Eviews数据统计与分析教程6章 基本回归模型的OLS估计-加权最小二乘法
- 格式:ppt
- 大小:329.50 KB
- 文档页数:20



加权最小二乘法(WLS) 是一种统计学方法,它用于解决带有误差的线性回归问题。
它的基本思想是在最小二乘法的基础上,通过给每个样本点赋予不同的权重,来解决样本点的误差不同的问题。
基本思想就是,通过给不同的样本点赋予不同的权重,来解决样本点的误差不同的问题。
在WLS中,每个观测值都有一个相应的权重。
权重是与观测值相关的标量值,可以用来衡量观测值的置信度或相对重要性。
权重越大,观测值对结果的影响就越大。
大残差的定义是指比较大的样本误差。
在WLS中,我们通过减小大残差对结果的影响来提高结果的精确度。


加权最小二乘回归系数的估计计算过程1. 概述加权最小二乘回归是一种对数据进行线性建模的方法,在现实应用中经常被使用。
通过加权最小二乘回归,我们可以得到对数据的线性关系进行建模的最佳拟合直线,并估计出各个自变量的系数。
本文将详细介绍加权最小二乘回归系数的估计计算过程,以便读者能够深入了解这一方法的原理和实现。
2. 加权最小二乘回归的基本原理加权最小二乘回归方法是最小化因变量的观测值与回归函数预测值之间的加权残差平方和来确定回归系数的方法。
其数学表达式为:(1)min∑wi(yi - β0 - β1xi1 - ... - βpxip)^2其中wi是观测值的权重,yi表示因变量的观测值,β0是截距项,β1到βp为自变量系数,xi1到xip为自变量观测值。
3. 加权最小二乘回归系数的估计计算步骤加权最小二乘回归系数的估计计算过程可以分为以下几个步骤:(1)计算加权变量根据给定的权重,对自变量和因变量进行加权变换,得到加权后的自变量和因变量。
(2)构建加权矩阵根据加权后的自变量和因变量,构建加权矩阵。
加权矩阵是一个n×(p+1)的矩阵,其中n为样本量,p为自变量的个数。
(3)计算加权矩阵的转置矩阵对加权矩阵进行转置,得到加权矩阵的转置矩阵。
(4)计算加权矩阵的乘积将加权矩阵和其转置矩阵相乘,得到乘积矩阵。
(5)计算乘积矩阵的逆矩阵对乘积矩阵进行求逆运算,得到逆矩阵。
(6)计算加权矩阵和因变量的乘积将加权矩阵和因变量相乘,得到乘积向量。
(7)计算回归系数利用逆矩阵和乘积向量,通过线性代数方法计算得到回归系数的估计值。
4. 加权最小二乘回归的优势加权最小二乘回归相对于普通最小二乘回归的优势在于,它能够更好地处理数据的异方差性。
在普通最小二乘回归中,对所有观测值一视同仁,忽略了不同观测值的方差可能不同的情况。
而通过加权最小二乘回归,我们可以根据数据的特点赋予不同观测值不同的权重,从而更准确地估计回归系数。


[经验分享] 使用eviews做线性回归分析Glossary:ls(least squares)最小二乘法R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaured()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criterion赤池信息量(AIC)(越小说明模型越精确)Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statistic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同gdp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p 值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
2)回归系数显著性检验(t检验):检验每一个自变量的合理性|t|大于临界值表示可拒绝系数为0的假设,即系数合理。
一、创建工作文件命令方式在命令窗口直接输入建立工作文件的命令CREATE , 命令格式:CREATE 数据频率 起始期 终止期 其中,数据频率类型分别为A (年)、Q (季)、M (月)、U (非时间序列数据)。
输入Eviews 命令时,命令字与命令参数之间只能用空格分隔。
如本例可输入命令:CREATE A 1984 2003工作文件创立后,需将工作文件保存到磁盘,单击工具条中Save →输入文件名、路径→保存,或单击菜单兰中File →Save 或Save as →输入文件名、路径→保存。
二、输入和编辑数据命令方式命令格式:data 〈序列名1〉 〈序列名2〉 … 〈序列名n 〉 功能:输入新变量的数据,或编辑工作文件中现有变量的数据。
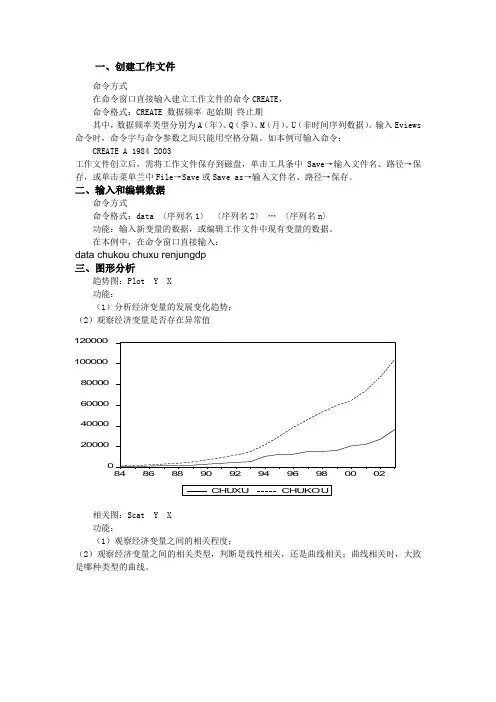
在本例中,在命令窗口直接输入:data chukou chuxu renjungdp 三、图形分析趋势图:Plot Y X 功能:(1)分析经济变量的发展变化趋势; (2)观察经济变量是否存在异常值02000040000600008000010000012000084868890929496980002相关图:Scat Y X 功能:(1)观察经济变量之间的相关程度;(2)观察经济变量之间的相关类型,判断是线性相关,还是曲线相关;曲线相关时,大致是哪种类型的曲线。
20000400006000080000100000120000010000200003000040000CHUXUC H U K O U四、OLS 估计参数在主菜单命令行键入 LS Y C X单击Equation 窗口中的Resid 按钮,将显示模型的拟合图和残差图-10000-50000500010000-2000002000040000600008000010000012000084868890929496980002单击Equation 窗口中的View → Actual, Fitted, Resid → Table 按钮,可以得到拟合直线和残差的有关结果五、预测在Equation 框中选Forecast 项后,弹出Forecast 对话框,Eviews 自动计算出样本估计期内的被解释变量的拟合值,拟合变量记为chukouF ,其拟合值与实际值的对比图如下-2000002000040000600008000010000012000084868890929496980002scalar CHUKOU1 = -5719.991597 + 2.116770043*0 + 3.773129627*0区间估计coef(2) confintconfint(1)=1243-@qtdist(.975,20)*eq01.@sddep confint(2)=1243+@qtdist(.975,20)*eq01.@sddep coef(4) confint1confint1(1)=eq01.@coefs(2)-@qtdist(.975,20)*eq01.*@stderrs(2) confint1(2)=eq01.@coefs(2)+@qtdist(.975,20)*eq01.*@stderrs(2) confint1(3)=eq01.@coefs(3)-@qtdist(.975,20)*eq01.*@stderrs(3) confint1(4)=eq01.@coefs(3)+@qtdist(.975,20)*eq01.*@stderrs(3)六、非线性回归模型的估计1.倒数模型:μββ++=XY 110 在命令窗口直接依次键入GENR X1=1/X LS Y C X12.多项式模型:μβββ+++=2210X X Y 在命令窗口直接依次键入GENR X1=X GENR X2=X^2 LS Y C X1 X23.准对数模型:μββ+++=X Y ln 10 在命令窗口直接依次键入GENR lnX=LOG(X)LS Y C lnX4.双对数模型:μββ+++=X Y ln ln 10 在命令窗口直接依次键入GENR lnX=LOG(X) GENR lnY=LOG(Y)LS lnY C lnX七、异方差检验与解决办法1.X e -2相关图检验法LS Y C X 对模型进行参数估计 GENR E=RESID 求出残差序列GENR E2=E^2 求出残差的平方序列 SORT X 对解释变量X 排序SCAT X E2 画出残差平方与解释变量X 的相关图2.戈德菲尔德——匡特检验已知样本容量n=26,去掉中间6个样本点(即约n/4),形成两个样本容量均为10的子样本。


案例分析1.问题的提出和模型的设定根据我国1978—1997年的财政收入Y 和国民生产总值X 的数据资料,分析财政收入和国民生产总值的关系建立财政收入和国民生产总值的回归模型。
假定财政收入和国民收入总值之间满足线性约束,则理论模型设定为i i i u X Y ++=21ββ其中i Y 表示财政收入,i X 表示国民生产总值。
表1我国1978—1997年财政收入和国民生产总值2.参数估计进入EViews 软件包,确定时间范围;编辑输入数据;选择估计方程菜单,估计样本回归函数如下表 2obsX Y 19783624.100 1132.260 19794038.200 1146.380 19804517.800 1159.930 19814860.300 1175.790 19825301.800 1212.330 19835957.400 1366.950 19847206.700 1624.860 19858989.100 2004.820 198610201.40 2122.010 198711954.50 2199.350 198814922.30 2357.240 198916917.80 2664.900 199018598.40 2937.100 199121662.50 3149.480 199226651.90 3483.370 199334560.50 4348.950 199446670.00 5218.100 199557494.90 6242.200 199666850.50 7407.990 1997 73452.50 8651.140估计结果为Y=858.3108 + 0.100031X(12.78768) (46.04788)R^2=0.991583 S.E.=208.508 F=2120.408括号内为t统计量值。
3.检验模型的异方差(一)图形法1、EViews软件操作。

Eviews估计方法汇总来源:计量经济学01最小二乘法(1)普通最小二乘估计(OLS):这是使用的最为普遍的模型,基本原理就是估计残差平方和最小化,不予赘述。
(2)加权最小二乘估计(WLS)Eviews路径:LS模型设定对话框-----optionsOLS的假设条件最为严格,其他的估计方法往往是在OLS的某些条件无法满足的前提下进行修正处理的。
WLS就是用来修正异方差问题的。
在解释变量的每一个水平上存在一系列的被解释变量值,每一个被解释变量值都有自己的分布和方差。
在同方差性假设下,OLS对每个残差平方ei^2都同等看待,即采取等权重1。
但是,当存在异方差性时,方差δi^2越小,其样本值偏离均值的程度越小,其观测值越应受到重视,即方差越小,在确定回归线时的作用应当越大;反之方差δi^2越大,其样本值偏离均值的程度越大,其在确定回归线时的作用应当越小。
WLS的一个思路就是在拟合存在异方差的模型的回归线时,对不同的δi^2区别对待。
在利用样本估计系数时依旧是使得总体残差最小化,但是WLS会给每个残差平方和一个权重wi=1/δi。
这样,当δi^2越小,wi越大;反之,δi^2越大,wi越小。
Eviews的WLS没有要求权重因子必须是1/δi。
一般纠正异方差性的方法还包括模型变换法,这种方法假定已知Var(ui)=δi^2=δ^2*f(Xi),令权重wi=f(Xi)^(1/2),用f(Xi)^(1/2)去除原模型,可知随机干扰项转换为ui/f(Xi)^(1/2),这时Var(ui)=δi^2=δ^2,即实现了同方差。
由上面的分析可知,WLS核心就是找到一个等式:Var(ui)=δi^2=δ^2*f(Xi)。
这个等式经过调整更容易理解:δ^2=δi^2/f(Xi)或δ=δi/f(Xi)^(1/2)。
δ为某一常数,权重wi=1/f(Xi)^(1/2),经过wi的加权便实现了同方差。
前面提到的特殊权重wi=1/δi,即f(Xi)=1/δi^2,这时δ=δi/f(Xi)^(1/2)=1。
例题中国居民人均消费支出与人均GDP(1978-2000),数据(例题1-2),预测,2001年人均GDP为4033.1元,求点预测、区间预测。
(李子奈,p50)解答:一、打开Eviews软件,点击主界面File按钮,从下拉菜单中选择Workfile。
在弹出的对话框中,先在工作文件结构类型栏(Workfile structure type)选择固定频率标注日期(Dated – regular frequency),然后在日期标注说明栏中(Date specification)将频率(Frequency)选为年度(Annual),再依次填入起止日期,如果希望给文件命名(可选项),可以在命名栏(Names - optional)的WF项填入自己选择的名称,然后点击确定。
此时建立好的工作文件如下图所示:在主界面点击快捷方式(Quick)按钮,从下拉菜单中选空白数据组(Empty Group)选项。
此时空白数据组出现,可以在其中通过键盘输入数据或者将数据粘贴过来。
在Excel文件(例题1-2)中选定要粘贴的数据,然后在主界面中点击编辑(Edit)按钮,从下拉菜单中选择粘贴(Paste),数据将被导入Eviews软件。
将右侧的滚动条拖至最上方,可以在最上方的单元格中给变量命名。
二、估计参数在主界面中点击快捷方式(Quick)按钮,从下拉菜单中选择估计方程(Estimate Equation)在弹出的对话框中设定回归方程的形式。
在方程表示式栏中(Equation specification ),按照被解释变量(Consp )、常数项(c )、解释变量(Gdpp )的顺序填入变量名,在估计设置(Estimation settings )栏中选择估计方法(Method )为最小二乘法(LS – Least Squares ),样本(Sample )栏中选择全部样本(本例中即为1978-2000),然后点击确定,即可得到回归结果。
计量经济学EVIEWS教程计量经济学软件包Eviews教程二、创建工作文件如果不对工作文件进行保存,工作文件中的任何东西,关闭机器时将被丢失。
建立工作文件的方法:点击File/New/Workfile。
选择数据类型和起止日期,并在出现的对话框中提供必要的信息:适当的时间频率(年、季度、月度、周、日);确定起止日期或最大处理个数下面的图片说明了具体操作过程。
1、打开新建对象类型对话框,选择工作文件Workfile,见图二。
(图二)2、打开工作文件新建对话框,要求在Workfile Structure Type 对话框中选择数据结构类型:(1)Dated—regular frequency(默认),见(图三)a;(图三)a(2)Unstructed/Undated,见(图三)b;(图三)b (3)Balanced Panel,见(图三)c。
(图三)c 3、点击OK确认,得新建工作文件窗口,见图四。
(图四)工作文件窗口:它有标题栏、控制按钮和工具条。
标题栏指明窗口的类型workfile、工作文件名。
工具条按钮:Views观察按钮,Procs 过程按钮,Object对象按钮,Print打印选项按钮,Save(保存)工作文件,Details+/-显示/不显示对象的相关信息,Show用来生成对象的一个显示窗口,Fetch(从磁盘上读取数据),Store(将数据存储到磁盘),Delete(删除)对象,Gener(利用已有的序列生成新的序列),Sample(设置观察值的样本区间)。
4、保存工作成果:将工作成果保存到磁盘,点击工具条中save\输入文件名、路径\保存,或点击菜单栏中File\Save或Save as \输入文件名、路径\保存。
5、打开工作文件:我们可以打开一个已有的工作文件继续以前的工作,点击主菜单中的File\Open\Workfile\选定文件\打开。
三、输入和编辑数据输入数据有两种基本方法:data命令方式和鼠标图形界面方式1、data命令方式:命令格式为:data <序列名1> <序列名2>......<序列名n>,序列名之间用空格隔开,输入全部序列后回车就进入数据编辑窗口,如图五所示。