正交试验设计与数理统计作业
- 格式:doc
- 大小:3.20 MB
- 文档页数:45

1.正交试验设计法的基本思想正交试验设计法,就是使用已经造好了的表格--正交表--来安排试验并进行数据分析的一种方法。
它简单易行,计算表格化,使用者能够迅速掌握。
下边通过一个例子来说明正交试验设计法的基本想法。
[例1]为提高某化工产品的转化率,选择了三个有关因素进行条件试验,反应温度(A),反应时间(B),用碱量(C),并确定了它们的试验范围:A: 80-90 CB:90-150 分钟C:5-7%试验目的是搞清楚因子A、B、C对转化率有什么影响,哪些是主要的,哪些是次要的,从而确定最适生产条件,即温度、时间及用碱量各为多少才能使转化率高。
试制定试验方案。
这里,对因子A,在试验范围内选了三个水平;因子B和C也都取三个水平:A: A i= 80°C, A2= 85C, A3=90°CB: B i = 90 分,B2 = 120 分,B3=150 分C: C i = 5%, C2 = 6%, C3= 7%当然,在正交试验设计中,因子可以是定量的,也可以是定性的。
而定量因子各水平间的距离可以相等,也可以不相等。
这个三因子三水平的条件试验,通常有两种试验进行方法:(I)取三因子所有水平之间的组合,即A i B i C i, A1B1C2, A1B2C1,……,A3B3C3,共有33=27 次试验。
用图表示就是图1立方体的27个节点。
这种试验法叫做全面试验法。
全面试验对各因子与指标间的关系剖析得比较清楚。
但试验次数太多。
特别是当因子数目多,每个因子的水平数目也多时。
试验量大得惊人。
如选六个因子,每个因子取五个水平时,如欲做全面试验,则需56=15625次试验,这实际上是不可能实现的。
如果应用正交实验法,只做25次试验就行了。
而且在某种意义上讲,这25次试验代表了15625次试验。
(n)简单对比法,即变化一个因素而固定其他因素,如首先固定B、C 于B i、C i,使A变化之: / A iB1C1 ~A 2' A3 (好结果)如得出结果A3最好,则固定A于A3, C还是C i,使B变化之:A3C1 ~B 2 (好结果)\ B 3得出结果以B2为最好,则固定B于B2, A于A3,使C变化之:/ CiA3B2TC 2 (好结果)\ C3试验结果以C2最好。

[实验项目]实验九正交设计方法及试验结果的统计[教学时数]2课时[实验目的与要求]掌握使用DPS进行正交设计及试验结果的统计方法.[实验材料与设备]计算机;有关数据资料。
[实验内容]1、正交设计方法。
2、正交设计的统计方法。
[实验方法]1、正交设计一般有以下几个步骤:第一步,明确试验目的,确定考核指标第二步.挑因素,选水平。
第三步,选择合适的正交表.第四步,进行表头设计。
第五步,确定试验方案。
2、使用DPS软件进行正交设计方法设计方法:打开DPS→菜单栏→试验设计→正交设计→在对话框中选择相应得因素水平数和试验次数→OK→即可自动显示设计结果。
3、正交设计的统计方法。
(1)单独观测值正交试验结果的方差分析打开DPS→输入数据并选定为数据块→菜单栏→试验统计→正交试验方差分析→输入试验因子数与空闲因子的总数(一般为默认值)→OK→输入空闲因子所在的列号→OK→选择多重比较的方法→确定。
(2)有重复观测值正交试验结果的方差分析打开DPS→输入数据并选定为数据块→菜单栏→试验统计→正交试验方差分析→输入试验因子数与空闲因子的总数(一般为默认值)→OK→输入空闲因子所在的列号→OK→选择多重比较的方法→确定。
(3)因素间有交互作用的正交设计与分析打开DPS→输入数据并选定为数据块→菜单栏→试验统计→正交试验方差分析→输入试验因子数与空闲因子的总数(一般为默认值)→OK→输入空闲因子所在的列号,各列号用空格隔开→OK→选择多重比较的方法→确定。
[指导与训练方案]1、将本次实验内容整理成实验报告。
2、练习:1、试验结果列于表12-26。
试对其进行方差分析。
在进行矿物质元素对架子猪补饲试验中,考察补饲配方、用量、食盐3个因素,每个因素都有3个水平。
试安排一个正交试验方案。
统计方法:将上表格输入DPS的单元格,设成数据块→菜单栏→试验统计→正交设计→输入处理椅子和空闲因子总数,点击:OK→输入空闲因子所在的列号,OK→选择多重比较方法→点确定,即可得统计结果。

枣果皮中酚类物质提取工艺优化及抗氧化活性分析1.实验数据背景叙述。
一:实验关于枣果皮中酚类物质提取工艺优化及抗氧化活性分析。
酚类物质是植物体内重要的次生代谢产物,主要通过莽草酸和丙二酸途径合成,广泛分布于植物界。
许多的酚类物质具有营养保健功效。
现代流行病学研究证明,经常食用富含酚类物质的果蔬能够预防由活性氧导致的相关疾病如癌症、糖尿病、肥胖症等的发生。
二:实验问题:为提高枣果皮中的酚类物质的提取效率,该文以马牙枣为试验材料,对枣果皮中酚类物质提取条件进行了优化。
同时分析枣果皮提取物中酚类物质的抗氧化活性。
三:实验目的:要通过实验得到枣果皮中酚类物质提取的最优条件。
并对提取物中酚类物质清除DPPH,2,2'-连氮基双(3-乙基苯并噻唑啉)-6-磺酸(ABTS)自由基及铁还原能力进行探讨,同时与合成抗氧化剂2,6-二叔丁基对甲酚(BHT)的抗氧化能力进行比较。
2. 实验数据处理方法选择及论述。
一:单因素试验(获得数据,将数据输入excel中,使用excel绘制图表,以便直观感受影响因素对实验的影响趋势。
)以冻干枣果皮为材料,分别以甲醇浓度、提取温度、提取料液比和提取时间作为因素,分析不同的提取条件对枣果皮中酚类物质提取效果的影响,检测指标为提取物中总酚含量。
二:正交试验(设计正交试验以便获得到枣果皮中酚类物质提取的最优条件,用excel进行结果直观分析,见表2。
)以冻干枣果皮为材料,以提取溶剂浓度(A)、提取温度(B)、料液比(C)、和浸提时间(D)作4 因素3水平的L9(34)正交设计(见表1),检测指标为提取物中总酚含量。
表1 枣果皮中酚类物质提取因素水平表三:统计分析所有提取试验均重复3 次,每次提取液的测定均重复3 次。
结果表示为平均值±标准偏差。
应用excel软件对所有数据进行方差分析。
3. 实验数据的处理的过程叙述。
一:在单因素试验中,将每次试验结果输入excel中,选中表格,点击“插入”柱形图。



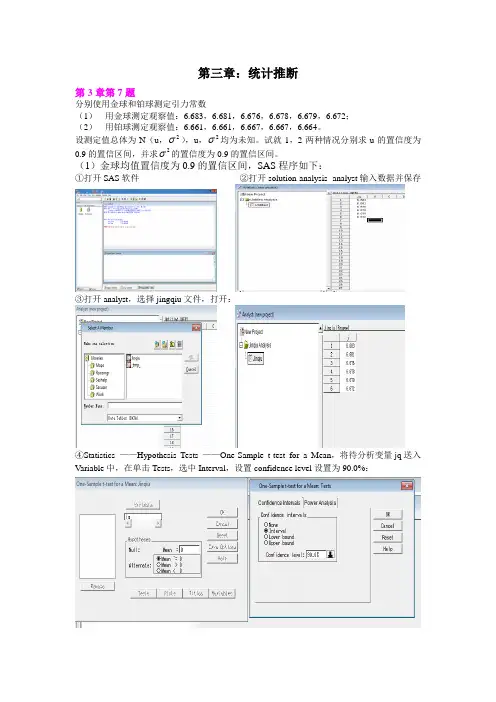
第三章:统计推断第3章第7题分别使用金球和铂球测定引力常数(1)用金球测定观察值:6.683,6.681,6.676,6.678,6.679,6.672;(2)用铂球测定观察值:6.661,6.661,6.667,6.667,6.664。
σ),u,2σ均为未知。
试就1,2两种情况分别求u的置信度为设测定值总体为N(u,2σ的置信度为0.9的置信区间。
0.9的置信区间,并求2(1)金球均值置信度为0.9的置信区间,SAS程序如下:①打开SAS软件②打开solution-analysis- analyst输入数据并保存③打开analyst,选择jingqiu文件,打开:④Statistics ——Hypothesis Tests ——One-Sample t-test for a Mean,将待分析变量jq送入Variable中,在单击Tests,选中Interval,设置confidence level设置为90.0%:⑤结果输出:金球u的置信度为0.9的置信区间为(6.67,6.68)。
(2)铂球均值置信度为0.9的置信区间,SAS程序如下:①打开solution-analysis- analyst输入数据并保存②打开analyst,选择Bq文件,打开:③Statistics ——Hypothesis Tests ——One-Sample t-test for a Mean,将待分析变量bq送入Variable中,在单击Tests,选中Interval,设置confidence level设置为90.0%:④结果输出:铂球u的置信度为0.9的置信区间为(6.66,6.67)。
(3)金球方差置信度为0.9的置信区间,SAS程序如下:①打开analyst,选择Bq文件,打开数据:②Statistics ——Hypothesis Tests ——One-Sample Test for a Variance,将待分析变量jq送入Variable中,并在Null:Var中设置一个大于0的数,再单击Intervals,选中Interval,设置confidence level设置为90.0%:③结果输出:金球σ2的置信度为0.9的置信区间为(676E-8, 0.0001)(4)铂球方差置信度为0.9的置信区间,SAS程序如下:①Statistics ——Hypothesis Tests ——One-Sample Test for a Variance,将待分析变量bq送入Variable中,并在Null:Var中设置一个大于0的数,再单击Intervals,选中Interval,设置confidence level设置为90.0%:②结果输出:铂球σ2的置信度为0.9的置信区间为(379E-8, 507E-7)。

第三章正交试验设计及其统计分析§3-1 正交试验设计利用正交表解决多因素的试验问题:(1)参数和交互作用对指标影响的显著性;(2)参数较优化组合;(3)指标的预测。
一、正交表的特点正交表代号La(bc)的含义:a—正交表行数,即试验点数;b—各因素水平数,c—正交表列数,每一列可安排一个因素。
L4(23)正交表试验号列号1 2 31 1 1 12 1 2 23 2 1 24 2 2 1正交的含意:若将表中2换成-1,则任一列之和为0,任两列乘积的和为0。
若将列看作向量,则两向量垂直相交,即正交。
从试验点的空间分布可知,L4(23)正交表为1/2实施。
(1)均衡搭配:即任一因素的任一水平与其它因素的每一水平相遇的次数均等。
(2)综合可比:即任一因素的各水平出现的次数相等。
二、交互作用表(挂一张L8(27)正交表)1、交互列的位置:要查交互列表。
2、混杂:若在交互两因素的交互列上,安排其它因素或其它因素的交互,则在此列将出现混杂现象。
3、如何对待混杂①若不想用较多的试验,则就可能有混杂,此时要用专业经验来判断。
②若不研究规律,只找出参数较优组合,则可不考虑混杂。
三、试验方案设计1、列因素水平表(挂豇豆脱水试验表)因素水平A B C D参数名称(单位)参数名称(单位)参数名称(单位)参数名称(单位)1 A1 B1 C1 D12 A2 B2 C2 D2 2、选正交表原则:正交表的列数应≥要考察的因素和交互作用个数的最小正交表。
3、表头设计 即因素放在哪一列。
其原则如下:①若不考虑交互作用,则因素随机放各列,但若有余列时,因素最好不要放在其它因素的交互列上,一则避免混杂,二则可看出交互作用的大小。
②若要考虑交互作用,则应先排要交互的因素,其它因素按不混杂的原则随机排列。
4、列出试验方案将表中字码换成对应的水平值。
每一行的因素水平组合即为一个试验点。
(挂清选机试验方案) 四、试验注意以下几点:(1)各因素的水平组合方案不能变。


第三章:统计推断第3章第7题分别使用金球和铂球测定引力常数(1)用金球测定观察值:6.683,6.681,6.676,6.678,6.679,6.672;(2)用铂球测定观察值:6.661,6.661,6.667,6.667,6.664。
σ),u,2σ均为未知。
试就1,2两种情况分别求u的置信度设测定值总体为N(u,2σ的置信度为0.9的置信区间。
为0.9的置信区间,并求2(1)金球均值置信度为0.9的置信区间,SAS程序如下:①打开SAS软件②打开solution-analysis- analyst输入数据并保存③打开analyst,选择jingqiu文件,打开:④Statistics ——Hypothesis Tests ——One-Sample t-test for a Mean,将待分析变量jq送入Variable中,在单击Tests,选中Interval,设置confidence level设置为90.0%:⑤结果输出:金球u的置信度为0.9的置信区间为(6.67,6.68)。
(2)铂球均值置信度为0.9的置信区间,SAS程序如下:①打开solution-analysis- analyst输入数据并保存②打开analyst,选择Bq文件,打开:③Statistics ——Hypothesis Tests ——One-Sample t-test for a Mean,将待分析变量bq 送入Variable中,在单击Tests,选中Interval,设置confidence level设置为90.0%:④结果输出:铂球u的置信度为0.9的置信区间为(6.66,6.67)。
(3)金球方差置信度为0.9的置信区间,SAS程序如下:①打开analyst,选择Bq文件,打开数据:②Statistics ——Hypothesis Tests ——One-Sample Test for a Variance,将待分析变量jq 送入Variable中,并在Null:Var中设置一个大于0的数,再单击Intervals,选中Interval,设置confidence level设置为90.0%:③结果输出:金球σ2的置信度为0.9的置信区间为(676E-8, 0.0001)(4)铂球方差置信度为0.9的置信区间,SAS程序如下:①Statistics ——Hypothesis Tests ——One-Sample Test for a Variance,将待分析变量bq送入Variable中,并在Null:Var中设置一个大于0的数,再单击Intervals,选中Interval,设置confidence level设置为90.0%:②结果输出:铂球σ2的置信度为0.9的置信区间为(379E-8, 507E-7)。

“数理统计”综合作业解析“数理统计”课程综合作业作业要求为了考核同学们综合运⽤统计⽅法解决实际问题的过程,请同学们结合当前社会⽣活实际中的问题,⾃⼰拟定⼀个研究题⽬,并应⽤参数估计、假设检验、回归分析、⽅差分析、正交设计(这些⽅法中⾄少选择两个)对其进⾏分析。
要求:(⼀)内容必须涵盖以下⼏个⽅⾯:1.题⽬;2.研讨的问题是什么;3.相关的数据及来源;4.建⽴的统计模型和统计问题是什么,样本数据是什么;5.使⽤的统计⽅法是什么?使⽤的统计分析软件是什么?5.计算过程(若统计软件,其计算结果是什么)6.对计算结果的说明或解释。
(⼆)格式包括报告题⽬、摘要、正⽂、参考⽂献和附录五个部分。
正⽂内容⼀般包括问题描述、数据描述、模型建⽴、统计⽅法选择和问题求解、结果分析等内容。
报告⽤Word ⽂本格式,中⽂字使⽤宋体、⼩四号字,英⽂⽤Roman 字体5 号字,数学符号⽤MathType 输⼊。
题⽬(⿊体,三号)摘要:(200-400字)(⿊体,⼩四)正⽂(正⽂标题:宋体,粗体,⼩四)⼀、问题提出。
(正⽂内容:宋体,五号)⼆、数据描述(⽤表格表达数据信息,指出数据来源或提供原始数据)三、建⽴统计模型四、统计⽅法设计和⽅法使⽤的条件,计算⼯具的选择。
五、计算过程和计算结果。
六、结果分析。
参考资料(标题:宋体,粗体,⼩四,内容:宋体,五号)附录(标题:宋体,粗体,⼩四,内容:宋体,五号)(三)课外作业提交形式纸质材料和电⼦⽂档注意:纸质材料打印内容从封⾯开始,包括作业要求,直⾄作业的所有内容。
电⼦⽂档:先提交给班长,再由班长将压缩⽂件提交给⽼师。
特别注意电⼦⽂档的名称,按如下模板写:2011级某班“数理统计”综合作业——姓名,学号。
(四)课外作业提交时间参加课程考试那天上午提交纸质材料,当天班长提交电⼦⽂档给⽼师。
请注意:不能复制现有成果,同学之间也不能相互复制内容。
股票市场中变量之间的关系摘要:在经济飞速发展的当代,⾦融市场占据着半壁江⼭,⽽在⾦融市场中股票作为公司筹资的重要来源,它占据着重要的地位,我接下来就是要研究股票市场中变量之间的关系,通过统计分析⽅法还原⼤数据时代海量数据所反映的事实,以及数据之间的规律性。
《实验设计与数据统计》习题1、简述正交试验设计的基本步骤.2、以合成某有机化合物的产率为试验指标。
该有机化合物的合成主要影响因素为反应温度、时间及催化剂,现对其合成工艺进行优化,以提高产率。
根据前期条件试验,确定的因素与水平如表1所示,假定因素间无交互作用。
试用正交设计和极差分析确定各因素的最优水平及组合。
表1 因素水平表3、现代药理学研究表明,红景天具有抗心律失常、调节免疫功能、镇静、抗疲劳、抗缺氧、抗衰老、抗癌等作用。
其化学成分中,红景天苷及其苷元酪醇是红景天主要有效成份,也是评价红景天及其提取物的最重要指标。
红景天有效成分的提取主要以醇提法和水提法为主,而以醇提法尤佳。
分别考察浸膏得率、红景天苷和酪醇含量,三个指标都是越大越好,根据前期预研试验,决定选取3个相对重要的因素:乙醇浓度、加醇量(倍数)和提取时间进行正交试验,它们各有3个水平,具体如下表2,不考虑因素间相互作用,试分析找出较好的提取工艺。
表2 因素水平表4、用石墨炉原子吸收分光光度法测定食品中的铅,为提高测定灵敏度,希望吸光度大。
为提高吸光度,对A(灰化温度/℃)、B(原子化温度/℃)和C(灯电流/mA)3个因素进行了考察,并考虑交互作用A×B、A×C,各因素及水平见表3—14。
试进行正交试验,找出最优水平组合。
表3 因素水平表5、某造板厂进行胶压制造工艺的实验,以提高胶压的性能,因素及水平如表4,胶压板的性能指标采用综合评分的方法,分数越高越好,忽略因素间的交互作用,试用正交设计和极差分析确定各因素的最优水平及组合.。
表4—1 因素水平表6、某制药厂为提高某种药品的合成率,决定对缩合工序进行优化,因素水平表如表4所示,忽略因素间的交互作用,试用正交设计和极差分析确定各因素的最优水平及组合..表5 因素水平表7、某厂拟采用化学吸收法,用填料塔吸收废气的SO 2,为了使废气中SO 2的浓度达到排放标准,通过正我试验对吸收工艺条件进行了摸索,试验的因素与水平如表6所示。
工科研究生数理统计课外作业
一、说明
1.要求:
请大家结合现实生活或者专业背景,说明参数估计、假设检验、方差分析、回归分析、正交设计(至少选择一个)的应用
要求大家自行提出问题、搜集数据(提供原始数据)和假设条件,建立模型,并且应用统计方法和相关统计软件进行模型求解,对计算结果进行解释和说明。
注意:不能复制已有结果,同学之间也不能相互复制相关内容2.评价标准:
以问题表述的清晰性、条件假设的合理性、建模的科学性和创造性、模型表达的正确性、计算方法选择的合理性、结果的正确性和文字表述的清晰程度、格式的规范性(科研论文格式规范)为主要标准
3.课外作业提交形式:
纸质报告(用A4纸打印)包括报告题目、摘要、正文、参考文献和附录五个部分。
正文内容应包括问题描述、数据描述、模型建立、求解和检验、模型结果分析等内容。
报告用Word 文本格式,中文字使用宋体、小四号字,英文用Roman 字体5 号字,数学符号用MathType 输入。
4.课外作业提交时间:由授课老师确定,但最迟提交时间为考试前.
二、报告基本格式
合肥工业大学研究生“数理统计”课程课外作业
姓名:学号:
学院:专业:
类型:
成绩:
题目:
摘要:
关键词:
正文:
一、问题提出,问题分析;
二、数据描述(用表格表达数据信息,指出数据来源或提供原始数据)
三、模型建立:
(1)提出假设条件,明确概念,引进参数;
(2)模型构建;
(3)模型求解。
四、计算方法设计和计算机实现。
五、主要的结论或发现。
六、结果分析与检验参考资料
附录。
一、填空题1、已知X~N(10,12)分布,则X位于9.0至9.5间的概率为0.149882。
2、已知某子样的均值x的数学期望是3.0,子样均值x的方差为0.02,子样的容量为16,则母体的数学期望为3.0,方差为0.32。
3、沉淀法测得BaCl2·2H2O (M=244.24g/mol)中Ba (M=137.33g/mol)的质量分数为0.5617,则这一测量中绝对误差为0.000575,相对误差为0.001022。
4、当总体方差已知时,样本平均数服从正态分布。
当总体方差未知时,样本平均数服从t分布。
5、在试验设计中,黄金分割法是在试验区间内取两个试验点,这两个试验点分别是该试验区间的0.618倍和0.382倍。
6、用正交表安排试验具有整齐可比性和均衡分散性的特征。
7、某试验考虑A, B, C, D四个因素,每个因素取3个水平,并且考虑3个交互作用A×B, A×C, A×D, 则应选择的合适的正交表为L27(313),。
8、误差根据其性质或产生的原因,可分为随机误差、系统误差和过失误差。
二、选择题1.在正交试验设计中,试验指标是(C)。
A.定量的B. 定性的C. 两者皆可D. 没有限定2.L9(34)中的3代表(B)。
A.最多允许安排因素的个数B.因素水平数C.正交表的横行数D.总的试验次数3.在1000—2000的实验范围内,采用黄金分割法找最优点,则第一个实验点和第二个实验点分别为(C)。
A. 1720, 1280B. 1692, 1308C. 1618, 1382D. 1589, 14114.可以进行适合性检验和独立性检验的是(C)。
A. t检验B. F检验C. χ2检验D. 以上均可5.在一个3×3的实验设计中,存在的交互作用有(A)。
A. 1个B. 3个C. 6个D. 9个6.假设检验过程中所犯的错误为第Ⅰ类错误,又称为(A)。
A. 弃真错误B. 取伪错误C. 假设错误D. 检验错误7.用L8(27)进行正交实验设计,若因素A和B安排在1、2列,则A×B应排在第(A)列。
第五章正交试验设计实验实验一镍铁合金电镀最佳配方和工艺条件的优化一.实验目的1.通过实验掌握用正交实验设计实验方案,用数理统计方法处理实验结果的优化试验设计方法。
2.掌握多指标问题的处理方法及定性指标的定量化。
3.加深对合金电镀基本原理、配方及工艺条件的理解。
二.实验原理在一定条件下,镀液中几种金属离子在阴极上共同析出,才能形成含有相应处分的合金镀层。
几种金属在阴极上共沉积达必要条件是:ϕ10+RT/z1Flna1+∆φ1=ϕ20+RT/z2Flna2+∆φ2=∙∙∙∙∙∙∙∙本实验采用络合剂使镍离子和铁离子的沉积电位达到相等,达到共沉积达目的。
三.实验仪器及试剂a)实验仪器直流稳压电源霍尔槽实验仪超级恒温仪 PH计b)氯化钠糖精钠“791”光亮剂十二烷基苯磺酸钠柠檬酸硫酸亚铁硫酸镍硼酸(以上试剂均为分析纯)柠檬酸钠镍板铁板四.实验内容1.镍铁合金电沉积工艺流程紫铜基片→清洗除油→电解除油→流动水洗→混酸侵蚀→流动水洗→去离子水洗→晾干→称重→弱侵蚀去离子水洗→电沉积镍铁合金→流动水洗→去离子水洗→晾干→称重→样品分析及性能测试。
2.霍尔槽实验3.设计正交实验(1). 明确实验目的——找到好的共沉积镍铁合金配方和工艺条件。
(2). 确定实验指标——镀速,光亮度(多指标问题)(3). 确定因素水平表固定参数为:氯化钠 20-25g/l柠檬酸钠 3-4g/l糖精钠 3g/l“791”光亮剂 4-6ml/l十二烷基苯磺酸钠 0.05-0.1g/l柠檬酸适量阳极面积(Ni:Fe) 4:1阴极与阳极面积比:Cu:Fe:Ni为1:2:8温度 50-55℃时间 50min选择适当的正交表,作出正交实验方案,完成实验。
并用极差分析法分析实验结果实验二化工产品的转化率(可根据实际情况实验)为提高某化工产品的转化率,选择了三个有关的因素进行条件试验,反应温度(A),反应时间(B),用碱量(C),并确定了它们的试验范围:A:80-90℃B:90-150MinC:5-7%试验目的是搞清楚因素A、B、C对转化率的影响,哪些是主要因素,哪些是次要因素,从而确定最优生产条件,即温度、时间及用碱量各为多少才能使转化率提高。
正交试验设计与数理统计作业The Standardization Office was revised on the afternoon of December 13, 2020第三章:统计推断第3章第7题分别使用金球和铂球测定引力常数(1)用金球测定观察值:,,,,,;(2)用铂球测定观察值:,,,,。
σ),u,2σ均为未知。
试就1,2两种情况分别求u 设测定值总体为N(u,2σ的置信度为的置信区间。
的置信度为的置信区间,并求2(1)金球均值置信度为的置信区间,SAS程序如下:①打开SAS软件②打开solution-analysis- analyst输入数据并保存③打开analyst,选择jingqiu文件,打开:④Statistics ——Hypothesis Tests ——One-Sample t-test for a Mean,将待分析变量jq送入Variable中,在单击Tests,选中Interval,设置confidence level设置为%:⑤结果输出:金球u的置信度为的置信区间为,。
(2)铂球均值置信度为的置信区间,SAS程序如下:①打开solution-analysis- analyst输入数据并保存②打开analyst,选择Bq文件,打开:③Statistics ——Hypothesis Tests ——One-Sample t-test for a Mean,将待分析变量bq送入Variable中,在单击Tests,选中Interval,设置confidence level设置为%:④结果输出:铂球u的置信度为的置信区间为,。
(3)金球方差置信度为的置信区间,SAS程序如下:①打开analyst,选择Bq文件,打开数据:②Statistics ——Hypothesis Tests ——One-Sample Test for a Variance,将待分析变量jq送入Variable中,并在Null:Var中设置一个大于0的数,再单击Intervals,选中Interval,设置confidence level设置为%:③结果输出:金球σ2的置信度为的置信区间为(676E-8,(4)铂球方差置信度为的置信区间,SAS程序如下:①Statistics ——Hypothesis Tests ——One-Sample Test for a Variance,将待分析变量bq送入Variable中,并在Null:Var中设置一个大于0的数,再单击Intervals,选中Interval,设置confidence level设置为%:②结果输出:铂球σ2的置信度为的置信区间为(379E-8, 507E-7)。
第3章第13题本题是两个正态总体的参数假设检验问题。
题目中已知两个总体方差相等,且相互独立。
关于均值差u1-u2的检验,其SAS程序如下:①打开solution-analysis- analyst输入数据并保存②打开analyst,选择markandsgrass文件,打开:③Statistics ——Hypothesis Tests——Two Sample t-test for Means,选择Twovariables,将两个变量分别送入Group1和2,并设置Mean1-Mean2=0,再将confidence level设置为%:④结果输出:因为在t 检验中p-value 值<,所以高度拒绝原假设,即认为两个作家所写的小品文中包含由3个字母组成的词的比例有高度显著的差异。
第3章第14题本题也是两个正态分布参数的假设检验问题,对方差进行假设检验,采用F检验,其相关SAS程序如下:①同上题的①②两步,打开数据;②Statistics ——Hypothesis Tests——Two Sample test for Variances,选择None,并将confidence level设置为%:③结果输出:因为在F检验中p-value 值>,所以高度接受原假设,即认为两总体方差相等是合理的。
第四章方差分析和协方差分析第4章第1题本题目属于单因素试验的方差分析,且题目中已知各总体服从正态分布,且方差相同,其SAS程序如下:①将数据输入SAS生成数据文件,然后运行②打开analyst,然后选择数据文件kangshesu,打开:③Statistics ——ANOVA ——ONE-WAY ANOVA,将分类变量su送入Independent中,将响应变量x送入Dependent中:④结果输出:因为p-value 值< ,所以高度拒绝原假设,即认为这些百分比的均值有高度显著差异。
第4章第2题①将数据输入SAS生成数据文件,然后运行②打开analyst,然后选择数据文件Dl,打开:③选择Statistics → ANOVA → FATORIAL ANOVA,将分类变量nd和wd送入Independent中,将响应变量X送入Dependent中:④结果输出:从分析结果可知,浓度nd的p-value值<,所以浓度对生产得率的影响显著;温度wd的p-value值>和交互作用nd*wd的p-value值>,所以温度和交互作用对生产得率的影响不显著,即只有浓度的影响是显著的。
第五章正交试验设计第5章第1题第5章第3题将A、B、C、D四个因素的水平按照L9(34)排出普通配比方案如下:因素A B C D试验号1 1 1 1 12 1 2 2 23 1 3 3 34 2 1 2 35 2 2 3 16 2 3 1 27 3 1 3 28 3 2 1 39 3 3 2 1由于题目要求各行的四个比值之和为1,故对每行分别进行计算:第一组:+++= 第二组:+++= 第三组:+++= 第四组:+++= 第五组:+++= 第六组: 第七组: 第八组: 第九组:1号试验中四种因素的比为 A:B:C:D=:::,因此在1号试验中A=*5.02.03.01.01+++=;B=*5.02.03.01.01+++=C=*5.02.03.01.01+++=;D=*5.02.03.01.01+++=同理:在2号试验中A=1/9=;B=4/9=;C=1/9=;D=3/9=在3号试验中A=1/8=;B=5/8=;C=1/8=;D=1/8=在4号试验中A=3/8=;B=3/8=;C=1/8=;D=1/8=在5号试验中A=3/13=;B=4/13=;C=1/13=;D=5/13=在6号试验中A=3/13=;B=5/13=;C=2/13=;D=3/13=在7号试验中A=2/9=;B=3/9=;C=1/9=;D=3/9=在8号试验中A=2/9=;B=4/9=;C=2/9=;D=1/9=在9号试验中A=2/13=;B=5/13=;C=1/13=;D=5/13=最后按照各自的比例计算,得到所求的配比方案如下表:因素A B C D试验号1 1 1 3 22 2 1 1 13 3 1 2 34 1 2 2 15 2 2 3 36 3 2 1 27 1 3 1 38 2 3 2 29 3 3 3 1第六章回归分析第6章第5题(1)做散点图,利用SAS/INSIGHT进行操作,其SAS程序及结果如下:①将数据输入SAS生成数据文件,然后运行:②打开SAS Interactive data analysis,然后选择数据文件,打开:③Analyze——Scatter Plot,在Scatter Plot窗口中将自变量x送入X, 将因变量y 送入Y:④结果输出:(2)回归方程求解:根据题意求y与x、x2之间的回归方程,因此令x1=x,x2=x2,采用SAS/INSIGHT进行求解,其相应的SAS程序及结果如下:①将数据输入SAS生成数据文件,然后运行:②打开SAS Interactive data analysis,然后选择数据文件,打开:③设置参数,Analyze→Fit,将Fit窗口中的自变量x1, x2送入X, 将因变量y送入Y④结果输出:结果第二部分提供了关于多元线性回归模型拟合的一般信息和模型方程,方程表明截距估计值为,表明在固定x2时,x1每增加1个单位时,y增加,同理可知的意义。
结果第三部分是模型拟合的汇总度量表,其中的相应均值(Mean of Response)是因变量 y 的平均值,模型决定系数R^2为,表明变量y变异有%可由x1,x2两个因素变动来解释. 校正-R^2为,考虑了加入模型的变量数,所以比较不同模型时用校正-R^2更适合。
结果第四部分是方差分析表,是对模型作用是否显著的假设检验。
由于p-value值<<,所以高度拒绝原假设,即认为有足够的理由断定该模型比所有自变量斜率为0的基线模型要好。
结果第五部分是三型检验表(Type III Tests),是F统计量和相联系的p值检验各自变量的回归系数为零的假设.(<表明x1的回归系数在统计上作用显著,不能舍去.同理(<)表明 x2的回归系数在统计上作用显著,不能舍去。
结果第六部分是参数估计表,给出了排除其它因素的各回归系数的显著性,包括对截距和变量x1,x2 的显著性检验.其中<(<表明截距的作用显著,不能舍去。
将x1=x,x2=x2,代入回归方程即可得到x、x2、y之间的回归方程为:y=+。
第6章第6题①将数据输入SAS生成数据文件,然后运行:②打开SAS Interactive data analysis,然后选择数据文件,打开:③设置参数,Analyze→Fit,将Fit窗口中的自变量x1, x2,x3送入X, 将因变量y 送入Y④结果输出:回归方程为:y=+×x1+×x2+×x3。
(1)当α=时:对于截距,因P<<,表明其在统计上作用高度显著,不能舍去。
对于x1,因P=<,故x1的回归系数在统计上作用显著,不能舍去。
对于x2,因P=<,故x2的回归系数在统计上作用显著,不能舍去。
对于x3,因P=<,故x3的回归系数在统计上作用显著,不能舍去。
由方差分析可知该该模型的 P= < ,故作用显著。
(2)当α=时:对于截距,因P<<,表明其在统计上作用高度显著,不能舍去。
对于x1,因P=≈,故x1的回归系数在统计上作用显著,不能舍去。
对于x2,因P=>,故x2的回归系数在统计上作用不显著,应该舍去。
对于x3,因P=<,故x3的回归系数在统计上作用显著,不能舍去。
优化后可得多元性回归方程为:y=++。
第6章第9题首先建立回归模型:y=b0+b1*x1+b2*x2+b3*x3+b4*x4+b5*x11+b6*x12+b7*x13+b8*x14+b9*x22+b10 *x23+b11*x24+b12*x33+b13*x34+b14*x44其中:x11=x1*x1;x12=x1*x2;x13=x1*x3;x14=x1*x4;x22=x2*x2;x23=x2*x3;x24=x2*x4; x33=x3*x4;x34=x3*x4;x44=x4*x4;①将数据输入SAS生成数据文件,然后运行:②打开analyst,选择sd文件,打开:③Statistics——Regression ——Linear,在Linear 窗口中将变量x1,x2,x3,x4,x11,x12,x12,x14,x22,x23,x24,x33,x34,x44送入Explanatory, 将变量y送入Dependent 中→Model →选中stepwise selection→OK④结果输出:由逐步分析过程知,截距、x24及x3的作用显著,所以回归方程为:y=将x3=x3,x24=x2*x4代入得y=第6章第10题(1)①将数据输入SAS生成数据文件,然后运行:②打开SAS Interactive data analysis,然后选择数据文件XBSL,打开:③Analyze——Scatter Plot,在Scatter Plot窗口中将自变量x送入X, 将因变量y 送入Y:由散点图可以看出,该组数据的散点图呈现S形增长趋势,可以采用Logistic非线性回归模型拟合此数据。