判别分析实例汇总
- 格式:pdf
- 大小:242.86 KB
- 文档页数:20

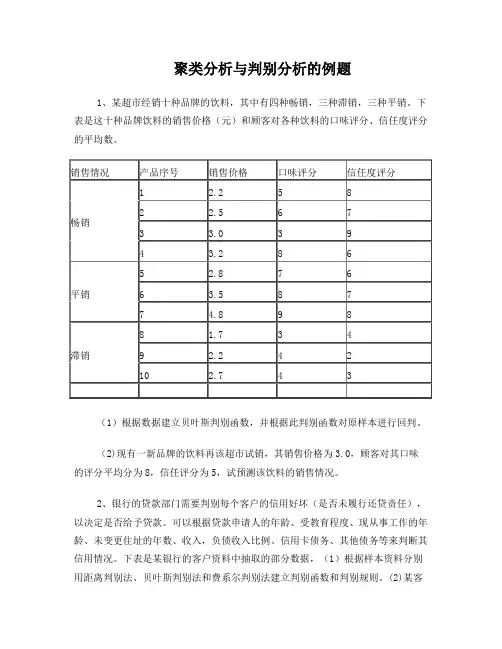
聚类分析与判别分析的例题1、某超市经销十种品牌的饮料,其中有四种畅销,三种滞销,三种平销。
下表是这十种品牌饮料的销售价格(元)和顾客对各种饮料的口味评分、信任度评分的平均数。
(1)根据数据建立贝叶斯判别函数,并根据此判别函数对原样本进行回判。
(2)现有一新品牌的饮料再该超市试销,其销售价格为3.0,顾客对其口味的评分平均分为8,信任评分为5,试预测该饮料的销售情况。
2、银行的贷款部门需要判别每个客户的信用好坏(是否未履行还贷责任),以决定是否给予贷款。
可以根据贷款申请人的年龄、受教育程度、现从事工作的年龄、未变更住址的年数、收入,负债收入比例、信用卡债务、其他债务等来判断其信用情况。
下表是某银行的客户资料中抽取的部分数据,(1)根据样本资料分别用距离判别法、贝叶斯判别法和费系尔判别法建立判别函数和判别规则。
(2)某客户的如上情况资料为(53,1,9,18,50,11,20,2.02,3.58),对其进行信用好坏的判别。
目前信用好坏客户序号已履行还贷责任1 23 1 7 2 31 6.6 0.34 1.712 34 1 173 59 8.0 1.81 2.913 42 2 7 23 41 4.6 0.94 0.944 39 1 195 48 13.1 1.93 4.365 35 1 9 1 34 5.0 0.40 1.30未履行还贷责任6 37 1 1 3 24 15.1 1.80 1.827 29 1 13 1 42 7.4 1.46 1.658 32 2 11 6 75 23.3 7.76 9.729 28 2 2 3 23 6.4 0.19 1.2910 26 1 4 3 27 10.5 2.47 0.363、从胃癌患者、萎缩性胃炎患者和非胃炎患者中分别抽取五个病人进行思想生化指标的化验:血清铜蛋白、蓝色反应、尿吲哚乙酸和中性硫化物,数据见下表。
试用距离判别法建立判别函数,并根据此判别函数对原样本进行回判。



例:研究某年全国各地区农民家庭收支的分布规律,根据抽样调查资料进行分类,共抽取28个省、市、自治区的六个指标数据。
先采用聚类分析,将28个省、市、自治区分为三组。
北京、上海、广州3个城市属于待判样本。
(家庭收支.sav)1.选中判别分析,2.选择Fisher 即bayes判别分析方法,易混!!!3.确定组别4. 选择保存结果5. 模型检验(即判别准确率)重要结果分类函数系数类别1 2 3食品.480 .473 .429 衣着 1.612 1.354 .933 燃料 2.421 2.189 .777 住房.555 .335 .052 用品及其它 1.032 .580 .847 文化支出 5.387 5.446 4.317(常量) -117.620 -89.052 -53.616Fisher 的线性判别式函数按照案例顺序的统计量案例数目实际组最高组第二最高组判别式得分预测组P(D>d |G=g)P(G=g| D=d)到质心的平方Mahalanobis距离组P(G=g| D=d)到质心的平方Mahalanobis距离函数1函数2 p df初始 1 1 1 .320 2 1.000 2.282 2 .000 22.754 3.163 -2.7172 1 1 .799 2 1.000 .449 2 .000 17.611 3.559 -1.6593 1 2**.095 2 .688 4.705 1 .312 6.283 2.737 1.2754 1 1 .797 2 .984 .453 2 .016 8.670 2.855 -.5695 1 1 .504 2 1.000 1.372 2 .000 20.770 4.205 -1.4616 1 1 .313 2 .996 2.321 2 .004 13.305 1.847 -2.1317 2 2 .788 2 .986 .476 1 .011 9.482 .566 .5958 2 2 .405 2 .992 1.806 1 .008 11.456 1.756 1.9139 2 2 .532 2 .987 1.263 1 .013 9.942 1.645 1.60710 2 2 .451 2 .999 1.593 1 .001 15.008 1.358 2.26911 2 2 .826 2 .984 .383 1 .015 8.758 .816 .71812 2 2 .769 2 .994 .524 1 .006 10.742 1.252 1.52313 2 2 .378 2 .861 1.945 3 .139 5.594 -.611 .53914 2 2 .219 2 .639 3.034 3 .361 4.179 -1.036 .60515 2 2 .304 2 .941 2.379 3 .059 7.903 -.943 1.59616 2 2 .935 2 .997 .134 1 .003 12.046 .874 1.48517 3 3 .387 2 .994 1.899 2 .006 12.039 -1.570 -1.44818 3 3 .801 2 1.000 .443 2 .000 19.449 -3.157 -1.07619 3 3 .413 2 .991 1.767 2 .009 11.104 -1.531 -1.30320 3 3 .570 2 .984 1.124 2 .016 9.398 -1.635 -.84721 3 3 .880 2 .997 .255 2 .003 11.791 -2.562 -.12822 3 3 .826 2 .993 .383 2 .007 10.155 -2.282 -.14023 3 3 .130 2 1.000 4.077 2 .000 29.305 -4.643 -.18324 3 3 .078 2 .995 5.095 2 .005 15.558 -3.369 1.52625 3 3 .323 2 1.000 2.260 2 .000 25.638 -3.294 -1.98926 未分组的1 .0002 1.000 20.223 2 .000 62.899 7.054 -3.27827 未分组的1 .0002 1.000 82.160 2 .000 150.236 11.796 -3.63028 未分组的1 .0052 1.000 10.431 2 .000 25.808 5.621 .759交叉验证a 1 1 1 .349 6 1.000 6.707 2 .000 27.3012 1 1 .025 6 .999 14.400 2 .001 29.4123 1 2**.087 6 1.000 11.051 1 .000 37.7404 1 1 .233 6 .900 8.064 2 .100 12.4595 1 1 .136 6 1.000 9.738 2 .000 28.7186 1 1 .182 6 .975 8.851 2 .025 16.1797 2 2 .249 6 .945 7.850 1 .043 14.0428 2 2 .734 6 .984 3.575 1 .016 11.8079 2 2 .039 6 .880 13.285 1 .120 17.26810 2 2 .078 6 .996 11.349 1 .004 22.46511 2 2 .701 6 .967 3.819 1 .031 10.68312 2 2 .461 6 .984 5.669 1 .016 13.90313 2 3**.129 6 .703 9.898 2 .297 11.62214 2 3**.444 6 .684 5.820 2 .316 7.36815 2 2 .123 6 .635 10.047 3 .365 11.15116 2 2 .000 6 .878 35.006 1 .121 38.97317 3 3 .114 6 .955 10.252 2 .044 16.40718 3 3 .925 6 1.000 1.939 2 .000 20.37119 3 3 .288 6 .959 7.373 2 .041 13.67820 3 3 .652 6 .963 4.186 2 .037 10.70721 3 3 .526 6 .991 5.139 2 .009 14.63422 3 3 .834 6 .986 2.792 2 .014 11.30223 3 3 .101 6 1.000 10.616 2 .000 39.41124 3 3 .018 6 .917 15.261 2 .083 20.05725 3 3 .268 6 1.000 7.611 2 .000 32.555对初始数据来说,平方Mahalanobis 距离基于典则函数。

例1. 现有分别来自总体A 和总体B 的两组随机样本,样本量分别为5和6,样本均值分别为⎪⎪⎭⎫⎝⎛00和⎪⎪⎭⎫⎝⎛23,样本离差阵分别为⎪⎪⎭⎫⎝⎛4004和⎪⎪⎭⎫ ⎝⎛5005.2。
今欲判别一个新样本⎪⎪⎭⎫⎝⎛2.11来自哪一个总体:(1). 请使用距离判别法(采用马氏距离)对上述新样本进行判别(不假设两个总体有相同的自协方差阵)。
(2). 请采用Fisher 判别法求出判别函数,并利用此判别函数对上述新样本进行判别。
解答:(1)、先求取新样本到不同总体均值的马氏距离: 44.22.11002.114004151002.112212=+=⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-'⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫⎝⎛=-AMD64.88.022232.115005.2161232.112212=+⨯=⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-'⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫⎝⎛=-B MD显然有22B AMD MD<,故此,应判别新样本来自总体A 。
(2) 、先求取线性判别函数: ⎪⎪⎭⎫ ⎝⎛=⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫ ⎝⎛-⎪⎪⎭⎫ ⎝⎛⎪⎪⎭⎫⎝⎛⎪⎪⎭⎫ ⎝⎛+⎪⎪⎭⎫⎝⎛=-+=--9/213/600235005.24004)()(11)2()1(A BX XSSu线性判别函数为:X X u y u '⎪⎪⎭⎫⎝⎛='=9/213/6)(。
新样本的判别函数值:7282.02.119/213/6)()0(≈⎪⎪⎭⎫⎝⎛'⎪⎪⎭⎫ ⎝⎛=X u ; 总体A 的均值的判别函数值:0)(=A X u ;总体B 的均值的判别函数值:829.1239/213/6)(≈⎪⎪⎭⎫⎝⎛'⎪⎪⎭⎫⎝⎛=B X u ; 临界值:9977.00116829.1)()(≈+⨯=+++BA B B BA A A n n n X u n n n X u ;由于)()(B A X u X u <,且7282.0)()0(≈X u 小于临界值0.9977,所以应判别新样本来自总体A 。



实验、判别分析
一、实验名称:判别分析
二、实验目的:通过本实验掌握使用SPSS进行判别分析
三、实验过程:
1.判断解释变量是属性变量而解释变量是度量变量。
2.判断各组的变量得协方差矩阵相等,并用很简单的公式来计算判别函数和进行显著性检验。
3. 各判别变量间具有多元正态分布,精确计算显著性检验值和分组归属的概率。
四、分析结果:
特征值
函数特征值方差的 % 累积 % 正则相关性
1 18.207a91.6 91.6 .974
2 1.460a7.
3 98.9 .770
3 .212a 1.1 100.0 .419
a. 分析中使用了前 3 个典型判别式函数。
从表显示出典型分析最终形成三个判别函数,判别函数F1的特征值为18.207,判别函数F2的特征值为1.460,判别函数F3的特征值为0.212.可见判别函数F1的判别能力大于F2和F3。
该表是非标准化的典型判别函数系数,写成函数为:
对原始数据中未进行分类的职工进行典型的判别分析。
得到结果如上图,可知职工号为26、27、28三个职工分别被判入了第三类和第四类。
数据:
表示工作产量,表示工作质量,表示工作出勤
表示工作损耗,表示工作态度,表示工作能力
五、心得体会:
通过判别,我们知道了当遇到需要识别一个个体所属类别的情况时,就能够运用自己所学的判别分析的知识,去解决这一类的问题,并能够准确的将其分类,甚至在遇到多重共线性问题,也能使用判别分析来解决。
通过此次的报告过程,我们对判别分析有了更进一步得认识,受益颇多。
第五章 判别分析1、 已知两总体的概率密度分别为f 1(x )和f 2(x ),且总体的先验分布为p1=0.2,p2=0.8,误判损失为c (2|1)=50,c (1|2)=100. (1) 建立Bayes 判别准则(2) 设有一个新样品x 0满足f1(x 0)=6.3,f 2(x 0)=0.5,判定x 0的归属 解: (1)在X 处的值,判定:X ∈G 1,1()2()f x f x ≥2(1|2)1(2|1)q c q c ,即1()2()f x f x ≥8X ∈G 2,1()2()f x f x 2(1|2)1(2|1)q c q c ,即1()2()f x f x 8(2)1(0)2(0)f x f x =12.6≥8,故x 0∈G 12、某商学院在招收研究生时,以学生在大学期间的平均学分x 1与管理能力考试成绩x 2帮助录取研究生,对申请者划分为3类。
G 1:录取;G 2:未录取;G 3:待定。
下表记录了近期报考者的值和录取情况。
(1)在先验概率相等的假定下,进行Bayes 判别,并确定回代和交叉确认误判率;(2)在先验概率由样本比例计算的假定下,进行Bayes 判别,并确定回代和交叉确认误判率;(3)设有两名新申请者的(x 1,x 2)分别为(3.61,513)和(2.91,497),利用所建立判别准则判别他们应该归为哪一类? 解:(1)回代误判率:8/85=0.0941,交叉确认误判率同样为8/85=0.0941,第2号、3号、24号、30号、31号、58号、74号、75号被误判。
(2)号、30号、31号、58号、74号、75号被误判。
(3)建立Fisher线性判别准则W1=-151.902+60.431X1+0.172X2W2=-89.815+45.255X1+0.138X2W3=-110.818+53.024X1+0.137X2把(3.61,513)代入以上三式,W1=154.48991,W2=144.34955,W3=150.87964把(2.91,497)代入以上三式,W1=109.43621,W2=110.46305,W3=111.57084故第一个申请者判为W1(W1最大),第二个申请者判为W3(W3最大)。
判别分析假设有k 个总体,判别分析就是根据某个个体的观察值来推断该个体是来自这k 个总体中哪一个总体。
下面的例子说明判别分析有着广泛的应用。
(1)根据已有的气象资料,如气温、气压等判断明天是晴天还是阴天,是有雨还是无雨。
明天的天气情况是未来的行为。
因为是未来行为,难以得到它的完全信息。
已有的气象资料仅是它的一部分信息。
基于未来行为的不完全信息对未来行为进行预测是判别分析的一个应用。
(2)在非洲发现了一种头盖骨化石,考古学家要研究它究竟是像猿(如黑猩猩)还是像人。
倘若研究对象是活的,就能对他进行各方面的观察,有充足乃至完全的信息。
但研究对象早就死了,他的很多重要信息都丢失了。
考古学家只能根据不完全信息,如牙齿的长宽来进行判断。
当信息丢失后,对过去的行为进行判断是判别分析的另一个应用。
(3)有时人们难以得到完全的信息,这里有两种情况。
情况之一是信息完全只能来自破坏性试验。
例如,汽车的寿命只有在把它用坏之后才知道。
一般地,希望根据一些测量指标(如零部件的性能)就能事先对汽车的寿命作出判断。
情况之二是获得完全信息的代价太高。
例如,有些疾病可用代价昂贵的检查或通过手术得到确诊。
但人们往往更希望用便于观察得到的一些外部症状来诊断体内的疾病,以避免过大的开支和损失。
在完全信息难以得到时,对行为判断是判别分析的又一格应用。
正因为判别分析是基于不完全信息作出的判断,它就不可避免地会犯错误,一个好的判别法则错判的概率应很小。
除了错判概率,在判别分析问题中还应考虑费用,一个好的判别法则错误的损失应很小。
关于判别法则优良性的讨论从略。
判别分析问题的描述:设有k 个m 维总体k G G G ,,,21 ,其分布特征已知(如已知分布函数分别为)(,),(),(21x F x F x F k ,或知道来自各个总体的训练样本)。
对给定的一个新样品X ,我们要判断它来自哪个总体。
在进行判别归类时,由假设的前提,判别的依据及处理的手法不同,可得出不同判别方法。
例:人文与发展指数是联合国开发计划署于 1990 年 5 月发表的第一份《人类发展报告》中公布的。
该报告建议,目前对人文发展的衡量指标应当以人生的三大要素为重点。
衡量人生的三大要素的指标分别为:实际人均 GDP 指数、出生时的预期寿命指数、受教育程度指数(由成人识字率指数和综合总人学率指数按 2/3、 1/3 的权重加权而得),将一生三个指数合成为一个指数就是人文发展指数。
今从 2007 年世界各国人文发展指数 (2005 年) 的排序中,选取高发展水平、中等发展水平和低发展水平国家各 6 个作为三组样品,另选四个国家作为待判样品,资料如下表所示。
试用判别分析过程对以下数据资料进行判别分析,并据此对待选的四个国家进行判别归类。
国家人均 GDP(美出生时的预成人识字率初等、中等和元) 期寿命(岁)(%) 高等教育入学率(%)第一类:高发美国41890 77.9 99.5 93.3 展水平国家德国29461 79.1 99.2 88希腊23381 78.9 96 99新加坡29663 79.4 92.5 87.3意大利28529 80.3 98.4 90.6韩国22029 77.9 99 96第二类:中等古巴6000 77.799.8 87.6发展水平国罗马尼亚906071.997.376.8家巴西8402 71.7 88.6 87.5 泰国8677 69.6 92.6 71.2data develop;input type gdp life rate zhrate@@;cards ;1 41890 77.9 99.5 93.31 29461 79.1 99.2 881 23381 78.9 96 991 29663 79.4 92.5 87.31 28529 80.3 98.4 90.61 22029 77.9 99 962 6000 77.7 99.8 87.62 9060 71.9 97.3 76.82 8402 71.7 88.6 87.52 8677 69.6 92.6 71.22 5137 71 92.6 81.12 8407 71.4 87.4 68.73 1550 62.6 48.6 58.13 1128 46.5 69.1 56.23 2299 49.8 67.9 62.33 2370 64.6 49.9 403 3071 73.7 90.3 63.93 3843 69.7 90.4 68.2. 31267 82.3 99 85.9. 3452 63.7 61 63.8. 6757 72.5 90.9 69.1. 11110 50.8 82.4 77;proc discrim simple wcov distance list;/*simple:要求技术各类样品的简单描述统计量;选项WCOV要求计算类内协方差阵;选项DISTANCE要求计算马氏距离;选项LIST要求输出重复替换归类结果。