hadoop开发实战培训36 - MapReduce高阶实现(10)
- 格式:ppt
- 大小:1.54 MB
- 文档页数:12

习题一、选择题1.下列有关 Hadoop 的说法正确的是( ABCD )。
A .Hadoop 最早起源于 NutchB .Hadoop 中HDFS 的理念来源于谷歌发表的分布式文件系统( GFS )的论文C .Hadoop 中 MapReduce 的思想来源于谷歌分布式计算框架 MapReduce 的论文D.Hadoop 是在分布式服务器集群上存储海量数据并运行分布式分析应用的一个开源的软件框架2.使用 Hadoop 的原因是( ABCD )。
A.方便:Hadoop 运行在由普通商用机器构成的大型集群上或者云计算服务上B.稳健:Hadoop 致力于在普通商用硬件上运行,其架构假设硬件会频繁失效,Hadoop 可以从容地处理大多数此类故障C .可扩展:Hadoop 通过增加集群节点,可以线性地扩展以处理更大的数据集D.简单:Hadoop 允许用户快速编写高效的并行代码3.Hadoop 的作者是( B )。
A .Martin FowlerB .Doug CuttingC .Kent BeckD .Grace Hopper4.以下关于大数据特点的描述中,不正确的是( ABC )。
A .巨大的数据量B .多结构化数据C .增长速度快D .价值密度高二、简答题1.Hadoop 是一个什么样的框架?答:Hadoop 是一款由Apache 基金会开辟的可靠的、可伸缩的分布式计算的开源软件。
它允许使用简单的编程模型在跨计算机集群中对大规模数据集进行分布式处理。
2.Hadoop 的核心组件有哪些?简单介绍每一个组件的作用。
答:核心组件有 HDFS 、MapReduce 、YARN 。
HDFS ( Hadoop Distributed File Sy,st doop 分布式文件系统)是 Hadoop 的核心组件之一,作为最底层的分布式存储服务而存在。
它是一个高度容错的系统,能检测和应对硬件故障,可在低成本的通用硬件上运行。

Hadoop Map/Reduce教程[一]编辑| 删除| 权限设置| 更多▼更多▲∙设置置顶∙推荐日志∙转为私密日志开心延年发表于2009年11月02日00:15 阅读(10) 评论(1) 分类:搜索与存储权限: 公开今天浏览了下hadoop的 map/reduce文档,初步感觉这东西太牛逼了,听我在这里给你吹吹。
你可以这样理解,假设你有很多台烂机器(假设1000台)1.利用hadoop他会帮你组装成一台超级计算机(集群),你的这台计算机是超多核的(很多个CPU),一个超级大的硬盘,而且容错和写入速度都很快。
2.如果你的计算任务可以拆分,那么通过map/Reduce,他可以统一指挥你的那一帮烂机器,让一堆机器帮你一起干活(并行计算),谁干什么,负责什么,他来管理,通常处理个几T的数据,只要你有机器那就小CASE。
3.hadoop要分析的数据通常都是巨大的(T级),网络I/O开销不可忽视,但分析程序通常不会很大,所以他传递的是计算方法(程序),而不是数据文件,所以每次计算在物理上都是在相近的节点上进行(同一台机器或同局域网),大大降低的IO消耗,而且计算程序如果要经常使用的话也是可以做缓存的。
4.hadoop是一个分布式的文件系统,他就像一个管家,管理你数据的存放,在物理上较远的地方会分别存放(这样一是不同的地方读取数据都很快,也起到了异地容灾的作用),他会动态管理和调动你的数据节点,高强的容错处理,最大程度的降低数据丢失的风险。
比较著名的应用:nutch搜索引擎的蜘蛛抓取程序,数据的存储以及pageRank(网页重要程序)计算。
QQ空间的日志分析处理(PV,UV)咋样,给他吹的够牛了吧。
下面是别人翻译的官方文档,经常做日志分析处理的同学可以研究下。
目的这篇教程从用户的角度出发,全面地介绍了Hadoop Map/Reduce框架的各个方面。
先决条件请先确认Hadoop被正确安装、配置和正常运行中。



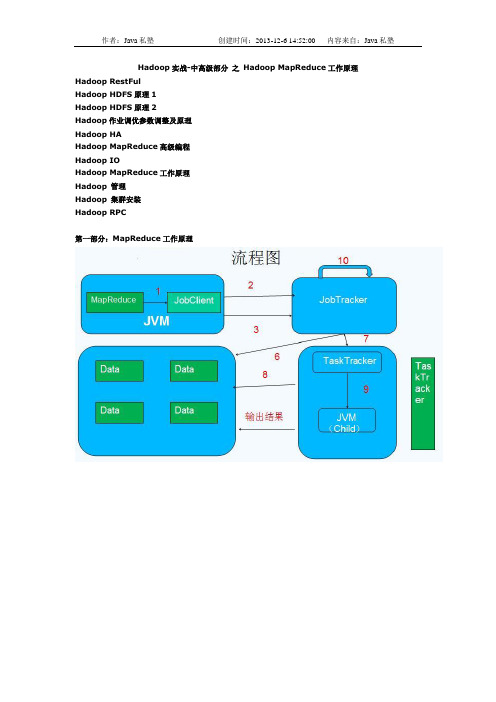
Hadoop实战-中高级部分之Hadoop MapReduce工作原理Hadoop RestFulHadoop HDFS原理1Hadoop HDFS原理2Hadoop作业调优参数调整及原理Hadoop HAHadoop MapReduce高级编程Hadoop IOHadoop MapReduce工作原理Hadoop 管理Hadoop 集群安装Hadoop RPC第一部分:MapReduce工作原理MapReduce 角色•Client :作业提交发起者。
•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业。
•TaskTracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。
提交作业•在作业提交之前,需要对作业进行配置•程序代码,主要是自己书写的MapReduce程序。
•输入输出路径•其他配置,如输出压缩等。
•配置完成后,通过JobClinet来提交作业的初始化•客户端提交完成后,JobTracker会将作业加入队列,然后进行调度,默认的调度方法是FIFO调试方式。
任务的分配•TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。
•TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。
任务的执行•申请到任务后,TaskTracker会做如下事情:•拷贝代码到本地•拷贝任务的信息到本地•启动JVM运行任务状态与任务的更新•任务在运行过程中,首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
•任务进度是通过计数器来实现的。
作业的完成•JobTracker是在接受到最后一个任务运行完成后,才会将任务标志为成功。
•此时会做删除中间结果等善后处理工作。
《Hadoop大数据开发实战》教学教案(第一部分)一、教学目标1. 理解Hadoop的基本概念和架构2. 掌握Hadoop的安装和配置3. 掌握Hadoop的核心组件及其作用4. 能够搭建简单的Hadoop集群并进行基本的操作二、教学内容1. Hadoop简介1.1 Hadoop的定义1.2 Hadoop的发展历程1.3 Hadoop的应用场景2. Hadoop架构2.1 Hadoop的组成部分2.2 Hadoop的分布式文件系统HDFS2.3 Hadoop的计算框架MapReduce3. Hadoop的安装和配置3.1 Hadoop的版本选择3.2 Hadoop的安装步骤3.3 Hadoop的配置文件解读4. Hadoop的核心组件4.1 NameNode和DataNode4.2 JobTracker和TaskTracker4.3 HDFS和MapReduce的运行原理三、教学方法1. 讲授法:讲解Hadoop的基本概念、架构和组件2. 实践法:引导学生动手实践,安装和配置Hadoop,了解其运行原理3. 讨论法:鼓励学生提问、发表观点,共同探讨Hadoop的应用场景和优缺点四、教学准备1. 教师准备:熟悉Hadoop的安装和配置,了解其运行原理2. 学生准备:具备一定的Linux操作基础,了解Java编程五、教学评价1. 课堂参与度:学生提问、回答问题的积极性2. 实践操作:学生动手实践的能力,如能够独立完成Hadoop的安装和配置3. 课后作业:学生完成课后练习的情况,如编写简单的MapReduce程序4. 综合评价:结合学生的课堂表现、实践操作和课后作业,综合评价学生的学习效果《Hadoop大数据开发实战》教学教案(第二部分)六、教学目标1. 掌握Hadoop生态系统中的常用组件2. 理解Hadoop数据存储和处理的高级特性3. 学会使用Hadoop进行大数据处理和分析4. 能够运用Hadoop解决实际的大数据问题七、教学内容1. Hadoop生态系统组件7.1 YARN的概念和架构7.2 HBase的概念和架构7.3 Hive的概念和架构7.4 Sqoop的概念和架构7.5 Flink的概念和架构(可选)2. Hadoop高级特性8.1 HDFS的高可用性8.2 HDFS的存储策略8.3 MapReduce的高级特性8.4 YARN的资源管理3. 大数据处理和分析9.1 Hadoop在数据处理中的应用案例9.2 Hadoop在数据分析中的应用案例9.3 Hadoop在机器学习中的应用案例4. Hadoop解决实际问题10.1 Hadoop在日志分析中的应用10.2 Hadoop在网络爬虫中的应用10.3 Hadoop在图像处理中的应用八、教学方法1. 讲授法:讲解Hadoop生态系统组件的原理和应用2. 实践法:引导学生动手实践,使用Hadoop进行数据处理和分析3. 案例教学法:分析实际应用案例,让学生了解Hadoop在不同领域的应用九、教学准备1. 教师准备:熟悉Hadoop生态系统组件的原理和应用,具备实际操作经验2. 学生准备:掌握Hadoop的基本操作,了解Hadoop的核心组件十、教学评价1. 课堂参与度:学生提问、回答问题的积极性2. 实践操作:学生动手实践的能力,如能够独立完成数据处理和分析任务3. 案例分析:学生分析实际应用案例的能力,如能够理解Hadoop在不同领域的应用4. 课后作业:学生完成课后练习的情况,如编写复杂的MapReduce程序或使用Hadoop生态系统组件进行数据处理5. 综合评价:结合学生的课堂表现、实践操作、案例分析和课后作业,综合评价学生的学习效果重点和难点解析一、Hadoop的基本概念和架构二、Hadoop的安装和配置三、Hadoop的核心组件四、Hadoop生态系统组件五、Hadoop数据存储和处理的高级特性六、大数据处理和分析七、Hadoop解决实际问题本教案涵盖了Hadoop的基本概念、安装配置、核心组件、生态系统组件、数据存储和处理的高级特性,以及大数据处理和分析的实际应用。
Hadoop大数据开发基础教案-MapReduce进阶编程教案一、MapReduce编程模型1.1 课程目标理解MapReduce编程模型的基本概念掌握MapReduce程序的编写和运行过程掌握MapReduce中的数据序列化和反序列化1.2 教学内容MapReduce编程模型概述Mapper和Reducer的编写和运行序列化和反序列化1.3 教学方法讲解MapReduce编程模型的基本概念通过示例演示Mapper和Reducer的编写和运行讲解序列化和反序列化的实现方法1.4 教学资源MapReduce编程模型PPT示例代码1.5 教学评估学生能理解MapReduce编程模型的基本概念学生能编写简单的MapReduce程序学生能实现序列化和反序列化功能二、MapReduce高级特性2.1 课程目标理解MapReduce高级特性的概念和作用掌握MapReduce中的数据分区、分片和合并掌握MapReduce中的数据压缩和溢出处理2.2 教学内容MapReduce高级特性概述数据分区和分片数据压缩和溢出处理2.3 教学方法讲解MapReduce高级特性的概念和作用通过示例演示数据分区和分片的实现方法讲解数据压缩和溢出处理的实现方法2.4 教学资源MapReduce高级特性PPT示例代码2.5 教学评估学生能理解MapReduce高级特性的概念和作用学生能实现数据分区和分片功能学生能处理数据压缩和溢出问题三、MapReduce性能优化3.1 课程目标理解MapReduce性能优化的目标和原则掌握MapReduce中的任务调度和资源管理掌握MapReduce中的数据本地化和压缩策略3.2 教学内容MapReduce性能优化概述任务调度和资源管理数据本地化和压缩策略3.3 教学方法讲解MapReduce性能优化的目标和原则通过示例演示任务调度和资源管理的实现方法讲解数据本地化和压缩策略的实现方法3.4 教学资源MapReduce性能优化PPT示例代码3.5 教学评估学生能理解MapReduce性能优化的目标和原则学生能实现任务调度和资源管理功能学生能应用数据本地化和压缩策略进行性能优化四、MapReduce案例分析4.1 课程目标理解MapReduce在实际应用中的案例掌握MapReduce在文本处理、数据挖掘和图像处理等方面的应用掌握MapReduce在分布式文件系统上的数据处理能力4.2 教学内容MapReduce案例概述文本处理、数据挖掘和图像处理的MapReduce应用分布式文件系统上的数据处理4.3 教学方法讲解MapReduce在实际应用中的案例通过示例演示文本处理、数据挖掘和图像处理的MapReduce应用讲解分布式文件系统上的数据处理方法4.4 教学资源MapReduce案例分析PPT示例代码4.5 教学评估学生能理解MapReduce在实际应用中的案例学生能应用MapReduce进行文本处理、数据挖掘和图像处理学生能掌握MapReduce在分布式文件系统上的数据处理能力五、MapReduce编程实践5.1 课程目标掌握MapReduce编程实践的基本步骤能够编写并运行一个完整的MapReduce程序理解MapReduce编程实践中的常见问题和解决方法5.2 教学内容MapReduce编程实践概述编写MapReduce程序的基本步骤常见问题和解决方法六、Hadoop生态系统中的MapReduce6.1 课程目标理解Hadoop生态系统中MapReduce的位置和作用掌握Hadoop中MapReduce与其他组件的交互理解MapReduce在不同Hadoop发行版中的配置和使用6.2 教学内容Hadoop生态系统概述MapReduce在Hadoop中的角色MapReduce与HDFS、YARN等组件的交互不同Hadoop发行版的MapReduce配置6.3 教学方法讲解Hadoop生态系统的结构和组件通过图解和实例说明MapReduce在Hadoop中的作用比较不同Hadoop发行版中MapReduce的配置差异6.4 教学资源Hadoop生态系统PPTMapReduce在不同Hadoop发行版中的配置示例6.5 教学评估学生能理解Hadoop生态系统中MapReduce的位置和作用学生能描述MapReduce与HDFS、YARN等组件的交互过程学生能根据不同Hadoop发行版配置MapReduce七、使用MapReduce处理复杂数据类型7.1 课程目标理解复杂数据类型的概念和重要性掌握MapReduce中处理复杂数据类型的方法学会使用MapReduce处理序列文件、自定义对象等7.2 教学内容复杂数据类型的介绍序列文件的处理自定义对象的处理数据压缩技术7.3 教学方法讲解复杂数据类型的概念和应用场景通过示例演示如何使用MapReduce处理序列文件和自定义对象介绍数据压缩技术在MapReduce中的应用7.4 教学资源复杂数据类型PPT序列文件和自定义对象处理的示例代码数据压缩技术文档7.5 教学评估学生能理解复杂数据类型的概念和重要性学生能使用MapReduce处理序列文件和自定义对象学生能应用数据压缩技术优化MapReduce程序八、MapReduce中的数据流控制8.1 课程目标理解MapReduce中数据流控制的概念掌握MapReduce中shuffle和sort的过程学会使用MapReduce实现数据过滤和聚合8.2 教学内容数据流控制概述shuffle和sort过程数据过滤和聚合技术8.3 教学方法讲解数据流控制的概念和作用通过图解和示例说明shuffle和sort的过程介绍如何使用MapReduce实现数据过滤和聚合8.4 教学资源数据流控制PPTshuffle和sort过程的图解和示例代码数据过滤和聚合的示例代码8.5 教学评估学生能理解数据流控制的概念学生能描述shuffle和sort的过程学生能使用MapReduce实现数据过滤和聚合九、使用MapReduce进行数据分析9.1 课程目标理解MapReduce在数据分析中的应用掌握使用MapReduce进行词频统计、日志分析等常见数据分析任务学会设计适用于MapReduce的数据分析算法9.2 教学内容数据分析概述词频统计日志分析数据分析算法设计9.3 教学方法讲解数据分析的概念和MapReduce的应用场景通过示例演示如何使用MapReduce进行词频统计和日志分析介绍如何设计适用于MapReduce的数据分析算法9.4 教学资源数据分析PPT词频统计和日志分析的示例代码适用于MapReduce的数据分析算法设计文档9.5 教学评估学生能理解MapReduce在数据分析中的应用学生能使用MapReduce进行词频统计和日志分析学生能设计适用于MapReduce的数据分析算法十、MapReduce最佳实践和技巧10.1 课程十一、MapReduce调试和优化11.1 课程目标理解MapReduce程序调试的重要性掌握MapReduce程序的调试技巧学会优化MapReduce程序的性能11.2 教学内容MapReduce程序调试的重要性MapReduce程序调试技巧MapReduce程序性能优化11.3 教学方法讲解调试和优化MapReduce程序的重要性通过实例演示MapReduce程序的调试技巧介绍优化MapReduce程序性能的方法11.4 教学资源MapReduce程序调试和优化PPT MapReduce程序调试技巧实例代码MapReduce程序性能优化文档11.5 教学评估学生能理解调试MapReduce程序的重要性学生能掌握调试MapReduce程序的技巧学生能掌握优化MapReduce程序性能的方法十二、MapReduce在实际项目中的应用12.1 课程目标理解MapReduce在实际项目中的应用场景掌握MapReduce在数据处理、分析等实际项目中的应用学会将MapReduce应用到实际项目中12.2 教学内容MapReduce在实际项目中的应用场景MapReduce在数据处理、分析等实际项目中的应用将MapReduce应用到实际项目中的方法12.3 教学方法讲解MapReduce在实际项目中的应用场景通过实例演示MapReduce在数据处理、分析等实际项目中的应用介绍将MapReduce应用到实际项目中的方法12.4 教学资源MapReduce在实际项目中应用PPTMapReduce在数据处理、分析等实际项目中的应用实例代码将MapReduce应用到实际项目中的方法文档12.5 教学评估学生能理解MapReduce在实际项目中的应用场景学生能掌握MapReduce在数据处理、分析等实际项目中的应用学生能将MapReduce应用到实际项目中十三、Hadoop生态系统中的其他数据处理工具13.1 课程目标理解Hadoop生态系统中除MapReduce外的其他数据处理工具掌握Hadoop生态系统中其他数据处理工具的基本使用方法学会在Hadoop生态系统中选择合适的数据处理工具13.2 教学内容Hadoop生态系统中其他数据处理工具概述Hadoop生态系统中其他数据处理工具的基本使用方法在Hadoop生态系统中选择合适的数据处理工具的方法13.3 教学方法讲解Hadoop生态系统中其他数据处理工具的概念和作用通过实例演示Hadoop生态系统中其他数据处理工具的基本使用方法介绍在Hadoop生态系统中选择合适的数据处理工具的方法13.4 教学资源Hadoop生态系统中其他数据处理工具PPTHadoop生态系统中其他数据处理工具的基本使用方法实例代码在Hadoop生态系统中选择合适的数据处理工具的方法文档13.5 教学评估学生能理解Hadoop生态系统中除MapReduce外的其他数据处理工具学生能掌握Hadoop生态系统中其他数据处理工具的基本使用方法学生能在Hadoop生态系统中选择合适的数据处理工具十四、Hadoop集群管理和维护14.1 课程目标理解Hadoop集群管理和维护的重要性掌握Hadoop集群的配置、监控和故障排除方法学会Hadoop集群的日常管理和维护技巧14.2 教学内容Hadoop集群管理和维护的重要性Hadoop集群的配置、监控和故障排除方法Hadoop集群的日常管理和维护技巧14.3 教学方法讲解Hadoop集群管理和维护的重要性通过实例演示Hadoop集群的配置、监控和故障排除方法介绍Hadoop集群的日常管理和维护技巧14.4 教学资源Hadoop集群管理和维护PPTHadoop集群的配置、监控和故障排除方法实例代码Hadoop集群的日常管理和维护技巧文档重点和难点解析本文主要介绍了Hadoop大数据开发基础中的MapReduce进阶编程教案,内容包括MapReduce编程模型、高级特性、性能优化、案例分析、编程实践、数据流控制、数据分析、最佳实践和技巧、实际项目中的应用、Hadoop生态系统中的其他数据处理工具以及Hadoop集群管理和维护。
一、MapReduce简介1.1 课程目标理解MapReduce的概念和原理掌握MapReduce编程模型了解MapReduce在Hadoop中的作用1.2 教学内容MapReduce定义MapReduce编程模型(Map、Shuffle、Reduce阶段)MapReduce的优势和局限性Hadoop中的MapReduce运行机制1.3 教学方法理论讲解实例演示学生实操1.4 教学资源PPT课件Hadoop环境MapReduce实例代码1.5 课后作业分析一个大数据问题,尝试设计一个简单的MapReduce解决方案二、Hadoop环境搭建与配置2.1 课程目标学会在本地环境搭建Hadoop掌握Hadoop配置文件的基本配置理解Hadoop文件系统(HDFS)的存储机制2.2 教学内容Hadoop架构简介Hadoop环境搭建步骤Hadoop配置文件介绍(如:core-site.xml、hdfs-site.xml、mapred-site.xml)HDFS命令行操作2.3 教学方法讲解与实操相结合学生分组讨论问答互动2.4 教学资源PPT课件Hadoop安装包Hadoop配置文件模板HDFS命令行操作指南2.5 课后作业搭建本地Hadoop环境,并配置Hadoop文件系统三、MapReduce编程基础3.1 课程目标掌握MapReduce编程的基本概念理解MapReduce的运行原理3.2 教学内容MapReduce编程入口(Java)MapReduce关键组件(Job, Configuration, Reporter等)MapReduce编程实践(WordCount案例)MapReduce运行流程解析3.3 教学方法理论讲解与实操演示代码解析学生实践与讨论3.4 教学资源PPT课件MapReduce编程教程WordCount案例代码编程环境(Eclipse/IntelliJ IDEA)3.5 课后作业完成WordCount案例的编写与运行分析MapReduce运行过程中的各个阶段四、MapReduce高级特性4.1 课程目标掌握MapReduce的高级特性了解MapReduce在复杂数据处理中的应用4.2 教学内容MapReduce高级数据处理(如:排序、分组合并等)MapReduce性能优化策略(如:数据分区、序列化等)复杂场景下的MapReduce应用(如:多层嵌套、自定义分区等)4.3 教学方法理论讲解与实操演示代码解析与优化学生实践与讨论4.4 教学资源PPT课件MapReduce高级特性教程性能优化案例代码编程环境(Eclipse/IntelliJ IDEA)4.5 课后作业优化WordCount程序的性能分析复杂场景下的MapReduce应用案例5.1 课程目标了解MapReduce在大数据处理领域的应用趋势掌握进一步学习MapReduce的途径5.2 教学内容MapReduce编程要点回顾MapReduce在实际项目中的应用案例大数据处理领域的新技术与发展趋势(如:Spark、Flink等)5.3 教学方法知识点梳理与讲解案例分享学生提问与讨论5.4 教学资源PPT课件实际项目案例相关技术资料5.5 课后作业结合实际项目,分析MapReduce的应用场景六、MapReduce编程实战(一)6.1 课程目标掌握MapReduce编程的实战技巧学会分析并解决实际问题理解MapReduce在不同场景下的应用6.2 教学内容实战案例介绍:倒排索引构建MapReduce编程实战:倒排索引的MapReduce实现案例分析:倒排索引在搜索引擎中的应用6.3 教学方法实操演示与讲解学生跟随实操案例分析与讨论6.4 教学资源PPT课件实战案例代码搜索引擎原理资料6.5 课后作业完成倒排索引的MapReduce实现分析MapReduce在搜索引擎中的应用七、MapReduce编程实战(二)7.1 课程目标进一步掌握MapReduce编程的实战技巧学会分析并解决复杂问题了解MapReduce在不同行业的应用7.2 教学内容实战案例介绍:网页爬虫数据处理MapReduce编程实战:网页爬虫数据的抓取与解析案例分析:MapReduce在网络爬虫领域的应用7.3 教学方法实操演示与讲解学生跟随实操案例分析与讨论7.4 教学资源PPT课件实战案例代码网络爬虫原理资料7.5 课后作业完成网页爬虫数据的MapReduce实现分析MapReduce在网络爬虫领域的应用八、MapReduce性能优化8.1 课程目标掌握MapReduce性能优化的方法与技巧学会分析并提升MapReduce程序的性能理解MapReduce性能优化的意义8.2 教学内容性能优化概述:MapReduce性能瓶颈分析优化方法与技巧:数据划分、序列化、并行度等性能优化案例:WordCount的性能提升8.3 教学方法理论讲解与实操演示代码解析与优化学生实践与讨论8.4 教学资源PPT课件性能优化教程性能优化案例代码编程环境(Eclipse/IntelliJ IDEA)8.5 课后作业分析并优化WordCount程序的性能研究其他MapReduce性能优化案例九、MapReduce在大数据处理中的应用9.1 课程目标理解MapReduce在大数据处理中的应用场景学会分析并解决实际问题掌握MapReduce与其他大数据处理技术的比较9.2 教学内容大数据处理场景:日志分析、分布式文件处理等MapReduce应用案例:日志数据分析MapReduce与其他大数据处理技术的比较9.3 教学方法理论讲解与实操演示案例分析与讨论学生提问与互动9.4 教学资源PPT课件大数据处理案例资料MapReduce与其他技术比较资料9.5 课后作业分析MapReduce在日志数据分析中的应用研究MapReduce与其他大数据处理技术的优缺点10.1 课程目标了解MapReduce技术的发展趋势掌握进一步学习MapReduce的途径10.2 教学内容MapReduce编程要点回顾MapReduce技术的发展趋势:YARN、Spark等拓展学习资源与推荐10.3 教学方法知识点梳理与讲解技术发展趋势分享学生提问与讨论10.4 教学资源PPT课件技术发展趋势资料拓展学习资源列表10.5 课后作业制定个人拓展学习计划重点和难点解析:一、MapReduce简介理解MapReduce的概念和原理掌握MapReduce编程模型了解MapReduce在Hadoop中的作用二、Hadoop环境搭建与配置学会在本地环境搭建Hadoop掌握Hadoop配置文件的基本配置理解Hadoop文件系统(HDFS)的存储机制三、MapReduce编程基础掌握MapReduce编程的基本概念学会编写MapReduce应用程序理解MapReduce的运行原理四、MapReduce高级特性掌握MapReduce的高级特性学会优化MapReduce程序性能了解MapReduce在复杂数据处理中的应用六、MapReduce编程实战(一)掌握MapReduce编程的实战技巧学会分析并解决实际问题理解MapReduce在不同场景下的应用七、MapReduce编程实战(二)进一步掌握MapReduce编程的实战技巧学会分析并解决复杂问题了解MapReduce在不同行业的应用八、MapReduce性能优化掌握MapReduce性能优化的方法与技巧学会分析并提升MapReduce程序的性能理解MapReduce性能优化的意义九、MapReduce在大数据处理中的应用理解MapReduce在大数据处理中的应用场景学会分析并解决实际问题掌握MapReduce与其他大数据处理技术的比较了解MapReduce技术的发展趋势掌握进一步学习MapReduce的途径本教案主要涵盖了MapReduce编程的基础知识、Hadoop环境搭建、编程实战、高级特性、性能优化以及应用场景等内容。
hadoop中mapreduce的实现机制Hadoop中的MapReduce是一个编程模型,用于处理和生成大数据集。
这个模型被设计为高度容错,并且可以轻松地部署在由普通机器组成的集群上。
以下是MapReduce在Hadoop中的实现机制:1. 数据分割:首先,大数据集被分割成较小的数据块,这些数据块可以在集群中的不同节点上进行处理。
默认情况下,这些数据块的大小是128MB,但可以根据需要进行调整。
2. Map阶段:每个数据块都会分配给一个工作节点,并运行Map函数。
Map函数读取输入数据,执行用户定义的转换操作,并输出一系列键值对(key-value pairs)。
这些键值对会被分区函数(Partitioner)进行分区,以便它们可以在Reduce阶段被正确处理。
3. Shuffle阶段:MapReduce框架会对所有相同键的键值对进行排序,并将它们收集到一个工作节点上。
这是所谓的"shuffle"过程。
这个过程由框架自动完成,确保每个键只会被处理一次。
4. Reduce阶段:在shuffle阶段之后,每个键值对都会被发送到同一个Reduce工作节点上。
Reduce函数读取这些键值对,执行用户定义的归约操作,并输出最终的结果。
5. 结果输出:一旦Reduce阶段完成,结果就会写入到输出文件中。
默认情况下,结果会存储在HDFS中,但也可以存储在其他位置。
6. 故障处理:MapReduce在Hadoop中的另一个关键特性是其对失败节点的处理。
如果在处理过程中的任何节点失败,该节点的任务将被重新分配给其他可用节点。
此外,MapReduce还提供了备份和检查点机制,以确保数据的完整性和可靠性。
总的来说,Hadoop中的MapReduce是一个高度可扩展、容错的计算模型,可以处理大规模数据集。
通过将数据分割、并行处理和自动故障转移等任务交给框架处理,开发人员可以专注于实现Map和Reduce函数,而不需要关心分布式系统的复杂性。