基于OWL元模型的本体建模研究
- 格式:pdf
- 大小:140.48 KB
- 文档页数:5

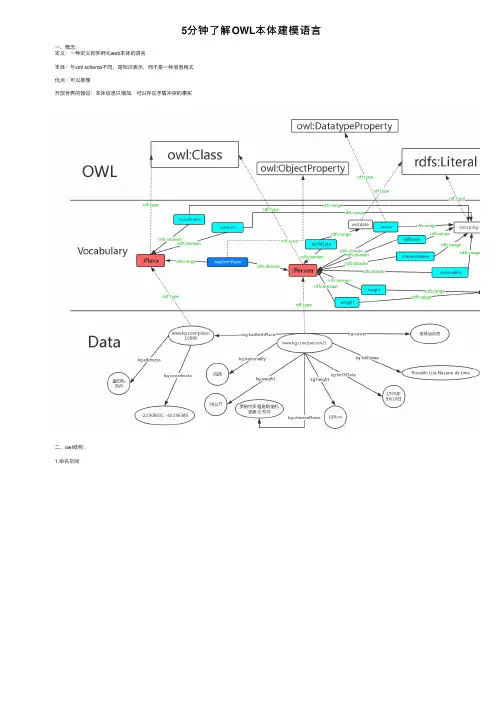
5分钟了解OWL本体建模语⾔⼀、概念:定义:⼀种定义和实例化web本体的语⾔本体:与xml schema不同,是知识表⽰,⽽不是⼀种消息格式优点:可以推理开放世界的假设:本体信息只增加,可以存在⽭盾冲突的事实⼆、owl结构:1.命名空间2.本体头部owl:Ontology元素是⽤来收集关于当前⽂档的OWL元数据的。
rdf:about属性为本体提供⼀个名称或引⽤。
根据标准,当rdf:about属性的值为""时,本体的名称是owl:Ontology元素的基准URI。
rdfs:comment提供了显然必须的为本体添加注解的能⼒。
owl:priorVersion是⼀个为⽤于本体的版本控制系统提供相关信息(hook)的标准标签。
owl:imports提供了⼀种嵌⼊机制。
owl:imports接受⼀个⽤rdf:resource属性标识的参数。
rdfs:label来对本体进⾏⾃然语⾔标注。
3.基本元素类(class)、属性(property)类的实例(instance)3.1类和个体类rdfs:subClassOf 所属⽗类个体rdf:type = 所属类3.2属性rdfs:subPropertyOf, rdfs:domain, rdfs:range数据类型属性对象属性3.3属性特性TransitivePropertySymmetricPropertyFunctionalPropertyinverseOfInverseFunctionalProperty3.4. 属性限制allValuesFromsomeValuesFrom参考资料:。


基于本体的数据结构课程知识表示研究与实现随着信息技术的飞速发展,人们对于知识的需求越来越高,尤其是在教育领域。
数据结构课程是计算机科学与技术专业中重要的一门课程,对于学生的计算机科学素养和编程能力的提高具有重要的作用。
然而,数据结构课程的知识点繁多,难度大,学生往往难以全面理解和掌握。
如何有效地表示和组织数据结构课程的知识点,是一个亟待解决的问题。
本文提出了一种基于本体的数据结构课程知识表示方法,并对其进行了实现和验证。
本体是一种形式化的知识表示语言,它能够用于描述领域知识的概念、属性、关系等。
在本体的基础上,我们将数据结构课程的知识点进行了建模和表示,形成了一个完整的知识结构。
首先,我们对数据结构课程的知识点进行了分析和分类。
根据知识点的性质和层次,我们将其分为基础概念、线性结构、树形结构、图结构等四个部分。
在每个部分中,我们又将知识点进行了细分和归纳,形成了一个层次化的知识结构。
其次,我们使用OWL(Web Ontology Language)语言对数据结构课程知识进行了建模。
OWL是一种基于本体的知识表示语言,能够描述概念、属性、关系等。
我们将数据结构课程的知识点用OWL 语言进行了建模,形成了一个本体结构。
在本体中,我们定义了课程的概念、知识点的概念、知识点之间的关系、知识点的属性等。
这些概念和关系能够准确地描述数据结构课程的知识结构,帮助学生更好地理解和记忆知识点。
最后,我们使用Protégé软件对本体进行了实现和验证。
Protégé是一种开源的本体编辑器,能够帮助用户创建和编辑本体。
我们将OWL语言表示的本体导入到Protégé软件中,进行了实现和验证。
在实现过程中,我们发现本体的表示能够帮助学生更好地理解数据结构课程的知识点,同时也能够帮助教师更好地组织和教授知识点。
在验证过程中,我们对本体进行了测试和调试,发现其表示能够准确地描述数据结构课程的知识结构,能够满足学生和教师的需求。


OWL本体之间概念相似度计算研究的开题报告
一、研究背景
现代信息技术快速发展,促进了语义Web的建设,语义Web通过Ontology规范和描述了知识和概念之间的关系,为机器自动推理提供了一种强有力的基础。
然而,大量的本体与知识库在语义Web上的广泛应用,使得概念的相似性计算显得越来越重要。
概念相似度计算是自然语言处理中的一个重要问题,它可以应用于对概念语义信息的挖掘、文本分类、问答系统中关键词选择、网络信息检索中的筛选等多种领域。
OWL(Web Ontology Language)本体是语义Web中常用的本体描述语言,本体之间概念的相似度计算可以为语义搜索、本体匹配和数据集成等多个方面提供支持。
二、研究目的
本研究的目标是设计一种有效的OWL本体之间的概念相似度计算方法,使其能够支持本体匹配、语义搜索和数据集成等应用。
三、研究内容
1. OWL本体描述语言的研究
OWL是一种本体描述语言,本研究将深入学习OWL语法、本体结构和知识表示等相关内容,为后续计算概念相似度做好准备。
2. 概念相似度计算算法研究
研究传统的基于词汇重叠的概念相似度计算方法,如路径长度、信息系数等,并对其进行改进和创新,提高其对语义信息的准确性和鲁棒性。
3. 基于OWL本体的相似度计算系统设计与实现
设计和实现基于OWL本体的概念相似度计算系统,包括本体的读取与解析、概念节点的分析和计算以及结果的展示等模块。
四、研究意义
本研究可以为语义Web的建设提供强有力的支持,为本体匹配、语义搜索和数据集成等多个领域提供基础技术支撑。
此外,在自然语言处理领域中,本研究也为相关技术的发展提供了参考和借鉴。


基于OWL本体构建的网页图文摘要提取算法研究的开题报告一、研究背景和意义随着信息技术的飞速发展,人们获取信息的方式和途径越来越多元化,但是海量信息的过程中,用户面临的一个难点是信息的有效筛选和摘要。
在互联网时代,网页成了人们获取信息最重要的来源之一。
网页中的图文信息对于数据挖掘、信息检索等领域都有着重要的应用价值。
简洁的图文摘要不仅能够帮助用户快速了解文本主题和内容,提高用户获取信息的效率,也对于信息检索系统的性能提升具有积极的作用。
本体论是一种描述事物及事物之间关系的一种模型,使用形式化的语言对实体和实体之间的关系进行定义和描述。
本体论的一个核心是本体语言OWL。
它提供了一个精确、可取消和可扩展的表达方式,能够帮助用户进行数据的整理和分类,提高数据的可重用性。
基于本体论构建的网页图文摘要提取算法,可以通过对网页文本内容进行语义解析,挖掘网页内容中的潜在信息,将其像机器人一样“自动化”摘取出来,为用户提供更加准确、精练和全面的图文摘要。
因此,本研究旨在基于OWL本体构建网页图文摘要提取算法,提高信息筛选和摘要的效率和准确率,促进信息处理和应用的发展。
二、研究内容本研究将着重围绕基于OWL本体构建的网页图文摘要提取算法,探索如何利用本体语言OWL对网页内容和语义进行精确的描述和定义,提高对网页内容的理解和分析能力,从而实现自动化的图文摘要提取。
具体实现步骤如下:1. 网页语义解析和本体建模:对网页文本内容进行语义解析,提取关键词、实体、事件等信息,构建本体模型,利用OWL语言对关键词、实体和事件等元素进行精确的描述和定义。
2. 网页图文提取:利用上一步中建立的本体模型,从网页中自动提取图片、文本、视频等元素,并通过推理技术进行关联,实现图文信息的自动整合和提取。
3. 图文摘要生成:基于提取的图文信息,设计合适的算法,生成简洁、准确、全面的图文摘要,并通过可视化界面的形式展示给用户,提高用户浏览效率。

基于OWL-S的Web服务质量本体的描述模式的设计魏娟丽【摘要】基于WSDL的Web服务描述没有涉及到Web服务语义信息的表示,仅仅从语法的角度解决了Web服务信息的描述.随着语义Web概念的提出,如何描述Web服务的语义信息成为学术界研究的热点.论述了OWL-S语言如何实现对Web服务的语义描述.同时针对OWL-S在描述服务质量方面的不足,提出了Web 服务质量本体的描述模式,以方便根据Web服务的质量信息对服务类中的服务进行筛选.【期刊名称】《现代电子技术》【年(卷),期】2006(029)015【总页数】2页(P65-66)【关键词】质量本体;描述模式;OWL-S;Web服务【作者】魏娟丽【作者单位】西安体育学院,陕西,西安,710068【正文语种】中文【中图分类】TP393.091 语义Web服务的描述语言OWL-SWeb服务的发现、自动组合和互操作,都需要对服务进行一定的语义描述。
基于WSDL的Web服务描述语言主要集中于数据交换和服务发布的语法标准。
计算机缺乏对服务描述的语义理解。
目前,研究者们提出了专门描述服务语义的OWL-S 语言[1]。
OWL-S包含一整套本体提供了Web服务的词汇表以描述服务的语义,他能够根据服务的输入(Inputs)、输出(Outputs)、前提条件(Preconditions)以及结果(Effects)进行推理。
OWL-S使得Web服务具备机器可理解性和易用性,从而支持智能主体自动的、动态的Web服务发现、执行、组合和互操作。
OWL-S包含以下3种任务:自动Web服务发现对于特定Web服务能够自动定位,这种服务匹配是基于语义的,而不是基于关键字的匹配。
自动Web服务调用通过计算机程序或智能主体自动执行某一特定的Web服务。
在这一点上,传统的Web服务技术已经能够做到这一点。
自动服务组合和互操作这个任务是让计算机可以自动地选择、组合Web服务,从而执行一些较复杂的任务。


网络本体语言(OWL)的标准体系解析1OWL系列标准规范体系的构成为了更好地描述语义化本体模型和进行知识表述,W3C首先提出用来描述资源及其之间关系的语言规范:资源描述框架(Resources Description Frame,RDF),在此基础上,欧洲开发了语义交互语言(Ontology Interchange Language,OIL),美国开发了DAML(DARPA Agent Markup Language)。
这两种网络本体语言都是对RDF类似的扩展,因此后来合并为DAML+OIL,随后W3C将其规范为理解力更强的网络本体语言(Web Ontology Language,OWL)。
OWL系列标准规范体系由6个推荐性标准文档组成,分别从理论、实例及规范性定义的角度对OWL进行了全面、简洁及规范化的阐述,它们是:●《网络本体语言概述》(OWL Web Ontology Language:Overview):通过列出OWL的语言特征并给出其简要的描述,对OWL进行简单介绍。
它通过对OWL各子语言特征的非形式化描述,提供了OWL的入门知识[2]。
●《网络本体语言指南》(OWL Web Ontology Language:Guide):通过一个扩展的例子说明如何使用OWL语言,同时也给出了这些文档中用到的术语的解释[2]。
具体内容包括如何使用OWL本体语言定义类和类的属性,以形成一个形式化的域;定义个体并确定它们的属性,并且对这些类和个体进行推断,以达到网络本体语言的形式化语义的许可程度[3]。
●《网络本体语言参考》(OWL Web Ontology Language:Reference):该文档对OWL语言的整体构造进行了结构化的非形式化描述[2],使用RDF/XML语法对OWL的所有建模原语进行子系统及详尽的描述,试图为构建OWL的用户提供参考[4]。
●《网络本体语言语义与抽象语法》(OWL Web Ontology Language:Semantics and Abstract Syntax):对OWL进行了最终的、形式化的规范性定义[2]。