SAS数据集的建立.
- 格式:pdf
- 大小:268.18 KB
- 文档页数:51

![[教学]sas常用函数和自动变量](https://uimg.taocdn.com/81b3c06600f69e3143323968011ca300a6c3f69a.webp)
SAS语言概述SAS提供了一种完善的编程语言。
类似于计算机的高级语言,SAS用户只需要熟悉其命令、语句及简单的语法规则就可以做数据管理和分析处理工作。
因此,掌握SAS编程技术是学习SAS的关键环节。
在SAS中,把大部分常用的复杂数据计算的算法作为标准过程调用,用户仅需要指出过程名及其必要的参数。
这一特点使得SAS编程十分简单。
一、SAS程序SAS程序是SAS语句的有序集合。
SAS程序可分为两部分:1.数据步(DATAStep)2.过程步(PROCStep)在一份SAS程序中,通常有一个数据步和一个过程步.有时可能有多个数据步和多个过程步。
数据步是为过程步准备数据的且将准备好的数据放在数据集中,过程步是把指定数据集中的数据计算处理并输出结果。
二、SAS语句SAS语句是以SAS关键词开头、后跟SAS名、特殊字符或操作符组成,并且以分号结尾。
一个SAS语句规定了一种操作或为系统提供某些信息。
1.SAS关键字关键字是系统已赋于确定意义的一个单词。
在SAS语言里,除了赋值、求和、注释等语句外,多数语句是以其关键字作为开头的。
如DATA、FORMA,PROC、INFILE等都是相应语句的关键字。
2.SAS名在SAS语句中,可能出现的SAS名有变量名,数据集名,输出格式名,过程名,选择项名,数组名和语句标号名。
还有SAS对文件的一种特殊称呼叫逻辑库名和文件逻辑名。
SAS名是字母或下划线开头后跟宇母或数宇或下划线的字符串,字符个数不多于八个。
空格和特殊宇符(如$,@,#等)不许在SAS名中出现。
另外,SAS保留了一些特殊的变量名并赋于特定的意义,这些变量都是以下划线开头和结尾,如N_表示数据步已执行过的次数。
三、语句描述记号(1)关键字用英文书写,在写程序时,这些词必须严格以给出的拼写形式书写。
(2)[ ]内的项是可选项。
(3)…表示有多个项目四、SAS数据集“SAS数据集(DataSet)”是SAS中一种特定的数据文件。



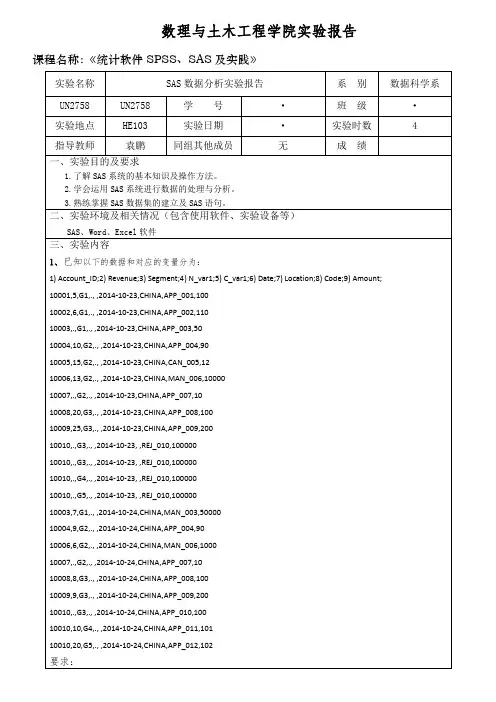
数理与土木工程学院实验报告课程名称:《统计软件SPSS、SAS及实践》实验结果(包括程序代码、程序结果分析)第一题:②基于数据集transaction,将变量“Revenue”中的缺失数据用其均值代替;data a;set a;array s(*) aa1-aa2;n=n(of s(*));mean=mean(of s(*));sum=sum( of s(*));do i=1to dim(s);if s(i)=.then s(i)=mean;end;run;proc print;run;③基于②,将取值全部缺失的变量删除。
data a;set a;array aa aa1-aa2;do over aa;if col=.then delete;end;run;proc transpose data=a out=transaction(drop=_name_);var aa1-aa2;run;proc print;run;第二题:a) 建立一个数据集合读入数据,变量为length,width和 height;data b;input length width height;cards;32 18 1216 15 2448 12 3215 30 4520 30 36;run;proc print data=b;run;b) 使用 set 语句,利用a)的数据集建立一个新数据集,它包括a)的所有数据,并建立三个新变量:每个c) 使用b)建立的数据集建立一个新数据集,只包括其中的volume 和 cost 变量。
data d;set c(keep=volume cost);run;proc print data=d;run;第三题:a)对车的标志(brand)的频数画竖直条形图。
libname mydata 'D:\data';proc print data=edcar;run;data e;set edcar; run;proc gchart;vbar brand;run;b)c)data g;set f;proc means data=g ;run;第四题:试分析:该地区单身人士的收入与住房面积之间是否相关?如果线性相关,确定一元线性回归方程,并做显著性检验。


实验1 SAS基本操作随着图形界面、用户友好等程序思想的发展,SAS陆续提供了一些不需编程就能进行数据管理、分析、报表、绘图的菜单操作功能,其中做得比较出色的有INSIGHT模块和Analyst 模块。
对于常用的一些统计分析方法,SAS系统中的如下三种方法可以达到同样的目的:●INSIGHT(“交互式数据分析”)●Analyst(“分析家”)●直接编程一般来说,INSIGHT模块在数据探索方面比较有特色,最为直观,便于步步深入;“分析家”可提供自动形成的程序,而且在属性数据分析和功效函数计算方面较INSIGHT强;编程方式是功能最强的,尤其是一些特殊或深入的分析功能只能用编程实现,但相对来说,编程较难熟练掌握。
在SAS系统中建立的众多SAS文件,可按不同需要将其归入若干个SAS逻辑库,以便对SAS文件进行访问和管理。
利用SAS系统功能直接建立数据集的方法很多,都需要将数据现场录入,费时费力。
较为简便的方法是,利用Excel录入数据,并作简单处理,然后将Excel数据表导入到SAS数据集中。
另外,也可以先将数据整理为文本文件(*.txt文件),再将文本文件导入为SAS数据集。
在对数据进行深入分析之前往往要利用INSIGHT或“分析家”对数据进行必要预处理。
1.1 实验目的通过实验熟悉SAS操作界面,掌握逻辑库的建立、数据集的导入与导出,掌握SAS的两个最为重要的模块:INSIGHT和“分析家”中对数据的预处理方法。
1.2 实验内容一、建立逻辑库二、数据集的导入与导出三、在INSIGHT中对数据的预处理四、在“分析家”中对数据的预处理1.3 实验指导首先建立存放数据的文件夹,如:“D:\SAS_SHIYAN”,其中再建两个文件夹:“原始数据”(用以存放本课程有关实验的Excel数据表及其他数据文件)和“SAS数据集”(用以存放本课程学习中生成的SAS数据集)。
1一、建立逻辑库【实验1-1】创建逻辑库“Mylib ”。

sas教程:第一章统计软件中的数据录入格式统计分析是科研中的必要环节,统计软件则是进行统计分析的利器。
但是,在计算机已逐渐普及的今天,统计软件却仍让人感到几分神秘:除了大型统计软件都还没有中文版这一原因,统计软件在许多小的方面也有自己的特点,往往就是这些小地方就会让许多人深入宝山而空返。
今天我们就来谈谈使用统计软件时一个最基本而又非常重要的问题--数据录入格式。
简言之,我们平时往往用表格的形式来记录数据,这并无不妥。
问题在于当进行统计分析时,如果我们直接将数据按平时记录的格式来进行分析,那就很可能不得其门而入--因为大多数统计软件对数据格式都有着特定的格式要求,下面我们就举一些常见的情况来解释这一问题。
1. 单组或多组数据平时我们多记录成" 第1组、第2组、第3组... " 等等,如表一左侧所示。
样本含量相等或不等。
主要用于成组资料比较的t、F或秩和检验等。
这种记录格式姑且称为统计表格格式,在各种统计软件中,该数据通用的分析格式如表一右侧所示,我们把这种格式称为统计分析格式。
表一①统计表格格式序号第1组第2组第3组1 0.1 0.4 0.62 0.2 0.5 0.73 0.3 0.84 0.9样本量 3 2 4②统计分析格式1 , 0.11 , 0.21 , 0.32 , 0.42 , 0.53 , 0.63 , 0.73 , 0.83 , 0.9看出来区别了吗?统计分析格式中第一列为“分组变量”,指示所在的组号;第二列为原始数据。
现在再回到SPSS等统计软件的菜单去,做one-way ANOVA(成组的方差分析)知道怎么选变量了吧!2. 配伍组数据平时的记录格式同上面相似。
主要用于配伍组资料比较或秩和检验等。
见表二:表二①统计表格格式序号第1组第2组第3组1 0.1 0.3 0.52 0.2 0.4 0.6样本量 2 2 2②统计分析格式1 , 1 , 0.11 ,2 , 0.22 , 1 , 0.32 , 2 , 0.43 , 1 , 0.53 , 2 , 0.6统计分析格式中第一列为“第一分组变量”,指示所在的组号;第二列为“第二分组变量”,指示在该组的序号,第三列为原始数据;3. 单组成对数据变量名分别为:X、Y,要求样本含量相等。


课时授课计课次序号:10、课题:实验四回归分析SAS过程(1)统计推断与预测二、课型:上机实验三、目的要求:1.掌握利用SAS建立多元回归方程的方法;2.能检验所建立回归方程的显著性与方程系数的显著性,能根据实际问题作预测与控制.四、教学重点:会对实际数据建立有效的多元回归模型;能对回归模型进行运用,对实际问题进行预测或控制.教学难点:多元回归模型的建立.五、教学方法及手段:传统教学与上机实验相结合.六、参考资料:《应用多元统计分析》,高惠璇编,北京大学出版社,2005;《使用统计方法与SAS系统》,高惠璇编,北京大学出版社, 2001;《多元统计分析》(二版),何晓群编,中国人民大学出版社, 2008;《应用回归分析》(二版),何晓群编,中国人民大学出版社, 2007;《统计建模与R软件》,薛毅编著,清华大学出版社,2007.七、作业:2.3 (单) 2.4八、授课记录:九、授课效果分析:实验四回归分析SAS过程(1)2学时、实验目的和要求掌握利用SAS建立多元回归方程的方法,掌握 PROC REG过程,并能检验所建立回归方程的显著性与方程系数的显著性,能根据实际问题作预测与控制.二、实验内容1.P ROC REG过程般格式:PROC REG <DATA=SAS data set>;MODEL 因变量=回归变量/ <选项部分>其它选择语句OUTPUT OUT=SAS 数据集名关键字名=输出数据集中的变量名;RUN;(1)PROC REG 语句此语句是PROC REG 过程的必需语句,指出要进行分析的数据集.省略此项,统对最新建立的数据集进行分析.SAS 系(2)MODEL 语句中的选项部分该语句定义建模用的因变量、回归变量(自变量)、模型的选择及拟合结果输出的选择.在关键词“ Model ”之后,应指明因变量,等号后依次列出回归变量,每个变量间用空格分开.此语句的选项部分提供了最优模型的选择方法和其他拟合结果的输出选项,其中包括:1)选择合适的建立模型方法:SELECTION=name其中“ n ame” 可以是FORWARD (或F)、BACKWARD (或 B )、STE PWISE、RSQUARE 、ADJRSQ 、CP 等之一.SELECTION=FORWARD SLENTRY= 显著性水平向前选择最优模型法(FORWARD ):从仅含常数项的回归模型开始,逐个加入自变量,对每一个尚不在方程内的自变量按一定显著性水平,根据其一旦进入模型后对模型的贡献大小逐步引入方程,直至再没有对模型有显著贡献的自变量.“SLENTRY= 显著性水平”为自变量进入模型的控制水平,写在选择方法语句之后.若省去此句,则SAS 系统默认的水平为SLENTRY=0.05 .SELECTION=BACKWARD SLSTAY=显著性水平向后删除法(BACKWARD ):先建立包含全部自变量的线性回归模型,然后按一定 的显著性水平从模型中逐步剔除变量.缺省SLSTAY =0.1SELECTION=STEPWISE SLENTRY = 入选水平 SLSTAY=易9除水平 逐步回归法(STE PWISE ):按向前选择法(前进法)进入变量,再对模型内所有变量检验,看是否有因新变量引入而对模型的贡献变得不显著,若有就剔除,若无则保留, 直至方程内所有变量均显著.逐步法有两个控制水平,即选入水平( SLENTRY=入选水平)和剔除水平(SLSTAY=剔除水平),而且剔除水平应低于选入水平.缺省 SLENTRY =0.15 SLSTAY =0.1 5SELECTION=RSQUARE在所有可能的回归方程中用 R p 准则选择最优模型 的方法.在每一个给定的自变量2个数的水平上,打印出使 R p 达到最大的那个回归模型的拟合结果.SELECTION=ADJRSQ :修订的R :准则选择最优模型法. SELECTION=CP : C p 准则选择最优模型法.注意:以上方法只可在选项部分写出其中一种,不可并用.2)对模型选取细节的选项DETAILS :对模型选取方法 FORW ARD 、BACKWARD 、STEPWISE ,若打印出每一步引入和删除自变量及相关信息选用此项.如一个自变量选入模型时的偏 型的R 2值和一个自变量被剔除时模型R 2值及有关参数估计的信息.NOINT :取消回归模型的常数项,即拟合过原点的回归方程. 3)对估计细节内容的选择:在选项部分,还可以选择一个或多个 (中间用空格分开) 参数估计和拟合残差等相关内 容,常用的有:CORRB :输出参数估计的 相关系数矩阵,第i 行第j 列为与时相关系数估计. COVB :输出估计参数的 协方差矩阵,即MSE (X TX )-1.P :输出因变量拟合值、观测值、拟合残差.若已选 CLI 、CLM 、R ,无需该选项. R :输出有关残差及用于影响性分析的各量,包括拟合值的标准差、残差、学生化残差(残差除以标准差)及 Cook 距离(度量了当删除某观测值后,参数估计的总变化量)T X 厂注意:以上选择内容可以和最优模型选择方法并用于BACKWARD 、FORWARD 、STEPWISE 的模型选择方法, 模型的相应结果;对 RSQUARE 准则,只给出全模型的相应结果;对于F 值、模I :输出矩阵(XTX )d .输出形式为「(XSSE 」Model 语句的“选项部分”.对 以上估计细节内容只是最终选择ADJRSQ 和 CP 方法,给出具有最大 R ;和C p 值的模型的相应结果.(3) OUT PUT 语句一一建立SAS 的输出结果数据集 此语句建立一个与估计内容有关的 SAS数据集.语句格式为:OUTPUT OUT=SAS 数据集名 关键字名=输出数据集中的变量名;关键字名为需要的统计量名,它们有PREDICTED (或P ) =name :因变量拟合值,指定名称为 name ; RESIDUAL (或R ) =name :残差及指定的名称; STUDENT=name :标准化(或学生化)残差;L95M=name :因变量期望值的95%的置信区间的置信下限; U95M=name :因变量期望值的95%的置信上限; L95=name :因变量值的95%置信区间的置信下限; U95=name :因变量值的95%的置信区间的置信上限;COOKD ( COOK 氏D 值)=name : Cooki 距离,用于影响性分析的统计量; H=name :杠杆量,即X i (X T X )」x T , i =1,2,…,n,X i 是设计矩阵X 的第i 行; PRESS=name : d i (p)值,用以估计第i 组观测值对拟合值的影响; DFFITS=name :用以估计第i 组观测值对参数估计的影响; STDP=name :期望值的标准误差 STDR=name :残差的标准误差; STD I =name :预测值的标准误差;其中等号前的部分为输出语句的关键词,后面的 以上介绍了一些常用的选项•无论选项如何, 的参数估计值及其标准差,检验参数是否为零的验回归关系显著性的 F 统计量和P 值,复相关系数及其平方值等.2. 示例例1 (书上例2.3 )某科学基金会的管理人员欲了解从事研究工作的中、高水平的数学家的年工资额丫与他们研究成果(论文、著作等)的质量指标X 1、从事研究工作时间 X 2、能 获得资助的指标 X 3 •为此按一定设计方案调查了24位此类型的数学家,得数据如书上表2.3所示.(1) 假设误差服从 N(0,b 2)分布,建立丫与X 1,X 2,X 3之间的线性回归方程并研究相 应的统计推断问题;name 飞等号前的变量指定一名称 PROC REG 过程总是自动输出相应模型t 统计量值及相应的 P 值•方差分析表、检(2)假设某位数学家的关于X i,X2,X3的值为(X oi,X o2,X o3)=(5.1,20,7.2),试预测他的年工资额并给出置信度为95%的置信区间.设丫与 X 1,X 2,X 3回归模型 丫 = * + P1X 1 +P 2X 2 + P 3X3+S 观测值满足 y i =p 0 + p 1 X i1 +p 2Xi2+ p3Xi3 +E i ,i =1,2,…,24(i =1,2"-,24)相互独立,且 S i ~ N(0,cr 2).£~ N(0, /1)SA 繇统回归分析的proc reg 过程进行统计推断程序:data exa mp2_3; input y x1-x3; cards33.2 3.5 9 6.1 40.35.3 206.438.7 5.1 18 7.4 46.8 5.8 33 6.7 41.44.2 31 7.537.5 6.0 13 5.9 39.0 6.8 25 6.0 40.75.5 30 4.030.1 3.1 5 5.8 52.9 7.2 47 8.3 38.2 4.5 25 5.0 31.8 4.9 11 6.4 43.38.0 23 7.644.1 6.5 35 7.0 42.86.6 39 5.033.6 3.7 21 4.434.2 6.2 7 5.5 48.0 7.0 40 7.0 38.0 4.0 35 6.0 35.9 4.5 23 3.5 40.45.9 33 4.936.8 5.6 27 4.3 45.24.8 34 8.0 35.1 3.9 15 5.0 run ;解:(1)建立回归模型进行统计推断其中1)proc reg data =exa mp 2 3; /*调用回归分析的reg 过程*/Sum of Mea nDF Squares SquareCorrected Total 23 SST=689.260001.75276 R-Square 0.9109 Depen de nt Mea n 39.50000Coeff Var 4.43735从方差分析表得出 c/2=MSE =3.0722 ;MSR H0真统计量F〜F (3, 20),其观测值F 0 =68.119MSEp = P H 0(F >F 0) =0.0001,拒绝H 0,认为Y 与X i ,X 2,X 3的线性回归关系是高度显著的.另外,由方差分析表给出宀磐二签勿9109,也表明线性回归关系高度显著・P arameter Estimates参数估计表model y=x1-x3/i; run ; /* 模型因变量 y,自变量x1、x2、 x3,输岀Hessian 矩阵*/ 2) 由方差分析表进行统计推断 An alysis of Varia nee方差分析表方差来源 自由度 平方和(SS ) Model Error 均方(MSp-1=3 SSR=627.81700 MSR=SSR/3=209.27233 F n-p=24-4=20 SSE=61.44300 MSE=SSE/20=3.072150=MSR/MSE检验 p 值 p 00=68.12 < 0001SourceF Value Pr > FRoot MSE Adj R-Sq 0.8975线性回归关系显著性检验:H 。
SAS编程基础-数据获取与数据集操作(1)1. 数据来源SAS数据来源主要有两种:⼀是通过input语句创建,另外⼀种⽅式是通过外部数据⽂件获取。
1.1 libname1.2 odbc1.3 passthrough1.4 import1.5 input该⽅式是在SAS系统下通过input语句输⼊SAS数据块,实践中是最不常的⽤的⼀块。
2. set语句从⼀个或者多个SAS数据集中读取观测值并实现纵向合并。
2.1 keep=选项data keep;set sashelp.class(keep = age sex);run;该⽅式创建了⼀个临时数据集keep(输出数据集),然后使⽤set语句从数据集sashelp.class中获取数据,keep=指定了读⼊的变量,其他冗余变量不读取,最后将读取的变量输⼊到数据集keep中。
还可以输出两个或者多个数据集:data d1(keep=name)d2(keep=name sex);set sashelp.class(keep=name sex);run;输出数据集d1和d2,并且分别在每个数据集后使⽤keep=指定了输出的变量。
在set语句中使⽤keep=语句,可以提⾼运⾏效率,因为它使得set语句从数据集class中只读取了name和sex两个变量到PDV中。
去掉这⾥的keep=不会报错,但是效率会降低。
进⼀步,如果将这⾥的keep修改为“keep=name”,即去掉sex,那么导致的结果是数据集d2中只包含name变量,⽽不包含sex变量,这是因为set语句没有读取sex 变量,⾃然不会输出到d2中。
2.2 rename=选项将变量名重新命名:data rename;set sashelp.class(keep = name sex rename=(name=name_new sex=sex_new));run;对重命名变量需要⽤括号括起来。
2.3 where表达式添加筛选条件:data where;set sashelp.class(keep=name sex where=(sex='男'));run;读取性别为男的⼈的姓名和性别。
在SAS中执行拟合优度检验,通常涉及以下步骤:
1. 创建数据集:首先,我们需要创建一个数据集并将其命名为my_data。
例如,我们可能有一些关于一周内每天客户数量的数据。
2. 执行卡方拟合优度检验:接下来,我们将使用卡方拟合优度检验来检查实际观测次数与理论次数之间是否一致。
这一步可以利用SAS的PROC FREQ或PROC CATMOD等过程来实现。
3. 选择适当的拟合优度检验方法:根据数据类型和分布特性,可能需要选择不同的拟合优度检验方法。
例如,安德森-达令拟合优度检验和卡方拟合优度检验是常用的概率分布检验方法。
SAS提供了多种拟合优度检验方法,如Pearson's拟合优度检验、偏差或称似然比拟合优度检验、Hosmer-Lemeshow拟合优度检验和稀疏资料拟合优度检验等。
4. 解读结果并做出决策:根据检验结果,我们可以判断数据是否与理论或预期的次数分布相符。
如果实际观测次数与理论次数显著不符,则可能需要调整模型或假设。
以上描述的过程主要针对的是卡方拟合优度检验,而在实际工作中可能还需要对场景进行深入研究,选择合适的统计方法进行模型拟合。
课时授课计划课次序号:03 04 一、课题:实验一SAS基本内容二、课型:讲授与上机实验三、目的要求:1.掌握SAS软件的基本功能与基本操作方法;2. 了解SAS软件的基本内容:数据的输入与输出,建立SAS数据集, SAS系统数学运算符号及常用的SAS函数,逻辑语句与循环语句.四、教学重点:SAS软件的基本功能与基本操作方法.教学难点:SAS软件的基本操作方法.五、教学方法及手段:传统教学与上机实验相结合.六、参考资料:1.《实用统计方法》,梅长林,周家良编,科学出版社;2.《SAS统计分析应用》,董大钧主编,电子工业出版社.七、作业:补充练习八、授课记录:九、授课效果分析:实验一 SAS基本内容(3学时)一、实验目的和要求了解SAS软件的基本内容:数据的输入与输出,建立SAS数据集, SAS系统数学运算符号及常用的SAS函数,逻辑语句与循环语句.会建立SAS数据集,运行程序,分析结果.二、实验内容1.直接输入数据建立SAS数据集在SAS程序窗口下,直接输入建立SAS数据集,基本语句:DATA name ; /* 要建立的数据集名称*/INPUT variables;/* 指明数据集变量名称,为不超过8字符的字符串*/CARDS; /* 此句后面将读入数据*/Data lines; /* 数据行,两个数据间用至少一个空格隔开;用格式化输入,则数据要按指定格式输入*/ ; /* 表数据输入结束*/RUN; /* 程序运行*/⑴自由输入建立SAS数据集INPUT 变量名 <$> ⋯;在INPUT后面依次列出变量名称,变量间至少一个空格,<>为可选项,变量名后输入$——代表字符型变量,如果数据中每行有多余一组观测值,可在INPUT variables后加@@,表示指针不换行读入各组观测值.例如: INPUT ID NAME $ VAR1 VAR2 VAR3 VAR4; /*输入6个变量,序号变量ID、字符型变量NAME及数值变量VAR1、VAR2、VAR3、VAR4 */INPUT ID NAME $ VAR1 - VAR4; /* 6个变量名,NAME字符型*/⑵格式化输入建立数据集方式一列输入:INPUT 变量名 <$> 开始列<- 结束列>⋯;通过指定变量取值所占列数输入相应值.在每个变量名后,空一格指出变量值占据的列数.例如: INPUT ID 1-2 NAME $ 4-20 VAR1 22-24 VAR2 26-30; /* 4个变量名,将1、2列的数值赋予变量ID,第4到20列字符赋予字符型变量NAME,22到24列数值赋予VAR1*/方式二格式化输入W.d格式:INPUT 变量名 <修饰符> 输入格式W.d ;W——变量取值所占总列数,d——表示从右到左小数部分列数.此这种方式尤其适合于各变量间取值无空格、和无小数点的数据集.例如INPUT ID 2.NAME $ 10.VAR1 5.2; /* 前2列赋予ID,第3列开始10列内容赋予非数值变量NAME,接下来5列赋予V AR1,最后两位为小数部分.*/如果变量ID与NAME的值之间有三个空格,在读完ID的值后,指针从第3列跳到第6列开始读入NAME的值,应在ID2.后空一格写上@6(移到第6列)或+3(跳过3行),另外,数据间的空格也可并到变量值的位数中.如果有连续几个变量的W.d格式相同,可用下列简写形式:INPUT (variables) (W.d);如INPUT (X Y Z)(2.1);INPUT (X1-X10)(2.)等.例8.1.1 设有数据集如下:LIMING 23 56 170LIUHUA25 60 174ZHANGWEI 30 65 165相应变量分别为NAME,AGE,WEIGHT和HEIGHT,输入数据以建立一个名为examp8_1_1的SAS数据集.方法一:自由格式输入数据以建立数据集,完整的SAS程序:data examp8_1_1; /* 建立数据集 examp8_1_1 */input name $ age weight height;/* 输入变量 */cards; /* 以下为数据行*/LIMING 23 56 17 /* 数据和变量名对应,数据间用空格表示*/ LIUHUA 25 60 174ZHANGWEI 30 65 165; /* 数据行结束*/run; /* 运行程序*/proc print data=examp8_1_1; /*打印输出数据集*/run; /* 运行程序*/方法二:格式化输入:若上述程序中数据行的形式保持不变,数据之间空一格,只要INPUT 语句修改即可data examp8_1_1;input name $ 1-8 age 10-11 weight 13-14 height 16-18;/*或 input name $ 8.+1 age 2.+1 weight 2.+1 height 3.; *//*或 input name $ 8. @10 age 2. @13 weight 2. @16 height 3.; *//*或 input name $ 9. age 3. weight 3. height 3.; */cards;LIMING 23 56 170LIUHUA 25 60 174ZHANGWEI 30 65 165;run;proc print data=examp8_1_1;run;方法三:格式化输入:如将NAME取值中的姓和名用一空格分开,且HEIGHT的值表成具有两位小数的形式,如下data examp8_1_1;input name $ 9. +1 age 2. +1 weight 2. +1 height 3.2;/* 或input name $ 9. @ 11 age 2. @ 14 weight 2. @ 17 height 3.2;*/ cards; /* name $ 9.说明NAME占9位,正好姓名之间有空格*/ LI MING 23 56 170LIU HUA 25 60 174ZHANG WEI 30 65 165;run;proc print data=examp8_1_1;run;方法四:格式化输入:如程序中数据集的变量之间无空格,且使height的变量值有2位小数的形式,可按如下data examp8_1_1;input name $ 9. age 2. weight 2. height 3.2;/*或 input name $ 1-9 age 10-11 weight 12-13 height 3.2;*/cards;LI MING 2356170LIU HUA 2560174ZHANG WEI3065165;run;proc print data=examp8_1_1;run;注意:必须按照名字占够9位(位数不够输入空格),年龄占10-11列,weight占12-13列,height占14-16列来输入程序,变量之间无空格.结果为 1 LI MING 23 56 1.702 LIU HUA 25 60 1.743 ZHANG WEI 30 65 1.65注意:例8.1.1建立的SAS数据集只能保存在SAS程序中.调用被保存的SAS程序,加上进行分析的程序(如描述性分析程序),形成完整的程序,再在进行统计分析计算.(3)建立永久数据集用Libname语句建立SAS永久数据集(name.sas7bdat),基本语句:Libname SAS数据库名“路径”;/*建立数据库引用名*/Data 数据集名;/*新建数据集名:数据库.数据集*/Input 变量名<$>⋯;Cards;⋯⋯;RUN;例8.1.2将上例建立永久数据集保存在E:\lixiaoyan目录下,集名examp8_1_1.sas7bdat.程序:LIBNAME lxy'E:\lixiaoyan'; /* 新建立逻辑库引用名lxy,地址E:\lixiaoyan,此地址用逻辑库名lxy代替 */DATA lxy. Examp8_1_1; /*建立数据集examp1_1_1,存此文件夹下,库引用名为lxy */ input name $ age weight height;cards;LIMING 23 56 17LIUHUA 25 60 174ZHANGWEI 30 65 165;run;proc print data=lxy.examp8_1_1;run;则在E:\lxy,生成数据集文件examp8_1_1.sas7bdat.注意:10重新调入数据库文件examp8_1_1.sas7bdat:在重新打开的程序窗口输入LIBNAME lxy'E:\lixiaoyan';PROC PRINT DATA=lxy. examp8_1_1;RUN;即可调入数据库文件examp8_1_1.sas7bdat,并在输出窗口显示刚才的结果.20建立SAS逻辑库的方法也可以先建好逻辑库,这样相应数据库中的数据集可以用Set命令直接调用Set 逻辑库名.数据集名;创建逻辑库步骤:1.在“资源管理器”(Explorer)(左边视窗)窗口中,点“逻辑库(Library)”文件夹 (或点击:查看View-资源管理器) ;2.选择“文件”(Files)“新建(NEW)”,或在SAS环境窗口右击逻辑库,选择“新建”;3.在“新建逻辑库(NEW Library)”窗口名称域(Names)中输入逻辑库名,如lxy.库名不超过8个字符;4.选择引擎(Engine)类型,一般选默认即可;5.如果希望以后SAS在启动时自动启用该逻辑库,选中“启动时启用(Enable atstartuo)”复选框;6.“逻辑库信息”各区域中输入相应信息,路径(Path)中给出SAS文件所在路径(或点Browse找文件所在路径,找到文件夹双击);7.单击“确定”按钮,新逻辑库出现在SAS资源管理器窗口的逻辑库中.双击逻辑库及文件名,可以显示数据集.练习8.1 利用8.1.1 的数据集以建立一个名为ex8-1的SAS永久数据student.sas7bdat 放在文件夹E:\个人文件夹下.相应变量不变,增加序号ID(3位)、性别SEX,输入数据采用格式化输入height保留2位小数,姓和名之间加空格,并重新调用打印输出.2. 利用外部数据文件建立SAS数据集(1)从外部文本文件读入数据利用SAS处理数据,经常是从外部文本数据文件中读入数据,建立一个数据集.要求的外部数据文件必须是可以在Windows操作系统下用显示其全部内容的ASCII文件.该文件的第一行就是数据,不可以是字段名,各变量值依次存放.可用INFILE语句将其读入并建立SAS数据集,DA TA程序步的三个主要步骤为:●启动一个数据步,命名将要创建的数据集(使用DA TA语句).●确定要读入的外部文件(使用INFILE语句).●描述如何读入每一条记录(使用INPUT语句).如果需要在程序中直接嵌入数据,第二步用CARDS语句代替INFILE语句.所对应的一般程序结构如下:DATA name ;/* 命名所要创建的数据集名*/INFILE ‘drive location :\file name’; /* 读取外部文件,drive locationz指驱动器名及子目录名,file name是数据文件名(包含后缀)*/INPUT variables; /* INPUT变量1读入模式变量2 读入模式,变量模式要根据数据集中格式确定相应的变量输入格式,不能有汉字*/RUN;例8.1.3 从文本文件导入数据集有一文本文件a.txt存于E:\lixiaoyan,内容如下:Beijing 338 93519 274803 66556 76347 18672Tianjin 230 72335 198537 52635 55223 13105Hebei 814 464146 1293887 318714 344686 67536Shanxi 560 228292 647261 163273 186674 36985InnerMongolia 372 179126 473568 117525 121274 24593Liaoning 464 258609 685199 169848 180225 35586Jilin 296 169907 451637 101107 123022 22302Heilongjiang 479 203315 546793 139441 185184 32648Shanghai 344 106474 313811 91017 76222 17832Jiangsu 844 494692 1373465 353177 330488 82855Zhejiang 610 299904 860613 215649 191700 53303Anhui 758 402700 1050188 248451 222229 45646Fujian 614 255749 659758 159242 163985 40132Jiangxi 642 294093 800049 198869 180557 43653将此文件调入建立数据集,并打印输出.解:将此文件调入,并保存到如保存到E:\lixiaoyan下,程序:* examp8_1_3;LIBNAME lxy'E:\lixiaoyan';DATA lxy.b;INFILE'E:\lixiaoyan\a.txt';INPUT name $ A B C D E F;PROC PRINT;RUN;则在E:\lixiaoyan下新增文件b.sas7bdat.注意:如果只是建一个临时文件,前两行输入“data b;”即可.练习8.2 文本文件E:\个人文件夹\a.txt,将其调入建同名数据集,存放此文件夹中.(2)从已建立的SAS数据集中读入数据利用SET语句,可以从一个已存在的SAS数据集依次读入每一个观测.对数据做某种处理后,写入新数据集.例如,刚才在E:\lixiaoyan目录下,已经建立了数据集名examp8_1_1.sas7bdat,将此数据集读入建立新数据集.LIBNAME lxy 'E:\lixiaoyan';DATA d1;SET lxy.Examp8_1_1;RUN;PROC PRINT;RUN;(3)从其它数据库文件中导入数据常用的数据管理软件将需要处理的数据录入到相应的数据库文件中,用SAS处理时,需将该数据格式的文件转换为SAS数据集.可以使用数据导入(Import)功能,实现Access、Excel、dbf等常见数据格式与SAS数据集的无缝转换.方式一:编程实现数据的导入导出例8.1.4 E:\sassy 中文件climate.xls中有4个变量,编程将此文件将其转换为同名SAS 数据集.* examp8_1_4;LIBNAME ss 'E:\sassy'; /* 引用逻辑库名ss,地址E:\sassy */PROC IMPORT OUT= ss.climate /*IMPORT过程实现转换,输出的数据集名ss.climate ,库ss */DATAFILE= "E:\sassy\climate.xls" /* 要导入的数据文件地址及文件名*/DBMS=EXCEL REPLACE; /*指定要导入的数据库管理系统为Excel*/ SHEET= "Sheet1$"; /*指定电子表格中的表单为Sheet1*/GETNAMES=YES; /* 指出第一行是否有字段名*/RUN;PROC PRINT;RUN;方式二:使用向导实现数据的导入和导出:步骤:1)进入SAS系统,单击“文件(File)”,选“导入数据(Import Data)”,启动“向导(Import Wizard)”;2)从下拉列表选择所使用的数据源类型,如Microsoft Excel97 or 2000 work book,单击“下一步(NEXT)”按钮;3)选择数据源文件,比如“E:\lixiaoyan\book1.xls”,单击“浏览(Browse)”,选中文件,单击“OK”按钮;4)选择数据表的表名(数据表有三个,选取需要的,如”Sheet1$”;5)选择建立何种数据集.确定数据集存储位置数据库(library)如lxy和数据集名(member)如c.可事先利用LINBNAME语句建立一个逻辑库,或利用系统提供的User逻辑库,建立永久数据集.如选library为ss, 成员写climate1(或从中选),单击下一步;6)单击“完成(Finish)”,如果需要将相应的操作写为程序文件,单击“Next”按钮;8)输入要建立的导入文件位置和文件名,单击“浏览”按钮,选择位置(如E:\lixiaoyan)及文件名如c,产生一个程序文件c.sas,单击完成即可.这样在E:\lixiaoyan可以看到数据集c.sas7bdat 和程序文件c.sas.再打开c.sas,就会出现如下程序:PROC IMPORT OUT= lxy.CLIMATE1DATAFILE= "E:\lixiaoyan\c.xls"DBMS=EXCEL2000 REPLACE;SHEET="Sheet1$";GETNAMES=YES;RUN;要再次调入此数据集,键入程序:DATA d1;SET lxy.c;RUN;PROC PRINT;RUN;即可,输出结果同上.3.利用已有的SAS数据集建立新的数据集(1)数据集的合并数据集的连接是把两个或两个以上的数据集的观测连接成一个新的数据集.连接的方式有二种:串(拼)接和合并.在SAS数据步中用SET语句可以拼接数据集,而用MERGE语句可以合并数据集.例如我们有二个数据集A和B,要拼接和合并成新的数据集C,二种不同方法的程序和结果见示意图所示:例8.1.5 两数据集的拼接* examp8_1_5;Data A ;Input common x ;Cards ;9801 19802 29803 3Data B ;Input common x ;Cards ;9801 49802 59803 6Data C ;Set A B ;Proc print data=C ;Run;结果输出:Obs common x1 9801 12 9802 23 9803 34 9801 45 9802 56 9803 6注意:如果在“E:\lixiaoyan”下,已经新建立了数据集,A.sas7dbat和B.sas7dbat,逻辑库如lxy已经调用(或设为永久库),则直接将A、B合并即可:Data lxy.C ;Set lxy.A lxy.B ;Proc print data=Gg.C ;Run;在“E:\lixiaoyan”下,新建了数据集,C.sas7dbat.结果如上.例8.1.6 两数据集的合并* examp8_1_5;Data A ;Input common x ;Cards ;9801 19802 29803 3Data B ;Input common Y ;Cards ;9801 49802 59803 6Data C ;MERGE A B ;Proc print data=C ;Obs common x Y1 9801 1 42 9802 2 53 9803 3 6(2)变量值的排序有时需要将某个名为“name”的SAS数据集中的各观测变量按某个变量的取值由小到大(数值变量)或按字母顺序(非数值变量)排序,SAS语句形式为:PROC SORT DATA=name;/* 调用排序过程SORT*/BY variable;/* 按variable 排序*/RUN;例8.1.5 中,按变量值common排序,程序:……Proc Sort Data=C;By common;Run;Proc print data=C ;Run;结果输出:Obs common x Y1 9801 1 .2 9801 . 43 9802 2 .4 9802 . 55 9803 3 .6 9803 . 6(3)删除数据集中的某些数据行(观测向量)DATA new name;SET A;IF conditions THEN DELETE;RUN;例如,练习8.1在E:\lixiaoyan建立的数据集examp8_1_1.Sas7bdat,删除第4行,程序:Libname ss 'E:\lixiaoyan'; /*数据集所在文件夹逻辑库*/data aa;set ss. examp8_1_1;If _N_=2Then DELETE;RUN ;Proc PRINT data=aa;Obs name age weight height1 LIMING 23 56 172 ZHANGWEI 30 65 165Obs(4)删除数据集中某些变量及相应观测值DATA new name;SET A;DROP X1 Y1;(或KEEP X2 Y2 Y3;)RUN;(5)产生新变量及其观测值对一个SAS数据集,有时需要产生一个新变量和计算相应观测值.例如,SAS系统只需对变量做相应运算,即可一次性产生新变量的各个观测值.例如,SAS数据集“OLD”中,包含变量Y1,X1和X2,有n行数据,这时要产生一个名为“NEW”的新数据集,除包含原变量及其数据外,还要包含新变量Y和X,其中Y=lnY1, X=X1*X2,且要求打印出新数据集,SAS程序如下:DA TA NEW;SET OLD;Y=LOG(YI);X=X1*X2;RUN;PROC PRINT DA TA=NEW;RUN;例8.1.7在'E:\lixiaoyan'下,有数据文件examp8_1_1.SAS7bdat,含有变量age和weight,要在此文件夹下建立新数据集NEW,并计算y=age+weight.程序:LIBNAME SS'E:\lixiaoyan';DATA SS.NEW; /* 建立新数据集*/SET SS.examp8_1_1;y= age+weight; /* 计算y */PROC PRINT DATA=SS.NEW;RUN;结果输出:Obs name age weight height y1 LIMING 23 56 17 792 LIUHUA 25 60 174 853 ZHANGWEI 30 65 165 95练习调用数据集并进行某些计算,打印输出.4. 逻辑语句与循环语句(1)逻辑语句SAS语言中逻辑语句的一般形式为IF conditions THEN command; /*如果conditions满足,执行command ,其中conditions指数据集中某些变量的取值或数据行的序号(如用_N_=1表示第一行)*/ ELSE command; /* 否则执行command*/另外,“ELSE⋯”也可用另一个语句“IF⋯THEN”代替.但当条件表达式较复杂时,使用“ELSE⋯”可以简化程序.如在“THEN”后面要执行多于一个SAS指令,将这些指令写在“DO”和“AND”之间基本形式:IF conditions THEN DO;Command;Command;⋯⋯END;(2)循环语句SAS循环语句以“DO”开始,“END”结束,使用DO语句的主要形式有四种,如下:DO语句的程序格式之一:DO 变量=开始值TO 终值BY步长值;一些SAS语句;END ;如DO I = 1 TO 10;DO I=1 TO k;DO T=0 TO 10 BY 0.5;又如,产生100个服从N(2,16)的随机数并输出结果到指定数据集,用下循环语句实现:DATA RANDOM;DO N=1TO100;X=2+4*RANNOR(1234);OUTPUT;END;PROC PRINT;RUN;结果输出:Obs N X1 1 7.68612 2 6.52423 3 7.6012┄94 94 4.5953995 95 -1.5629896 96 -1.8705997 97 7.4793598 98 -6.7392599 99 8.87999100 100 1.62646DO语句的程序格式之二:DO UNTIL (条件表达式);一些SAS语句;END ;DATA RANDOM;N=0;DO UNTIL (N=100); /*直到N=100为止*/X=2+4*RANNOR(1234);N=N+1;OUTPUT;END;PROC PRINT;RUN;结果输出同上.DO语句的程序格式之三:DO WHILE (条件表达式);一些SA S语句;END ;DATA RANDOM;N=0;DO WHILE (N<100); /* 当 N<100 不满足为止*/X=2+4*RANNOR(1234);N=N+1OUTPUT;END;PROC PRINT;RUN;DO语句的程序格式之四:IF条件表达式THEN DO ;一些SAS语句;END(与do对应);DO WHILE 和DO UNTIL语句中的表达式是用括号括起来的.两种循环程序格式的区别是,对条件表达式的判断位置.DO WHILE是在循环体的开头,而DO UNTIL是在循环体的结束,也就是说DO UNTIL至少执行循环体中一些SAS语句一次.例8.1.8 在统计研究中,经常需要用计算机进行Monte Carlo模拟.下面编写一个SAS 程序,模拟“抛掷硬币1000次,记录并输出正面(Head)数和反面(Tail)数”的随机试验.由于硬币均匀,即每次抛掷中出现正反面概率均为0.5,可用产生(0,1)内均匀分布随机数的方法实现.用HESADS,NTAILS和N分别表示正面数、反面数和总数SAS程序:DATA EXAMP8_1_8;NHEADS=0; NTAILS=0; N=0;DO UNTIL (N=1000); /* 可用“DO N=1 TO 1000;”或“DOWHILE(N<1000)”*/TOSS =RANUNI(-1); /* 产生(0,1)分布随机数函数中,Seed取-1,表示初值与计算机内时钟有关,表示不同时刻执行此程序结果不同*/IF TOSS >0.5THEN NHEADS=NHEADS+1;ELSE NTAILS=NTAILS+1; /* 本行可用“IF TOSS<=0.5 THEN NTAILS=NTALILS+1;代替”*/N=N+1;END;FILE PRINT;PUT'Number of Heads=' NHEADS; /* NHEADS 输出为Number of Heads*/ PUT'Number of Tails=' NTAILS;RUN;结果输出:Number of Heads=525Number of Tails=475注:也可用中文输出,结果如下:PUT'正面次数=' NHEADS;PUT'反面次数=' NTAILS;正面次数=492反面次数=508课堂总结:建立SAS数据集1.程序窗口建立;2.利用外部文件建立;3.调用已有SAS数据库文件建立数据集.要求:掌握建立SAS数据集的方法作业:补充练习。