SAS系统和数据分析SAS数据集的编辑
- 格式:doc
- 大小:305.50 KB
- 文档页数:11
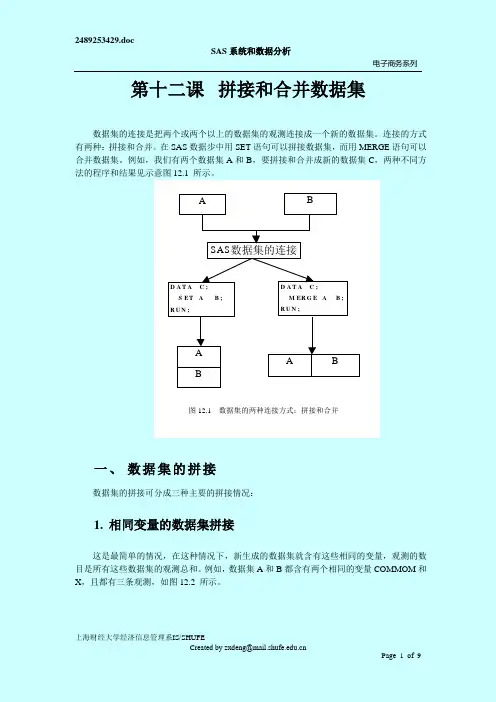
第十二课 拼接和合并数据集数据集的连接是把两个或两个以上的数据集的观测连接成一个新的数据集。
连接的方式有两种:拼接和合并。
在SAS 数据步中用SET 语句可以拼接数据集,而用MERGE 语句可以合并数据集。
例如,我们有两个数据集A 和B ,要拼接和合并成新的数据集C ,两种不同方法的程序和结果见示意图12.1 所示。
一、 数据集的拼接数据集的拼接可分成三种主要的拼接情况:1. 相同变量的数据集拼接这是最简单的情况,在这种情况下,新生成的数据集就含有这些相同的变量,观测的数目是所有这些数据集的观测总和。
例如,数据集A 和B 都含有两个相同的变量COMMOM 和X ,且都有三条观测,如图12.2 所示。
A BSAS 数据集的连接D A T A C ; S ET A B ;R U N ;D A T A C ;M ER G E A B ;R U N ;A BA B图12.1 数据集的两种连接方式:拼接和合并DATA A DATA B OBS COMMON X OBS COMMON X 198011198014 298022298025 398033398036图12.2 含有相同的变量COMMOM和X的两个数据集用下面程序生成新数据集C有两个相同的变量COMMOM和X,6条观测。
Data A;Input common x ;Cards ;9801 19802 298033Data B ;Input common x ;Cards ;980149802598036Data C ;Set A B ;Proc print data=C;Run;拼接生成的新数据集C的结果如图12.3所示。
图12.3 相同变量的数据集拼接结果2.不相同变量的数据集拼接如果两个数据集A和B含有的变量不完全相同,如上例中数据集B含有的不是COMMON 和X变量而是COMMON和Y变量,如图12.4所示。
用SET语句拼接A和B数据集后,新生成的数据集C就含有三个变量COMMON、X和Y,观测的数目仍然是所有这些数据集的观测总和,但原数据集中没有的变量在拼接后新数据集中为缺失值。

如何使用SAS进行数据分析数据分析在现代社会中变得越来越重要。
从业务领域到学术研究,许多领域都需要对大量数据进行分析和解释。
数据分析可以让人们更了解他们的业务、客户和市场,以及发现潜在的趋势和模式。
在这个过程中,数据处理和统计软件起着至关重要的作用。
SAS就是一个被广泛使用的数据处理和统计工具包。
在本文中,我们将深入了解如何使用SAS进行数据分析。
1. 数据准备数据准备是进行数据分析的首要任务。
数据准备包括数据清洗、转换、选取和缺失值处理。
SAS提供了众多命令和函数,可以轻松地进行数据准备工作。
除此之外,SAS还提供了一个方便的用户界面,SAS Enterprise Guide,可以帮助用户快速准确地进行数据处理。
2. 描述性分析描述性分析是对数据进行初步分析的过程。
在这个过程中,对数据的各种属性进行了解和描述,包括数据的集中趋势、分散趋势和分布形状。
SAS提供了多种统计方法和图形工具,可以帮助用户更轻松地进行描述性分析。
例如,PROC UNIVARIATE和PROC MEANS命令可以计算数据的平均值、标准差、最值和百分位数等统计数据,并输出相应的表格和图形。
此外,图形工具包括直方图、箱形图和散点图等,可以帮助用户更形象地理解数据的分布情况。
3. 探索性分析探索性分析是深入了解数据的过程。
在这个过程中,用户将使用多种方法和技术来探索数据之间的关系和可视化。
SAS提供了多种探索性分析工具。
PROC CORR和PROC REG命令可以帮助用户计算两个或多个变量之间的相关系数和回归系数,并绘制相关图形。
PROC FACTOR和PROC PRINCOMP命令可以帮助用户进行因子分析和主成分分析等多变量分析。
此外,SAS还提供了交互式可视化工具,如SAS Visual Analytics和SAS Visual Statistics,可以帮助用户更方便快速地进行探索性分析。
4. 统计建模在对数据进行描述性分析和探索性分析后,用户可以利用统计建模技术进行预测和分类分析。


第一课SAS系统简介一、SAS系统1.SAS系统的功能SAS系统是大型集成应用软件系统,具有完备的以下四大功能:●数据访问●数据管理●数据分析●数据呈现它是美国软件研究所(SAS Institute Inc.)经多年的研制于1976年推出。
目前已被许多国家和地区的机构所采用。
SAS系统广泛应用于金融、医疗卫生、生产、运输、通信、政府、科研和教育等领域。
它运用统计分析、时间序列分析、运筹决策等科学方法进行质量管理、财务管理、生产优化、风险管理、市场调查和预测等等业务,并可将各种数据以灵活多样的各种报表、图形和三维透视的形式直观地表现出来。
在数据处理和统计分析领域,SAS系统一直被誉为国际上的标准软件系统。
2.SAS系统的支持技术在当今的信息时代中,如何有效地利用业务高度自动化所产生的巨量宝贵数据,挖掘出对预测和决策有用的信息,就成为掌握竞争主导权的关键因素。
因此,SAS系统始终致力于应用先进的信息技术和计算机技术对业务和历史数据进行更深层次的加工。
经过二十多年的发展,SAS系统现在是以下三种技术的主要提供者:●数据仓库技术(Data Warehouse)数据仓库是用于支持管理决策过程的面向主题的、集成的、随时间而变化的、持久的(非易失的)数据集合。
通俗地说,可以将数据仓库理解为“将多个生产数据源中的数据按一定规则统一集中起来,并提供灵活的观察分析数据手段,从而为企业制定决策提供事实数据的支持”。
数据仓库最大的用途是能够提供给用户一种全新的方式从宏观或微观的角度来观察多年积累的数据,从而使用户可以迅速地掌握自己企业的经营运转状况、运营成本、利润分布、市场占有率、发展趋势等对企业发展和决策有重要意义的信息,使用户能制定更加准确科学的决策迅速对市场做出反应。
利用数据仓库技术可以使大企业运作的像小企业一样灵活,也可以使小企业像大企业一样规范。
从目前情况来看,许多企业和机构已经建立了相对完善的生产数据库系统。

使用SAS进行数据处理和分析第一章:简介数据处理和分析是现代社会中重要的技能之一,它帮助我们从大量的数据中提取有用的信息,并做出科学决策。
SAS(Statistical Analysis System)是一种功能强大的统计分析软件包,广泛应用于各个领域的数据处理和分析任务中。
本文将介绍SAS的基本功能和常用技术,帮助读者了解如何使用SAS进行数据处理和分析。
第二章:SAS的基本操作SAS具有友好的图形用户界面和强大的命令行功能,可以满足不同用户的需求。
在本章中,我们将介绍SAS的基本操作,包括启动SAS软件、创建和保存数据集、导入和导出数据、运行SAS程序等。
通过学习这些基本操作,读者将能够掌握SAS的基本使用方法。
第三章:数据预处理数据预处理是数据分析的第一步,它包括数据清洗、数据变换、数据归一化等过程。
在本章中,我们将介绍如何使用SAS进行数据预处理,包括缺失值处理、异常值处理、去重、数据变换等技术。
通过学习这些技术,读者将能够清洗和准备好用于分析的数据。
第四章:基本统计分析统计分析是数据处理和分析的核心部分。
在本章中,我们将介绍SAS中常用的统计分析方法,包括描述统计分析、推断统计分析、多元统计分析、回归分析等。
通过学习这些统计分析方法,读者将能够对数据进行全面的分析,并得出科学的结论。
第五章:高级统计分析除了基本的统计分析方法外,SAS还提供了许多高级的统计分析技术,包括因子分析、聚类分析、判别分析、时间序列分析等。
在本章中,我们将介绍这些高级统计分析技术的基本原理和应用方法,帮助读者更好地理解和应用这些技术。
第六章:数据可视化数据可视化是数据分析中的重要环节,它能够帮助我们更直观地理解数据的特征和规律。
在本章中,我们将介绍SAS中常用的数据可视化技术,包括柱状图、折线图、散点图、箱线图等。
通过学习这些数据可视化技术,读者将能够使用图表和图形展示数据的特征和规律。
第七章:模型建立与评估在数据分析中,我们常常需要建立模型来解释和预测数据。
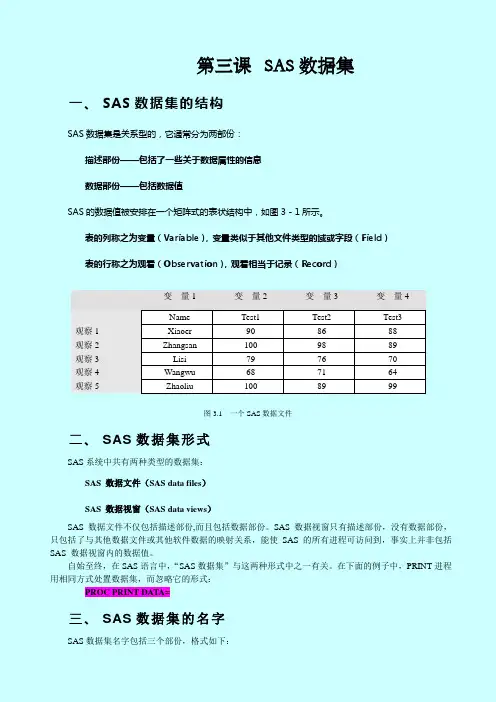
第三课SAS数据集一、SAS数据集的结构SAS数据集是关系型的,它通常分为两部份:描述部份——包括了一些关于数据属性的信息数据部份——包括数据值SAS的数据值被安排在一个矩阵式的表状结构中,如图3-1所示。
表的列称之为变量(Variable),变量类似于其他文件类型的域或字段(Field)表的行称之为观看(Observation),观看相当于记录(Record)变量1 变量2 变量3 变量4Name Test1 Test2 Test3 观察1 Xiaoer 90 86 88观察2 Zhangsan 100 98 89观察3 Lisi 79 76 70观察4 Wangwu 68 71 64观察5 Zhaoliu 100 89 99图3.1 一个SAS数据文件二、SAS数据集形式SAS系统中共有两种类型的数据集:SAS 数据文件(SAS data files)SAS 数据视窗(SAS data views)SAS 数据文件不仅包括描述部份,而且包括数据部份。
SAS 数据视窗只有描述部份,没有数据部份,只包括了与其他数据文件或其他软件数据的映射关系,能使SAS的所有进程可访问到,事实上并非包括SAS 数据视窗内的数据值。
自始至终,在SAS语言中,“SAS数据集”与这两种形式中之一有关。
在下面的例子中,PRINT进程用相同方式处置数据集,而忽略它的形式:PROC PRINT DATA=三、SAS数据集的名字SAS数据集名字包括三个部份,格式如下:(库标记)──这是SAS数据库的逻辑名字data-set-name(数据集名字)──这是SAS数据集的名字membertype(成员类型)──SAS数据集名字的这一部份用户使历时没必要给出。
SAS 数据文件的成员类型是DATA;SAS数据视窗的成员类型是VIEW例如,上面例子中的那个SAS数据集名字,aaa是库标记,abc是数据集名字,成员类型没有写出,应该是DATA或VIEW中的一个。

第四课SAS数据库一、SAS数据库(SAS data library)的成员一个目录里的所有SAS文件都是一个SAS数据库(SAS data library)的成员。
一个目录可以包含外部文件(非SAS文件)以及SAS文件,但只有这些SAS文件才是SAS数据库的成员。
SAS数据库是一个逻辑概念,没有物理实体。
图4.1描述了SAS数据库、SAS文件和SAS 文件的元素之间的关系。
注意,这个库对应于主机操作系统的一个目录,而SAS文件对应于目录内的一个文件。
图4.1 在SAS数据库中的成员类型例如,我们前面定义的Study永久库就是一个SAS数据库,对应的目录为d:\sasdata\mydir,在此目录内有SAS数据集文件:●Class.sd2(包含两种成员类型DATA和VIEW)●索引文件Class.si2其他SAS文件如用BASE SAS软件的存储程序功能产生的成员类型为:●PROGRAM程序文件SAS的目录是具有成员类型为:●CATALOG的SAS文件此文件用来存储许多称为目录条目(catalog entries)的不同类型的信息,用于SAS系统识别它的结构。
典型地,像BASE SAS软件,如果存储目录条目信息对于处理是必要的话,就自动地存储SAS目录条目,而在其他SAS软件中,用户必须在各个过程中规定这个目录条目,用下面完整的四级名字形式来识别:libref.catalog.entry-name.entry-type(库标记.目录名.条目名.条目类型)。
SAS系统有一些特性帮助你管理目录中的条目,一是CATALOG过程,它是BASE SAS软件中的一个过程;另一个是显示管理的CATALOG窗口。
SAS访问描述器是一个允许用户创建SAS/ACCESS视图的工具,访问描述器的成员类型为:●ACCESS的一些文件我们可以用SAS/ACCESS软件里的ACCESS过程创建它们。
访问描述器描述存储在SAS 系统外部的数据,如一些公开的数据库管理系统(DBMS)中的数据,每个访问描述器保存我们想要访问的有关DBMS文件的必要信息,如它的名字、列名和列类型等。

SAS系统和数据分析输入输出格式SAS(Statistical Analysis System)是一种用于数据分析的软件系统,它可以用于数据处理、统计建模、数据挖掘、报告生成等多个方面。
SAS系统提供了一套完整的数据分析工具和功能,使得用户可以方便地进行数据处理和分析工作。
在SAS系统中,数据的输入和输出格式对于数据分析是至关重要的。
正确的输入格式可以确保数据能够被正确地导入到SAS系统中进行分析,而输出格式则决定了分析结果的呈现方式和使用方式。
对于文本文件的输入,SAS系统可以通过DATA步骤或者PROC IMPORT 过程来导入数据。
在DATA步骤中,用户可以使用INFILE语句来指定输入文件路径和参数,然后使用INPUT语句来定义数据的列变量和格式。
PROC IMPORT过程则可以通过对话框或者语句方式导入数据,用户可以选择数据文件、工作表和导入选项。
对于Excel文件的输入,PROC IMPORT过程同样可以很方便地将数据导入到SAS系统中。
在数据输入之后,SAS系统中的数据可以采用两种不同的存储方式,即SAS数据集和SAS视图。
SAS数据集是一种独立于数据源的数据存储方式,它可以被完全加载到存储器中,方便用户进行数据处理和分析。
而SAS视图则是一种基于数据源的虚拟表格,它不占用存储空间,只有在需要数据时才从数据源中获取。
用户可以通过DATA步骤或者PROCSQL语句来创建SAS数据集和SAS视图。
在数据分析之后,SAS系统中的数据可以通过多种方式进行输出。
最常见的输出方式是创建报告和导出结果。
SAS系统提供了PROC REPORT和PROC TABULATE等过程,可以帮助用户根据数据的特点和要求生成不同样式的报告。
用户可以通过对话框或者语句方式设置报告的格式、样式和输出路径。
此外,SAS系统还支持将结果输出到外部文件,例如文本文件、Excel文件、PDF文件等。
用户可以通过DATA步骤或者PROC EXPORT过程将数据导出到指定的文件中。

第六课建立SAS系统的数据集(ASSIST)得到SAS数据集的五种途径●用SAS/ASSIST 通用菜单系统创建数据集●用SAS/FSP系统的FSEDIT过程创建数据集●用SAS数据步(DATA STEP)将外部文件转换为数据集●用SAS/ACCESS系统访问其他数据库●用FILE/IMPORT或EXPORT输入输出数据库其中,如何使用SAS数据步读入外部原始数据文件,并将它们转换为SAS数据集是我们要重点掌握的。
一、用ASSIST通用菜单援助系统创建数据集下面我们通过创建一个SURVEY数据集,并用报表形式显示的例子,来说明SAS/ASSIST 软件的具体的操作步骤。
1.启动SAS/ASSIST软件最简单的方法是单击工具拦上的SAS/ASSIST按钮,或选择菜单命令:●Globals/SAS/ASSIST或在左上角的命令框直接键入Assist并按Enter键,都可启动SAS/ASSIST软件,主菜单如图6.1所示。
共有11个子系统:TUTORIALDA TA MGMT (DA TA Management)REPORT WRITINGGRAPHICSDATA ANAL YSISPLANNING TOOLSEISREMOTE CONNECTRESULTSSETUPINDEX图6.1 SAS/ASSIST软件的主菜单2.选择主菜单中的DATA MGMT(数据管理)项选择主菜单上的DATA MGMT(数据管理)子菜单,如图6.2所示。
图6.2 数据管理的主菜单3.选择CREATE/IMPORT(创建数据集或输入数据)的方法选择CREATE/IMPORT菜单后,提供几种创建数据集的方法供用户选择,如图6.3所示。
假设我们:(1)选择用交互式方法录入数据:图6.3 创建和输入菜单Enter data interactively….(2)选择第二种以表格的形式输入记录的方式图6.4 选择以表格的形式输入记录的方式如图6.4所示,又提供了两种输入观测的方法供用户选择:Enter data one record at a time (一次输入一条记录的方式)和Enter data in tabular form(以表格的形式输入)。

学习使用SAS进行数据处理与分析第一章:介绍SAS及其应用领域SAS(Statistical Analysis System)是由SAS Institute开发的一种统计分析软件。
它是一个功能强大的工具,用于数据处理、数据分析和预测建模等任务。
SAS广泛应用于各个领域,如金融、医疗、市场研究等,可以帮助用户从数据中挖掘有价值的信息。
第二章:SAS环境及基本操作在开始使用SAS之前,我们首先需要了解SAS的运行环境和基本操作。
SAS提供了多种版本,包括SAS Base和SAS Enterprise。
在Windows操作系统上,我们可以通过SAS界面进行操作,也可以通过编写SAS程序进行批量处理。
在本章中,我们将介绍SAS的安装和配置,以及SAS界面和常用的命令。
第三章:数据导入与导出数据导入是数据处理的第一步,也是最重要的一步。
SAS支持导入多种数据格式,如CSV、Excel、Access等。
我们可以使用SAS提供的导入工具,也可以通过编写SAS程序进行导入。
此外,SAS还支持将处理结果导出为各种数据格式,方便与其他软件进行交互。
第四章:数据清洗与转换在实际应用中,原始数据往往存在一些问题,如缺失值、异常值、重复值等。
数据清洗是为了使数据符合分析的要求,需要进行缺失值填充、异常值处理、数据规范化等操作。
SAS提供了丰富的函数和工具,可以方便地进行数据清洗和转换。
第五章:数据探索与可视化数据探索是数据分析的关键步骤之一。
通过统计指标、频率分布、散点图等方式,我们可以了解数据的分布情况、变量之间的关系等。
SAS提供了多种统计分析和可视化功能,如描述统计、相关分析、箱线图、直方图等,可以帮助用户深入了解数据。
第六章:数据建模在数据分析的过程中,我们往往需要基于数据构建一个模型,用于预测或分类。
SAS提供了多种建模技术,包括线性回归、逻辑回归、决策树、支持向量机等。
在本章中,我们将介绍SAS中常用的建模方法和建模步骤,并通过实例演示如何进行模型构建和验证。
如何使用SAS进行统计建模和数据分析章节一:介绍SAS软件和统计建模的基本概念SAS是一个功能强大的统计分析软件,它能够帮助用户进行高效的数据管理、统计建模和数据分析。
本章将介绍SAS软件的特点、优势以及统计建模的基本概念。
1.1 SAS软件的特点和优势SAS具有易学易用、灵活可扩展、高效稳定的特点。
它提供了丰富的数据处理和分析函数,可以处理各种类型和规模的数据。
此外,SAS还具有强大的编程语言,可以根据用户需求进行定制化分析。
1.2 统计建模的基本概念统计建模是一种通过统计学方法对数据进行拟合、预测和推断的过程。
它包括数据预处理、模型选择、参数估计和模型评估等步骤。
统计建模可以帮助用户理解数据背后的规律和关系,并用于预测和决策。
章节二:数据准备和整理在进行统计建模和数据分析之前,首先需要对数据进行准备和整理。
本章将介绍常见的数据准备和整理方法,并演示如何使用SAS实现这些方法。
2.1 数据清洗和缺失值处理数据清洗是指对原始数据进行去除重复值、异常值和错误值等预处理步骤。
缺失值处理是指对数据中的缺失值进行填补或删除。
我们可以使用SAS的数据处理函数和过程来进行数据清洗和缺失值处理。
2.2 数据变换和标准化数据变换是指对数据进行数学变换,以便满足建模和分析的假设前提。
标准化是指将数据按照一定比例转化为均值为0、标准差为1的标准正态分布。
SAS提供了丰富的数据变换和标准化函数,能够满足不同需求。
章节三:统计建模方法和步骤在进行统计建模和数据分析时,需要选择合适的建模方法和步骤。
本章将介绍常见的统计建模方法和步骤,并演示如何使用SAS实现这些方法。
3.1 探索性数据分析(EDA)探索性数据分析是指通过可视化和统计方法来了解和描述数据。
它包括数据可视化、数据摘要和数据分布等分析步骤。
SAS提供了丰富的数据可视化和统计函数,可以帮助用户进行探索性数据分析。
3.2 回归分析和预测建模回归分析是一种用来研究自变量与因变量之间关系的方法。
使用SAS进行统计分析和数据建模的方法1. 引言介绍SAS(统计分析系统), 这是一个广泛使用的统计软件,它提供了丰富的统计分析和数据建模功能。
2. 数据准备描述如何准备数据,包括数据清洗、数据预处理和数据转换等步骤。
3. 描述性统计分析使用SAS进行描述性统计分析,包括计算数据的均值、中位数、方差、标准差等基本统计指标,以及绘制频率分布图、直方图等。
4. 假设检验介绍如何使用SAS进行假设检验,包括t检验、方差分析、卡方检验等常用的统计检验方法。
讲解如何设置假设并根据样本数据判断是否拒绝假设。
5. 回归分析详细说明如何进行回归分析,包括简单线性回归和多元线性回归,介绍如何选择适当的回归模型,并解释模型的结果。
6. 非参数统计介绍如何使用非参数统计方法对数据进行分析,例如Wilcoxon秩和检验、Mann–Whitney U检验和Kruskal-Wallis单因素方差分析等。
7. 因子分析详细讲解如何使用SAS进行因子分析,包括主成分分析和因子旋转等步骤,解释如何提取因子并解释因子的含义。
8. 聚类分析介绍如何使用SAS进行聚类分析,包括层次聚类和K均值聚类方法,讲解如何选择合适的聚类数目并解释聚类结果。
9. 时间序列分析详细描述如何使用SAS进行时间序列分析,包括平稳性检验、ARIMA模型拟合、预测和模型诊断等。
10. 数据挖掘与机器学习介绍如何使用数据挖掘和机器学习方法进行预测和分类,包括决策树、随机森林、逻辑回归和支持向量机等。
11. 模型评估和验证讲解如何评估和验证统计模型的性能,包括拟合优度检验、交叉验证和ROC曲线等。
12. 结论总结使用SAS进行统计分析和数据建模的主要方法和步骤,并强调使用合适的方法来解决实际问题的重要性。
以上是使用SAS进行统计分析和数据建模的一些方法和步骤,虽然每个章节只是简要介绍了相关内容,但在实际应用中,每个章节都有更加详细和深入的讨论和分析。
了解并掌握这些方法和步骤,可以使我们更好地利用SAS进行统计分析和数据建模,为决策提供有力的支持。
如何使用SAS进行数据分析数据分析是现代社会中不可或缺的一项技能。
而SAS(统计分析系统)作为一种广泛应用于商业和学术领域的数据分析工具,为我们提供了许多强大的功能和方法。
在本文中,我将介绍如何使用SAS进行数据分析的基本步骤和技巧,希望能为初学者提供一些帮助。
一、数据准备在开始数据分析之前,首先需要准备好数据。
这包括数据的收集、整理和清洗等步骤。
SAS提供了丰富的数据导入和处理功能,可以方便地从各种数据源中导入数据。
在导入数据时,我们需要确保数据格式正确并进行必要的数据转换和处理。
二、数据探索数据分析的第一步是对数据进行探索。
我们可以使用SAS的统计分析和可视化工具来了解数据的基本特征和分布。
例如,可以使用PROC MEANS来计算数据的平均值、标准差等统计指标,使用PROC FREQ来计算数据的频数和比例,使用PROC UNIVARIATE来进行数据的单变量分析等。
此外,SAS还提供了多种数据可视化方法,如PROC SGPLOT和PROC GPLOT等,可以帮助我们更直观地了解数据的特征。
三、数据预处理在数据分析过程中,往往需要对数据进行预处理。
这包括数据的缺失值处理、异常值处理、变量转换等。
SAS提供了一系列函数和过程来帮助我们完成这些任务。
例如,可以使用PROC MI来处理缺失值,使用PROC TTEST来检测异常值,使用PROC TRANSPOSE来进行变量转换等。
在进行数据预处理时,需要根据具体情况选择适当的方法和技巧。
四、数据建模数据建模是数据分析的核心部分。
在SAS中,我们可以使用PROC REG或PROC LOGISTIC等过程来进行线性回归分析和逻辑回归分析;使用PROC GLM或PROC ANOVA等过程来进行方差分析;使用PROC CLUSTER或PROC FACTOR等过程来进行聚类分析和因子分析等。
选择适当的模型和方法是数据分析的关键,需要根据具体问题和数据特点进行判断。
第四讲:SAS Data步和SAS数据集编辑建立SAS数据集之后,需要对数据集进行必要的编辑。
如删除一些变量或观测、产生新变量等等。
利用SAS的DATA步,通过编程可以灵活的对SAS数据集进行编辑。
§4.1 SAS编程基础1、SAS程序SAS语句:由SAS关键词、SAS名字、特殊字符和运算符组成的字符串,并以分号(;)结尾。
它要求SAS系统执行一个操作或给SAS系统提供信息。
如:data score;proc means;set A;等都是SAS语句,其中的data 、proc、set等都是关键词,score、means、A等为SAS名字。
SAS关键词:除个别语句(赋值语句、累加语句、注释语句和空语句)外,SAS语句都是以关键词开始的,相当于一句话中的动词,告诉SAS要执行什么操作。
如data 关键词告诉SAS要产生一个数据集合。
SAS名字:可以理解为SAS关键词的作用对象。
SAS名字分很多种,如变量名、数据集合名、过程名等。
如语句data score;中的score就是数据集合名,它表明要产生一个临时数据集合score。
SAS名字的命名规则与Window命名规则类似。
例如,第一个字符必须是字母或者下划线、不能出现空格和一些特殊字符($、@、#等),也不能和系统已有的特殊名字重名。
SAS程序:按一定次序排列、并以run;语句结束的一系列语句,具有特定功能。
SAS程序分为两大类:DATA(数据)步和PROC(过程)步。
DATA可以产生一个或多个SAS数据集合,并可以对所创建的集合进行必要的运算和操作。
报表编写、文件管理、信息检索等都在DATA步中完成。
PROC步从SAS系统的过程库中调出过程并执行,执行的对象通常是一个SAS数据集合。
因此,PROC后面紧接的是过程名,然后是对数据集合的指定。
如PROC means data=class;就是对临时数据库(work)中的数据集合class进行描述统计分析。
使用SAS进行数据分析的步骤第一章:引言数据分析是现代商业和科学领域中不可或缺的一部分。
它可以帮助我们从数据中获取有价值的信息和见解,用以支持决策制定和问题解决。
而SAS(Statistical Analysis System)作为一种流行的数据分析工具,被广泛应用于各个领域。
本文将介绍使用SAS进行数据分析的步骤,并以实例来说明每个步骤的具体操作。
第二章:数据准备一个成功的数据分析过程必须以正确的数据准备开始。
首先,收集所需数据,并确保数据的完整性和准确性。
然后,对数据进行清洗和预处理,包括处理缺失值、异常值和重复值等。
接下来,对数据进行变量选择和变换,以便更好地适应后续的分析需求。
第三章:探索性数据分析在进行正式的统计分析之前,我们需要对数据进行探索性分析,以了解数据的基本特征和潜在关系。
这包括计算和绘制描述性统计指标,如均值、中位数、方差等,以及创建图表和图形,如直方图、散点图、箱线图等。
通过这些分析,我们可以对数据的分布、相关性和异常情况有一个初步的了解。
第四章:假设检验当我们想要通过数据来验证一个假设时,可以使用假设检验进行统计分析。
首先,我们需要明确研究的问题和假设,并选择适当的假设检验方法。
然后,我们将数据导入SAS,并根据所选的假设检验方法进行相应的计算和分析。
最后,根据分析结果来判断是否拒绝或接受原假设。
第五章:建立模型在一些情况下,我们希望通过建立数学模型来解释和预测数据。
在SAS中,我们可以使用线性回归、逻辑回归、时间序列分析等方法来建立模型。
首先,我们需要选择适当的变量和模型类型。
然后,我们可以使用SAS的建模工具来进行变量筛选、模型拟合和验证。
最后,我们可以评估模型拟合的好坏,并通过模型预测来进行决策支持。
第六章:结果解释和报告当我们完成数据分析时,需要将结果进行解释和报告,以便他人理解和使用。
首先,我们需要对分析结果进行解释,包括各个变量的作用和解释、模型的拟合程度、假设检验的结论等。
sas处理流程SAS处理流程SAS是一种常用于数据分析和统计建模的软件,其处理流程主要分为数据准备、数据清洗、数据分析和模型建立四个步骤。
以下将详细介绍每个步骤的具体流程。
1. 数据准备数据准备是SAS处理流程的第一步,其目的是将原始数据转化为可进行后续处理的数据格式。
具体而言,数据准备包括数据导入、数据格式转换、数据合并和数据拆分等操作。
其中,数据导入是将原始数据从外部文件中导入到SAS中,常见的数据格式包括Excel、CSV、XML等。
数据格式转换是将数据转化为SAS可以识别的格式,如将日期格式转换为SAS日期格式、将字符型变量转换为数值型变量等。
数据合并是将两个或多个数据集合并成一个数据集,常见的合并方式有追加、合并和交叉等。
数据拆分是将一个数据集拆分为多个数据集,常见的拆分方式有随机抽样、分层抽样和分组抽样等。
2. 数据清洗数据清洗是SAS处理流程的第二步,其目的是检查和修复数据中的错误和异常值,以确保数据的质量和准确性。
数据清洗包括缺失值处理、异常值处理、重复值处理和数据类型检查等操作。
其中,缺失值处理是检查和处理数据中的缺失值,常见的处理方法有删除、替换和插值等。
异常值处理是检查和处理数据中的异常值,常见的处理方法有删除、替换和离群点检测等。
重复值处理是检查和处理数据中的重复值,常见的处理方法有删除和合并等。
数据类型检查是检查数据的类型是否正确,如数值型变量是否为数值型、字符型变量是否为字符型等。
3. 数据分析数据分析是SAS处理流程的第三步,其目的是对数据进行各种分析和统计建模,以发现数据中的规律和趋势。
数据分析包括统计分析、数据可视化和机器学习等操作。
其中,统计分析是使用各种统计方法对数据进行分析,如描述性统计、假设检验和回归分析等。
数据可视化是将数据转化为可视化图形,以便更直观地了解数据的分布和趋势,常见的可视化图形有散点图、直方图和饼图等。
机器学习是使用机器学习算法对数据进行建模和预测,常见的算法有决策树、支持向量机和神经网络等。
第十一课SAS数据集的编辑通常从外部数据源转换得到SAS数据集后,并不是所有的数据集都满足统计数据要求,可立即调用统计过程进行统计分析。
需要对数据集进行满足统计数据要求的编辑或生成新的数据集。
一、增加数据集一个新变量SAS系统可通过赋值语句把包含操作符的表达式赋值给数据集所要创建的新变量。
SAS 的表达式中还可以包含SAS函数,如一些常用的SAS函数见下表:函数分类常用函数功能数学运算函数ABS( ) 取绝对值SQRT( ) 求平方根INT( ) 取整数部分EXP( ) 计数e的次幂LOG( ) 求e为底的自然对数SIN( ) 计算正弦LAGn( ) 求给定变量滞后为n的值统计计算函数MAX( ) 求最大值MIN( ) 求最小值MEAN( ) 求平均值SUM( ) 求和DIFn( ) 求给定变量X的第n阶差STD( ) 求标准差PROBNORM( ) 标准正态分布函数日期时间处理函数DA TE( )/TODAY()取当日的日期值DAY( ) 计算某月的那一日HOUR( ) 计算小时TIME( ) 取当日的时间YEAR( ) 取年值字符函数INDEX( ) 搜寻字符串的位置LEFT( ) 字符串表达式左对齐SUBSTR( ) 抽取子字符串TRIM( ) 移走尾部空格LENGTH( ) 给出字符变量的长度UPCASE( ) 转换为大写财政金融函数COMPOUND( ) 计算复利IRR( ) 计算内部赢利率NPV( ) 计算净现值SA VING( ) 计算定期储蓄的本金和利息例如,有一个学生成绩数据集中的数据来源写在CARDS语句后,但我们还需产生新的变量平均分和总分,数据步的程序如下:Data class2 ;Input id test1-test5 ;average=mean(test1,test2,test3,test4,test5);total=test1+test2+test3+test4+test5;Cards ;980801 100 100 100 100 100980802 90 100 90 100 90980803 81 82 83 84 85Proc print data=class2 ;Run ;在OUTPUT窗口中显示的运行结果见图11.1所示。
图11.1 用赋值表达式创建数据集的新变量二、选择数据集的变量和观测数据库的三种基本操作是选择、投影和连接,如果我们把数据库看成是一张表格,选择和投影操作相当于从一张大的数据库表格中挑选所需的行和列形成一张小的数据库表格。
连接操作相当于把两张或两张以上的数据库表格按某种规则合并成一张数据库表格。
原始数据库表格可以是外部数据文件(用INFILE语句输入),或在作业流中(用CARDS语句输入),或来自其他SAS数据集(用SET语句输入)。
1.选择变量(即选择列)使用DATA语句的DROP=和KEEP=选项可以控制从原始数据库中读出的变量是否被写入将要创建的数据集。
例如,假设我们要从CLASS2数据集中产生只包含ID、A VERAGE和TOTAL变量,而不包含TEST1、TEST2、TEST3、TEST4、TEST5变量的新数据集CLASS3。
有两种程序编法都能达到相同的目的,一是使用DATA语句的DROP=选项,表示从原有变量中去掉DROP=中指明的变量;二是使用DA TA语句的KEEP=选项,表示从原有变量中只保留KEEP=中指明的变量。
程序如下:程序一:Data class3 (drop=test1 test2 test3 test4 test5 ) ;Set class2;Proc print data=class3 ;Run;程序二:Data class3 ( keep=id average total ) ;Set class2 ;Proc print data=class3 ;Run ;程序一和程序二的运行结果相同。
在OUTPUT窗口中显示的运行结果如图11.2所示。
图11.2 对数据集用DROP或KEEP进行变量选择2.选择观测(即选择行)选择满足条件的记录行来形成新的数据集,可使用DATA步的IF语句,IF语句的作用就像一个过滤网,IF语句中的条件表达式就像过滤网的形状,只允许符合条件表达式的记录行通过,如果条件表达式恒为真,意味着过滤网是空的,让所有的记录行通过。
对于不符合条件的记录行不作任何处理,直接回到数据步的顶部再将下一条记录来通过过滤网。
如果在条件语句IF中使用了DELETE语句,则可以控制哪些记录行不被写入将要创建的新数据集。
在条件表达式中要使用到比较操作符和逻辑操作符,SAS系统的比较操作符如下表所示:操作符符号意义LT < 小于(Less Than)GT > 大于(Greater Than)EQ = 等于(Equal)LE <= 小于等于(Less Equal)GE >= 大于等于(Greater Equal)NE ^= 不等于(Not Equal)IN 等于列举中一个SAS系统的逻辑操作符如下表所示:操作符符号意义AND & 与OR | 或NOT ^ 非请注意在条件表达示中使用上面两个表中的操作符或符号是等价的,特别要注意的是在一个复杂的条件表达式中可能同时包含算数运算符(+ - * / **)、比较操作符和逻辑操作符,此时运算的优先次序为括号、算数运算符、比较操作符和逻辑操作符。
下面的三个DATA步程序是从同一个数据集CLASS2中,按不同的条件表达式选择记录行形成新的数据集CLASS4,结果相同。
程序一:Data class4 ;Set class2 ;if total ge 450 ;Proc print data=class4 ;Run ;程序二:Data class4 ;Set class2 ;if total lt 450 then delete;Proc print data=class4 ;Run ;程序三:Data class4 ;Set class2;if average>=80 and 100 in (test1,test2,test3,test4,test5) ;Proc print data=class4 ;Run ;运行结果如图11.3 所示。
第十二课程序三中的IF语句条件表达式图11.3 用IF条件语句选择数据集中的观测等价于IF average>=80 and (100=test1 or100=test2 or 100=test3 or 100=test4 or 100=test5),由于AND的优先级比OR的高,与条件表达式IF average>=80 and100=test1 or 100=test2 or 100=test3 or100=test4 or 100=test5是有区别的。
拼接和合并数据集数据集的连接是把两个或两个以上的数据集的观测连接成一个新的数据集。
连接的方式有两种:拼接和合并。
在SAS数据步中用SET语句可以拼接数据集,而用MERGE语句可以合并数据集。
例如,我们有两个数据集A和B,要拼接和合并成新的数据集C,两种不同方法的程序和结果见示意图12.4 所示。
一、 数据集的拼接数据集的拼接可分成三种主要的拼接情况:1. 相同变量的数据集拼接这是最简单的情况,在这种情况下,新生成的数据集就含有这些相同的变量,观测的数目是所有这些数据集的观测总和。
例如,数据集A 和B 都含有两个相同的变量COMMOM 和X ,且都有三条观测,如图12.5 所示。
用下面程序生成新数据集C 有两个相同的变量COMMOM 和X ,6条观测。
Data A ;Input common x ;A BSAS 数据集的连接D A T A C ; S ET A B ;R U N ;D A T A C ;M ER G E A B ;R U N ;A BA B图12.4 数据集的两种连接方式:拼接和合并O BS CO MMO NX O BS CO MMO NX198011198014298022298025398033398036DATA A DATA B图12.5 含有相同的变量COMMOM 和X 的两个数据集Cards ;9801 19802 298033Data B ;Input common x ;Cards ;980149802598036Data C ;Set A B ;Proc print data=C;Run;拼接生成的新数据集C的结果如图12.6所示。
图12.6 相同变量的数据集拼接结果2.不相同变量的数据集拼接如果两个数据集A和B含有的变量不完全相同,如上例中数据集B含有的不是COMMON 和X变量而是COMMON和Y变量,如图12.7所示。
用SET语句拼接A和B数据集后,新生成的数据集C就含有三个变量COMMON、X和Y,观测的数目仍然是所有这些数据集的观测总和,但原数据集中没有的变量在拼接后新数据集中为缺失值。
DATA A DATA BO BS CO MMO N X O BS CO MMO N Y198011198014298022298025398033398036图12.7 含有不相同的变量X和Y的两个数据集生成新数据集C的程序如下:Data C;Set A B ;Proc print data=C ;Run ;拼接生成的新数据集C的结果如图12.8所示。
图12.8 不相同变量的数据集拼接结果3.按关键字排序后拼接数据集如果要求新生成的数据集C按共同的关键字例如COMMON排序观测,那么预先要数据集A和B也已按COMMON关键字排序好,可通过排序过程PROC SORT 和BY指明关键字。
生成新数据集C的程序如下:Proc sort data= A;By Common ;Proc sort data= B ;By Common ;Data C;Set A B ;By Common ;Proc print data=C ;Run ;拼接生成的新数据集C的结果如图12.9所示。
图12.9 按关键字排序后拼接的数据集结果无论哪一种拼接形式,用SET语句拼接生成的新数据集的观测总数为原各输入数据集观测数之和。
二、数据集的合并数据集的合并是通过使用MERGE语句把两个或两个以上数据集中的两条观测或两条以上的观测合并为新生数据集中的一条观测。
数据集的合并可分成两种主要的合并情况:●一对一合并(不带BY语句)●匹配合并(带有BY语句)1.一对一合并(不带BY语句)把一个数据集中的第一条观测同另外一个数据集中第一条观测合并,第二条观测同另外一个数据集中第二条观测合并,以此类推。