判别分析案例
- 格式:ppt
- 大小:3.99 MB
- 文档页数:49




图1由前面分析发现,协方差矩阵不等,可以考虑采用Separate-groups协方差矩阵。
输出结果表1-10:分類結果a被解释变量預測的群組成員資格總計Setosa 鸢尾花Versico-lor 鸢尾花Virginica 鸢尾花原始計數Setosa 鸢尾花50 0 0 50 Versico-lor 鸢尾花0 47 3 50Virginica 鸢尾花0 1 49 50 %Setosa 鸢尾花100.0 .0 .0 100.0 Versico-lor 鸢尾花.0 94.0 6.0 100.0 Virginica 鸢尾花.0 2.0 98.0 100.0a. 97.3% 個原始分組觀察值已正確地分類。
图2分類處理摘要已處理31 已排除遺漏或超出範圍群組代碼0至少一個遺漏識別變數0已在輸出中使用31群組的事前機率地区在前分析中使用的觀察值未加權加權1 .3332 2.0002 .333 2 2.0003 .333 1 1.000總計 1.000 5 5.000分類函數係數地区1 2 3人均食品支出.014 -.004 .021 人均衣着支出-.058 .024 -.092 (常數)-10.708 -3.645 -19.157 費雪 (Fisher) 線性區別函數图4 分類結果a地区預測的群組成員資格總計1 2 3原始計數 1 2 0 0 22 0 2 0 23 1 0 0 1未分組的觀察值8 18 0 26% 1 100.0 .0 .0 100.02 .0 100.0 .0 100.03 100.0 .0 .0 100.0未分組的觀察值30.8 69.2 .0 100.0a. 80.0% 個原始分組觀察值已正確地分類。
由表1-10可以看出,通过判别函数预测,有146个观测是分类正确的,其中,y=1组50个观测全部被判对,y=2组50个观测中有47个被判对,y=3组50个观测中有49个被判对,从而有97.3%的原始观测被判对。


例1. 现有分别来自总体A 和总体B 的两组随机样本,样本量分别为5和6,样本均值分别为⎪⎪⎭⎫⎝⎛00和⎪⎪⎭⎫⎝⎛23,样本离差阵分别为⎪⎪⎭⎫⎝⎛4004和⎪⎪⎭⎫ ⎝⎛5005.2。
今欲判别一个新样本⎪⎪⎭⎫⎝⎛2.11来自哪一个总体:(1). 请使用距离判别法(采用马氏距离)对上述新样本进行判别(不假设两个总体有相同的自协方差阵)。
(2). 请采用Fisher 判别法求出判别函数,并利用此判别函数对上述新样本进行判别。
解答:(1)、先求取新样本到不同总体均值的马氏距离: 44.22.11002.114004151002.112212=+=⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-'⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫⎝⎛=-AMD64.88.022232.115005.2161232.112212=+⨯=⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-'⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫⎝⎛=-B MD显然有22B AMD MD<,故此,应判别新样本来自总体A 。
(2) 、先求取线性判别函数: ⎪⎪⎭⎫ ⎝⎛=⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛+⎪⎪⎭⎫⎝⎛=-+=--9/213/600235005.24004)()(11)2()1(A BX XSSu线性判别函数为:X X u y u '⎪⎪⎭⎫⎝⎛='=9/213/6)(。
新样本的判别函数值:7282.02.119/213/6)()0(≈⎪⎪⎭⎫⎝⎛'⎪⎪⎭⎫ ⎝⎛=X u ; 总体A 的均值的判别函数值:0)(=A X u ;总体B 的均值的判别函数值:829.1239/213/6)(≈⎪⎪⎭⎫⎝⎛'⎪⎪⎭⎫⎝⎛=B X u ; 临界值:9977.00116829.1)()(≈+⨯=+++BA B B BA A A n n n X u n n n X u ;由于)()(B A X u X u <,且7282.0)()0(≈X u 小于临界值0.9977,所以应判别新样本来自总体A 。



Wilks 的 Lambda卡方df Sig.函数检验Wilks 的Lambda1 到2 .025 538.950 8 .0002 .774 37.3513 .000标准化的典型判别式函数系数函数1 2花萼长-.346 .039花萼宽-.525 .742花瓣长.846 -.386花瓣宽.613 .555-=0.613⨯⨯0.846-1+3460.525.0花萼长z花萼宽花瓣长⨯z花瓣宽zD⨯+z=0.555⨯+0.3860.742⨯20.039-⨯花萼宽花瓣长花瓣宽花萼长zzD⨯+zz结构矩阵函数1 2花瓣长.726*.165花萼宽-.121 .879*花瓣宽.651 .718*花萼长.221 .340*判别变量和标准化典型判别式函数之间的汇聚组间相关性按函数内相关性的绝对大小排序的变量。
*. 每个变量和任意判别式函数间最大的绝对相关性0.1550.196--=0.299.0花瓣宽.2526-0631zz花萼长z花萼宽⨯z花瓣长⨯D⨯+⨯+0.089-+-=0.271 978⨯2.60.0070.218z花萼长z花萼宽花瓣长花瓣宽zz⨯⨯+D⨯+区域图典则判别函数 2-16.0 -12.0 -8.0 -4.0 .0 4.0 8.0 12.0 16.0+---------+---------+---------+---------+---------+---------+---------+---------+16.0 + 13 +I 13 II 13 II 123 II 123 II 12 23 I12.0 + + + + 12 23 + + + +I 12 23 II 12 23 II 12 23 II 12 23 II 12 23 I8.0 + + + + 12 + 23 + + + +I 12 23 II 12 23 II 12 23 II 12 23 II 12 23 I4.0 + + + + 12 + 23 + + + +I 12 23 II 12 23 II 12 23 II 12 23 II 12 23 * I.0 + + + * + 12 + 23 + + +I 12 * 23 II 12 23 II 12 23 II 12 23 II 12 23 I-4.0 + + + + 12 + + 23 + + +I 12 23 II 12 23 II 12 23 II 12 23 II 12 23 I-8.0 + + + +12 + + 23 + + +I 12 23 II 12 23 II 12 23 II 12 23 II 12 23 I-12.0 + + + 12 + + 23 + +I 12 23 II 12 23 II 12 23 II 12 23 II 12 23 I-16.0 + 12 23 ++---------+---------+---------+---------+---------+---------+---------+---------+ -16.0 -12.0 -8.0 -4.0 .0 4.0 8.0 12.0 16.0典则判别函数 1区域图中使用的符号符号组标签---- -- --------------1 1 刚毛鸢尾花2 2 变色鸢尾花3 3 佛吉尼亚鸢尾花* 表示一个组质心。
实验、判别分析
一、实验名称:判别分析
二、实验目的:通过本实验掌握使用SPSS进行判别分析
三、实验过程:
1.判断解释变量是属性变量而解释变量是度量变量。
2.判断各组的变量得协方差矩阵相等,并用很简单的公式来计算判别函数和进行显著性检验。
3. 各判别变量间具有多元正态分布,精确计算显著性检验值和分组归属的概率。
四、分析结果:
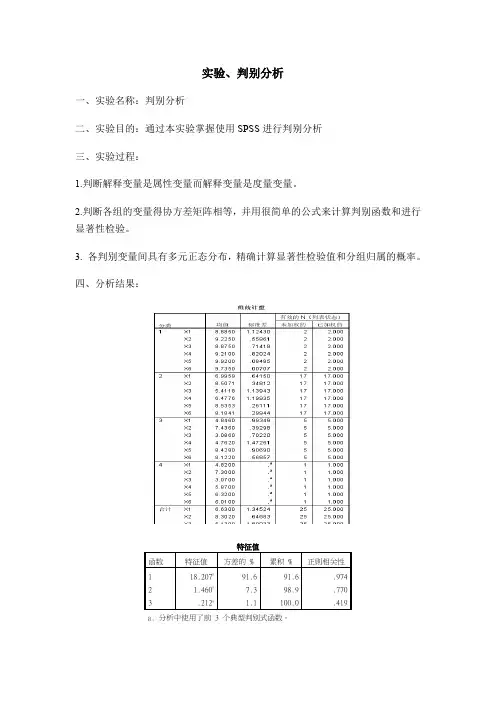
特征值
函数特征值方差的 % 累积 % 正则相关性
1 18.207a91.6 91.6 .974
2 1.460a7.
3 98.9 .770
3 .212a 1.1 100.0 .419
a. 分析中使用了前 3 个典型判别式函数。
从表显示出典型分析最终形成三个判别函数,判别函数F1的特征值为18.207,判别函数F2的特征值为1.460,判别函数F3的特征值为0.212.可见判别函数F1的判别能力大于F2和F3。
该表是非标准化的典型判别函数系数,写成函数为:
对原始数据中未进行分类的职工进行典型的判别分析。
得到结果如上图,可知职工号为26、27、28三个职工分别被判入了第三类和第四类。
数据:
表示工作产量,表示工作质量,表示工作出勤
表示工作损耗,表示工作态度,表示工作能力
五、心得体会:
通过判别,我们知道了当遇到需要识别一个个体所属类别的情况时,就能够运用自己所学的判别分析的知识,去解决这一类的问题,并能够准确的将其分类,甚至在遇到多重共线性问题,也能使用判别分析来解决。
通过此次的报告过程,我们对判别分析有了更进一步得认识,受益颇多。
判别分析假设有k 个总体,判别分析就是根据某个个体的观察值来推断该个体是来自这k 个总体中哪一个总体。
下面的例子说明判别分析有着广泛的应用。
(1)根据已有的气象资料,如气温、气压等判断明天是晴天还是阴天,是有雨还是无雨。
明天的天气情况是未来的行为。
因为是未来行为,难以得到它的完全信息。
已有的气象资料仅是它的一部分信息。
基于未来行为的不完全信息对未来行为进行预测是判别分析的一个应用。
(2)在非洲发现了一种头盖骨化石,考古学家要研究它究竟是像猿(如黑猩猩)还是像人。
倘若研究对象是活的,就能对他进行各方面的观察,有充足乃至完全的信息。
但研究对象早就死了,他的很多重要信息都丢失了。
考古学家只能根据不完全信息,如牙齿的长宽来进行判断。
当信息丢失后,对过去的行为进行判断是判别分析的另一个应用。
(3)有时人们难以得到完全的信息,这里有两种情况。
情况之一是信息完全只能来自破坏性试验。
例如,汽车的寿命只有在把它用坏之后才知道。
一般地,希望根据一些测量指标(如零部件的性能)就能事先对汽车的寿命作出判断。
情况之二是获得完全信息的代价太高。
例如,有些疾病可用代价昂贵的检查或通过手术得到确诊。
但人们往往更希望用便于观察得到的一些外部症状来诊断体内的疾病,以避免过大的开支和损失。
在完全信息难以得到时,对行为判断是判别分析的又一格应用。
正因为判别分析是基于不完全信息作出的判断,它就不可避免地会犯错误,一个好的判别法则错判的概率应很小。
除了错判概率,在判别分析问题中还应考虑费用,一个好的判别法则错误的损失应很小。
关于判别法则优良性的讨论从略。
判别分析问题的描述:设有k 个m 维总体k G G G ,,,21 ,其分布特征已知(如已知分布函数分别为)(,),(),(21x F x F x F k ,或知道来自各个总体的训练样本)。
对给定的一个新样品X ,我们要判断它来自哪个总体。
在进行判别归类时,由假设的前提,判别的依据及处理的手法不同,可得出不同判别方法。
第四章判别分析习题4.8(1)根据数据建立贝叶斯判别函数,并根据此判别函数对原样本进行回判。
(2)现有一新品牌的饮料在该超市试销,其销售价格为3.0,顾客对其口味评分为8,信任度评分平均为5,试预测该饮料的销售情况。
将数据导入SPSS,分析得到以下结果:1.典型判别函数的特征函数的特征值表表1-1 特征值表表1-1所示是典型判别函数的特征值表,只有两个判别函数,所以特征值只有2个。
函数1的特征值为17.791,函数2的特征值为0.720,判别函数的特征值越大,说明函数越具有区别判断力。
函数1方差的累积贡献率高达96.1%,且典型相关系数为0.973,而函数2方差的贡献率仅为3.9%,典型相关系数为0.647。
由此,说明函数1的区别判断力比函数2的强,函数1更具有区别判断力。
2.Wilks检验结果表1-2 Wilks 的Lambda上表中判别函数1和判别函数2的Wilks’Lambda值为0.031,判别函数2的Wilks’Lambda值为0.581。
“1到2”表示两个判别函数的平均数在三个类间的差异情况,P值=0.002<0.05表示差异达到显著水平“2”表示在排除了第一个判别函数后,第二个判别函数在三个组别间的差异情况,P值=0.197>0.05表示判别函数2未达到显著水平。
3.建立贝叶斯判别函数表1-3 贝叶斯判别法函数系数上表为贝叶斯判别函数的系数矩阵,用数学表达式表示各类的贝叶斯判别函数为:第一组:F1=-81.843-11.689X1+12.97X2+16.761X3第二组:F2=-94.536-10.707X1+13.361X2+17.086X3第三组:F3=-17.499-2.194X1+4.960X2+6.447X3将新品牌饮料样品的自变量值分别代入上述三个贝叶斯判别函数,得到三个函数值为:F1=65.271,F2=65.661,F3=47.884比较三个值,可以看出F2=65.661最大,据此得出新品牌饮料样品应该属于第二组,即该饮料的销售情况为平销。
一、案例背景随着现代人力资源管理理论的迅速开展,绩效考评技术水平也在不断提高。
绩效的多因性、多维性,要求对绩效实施多标准大样本科学有效的评价。
对企业来说,对上千人进展多达50~60个标准的考核是很常见的现象。
但是,目前多标准大样本大型企业绩效考评问题仍然困扰着许多人力资源管理从业人员。
为此,有必要将当今国际上最流行的视窗统计软件SPSS应用于绩效考评之中。
在分析企业员工绩效水平时,由于员工绩效水平的指标很多,各指标之间还有一定的关联性,缺乏有效的方法进展比拟。
目前较理想的方法是非参数统计方法。
本文将列举某企业的具体情况确定适当的考核标准,采用主成分分析以及聚类分析方法,比拟出各员工绩效水平,从而为企业绩效管理提供一定的科学依据。
最后采用判别分析建立判别函数,同时与原分类进展比拟。
聚类分析二、绩效考评的模型建立1、为了分析某企业绩效水平,按照综合性、可比性、实用性和易操作性的选取指标原那么,本文选择了影响某企业绩效水平的成果、行为、态度等6个经济指标(见表1)。
2、对某企业,搜集整理了28名员工2021年第1季度的数据资料。
构建1个28×6维的矩阵(见表2)。
3、应用SPSS数据统计分析系统首先对变量进展及主成分分析,找到样本的主成分及各变量在成分中的得分。
去结果中的表3、表4、表5备用。
表 5成份得分系数矩阵a成份1 2Zscore(X1) .227Zscore(X2) .228Zscore(X3) .224Zscore(X4) .177Zscore(X5) .186 .572Zscore(X6) .185 .587提取方法 :主成份。
构成得分。
a. 系数已被标准化。
4、从表3中可得到前两个成分的特征值大于1,分别为3.944和1.08,所以选取两个主成分。
根据累计奉献率超过80%的一般选取原那么,主成分1和主成分2的累计奉献率已到达了83.74%的水平,说明原来6个变量反映的信息可由两个主成分反映83.74%。
%--------------------------------------------------------------------------% 读取examp10_01.xls中数据,进行距离判别%--------------------------------------------------------------------------%********************************读取数据***********************************% 读取文件examp10_01.xls的第1个工作表中C2:F51范围的数据,即全部样本数据,包括未判企业sample = xlsread('examp10_01.xls','','C2:F51');% 读取文件examp10_01.xls的第1个工作表中C2:F47范围的数据,即已知组别的样本数据,training = xlsread('examp10_01.xls','','C2:F47');% 读取文件examp10_01.xls的第1个工作表中B2:B47范围的数据,即样本的分组信息数据,group = xlsread('examp10_01.xls','','B2:B47');obs = [1 : 50]'; % 企业的编号%**********************************距离判别*********************************% 距离判别,判别函数类型为mahalanobis,返回判别结果向量C和误判概率err[C,err] = classify(sample,training,group,'mahalanobis');[obs, C] % 查看判别结果err % 查看误判概率%--------------------------------------------------------------------------% 加载fisheriris.mat中数据,进行贝叶斯判别%--------------------------------------------------------------------------%********************************加载数据*********************************** load fisheriris % 把文件fisheriris.mat中数据导入MA TLAB工作空间%**********************************查看数据********************************* head0 = {'Obj', 'x1', 'x2', 'x3', 'x4', 'Class'}; % 设置表头[head0; num2cell([[1:150]', meas]), species] % 以元胞数组形式查看数据%*********************************贝叶斯判别********************************% 用meas和species作为训练样本,创建一个朴素贝叶斯分类器对象ObjBayesObjBayes = NaiveBayes.fit(meas, species);% 利用所创建的朴素贝叶斯分类器对象对训练样本进行判别,返回判别结果pre0,pre0也是字符串元胞向量pre0 = ObjBayes.predict(meas);% 利用confusionmat函数,并根据species和pre0创建混淆矩阵(包含总的分类信息的矩阵)[CLMat, order] = confusionmat(species, pre0);% 以元胞数组形式查看混淆矩阵[[{'From/To'},order'];order, num2cell(CLMat)]% 查看误判样品编号gindex1 = grp2idx(pre0); % 根据分组变量pre0生成一个索引向量gindex1gindex2 = grp2idx(species); % 根据分组变量species生成一个索引向量gindex2errid = find(gindex1 ~= gindex2) % 通过对比两个索引向量,返回误判样品的观测序号向量% 查看误判样品的误判情况head1 = {'Obj', 'From', 'To'}; % 设置表头% 用num2cell函数将误判样品的观测序号向量errid转为元胞向量,然后以元胞数组形式查看误判结果[head1; num2cell(errid), species(errid), pre0(errid)]% 对未知类别样品进行判别% 定义未判样品观测值矩阵xx = [5.8 2.7 1.8 0.735.6 3.1 3.8 1.86.1 2.5 4.7 1.16.1 2.6 5.7 1.95.1 3.16.5 0.625.8 3.7 3.9 0.135.7 2.7 1.1 0.126.4 3.2 2.4 1.66.7 3 1.9 1.16.8 3.57.9 1];% 利用所创建的朴素贝叶斯分类器对象对未判样品进行判别,返回判别结果pre1,pre1也是字符串元胞向量pre1 = ObjBayes.predict(x)%--------------------------------------------------------------------------% 加载fisheriris.mat中数据,进行Fisher判别%--------------------------------------------------------------------------%********************************加载数据*********************************** load fisheriris % 把文件fisheriris.mat中数据导入MA TLAB工作空间%**********************************待判样品********************************* % 定义待判样品观测值矩阵xx = [5.8 2.7 1.8 0.735.6 3.1 3.8 1.86.1 2.5 4.7 1.16.1 2.6 5.7 1.95.1 3.16.5 0.625.8 3.7 3.9 0.135.7 2.7 1.1 0.126.4 3.2 2.4 1.66.7 3 1.9 1.16.8 3.57.9 1];%*********************************Fisher判别********************************% 利用fisher函数进行判别,返回各种结果(见fisher函数的注释)[outclass,TabCan,TabL,TabCon,TabM,TabG] = fisher(x,meas,species)%************************绘制两个判别式得分的散点图************************** % 利用fisher函数进行判别,返回各种结果,其中ts为判别式得分[outclass,TabCan,TabL,TabCon,TabM,TabG,ts] = fisher(x,meas,species);% 提取各类的判别式得分ts1 = ts(ts(:,1) == 1,:); % setosa类的判别式得分ts2 = ts(ts(:,1) == 2,:); % versicolor类的判别式得分ts3 = ts(ts(:,1) == 3,:); % virginica类的判别式得分plot(ts1(:,2),ts1(:,3),'ko') % setosa类的判别式得分的散点图hold onplot(ts2(:,2),ts2(:,3),'k*') % versicolor类的判别式得分的散点图plot(ts3(:,2),ts3(:,3),'kp') % virginica类的判别式得分的散点图legend('setosa类','versicolor类','virginica类'); %加标注框xlabel('第一判别式得分'); %给X轴加标签ylabel('第二判别式得分'); %给Y轴加标签%************************只用一个判别式进行Fisher判别************************ % 令fisher函数的第4个输入为0.5,就可以只用一个判别式进行判别[outclass,TabCan,TabL,TabCon,TabM,TabG] = fisher(x,meas,species,0.5)function [outclass,TabCan,TabL,TabCon,TabM,TabG,trainscore] = fisher(sampledata,training,group,contri)%FISHER 判别分析.% class = fisher(sampledata,training,group) 根据训练样本training构造判别式,% 利用所有判别式对待判样品sampledata进行判别. sampledata和training是具有相同% 列数的矩阵,它们的每一行对应一个观测,每一列对应一个变量. group是training对% 应的分组变量,它的每一个元素定义了training中相应观测所属的类. group可以是一% 个分类变量,数值向量,字符串数组或字符串元胞数组. training和group必须具有相% 同的行数. fisher函数把group中的NaN或空字符串作为缺失数据,从而忽略training % 中相应的观测. class中的每个元素指定了sampledata中的相应观测所判归的类,它和% group具有相同的数据类型.%% class = fisher(sampledata,training,group,contri) 根据累积贡献率不低于% contri,确定需要使用的判别式个数,默认情况下,使用所有判别式进行判别. contri % 是一个在(0, 1]区间内取值的标量,用来指定累积贡献率的下限.%% [class, TabCan] = fisher(...)以表格形式返回所用判别式的系数向量,若contri% 取值为1,则返回所有判别式的系数向量. TabCan是一个元胞数组,形如% 'Variable' 'can1' 'can2'% 'x1' [-0.2087] [ 0.0065]% 'x2' [-0.3862] [ 0.5866]% 'x3' [ 0.5540] [-0.2526]% 'x4' [ 0.7074] [ 0.7695]% [class, TabCan, TabL] = fisher(...)以表格形式返回所有特征值,贡献率,累积% 贡献率等. TabL是一个元胞数组,形如% 'Eigenvalue' 'Difference' 'Proportion' 'Cumulative'% [ 32.1919] [ 31.9065] [ 0.9912] [ 0.9912]% [ 0.2854] [] [ 0.0088] [ 1]%% [class, TabCan, TabL, TabCon] = fisher(...)以表格形式返回混淆矩阵(包含总% 的分类信息的矩阵). TabCon是一个元胞数组,形如% 'From/To' 'setosa' 'versicolor' 'virginica'% 'setosa' [ 50] [ 0] [ 0]% 'versicolor' [ 0] [ 48] [ 2]% 'virginica' [ 0] [ 1] [ 49]%% [class, TabCan, TabL, TabCon, TabM] = fisher(...)以表格形式返回误判矩阵.% TabM是一个元胞数组,形如% 'Obj' 'From' 'To'% [ 71] 'versicolor' 'virginica'% [ 84] 'versicolor' 'virginica'% [134] 'virginica' 'versicolor'%% [class, TabCan, TabL, TabCon, TabM, TabG] = fisher(...)将所用判别式作用% 在各组的组均值上,得到组均值投影矩阵,以表格形式返回这个矩阵. TabG是一个元胞% 数组,形如% 'Group' 'can1' 'can2'% 'setosa' [-1.3849] [1.8636]% 'versicolor' [ 0.9892] [1.6081]% 'virginica' [ 1.9852] [1.9443]% [class, TabCan, TabL, TabCon, TabM, TabG, trainscore] = fisher(...)返回% 训练样品所对应的判别式得分trainscore. trainscore的第一列为各训练样品原本所% 属类的类序号,第i+1列为第i个判别式得分.%% Copyright 2009 xiezhh.% $Revision: 1.0.0.0 $ $Date: 2009/10/03 10:40:34 $if nargin < 3error('错误:输入参数太少,至少需要3个输入.');end% 根据分组变量生成索引向量gindex,组名元胞向量groups,组水平向量glevels [gindex,groups,glevels] = grp2idx(group);% 忽略缺失数据nans = find(isnan(gindex));if ~isempty(nans)training(nans,:) = [];gindex(nans) = [];endngroups = length(groups);gsize = hist(gindex,1:ngroups);nonemptygroups = find(gsize>0);nusedgroups = length(nonemptygroups);% 判断是否有空的组if ngroups > nusedgroupswarning('警告: 有空的组.');end[n,d] = size(training);if size(gindex,1) ~= nerror('错误: 输入参数大小不匹配,GROUP与TRAINING必须具有相同的行数.'); elseif isempty(sampledata)sampledata = zeros(0,d,class(sampledata));elseif size(sampledata,2) ~= derror('错误: 输入参数大小不匹配,SAMPLEDATA与TRAINING必须具有相同的列数.'); end% 设置contri的默认值为1,并限定contri在(0, 1]内取值if nargin < 4 || isempty(contri)contri = 1;endif ~isscalar(contri) || contri > 1 || contri <= 0error('错误: contri 必须是一个在(0, 1]内取值的标量.');endif any(gsize == 1)error('错误: TRAINING中的每个组至少应有两个观测.');end% 计算各组的组均值gmeans = NaN(ngroups, d);for k = nonemptygroupsgmeans(k,:) = mean(training(gindex==k,:),1);end% 计算总均值totalmean = mean(training,1);% 计算组内离差平方和矩阵E和组间离差平方和矩阵BE = zeros(d);B = E;for k = nonemptygroups% 分别估计各组的组内离差平方和矩阵.[Q,Rk] = qr(bsxfun(@minus,training(gindex==k,:),gmeans(k,:)), 0);% 各组的组内离差平方和矩阵:AkHat = Rk'*Rk% 判断各组的组内离差平方和矩阵的正定性s = svd(Rk);if any(s <= max(gsize(k),d) * eps(max(s)))error('错误: TRAINING中各组的组内离差平方和矩阵必须是正定矩阵.');endE = E + Rk'*Rk; % 计算总的组内离差平方和矩阵E% 计算组间离差平方和矩阵BB = B + (gmeans(k,:) - totalmean)'*(gmeans(k,:) - totalmean)*gsize(k);end% 求inv(E)*B的正特征值与相应的特征向量EB = E\B;[V, D] = eig(EB);D = diag(D);[D, idD] = sort(D,'descend'); %将特征值按降序排列V = V(:,idD);NumPosi = min(ngroups-1, d); %确定正特征值个数D = D(1:NumPosi, :);CumCont = cumsum(D/sum(D)); %计算累积贡献率% 以表格形式返回所有特征值,贡献率,累积贡献率等. TabL是一个元胞数组head = {'Eigenvalue', 'Difference', 'Proportion', 'Cumulative'};TabL = cell(NumPosi+1, 4);TabL(1,:) = head;TabL(2:end,1) = num2cell(D);if NumPosi == 1TabL(2:end-1,2) = {0};elseTabL(2:end-1,2) = num2cell(-diff(D));endTabL(2:end,3) = num2cell(D/sum(D));TabL(2:end,4) = num2cell(CumCont);% 根据累积贡献率的下限contri确定需要使用的判别式个数CumContGeCon CumContGeCon = find(CumCont >= contri);CumContGeCon = CumContGeCon(1);V = V(:, 1:CumContGeCon); %需要使用的判别式系数矩阵% 以表格形式返回所用判别式的系数向量,若contri取值为1,% 则返回所有判别式的系数向量. TabCan是一个元胞数组TabCan = cell(d+1, CumContGeCon+1);TabCan(1, 1) = {'Variable'};TabCan(2:end, 1) = strcat('x',cellstr(num2str((1:d)')));TabCan(1, 2:end) = strcat('can',cellstr(num2str((1:CumContGeCon)')));TabCan(2:end, 2:end) = num2cell(V);% 将训练样品与待判样品放在一起进行判别m = size(sampledata,1);gv = gmeans*V;stv = [sampledata; training]*V;nstv = size(stv, 1);message = '';outclass = NaN(nstv, 1);for i = 1:nstvobji = bsxfun(@minus,stv(i,:),gv);obji = sum(obji.^2, 2);idclass = find(obji == min(obji));if length(idclass) > 1idclass = idclass(1);message = '警告: 出现了一个或多个结';endoutclass(i) = idclass;endwarning(message);trclass = outclass(m+(1:n)); %训练样品的判别结果(由类序号构成的向量)outclass = outclass(1:m); %待判样品的判别结果(由类序号构成的向量)outclass = glevels(outclass,:); %将待判样品的判别结果进行一个类型转换trg1 = groups(gindex); %训练样品的初始类名称trg2 = groups(trclass); %训练样品经判别后的类名称% 以表格形式返回混淆矩阵(包含总的分类信息的矩阵). TabCon是一个元胞数组[CLMat, order] = confusionmat(trg1,trg2);TabCon = [[{'From/To'},order'];order, num2cell(CLMat)];% 以表格形式返回误判矩阵. TabM是一个元胞数组miss = find(gindex ~= trclass); %训练样品中误判样品的编号head1 = {'Obj', 'From', 'To'};TabM = [head1; num2cell(miss), trg1(miss), trg2(miss)];% 将所用判别式作用在各组的组均值上,得到组均值投影矩阵,以表格形式返回这个矩阵. % TabG是一个元胞数组TabG = cell(ngroups+1,CumContGeCon+1);TabG(:,1) = [{'Group'};groups];TabG(1,2:end) = strcat('can',cellstr(num2str((1:CumContGeCon)')));TabG(2:end,2:end) = num2cell(gv);% 计算训练样品所对应的判别式得分trainscore = training*V;trainscore = [gindex, trainscore];。
spss判别分析案例详解SPSS判别分析案例详解。
在统计学中,判别分析是一种用于确定不同组别之间差异的统计方法。
它可以帮助我们理解不同变量之间的关系,以及这些变量在预测和分类方面的作用。
在本文中,我们将通过一个实际的案例来详细介绍如何使用SPSS进行判别分析。
案例背景:假设我们是一家电子商务公司的数据分析师,我们想要确定哪些因素对于用户购买高价值产品的决策具有影响力。
我们收集了一些用户的个人信息和他们的购买行为数据,希望通过判别分析找出影响用户购买高价值产品的关键因素。
数据准备:首先,我们需要将收集到的数据导入SPSS软件中。
在导入数据后,我们可以对数据进行初步的检查,确保数据的完整性和准确性。
接下来,我们需要选择判别分析作为我们的分析方法,并将购买高价值产品作为分类变量,个人信息和购买行为数据作为判别变量。
分析步骤:1. 设定判别分析的目的和假设,在进行判别分析之前,我们需要明确分析的目的是什么,以及我们的假设是什么。
在这个案例中,我们的目的是找出影响用户购买高价值产品的关键因素,我们的假设是个人信息和购买行为数据会对用户的购买决策产生影响。
2. 进行判别分析,在设定好目的和假设后,我们可以开始进行判别分析。
SPSS 会根据我们选择的分类变量和判别变量,自动进行变量选择和模型拟合,得出判别函数和判别系数。
通过判别函数和判别系数,我们可以了解每个判别变量对于不同组别的影响程度,以及它们对于用户购买高价值产品的预测能力。
3. 结果解释,在得出判别函数和判别系数后,我们需要对结果进行解释。
我们可以通过判别函数的系数来理解每个判别变量对于用户购买高价值产品的影响程度,以及它们之间的相互关系。
同时,我们还可以通过判别系数的大小来评估判别模型的预测能力和区分能力。
案例分析:通过对案例数据的判别分析,我们得出了以下结论:1. 个人收入、年龄和教育程度是影响用户购买高价值产品的重要因素,其中个人收入对用户购买高价值产品的影响最大,其次是年龄和教育程度。