填充。
连接操作可以使用多个列作为连接条件,也可以使用索引进行连接。
在进行连接操作之前,应先对数据进行排序或者去重,以确保连接的准确性。
2.2 追加(Append)追加是将两个数据集按照行的方向进行合并的方法。
追加操作可以将一个数据集的行添加到另一个数据集的末尾,从而扩展数据集的行数。
追加操作适用于两个数据集具有相同的列,但行数不同的情况。
追加操作可以使用concat()函数实现,在追加之前需要保证两个数据集的列名和列顺序相同。
2.3 堆叠(Stack)堆叠是将两个数据集按照列的方向进行合并的方法。
堆叠操作可以将一个数据集的列添加到另一个数据集的后面,从而扩展数据集的列数。
堆叠操作适用于两个数据集具有相同的行索引,但列数不同的情况。
堆叠操作可以使用merge()函数实现,在堆叠之前需要保证两个数据集的行索引相同。

sas 双set 语句SAS双set语句是SAS语言中用于合并和匹配数据集的强大工具。
它可以根据指定的变量将两个或多个数据集连接起来,并根据指定的条件将它们合并成一个新的数据集。
下面将详细介绍SAS双set 语句的用法和一些常见应用场景。
1. 基本用法:使用SAS双set语句合并两个数据集的基本语法如下:```sasdata new_dataset;set dataset1 dataset2;by common_variable;run;```以上代码中,new_dataset是合并后的新数据集的名称,dataset1和dataset2是要合并的两个数据集的名称,common_variable是两个数据集中共有的变量名称,用于指定合并的基准。
2. 内连接(inner join):内连接是SAS双set语句的默认连接方式,它只会保留两个数据集中共有的观测值。
通过设置SAS双set语句的选项,可以实现内连接。
例如:```sasdata new_dataset;set dataset1 dataset2;by common_variable;if not missing(variable1) and not missing(variable2);run;```以上代码中,通过添加if语句,可以实现对合并后的数据集进行筛选,只保留两个数据集中对应观测值都不为空的情况。
3. 左连接(left join):左连接是指保留左边数据集中所有的观测值,并将右边数据集中符合连接条件的观测值合并到左边数据集中。
通过设置SAS双set 语句的选项,可以实现左连接。
例如:```sasdata new_dataset;set dataset1 dataset2;by common_variable;if not missing(variable1);run;```以上代码中,通过添加if语句,可以实现只保留左边数据集中对应观测值不为空的情况。
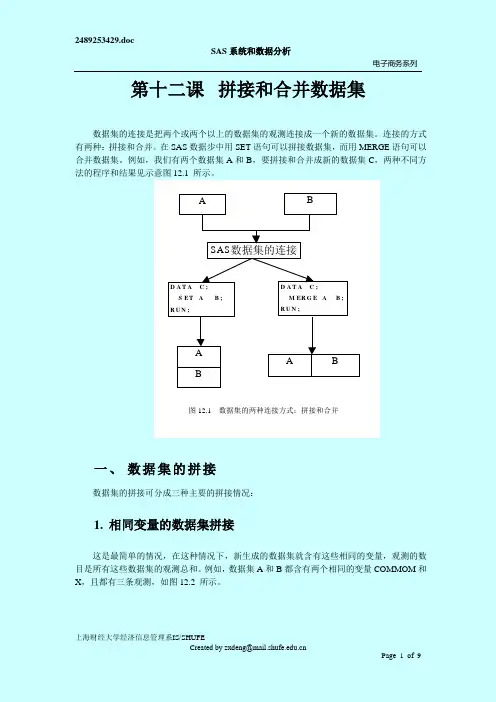
第十二课 拼接和合并数据集数据集的连接是把两个或两个以上的数据集的观测连接成一个新的数据集。
连接的方式有两种:拼接和合并。
在SAS 数据步中用SET 语句可以拼接数据集,而用MERGE 语句可以合并数据集。
例如,我们有两个数据集A 和B ,要拼接和合并成新的数据集C ,两种不同方法的程序和结果见示意图12.1 所示。
一、 数据集的拼接数据集的拼接可分成三种主要的拼接情况:1. 相同变量的数据集拼接这是最简单的情况,在这种情况下,新生成的数据集就含有这些相同的变量,观测的数目是所有这些数据集的观测总和。
例如,数据集A 和B 都含有两个相同的变量COMMOM 和X ,且都有三条观测,如图12.2 所示。
A BSAS 数据集的连接D A T A C ; S ET A B ;R U N ;D A T A C ;M ER G E A B ;R U N ;A BA B图12.1 数据集的两种连接方式:拼接和合并DATA A DATA B OBS COMMON X OBS COMMON X 198011198014 298022298025 398033398036图12.2 含有相同的变量COMMOM和X的两个数据集用下面程序生成新数据集C有两个相同的变量COMMOM和X,6条观测。
Data A;Input common x ;Cards ;9801 19802 298033Data B ;Input common x ;Cards ;980149802598036Data C ;Set A B ;Proc print data=C;Run;拼接生成的新数据集C的结果如图12.3所示。
图12.3 相同变量的数据集拼接结果2.不相同变量的数据集拼接如果两个数据集A和B含有的变量不完全相同,如上例中数据集B含有的不是COMMON 和X变量而是COMMON和Y变量,如图12.4所示。
用SET语句拼接A和B数据集后,新生成的数据集C就含有三个变量COMMON、X和Y,观测的数目仍然是所有这些数据集的观测总和,但原数据集中没有的变量在拼接后新数据集中为缺失值。

数据合并操作方法数据合并操作是指将两个或多个数据集合并成一个数据集的过程。
在数据分析和数据处理中,数据合并是非常常见和必要的操作,可以帮助我们快速整理和汇总数据,进而进行后续的分析和处理。
数据合并的方法有多种,下面将介绍几种常用的方法。
1. 列合并列合并是最简单的合并方法之一,也是最常见的合并方式之一。
列合并主要针对两个数据集具有相同的行索引,但列索引略有不同的情况。
例如,有两个数据集A和B,其中A包含3个列(col1、col2、col3),B包含2个列(col1、col4)。
我们可以使用列合并的方法将两个数据集合并成一个新的数据集。
具体操作步骤如下:- 确保两个数据集具有相同的行索引。
- 将两个数据集按照列索引对齐,对于不存在的列索引,对应的列填充缺失值。
- 将两个数据集按照相同的行索引进行合并。
2. 行合并行合并是将两个或多个数据集按照行的维度进行合并的方法。
行合并适用于两个数据集有相同的列索引,但行索引略有不同的情况。
例如,有两个数据集A和B,其中A包含3行(row1、row2、row3),B包含2行(row1、row4)。
我们可以使用行合并的方法将两个数据集合并成一个新的数据集。
具体操作步骤如下:- 确保两个数据集具有相同的列索引。
- 将两个数据集按照行索引对齐,对于不存在的行索引,对应的行填充缺失值。
- 将两个数据集按照相同的列索引进行合并。
3. 内连接内连接是将两个数据集按照某个或多个列索引进行连接的方法,只保留两个数据集中共有的行。
内连接适用于需要根据某个或多个列进行数据关联的情况。
具体操作步骤如下:- 确保两个数据集具有相同的列索引。
- 指定连接键,将两个数据集按照连接键进行连接。
- 如果连接键存在于两个数据集中,则保留两个数据集中连接键相同的行。
- 如果连接键只存在于一个数据集中,则删除该数据集中不匹配的行。
4. 左连接中的所有行,并根据连接键匹配右边数据集中的行。
左连接适用于需要扩充左边数据集的情况。

sas 教程
SAS(Statistical Analysis System)是一种统计分析系统,用于数据分析和应用的程序和工具的集合。
它具有强大的数据处理和分析功能,常被应用于各种数据处理和统计分析的领域。
SAS的语法结构相对严谨,下面介绍一些常用的SAS基础语法和操作:
1. 数据集的创建和导入
使用DATA语句创建SAS数据集,并使用SET、MERGE、UPDATE等语句导入和合并数据集。
2. 数据集的浏览和修改
使用PROC PRINT、PROC CONTENTS等语句来查看数据集的内容和属性,并使用DATA语句和相关函数对数据集进行修改。
3. 数据处理和转换
使用DATA和相关函数来进行数据处理和转换,如变量的重编码、缺失值处理、变量的计算和排序等。
4. 统计分析
使用PROC或DATA步骤中的相关统计函数进行数据分析,如频数分析、描述统计、方差分析、回归分析等。
5. 数据报告
使用PROC REPORT、PROC TABULATE等语句对数据进行
报告和汇总,生成PDF、Excel等报告格式。
6. 图表和可视化
使用PROC SGPLOT、PROC GCHART等语句进行图表和可视化的绘制,如直方图、散点图、饼图等。
7. 宏变量和宏语言
使用%LET语句定义宏变量,使用%MACRO和%MEND定义和调用宏语言,实现在SAS程序中的自动化和批量处理。
以上是SAS的一些基础语法和操作,通过学习和实践,可以进一步掌握SAS在数据分析和统计建模方面的应用。
SAS拥有庞大的社区和资源,可以通过官方文档、在线论坛和培训课程等途径获取更多的学习资料和支持。

sas中set的用法在SAS(Statistical Analysis System)中,`SET` 语句用于将一个数据集的内容复制到另一个数据集中。
这可以用于合并数据、创建新的数据集或者按照某种顺序组合数据。
以下是`SET` 语句的一般用法:```sasDATA 新数据集名;SET 原数据集名;/* 其他数据步操作*/RUN;```这里是一些关键点和示例:1. 基本用法:`SET` 语句简单地将原始数据集的内容复制到新的数据集中。
```sasDATA 新数据集名;SET 原数据集名;RUN;```2. 合并数据集:你可以使用`SET` 语句来合并两个或多个数据集。
```sasDATA 合并数据集名;SET 第一个数据集名第二个数据集名;RUN;```这将按照数据集出现的顺序合并它们。
3. 指定观测范围:你可以使用`FIRSTOBS` 和`OBS` 选项来指定要从原始数据集中复制的观测的范围。
```sasDATA 新数据集名;SET 原数据集名(FIRSTOBS=起始观测编号OBS=结束观测编号);RUN;```4. 重命名变量:你可以在`SET` 语句中使用`RENAME` 选项来为变量指定新的名称。
```sasDATA 新数据集名;SET 原数据集名(RENAME=(原变量名=新变量名));RUN;```这只是`SET` 语句的基本用法。
在实际应用中,你可能需要更复杂的操作,例如使用`BY` 语句进行分组合并,使用`IF` 语句进行条件筛选等。
SAS 的文档提供了详细的信息和示例,可以帮助你更好地理解和使用`SET` 语句。

10.合并数据集一、用SET 语句拼接合并数据集用SET语句可以把两个数据集拼接合并在一起,适用于两个数据集具有相同的变量。
基本形式为:data 新数据集名;set 旧数据集1 旧数据集2;注:(1)按原来顺序合并成新数据集(数据集1在上,2在下);(2)若一个数据集包含了另一个数据集没有的变量,那么合并后,该变量下将会出现缺省值。
例1路径“C:\MyRawData\”下有关于娱乐公园南北门游客的数据South.dat 和North.dat,都包括变量Entrance、PassNumber、PartySize、Age,后者多了一列Lot(停车):先分别读入数据存为数据集再合并成一个新数据集,并创建了新变量,AmountPaid.代码:data southentrance;infile'c:\MyRawData\South.dat';input Entrance $ PassNumber PartySize Age;proc print data = southentrance;title'South Entrance Data';run;data northentrance;infile'c:\MyRawData\North.dat';input Entrance $ PassNumber PartySize Age Lot;proc print data = northentrance;title'North Entrance Data';run;data bothentrance;set southentrance northentrance;if Age =.then AmountPaid =.;else if Age < 3then AmountPaid = 0;else if Age < 65then AmountPaid = 35;else AmountPaid = 27;run;proc print data = bothentrance;title'Both Entrances';run;运行结果:注意:南门数据中缺少Lot数据,堆叠合并后的观测值为缺省值。

•、用SET 语句拼接合并数据集用SET 语句可以把两个数据集拼接合并在一起,适用于两个数据集具 的变量。
基本形式为: data 新数据集名;set 旧数据集1旧数据集2;注:(1)按原来顺序合并成新数据集(数据集 1在上,2在下);(2)若一个数据集包含了另一个数据集没有的变量,那么合并后, 下将会出现缺省值。
例1路径“ ”下有关于娱乐公园南北门游客的数据 都包括变量 Entrance 、PassNumbe 、PartySize 、Age,后者多了一列 车): 先分别读入数据存为数据集再合并成一个新数据集,并创建了新变量,Amoun tPaid.代码:data southe ntran ce;infile 'c:\MyRawData\';in put En tra nee $ PassNumber PartySize Age; proc print data = southe ntran ce;title 'South Entrance Data';run;data no rthe ntran ce;infile 'c:\MyRawData\';10.合并数据集 有相同该变量 和, Lot (停in put Entrance $ PassNumber PartySize Age Lot; proc print data = no rthe ntran ce;title 'North Entrance Data';run;data bothe ntran ce;set southe ntrance no rthe ntran ce;if Age = . then AmountPaid =.;else if Age < 3 then AmountPaid = 0; else if Age < 65 then AmountPaid = 35; elseAmou ntPaid = 27;run;proc print data = bothe ntran ce;title 'Both Entran ces';run;运行结果:注意:南门数据中缺少Lot数据,堆叠合并后的观测值为缺省值。

sas中merge的用法
1. 哎呀呀,你知道吗,sas 中的 merge 就像是一个神奇的拼接大师!比如说,你有两个数据集,就像两块拼图,merge 就能把它们巧妙地拼在一起!比如你有一个学生信息数据集和一个成绩数据集,通过 merge 不就能一下子把学生信息和对应成绩连接起来啦,多厉害呀!
2. 嘿,sas 里的 merge 用法真的超有用呢!它就好比是把不同的故事片段连起来变成一个完整故事。
举个例子,有销售数据和客户信息数据,用merge 就能让它们完美结合,就像给每个销售记录都找到了主人一样,多有意思呀!
3. 哇塞,merge 在 sas 里简直就是魔法呀!就好像一个黏合剂把相关的东西都黏合在一起。
比如有产品信息和库存数量,通过 merge 就能清晰地知道每个产品的库存情况啦,这不是很棒吗?
4. 你想想看,sas 中的 merge 不就像是个搭桥的能手嘛!比如说有员工信息和部门信息,利用 merge 不就能把员工和他们所属部门联系起来了嘛,这多实用呀!
5. 哈哈,sas 里的 merge 真的太神奇啦!它就像一双灵巧的手把不同的部分组合起来。
就像是有订单信息和客户评价,merge 一下,就能清楚看到每个订单对应的客户反馈啦,多方便呀!
6. 天哪,merge 在 sas 里的作用可太重要啦!就如同是一个神奇的纽带。
比如有不同时间段的销售数据,通过 merge 可以把它们汇总起来,形成一个全面的销售情况画面,酷不酷?
总的来说,merge 在 sas 中是非常强大且实用的功能,一定要好好掌握和运用它呀!。
数据分析知识:如何进行数据分析的数据合并数据分析知识:如何进行数据分析的数据合并数据合并是数据分析的重要一环。
在进行数据分析之前,我们通常需要将所有相关数据合并到一个数据集中。
因此,数据合并技能是每个数据分析师必须掌握的技能之一。
数据合并的目的是将多个数据集合并在一起,形成一个完整的数据集。
在实际应用中,这些数据集可能来自不同来源,需要被整合到同一个数据集中。
在本文中,我们将讨论如何对数据集进行合并以及常见的数据合并方法。
1.如何对数据集进行合并在讨论常见的数据合并方式之前,我们需要知道如何将数据集进行合并。
当我们合并数据集时,需要考虑以下因素:-合并方式:我们需要确定合并方式,即使用何种方法将两个数据集合并在一起。
通常使用的方法有连接、联接和拼接等。
-合并位置:我们需要确定数据集的哪些列需要进行合并。
在很多情况下,我们需要使用某个共同的列(如ID)来合并数据集。
-数据集大小:我们需要考虑合并后数据集的大小。
合并后的数据集应该是我们可以处理的大小,否则可能出现性能问题。
2.常见的数据合并方式现在让我们来看一下常见的数据合并方式:-连接(Join):连接是将两个数据表格按照某个共同的键连接在一起的方法。
我们可以使用不同的连接方式,如内连接、左连接、右连接和外连接等。
这些连接方式决定了合并后数据集的内容和形式。
连接操作通常会涉及到一些复杂的逻辑,因此我们需要谨慎使用,以确保我们得到正确的结果。
-联接(Merge):联接是将两个数据集按照某个或多个共同的键联接在一起的方法。
联接通常是指在行级别上进行的合并操作。
它通常用于合并两个相对简单的数据集,其中一个数据集是基础数据集,另一个是需要增加新列的数据集。
-拼接(Concatenate):拼接是将两个数据集按照列或行拼接在一起的方法。
在按列拼接时,我们将两个数据集的列拼接在一起,形成一个新的数据集。
在按行拼接时,两个数据集将会按行拼接在一起,形成一个新的数据集。
目录SAS 数据集操作2014年03月28日1.合并2.删选,修改3.查询PPT 模板下载:/moban/1数据集的合并:(1)纵向合并:添加或合并样本变量(2)横向合并:添加或合并(指标)变量(1)数据集纵向合并:可以添加或合并样本变量形式:data 合并后数据名;set 数据名1 数据名2 ;run;例:将名为male、female 的两个数据集纵向合并成一个名为total 的数据集data total;set male female;proc print data=total;run;/*若male 与female 变量名不同则total 的变量名为两者之并,数据值以缺失值形式出现*/(2)数据集横向合并:添加或合并(指标)变量形式:data 合并后数据名;merge 数据名1 数据名2 ;by 共有变量名;run;例:将名为dataONE 和data TWO 的两个数据集按共有变量pid 横向合并成数据集total2(以下程序以data total2 名义保存)data one;input pid sex$ age; cards;101 m 54105 w 36102 m 43104 w 45;data two;input pid weight height; cards;105 54 163102 63 174103 57 173104 45 156;proc sort data=one;/*必须先对共有变量(本例中pid)分别排序才能横向合并*/by pid; /* 排序语句proc sort data=被排序变量所在数据集名; by 被排序变量名;排序时默认数值由小到大字母由先而后*/proc sort data=two; /*必须先对共有变量(本例中pid)分别排序才能横向合并*/by pid;/*以下为合并过程*/data total2; /*合并后数据名*/merge one two; /*形式: merge 被合并数据集名1 被合并数据集名2; */注意输出结果中的缺省值,输入数据时若有缺省分量一定要以. 表示,否则SAS 会将该行数据自行删除*/by pid;proc print data=total2;run;2(1)数据集的数据的删选拆分if…then output 选择(或delete 删除)(else output…)例:数据表E25data E26;set E25;/* 注: 调用sas 数据集中数据E25*/if sex=’m’then output;/*等同于if sex=’w’then delete;*/proc print data=E26;run;/*若要拆分成名为male、female 的两个数据集则可用以下方法*/data male female;set E25;if sex=’m’then output male;else output female;proc print data=male female; /*在output 窗口输出名为male、female 的两.个.数据集*/run;经数据删选得数据表E26经数据分拆得数据表male 与female(2)数据集的复制与修改例:C9501.XLS①数据集复制②修改③用UPDATE 语句更新数据集例:UPDATE 语句更新数据集3运用PROC SQL 查询数据用PROC SQL最简单的用法如下:PROC SQL;SELECT 第一项,第二项,......,第n项FROM 数据集WHERE 观测选择条件RUN;按观测条件查询:查询结果排序:联合查询:查询结果转存:THANK YOU2014年03月27日徐洋东。
sas数据操作-by、mergeBy语句By语句⽤于规定分组变量,控制set,merge,update或modify语句官⽅说明:BY<DESCENDING> variable-1<...<DESCENDING>variable-n> <NOTSORTED> ;specifies the variable that the procedure uses to form BY groups. You can specify more than one variable. By default, the procedure expects observations in the data set to be sorted in ascending order by all the variables that you specify or to be indexed appropriately.简单意思为:默认为升序,可以声明多个变量声明为降序:by descending var1 descending var2;每个变量前⾯都要写上descending.NOTSORTED:specifies that observations with the same BY value are grouped together, but are not necessarily sorted in alphabetical or numeric order. The observations can be grouped in another way (for example, in chronological order).声明所有by组的观测在⼀起,但是没有被排序,如果前⾯⽤到了descending,则会覆盖掉,使其⽆⽤data me; set sashelp.class;run;/*排序后me的内容会发⽣变化*/proc sortdata=work.me;by sex age;run;/*排序后的变量才能使⽤by,没排序的变量如果放在排序变量前会出现错误,放在后⾯没事⼉,这⾥是产⽣first和last观测值的步骤*//*意义在于寻找by组内的第⼀个和最后⼀个观测值*/data fst_lst;set me;by sex age ;fisrt_a = first.age;last_a = last.age;fisrt_n = first.sex;last_n = last.sex;run;/*复制到sas中会飘红,是格式问题,删除前⾯的空格即可*/data fst_data last_data; set me; by sex age; if first.sex then output fst_data; if last.sex then output lst_data;run;2:Merge语句Merge有四种形式,在连接时需要注意的⼏个问题是1:how each method treats duplicate values of common variables2:how each method treats missing values or nonmatched values of common variables注意的⼩问题如果有同名变量,那么后⼀个数据集的变量会覆盖前⼀个数据集中的同名变量The MERGE statement returns both matches and non-matches by defaultMerge的变量需要相同的type和name,但是不需要相同的length。
sas 合并数据集的条件
在SAS中,合并数据集的过程是基于两个或多个数据集之间共享的公共变
量进行的。
以下是合并数据集的先决条件:
1. 输入数据集必须至少有一个要合并的公用变量。
2. 输入数据集必须按照将用于合并的公共变量排序。
当公共变量的值存在匹配时,这些变量可以形成一个或多个数据集合,进而合并成一个记录。
在此过程中,通过使用MERGE和BY语句,可以将多个
数据集进行合并。
其中,公共变量是用于匹配合并的数据集合的变量。
例如,假设有两个SAS数据集,一个包含具有名称和工资的雇员ID,另一个包含
具有雇员ID和部门的雇员ID。
为了获得每个员工的完整信息,我们可以合并这两个数据集。
最终数据集仍将对每个员工有一个观察值,但它将包含薪水和部门变量。
以上内容仅供参考,如需更多信息,建议查阅SAS官方网站或咨询专业数
据分析师。
sas merge解释English Answer:SAS MERGE Statement.The SAS MERGE statement is used to combine data fromtwo or more SAS datasets. The resulting dataset willcontain all of the variables from all of the input datasets. The MERGE statement has the following syntax:proc sort data=dataset1 dataset2 ... datasetn;by variable-list;run;The DATA option specifies the input datasets that you want to merge. You can specify multiple datasets, separated by commas.The BY option specifies the variables that you want to use to merge the datasets. The variables that you specifyin the BY option must be common to all of the input datasets.Example.The following SAS code will merge the datasets`dataset1` and `dataset2` by the variable `id`:proc sort data=dataset1 dataset2;by id;run;The resulting dataset will contain all of the variables from both `dataset1` and `dataset2`. The data in the resulting dataset will be sorted by the `id` variable.Additional Options.The MERGE statement has a number of additional options that you can use to control the merging process. These options include:IN Specifies the datasets that you want to include in the merge.KEEP Specifies the variables that you want to keep in the resulting dataset.DROP Specifies the variables that you want to drop from the resulting dataset.RENAME Specifies the names of the variables that you want to rename in the resulting dataset.Example.The following SAS code will merge the datasets`dataset1` and `dataset2` by the variable `id`, and it will keep only the variables `name` and `age` from the resultingdataset:proc sort data=dataset1 dataset2;by id;keep name age;run;The resulting dataset will contain only the variables `name` and `age`, and it will be sorted by the `id` variable.中文回答:SAS MERGE 语句。
SAS-合并数据集(⼀)在SAS中,使⽤ SET 语句进⾏数据集纵向合并,⽤ MERGE 语句进⾏横向合并:DATA new_dataset; SET dataset_1 dataset_n;DATA new_dataset; MERGE dataset_1 dataset_n;BY variable_list;纵向合并后,new_dataset 的⾏数等于每个数据集⾏数的加总。
If one of the data sets has a variable not contained in the other data sets, then the observations from the other data sets will have missing values for that variable.横向合并中的 by variable list 是所有数据集共同的变量。
⼀、纵向合并例⼀:合并两个数据集 southentrance 和 northentrance, 合并后数据集观测值的顺序维持各⾃不变DATA both;SET southentrance northentrance;IF Age = . THEN AmountPaid = .;ELSE IF Age <3THEN AmountPaid =0;ELSE IF Age <65THEN AmountPaid =35;ELSE AmountPaid =27;PROC PRINT DATA = both;TITLE 'Both Entrances';RUN;例⼆:合并后数据集观测值按照 PassNumer 排序DATA interleave;SET northentrance southentrance;BY PassNumber;PROC PRINT DATA = interleave;TITLE 'Both Entrances, By Pass Number';RUN;⼆、横向合并例⼀:合并两个数据集 salesdata 和 descriptions,合并后的数据集包含两个数据集的所有观测值,相当于 full join/*Merge之前必须先对两个数据集按照 By variables 排序*/DATA chocolates;MERGE sales descriptions;BY CodeNum;PROC PRINT DATA = chocolates;TITLE ”Today's Chocolate Sales”;RUN;合并后的数据集 chocolates 包含两个数据集的所有 observations, 如果某条 observation 在另外⼀个数据集中没有,则对应的variable展⽰为缺失值。
10.合并数据集一、用SET 语句拼接合并数据集用SET语句可以把两个数据集拼接合并在一起,适用于两个数据集具有相同的变量。
基本形式为:data 新数据集名;set 旧数据集1 旧数据集2;注:(1)按原来顺序合并成新数据集(数据集1在上,2在下);(2)若一个数据集包含了另一个数据集没有的变量,那么合并后,该变量下将会出现缺省值。
例1路径“C:\MyRawData\”下有关于娱乐公园南北门游客的数据South.dat 和North.dat,都包括变量Entrance、PassNumber、PartySize、Age,后者多了一列Lot(停车):先分别读入数据存为数据集再合并成一个新数据集,并创建了新变量,AmountPaid.代码:data southentrance;infile'c:\MyRawData\South.dat';input Entrance $ PassNumber PartySize Age;proc print data = southentrance;title'South Entrance Data';run;data northentrance;infile'c:\MyRawData\North.dat';input Entrance $ PassNumber PartySize Age Lot;proc print data = northentrance;title'North Entrance Data';run;data bothentrance;set southentrance northentrance;if Age =.then AmountPaid =.;else if Age < 3then AmountPaid = 0;else if Age < 65then AmountPaid = 35;else AmountPaid = 27;run;proc print data = bothentrance;title'Both Entrances';run;运行结果:注意:南门数据中缺少Lot数据,堆叠合并后的观测值为缺省值。
二、用SET+BY语句排序拼接合并数据集前面是保持数据集原有顺序直接拼接合并,根据需要新数据集可以作排序处理。
但这样效率较低,更好的方法是先排好序再合并。
基本形式:data 新数据集名;set 旧数据集1 旧数据集2;by 变量1 变量2…;注:旧数据集必须是事先排好序的。
例2 同样是例1 的数据,对PassNumber 做排序拼接合并,注意南门数据已经按PassNumber 排序。
代码:infile'c:\MyRawData\South.dat';input Entrance $ PassNumber PartySize Age;proc print data = southentrance;title'South Entrance Data';run;data northentrance;infile'c:\MyRawData\North.dat';input Entrance $ PassNumber PartySize Age Lot;proc sort data = northentrance;by PassNumber;proc print data = northentrance;title'North Entrance Data';run;data sortbothentrance;set northentrance southentrance;by PassNumber;run;proc print data = sortbothentrance;title'Both Entrances, By Pass Number';run;运行结果:三、一对一匹配合并数据集经常会遇到合并两个数据集,它们有共同的变量(其不同取值都是各出现一次),用MERGE语句可以将两个数据集按共同变量进行一对一匹配合并。
注意:要求两数据集事先已按共同变量排序。
基本形式:DATA new-data-set;MERGE data-set-1 data-set-2 …;BY variable-list;注:(1)BY 语句指定共同变量;(2)若两个数据集有重叠的变量(除了BY指定的共同变量),第2 个数据集中的变量将覆盖第 1 个数据集中的相同变量。
例3路径“C:\MyRawData\”下有关于某巧克力店的数据,chocsales.dat 记录了所卖的巧克力代码、数量;chocolate.dat记录了巧克力代码、所代表的类型、描述:读入数据,按共同变量“巧克力代码”匹配合并数据集。
代码:data descriptions;infile'c:\MyRawData\chocolate.dat'TRUNCOVER;input CodeNum $ 1-4 Name $ 6-14 Description $ 15-60;run;data sales;infile'c:\MyRawData\chocsales.dat';input CodeNum $ 1-4 PiecesSold 6-7;proc sort data = sales;by CodeNum;run;data chocolates;merge sales descriptions;by CodeNum;run;proc print data = chocolates;title"Today's Chocolate Sales";run;运行结果:注意:数据1 中没有代码为“M315”的销售记录,合并后的观测值显示缺省值。
四、一对多匹配合并数据集也是两个包含共同变量的数据集要匹配合并,不同在于:该共同变量的同一取值在一个数据集中出现 1 次,在另一数据集中出现多次。
此时就是“一对多匹配合并”。
语法同“一对一匹配合并”完全相同。
例4 路径“C:\MyRawData\”下有关于鞋子打折的数据:Shoe.dat是关于鞋子的风格、类型、价格;Disc.dat 是关于每个类型鞋子的折扣(训练鞋、跑步鞋、走路鞋的折扣各不同):读入数据,按鞋子的类型合并数据集。
代码:data regular;infile'c:\MyRawData\Shoe.dat';input Style $ 1-15 ExerciseType $ RegularPrice;run;proc sort data = regular;by ExerciseType;run;data discount;infile'c:\MyRawData\Disc.dat';input ExerciseType $ Adjustment;run;/* Perform many-to-one match merge; */data prices;merge regular discount;by ExerciseType;NewPrice = ROUND(RegularPrice - (RegularPrice * Adjustment),.01);run;proc print data = prices;title'Price List for May';run;运行结果:五、在数据步中用IN = 选项跟踪选择观测值在DATA 步中,IN选项可以被用在SET, MERGE, 或者UPDATE 语句(更多是在MERGE 语句),接在要“追踪选择的数据集”后面。
结合下面的示例,其作用是给原数据集(customer)的每条观测都定义一个临时标签变量(只存在数据步期间不带入数据集,取值0 或1)用来指示“BY变量(CustomerNumber)”是否存在于“跟踪选择数据集(orders)”中,若存在,该条观测的临时标签变量Recent 取值为1,否则取值为0. 然后,将满足条件“Recent = 0”的观测,即CustomerNumber 号未包含在(orders)中的观测被选出来创建新数据集(noorders)。
示例:DATA noorders;MERGE customer orders (IN = Recent);BY CustomerNumber;IF Recent = 0;例5 运动品厂商有两份数据,一是包括所有客户的数据(C:\MyRawData\CustAddress.dat),变量包括客户编号、姓名、地址;一是包括了第三季度订单的数据(C:\MyRawData\OrdersQ3.dat),变量包括客户编号、总价格:现在想要了解哪些客户在第三季度没有任何订单,即可以用in=option 选项。
代码:data customer;infile'c:\MyRawData\CustAddress.dat'TRUNCOVER;input CustomerNumber Name $ 5-21 Address $ 23-42;data orders;infile'c:\MyRawData\OrdersQ3.dat';input CustomerNumber Total;proc sort data = orders;by CustomerNumber;run;/* Combine the data sets using the IN= option; */data noorders;merge customer orders (IN = Recent);by CustomerNumber;if Recent = 0;run;proc print data = noorders;title'Customers with No Orders in the Third Quarter';run;运行结果:。