典型关联分析
- 格式:docx
- 大小:192.00 KB
- 文档页数:7

数据挖掘中的关联分析方法数据挖掘是一门利用统计学、机器学习和数据库技术来发现模式和趋势的学科。
在大数据时代,数据挖掘变得尤为重要,因为海量的数据蕴含着无限的商业价值和科学意义。
而关联分析方法作为数据挖掘的重要技术之一,在市场分析、商品推荐、医疗诊断等领域有着广泛的应用。
关联分析方法是指在大规模数据集中发现变量之间的关联关系,并且用这些关联关系构建模型,以便做出预测或者发现隐藏的信息。
其中,最为典型的例子就是购物篮分析。
通过分析顾客购物篮中的商品组合,商家可以发现哪些商品具有相关性,并且做出相应的销售策略。
首先,关联分析方法中最为经典的算法就是Apriori算法。
Apriori算法是一种用于发现频繁项集的算法,它的核心思想就是通过迭代的方法来挖掘频繁项集。
具体地说,算法首先扫描数据集,找出数据集中的频繁1项集;然后通过频繁1项集来生成候选2项集,并再次扫描数据集,找出频繁2项集;如此循环下去,直至无法生成更多的频繁项集为止。
而这些频繁项集就是具有关联关系的商品组合,商家可以根据这些关联关系来进行商品的搭配销售,以提高销售额。
其次,关联分析方法中还有一种常用的算法叫做FP-Growth算法。
FP-Growth算法是一种用于挖掘频繁项集的算法,与Apriori算法相比,FP-Growth算法在性能上有着更好的表现。
其核心思想是通过构建FP树(频繁模式树)来高效地发现频繁项集。
FP树是一种用来存储数据集中元素项的树形结构,通过构建FP树,我们可以高效地发现频繁项集。
因此,在实际应用中,FP-Growth算法常常被用来挖掘大规模数据集中的频繁项集。
除了这两种经典的算法之外,关联分析方法中还有很多其他的技术和方法。
例如基于模式增长的方法、基于随机抽样的方法、基于模糊关联规则的方法等等。
这些方法各有其特点,适用于不同的应用场景。
而在实际应用中,人们可以根据具体的数据集和问题,选择合适的关联分析方法来进行数据挖掘。


五年级下册语文基础专题讲解关联词语的分类及运用全国通用关联词语的分类及运用知识图谱-关联词语的分类及运用选择题填空题第14讲_关联词语的分类及运用错题回顾关联词语的分类及运用知识精讲一、要点梳理关联词是指在各级语言单位中起关联作用的词语,一般成对出现,如“因为……所以……”,“虽然……但是……”等。
同学们选填关联词语时一般可以从以下几个方面去考虑:1.分析关联词语的搭配是否合理;2.从分辨语句间的意义关系人手,分析句与句之间本身蕴含着什么样的关系,再确定表示这种关系的关联词语;3.从语感方面分析,看看所填的关联词语是否通顺合理,上下衔接。
(一)常见关联词语1.并列关系……又……又…………一面……一面……4.选择关系……不是……就是…………或是……或是…………宁可……也不…………还是……例1:日明喜爱球类运动,每天清早,他不是打球,就是踢球去了。
例2:我宁可给老师责罚,也不说谎,隐瞒真相。
5.转折关系尽管……可是……虽然……但是…………却…………然而……例1:尽管天气严寒,可是伯父仍到海滩游泳。
例2:妈妈爱静,爸爸却爱动,两人性格截然不同。
6.假设关系如果……就……假使……便……要是……那么……例1:如果明天下雨,旅行就要取消了。
例2:要是你不听爸爸的劝告,那么定会闯祸。
7.条件关系只要……就……只有……才……无论……都……不管……也……例1:只要多读多写,语文水平就可提高。
例2:不管多少险阻,我也无惧前进。
8.因果关系因为……所以……由于……因此……既然……那么……例1:由于弟弟粗心大意,因此做错了两道数学题。
例2:因为志文的腿摔坏了,所以需要用拐杖来走路。
二、方法点拨1.一般方法初读句子,弄清分句之间的关系。
选择关联词语,填入句子。
在读句子,检查句子是否通顺,句意是否正确。
2.两个注意点(1)搭配要得当使用一组关联词语是要前后呼应,要“成双配对”,不能交叉使用,这样才能是句意畅通、明确。
(2)运用要合理该用的时候用,不该用的时候就不用,不要生搬硬套。


典型关联分析(Canonical Correlation Analysis)[pdf版本]典型相关分析.pdf1. 问题在线性回归中,我们使用直线来拟合样本点,寻找n维特征向量X和输出结果(或者叫做label)Y之间的线性关系。
其中,。
然而当Y也是多维时,或者说Y也有多个特征时,我们希望分析出X和Y的关系。
当然我们仍然可以使用回归的方法来分析,做法如下:假设,,那么可以建立等式Y=AX如下其中,形式和线性回归一样,需要训练m次得到m个。
这样做的一个缺点是,Y中的每个特征都与X的所有特征关联,Y中的特征之间没有什么联系。
我们想换一种思路来看这个问题,如果将X和Y都看成整体,考察这两个整体之间的关系。
我们将整体表示成X和Y各自特征间的线性组合,也就是考察和之间的关系。
这样的应用其实很多,举个简单的例子。
我们想考察一个人解题能力X(解题速度,解题正确率)与他/她的阅读能力Y(阅读速度,理解程度)之间的关系,那么形式化为:和然后使用Pearson相关系数来度量u和v的关系,我们期望寻求一组最优的解a和b,使得Corr(u, v)最大,这样得到的a和b就是使得u和v就有最大关联的权重。
到这里,基本上介绍了典型相关分析的目的。
2. CCA表示与求解给定两组向量和(替换之前的x为,y为),维度为,维度为,默认。
形式化表示如下:是x的协方差矩阵;左上角是自己的协方差矩阵;右上角是;左下角是,也是的转置;右下角是的协方差矩阵。
与之前一样,我们从和的整体入手,定义我们可以算出u和v的方差和协方差:上面的结果其实很好算,推导一下第一个吧:最后,我们需要算Corr(u,v)了我们期望Corr(u,v)越大越好,关于Pearson相关系数,《数据挖掘导论》给出了一个很好的图来说明:MaximizeSubject to:求解方法是构造Lagrangian等式,这里我简单推导如下:求导,得令导数为0后,得到方程组:第一个等式左乘,第二个左乘,再根据,得到也就是说求出的即是Corr(u,v),只需找最大即可。

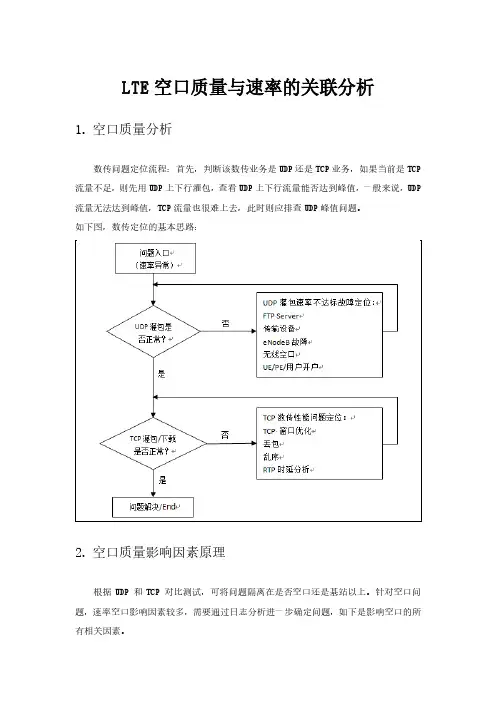
LTE空口质量与速率的关联分析1.空口质量分析数传问题定位流程:首先,判断该数传业务是UDP还是TCP业务,如果当前是TCP 流量不足,则先用UDP上下行灌包,查看UDP上下行流量能否达到峰值,一般来说,UDP 流量无法达到峰值,TCP流量也很难上去,此时则应排查UDP峰值问题。
如下图,数传定位的基本思路:2.空口质量影响因素原理根据UDP 和TCP 对比测试,可将问题隔离在是否空口还是基站以上。
针对空口问题,速率空口影响因素较多,需要通过日志分析进一步确定问题,如下是影响空口的所有相关因素。
如上图所示,影响空口速率的要素主要包括:空口资源、空口编码与覆盖、MIMO。
●空口资源表现为调度次数和RB数是否充足,需重点排查基站上游来水量及异频测量GAP等。
●空口覆盖与编码1)检查MCS选阶MCS选阶体现空口编码调制效率,直接影响到每TTI调度的TBS选择。
检查MCS是否符合要求速率。
2)检查无线信号(RSRP/SINR)根据测试终端配套软件上检查RSRP、SINR信号质量参数。
要保证测试用户获得要求速率,RSRP、SINR要满足不同的条件,比如要测理论峰值,要保证小区RSRP在-80dBm以上,SINR在25dB以上。
3)检查空口误码率(BLER)MCS选阶是根据IBLER 10%收敛进行调整的,如果空口误码率大于10%,则信号环境较差,需改善无线环境,提高下行信号质量。
若要求测试理论峰值,则误码率保证为0。
4)检查是否存在干扰当SINR较好,但MCS选阶低,需排查是否存在干扰导致。
下行,需排查邻区干扰及系统外干扰。
邻区信号强度与服务小区信号相差10dB以内,对服务小区解调有明显影响;上行,需重点排查上行干扰;上行空载时(UE关机,小区里没有业务),可以检测上行全带宽上的接收功率RSSI。
正常情况下,空载时每个RB上的RSSI应该是-120dBm左右,如果有突然升高3~5dBm 以上情况,说明上行有干扰,需要排查干扰源。

数据分析中的关联分析方法在当今信息爆炸的时代,海量的数据被不断产生和积累。
如何从这些数据中提取有用的信息,成为了数据分析的重要课题之一。
关联分析作为数据挖掘的一种方法,通过发现数据集中的关联规则,帮助我们揭示数据背后的隐藏规律和关系。
本文将介绍关联分析的基本概念、方法和应用。
一、关联分析的基本概念关联分析是一种基于频繁项集的数据挖掘方法,其核心思想是通过寻找频繁出现的项集之间的关联规则,来发现数据中的关联关系。
在关联分析中,项集是指数据集中的一组项目的集合,而关联规则是指形如“A→B”的条件语句,表示当某一项集A出现时,另一项集B也很可能出现。
二、关联分析的方法1. Apriori算法Apriori算法是关联分析中最经典的算法之一,它通过迭代的方式来发现频繁项集。
该算法的基本思想是利用Apriori原理,即如果一个项集是频繁的,那么它的所有子集也一定是频繁的。
Apriori算法的步骤包括:扫描数据集,生成候选项集,计算候选项集的支持度,根据最小支持度筛选频繁项集,并通过组合生成新的候选项集,不断迭代直到无法生成新的候选项集为止。
2. FP-Growth算法FP-Growth算法是一种基于前缀树的关联分析算法,相较于Apriori算法,它能够更高效地发现频繁项集。
该算法的核心是构建FP树(频繁模式树),通过压缩数据集来减少计算量。
FP-Growth算法的步骤包括:构建FP树,通过FP树挖掘频繁项集,生成条件FP树,递归挖掘频繁项集。
三、关联分析的应用关联分析在实际应用中具有广泛的应用价值,以下是几个常见的应用场景:1. 超市购物篮分析超市购物篮分析是关联分析的典型应用之一。
通过分析顾客购买商品的组合,超市可以了解到哪些商品之间存在关联关系,进而制定促销策略,提高销售额。
例如,当顾客购买了牛奶和面包时,很可能还会购买黄油,超市可以将这三种商品放在一起展示,以增加销售。
2. 网络推荐系统关联分析在网络推荐系统中也有着重要的应用。


典型相关分析(CCA)简介一、引言在多变量统计分析中,典型相关分析(Canonical Correlation Analysis,简称CCA)是一种用于研究两个多变量之间关系的有效方法。
这种方法最早由哈罗德·霍特林(Harold Hotelling)于1936年提出。
随着数据科学和统计学的发展,CCA逐渐成为多个领域分析数据的重要工具。
本文将对典型相关分析的基本原理、应用场景以及与其他相关方法的比较进行详细阐述。
二、典型相关分析的基本概念1. 什么是典型相关分析典型相关分析是一种分析两个多变量集合之间关系的方法。
设有两个随机向量 (X) 和 (Y),它们分别包含 (p) 和 (q) 个变量。
CCA旨在寻找一种线性组合,使得这两个集合在新的空间中具有最大的相关性。
换句话说,它通过最优化两个集合的线性组合,来揭示它们之间的关系。
2. 数学模型假设我们有两个数据集:(X = [X_1, X_2, …, X_p])(Y = [Y_1, Y_2, …, Y_q])我们可以表示为:(U = a^T X)(V = b^T Y)其中 (a) 和 (b) 是待求解的权重向量。
通过最大化协方差 ((U, V)),我们得到最大典型相关系数 (),公式如下:[ ^2 = ]通过求解多组 (a) 和 (b),我们可以获得多个典型变量,从而得到不同维度的相关信息。
三、典型相关分析的步骤1. 数据准备在进行CCA之前,需要确保数据集满足一定条件。
一般来说,应对数据进行标准化处理,以消除可能存在的量纲差异。
可以使用z-score标准化的方法来处理数据。
2. 求解协方差矩阵需要计算两个集合的协方差矩阵,并进一步求出其逆矩阵。
给定随机向量 (X) 和 (Y),我们需要计算如下协方差矩阵:[ S_{xx} = (X, X) ] [ S_{yy} = (Y, Y) ] [ S_{xy} = (X, Y) ]同时,求出逆矩阵 (S_{xx}^{-1}) 和 (S_{yy}^{-1})。

房贷利率与通货膨胀的关联性分析房贷利率和通货膨胀是经济领域中两个重要的概念,它们对于个人和整个社会都具有重大影响。
本文将对房贷利率与通货膨胀之间的关联性进行深入分析。
一、引言房贷利率是指购买房产时需要支付的利息,通货膨胀则是衡量物价总水平上升的指标。
理论上,房贷利率和通货膨胀之间应该存在一定的关联性,因为通货膨胀影响着整个经济环境,从而对房贷利率产生影响。
二、房贷利率与通货膨胀的影响因素1. 货币政策货币政策是通过调整利率来影响货币供应量和流动性的政策工具。
当通货膨胀上升时,央行可能会加息以抑制通胀压力,进而提高房贷利率。
反之,当通货膨胀下降时,央行可能会降息以刺激经济增长,从而降低房贷利率。
2. 需求和供应关系房地产市场的需求和供应也会对房贷利率和通货膨胀产生影响。
当需求增加时,房地产市场火爆,房贷需求增加,相应的银行可能会提高房贷利率。
而通货膨胀会导致房地产市场价格上涨,增加了购房成本,从而进一步影响房贷利率。
三、房贷利率与通货膨胀的关联性1. 正相关性一般情况下,房贷利率和通货膨胀呈正相关关系。
当通货膨胀上升时,央行为控制通胀可能会提高利率,进而导致房贷利率上升。
这是因为通货膨胀会降低货币的购买力,导致借款风险增加,银行为了保证自身利润和风险控制,会采用提高房贷利率的方式。
2. 逆向相关性但在某些特殊情况下,房贷利率和通货膨胀可能出现逆向相关关系。
当通货膨胀上升较快时,央行可能会采取紧缩货币政策,提高利率以抑制通胀。
然而,此时高利率可能会影响房地产市场需求,从而导致房价下降,进而影响房贷利率。
四、影响因素举例分析以中国为例,近年来的房地产市场是房贷利率与通货膨胀关联性研究的典型案例。
中国央行通过调整利率和货币政策来影响通货膨胀和房贷利率。
随着中国经济的快速发展,通货膨胀压力增大,央行采取一系列措施加息以抑制通胀。
这也导致了一段时间内房贷利率的上升。
然而,中国房地产市场需求旺盛,房价也一度上涨迅猛。
JerryLead典型关联分析(Canonical Correlation Analysis )[pdf 版本] 典型相关分析.pdf1. 问题在线性回归中,我们使用直线来拟合样本点,寻找n维特征向量X 和输出结果(或者叫做label)Y 之间的线性关系。
其中,。
然而当Y 也是多维时,或者说Y 也有多个特征时,我们希望分析出X 和Y 的关系。
当然我们仍然可以使用回归的方法来分析,做法如下:假设,,那么可以建立等式Y=AX 如下其中,形式和线性回归一样,需要训练m 次得到m 个。
这样做的一个缺点是,Y 中的每个特征都与X 的所有特征关联,Y 中的特征之间没有什么联系。
我们想换一种思路来看这个问题,如果将X 和Y 都看成整体,考察这两个整体之间的关系。
我们将整体表示成X 和Y 各自特征间的线性组合,也就是考察和之间的关系。
这样的应用其实很多,举个简单的例子。
我们想考察一个人解题能力X (解题速度,解题正确率)与他/她的阅读能力Y (阅读速度,理解程度)之间的关系,那么形式化为:和 然后使用Pearson 相关系数来度量u 和v 的关系,我们期望寻求一组最优的解a 和b ,使得Corr(u, v)最大,这样得到的a 和b 就是使得u 不想飞翔,不是因为没有翅膀,而是失去了梦想和v就有最大关联的权重。
到这里,基本上介绍了典型相关分析的目的。
2. CCA表示与求解给定两组向量和(替换之前的x为,y为),维度为,维度为,默认。
形式化表示如下:是x的协方差矩阵;左上角是自己的协方差矩阵;右上角是;左下角是,也是的转置;右下角是的协方差矩阵。
与之前一样,我们从和的整体入手,定义我们可以算出u和v的方差和协方差:上面的结果其实很好算,推导一下第一个吧:最后,我们需要算Corr(u,v)了我们期望Corr(u,v)越大越好,关于Pearson相关系数,《数据挖掘导论》给出了一个很好的图来说明:横轴是u ,纵轴是v ,这里我们期望通过调整a和b 使得u 和v 的关系越像最后一个图越好。
典型相关分析法范文典型相关分析(Canonical Correlation Analysis,CCA)是一种统计方法,用于研究两组变量之间的相关性和关联性。
它可以描述两组变量之间的线性关系,并找到它们之间的典型关联的模式。
本文将介绍典型相关分析的基本原理、应用领域、实施步骤和解释结果的方法。
典型相关分析广泛用于社会科学、心理学、医学、生物学等领域。
例如,在心理学研究中,研究人员可能对个体的性格特征和行为特征进行测量,然后希望找到它们之间的关联模式。
在医学研究中,研究人员可能对患者的基因表达数据和临床特征进行测量,然后希望了解它们之间的关联性。
实施典型相关分析的步骤如下:1.数据收集:收集两组变量的观测数据。
每组变量可以包含任意数量和类型的变量。
2.数据预处理:对数据进行预处理,以便满足典型相关分析的假设。
常见的预处理步骤包括缺失值处理、标准化和处理异常值。
3.计算相关系数:通过计算两组变量之间的相关系数矩阵来确定它们的关联程度。
对于大样本量情况下的相关系数,通常使用皮尔逊相关系数;对于小样本量情况下或非正态分布的变量,可以使用斯皮尔曼相关系数。
4.运行典型相关分析模型:将两组变量作为输入,运行典型相关分析模型。
典型相关分析的目标是找到两组变量之间的最大相关系数。
可以根据需求自定义典型相关变量的数量。
5.解释结果:解释得到的结果,以了解两组变量之间的关联模式。
可以根据典型相关系数的大小和相关变量的权重来解释模型的结果。
相关系数越大,表示两组变量之间的关系越强;相关变量的权重表示它们在模型中的重要性。
1.可视化:通过绘制典型变量的变化曲线、散点图或热力图,来展示两个变量之间的相关关系。
2.解释权重:通过解释典型相关变量的权重,来了解不同变量对典型相关分析模型的贡献。
具有较大权重的变量被认为在模型中起到了更重要的作用。
3.解释解释变量:对于解释变量较少的情况,可以分析典型变量和原始变量之间的关系,以获得更深入的认识。
1.预备知识1.1.数理统计相关概念12{,,...,}n X x x x =12{,,...,}n Y y y y =11()nk k E X x n ==∑211()(())nk k D X x E X n ==-∑11(,){[(X)][()]}[()][()]nk k k Cov X Y E X E Y E Y x E X y E Y n ==--=-⨯-∑()(,)D X Cov X X =(协方差解释:如果有X ,Y 两个变量,每个时刻的“X 值与其均值之差”乘以“Y 值与其均值之差”得到一个乘积,再对这每时刻的乘积求和并求出均值) (可能成立的:如果一个矩阵的期望是0,则另一矩阵与该矩阵相乘得到的矩阵期望也为0)1.2.数据标准化(z-score 标准化)最常见的标准化方法就是Z 标准化,也叫标准差标准化,这种方法给予原始数据的均值(mean )和标准差(standard deviation )进行数据的标准化。
经过处理的数据符合标准正态分布,即均值为0,标准差为1,注意,一般来说z-score 不是归一化,而是标准化,归一化只是标准化的一种。
其转化函数为:*()/X X μσ=-其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
z-score 标准化方法适用于属性A 的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
该种标准化方式要求原始数据的分布可以近似为高斯分布,否则效果会变得很糟糕。
标准化的公式很简单,步骤如下:求出各变量(指标)的算术平均值(数学期望)x i 和标准差s i ;进行标准化处理:z ij =(x ij -x i )/s i ,其中:z ij 为标准化后的变量值;x ij 为实际变量值;将逆指标前的正负号对调。
标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
1.3.拉格朗日乘数法求条件极值作为一种优化算法,拉格朗日乘子法主要用于解决约束优化问题,它的基本思想就是通过引入拉格朗日乘子来将含有n 个变量和k 个约束条件的约束优化问题转化为含有(n+k )个变量的无约束优化问题。
拉格朗日乘子背后的数学意义是其为约束方程梯度线性组合中每个向量的系数。
如何将一个含有n 个变量和k 个约束条件的约束优化问题转化为含有(n+k )个变量的无约束优化问题?拉格朗日乘数法从数学意义入手,通过引入拉格朗日乘子建立极值条件,对n 个变量分别求偏导对应了n 个方程,然后加上k 个约束条件(对应k 个拉格朗日乘子)一起构成包含了(n+k )变量的(n+k )个方程的方程组问题,这样就能根据求方程组的方法对其进行求解。
解决的问题模型为约束优化问题:min/max a function f(x,y,z), where x,y,z are not independent and g(x,y,z)=0.即:min/max f(x,y,z) s.t. g(x,y,z)=0给定椭球求这个椭球的内接长方体的最大体积。
这个问题实际上就是条件极值问题,即在条件下,求的最大值。
当然这个问题实际可以先根据条件消去,然后带入转化为无条件极值问题来处理。
但是有时候这样做很困难,甚至是做不到的,这时候就需要用拉格朗日乘数法了。
通过拉格朗日乘数法将问题转化为:对求偏导得到:联立前面三个方程得到和,带入第四个方程解之带入解得最大体积为:拉格朗日乘数法对一般多元函数在多个附加条件下的条件极值问题也适用。
1.4.奇异值分解奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。
就像是描述一个人一样,给别人描述说这个人长得浓眉大眼,方脸,络腮胡,而且带个黑框的眼镜,这样寥寥的几个特征,就让别人脑海里面就有一个较为清楚的认识,实际上,人脸上的特征是有着无数种的,之所以能这么描述,是因为人天生就有着非常好的抽取重要特征的能力,让机器学会抽取重要的特征,SVD 是也一个重要的方法。
在机器学习领域,有相当多的应用与奇异值都可以扯上关系,比如做feature reduction 的PCA ,做数据压缩(以图像压缩为代表)的算法,还有做搜索引擎语义层次检索的LSI (Latent Semantic Indexing )。
1.4.1.奇异值详解特征值分解和奇异值分解两者有着很紧密的关系,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。
先谈谈特征值分解吧:1.4.1.1.特征值如果说一个向量v 是方阵A 的特征向量,将一定可以表示成下面的形式:Av v λ=这时候λ就被称为特征向量v 对应的特征值,一个矩阵的一组特征向量是一组正交向量。
特征值分解是将一个矩阵分解成下面的形式: 1A Q Q -=∑其中Q 是这个矩阵A 的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。
首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。
比如说下面的一个矩阵:3001M ⎡⎤=⎢⎥⎣⎦它其实对应的线性变换是下面的形式:因为这个矩阵M 乘以一个向量(x,y)的结果是:30301x x y y ⎡⎤⎡⎤⎡⎤=⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦⎣⎦上面的矩阵是对称的,所以这个变换是一个对x ,y 轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时拉长,当值<1时缩短),当矩阵不是对称的时候,假如说矩阵是下面的样子:1101M ⎡⎤=⎢⎥⎣⎦它所描述的变换是下面的样子:这其实是在平面上对一个轴进行的拉伸变换(如蓝色的箭头所示),在图中,蓝色的箭头是一个最主要的变化方向(变化方向可能有不止一个),如果我们想要描述好一个变换,那我们就描述好这个变换主要的变化方向就好了。
反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)当矩阵是高维的情况下,那么这个矩阵就是高维空间下的一个线性变换,这个线性变化可能没法通过图片来表示,但是可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N 个特征向量,那么就对应了这个矩阵最主要的N 个变化方向。
我们利用这前N 个变化方向,就可以近似这个矩阵(变换)。
也就是之前说的:提取这个矩阵最重要的特征。
总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。
不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
A 算法A 原理典型关联分析(Canonical Correlation Analysis ,简称CCA)是最常用的挖掘数据关联关系的算法之一。
比如我们拿到两组数据,第一组是人身高和体重的数据,第二组是对应的跑步能力和跳远能力的数据。
那么我们能不能说这两组数据是相关的呢?CCA 可以帮助我们分析这个问题。
在数理统计里面,都知道相关系数这个概念。
假设有两组一维的数据集X 和Y ,则相关系数ρ的定义为:(,)X Y ρ=其中cov(X,Y)是X 和Y 的协方差,而D(X),D(Y)分别是X 和Y 的方差。
相关系数ρ的取值为[-1,1],ρ的绝对值越接近于1,则X 和Y 的线性相关性越高。
越接近于0,则X 和Y 的线性相关性越低。
虽然相关系数可以很好的帮我们分析一维数据的相关性,但是对于高维数据就不能直接使用了。
如上所述,如果X 是包括人身高和体重两个维度的数据,而Y 是包括跑步能力和跳远能力两个维度的数据,就不能直接使用相关系数的方法。
那我们能不能变通一下呢?CCA 给了我们变通的方法。
CCA 使用的方法是将多维的X 和Y 都用线性变换为1维的X'和Y',然后再使用相关系数来看X'和Y'的相关性。
将数据从多维变到1位,也可以理解为CCA 是在进行降维,将高维数据降到1维,然后再用相关系数进行相关性的分析。
CCA 是将高维的两组数据分别降维到1维,然后用相关系数分析相关性。
但是有一个问题是,降维的标准是如何选择的呢?回想下主成分分析PCA ,降维的原则是投影方差最大;再回想下线性判别分析LDA ,降维的原则是同类的投影方差小,异类间的投影方差大。
对于我们的CCA ,它选择的投影标准是降维到1维后,两组数据的相关系数最大。
(思考一下,两个模态样本描述的事物是相似的,训练的时候是让样本特征的相关系数最大)假设数据集是X 和Y ,X 为n 1×m 的样本矩阵,Y 为n 2×m 的样本矩阵.其中m 为样本个数,而n 1,n 2分别为X 和Y 的特征维度。
对于X 矩阵,将其投影到1维,对应的投影向量为a, 对于Y 矩阵,将其投影到1维,对应的投影向量为b, 这样X ,Y 投影后得到的一维向量分别为X',Y',则:','T T X a X Y b Y ==CCA 的优化目标是最大化ρ(X ′,Y ′),得到对应的投影向量a,b ,即,arg a b在投影前,一般会把原始数据进行标准化,得到均值为0而方差为1的数据X 和Y 。
这样我们有:cov(',')cov(,){[()][()]}(()())()T T T T T T T T T T T X Y a X b Y E a X E a X b Y E b Y E a X b Y a E XY b==--==(之所以第三个等号成立,均值为0)(')()(,){[()][()]}()()T T T T T T T T T T T D X D a X Cov a X a X E a X E a X a X E a X E a XX a a E XX a===--==(')()T T D Y b E YY b =由于X ,Y 的均值均为0,则:()cov(,)(),()cov(,)()T T D X X X E XX D Y Y Y E YY ====cov(,)(),cov(,)()T T X Y E XY Y X E YX ==所以有:,,,arg arg arg T T T a b a b a b ==令S XY =cov(X,Y),则有:,arg maxT a b 由于分子分母增大相同的倍数,优化目标结果不变,我们可以采用和SVM 类似的优化方法,固定分母,优化分子,具体转化为:,arg max (..1,1)T T T XY XX YY a b a S b s t a S a b S b ==进而CCA 算法的目标最终转化为一个凸优化过程,只要求出了这个优化目标的最大值,就是前面提到的多维X 和Y 的相关性度量,而对应的a,b 则为降维时的投影向量。