基于Protege的本体建模研究综述
- 格式:pdf
- 大小:258.47 KB
- 文档页数:3

CoMoTo_⼀个基于本体的情境建模⼯具CoMoTo:⼀个基于本体的情境建模⼯具徐朝晖吴刚上海交通⼤学软件学院,上海 200240摘要:情境感知是近⼏年来普适计算的研究热点,合适的情境建模⽅法和⼯具是实现情境感知的基础。
本⽂采⽤了基于本体的⽅法进⾏情境的建模,并从通⽤性和易⽤性两个⾓度出发,给出了⼀个基于本体的情境建模⼯具(CoMoTo)。
⽂中讨论了对情境进⾏分级建模的⽅法,描述了该建模⼯具的分析与设计⼯作,并通过⼀个案例说明了该⼯具的建模能⼒。
关键词:情境建模;本体;建模⼯具1.引⾔普适计算是以⼈为中⼼的计算,⼀个重要特性就是情境感知的能⼒,即能随着所处环境中情境的变化⽽动态地作出相称的反应。
为了更好地描述和管理情境,需要对情境有⼀个统⼀的认识。
许多⽂献都给出了情境的定义,但因为作者分析⾓度的不同⽽不尽相同,Dey[1]等⼈提出的定义是其中具有代表性、通⽤性相对较强的⼀个,他们认为情境是任何可以⽤来刻画⼀个实体的处境的信息,⽽这个实体可以是⼈、地⽅或者任何跟⽤户与应⽤之间的交互有关联的物体(包括⽤户和应⽤本⾝)。
本⽂涉及的情境,其含义均参考这⼀描述。
在情境感知应⽤中,情境信息可以通过多种渠道获得(例如传感器、存储器及⼿⼯输⼊等),情境信息的这种异源性导致对其进⾏描述、管理和利⽤等操作都将是复杂的过程。
情境模型通过为情境感知应⽤提供情境的抽象描述,使得上述这些复杂的操作对其变得透明,从⽽在很⼤程度上简化了搭建情境感知应⽤的流程。
因此,⼀个具有良好结构的情境模型是构建情境感知系统的关键[2]。
本体作为⼀种描述⼿段,能明确地、形式化⽽规范地对共享概念模型进⾏说明[3],强⼤的表达能⼒使得其能描述更复杂的情境,⽽它提供的丰富的语义⽀持也使得基于情境进⾏推理成为可能。
得益于这些优势,研究⼈员⼴泛使⽤本体对情境信息进⾏建模。
当前已有多种软件⽤于构建本体,斯坦福⼤学开发的Protege便是其中优秀的⼀员。
然⽽,由于Protege⾯向所有领域的本体构建,其极强的通⽤性使得操作⽐较复杂,建模⼈员需要有很强的专业知识。

语义网技术在知识图谱构建中的应用研究随着互联网的不断发展,人们的知识需求也变得越来越高,如何更好地组织和利用大量的知识成为了重要的研究领域。
知识图谱作为一种新型的知识组织方式,被广泛地应用于各种领域中。
语义网技术作为知识图谱构建的重要组成部分,也受到了广泛关注和应用。
一、知识图谱和语义网的概念及关系知识图谱是一种以图谱形式来描述现实世界中实体、属性、关系的知识组织结构。
知识图谱由大量的三元组(即主语-谓语-宾语)构成,它可以帮助人们更好地理解和利用知识。
语义网是一种通过在Web上表示、共享和使用数据,以提供更加智能化和有用的网络的技术。
语义网技术包括本体论、元数据、知识表示语言等。
知识图谱可以看作是语义网技术的应用之一。
二、语义网技术在知识图谱构建中的应用1、本体论建模本体是描述现实世界中特定领域或应用中概念及其关系的形式化表示。
它是知识图谱构建的核心组成部分,也是语义网技术的重要应用。
本体的建立需要通过专门的建模工具进行,如Protege、OntoStudio等。
2、知识表示语言知识表示语言包括RDF、RDFS、OWL等,它们提供了一种机器可读的方式来描述知识,并可以在语义层面上对知识进行表示和推理。
3、实体链接实体链接是指将文本中的实体与知识图谱中的对应实体进行链接。
常用的实体链接技术包括基于规则的方法、基于统计的方法和基于深度学习的方法等。
4、关系抽取关系抽取是指从文本中抽取出实体之间的关系。
常用的关系抽取技术包括基于规则的方法、基于模板的方法和基于深度学习的方法等。
5、链接数据链接数据是指将知识图谱与外部数据源进行链接,使得用户可以从不同的角度来理解和利用知识。
常用的链接数据技术包括SPARQL查询、Linked Data Platform等。
三、语义网技术在知识图谱构建中的挑战与展望1、本体的建模本体建模需要考虑到不同领域知识的复杂性和多样性,而且需要不断地维护和更新。
因此,如何有效地进行本体的建模是一个重要的挑战。

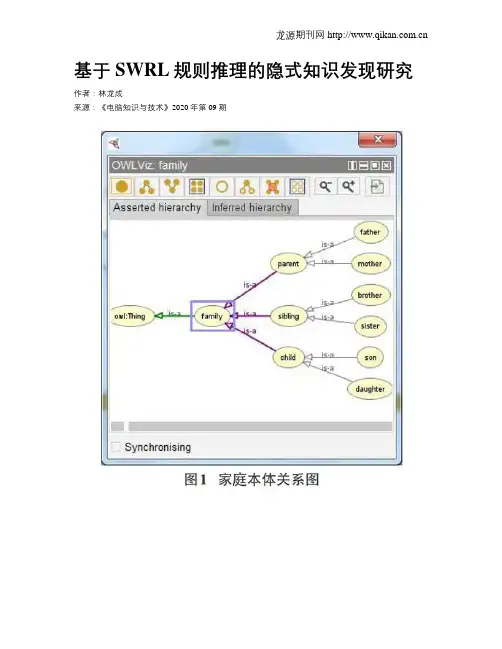
基于SWRL规则推理的隐式知识发现研究作者:林龙成来源:《电脑知识与技术》2020年第09期摘要:语义网( semantic web)是当前Web的扩展,已被各个领域广泛接受,本体是语义网的关键,利用本体语言对Web上已有的信息进行更为有意义的组织和编码,从而实现机器与人之间的有效通信。
语义网规则语言SWRL( Semantic Web RuleLanguage)是以语义的方式呈现规则的一种语言,本文首先介绍了本体构建的基本步骤,并依据此步骤构建了家庭本体,设计了针对家庭关系的SWRL规则,最后利用HermiT推理机挖掘出隐式的家庭关系。
关键词:本体;SWRL;Protege;隐式知识发现中图分类号:TP311 文献标识码:A文章编号:1009-3044(2020)09-0191-02背景语义网的概念是由万维网(WWW)的发明者Tim BernersLee在1996年提出的,目标是将当前的信息转换成机器友好的语言,语义网并不是一个独立的网络,而是当前网络的扩展,它赋予信息明确的含义,使得信息共享和重用成为可能,计算机和人们能够更好地协同工作。
简单地说,它被称为信息的储存库和表达这些信息所涉及的语言。
近年来.语义网以其良好的知识表示、交流、共享和推理能力,在web上得到了广泛的应用,从支撑网站到让搜索引擎更容易地理解网页的内容,语义网技术正在被各式各样的应用所使用。
1 本体构建本体是对特定领域中概念的形式化的明确描述,每个概念的属性描述了概念的各种特征和属性。
一个本体和一组单独的类实例构成了一个知识库。
本体构建齄1齄包括以下几个步骤:1)确定本体的领域和范畴。
可以通过回答下面几个问题来确定本体的应用领域和范畴:包括本体应用到哪个领域?我们要用本体论做什么?对于哪些类型的问题,本体中的信息应该提供答案?谁将使用和维护本体?2)考虑复用现有本体的可行性。
可以下载已经开发好的本体,导入到本体开发环境中。

本体的构建方法大连理工仇鹏1.一些概念•本体(ontology)这一概念源自哲学,用于表示客观的存在。
信息科学中的本体概念主要是用来描述所研究领域的背景知识。
•本体的定义众说纷纭,比较有代表性的定义是:本体是共享概念模型的明确的、形式化的规范描述。
•我们可以将本体简单形式化为O=<C,R>,其中C=Concept,R=Relationship。
•本体的结构表示为一5元组{C,R,H R,Rel,A}•本体被用于构造一人与人、人与机能共同理解的知识背景,在人与人、人与机交流中起到桥梁作用。
2.本体的构造方法•人工方法;由领域专家借助工具(如protege)完成本体构建,已有许多成功例子,如Cyc•半自动方法;通过大量领域数据,在专家的协助下完成本体构建•自动方法;完全靠大量的领域数据,运用数据挖掘、人工智能等方法自动构建本体,准确率不高。
2.本体构建方法相比之下,人工构建本体有较成功的案例,但构造代价大,且构造的本体缺乏灵活性难以适应外界变化。
而完全自动的由机器构造本体,准确性不高,且受训练数据影响较大,实施有一定难度。
半自动构建已有不少学者提出了可行的方案。
3.本体构建主要解决的问题•概念的提取•关系的提取,包括层次关系、一般非层次关系的提取•公理的提取4.基于字典构造方法•字典是预先做好的,形式化表示词的词性、词义以及词之间关系的一种工具。
•字典是一个基础的通用本体•一些字典英文WordNet中文HowNet 知网CKIP (台湾)4.基于字典构造方法利用概念与关系提取分词技术从文档中抽词,利用字典对词的词性标注去除虚词,保留实词并按性质分类标注。
如“电脑”标“Nab”, “软件”标“Nac”在字典中标注就构成了一种层次关系,这一关系可以利用到词的聚类和词的关系分析中去。
4.基于字典构造方法预先定义好不同词在句中的角色,如“天空”、“北京”等其角色即为概念,“位置”、“香气”等角色即可以为概念也可以为属性。


知识图谱学习与实践(5)——Protégé使⽤⼊门1 Protégé简介Protégé是⼀个本体建模⼯具软件,由斯坦福⼤学基于java语⾔开发的,属于开放源代码软件。
软件主要⽤于语义⽹中本体的构建和基于本体的知识应⽤,是本体构建的核⼼开发⼯具,最新版本为5.5.0(截⾄2019年7⽉)。
Protégé⽀持中⽂,能够实现实体关系的中⽂展⽰。
如下图。
具体来说,Protégé具有以下功能。
类建模。
Protégé提供了⼀个图形化⽤户界⾯来建模类(包括概念)和它们的属性以及关系。
实例编辑。
根据创建的类型,Protégé会⾃动产⽣交互的形式,可以根据类之间的关系获得相应实例的约束,并对实例进⾏编辑。
模型处理。
Protégé有⼀些插件库,可以定义语义、解答询问以及定义逻辑⾏为。
模型交换。
最终的模型(类、实例、关系、属性等)能以各种各样的格式被保存和加载,包括XML、UML、RDF、OWL等。
2 Protégé的安装直接运⾏Protege.exe即可。
Protégé是由java开发的,运⾏时需要java运⾏时环境,运⾏时可能需要配置⼀下java的运⾏时环境,按照提⽰进⾏配置就可以了。
3 软件主要⼯作tab打开软件后,可以看到⼯作区域是由很多tab组成。
Active ontology是显⽰当前的实体名称,以URI的形式显⽰,前⾯是后⾯跟着主机名(我的主机名称为dell),再后⾯是默认的根据时间命名实体。
Entities,可以看作是实体的总览,能够看到我们创建实体的⼀些主要信息,是对实体信息的汇总。
Classes,是对本体模型中,类型部分的编辑,能够定义类之间的层次关系,相互之间的关系。
Object properties,物体关系,可以理解为编辑实体外部的关系,也就是实体和实体之间的关系。

Geo本体geo-ontology层次结构图应用地理本体是最小粒度的地理本体和原子地理本体。
因此,实际应用中包含的空间信息量最丰富,但信息的共享和重用最少;domaingeo-ontology是针对空间信息领域的一个层次结构的概念系统,包含空间信息领域里共同认可的共享知识库;Topgeo本体描述了空间事物和现象最常见的概念系统,具有最大程度的共享性。
图可以看出,随着geo-ontology层次的不断升高,信息共享和互操作的程度也越来越高,范围也越来越大。
同时,geo-ontology的概括程度也越来越高,但是也存在详细程度不断降低,用户在高层会获得较少的信息详细程度。
本体描述通过subclassof,subpropertyof形成概念及其关系的分类化(上下级关系)、通过sameclassas,SameProperty如INVERSEOF、Equalento等形成语义关系(对等关系),如概念之间的同义和反义,通过intersectionof,unionof,oneof等构成概念间的逻辑组合关系,(不同应用和需求的关系)关系约束由域、范围、hasvalue、序数、最大基数、最小基数等描述,通过disjointwith,uniqueproperty,unambiguousproperty,transitiveproperty等实现对概念及其关系的公理定义。
地理本体建模本体的开发和建模到目前为止还没有统一的标准,基本是开发者直接用自身熟悉的方式和方法构建本体。
本体开发方法论的发展历史从时间上来看还是比较短的。
五种本体建模方法的比较目前比较典型的构造本体的方法有5种,分别是(1)针对企业建模过程的uschold和king方法;(2)基于面向Grunger和fox的业务流程和行为模型开发方法;(3)用于研究复杂系统中知识重用的可行性和ontology在其中的作用的berneras方法;(4)用于在知识层上构造ontology的methontology方法;(5)用于自然语言处理的sensus方法。

《信息检索与利用》检索报告一、要求1.检索报告需用A4纸打印出来,并在6月18日之前交到图书馆206室。
2.课题应与你的专业相关。
3.请按照考试模板中提供的格式答题。
二、检索报告评分办法(一)文献检索范围及检索策略(20%)含数据库及检索结果、检索词及检索式。
(二)检索结果(20%)列举8-10篇(含外文)与你课题密切相关的文献,根据相关性评分。
列举的文献要求包括篇名、作者、文献来源、文献摘要。
(三)综述(60%)1.文献内容简介部分,要求简明扼要地介绍每篇文献的主要内容。
理论性文献,要求列举其主要观点,简要介绍其产生的效果;技术或产品类文献,则要说明该技术或产品的特点、原理、效果及存在的问题。
2.综合列举文献,介绍该课题的意义、国内外研究现状和研究发展趋势。
(1)该课题研究的意义:要求简要说明研究工作的目的和重要性、所属学科范围、相关理论基础和分析、研究设想、研究方法和预期结果等。
(2)目前国内外研究现状:包括两部分内容,一部分是简明扼要地写出该课题的历史沿革,相关背景,曾经获得的重大成果,以及相关时间、人物等;另一部分是课题发展的当前水平,要求写出目前课题研究状况。
如果是理论性观点综述,则要列举、分析、各种理论观点,找出其共性与差异、探讨出中心一个论题。
如果是某种技术或产品,则要概括出同类技术或产品中有代表性的,说明它们的特点、原理及存在的问题。
注意要围绕论题,准确、鲜明、生动地展开叙述,突出重点,结构合理。
(3)课题研究发展趋势:对其可能产生的重大影响和可能出现的问题等趋势进行预测;也可在回顾和分析的基础上,提出新的研究方向和研究建议等。
三、期末考试评分办法满分100分,检索报告50%+(出勤+作业)50%四、考试模板。

本体构建Protege基础教程写在前面的话Ontology,即本体,来源于哲学领域,但自从被图书情报领域专家运用于图书情报领域,便在此领域得到大家的一致认可,各种基于本体的研究论文也层出不穷,但Protege4.0以上版本较之Protege3.X版本,界面功能发生了很大变化,以前其他学者出的学习教程已经并不适合初入本体领域的学者,而Protege官方说明又是全英文解释,给初学者更是带来了很大不便,由此,本人这篇本体构建Protege基础教程应运而生,衷心希望可以给其他学者学习本体构建工具以及以后进行基于本体构建领域的研究工作带来便利。
在此,特别感谢唐门的GGJJ在我学习运用Protege过程中给了我很多的理论支持,使我在这个学习过程中思维更加清晰。
——soonfy学习软件,首先还是看软件版本,本人演示的是Protege4.1版本,与Protege4.0版本以上的版本界面都较为相似,版本是4.0以上的学者,都可以借鉴。
另外,本文档主要是界面介绍及逻辑推理,至于本体构建中的个体关联、实体查询请关注下期文档。
一、界面介绍1、打开Protege软件。
如图1所示。
图1在图1中,方框1Create new OWL ontology:新建OWL本体;Open OWL ontology:打开一个OWl本体;Open OWL ontology from URI:通过通用资源标识符(URI)打开一个OWL本体;Open from the TONES repository:从TONES库打开OWL本体。
方框2Open recent:最近打开的OWL本体路径。
More actions:更多功能。
功能有“重新回到默认设置”、“检查更新”。
2、新建OWL本体文件介绍图2在图2中,方框1Ontology IRI:默认的IRI路径(不可随意更改,必须符合RDF文件规则)。
方框2Default base:默认URI路径信息。
图3图3为URI默认设置,方框1Default base URI:默认的URI路径。

基于本体的知识表示研究报告目录一知识 (3)1.1 知识的定义 (3)1.2知识的分类 (3)1.3知识表示 (3)1.3.1知识表示方法 (4)二本体 (5)2.1本体的定义 (5)2.2 本体的分类 (5)2.3 本体开发方法 (5)2.4 本体表示语言 (6)2.5构建本体的工具 (7)三国内外研究现状 (8)3.1 国外本体论的研究概况 (8)3.2国内本体论的研究概况 (8)四本体的案例 (10)参考文献 (12)一知识1.1 知识的定义知识是人们在改造客观世界的实践中积累起来的认识和经验。
其中认识包括:对事物现象、本质、属性、状态、关系、联系和运动等的认识;经验包括如步骤、操作、规则、过程、技巧等的解决问题的微观方法,和如战略、战术、计谋、策略等的宏观方法。
1.2知识的分类对知识从不同的角度进行划分,可得到不同的分类。
(1)按知识的作用域按知识的作用域不同,可分为共性知识和个性知识两大类,又称为常识性知识和领域性知识。
常识性知识:通用通识的知识,人们普遍知道的、适应所有领域的知识。
领域性知识:面向某个具体领域的知识,是专业性的知识,只有相应的专业人员才能掌握并且用来求解有关的问题。
例如:专家经验。
(2)按知识的表现形式按知识的表现形式不同,分为显性知识和隐性知识两大类。
显性知识又称为“记录的知识”,是可以用文字或符号表现出来的、可加以编辑集成的知识,并存储在诸如印本资料、视听资料等载体上。
显性知识可以明确归类,人们一般通过社会手段(如接受教育、阅读公开发行的图书资料等),就可掌握这类知识。
隐性知识即“意会的知识”,是指无法用社会逻辑工具语义明确表达、分类的知识,包括人们由经验产生的直觉、技能等。
这部分知识只存在于人的大脑中,不能直接储存与转换到物理媒介上,只能通过与隐性知识拥有者的直接接触和交流来实现知识的共享。
(3)按知识的确定性按知识的确定性不同,可分为确定性知识和不确定性知识两大类。
第32期2021年11月No.32November ,2021基于WoS 的图书情报领域知识管理相关研究综述周文奇(郑州大学,河南郑州450001)摘要:为探索近期图书情报领域知识管理研究热点与趋势,揭示国外现有研究现状,为国内开展相关课题提供参考。
文章将Web of Science 收录的以知识管理为主题的图情领域文献作为数据源,利用CiteSpace 对近期知识管理相关研究的关键被引文献、关键词共现、关键词突现等进行可视化分析,并在此基础上对近期知识管理关键性文献和研究热点做进一步阐述与分析。
关键词:知识管理;图书情报;综述文献;前沿热点中图分类号:G353.1文献标志码:A 江苏科技信息Jiangsu Science &Technology Information作者简介:周文奇(1996—),女,山东淄博人,硕士研究生;研究方向:信息服务与信息政策。
引言20世纪80年代,企业为了实现在竞争中赢得优势,得以生存,开始将信息与企业集体智慧知识以及人类的创新能力相结合,这一需求催生了知识管理。
普遍意义上的知识管理就是确保知识的积累、获取、导航、开发、创新和保存,实现显性知识和隐性知识的共享,促进知识创新并最大限度地激发智力资源的过程[1]。
本文针对图情领域相关研究内容进行详细探究。
目前,已有部分学者对此展开了综述性的定量分析和定性解读。
除了对知识管理本身的综述研究,近年来关于知识管理的活动过程要素概述较为频繁。
不难发现目前关于国外知识管理的近期现状研究较少,仅有的少部分聚焦于知识管理的要素研究。
本文从知识管理的整体出发,对近5年的国外相关研究进行可视化分析。
1数据来源与研究方法本文以Web of Science 核心合集数据库为数据来源。
将检索策略设定为:主题=“KM ”or “Konwledge Management ”,选择精炼类别为“INFORMATION SCIENCE LIBRARY SCIENCE ”,文献类型为“ARTICLE ”,时间跨度设置为2016—2020,检索日期是2020年12月1日,进行检索后得到956篇文献。
protege和swrl规则Protege是一款知识建模工具,可以帮助用户快速构建知识库并进行推理。
其建模能力可以应用于多个领域,包括医疗、金融等。
其中,在知识模型中可以设置规则,Protege支持两种规则,一种是基于事件的规则,另一种则是基于SWRL规则。
那么,什么是SWRL规则呢?SWRL规则是Protege中的一种推理规则,它基于判定式逻辑的扩展形式,可以用于描述知识模型中的逻辑约束和规则。
SWRL规则是一种语言,它结合了OWL和规则语言部分。
它采用了黄色多媒体网的构建原理,将知识表示为本体框架。
SWRL规则支持复杂的规则表达式,使得用户可以在不担心底层技术的情况下,管理复杂的知识图谱,并通过简单的规则进行推理。
使用SWRL规则,用户可以定义新的类和属性及关系。
这些新定义的结构可以成为本体的一部分,并影响到在系统中定义的本体和实例。
以下是一个SWRL规则的例子:Rule: 如果一个人喜欢一种水果,那么这个人需要健康的饮食。
p(?x,likes,?y),fruits(?y)-> p(?x,hasDietHealthy,Y).在上面的例子中,规则告诉我们,如果一个人喜欢水果,那么这个人需要健康的饮食。
p(?x,likes,?y)表示“某人喜欢某种水果”,而fruits(?y)表示“某种水果是水果类的实例”。
它们都是事实表达式。
p(?x,hasDietHealthy,Y)表示“一个人有健康的饮食”。
它是一个新事实表达式,SWRL规则使用它来推理,因为根据规则,如果一个人喜欢水果,那么这个人需要健康的饮食。
SWRL规则可以使用Protege进行编辑和查询,包括动态查询,这个功能可以快速的测试规则。
在Protege中,可以通过添加任意数量的SWRL规则来构建本体,然后可以执行规则以检查用户输入的约束是否正确。
此外,Protege还提供了一个可视化管理工具,帮助用户设计和组织知识模型,以及编辑SWRL规则。
Fault diagnosis of aircraft control surface based on
ontology
作者: 袁侃;胡寿松
作者机构: 南京航空航天大学自动化学院,南京210016
出版物刊名: 系统工程理论与实践
页码: 1826-1830页
年卷期: 2012年 第8期
主题词: 系统工程;飞机;故障诊断;本体;自修复
摘要:从系统工程的角度分析了飞机系统的复杂性,将飞机族的概念引入到飞机的本体建模中,并以舵面故障诊断过程为研究对象,首先用Protege建立了飞机本体的领域知识模型,然后将单故障和组合故障的诊断知识列为本体中的SWRL规则,最后利用JESS推理出新知识得出诊断结果,实现了用本体来选择修复方案的过程.该方法能够实现复杂系统的建模及故障诊断方案的准确选择.并可通过增加新的诊断知识来完善故障诊断知识库.。
基于本体的可视化股票信息系统的开题报告1. 项目背景随着互联网技术的发展,投资者在投资股票时更倾向于使用在线工具来帮助他们做出决策。
基于这个背景,我们设计了一个基于本体的可视化股票信息系统,旨在帮助投资者更轻松地获得股票市场的实时信息和数据。
本体(ontology)是一种用于表示知识和概念的方式,可以帮助我们更好地组织和理解信息。
在本项目中,我们将使用本体工具设计一个可以自动更新数据的股票本体,并使用可视化图表展示股票市场的实况和趋势。
2. 研究目标本项目的指导思想是让投资者更轻松地了解和分析股票市场的实况和趋势。
具体研究目标如下:- 设计可用于自动更新数据的股票本体- 开发基于本体的股票信息系统- 支持投资者查看实时股票数据和市场趋势- 提供股票市场的数据可视化分析工具3. 设计方法本项目主要包含三个部分:股票本体设计、股票信息系统开发、数据可视化分析工具首先,我们将使用本体工具(如Protege)设计一个股票本体,将股票市场的关键概念和属性进行建模。
然后,我们将使用Java和Web技术开发一个基于本体的股票信息系统,实现数据的获取,存储和可视化展示。
最后,我们将提供数据可视化分析工具,支持投资者更方便地了解股票市场的实况和趋势。
4. 系统功能本项目的股票信息系统将提供以下基本功能:- 实时股票数据查询- 股票市场趋势分析- 股票新闻和公告的监控- 股票收益分析和预测- 多维度数据分析和可视化展示投资者可以使用我们的系统来获取实时的股票数据,了解股票市场的趋势,分析个人股票收益和预测未来市场趋势,以及使用数据分析和可视化工具深入了解市场的各方面情况。
5. 项目意义本项目的实现将有助于投资者更好地了解和分析股票市场数据,帮助他们作出更明智的投资决策。
与传统股票信息检索工具相比,我们的系统不仅提供股票的实时数据,还有能够对数据进行多维度分析的工具,这能够帮助用户更全面地了解市场的趋势和变化,从而做出更及时、准确地决策。
语义网中OWL本体概述及其构建方法研究作者:林龙成来源:《电脑知识与技术》2020年第12期摘要:近年来,语义网(Semantic Web)以其良好的知识表达、交流、共享和推理能力,已被各个领域广泛接受,语义网是当前Web的延伸。
而本体是语义网的关键,利用本体语言对Web上已有的信息进行更为有意义的组织和编码,从而实现机器与人之间的有效通信。
本文对语义网和本体语言进行了分析,并在此基础上阐述了基于Protege的OWL本体构建技术。
关键词:语义网;本体;OWL;Protege中图分类号:TP393 文献标识码:A文章编号:1009-3044(2020)12-0203-02万维网是一个由数百万个文档组成的分布式存储库,覆盖了广泛的多学科信息,在这些文档中提取和检索特定的信息是一项烦琐的工作。
为了提高关联度,需要向语义Web(Web3.0)和本体论方向发展。
语义Web是当前Web的扩展,其中Web上已有的信息被有意义地编码并赋予一个明确定义的结构,从而使计算机和人类以高效的方式进行通信。
在语义网中,所有的信息都有明确的含义,使机器能够解释、处理、推理和派生新的知识,以支持实时应用中的特定任务。
随着语义网的迅速发展,支持本体功能的语言层出不穷。
Web本体语言(OWL)、资源描述框架(RDF)和资源描述框架模式(RDFS)是语义网的基本表示语言。
本体是语义网的关键,它将一个特定领域的相关概念编码成机器可读的格式,在这种格式中,机器可以处理和理解编码的知识,Web本体语言OWL是一种在Web上定义本体的语言,从类、属性和个体的角度描述一个域,并且可以包含对这些对象特性的丰富描述。
1语义网语义网的概念是由万维网的发明者Tim Berners Lee在1996年提出的,目标是将当前的信息转换成机器友好的语言,语义网并不是一个独立的网络,而是当前网络的扩展,它赋予信息明确的含义,使得信息共享和重用成为可能,计算机和人们能够更好地协同工作。