Eviews 进行异方差性检验及估计模型
- 格式:doc
- 大小:141.50 KB
- 文档页数:7

eviews异方差检验步骤Eviews是一款常用的经济学软件,它允许用户进行多种统计分析,其中包括异方差检验。
异方差是指随着自变量的变化,因变量的方差也会发生变化。
在实际分析中,如果忽略了异方差,则会导致统计结果不准确。
因此,在使用Eviews进行分析时,进行异方差检验十分重要。
以下是Eviews进行异方差检验的步骤:1. 打开Eviews软件,并导入所需的数据。
在“工作文件”菜单下选择“打开文件”,找到所需的数据文件并打开。
2. 选择变量。
单击“变量”菜单,并选择要检验的因变量和自变量。
如果有多个自变量,在本例中就需要选择多个自变量。
3. 进行回归分析。
单击“Quick”菜单下的“Estimate Equation”选项,进行回归分析。
在回归分析中,需要输入因变量和自变量,并进行模型估计。
4. 异方差检验。
在回归分析完成后,单击“View”菜单下的“Residual Diagnostics”选项,进入错误项诊断。
5. 在错误项诊断中选择异方差检验。
在错误项诊断面板中,选择“Heteroskedasticity Tests”选项,并选择所需的异方差检验类型。
在Eviews中,通常可以使用Breusch-Pagan/Godfrey测试或White 测试来检验异方差。
6. 查看结果。
完成异方差检验后,Eviews会返回检验结果。
如果结果显示存在异方差,则需要进行调整,以消除异方差的影响。
总之,在使用Eviews进行经济学分析时,进行异方差检验至关重要,可以保证模型分析的准确性和可靠性。
上述步骤简单易懂,只要按照步骤操作,就可以轻松地完成异方差检验。


计量经济学论文(eviews分析)我国限额以上餐饮企业营业额的影响因素分析摘要:本文收集了1999年至2009年共11年的相关数据,选取餐饮企业数量、城镇居民人均年消费性支出、全国城镇人口数以及公路里程数作为解释变量构建模型,对我国限额以上餐饮企业营业额的影响因素进行分析。
利用Eviews软件对模型进行参数估计和检验,并加以修正,最后根据模型的最终结果进行经济意义分析,提出自己的看法。
关键词:餐饮企业营业额、影响因素、计量分析一、研究背景近十年来,投资者进入餐饮企业的数量不断增加。
在他们进入一个行业之前,势必要对该行业的营业额、营业利润等进行估计,当这些因素的估计值能够达到他们的预期时,他们才会对其进行投资。
由于餐饮企业的营业额是影响投资者是否进入餐饮业的一个重要因素,对于我国餐饮企业的营业额问题的深入研究就显得尤为必要,这有助于投资者作出合理的决策。
因此,本文进行了对我国限额以上餐饮企业营业额的计量模型研究。
二、变量的选取影响餐饮企业营业额的因素有很多,包括餐饮企业的数量、营业面积、从业人员、城镇居民人均年消费性支出、全国城镇人口数、餐饮企业的平均价格水平及公路里程数(表示交通状况)。
但综合考虑后,本文选取了其中的一部分变量(企业数、城镇居民人均年消费性支出、全国城镇人口数、公路里程数)进行研究,并对各个变量对餐饮企业营业额的影响进行预测。
1.企业数本文认为餐饮企业营业额与餐饮企业的数量有关,并预测两者之间呈正相关。
2.城镇居民人均年消费性支出本文认为餐饮企业营业额与城镇居民人均年消费性支出有关,并预测两者之间呈正相关。
3.全国城镇人口数本文认为餐饮企业营业额与全国城镇人口数有关,并预测两者之间呈正相关。
4.公路里程数本文认为餐饮企业营业额与公路里程数有关,并预测两者之间呈正相关。
三、相关数据本文收集了1999年至2009年共11年的相关数据,包括营业额(单位:亿元)、企业数(单位:个)、人均年消费性支出(单位:元)、全国城镇人口数(单位:万人)以及公路里程数(单位:万公里)。

计量经济学实验指导系部:基础部专业:计算与信息科学教师:仓定帮I.实验一多元线性回归模型 (3)II.实验二异方差的检验与处理 (16)III.实验三序列相关的检验与处理 (24)IV.实验四多重共线性的检验与处理 (32)V.实验五虚拟变量模型 (39)VI.实验六分布滞后模型 (45)VII.实验七联立方程模型 (51)VIII.实验八时间序列模型分析 (58)IX.实验九V AR模型的建立与分析 (77)A. ADF检验 (78)B. VAR模型的建立 (79)C. 协整检验 (80)D. GRANGER因果检验 (81)E. 脉冲响应分析 (81)实验内容注:必做实验课堂时间完成,选做实验由学生课后选择时间完成。
每次实验后学生上交实验分析结果。
I.实验一多元线性回归模型【实验目的】通过本实验,了解Eviews软件,熟悉软件建立工作文件,文件窗口操作,数据输入与处理等基本操作。
掌握多元线性回归模型的估计方法,学会用Eiews 软件进行多元回归分析。
通过本实验使得学生能够根据所学知识,对实际经济问题进行分析,建立计量模型,利用Eiews软件进行数据分析,并能够对输出结果进行解释说明。
【实验内容及步骤】本实验选用美国金属行业主要的27家企业相关数据,如下表,其中被解释变量Y表示产出,解释变量L表示劳动力投入,K表示资本投入。
试建立三者之间的回归关系。
7 2427.89 452 3069.91 21 5159.31 835 5206.368 4257.46 714 5585.01 22 3378.4 284 3288.729 1625.19 320 1618.75 23 592.85 150 357.3210 1272.05 253 1562.08 24 1601.98 259 2031.9311 1004.45 236 662.04 25 2065.85 497 2492.9812 598.87 140 875.37 26 2293.87 275 1711.7413 853.1 154 1696.98 27 745.67 134 768.5914 1165.63 240 1078.79【实验内容及步骤】1.数据的输入STEP1:双击桌面上Eviews快捷图标,打开Eviews,如图1.图1STEP2:点击Eviews主画面顶部按钮file/new/Workfile ,如图2,弹出workfile create对话框如图3。
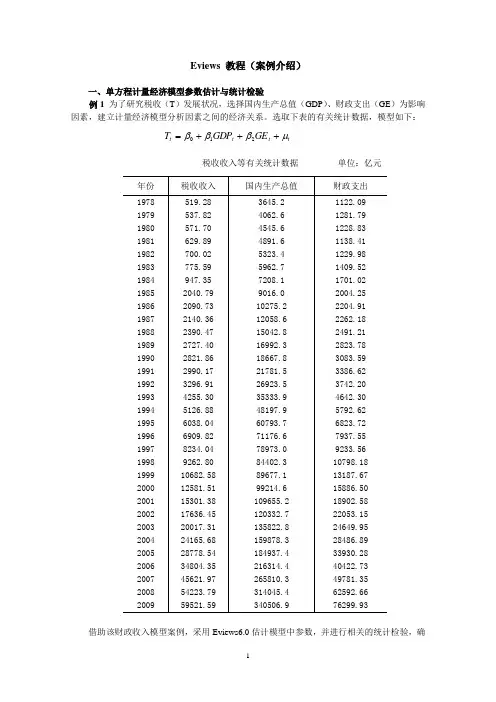
Eviews 教程(案例介绍)一、单方程计量经济模型参数估计与统计检验例1 为了研究税收(T )发展状况,选择国内生产总值(GDP )、财政支出(GE )为影响因素,建立计量经济模型分析因素之间的经济关系。
选取下表的有关统计数据,模型如下:t t t t GE GDP T μβββ+++=210税收收入等有关统计数据 单位:亿元借助该财政收入模型案例,采用Eviews6.0估计模型中参数,并进行相关的统计检验,确定最终模型。
Eviews软件模型分析过程如下:1.创建工作文件启动Eviews软件,在主菜单上依次单击File→New→Workfile,选择数据类型(时间序列或非时间序列),并输入样本区间和工作文件名,创建工作文件的子窗口如图1-1所示。
图1-1 创建工作文件2.建立变量组Eviews软件建立变量组可采用三种途径:(1)在主菜单上依次单击Quick→Empty Group,在数据编辑窗口中单击Edit+/-,并按上行健↑,这样可依次输入变量名;(2)在主菜单上依次单击Objects→New Objects,在对话框中选择“Group”并定义文件名,在数据编辑窗口中首先按上行健↑,这样可依次输入变量名;(3)在主菜单上Eviews命令框中直接输入命令:Data T GDP GT CPI(命令及变量名之间用空格分隔),将直接出现已定义变量名称的数据编辑窗口。
图1-2 数据编辑窗口3.输入经济变量的样本数据在图1-2所示的数据编辑窗口中,在“NA”的位置可输入各经济变量的样本数据,输入样本数据后及时予以保存。
样本数据也可以从有关Office软件的各类表格中进行数据的复制;也可以通过Eviews 软件本身生产新的变量数据序列,如在主菜单上依次单击Quick→Generate Series、或者在工作文件(Workfile)窗口中单击Generate,在弹出窗口中输入方程式,如图1-3所示。
图1-3 生产新变量数据序列4.估计模型参数在主菜单上依次单击Quick→Estimate Equation,弹出对话框,在“Specification”选项卡中输入模型中被解释变量、常数项、解释变量序列,并选择估计方法及样本区间,如图1-4所示,估计结果如图1-5。


eviews异方差、自相关检验与解决办法一、异方差检验:1.相关图检验法LS Y C X 对模型进行参数估计GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列SORT X 对解释变量X排序SCAT X E2 画出残差平方与解释变量X的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。
SORT X 将样本数据关于X排序SMPL 1 10 确定子样本1LS Y C X 求出子样本1的回归平方和RSS1SMPL 17 26 确定子样本2LS Y C X 求出子样本2的回归平方和RSS2计算F统计量并做出判断。
解决办法3.加权最小二乘法LS Y C X 最小二乘法估计,得到残差序列GRNR E1=ABS(RESID) 生成残差绝对值序列LS(W=1/E1) Y C X 以E1为权数进行加权最小二成估计二、自相关1.图示法检验LS Y C X 最小二乘法估计,得到残差序列GENR E=RESID 生成残差序列SCAT E(-1) E et—et-1的散点图PLOT E 还可绘制et的趋势图2.广义差分法LS Y C X AR(1) AR(2)首先,你要对广义差分法熟悉,不是了解,如果你是外行,我奉劝你还是用eviews来做就行了,其实我想老师要你用spss无非是想看你是否掌握广义差分,好了,废话不多说了。
接着,使用spss16来解决自相关。
第一步,输入变量,做线性回归,注意在Liner Regression 中的Statistics中勾上DW,在save中勾Standardized,查看结果,显然肯定是有自相关的(看dw值)。
第二步,做滞后一期的残差,直接COPY数据(别告诉我不会啊),然后将残差和滞后一期的残差做回归,记下它们之间的B指(就是斜率)。
第三步,再做滞后一期的X1和Y1,即自变量和因变量的滞后一期的值,也是直接COPY。
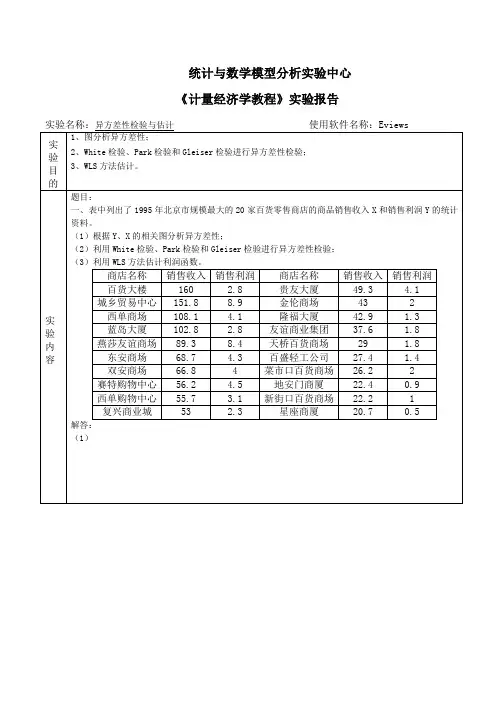

第四章异方差性例4.1.4一、参数估计进入Eviews软件包,确定时间范围,编辑输入数据;选择估计方程菜单:(1)在Workfile对话框中,由路径:Quick/Estimate Equation,进入Equation Specification对话框,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果;(2)直接在命令栏里输入“ls log(y) c log(x1) log(x2)”,按Enter,得到样本回归估计结果;(3)在Group的当前窗口,由路径:Procs/Make Equation,进入Equation Specification窗口,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果。
如表4.1:表4.1图4.1估计结果为:(3.14) (1.38) (9.25)R2=0.7798 D.W.=1.78 F=49.60 RSS=0.8357括号内为t统计量值。
二、检验模型的异方差(一)图形法(1)生成残差平方序列。
①在Workfile的对话框中,由路径:Procs/Generate Series,进入Generate Series by Equation对话框,键入“e2=resid^2”,生成残差平方项序列e2;②直接在命令栏里输入“genr e2=resid^2”,按Enter,得到残差平方项序列e2。
(2)绘制散点图。
①直接在命令框里输入“scat log(x2) e2”,按Enter,可得散点图4.2。
②选择变量名log(x2)与e2(注意选择变量的顺序,先选的变量将在图形中表示横轴,后选的变量表示纵轴),再按路径view/graph/scatter/simple scatter,可得散点图4.2。
③由路径quick/graph进入series list窗口,输入“log(x2) e2”,确认并ok,再在弹出的graph窗口把line graph换成scatter diagram,再点ok,可得散点图4.2。
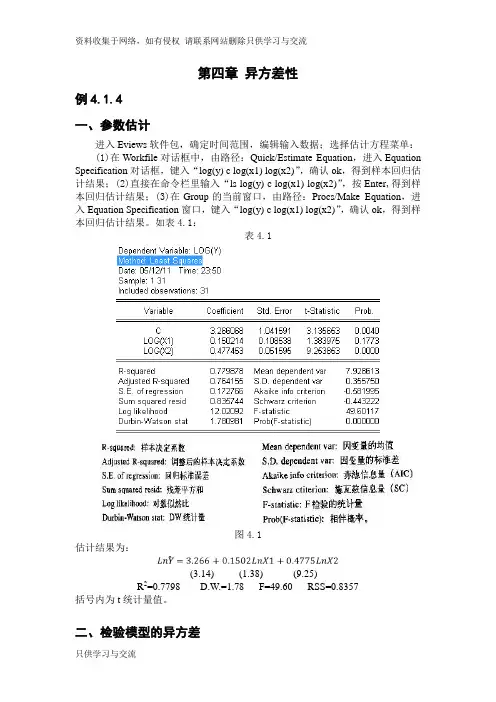
第四章异方差性例4.1.4一、参数估计进入Eviews软件包,确定时间范围,编辑输入数据;选择估计方程菜单:(1)在Workfile对话框中,由路径:Quick/Estimate Equation,进入Equation Specification对话框,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果;(2)直接在命令栏里输入“ls log(y) c log(x1) log(x2)”,按Enter,得到样本回归估计结果;(3)在Group的当前窗口,由路径:Procs/Make Equation,进入Equation Specification窗口,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果。
如表4.1:表4.1图4.1估计结果为:(3.14) (1.38) (9.25)R2=0.7798 D.W.=1.78 F=49.60 RSS=0.8357括号内为t统计量值。
二、检验模型的异方差(一)图形法(1)生成残差平方序列。
①在Workfile的对话框中,由路径:Procs/Generate Series,进入Generate Series by Equation对话框,键入“e2=resid^2”,生成残差平方项序列e2;②直接在命令栏里输入“genr e2=resid^2”,按Enter,得到残差平方项序列e2。
(2)绘制散点图。
①直接在命令框里输入“scat log(x2) e2”,按Enter,可得散点图4.2。
②选择变量名log(x2)与e2(注意选择变量的顺序,先选的变量将在图形中表示横轴,后选的变量表示纵轴),再按路径view/graph/scatter/simple scatter,可得散点图4.2。
③由路径quick/graph进入series list窗口,输入“log(x2) e2”,确认并ok,再在弹出的graph窗口把line graph换成scatter diagram,再点ok,可得散点图4.2。
eviews异方差检验步骤Eviews异方差检验步骤异方差是指随着自变量的变化,因变量的方差也会发生变化。
在回归分析中,如果存在异方差,会导致回归系数的估计值不准确,从而影响模型的可靠性。
因此,进行异方差检验是非常重要的。
Eviews是一款常用的统计软件,它提供了多种方法来检验异方差。
下面我们将介绍Eviews中进行异方差检验的步骤。
步骤一:建立回归模型我们需要建立一个回归模型。
在Eviews中,可以通过“Quick”菜单中的“Estimate Equation”来建立回归模型。
在弹出的对话框中,选择因变量和自变量,并设置其他参数,如拟合方法、截距项等。
步骤二:检验异方差建立好回归模型后,我们需要进行异方差检验。
在Eviews中,可以通过“View”菜单中的“Residual Diagnostics”来进行检验。
在弹出的对话框中,选择“Heteroskedasticity Tests”选项卡,然后选择需要进行的异方差检验方法。
Eviews提供了多种异方差检验方法,包括Breusch-Pagan-Godfrey 检验、White检验、Goldfeld-Quandt检验等。
这些方法的原理和适用条件不同,需要根据具体情况选择合适的方法。
步骤三:解释检验结果进行异方差检验后,Eviews会输出检验结果。
通常包括检验统计量、p值等信息。
如果p值小于显著性水平(通常为0.05),则可以拒绝原假设,认为存在异方差。
如果检验结果显示存在异方差,我们需要对模型进行修正。
常用的方法包括使用异方差稳健标准误、进行加权最小二乘回归等。
总结Eviews提供了多种方法来检验异方差,包括Breusch-Pagan-Godfrey 检验、White检验、Goldfeld-Quandt检验等。
进行异方差检验后,需要根据检验结果对模型进行修正,以提高模型的可靠性。
一、背景分析2009年国民经济继续朝着宏观调控预期方向发展,总体保持了平稳较快的运行状态,国际贸易迅速发展,外汇储备再创新高,人民币汇率升值仍然保持一个较高的预期。
汇率受到诸多方面的影响,其变动原因较为复杂。
很明显,汇率首先受到一国外汇储备的制约。
汇率是不同货币之间的比率关系,而外汇储备是一个国家拥有的非本国货币的金额。
2009年6月,我国外汇储备已经超过2.1万亿美元。
如此庞大的外汇储备导致人民币升值的压力进一步加大。
在外汇储备不断增加的情况下,流通中的货币量也在增加,央行不得不发行更多的人民币来兑换贸易或投资中得到的外汇。
利益方面,在经济起飞过程中汇率升值的问题是肯定会出现的,汇率和人均GDP之间的影响非常之大.。
如韩国,台湾与日本,以起飞过程中汇率都升值了一倍以上.而韩国从2000年到两面仅仅七年时间,汇率就涨了四成.而日本仅在1987年日元的汇率就涨了差不多100%.但中国呢则非常奇怪,在经济起飞的前二十年,1980-1996,中国的汇率不但不升,反而贬值了560%.1996的时候,中国经济已经高速增长了二十年,按日本四小龙的经验,货币已经开始一倍两倍地大幅升值了,但中国人民币却不动如山的稳定了十年,直到2005.而2005到现在,人民币虽然开始了升值,却依然是虫子爬行般地升值.而如果从1980年算起综合起来看,人民币在1980-2007年期间,不但没有升值,反而贬了了差不多500%.这都说明,人民币升值压力加大。
不管中国有何感觉,鉴于此次危机的严重程度,实际上针对中国出口的保护主义力度并不是很大。
其次,中国低汇率的政策相当于提供出口补贴和以统一的税率征收关税,换句话说,带有保护主义色彩。
第三,截至今年9月,中国已积累了2.273万亿美元的外汇储备,由此压低人民币汇率,达到世界经济史上从未曾见的水平。
尽管中国的经济增长率和经常账户盈余居世界之首,但中国的实际汇率不高于1998年初的水平,过去7个月,人民币已累计贬值12%。
第四章异方差性例一、参数估计进入Eviews软件包,确定时间范围,编辑输入数据;选择估计方程菜单:(1)在Workfile对话框中,由路径:Quick/Estimate Equation,进入Equation Specification对话框,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果;(2)直接在命令栏里输入“ls log(y) c log(x1) log(x2)”,按Enter,得到样本回归估计结果;(3)在Group的当前窗口,由路径:Procs/Make Equation,进入Equation Specification窗口,键入“log(y) c log(x1) log(x2)”,确认ok,得到样本回归估计结果。
如表:表图估计结果为:R2= .= F= RSS=括号内为t统计量值。
二、检验模型的异方差(一)图形法(1)生成残差平方序列。
①在Workfile的对话框中,由路径:Procs/Generate Series,进入Generate Series by Equation对话框,键入“e2=resid^2”,生成残差平方项序列e2;②直接在命令栏里输入“genr e2=resid^2”,按Enter,得到残差平方项序列e2。
(2)绘制散点图。
①直接在命令框里输入“scat log(x2) e2”,按Enter,可得散点图。
②选择变量名log(x2)与e2(注意选择变量的顺序,先选的变量将在图形中表示横轴,后选的变量表示纵轴),再按路径view/graph/scatter/simple scatter ,可得散点图。
③由路径quick/graph进入series list窗口,输入“log(x2) e2”,确认并ok,再在弹出的graph窗口把line graph换成scatter diagram,再点ok,可得散点图。
图由图可以看出,残差平方项e2对解释变量log(X2)的散点图主要分布图形中的下三角部分,大致看出残差平方项e2随log(X2)的变动呈增大的趋势,因此,模型很可能存在异方差。
异方差性及其检验I 概念对于多元线性回归模型同方差性假设为 如果出现即对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,不具有等同的分散程度,则认为出现了异方差(Heteroskedasticity ) II 类型同方差性假定是指,回归模型中不可观察的随机误差项i u 以解释变量X 为条件的方差是一个常数,因此每个i u 的条件方差不随X 的变化而变化,即有2()i i f X σ=≠常数在异方差的情况下,总体中的随机误差项i u 的方差 2i σ不再是常数,通常它随解释变量值的变化而变化,即异方差一般可归结为三种类型:01122 1,2,,i i i k ki i Y X X X i n ββββμ=+++++=2(), 1,2,...,i Var i n μσ==2(), 1,2,...,i i Var i nμσ==2()i i f X σ=异方差类型图:III来源(1)截面数据(不同样本点除解释变量外其他影响差异大)(2)时间序列(规模差异)(3)分组数据、异常值等(4)模型函数形式设置不正确和数据变形不正确(5)边错边改学习模型IV影响计量经济学模型一旦出现异方差,如果仍然用普通最小二乘法估计模型参数,会产生一系列不良后果。
(1)参数估计量非有效(2)OLS估计的随机干扰项的方差不再是无偏的(3)基于OLS估计的各种统计检验非有效(4)模型的预测失效V检验异方差性,即相对于不同的样本点,也就是相对于不同的解释变量观测值,随机干扰项具有不同的方差,那么检验异方差性,也就是检验随机干扰项的方差与解释变量观测值之间的相关性。
一般检验方法如下:(1)图示检验法(2)帕克(Park)检验与戈里瑟(Gleiser)检验(3)G-Q(Goldfeld-Quandt)检验(4)F检验(5)拉格朗日乘子检验(6)怀特检验(具体步骤随后介绍)VI修正方法加权最小二乘法定义:加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用OLS法估计其参数。
田青帆1006010131 国贸1001班建立模型Y t=β1+β2X t+uX:1994-2011年中国国内生产总值Y:1994-2011年中国进口总额数据来源:国泰安数据服务中心/p/sq/一、异方差的检验1、图示法由上图可以看出,残差平方项e2随X的变动而变动,一次,模型很可能存在异方差,但是否确实存在异方差还应通过更进一步的检验。
2、等级相关系数检验t值为29.48788,自由度为18-2=16在95%的显著水平下,查表可得t0.025(16)=2.1199t>t0.025(16),说明X i和|e i|之间存在系统关系,则说明模型中存在异方差3、戈德菲尔德-夸特检验(样本分段比检验)在本例中,样本容量为18,删去中间4个观测值,余下部分平分的两个样本区间:1-7和12-18,他们的样本数都是7个,用OLS方法对这两个子样本进行回归估计,结果如下图所示计算检验统计量FF=[RSS2/(n2-k)] ÷[RSS1/(n1-k)]n2-k=n1-k=7-2=5F=RSS2/RSS1=4588102/229037.4=20.03在95%的显著水平下,查表可得F0.05(5,5)=5.05 F>F0.05(5,5)所以,模型存在异方差4、戈里瑟(Glejser)检验用残差绝对值建立的回归模型为|e i|=α1+α2 (1/X i)由上表可知,回归模型为|e i|=1416.049+10.37101(1/X i)≠0,则存在异方差α25、怀特检验由上图可知:P值=0.017140﹤0.05,所以存在异方差二、异方差的修正(加权最小二乘法)1、选择1/x为权数,即对模型两边同时乘以1/x,使用最小二乘法进行回归估计,所得结果如下:由上图可知,P值=0.0001﹤0.05,模型依然存在异方差2、选择1/|e|为权数,即对模型两边同时乘以1/|e|,使用最小二乘法进行回归估计,所得结果如下:此时,P值=0.2139>0.05,将异方差模型变成了同方差。
异方差性检验及存在异方差模型估计
检验使用方法:(1)G-Q检验(2)White 检验
模型估计方法:加权最小二乘法(WLS)
下表为2000年中国部分省市城镇居民每个家庭平均年可支配收入(X)与消费性支出(Y)的统计数据:
1
江苏6800.23 5323.18 甘肃4916.25 4126.47 浙江9278.16 7020.22 青海5169.96 4185.73 山东6489.97 5022.00 新疆5644.86 4422.93
一、利用Eviews求出线性模型
2
3
可得模型:ˆ272.2250.755i i Y X =+
(1.705) (32.394) R 2=0.9832
二、异方差检验
(1)G-Q 检验:首先将可支配收入X 升序进行排列,然后去掉中间4个样本,将余下的样本分为容量各为8的两个子样本,并分别进行回归。
湖南6218.73 5218.79 山西4724.11 3941.87 大样本小样本
样本取值较小的Eviews输出结果如下
残差平方和:RSS1=126528.3
4
样本取值较大的Eviews输出结果如下:残差平方和:RSS2=615073.7
因此统计量为:2
14.8611
RSS
F
RSS
==
5
F=,4.86>4.28,因此拒绝原假设,存在异方差性。
在5%的显著性水平下,0.05(6,6) 4.28
(2)White检验:在原模型的最小二乘估计窗口上选择“View\Residual Tests\Heteroskedasticity Tests\White”得到如下结果:
x=,因此12.6478>5.99,因而拒绝原假设,检验统计量值为12.64768,查询20.05(2) 5.99
模型存在异方差。
三、估计存在异方差的经济模型
利用加权最小二乘法(WLS)进行估计:首先在对原模型进行估计后,保存残差,步骤如下:①Quick\Generate Series 再输入“e1=resid”,得到e1
6
②Quick\Estimte Equation 再输入“Y C X”
③选择Options,在“Weighted LS/TLS”输入“1/abs(e1)”(备注:abs表示绝对值) 得到如下结果;
7。