第四章 完全信息动态博弈的基本理论(新)
- 格式:doc
- 大小:228.00 KB
- 文档页数:8



完全信息动态博弈模型完全信息动态博弈模型是博弈论中一种重要的博弈模型,它描述了一组参与者在了解所有相关信息的情况下,通过一系列决策和行动来实现最优化的结果。
下面将详细介绍完全信息动态博弈模型的相关内容。
一、博弈的参与者:完全信息动态博弈模型中,通常包括两个或多个参与者,每个参与者都可以做出自己的决策和行动。
参与者可以是个人、组织、公司等,他们之间存在着相互竞争和合作的关系。
二、博弈的信息:完全信息动态博弈模型中的参与者拥有完全信息,即每个参与者都能够获得关于其他参与者的决策和行动的完整信息。
通过完全信息,参与者能够准确地评估自己的决策和行动对其他参与者的影响,并作出最优化的决策。
三、博弈的行动和策略:在完全信息动态博弈中,参与者可以选择不同的行动和策略来达到自己的目标。
每个参与者根据自己对其他参与者行动和策略的评估,以及自己的目标和利益,选择最优化的行动和策略。
四、博弈的时间顺序:完全信息动态博弈是一个时间序列上的博弈模型,参与者的决策和行动是有序进行的。
参与者按照一定的时间顺序依次进行决策和行动,每个参与者都会考虑前面参与者的行动和决策对自己的影响,进而作出自己的决策。
五、博弈的结果和收益:完全信息动态博弈模型的结果是参与者的收益和利益。
通过多轮反复的博弈过程,参与者根据自己的决策和行动可以获得不同的结果和收益。
每个参与者的最终目标是通过优化自己的决策和行动,获得最大的收益和利益。
完全信息动态博弈模型是博弈论中一种重要的模型,它能够帮助我们分析和理解多方参与者在了解所有相关信息的情况下,通过一系列决策和行动来实现最优化的结果。
通过对博弈的参与者、信息、行动和策略、时间顺序以及结果和收益的分析,可以更好地理解和应用完全信息动态博弈模型。


博弈论——完全信息动态博弈2 完全信息的动态博弈2.1完全和完美信息的动态博弈动态博弈(dynamic game):参与⼈在不同的时间选择⾏动。
完全信息动态博弈指的是各博弈⽅先后⾏动,后⾏动者知道先⾏动者的具体⾏动是什么且各博弈⽅对博弈中各种策略组合下所有参与⼈相应的得益都完全了解的博弈静态博弈习惯⽤战略式(Strategic form representation)表述,动态博弈习惯⽤扩展式(Extensive form representation)表述。
战略式表述的三要素:参与⼈集合、每个参与⼈的战略集合、由战略组合决定的每个参与⼈的⽀付。
扩展式表述的要素包括:参与⼈集合、参与⼈的⾏动顺序、参与⼈的⾏动空间、参与⼈的信息集、参与⼈的⽀付函数、外⽣事件(⾃然的选择)的概率分布。
n⼈有限战略博弈的扩展式表述⽤博弈树来表⽰1(1,2) (0,3)①结:包括决策结和终点结。
决策结是参与⼈采取⾏动的时点,终点结是博弈⾏动路径的终点。
第⼀个⾏动选择对应的决策结为“初始结”,⽤空⼼圆表⽰,其它决策结⽤实⼼圆表⽰。
X表⽰结的集合,x X表⽰某个特定的结。
z表⽰终点结,Z表⽰终点结集合。
表⽰结之间的顺序关系,x x′表⽰x在x′之前。
x之前所有结的集合称为x的前列集,x之后所有结的集合称为x的后续集。
以下两种情况不允许:前者违背了传递性和反对称性;后者违背了前列节必须是全排序的。
在以上两个假设之下,每个终点结都完全决定了博弈树的某个路径。
②枝:博弈树上,枝是从⼀个决策结到其直接后续结的连线,每⼀个枝代表参与⼈的⼀个⾏动选择。
在每⼀个枝旁标注该具体⾏动的代号。
⼀般地,每个决策结下有多个枝,给出每次⾏动时参与⼈的⾏动空间,即此时有哪些⾏动可供选择。
③信息集(information sets):博弈树中某⼀决策者在某⼀⾏动阶段具有相同信息的所有决策结集合称为⼀个信息集。
博弈树上的所有决策结分割成不同的信息集。
每⼀个信息集是决策结集合的⼀个⼦集(信息集是由决策结构成的集合),该⼦集包括所有满⾜下列条件的决策结:(1)每⼀个决策结都是同⼀个参与⼈的决策结。





1第四章 完全信息动态博弈及其均衡解1.完全且完美信息动态博弈完全信息博弈指的是参与者的收益是共同知识。
完全且完美信息动态博弈指的是:博弈中的每一步中参与人都知道这一步之前博弈进行的整个过程。
因此,我完全且完美信息动态博弈的特点:(1)行动是顺序发生的;(2)下一步行动选择之前所有以前的行动都可以被观察到;(3)每一可能的行动组合下的参与人的收益都是公共知识。
而不完美信息博弈指的是,在某一步参与人不知道以往博弈所进行的历史或者没有观察到以往的所有行动。
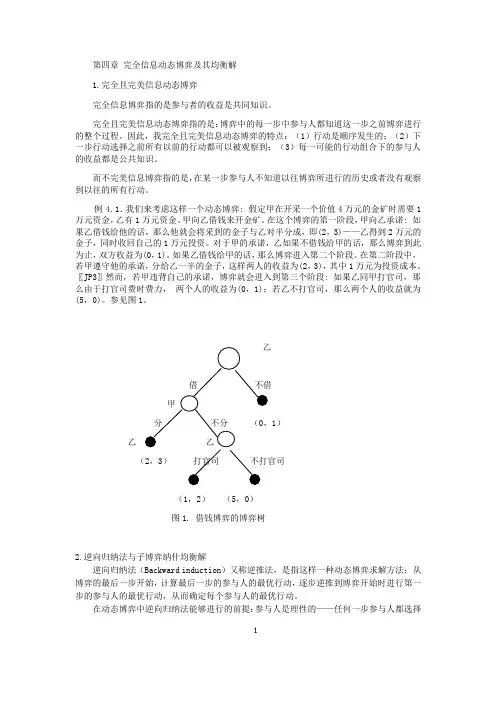
例4.1.我们来考虑这样一个动态博弈: 假定甲在开采一个价值4万元的金矿时需要1万元资金,乙有1万元资金。
甲向乙借钱来开金矿。
在这个博弈的第一阶段,甲向乙承诺: 如果乙借钱给他的话,那么他就会将采到的金子与乙对半分成,即(2,3)——乙得到2万元的金子,同时收回自己的1万元投资。
对于甲的承诺,乙如果不借钱给甲的话,那么博弈到此为止,双方收益为(0,1)。
如果乙借钱给甲的话,那么博弈进入第二个阶段。
在第二阶段中,若甲遵守他的承诺,分给乙一半的金子,这样两人的收益为(2,3),其中1万元为投资成本。
〖JP3〗然而,若甲违背自己的承诺,博弈就会进入到第三个阶段: 如果乙同甲打官司,那么由于打官司费时费力, 两个人的收益为(0,1);若乙不打官司,那么两个人的收益就为(5,0)。
参见图1。
乙借 不借甲分 不分 (0,1)乙 乙 (2,3) 打官司 不打官司(1,2) (5,0)图1. 借钱博弈的博弈树2.逆向归纳法与子博弈纳什均衡解逆向归纳法(Backward induction )又称逆推法,是指这样一种动态博弈求解方法:从博弈的最后一步开始,计算最后一步的参与人的最优行动,逐步逆推到博弈开始时进行第一步的参与人的最优行动,从而确定每个参与人的最优行动。
在动态博弈中逆向归纳法能够进行的前提:参与人是理性的——任何一步参与人都选择甲乙2最优策略;理性是公共知识——参与人选择最优策略是其他人所能够预测的。
完全信息动态博弈模型完全信息动态博弈模型是博弈论中的一种重要模型,它描述了参与者具有完全信息(即对所有相关信息都有准确了解)的情况下进行的博弈过程。
在该模型中,参与者能够观察其他人的行为和选择,并根据这些观察作出自己的决策。
在完全信息动态博弈模型中,博弈过程分为多个阶段。
每个参与者在每个阶段都必须做出自己的决策,而后续的决策将依赖于先前的决策。
参与者可以根据观察到的其他人的行为和选择来调整自己的策略。
这种博弈模型特别适用于描述多个参与者之间具有时间序列关系的情况,如竞价拍卖、价格战等。
完全信息动态博弈模型可以用博弈树来表示。
博弈树由一系列节点和边组成,每个节点表示参与者的决策点,边表示参与者的决策选择。
根节点表示博弈的初始状态,而叶节点表示博弈的终止状态。
在每个节点上,参与者根据其他人的选择和观察到的信息来做出决策。
通过沿着博弈树的边一步一步向下移动,参与者可以在每个阶段根据观察到的信息进行反应和调整。
完全信息动态博弈模型需要考虑的核心概念是策略和均衡。
策略是参与者通过决策选择在每个节点上的行为规则,决定了参与者在每个阶段应该如何行动。
而均衡是一种状态,其中所有的参与者都无法通过单方行动来改善自己的收益。
在完全信息动态博弈模型中,通常存在多个均衡解,其中每个参与者都选择出使自己获得最大收益的策略。
通过建立完全信息动态博弈模型,我们可以分析不同参与者的决策行为和相应结果的演化过程。
通过求解均衡解,我们可以预测在不同情况下各参与者的最佳策略选择,从而为参与者提供决策依据。
此外,完全信息动态博弈模型也可以用于研究不同决策因素对博弈结果的影响,并为参与者提供制定最优策略的指导。
总之,完全信息动态博弈模型是博弈论中重要的一个模型,它描述了参与者具有完全信息的情况下进行的博弈过程。
通过建立博弈树、分析策略和求解均衡解,我们可以预测参与者的决策行为和相应结果的演化,并提供决策指导。
这种模型对于研究多个参与者之间具有时间序列关系的博弈情况非常有用,为决策者提供了重要的参考和指导。
第四章 完全信息动态博弈的基本理论一.回顾如何用标准型表述、刻画博弈?回顾如何用扩展型表述、刻画博弈?二.信息集1.观察下列两个扩展型博弈在结构上有什么区别?2.参与人i 的信息集是指由这样一些决策节点组成的集合,第一,i 的信息集中每个节点都是i 的决策节点,即如果博弈进行到这一步,轮到i 行动;第二,当博弈到达i 的某个信息集,参与人i 并不知道自己究竟已经到了信息集中的哪个节点。
3.对信息集的进一步理解A 信息集用于表示博弈参与人在轮到他行动时所掌握的信息。
B 信息集定义的第二点意味着在同一个信息集的节点有着相同的可行的行动集(思考:为什么?)。
C 同一个信息集的节点不能相互构成前续节点与后续节点的关系。
4.思考:画出下列博弈的博弈树或扩展型表示。
第一步,参与人甲从行动集(L ,R )中进行选择;第二步,参与人乙观察到参与人甲的行动选择后从自己的行动集(M ,N )中进行选择;最后一步,参与人甲只能观察到过去的选择是否是(R ,N ),并从行动集(V ,W )中进行选择。
5.完全完美信息(complete and perfect )博弈与完全不完美信息(complete and imperfect)博弈(1)完全信息与不完全信息:区分完全信息与否的标准就看每个博弈参与人的支付函数是否是博弈的公共知识。
(2)完美信息与不完美信息:区分完美信息与否的标准就看该博弈的每个信息集是否都是单点的(singleton )。
完美信息意味着该博弈的每个信息集都是单点集。
思考:完美信息博弈意味着博弈参与人对所参与的博弈究竟知道些什么?意味着在博弈的每个行动时刻轮到行动的参与人知道博弈迄今为止的全部历史。
夫夫(3)不完全信息也意味着不完美信息;完美信息必定也是完全信息的。
三.行动(action )与策略1.在博弈的扩展型表示中,每个决策节点的一根“树枝”就代表着该参与人在此时的一个可供选择的行动。
2.参与人i 的策略是指参与人i 的一个完整的行动计划,即它规定了参与人i 在每一个要求他行动的contingency 之下所采取的可行的行动,即参与人i 在每一个要求他行动的信息集之下所采取的可行的行动。
3.思考:写出动态夫妻博弈中夫妻双方的所有策略。
4.思考:为什么参与人的策略必须对似乎好不可能出现的博弈情形也规定如何选择行动?因为不这么做,就无法找出参与人针对对手策略的最优反应以及运用纳什均衡。
四.完全信息静态博弈与完全信息动态博弈的标准型表示与扩展型表示1.思考:如何用扩展型表示囚徒困境与静态夫妻博弈?如何用标准型表示动态夫妻博弈?FF FB BB BF2.结论与启示:(1)任何博弈既可以用标准型表示,也可以用扩展型表示;不过,标准型更适合表示静态博弈,扩展型更适合表示动态博弈。
(2)识别静态博弈的真正标准不是物理时间上的同时,而是关于行动的信息,即每个参与人是否知道对手过去的行动选择。
(3)标准型表示与扩展型表示的优点标准型能够清晰地展示出每个参与人的策略集;扩展型能够清晰地展示出参与人在每个博弈阶段的信息状况。
3.求解动态夫妻博弈的纳什均衡并思考:这些纳什均衡之间有哪些不同?您认为哪些纳什均衡是合理的?哪些是不合理的?一个结论与启示:动态夫妻博弈存在多重纳什均衡,其中有些纳什均衡包含着不可信的承诺(commitment ,包括威胁——threat 和允诺——promise 两种形式)。
承诺的可信性是动态博弈的核心问题,由于博弈存在动态结构,于是就可以研究参与人关于未来行为的威胁与允诺对其他参与人当前行为选择的影响。
五.子博弈(subgame )1.子博弈是指始于某个单点信息集上决策节点的所有后续节点,而且不能分割或破坏原博弈的信息结构。
原博弈也是自身的一个子博弈,但本课以后所说的子博弈均是小于原博弈夫 FB的子博弈。
2.找出下列博弈的子博弈(略)。
3.思考:为什么子博弈不能分割或破坏原博弈的信息结构?理由有两条,一是因为一旦破坏了原博弈的信息结构,就无法利用子博弈分析原博弈;二是因为只有这样才能保证该子博弈之前的博弈历史成为所有子博弈参与人的公共知识。
六.子博弈完美(subgame perfect)纳什均衡——完全信息动态博弈的解1.子博弈完美纳什均衡是指这样的一些纳什均衡,该策略组合在每一个子博弈均构成纳什均衡。
2.子博弈完美纳什均衡有助于在完全信息动态博弈中剔除包含不可置信承诺的纳什均衡;它是博弈论对完全信息博弈提出的解概念,是对纳什均衡概念的进一步提炼,这是理性原则在动态博弈中彻底运用的结果。
3.逆向归纳法——寻找子博弈完美纳什均衡的有效方法(1)逆向归纳法(backward induction)的基本做法是从求解最后一个子博弈的纳什均衡开始,不断向后推,直至到初始决策节点,以求解整个博弈的纳什均衡。
以这种方法找出的纳什均衡必定是子博弈完美纳什均衡。
(2)思考完全信息动态博弈的基本思路是:向前展望——以寻找出原博弈的子博弈;向后推理——以求解原博弈。
七.前向归纳法1.如果某博弈是一个更大博弈的一部分,则小博弈的均衡策略就可能依赖于大博弈。
2.前向归纳法(forward induction)(1)例子:博士学习计划(故事略)(2)前向归纳法:参与人通过其他参与人早期的、过去的决策推断出一些信息,以帮助求解动态博弈。
前向归纳法与逆向归纳法之间并没有冲突,而是相互补充。
八.完全信息无限期讨价还价理论1.什么是讨价还价讨价还价是指各方具有共同的合作利益,但对合作利益如何分配却存在分歧。
可以描述为:有一块大小一定的蛋糕要在若干人中间分配,各方就如何分割蛋糕进行讨价还价,每一方都试图最大化自己的蛋糕份额,如果无法达成分配协议,则谁也不能分享这块蛋糕;如果达成了协议,则各方按照协议的规定进行分配。
2.完全信息无限期讨价还价的非合作博弈研究核心成果是Rubinstein的两人无穷期讨价还价博弈,该博弈唯一的子博弈完美均衡结局是:假设蛋糕的大小为 ,参与人风险中性,以及无协议时双方的报酬为0,则双方获得的蛋糕份额为:第一个开价的的人(A )获得:B A B r r r π+,第二个开价的人(B )获得:A A Brr r π+。
这个结论告诉我们:谁相对更加有耐心,谁的讨价还价力量就相对更大;这个结果与纳什讨价还价解等价。
总结与回顾:(1)前面所分析的所有博弈,不论是静态的还是动态的,具有一个共同的特点:所有的博弈都是一次性的。
(2)第二章思考的社会困境解决办法总是求助于外在的强制与约束力量,能否存在其他的解决机制?(3)如果相同的博弈多次重复,是否会因为存在未来惩罚不合作行为与奖励对手合作行为的机会,而有助于博弈各方的合作?九.重复博弈1.重复博弈的一些例子2.重复博弈是指相同的参与人重复地进行相同的博弈,而且在进行某阶段的博弈时,前面所有阶段的博弈结局是所有参与人的公共知识。
这个被重复进行的博弈就被称之为阶段博弈(stage game )。
3.有限重复博弈(0)有限重复博弈:给定阶段博弈G ,G (T )表示阶段博弈G 重复T 次的有限重复博弈,其中第t 次阶段博弈开始时,对全体博弈参与人来说,所有t -1次阶段博弈的结局都是可观测的,是博弈的公共知识。
假设不存在贴现因素,重复博弈G (T )的支付就是所有T 次阶段博弈的支付的简单加总。
(1)情形1:阶段博弈具有唯一的纳什均衡 A 例子甲乙就双方的合作达成了协议,协议订立后双方均面临两个选择:违约或守约。
我们称这个博弈为守约博弈。
博弈问题1:该博弈的纳什均衡是什么?问题2:如果甲乙双方的博弈关系持续两期,也就是说,甲乙两人的守约博弈重复进行两次,请问,该重复博弈的最终结局是什么?乙甲 违约守约B 结论:如果阶段博弈G 有唯一的纳什均衡,那么,对任意的有限次数T ,重复博弈G (T )有唯一的子博弈完美结局(outcome ):在每个博弈阶段,参与人均重复阶段博弈的纳什均衡。
C 进一步的理解:通过上面的例子可以看出,完全信息重复博弈其实也是完全信息动态博弈,故同样使用子博弈完美纳什均衡作为重复博弈的解(值得注意的是,动态博弈本身也是可以重复的)D 思考:为什么说“在每个博弈阶段,参与人均重复阶段博弈的纳什均衡”只是重复博弈的子博弈完美结局,而不说它是子博弈完美均衡?(2)情形2:阶段博弈具有多重(multiple )纳什均衡 A 例子1有阶段博弈如下乙 2L 2M 2R1L甲1M1R问题1:请问阶段博弈的纳什均衡是什么?问题2:如果该阶段博弈重复两次,请问您能否想出一个办法,使得(4,4)这个结局成为第一阶段博弈的子博弈完美结局?结论:如果完全信息阶段博弈G 具有多重纳什均衡,则重复博弈G (T )存在子博弈完美结局:对任意的t<T ,阶段t 的结局不是阶段博弈G 的纳什均衡。
之所以如此,在于阶段博弈的多重纳什均衡为参与人在未来奖励、惩罚对手提供了可信的允诺与威胁,这说明对未来行为的可信的允诺或威胁会对当前的行为产生影响。
B 例子2有阶段博弈如下乙2L 2M 2R 2P 2Q 1L1M 甲 1R1P1Q问题1:上述阶段博弈的纳什均衡是什么?问题2:如果上述阶段博弈重复两次,博弈参与人预期第二阶段的结局如下,如果第一阶段的结局是(1M ,2M ),则第二阶段的结局是(1R ,2R );如果第一阶段的结局是(1M ,w ),其中w 为2M 以外的任何行动选择,则第二阶段的结局是(1P ,2P );如果第一阶段的结局是(x ,2M ),其中x 为1M 以外的任何行动选择,则第二阶段的结局是(1Q ,2Q );如果第一阶段的结局是除上述情形以外的其他情形,则第二阶段的结局为(1R ,2R )。
请问,在上述预期下,重复博弈的子博弈完美结局是什么?问题3:请将例子2的子博弈完美结局与例子1的子博弈完美结局进行比较,看看二者惩罚第一阶段不合作行为的机制有什么不同?或者说,谁的惩罚威胁是更加可信的?结论:可信的承诺应该要求在该承诺之下参与人不存在再协商(renegotiation )的可能或积极性,否则,承诺的可信程度就会大打折扣。
4.无限重复博弈(infinitely repeated game ) (1)无限重复博弈:给定阶段博弈G ,G (∞)表示阶段博弈G 重复无限次的无限重复博弈,其中当前的阶段博弈开始时,所有以前的阶段博弈的结局都是可观测的,是博弈的公共知识。
(2)无限重复博弈中参与人支付的计算A 给定贴现因子δ,无穷支付序列1π,2π,3π……的贴现值为:1π+δ2π+2δ3π+……=11t t t δπ∞-=∑。
所谓贴现因子就是指下一期的一块钱在今天(即现期)的价值,11rδ=+,其中r 为每一期的利率。