判别分析解明明
- 格式:ppt
- 大小:501.58 KB
- 文档页数:13



判别分析导言判别分析是统计学中一种常用的数据分析方法,用于区分不同群体或类别之间的差异。
它通过寻找最佳的分类边界,帮助我们预测或判定未知样本的分类。
判别分析常用于模式识别、数据挖掘、生物学、医学等领域。
本文将介绍判别分析的基本概念、应用领域和算法。
一、判别分析的基本概念判别分析旨在通过构造合适的判别函数,将不同群体或类别的样本区分开来。
判别函数的建立是判别分析的核心任务,而判别函数的类型通常根据问题的特点来选择。
常见的判别函数有线性判别函数、二次判别函数、贝叶斯判别函数等。
判别分析的目标是使得样本在不同类别的判别函数值有较大差异。
二、判别分析的应用领域1. 模式识别判别分析在模式识别中的应用非常广泛。
通过判别分析,我们可以建立能够识别不同模式的模型。
例如,在人脸识别任务中,我们可以使用判别分析来建立一个分类器,能够将不同人脸的图像正确分类。
2. 数据挖掘在数据挖掘领域,判别分析可以帮助我们发现变量之间的关系,并进行预测。
通过对已有数据进行判别分析,我们可以预测未知样本的分类。
例如,在市场营销中,通过对消费者进行判别分析,我们可以预测消费者的购买行为,从而制定更精准的营销策略。
3. 生物学和医学判别分析在生物学和医学领域中也有广泛的应用。
例如,在癌症诊断中,通过对患者的临床数据进行判别分析,我们可以建立一个分类器,能够判断该患者是否患有癌症。
三、判别分析的算法判别分析的算法根据问题的特点和要求选择。
下面介绍两种常见的判别分析算法:1. 线性判别分析(LDA)线性判别分析是一种常见且简单的判别分析算法。
它的核心思想是通过将高维数据映射到低维空间中,使得不同类别的样本在投影空间中有较大的差异。
在LDA算法中,我们需要计算类内散度矩阵和类间散度矩阵,并求解其特征值和特征向量,从而确定投影向量。
2. 二次判别分析(QDA)二次判别分析是一种更为复杂的判别分析算法。
它假设不同类别的样本的协方差矩阵不相等,即每个类别内部的变化程度不同。


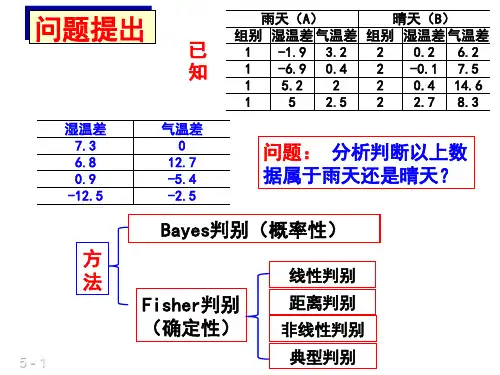
判别分析距离判别分析距离判别的最直观的想法是计算样品到第i类总体的平均数的距离,哪个跖离最小就将它判归哪个总体,所以,我们首先考虑的是是否能够构造一个恰当的距离函数,通过样本与某类别之间距离的大小,判别其所属类别。
设X=(s……以n)'和Y = O1,……,%)'是从期望为|1=(血,……川Q '和方差阵Y= (Ou)>0的总体G抽得的两个观测值,则称X与Y之间的马氏距离为:y mxmd2 =(X-Y)样本X与G,之间的马氏距离定义为X与类重心间的距离,即:9护=(乂一地)丫7(乂一&)i = 1,2・・.・・.,k附注:1、马氏距离与欧式距离的关联:为=1,马氏距离转换为欧式距离;2、马氏距离与欧式距离的差异:马氏距离不受计暈单位的影响,马氏距离是标准化的欧式距离两总体距离判别先考虑两个总体的情况,设有两个协差阵E相同的p维正态总体,对给定的样本Y,判别一个样本Y到底是来自哪一个总体,一个最直观的想法是计算Y到两个总体的距离。
故我们用马氏距离来给定判别规则,有:如/(y, J2(y, G2),<yeGp 如〃2(y, G2)<d2(y9 Gj待判,如=〃2(y,G2)沪(y,Gj=(y 2)' "(y 2)(y J' L(y J=y- 2y为一1角 + “;賞“2 -(y^1y-2y^1 + 冲?如) =2y 0一1 (" - 角)-("i + “2)尸(“i - “2)= 2[y —丫》-“2)2令"=1虽« = Z_1(//1-//2) = (a1,a2,-.-,a p yW(y) = (y - p)U = a f(y一p.)= a1(y1-/z1) + --- + a p(y p-/7p)= a'y _a'ji则前面的判别法则表示为y w Gp 如W (y) > 0,y e G2,如FT (y ) < 0o待判,如W(Y) = 0当忙“2和刀已知时, "1 2)是一个已知的P维向量,W (y)是y的线性函数,称为线性判别函数。


判别分析四种方法判别分析(Discriminant Analysis)是一种用于分类问题的统计方法, 它通过分析已知分类的样本数据,构造出一个判别函数,然后将未知类别的样本数据带入判别函数进行分类。
判别分析可以用于研究变量之间的关系以及确定分类模型等方面。
在判别分析中,有四种主要的方法,包括线性判别分析(Linear Discriminant Analysis, LDA)、二次判别分析(Quadratic Discriminant Analysis, QDA)、多重判别分析(Multiple Discriminant Analysis, MDA)和正则化判别分析(Regularized Discriminant Analysis, RDA)。
1.线性判别分析(LDA):线性判别分析是最常用的判别分析方法之一、它假设每个类别的样本数据都服从多元正态分布,并且各个类别具有相同的协方差矩阵。
基于这些假设,LDA通过计算类别间离散度矩阵(Sb)和类别内离散度矩阵(Sw),然后求解广义瑞利商的最大化问题,得到最佳的线性判别函数。
线性判别分析适用于样本类别数量较少或样本维度较高的情况。
2.二次判别分析(QDA):二次判别分析是基于类别的样本数据服从多元正态分布的假设构建的。
与LDA不同的是,QDA没有假设各个类别具有相同的协方差矩阵。
相反,QDA为每个类别计算一个特定的协方差矩阵,并将其带入到判别函数中进行分类。
由于QDA考虑了类内协方差矩阵的差异,因此在一些情况下可以提供比LDA更好的分类效果。
3.多重判别分析(MDA):4.正则化判别分析(RDA):正则化判别分析是近年来提出的一种改进的判别分析方法。
与LDA和QDA不同的是,RDA通过添加正则化项来解决维度灾难问题,以及对输入数据中的噪声进行抑制,从而提高分类的准确性。
正则化项的引入使得RDA可以在高维数据集上进行有效的特征选择,并获得更鲁棒的判别结果。

判别分析汇报范文判别分析(Discriminant Analysis)是一种多元统计分析方法,它通过建立线性分类器,将样本根据其特征的分布情况划分到多个预先定义好的类别中。
判别分析在许多实际问题中都有广泛的应用,如金融风险评估、疾病诊断、情感识别等。
在本次汇报中,我将介绍判别分析的基本原理和步骤,以及如何进行判别分析的模型评估和结果解释。
一、判别分析的基本原理判别分析的目标是找到一个线性函数,将样本数据投影到低维空间中,并使得不同类别的样本在投影后的空间中有最大的区分度。
判别分析假设每个类别的样本在每个特征上都是以多元正态分布的方式分布的,因此它也被称为线性判别分析(Linear Discriminant Analysis,LDA)。
判别分析的基本思想是通过计算各个类别的均值向量和类内离散度矩阵(Within-class Scatter Matrix)来获得判别函数。
判别函数在特征空间中为超平面,可以将不同类别的样本分开。
二、判别分析的步骤判别分析的步骤主要包括数据预处理、模型训练和模型评估等。
1.数据预处理数据预处理是判别分析的第一步,它包括数据清洗、特征选择和数据标准化等。
数据清洗主要是去除异常值和缺失值,特征选择是为了选取对判别函数有重要影响的特征,数据标准化是为了使不同特征之间具有可比性。
2.模型训练模型训练是判别分析的核心步骤,它主要包括计算均值向量和类内离散度矩阵、计算类间离散度矩阵(Between-class Scatter Matrix)和求解广义特征值问题等。
通过这些步骤可以得到判别函数的系数,进而得到判别函数。
3.模型评估模型评估是为了评估判别函数的性能和判别模型的准确性。
常用的模型评估指标包括分类准确率、召回率、精确率和F1值等。
通过这些指标可以对判别函数的预测结果进行评估。
三、判别分析的模型评估和结果解释判别分析的模型评估可以通过交叉验证等方法来进行。
交叉验证可以将数据集划分为训练集和测试集,并使用训练集来训练判别模型,在测试集上对模型进行评估。

判别分析方法在医学应用中的进展作者:王静, 夏结来, 叶冬青, WANG Jing, XIA Jie-lai, YE Dong-qing作者单位:王静,叶冬青,WANG Jing,YE Dong-qing(安徽医科大学流行病与卫生统计学系,安徽合肥,230032), 夏结来,XIA Jie-lai(第四军医大学预防医学系,陕西西安,710000)刊名:数理统计与管理英文刊名:APPLICATION OF STATISTICS AND MANAGEMENT年,卷(期):2008,27(2)被引用次数:3次1.Qu Y;Adam BL;Thornquist M Data reduction using a discrete wavelet transformation in discriminant analysis of very high dimensinality data[外文期刊] 2003(1)2.周晓彦;郑文明基于模糊核判别分析的基因表达数据分析方法[期刊论文]-华中科技大学学报 2007(zk)3.Baudat G;Anouar F Generalized discriminant analysis using a kernel approach[外文期刊] 2000(10)4.Strobl C;Boulesteix AL;Zeileis A Bias in random forest variable importancemeasures:Illustrations,sources and a solution 20075.武晓岩;闫晓光;李康基因表达数据的随机森林逐步判别分析方法[期刊论文]-中国卫生统计 2007(2)6.Adele Cutler;John R.Stevens Random Forests for Microarrays 20067.Dettling M;B ǘ hlmann P Boosting for tumor classification with gene expression data[外文期刊] 2003(9)8.富春枫;苟鹏程;赵杨logitboost及其在判别分析中的应用[期刊论文]-中国卫生统计 2006(2)9.杨福生小波变换的工程分析与应用 199910.李建平;唐远炎小波分析方法的应用(第1版) 199911.谭鲜明;张润楚高维数据判别分析中的特征选择[期刊论文]-数学物理学报 2006(5)12.钱国华;荀鹏程;陈峰偏最小二乘法降维在微阵列数据判别分析中的应用[期刊论文]-中国卫生统计 2007(2)13.Nguyen DV;Rocke DM Multi-class cancer classification via partial least squares with gene expression profiles[外文期刊] 200214.Nguyen DV;Rocke DM Wunlor classification by partial least squares using microarray gene expression data 200215.李建军;丁正生;张海燕常用判别分类方法分析[期刊论文]-西安科技大学学报 2007(1)16.花俊洲;吴冲锋变系数logistic模型估计及其应用[期刊论文]-上海交通大学学报 2004(8)17.丁跃潮;浦云明;林颖贤有序判别分析新算法及其应用[期刊论文]-数理统计与管理 2007(2)18.丁跃潮;万春;孙扬定向判别分析新算法及应用[期刊论文]-计算机工程与科学 2006(9)19.陈峰医用多元统计分析方法 20001.王建.圣建惠.申悦平.张建军.王捷婷Logitboost算法在慢性乙型肝炎肝纤维化中的应用研究[期刊论文]-检验医学与临床 2012(3)2.王文.杨土保.张喆.蔡韵学生体质综合评价研究综述[期刊论文]-实用预防医学 2010(1)3.曾高.焦风.宋修会.申涛.栾文忠.梁冶矢应用非参数逐步判别分析法建立颅内压半定量数学模型[期刊论文]-中本文链接:/Periodical_sltjygl200802025.aspx。
逐步判别分析运行记录,第一步纳入人均地方财政收入,第二步纳入人均国内生产总值,以此类推。
共5 个变量进入判别模型,其他5个变量未进入。
5步的Wilks 的 Lambda检验均小于0.05。
拒绝原假设,说明5步中分别纳入判别函数的变量对正确判断分类都是有作用的。
分析中一共提取出了来年各个维度的典型判别函数,期中第一个函数解释了所有变异的99.3%,第二个函数解释了0.7%。
说明建立的各个判别函数有无统计学意义,上表显示第一个判别函数有意义,第二个判别函数搭边。
说明人均国内生产总值,人均地方财政收入在第一个判别函数中比较重要,人均进出口贸易总额、移动电话普及率、电话普及率在第二个判别函数中比较重要。
说明判别结果正确。
一种基于广义奇异值分解的无关联线性判别分析算法何红洲【摘要】有监督学习旨在样本数据集中找到最优判决向量.线性判别分析(LDA)和无关联线性判别分析(ULDA)是解决该问题的常用方法.研究中改进了古曲IDA方法使其与ULDA等价,并给出了相应求判决向量的ULDA/QR算法来简化ULDA中对判决向量的求解;为了有效地解决LDA方法和ULDA方法中类内散布矩阵奇异性的问题,提出了一种基于ULDA/QR,正则LDA和广义奇异值分解(GSVD)的无关联线性判别分析算法.【期刊名称】《绵阳师范学院学报》【年(卷),期】2010(029)005【总页数】6页(P102-107)【关键词】特征抽取;散布矩阵;最优判决向量;无关联线性判别分析;广义奇异值分解【作者】何红洲【作者单位】绵阳师范学院数学与计算机科学学院,四川绵阳,621000【正文语种】中文【中图分类】TP301在信息检索、面部特征识别等众多的多类别应用领域的分类中,会遇到抽样数据具有多达100个甚至更多的特征问题,因此特征数据向量具有高维性,但我们有理由怀疑这些不同特征之间存在某些相关性(特征数据冗余),因而提出了有关特征抽取,即从大量的特征中抽取较少的对后续处理(如分类)有用特征(集)的问题。
这儿“有用”一方面表示抽取特征(集)能够真实地反映初始数据的主要特性;另一方面也表示抽取的特征也更容易把初始数据分成有意义的类,即来自同一类别的数据具有更大的“相似性”,而来自不同类别的数据具有更大的“相异性”[1-2]。
文献[3]提出了特征抽取的PCA(Principal Component Analy2 sis,主成分分析)方法,其目的是寻找在最小均方意义下将初始的特征向量向更低维的空间投影的方法,以提取主要的成份,确定主轴的方向,该方法对于真实地反映初始数据的主要特性很有效,但对区分不同类别的数据没有多大的作用;文献[4]说明了PCA更为广泛的应用领域;文献[5]提出了古典LDA(Linear DiscriminantAnalysis,线性判别分析)方法,利用对散布矩阵的特征分解来找出最优判决向量,但当类内散布矩阵奇异时(在数据欠抽样时往往是这种情况),该方法失效;文献[6]提出了正则LDA算法,通过给类内散布矩阵主对角线上的元素都增加同一个修正量以消除该散布矩阵的奇异性问题,但没给出修正量值的确定方法;文献[7]提出了两阶段子空间LDA算法,虽然在第二阶段消除了类内散布矩阵奇异性问题,但在第一阶段仍使用PCA算法,故与PCA存在同样的问题;文献[8-9]提出了ULDA(Uncorrelated Linear DiscriminantAnalysis,无关联线性判别分析)算法,使得抽取的特征彼此不相关,但一方面计算量很大,另一个方面与古典LDA算法一样也没有消除类内散布矩阵奇异性的问题。
一种自适应的非参数判别分析方法
黄亮;赵宇明
【期刊名称】《微计算机信息》
【年(卷),期】2009(25)1
【摘要】线性判别分析(LDA)是在包括人脸识别等多个应用领域被广泛采用的降维方法.但是,由于LDA是基于各类均服从高斯分布的假设,导致其类间散度矩阵的定义会产生相邻类别的重叠问题.因此,我们提出了一种自适应的非参数判别分析方法(ANDA),此方法通过增加位于类边界附近样本点在类间散度矩阵中的权重的方法来增大不同类的相邻样本点之间的距离.本文通过在FERET以及ORL人脸库上的实验把ANDA方法与传统的PCA+LDA,Orthogonal LDA(OLDA)和非参数判剐分析(NDA)进行了比较,实验结果表明本文提出的方法优于其他方法.
【总页数】3页(P256-258)
【作者】黄亮;赵宇明
【作者单位】200240,上海,上海交通大学,图像处理与模式识别研究所;200240,上海,上海交通大学,图像处理与模式识别研究所
【正文语种】中文
【中图分类】TP391.41
【相关文献】
1.一种非定比多轴系自适应阶比分析方法的研究 [J], 李泓锦;杨晓冬;李万军;张兰;申同强
2.入库洪水判别的一种水文参数分析方法 [J], 夏军;叶守泽
3.一种非参数的多策略方法:多策略的海明距离判别法 [J], 李元白;曾平飞;杨亚坤;康春花
4.一种无参数的局部线性判别分析方法 [J], 黄礼泊;凌永权
5.二维非参数化判别分析方法中的人脸识别算法研究 [J], 张旭;曹健;刘玉树
因版权原因,仅展示原文概要,查看原文内容请购买。
一种两阶段判别分析方法
曾青松
【期刊名称】《电脑与电信》
【年(卷),期】2016(0)5
【摘要】为了解决LDA对复杂分布数据的表达问题,本文提出了一种新的非参数形式的散度矩阵构造方法.该方法能更好的刻画分类边界信息,并保留更多对分类有用的信息.同时针对小样本问题中非参数结构形式的类内散度矩阵可能奇异,提出了一种两阶段鉴别分析方法对准则函数进行了最优化求解.该方法通过奇异值分解把人脸图像投影到混合散度矩阵的主元空间,使类内散度矩阵在投影空间中是非奇异的,通过CS分解,从理论上分析了同时对角化散度矩阵的求解,并证明了得到的投影矩阵满足正交约束条件.在ORL,Yale和YaleB人脸库上测试的结果显示,改进的算法在性能上优于PCA+LDA,ULDA和OLDA等子空间方法.
【总页数】6页(P14-19)
【作者】曾青松
【作者单位】广州番禺职业技术学院信息工程学院,广东广州 511483
【正文语种】中文
【中图分类】TP391.41
【相关文献】
1.一种新型多核判别分析方法 [J], 梁军;张飞云;陈龙;李世浩;顾胜强;张婉婉
2.一种确定页岩气储层产气潜力的判别分析方法 [J], 徐春华;彭玲莉;刘理湘
3.一种两阶段变量选择的LIBS定量分析方法 [J], 郭宇潇;史晋芳;王慧丽;邱荣;邓承付
4.一种无参数的局部线性判别分析方法 [J], 黄礼泊;凌永权
5.一种用于多级压裂水平井判别来水方向的多井干扰压力分析方法 [J], 程时清;李猛;何佑伟;吕亿明;崔文浩;陈建文;段晓宸;吴德志
因版权原因,仅展示原文概要,查看原文内容请购买。