蛋白抗原表位预测算法及多肽抗原设计原则
- 格式:pdf
- 大小:176.60 KB
- 文档页数:2

抗原多肽选择及抗原多肽设计的基本原则一、抗原多肽选择的基本原则1、尽可能是在蛋白表面2、保证该段序列不形成α-helix3、N,C 端的肽段比中间的肽段更好4、避免蛋白内部重复或接近重复段的序列5、避免同源性太强的肽段6、交联可以交联在N,C 两端,选择依据就是交联在对产生抗体不太重要的一端7、序列中不能有太多的Pro,但有一两个Pro 有好处,可以使肽链结构相对稳定一些,对产生特异性抗体有益。
二、抗原多肽设计的基本原则为了使生产抗体获得最佳效果,仔细地设计抗原多肽是很有必要的,设计应满足一个基本条件:在免疫过程中,该抗原既不会产生过强的免疫反应,同时又能产生出对感兴趣的蛋白有结合能力的抗体。
尽管抗原设计是一个很复杂的课题,有诸多需要注意的细节,已超过了我们所能提供的范围,根据我们所积累的经验,有几点关键的基本设计原则可以提供给大家参考:1、确定抗体的用途(应用)新开展一个研究项目,弄清楚所感兴趣的蛋白的一些基本特性是很有必要的,特别是如果知道蛋白的结构会对选择抗体易于接触和识别的识别区域有很大的帮助。
然而,在没有这样精确的结构信息(多数是这种情况)的情况下,了解研究的用途(应用)会影响多肽设计的策略。
例如:如果研究重点是集中在蛋白的不同区域,如C 端或N 端,或在一种特定状态下的蛋白,如磷酸化等,那么按照所需序列设计的多肽和产生的相应的抗体在应用上应该没有太大的困难,然而,蛋白的构象将影响抗体与其识别区域之间的相互作用。
这种情况下可能存在的问题是如果在折叠的蛋白中,该识别区域被藏在蛋白的内部,抗体将无法接触到该区域。
(无法产生相互作用)。
2、识别区域的选择原则一般说来最理想的抗原性识别区域应具备亲水、位于蛋白表面和结构上易变形性等特点。
因为在大多数的天然(自然)环境中,亲水区域倾向于集中在蛋白表面,而疏水区域常常被包裹在蛋白内部,同样道理,抗体只能与在蛋白表面发现的识别区域免责声明:以上资料来源于网络、专业书籍、发表论文、学术期刊且不限于上述媒体,由钟鼎生物专业技术人员整理汇总,所相互作用,而当这些识别区域有足够的结构易变形性而转移到抗体可接触的位置时,将会与抗体间有很高的亲和性。
抗原表位分析新突破:基于氨基酸多样性解谜抗原表位分析是生物药物领域中的重要研究方向,它关注的是抗原与抗体之间的相互作用。
抗原表位是抗原分子上能够与抗体结合的特定区域,对于疫苗设计、药物研发和免疫治疗等方面具有重要意义。
近年来,基于氨基酸多样性的抗原表位分析取得了新的突破,为我们解谜抗原与抗体之间的相互作用提供了新的思路和方法。
一、氨基酸多样性与抗原表位抗原表位通常由抗原分子上的氨基酸残基组成,而氨基酸的多样性决定了抗原表位的多样性。
在过去的研究中,科学家们主要通过实验方法来鉴定抗原表位,但这种方法费时费力且成本高昂。
而基于氨基酸多样性的抗原表位分析则能够更加高效地预测和鉴定抗原表位。
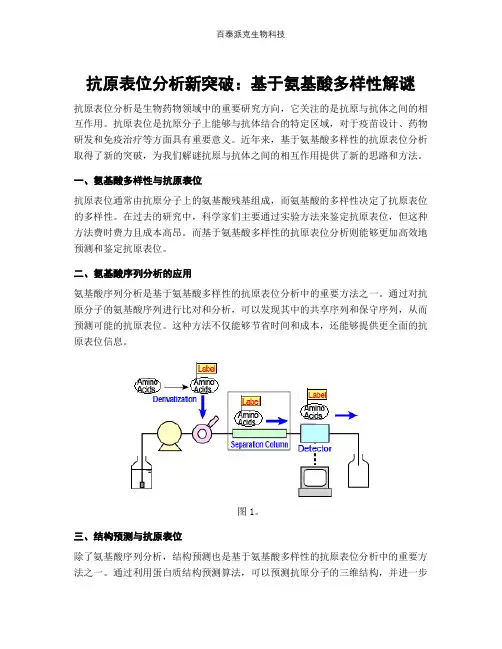
二、氨基酸序列分析的应用氨基酸序列分析是基于氨基酸多样性的抗原表位分析中的重要方法之一。
通过对抗原分子的氨基酸序列进行比对和分析,可以发现其中的共享序列和保守序列,从而预测可能的抗原表位。
这种方法不仅能够节省时间和成本,还能够提供更全面的抗原表位信息。
图1。
三、结构预测与抗原表位除了氨基酸序列分析,结构预测也是基于氨基酸多样性的抗原表位分析中的重要方法之一。
通过利用蛋白质结构预测算法,可以预测抗原分子的三维结构,并进一步预测抗原表位的位置和特征。
这种方法能够更加准确地预测抗原表位,为疫苗设计和药物研发提供更可靠的依据。
图2。
四、机器学习在抗原表位分析中的应用近年来,机器学习技术在生物药物领域中得到了广泛应用,包括抗原表位分析。
通过建立机器学习模型,可以从大量的氨基酸序列和结构数据中学习抗原表位的特征,从而预测新的抗原表位。
这种方法不仅能够提高预测的准确性,还能够加快研究的进展速度。
五、抗原表位分析的应用前景基于氨基酸多样性的抗原表位分析为疫苗设计、药物研发和免疫治疗等方面提供了新的思路和方法。
通过准确预测和鉴定抗原表位,科学家们可以设计出更有效的疫苗和药物,从而提高治疗效果和生活质量。
未来,随着技术的不断发展和创新,抗原表位分析将在生物药物领域发挥越来越重要的作用。

蛋白抗原表位猜测及抗原多肽设计运用在线软件BepiPred 1.0 Server()从蛋白序列直接猜测抗原表位还有其他在线猜测网站进Antigenic Peptide Prediction 用tools把氨基酸序列粘贴进去,就可以直接得出猜测成果抗原多肽选择的基起源基础则1.尽可能是在蛋白概况2.包管该段序列不形成α-helix3.N,C端的肽段比中央的肽段更好4.防止蛋白内部反复或接近反复段的序列5.防止同源性太强的肽段6.交联可以交联在N,C两头,选择根据就是交联在对产生抗体不太主要的一端7.序列中不克不及有太多的Pro,但有一两个Pro有利益,可以使肽链构造相对稳固一些,对产生特异性抗体有益.抗原多肽设计的基起源基础则为了使临盆抗体获得最佳后果,细心地设计抗原多肽是很有须要的,设计应知足一个根本前提:在免疫进程中,该抗原既不会产生过强的免疫反响,同时又能产生出对感兴致的蛋白有联合才能的抗体.尽管抗原设计是一个很庞杂的课题,有诸多须要留意的细节,已超出了我们所能供给的规模,根据我们所积聚的经验,有几点症结的根本设计原则可以供给应大家参考:1.肯定抗体的用处(运用)新开展一个研讨项目,弄清晰所感兴致的蛋白的一些根本特征是很有须要的,特别是假如知道蛋白的构造会对选择抗体易于接触和识此外辨认区域有很大的帮忙.然而,在没有如许准确的构造信息(多半是这种情形)的情形下,懂得研讨的用处(运用)会影响多肽设计的计谋.例如:假如研讨重点是分散在蛋白的不合区域,如C端或N端,或在一种特定状况下的蛋白,如磷酸化等,那么按照所需序列设计的多肽和产生的响应的抗体在运用上应当没有太大的艰苦,然而,蛋白的构象将影响抗体与其辨认区域之间的互相感化.这种情形下可能消失的问题是假如在折叠的蛋白中,该辨认区域被藏在蛋白的内部,抗体将无法接触到该区域.(无法产生互相感化).2.辨认区域的选择原则一般说来最幻想的抗原性辨认区域应具备亲水.位于蛋白概况和构造上易变形性等特色.因为在大多半的天然(天然)情形中,亲水区域偏向于分散在蛋白概况,而疏水区域经常被包裹在蛋白内部,同样道理,抗体只能与在蛋白概况发明的辨认区域互相感化,而当这些辨认区域有足够的构造易变形性而转移到抗体可接触的地位时,将会与抗体间有很高的亲和性.3.持续的与不持续的辨认区域持续的区域是指由持续的氨基酸序列(残基)组成的辨认区域.大多半抗体是针对持续辨认区域的,抗体能与这类区域以很高的亲和力相联合标明这段序列不在蛋白内部.不持续的辨认区域是代表有必定折叠的一段多肽序列,或是将两段分别开的多肽连在一路的抗体的辨认区域.在某些情形下,针对如许不持续辨认区域的抗体也能产生,只是用来免疫的抗原多肽必须具备与该不持续辨认区域类似的二级构造,而序列的长度须要相符相干的请求.4.根本建议为了防止辨认区域隐蔽在蛋白内部的风险,我们平日建议选择蛋白的N,C两头来产生的响应的抗体.因为在完全的蛋白中,N,C两头平日是吐露在蛋白概况的.然而,必定要留意膜蛋白的C端疏水性太强,不合适作为抗原.5.序列的长度平日我们建议抗原多肽的序列长度在8-20个氨基酸残基之间,假如太短,就有多肽太特别.所产生的抗体与天然蛋白之间的亲和力(联合才能)不敷强的风险,同样,假如序列长度超出20,将有可能引入二级构造,所产生的抗体掉去特异性的可能,并且肽链越长,平日合成难度增大,不轻易获得高纯度的产品.6.载体蛋白交联的选择基起源基础则:将载体蛋白加在远离抗体辨认区域的一端,在序列中没有Cys的情形下在N或C端加上Cys为交联的首选办法.7.经常运用剖析软件MacVecfor TM ;DNA star TM;PC-Gene TM。

收稿日期:2006204225;修回日期:20062092083通讯作者:毛旭虎,湖北人,教授,硕士生导师。
作者简介:李海侠(19802),女,硕士研究生,主要从事单克隆抗体,基因工程抗体和蛋白质抗原表位筛选及鉴定的实验研究。
E 2mail:yingchun1220@yahoo 蛋白质抗原表位研究进展李海侠综述;毛旭虎3审校(第三军医大学临床微生物及免疫学教研室重庆市生物制药工程技术研究中心,重庆400038)摘 要:本文综述了蛋白质抗原表位的种类及特性,回顾了近几年来实验确定和理论预测B 细胞蛋白质抗原表位的常用方法,介绍了表位作图和表位疫苗的研究现状。
关键词:抗原表位;噬菌体随机肽库;表位预测;表位作图;表位疫苗中图分类号:R 392.11文献标识码:A文章编号:100525673(2007)0120054205 免疫细胞通常难以借助其表面受体识别整个蛋白质抗原分子,而仅识别抗原肽分子上的一个特定部分即表位(Ep it ope ),又称为抗原决定簇(Antigen 2ic deter m inant )。
因而表位代表了抗原分子上的一个免疫活性区,负责与抗体分子或免疫细胞表面的抗原受体结合,严格说来,抗体的特异性是针对表位而不是针对完整的抗原分子的〔1〕。
一个蛋白质抗原,它不但含有B 细胞、Th 细胞、CT L 细胞、NK 细胞等与免疫识别密切相关的表位结构,同时还含有一些对于保护性免疫不利的结构。
如:毒性或抑制性表位、优势非中和性表位、病理及自身抗原交叉反应性表位等。
人们还认识到同一分子的众多表位中,各表位对抗原性的贡献不同,有优势表位和非优势表位之分。
此外,表位间的相对位置、构象特征、表位侧翼顺序等也与表位功能的表达密切相关。
而表位的功能表达还取决于MHC 限制位(Agret ope )、组织位(H ist ot ope )等相关结构。
许多研究发现,天然蛋白质在引发免疫反应时,不能满足清除病原体的需要。


抗原多肽的设计、偶联策略抗体是生命科学研究中不可或缺的工具之一,应用范围包括蛋白质表达检测和鉴定、蛋白质加工、蛋白质在细胞内的定位、免疫中和反应、蛋白质同源结构域研究、蛋白质纯化以及疾病的免疫诊断和治疗。
尽管抗体的制备过程不存在技术难点,但是抗原的选择以及所制备抗体的用途对能否获得一个优质高效的抗体至关重要。
以下将对抗原多肽的设计、偶联策略等逐一介绍.抗原设计首先选择合适的多肽序列,明确最终产物的用途对选择序列非常重要。
如果仅仅需要生产针对蛋白质某个区域的特异抗体,比如研究蛋白质N端的前提物,我们就需要设计N末端的多肽抗原。
如果抗体的使用目的是识别修饰的氨基酸,如磷酸化的丝氨酸、苏氨酸或者酪氨酸,乙酰化赖氨酸等,就必须对多肽进行相应的修饰。
如果抗体最终用来识别自然状态下的蛋白质,对抗原的设计就要求更高。
一般情况下抗血清能够识别用来免疫的多肽序列,但是不一定识别蛋白质的折叠结构。
蛋白质的抗原决定簇一般由6-12个氨基酸构成,呈连续性或者非连续性序列。
连续性抗原决定簇由连续的氨基酸序列构成,而非连续抗原决定簇包括一组非连续氨基酸,这些氨基酸由于蛋白质的折叠而形成在空间上相互毗邻。
针对连续性抗原决定簇的抗体能够识别没有被埋藏在蛋白质内部的序列,而非连续性抗原的抗体能否识别抗原决定簇取决于用于抗体生产的多肽是否存在二级结构。
氨基酸序列的亲水性、表露性、柔韧性决定了多肽的抗原性。
许多水融性的自然状态下的蛋白质其亲水序列暴露在外测,而疏水性氨基酸序列包埋在内部。
抗体结合蛋白质表面的抗原决定簇,另外抗原决定簇柔韧性比较高。
蛋白质的C末端经常暴露在外测并且有较高的柔韧性,因此经常被用来作为抗体生产的抗原。
但是如果C末端是跨膜蛋白质的膜内部分,该序列可能由于疏水性太强而不适合用来作为抗原。
同C末端序列类似,蛋白质的N末端序列也经常暴露在蛋白质的表面,同样为首选抗原序列。
预测蛋白特性(例如亲水性、疏水性)及二级结构(例如α-螺旋,β-折叠,β-回旋)的一些算法有助于选择表露性较高,有抗原性的内部序列以用于抗体生成。

抗原序列设计抗原序列设计是现代生物技术领域的一个重要研究方向,它涉及到新药研发、疫苗设计和免疫治疗等诸多领域。
本文将从多个角度探讨抗原序列设计的相关知识和应用。
一、引言抗原序列是指具有诱导机体产生免疫应答的蛋白质或多肽的特定线性序列。
在生物医学研究中,抗原序列的设计可以用于开发新药、疫苗和免疫疗法,通过模拟或增强机体的免疫应答来达到治疗或预防疾病的目的。
二、抗原序列的设计原则1. 免疫原性:抗原序列应具有良好的免疫原性,即能够诱导机体产生免疫应答。
这需要考虑抗原的结构、亲水性和氨基酸组成等因素。
2. 特异性:抗原序列应具有特异性,即能够与特定抗体或免疫细胞结合,并产生特定的免疫应答。
这需要根据目标疾病或治疗目标选择合适的抗原序列。
3. 稳定性:抗原序列应具有良好的稳定性,能够在体内长时间存在并保持其免疫活性。
这需要考虑抗原的热稳定性、酸碱稳定性和抗蛋白酶降解等因素。
三、抗原序列设计的应用1. 新药研发:抗原序列设计可以用于开发新药,特别是蛋白质药物。
通过合理设计抗原序列,可以提高药物的免疫原性和稳定性,从而增强药物的疗效和安全性。
2. 疫苗设计:抗原序列设计是疫苗研发的重要一环。
通过选择合适的抗原序列,可以诱导机体产生特定的免疫应答,从而预防或治疗特定的疾病。
3. 免疫疗法:抗原序列设计可以用于免疫疗法的开发。
通过合理设计抗原序列,可以改善免疫细胞的识别和杀伤能力,从而增强免疫疗法的疗效。
四、抗原序列设计的挑战和未来发展方向1. 多样性:不同的疾病和治疗目标需要不同的抗原序列设计策略。
如何根据具体情况选择合适的抗原序列仍然是一个挑战。
2. 预测:目前,抗原序列设计主要依赖于实验和经验。
如何通过计算模型和算法来预测和优化抗原序列,是未来的研究方向。
3. 个体化:不同个体对抗原序列的免疫应答可能存在差异。
如何根据个体的基因组信息来设计个性化的抗原序列,是一个有待研究的问题。
结语抗原序列设计是现代生物技术领域的一个重要研究方向。


有鉴定表位的相关技术和文献。
也有一些表位预测软件。
一般来说,目前研究主要集中在线性表位上,而构象表位的预测和鉴定方法目前不是很成熟。
找到一个帖子,楼主可以参考:1、B细胞表位预测对于多种免疫学研究是必不可少的。
针对不同的蛋白,应选择不同的方法。
一般来说,蛋白质的C端具有较好的亲水性、表面可及性和柔性,所以是很好的抗原决定簇区域。
本课题选用的蛋白质C-末端序列标签都是唯一的、或是其家族中的几个成员所共有的。
在人蛋白质中,约81%的蛋白质其C末端的5个氨基酸残基的小肽是该蛋白质所特有的,制备针对蛋白质C末端小肽的抗体,常常能得到特异性识别该全蛋白的抗体。
另外,蛋白的二级结构是B细胞表位计算机预测的重要参数之一,β转角为凸出结构,多出现在蛋白质抗原表面,有利于与抗体结合,较可能成为抗原表位。
而α螺旋和β折叠结构规则不易变形,较难结合抗体,一般不作为抗原表位。
含有5个以上的氨基酸残基的转角又常称为环(loop)。
以往的研究表明,蛋白表面的loop区可能为功能性抗体的识别位点,特异性好,可及性强。
本课题选用的HPO、G-CSF、HSA空间结构已明确,所以直接选择loop区或无规卷曲作为B细胞表位。
举例:人Pif1基因编码至少两种蛋白亚型,分子量分别为74kDa和80kDa,与酵母具有高度的同源性,α型和β型Pif1只有C末端不同[20>,其余部分完全相同,并且二者的C末端在蛋白数据库中都是唯一的,选择α型和β型的C末端作为B细胞表位,既满足特异性的需要,也能区分亚型。
GPAA1是一种跨膜蛋白,原核表达非常困难,形成包涵体,且包涵体难以溶解和复性。
对这一类型的蛋白,非常适合选择其特有的B细胞表位免疫动物,来最终制备识别全蛋白质的抗体。
ABCpred是基于人工神经网络模型的线性B细胞表位预测工具,该系统检验了源于Bcipep数据库的700个非冗余B细胞表位和源于Swiss-Prot 数据库的700个长度为10~20个氨基酸的随机选择多肽,准确率近66%。

蛋白质多肽结构预测与设计蛋白质多肽结构预测与设计蛋白质是生命体中最为重要的分子之一,它们在细胞内发挥着各种生物学功能,如催化反应、传递信息、维持细胞结构等。
蛋白质的功能与其结构密切相关,因此,了解蛋白质的结构对于研究其功能至关重要。
然而,在实验室中解析蛋白质结构的过程非常耗时、昂贵,因此,研究人员开始尝试使用计算方法对蛋白质结构进行预测和设计。
蛋白质结构预测是指根据蛋白质的氨基酸序列,预测其可能的三维结构。
目前,常用的蛋白质结构预测方法包括比对法、拓扑法、模拟退火法、分子力学法、分子动力学法等。
其中,分子动力学法是最常用的方法之一。
该方法利用分子动力学模拟技术,将蛋白质分子作为一个动态系统进行模拟,通过计算其能量和构象变化,预测其可能的三维结构。
此外,还有一些基于人工智能算法的蛋白质结构预测方法,如神经网络、支持向量机等。
蛋白质结构设计是指通过改变蛋白质分子的氨基酸序列,设计出具有特定功能或性质的新型蛋白质。
目前,常用的蛋白质结构设计方法包括理论设计和实验设计两种。
理论设计是指利用计算方法,根据蛋白质结构和功能的相关知识,设计出具有特定功能或性质的新型蛋白质序列。
实验设计则是指利用实验手段,通过改变蛋白质分子的氨基酸序列,制备出具有特定功能或性质的新型蛋白质。
在实际应用中,蛋白质结构预测和设计技术已经得到了广泛应用。
例如,在药物研发中,研究人员可以利用蛋白质结构预测技术,预测药物分子与靶标蛋白之间的相互作用方式,从而快速筛选出具有潜在药效的化合物。
此外,在生物工程领域,研究人员可以利用蛋白质结构设计技术,设计出具有特定功能或性质的新型酶、抗体等生物分子,用于生产生物制品或治疗疾病。
总之,蛋白质多肽结构预测和设计技术是现代生命科学研究中不可或缺的一部分。
随着计算机技术和人工智能算法的不断发展,这些技术将会更加精确和高效地应用于生命科学研究中,并为人类健康和生命科学领域的发展做出更大的贡献。

蛋白质序列的分析预测教程目的:通过此教程,了解Discovery Studio中预测蛋白质二硫键的操作过程。
所需功能和模块:Discovery Studio Client,DS Sequence Analysis所需数据文件:1jfq.fasta所需时间:1小时介绍Predict Protein Sequence功能可基于单一蛋白序列预测并计算如下性质:➢基于蛋白序列预测蛋白翻译后修饰(PTM)位点:氧化位点、糖基化位点、水解位点、脱酰胺基位点、裂解位点、天冬氨酸异构化位点➢基于蛋白序列预测抗体中保守氨基酸残基➢基于蛋白序列预测抗原表位➢基于蛋白序列识别半胱氨酸、二硫键中的半胱氨酸的识别(需提供蛋白结构)➢基于蛋白序列计算生物物理学性质,包括分子量、等电点、净电荷、摩尔消光系数、包涵体表达发生几率;➢基于蛋白序列预测蛋白亲疏水性、跨膜区。
蛋白质序列的分析预测首先从RCSB网站下载1jfq.fasta文件,将文件中的冒号改为"_",将文件中的"|"改为空格,在写字板中删除轻链(L)部分。
在文件浏览器(Files Explorer)中,找到1jfq.fasta文件,双击打开在分子窗口中显示。
图1在工具浏览器(Tools Explorer)中,展开Macromolecules| Analyze Sequences,点击Predict Sequence Properties。
流程对应参数在参数浏览器中打开。
Input Sequences设置为1jfg:All。
如有相应蛋白结构,则可设置Input Protein Structures参数,若无法提供,则该参数空着即可。
设置Calculate Biophysical Properties参数为True,用于计算蛋白的分子量、等电点、净电荷、摩尔消光系数、包涵体表达发生几率等生物物理学性质。
点击Annotation Types下拉菜单,可勾选Sequence motifs,基于PROSITE预测蛋白翻译后修饰位点(PTM位点);也可勾选Conserved amino acids识别出抗体中的保守残基;也可勾选Antigenic regions预测蛋白潜在的抗原线性表位。
新型疫苗中抗原表位的预测和鉴定随着新冠肺炎疫情的爆发,研究和开发疫苗的工作也在全球范围内加速进行。
新型疫苗技术中,抗原表位的预测和鉴定是极其重要的环节,关系到疫苗研发的效率和准确性。
一、抗原表位的定义和作用抗原表位是指抗原分子上能被免疫系统认知并结合抗体、T细胞受体等抗原识别分子的区域。
抗原表位的作用是与免疫系统的特异性受体一一对应,引发特异性免疫应答。
在疫苗研发中,确定和正确预测抗原表位,是制备高效疫苗的前提。
二、抗原结构预测技术抗原的三维结构决定了其中抗原表位的位置和形状。
因此,抗原结构预测技术是预测和鉴定抗原表位的重要手段之一。
目前广泛应用的一些抗原结构预测软件包括Phyre、Rosetta、I-TASSER、Modeller等。
这些软件通过计算、模拟等手段,将抗原分子的序列和三维结构联系起来,预测和探测抗原表位。
三、抗原表位鉴定技术除了抗原结构预测技术,抗原表位鉴定技术也是预测和确定抗原表位的重要手段。
其中最常用的方法是抗原表位映射和抗体筛选。
抗原表位映射通过对抗原分子中不同肽段与特定抗体的结合情况进行研究,确定抗原表位;而抗体筛选则是利用一些具有不同特异性的抗体,通过对抗原分子中的多个区域进行结合实验,最终确定抗原表位。
四、抗原表位的应用确定和鉴定抗原表位是疫苗研发的重要前置工作,它对制备高效和安全的疫苗具有重要意义。
在当前新冠肺炎的疫苗研发中,科学家们已经成功地预测和鉴定了新冠病毒的刺突蛋白上的重要抗原表位。
接下来,疫苗的开发工作将会基于这些信息来进行,力求制备出具有良好免疫效果和安全性的疫苗。
总之,抗原表位的预测和鉴定是新型疫苗研发的重要环节,现代科学技术为此提供了有力的支持。
在新冠肺炎疫情的背景下,科学家们正加紧研发新型疫苗,为抗击病毒提供有力保障。
蛋白抗原表位预测及抗原多肽设计公司标准化编码 [QQX96QT-XQQB89Q8-NQQJ6Q8-MQM9N]蛋白抗原表位预测及抗原多肽设计利用在线软件BepiPred Server()从蛋白序列直接预测抗原表位还有其他在线预测网站进Antigenic Peptide Prediction 用tools把氨基酸序列粘贴进去,就可以直接得出预测结果抗原多肽选择的基本原则1、尽可能是在蛋白表面2、保证该段序列不形成α-helix3、N,C端的肽段比中间的肽段更好4、避免蛋白内部重复或接近重复段的序列5、避免同源性太强的肽段6、交联可以交联在N,C两端,选择依据就是交联在对产生抗体不太重要的一端7、序列中不能有太多的Pro,但有一两个Pro有好处,可以使肽链结构相对稳定一些,对产生特异性抗体有益。
抗原多肽设计的基本原则????? 为了使生产抗体获得最佳效果,仔细地设计抗原多肽是很有必要的,设计应满足一个基本条件:在免疫过程中,该抗原既不会产生过强的免疫反应,同时又能产生出对感兴趣的蛋白有结合能力的抗体。
尽管抗原设计是一个很复杂的课题,有诸多需要注意的细节,已超过了我们所能提供的范围,根据我们所积累的经验,有几点关键的基本设计原则可以提供给大家参考:1、确定抗体的用途(应用)新开展一个研究项目,弄清楚所感兴趣的蛋白的一些基本特性是很有必要的,特别是如果知道蛋白的结构会对选择抗体易于接触和识别的识别区域有很大的帮助。
然而,在没有这样精确的结构信息(多数是这种情况)的情况下,了解研究的用途(应用)会影响多肽设计的策略。
例如:如果研究重点是集中在蛋白的不同区域,如C端或N端,或在一种特定状态下的蛋白,如磷酸化等,那么按照所需序列设计的多肽和产生的相应的抗体在应用上应该没有太大的困难,然而,蛋白的构象将影响抗体与其识别区域之间的相互作用。
这种情况下可能存在的问题是如果在折叠的蛋白中,该识别区域被藏在蛋白的内部,抗体将无法接触到该区域。
多肽文库抗原表位筛选
1. 多肽文库构建,首先,需要构建一个包含大量多肽序列的文库,这些多肽可以来自不同的蛋白质或是设计合成的多肽。
多肽文库的构建可以通过合成化学方法或是从已知蛋白质序列中提取。
2. 抗原表位预测,接下来,可以利用生物信息学工具对多肽文库中的序列进行抗原表位预测。
这些工具可以根据已知的抗原表位结构和性质,预测多肽序列中可能具有抗原表位特性的区域。
3. 抗原表位筛选,根据预测结果,可以对多肽文库中的序列进行筛选,筛选出具有潜在抗原表位特性的多肽片段。
这一步通常涉及使用生物学实验手段,如ELISA或细胞免疫反应等,来验证多肽片段的抗原表位特性。
4. 鉴定和分析,最后,经过筛选的多肽片段可以进行进一步的鉴定和分析,包括确定其在特定免疫反应中的作用、与抗原受体的结合能力等,从而评估其作为潜在疫苗或免疫治疗药物的潜力。
总的来说,多肽文库抗原表位筛选涉及多个阶段,从多肽文库构建到抗原表位预测、筛选和最终的鉴定分析,需要综合运用生物
信息学、生物化学和免疫学等多个学科的知识和技术手段。
这一过程对于疫苗研发和免疫治疗药物的发现具有重要意义。
疫苗研究中的抗原表位预测及其应用随着科技的发展和医学技术的进步,人类越来越能够控制和治愈许多疾病。
其中,疫苗的研制和使用是一项非常重要的领域。
疫苗的工作原理是通过引入一种被称为“抗原”的物质来刺激人体免疫系统产生抵抗病原体的抗体。
因此,抗原表位预测成为了疫苗研究中重要的一环。
抗原表位是指抗原分子上的一个小区域,它可以被特定的抗体所识别和结合。
在疫苗研究中,通过识别和利用这些抗原表位,研究人员可以制造出能够刺激人体免疫系统产生抵抗病原体的抗体的疫苗。
在过去几十年的疫苗研究中,科学家们主要通过实验室实验来鉴定抗原表位。
这种方法已经被证明是可行的,但是它的过程非常漫长和费力。
随着计算机技术的进步,疫苗研究人员开始探索使用计算机来预测抗原表位。
抗原表位预测是一个多学科领域,涉及生物学、计算机科学和统计学等。
目前,有多种方法可用于预测抗原表位。
下面,我们将介绍其中的一些方法。
1.序列比对法序列比对法是最简单和最常见的抗原表位预测方法之一。
该方法依赖于对大量已知抗原序列的比对和分析。
研究人员可以通过对这些序列进行分析,以识别与特定病原体相关的抗原表位。
虽然这种方法比较简单,但是它的准确性有限,因为它不能很好地处理序列变异的情况。
2.二级结构预测法二级结构预测法是通过计算蛋白质序列中二级结构元素的出现概率来预测抗原表位的一种方法。
该方法利用蛋白质的二级结构信息来预测哪些区域能够被抗体所结合。
这种方法比较准确,特别是对于那些有许多保守序列和结构的蛋白质来说。
3.机器学习法机器学习法是一种新兴的抗原表位预测方法。
它利用计算机算法和人工智能技术来识别与特定病原体相关的抗原表位。
该方法利用机器学习算法来分析大量已知的抗原和非抗原序列的特征,并用这些特征来预测待定的序列是否是抗原。
虽然这种方法还比较新颖,但是它已被证明是一种高效和准确的抗原表位预测方法。
除了在抗原表位预测中,抗原表位预测技术还被广泛应用于疫苗设计和疫苗评估。
蛋白抗原表位预测算法及多肽抗原设计原则概述为了获取识别天然蛋白的抗体,有两种方式可以选择。
一种是利用重组蛋白的方式获取尽可能接近天然条件下的重组蛋白,然后刺激试验动物免疫系统,进而获取相应抗体。
这种方式获取抗体的成功率较高且效价较好;另一种是预测天然蛋白的抗原决定簇,这种抗原决定簇最终体现为多肽形式,将其与相应的载体偶联后刺激试验动物免疫系统,也可以获取相应的抗体。
这种方式的选择有其特殊需要。
我们德泰生物科技南京有限公司提供这两种类型的抗体定制服务。
什么是抗原决定簇蛋白质表面部分可以使免疫系统产生抗体的区域叫抗原决定簇。
一般抗原决定簇是由 6-12 氨基酸或碳水基团组成,它可以是由连续序列(蛋白质一级结构)组成或由不连续的蛋白质三维结构组成。
蛋白抗原表位预测方法目前蛋白质抗原表位预测的方法大致可以分为两类,一类是基于蛋白质高级结构预测,像beta‐转角、膜蛋白跨膜区预测等;一种是基于氨基酸的统计学倾向性,像亲水性(hydrophilicity)、弹性(flexibility)、表面可接触性(surface accessibility)、抗原倾向性(antigenic propensity)。
具体算法请参考相关文献,部分文献如下:1)Chou, Fasman Adv Enzymol Relat Areas Mol Biol. 1978;47:45‐148.2)Hopp, T.P. and Woods, K.R. (1981) Proc. Natl. Acad. Sci. USA 78, 3824‐3828.3)Welling, G.W., Weijer, W.J., van der Zee, R. and Welling‐Wester, S. (1985) FEBS Lett. 188,215‐218.4)Karplus PA, Schulz GE. Naturwissenschafren 1985; 72:212‐3.5)Emini EA, Hughes JV, J Virol. 1985 Sep;55(3):836‐9.6)Parker, J.M.R., Guo, D. and Hodges, R.S. (1986) Biochemistry 25, 5425‐5432.7)Schmidt, A.M. (1989) Biotect. Adv. 7, 187‐213.8) A.S. Kolaskar and Prasad C. Tongaonkar (1990) FEBS 092109)K. Hofmann & W. Stoffel (1993)10)Paul Horton, Keun‐Joon Park, Takeshi Obayashi & Kenta Nakai, Proceedings of the 4th AnnualAsia Pacific Bioinformatics Conference, Taiwan. pp. 39‐48, 2006.11)Jens Erik Pontoppidan Larsen, Ole Lund and Morten Nielsen. Immunome Res. 2006选择多肽抗原的方法不同算法预测出的候选多肽序列有所不同,需要综合考虑各种预测方法,同时结合实际应用进行最终选择。
有鉴定表位的相关技术和文献。
也有一些表位预测软件。
一般来说,目前研究主要集中在线性表位上,而构象表位的预测和鉴定方法目前不是很成熟。
找到一个帖子,楼主可以参考:1、B细胞表位预测对于多种免疫学研究是必不可少的。
针对不同的蛋白,应选择不同的方法。
一般来说,蛋白质的C端具有较好的亲水性、表面可及性和柔性,所以是很好的抗原决定簇区域。
本课题选用的蛋白质C-末端序列标签都是唯一的、或是其家族中的几个成员所共有的。
在人蛋白质中,约81%的蛋白质其C末端的5个氨基酸残基的小肽是该蛋白质所特有的,制备针对蛋白质C末端小肽的抗体,常常能得到特异性识别该全蛋白的抗体。
另外,蛋白的二级结构是B细胞表位计算机预测的重要参数之一,β转角为凸出结构,多出现在蛋白质抗原表面,有利于与抗体结合,较可能成为抗原表位。
而α螺旋和β折叠结构规则不易变形,较难结合抗体,一般不作为抗原表位。
含有5个以上的氨基酸残基的转角又常称为环(loop)。
以往的研究表明,蛋白表面的loop区可能为功能性抗体的识别位点,特异性好,可及性强。
本课题选用的HPO、G-CSF、HSA空间结构已明确,所以直接选择loop区或无规卷曲作为B细胞表位。
举例:人Pif1基因编码至少两种蛋白亚型,分子量分别为74kDa和80kDa,与酵母具有高度的同源性,α型和β型Pif1只有C末端不同[20>,其余部分完全相同,并且二者的C末端在蛋白数据库中都是唯一的,选择α型和β型的C末端作为B细胞表位,既满足特异性的需要,也能区分亚型。
GPAA1是一种跨膜蛋白,原核表达非常困难,形成包涵体,且包涵体难以溶解和复性。
对这一类型的蛋白,非常适合选择其特有的B细胞表位免疫动物,来最终制备识别全蛋白质的抗体。
ABCpred是基于人工神经网络模型的线性B细胞表位预测工具,该系统检验了源于Bcipep数据库的700个非冗余B细胞表位和源于Swiss-Prot 数据库的700个长度为10~20个氨基酸的随机选择多肽,准确率近66%。
蛋白抗原表位预测算法
及多肽抗原设计原则
概述
为了获取识别天然蛋白的抗体,有两种方式可以选择。
一种是利用重组蛋白的方式获取尽可能接近天然条件下的重组蛋白,然后刺激试验动物免疫系统,进而获取相应抗体。
这种方式获取抗体的成功率较高且效价较好;另一种是预测天然蛋白的抗原决定簇,这种抗原决定簇最终体现为多肽形式,将其与相应的载体偶联后刺激试验动物免疫系统,也可以获取相应的抗体。
这种方式的选择有其特殊需要。
我们德泰生物科技南京有限公司提供这两种类型的抗体定制服务。
什么是抗原决定簇
蛋白质表面部分可以使免疫系统产生抗体的区域叫抗原决定簇。
一般抗原决定簇是由6-12氨基酸或碳水基团组成,它可以是由连续序列(蛋白质一级结构)组成或由不连续的蛋白质三维结构组成。
蛋白抗原表位预测方法
目前蛋白质抗原表位预测的方法大致可以分为两类,一类是基于蛋白质高级结构预测,像beta-转角、膜蛋白跨膜区预测等;一种是基于氨基酸的统计学倾向性,像亲水性(hydrophilicity)、弹性(flexibility)、表面可接触性(surface accessibility)、抗原倾向性(antigenic propensity)。
具体算法请参考相关文献,部分文献如下:
1)Chou,Fasman Adv Enzymol Relat Areas Mol Biol.1978;47:45-148.
2)Hopp,T.P.and Woods,K.R.(1981)A78,3824-3828.
3)Welling,G.W.,Weijer,W.J.,van der Zee,R.and Welling-Wester,S.(1985)FEBS Lett.188,215-218.
4)Karplus PA,Schulz GE.Naturwissenschafren1985;72:212-3.
5)Emini EA,Hughes JV,J Virol.1985Sep;55(3):836-9.
6)Parker,J.M.R.,Guo,D.and Hodges,R.S.(1986)Biochemistry25,5425-5432.
7)Schmidt,A.M.(1989)Biotect.Adv.7,187-213.
8) A.S.Kolaskar and Prasad C.Tongaonkar(1990)FEBS09210
9)K.Hofmann&W.Stoffel(1993)
10)Paul Horton,Keun-Joon Park,Takeshi Obayashi&Kenta Nakai,Proceedings of the4th Annual Asia
Pacific Bioinformatics Conference,Taiwan.pp.39-48,2006.
11)Jens Erik Pontoppidan Larsen,Ole Lund and Morten Nielsen.Immunome Res.2006
选择多肽抗原的方法
不同算法预测出的候选多肽序列有所不同,需要综合考虑各种预测方法,同时结合实际应用进行最终选择。
最终选择的多肽序列一般在15-20个碱基。
单个抗原决定簇一般包含5-8个碱基,那么15-20个碱基的多肽一般会包含1个或更多个抗原决定簇。
相对长一些的多肽段能够更好的保持和天然蛋白的一致性,更容易产生抗体。
由于多肽是采用化学方法合成出来的,我们也要考虑到多肽合成的难度及其良好的可溶性。
我们一般会选择亲水区的多肽,其可溶性一般没太大问题,但是这些区域也会包含疏水性的碱基(如亮氨酸、色氨酸、异亮氨酸、缬氨酸、苯丙氨酸)。
如果可能,尽量少选择带有这类氨基酸的多肽。
谷氨酰胺由于容易和肽链形成氢键而导致多肽不可溶,所以具有多个谷氨酸的多肽也要尽量避免。
半胱氨酸有利于将多肽偶联到载体蛋白上。
所以应该保留多肽N端或C端的半胱氨酸,以便于载体蛋白偶联,从而具有较好的免疫原性。
同时两个或更多半胱氨酸的情况需要避免,因为它会造成多肽链之间形成二硫键,进而导致不溶和结构变化。
当选择的多肽缺少半胱氨酸时,我们可以在N端或C端加上半胱氨酸。
脯氨酸采用顺式酰胺键的方式存在于多肽中,而一般多肽的酰胺键是反式的,它的存在更能使多肽与天然蛋白相似。
在大多数情况下,脯氨酸的存在更能形成自然结构,增强多肽的免疫原性。
如果抗体用于识别目标蛋白翻译后的修饰区域(如磷酸化、糖基化位点),那么我们的多肽就需要在两端稍作延伸。
从另一个方面来说,如果抗体用于识别翻译修饰前的蛋白,那么相应的位点需要去除掉。
跨膜区蛋白段需要移出掉,因为跨膜区无法被抗体接触到。
林林总总,经过层层规则的过滤,最终我们会保留至少3条多肽(经验证明3条多肽可以使抗体识别天然蛋白的成功率达到93%以上)。
化学合成的多肽,在抗体生产中,其浓度也影响着免疫应答反应。
纯度越高,特异性免疫应答反应越强。