关联分析 spss
- 格式:ppt
- 大小:1.89 MB
- 文档页数:93

SPSS结合分析
SPSS是一种统计分析软件,可以帮助研究者对数据进行管理、统计分析和数据展示。
结合分析是指将两个或多个变量进行结合,并探索它们之间的关系。
本文将介绍如何在SPSS中进行结合分析,并以一个实际案例进行说明。
除了相关性分析,SPSS还提供了其他的结合分析方法,如多元回归分析、因子分析、聚类分析等。
这些方法可以帮助我们更深入地了解变量之间的关系,并进行预测和分类。
总之,SPSS是一种功能强大的统计分析软件,可以帮助研究者进行结合分析。
通过SPSS,我们可以计算相关系数、进行多元回归分析等,并通过图表展示分析结果。
这些功能可以帮助研究者更好地理解和解释变量之间的关系,并做出合理的决策。

SPSS典型相关分析案例典型相关分析(Canonical Correlation Analysis,CCA)是一种统计方法,用于研究两组变量之间的相关性。
它可以帮助研究人员了解两组变量之间的关系,并提供有关这些关系的详细信息。
在SPSS中,可以使用典型相关分析来探索两个或多个变量之间的关系,并进一步理解这些变量如何相互影响。
下面我们将介绍一个典型相关分析的案例,以展示如何在SPSS中执行该分析。
案例背景:假设我们有一个医学研究数据集,包含30名患者的多个生物标记物和他们的疾病严重程度评分。
我们希望了解这些生物标记物与疾病严重程度之间的关系,并查看是否可以建立一个线性模型来预测疾病严重程度。
以下是执行这个案例的步骤:第1步:准备数据首先,我们需要准备数据,确保所有变量都是数值型。
在SPSS中,我们可以通过检查数据集的描述性统计信息或查看变量视图来做到这一点。
第2步:导入数据在SPSS中,我们可以通过选择菜单中的"File"选项,然后选择"Open"来导入数据集。
我们应该选择包含待分析数据的文件,并确保正确指定变量的类型。
第3步:执行典型相关分析要执行典型相关分析,我们可以选择菜单中的"Analyze"选项,然后选择"Canonical Correlation"。
在弹出的对话框中,我们应该选择我们希望研究的生物标记物变量和疾病严重程度评分变量。
然后,我们可以选择一些选项,如方差-协方差矩阵、相关矩阵和判别系数,并点击"OK"执行分析。
第4步:解释结果完成分析后,SPSS将提供几个输出表。
我们应该关注典型相关系数和标准化典型系数,以了解两组变量之间的关系。
我们可以使用这些系数来解释生物标记物如何与疾病严重程度相关联,并找到最重要的变量。
此外,我们还可以使用SPSS提供的其他统计结果来进一步解释模型的效果和预测能力。




S P S S关联模型步骤精选文档TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-SPSS Clementines 预测分析模型----啤酒+尿片故事的实现机理(使用11版本实现)SPSS Clenmentines提供众多的预测模型,这使得它们可以应用在多种商业领域中:如超市商品如何摆放可以提高销量;分析商场营销的打折方案,以制定新的更为有效的方案;保险公司分析以往的理赔案例,以推出新的保险品种等等,具有很强的商业价值。
超市典型案例如何摆放超市的商品引导消费者购物从而提高销量,这对大型连锁超市来说是一个现实的营销问题。
关联规则模型自它诞生之时为此类问题提供了一种科学的解决方法。
该模型利用数据挖掘的技术,在海量数据中依据该模型的独特算法发现数据内在的规律性联系,进而提供具有洞察力的分析解决方案。
通过一则超市销售商品的案例,利用“关联规则模型”,来分析商品交易流水数据,以其发现合理的商品摆放规则,来帮助提高销量。
关联规则简介关联规则的定义关联规则表示不同数据项目在同一事件中出现的相关性,就是从大量数据中挖掘出关联规则。
有关数据挖掘关联规则的具体理论依据这里不做详细讲解,大家可以参看韩家炜的数据挖掘概论。
为了更直观的理解关联规则,我们首先来看下面的场景。
一个市场分析人员经常要考虑这样一个问题:哪些商品是频繁被顾客同时购买的?顾客1:牛奶+面包+谷类顾客2:牛奶+面包+糖+鸡蛋顾客3:牛奶+面包+黄油顾客4:糖+鸡蛋以上的情景类似于当年沃尔玛做的市场调查:啤酒+尿片摆放在同一个货架上,销售业绩激增的着名关联规则应用。
市场分析员分析顾客购买商品的场景,顾客购买面包同时也会购买牛奶的购物模式就可用以下的关联规则来描述:面包 => 牛奶 [ 支持度 =2%, 置信度 =60%] (式 1)式 1中面包是规则前项(Antecedent),牛奶是规则后项 (Consequent)。


SPSS 关联研究的Crosstabs过程(2009-04-14 09:31:44)标签:spps卡方关联研究杂谈分类:SPSS学习Crosstabs过程用于对计数资料和有序分类资料进行统计描述和简单的统计推断。
在分析时可以产生二维至n维列联表,并计算相应的百分数指标。
统计推断则包括了我们常用的X2检验、Kappa值,分层X2(X2M-H)。
如果安装了相应模块,还可计算n维列联表的确切概率(Fisher's Exact Test)值。
Crosstabs过程不能产生一维频数表(单变量频数表),该功能由Frequencies过程实现。
6.4.1 界面说明【Rows框】用于选择行*列表中的行变量。
【Columns框】用于选择行*列表中的列变量。
【Layer框】Layer指的是层,对话框中的许多设置都可以分层设定,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。
如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next钮设为不同层。
Layer 在这里用的比较少,在多元回归中我们将进行详细的解释。
【Display clustered bar charts复选框】显示重叠条图。
【Suppress table复选框】禁止在结果中输出行*列表。
【Exact钮】针对2*2以上的行*列表设定计算确切概率的方法,可以是不计算(Asymptotic only)、蒙特卡罗模拟(Monte Carlo)或确切计算(Exact)。
蒙特卡罗模拟默认进行10000次模拟,给出99%可信区间;确切计算默认计算时间限制在5分钟内。
这些默认值均可更改。
如果你在安装SPSS时没有安装EXACT模块,则此处对话框中不会出现Exact 钮。
在3*3及以上的行*列表中,确切概率的精确计算是极为漫长的过程。
我曾经用SAS 6.12在P133机上计算过一个12格表的确切概率,整整跑了两个小时后,SAS告诉我说机器内存不足:(。
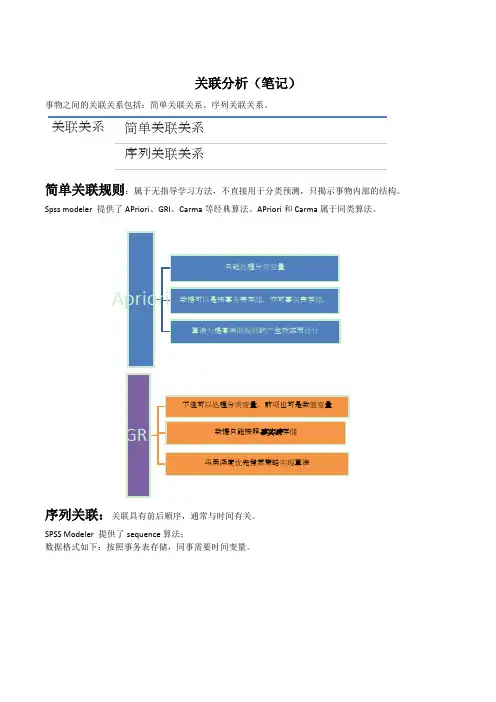
关联分析(笔记)事物之间的关联关系包括:简单关联关系、序列关联关系。
关联关系简单关联关系序列关联关系简单关联规则:属于无指导学习方法,不直接用于分类预测,只揭示事物内部的结构。
Spss modeler 提供了APriori、GRI、Carma等经典算法。
APriori和Carma属于同类算法。
序列关联:关联具有前后顺序,通常与时间有关。
SPSS Modeler 提供了sequence算法;数据格式如下:按照事务表存储,同事需要时间变量。
简单关联规则要分析的对象是事务事务的储存方式有事务表和事实表两种方式。
事务表顾客ID项集1A1D2B2D3A3C事实表顾客ID项目A项目B项目C项目D110012010131010两种表均表明,顾客1购买了AD两种物品,顾客2购买了BD两种物品,顾客三购买了AC两种物品。
关联规则有效性的测度指标1、支持度support:所有购买记录中,A、B同时被购买的比例。
2、置信度confidence:在购买A的事务中,购买B的比例。
关联规则实用性的测度指标1、提升度lift:(在购买A的事务中,购买B的比例)/(所有事务中,购买B的比例)2、置信差3、置信率、正态卡方、信息差等等简单关联关系实例例1数据格式:事实表算法:Apriori所有购买项目均选入前项antecedent和后项consequent。
输出结果的最低支持度是10%;本例设定的划分频繁项集的标准大于最小支持度10%。
最小置信度是80%;前项最多项目数:5本例中,三项以上没有超过10%的支持度,所以不能形成三项以上的频繁项集,最大的频繁项集大小是2。
结论解释:实例:包含前项beer、cannedveg的样本有167个,在1000个样本中前项支持度为16.7%。
规则支持度:同时购买beer、cannedveg、frozenmeal三项的支持度为14.6%。
规则置信度:购买beer、cannedveg的客户中,87.425%的人有购买frozenmeal。

spss相关性分析2篇SPSS相关性分析SPSS (Statistical Package for the Social Sciences)是一款专门用于统计分析的软件。
在研究中,经常需要探究两个或多个变量之间的关系。
通过SPSS相关性分析,可以帮助研究者了解变量之间的相关程度,有助于发现变量之间的作用和关系。
相关性分析是一种统计方法,用于研究两个或多个变量之间是否存在关系以及这种关系有多强。
通常分为两大类:相关系数和回归分析。
相关系数分析是通过计算相关系数来度量变量之间线性关系的强弱;而回归分析则在相关系数的基础上进一步分析自变量和因变量之间的函数关系,以确定自变量对因变量的影响程度。
SPSS相关系数分析在SPSS中,相关系数分析用于评估两个变量之间的线性关系强度。
常见的相关系数有皮尔逊相关系数、斯皮尔曼相关系数和切比雪夫相关系数。
皮尔逊相关系数用于评估两个连续变量之间的线性关系。
取值范围在-1到1之间。
当两个变量正相关时,相关系数接近于1;当两个变量负相关时,相关系数接近于-1;当两个变量没有线性关系时,相关系数接近于0。
斯皮尔曼相关系数也用于评估两个变量之间的相关程度,但是它可以应用于有序等级变量或者连续变量,无需考虑变量是否呈正态分布。
切比雪夫相关系数是一种非参数的相关系数,适用于评估两个变量之间的任何类型的关系。
它通常用于评估非正态分布变量之间的相关性。
SPSS回归分析回归分析用于评估自变量对因变量的影响程度。
在SPSS 中,回归分析可分为线性回归和多元回归。
线性回归是一种用于解释一个连续因变量与一个或多个连续自变量之间线性关系的回归分析。
它旨在拟合一个直线来预测因变量的值,这个直线被称为最小二乘线。
线性回归的输出结果包括R方值、标准误差和假设检验。
多元回归是一种用于解释一个连续因变量与多个自变量之间线性关系的回归分析。
相比于线性回归,它可以控制多个自变量对因变量的影响。
多元回归的输出结果包括多元R方值、标准误差和假设检验。

数学建模SPSS双变量相关性分析
关键词:数学建模相关性分析SPSS
摘要:在数学建模中,相关性分析是很重要的一部分,尤其是在双变量分析时,要根据变量之间的联系建立评价指标,并且通过这些指标来进行比对赋值而做出评价结果。
本文由数学建模中的双变量分析出发,首先阐述最主要的三种数据分析:Pearson系数,Spearman系数和Kendall系数的原理与应用,再由实际建模问题出发,阐述整个建模过程和结果。
r s=
∑(P i−P ave)(Q i−Q ave)√∑(P i−P ave)2(Q i−Q ave)2
在SPSS中打开数据,点击:分析—>相关—>双变量,打开对话窗口,选择需要分析的两个变量、Spearman秩相关系数分析以及双侧检验。
需要说明两点:
(1)因各体重与各体质数据之间的相关性正负未知,需选用双侧检验;
(2)除了数据满足非正态分布以外,Spearman秩相关系数分析还需要数据分级,以计算秩。
但在SPSS中程序会自动生成秩,无需再手动分级。
注意要保证总体相关系数ρ与样本相关系数r保持一致,还须考虑Sig值。
由数据,Sig<0.5表示接受原假设,即Rho>|r|。
Sig<0.5则拒绝原假设,两者不相关。
而r值则代表了正负相关性,以及相关性大小。
结果见表。
SPSS处理对应分析SPSS是一种广泛使用的统计分析软件,可以对数据进行各种统计分析,包括描述性统计、相关分析、回归分析、方差分析等。
其中,对应分析是一种用于研究两个分类变量之间关系的统计方法。
对应分析是根据两个分类变量之间的关联关系来分析它们的相互关系。
它适用于有两个或多个分类变量的研究,可以揭示不同分类变量之间的关系及其相互影响。
对应分析的原理是通过计算两个分类变量之间的卡方值,确定它们之间的相关性。
卡方值越大,两个变量之间的关联关系就越强。
在SPSS中进行对应分析,首先需要导入要进行分析的数据。
在导入数据后,点击“数据”菜单,选择“描述性统计”-“交叉表”,然后将需要分析的两个分类变量选择到右边的框中。
点击“统计量”按钮,选择“卡方”选项,然后点击“确定”按钮进行计算。
对应分析的结果将显示在分析窗口的下方。
结果包括两个变量之间的卡方值、自由度、卡方值显著性等信息。
卡方值越大,两个变量之间的关系就越显著。
通过卡方值的显著性,可以判断两个变量之间是否存在关联关系。
对应分析还可以通过绘制图表来展示两个变量之间的关系。
在SPSS 中,可以选择绘制分组柱状图、堆积柱状图、饼图等图表,来直观地展示两个变量之间的关联关系。
对应分析的应用领域广泛,例如市场调查、社会学研究、心理学研究等。
通过对应分析,可以揭示不同分类变量之间的关系及其影响因素,为相关研究提供依据和支持。
总之,SPSS是一种非常实用的统计分析软件,对应分析是其中的一种重要分析方法。
通过对应分析,可以研究不同分类变量之间的关联关系,并通过计算卡方值来判断其显著性。
对应分析的结果可以通过绘制图表来展示,直观地展示两个变量之间的关系。
对应分析可应用于不同领域的研究,为相关研究提供依据和支持。
1.数据格式:将个体的生长性状(体重,体长等)与个体基因型数据导入Excel,建立文档。
如图:2.导入SPSS软件:打开SPSS软件后点击File-OPEN-DATA,选定数据文档3.分析数据:点击Analyze-General linear model-univariate(当分析多个性状时选择Multivariate)-将体重设为Dependent(可同时分析多个性状)-将基因型设为Fixed factors(可以多选)——点击右边的Model,选择Custom,将Build term 选择为Main effects, 然后将基因型数据点击进入右边窗口,完成后点击Continue返回上个窗口——点击Plots,选择基因型数据进入Horizontal Axis,用于后续数据结果显示时出现图表(只有当基因型为3个及以上时才有必要)——点击Post Hoc,在新跳出的窗口中将基因型数据选入右边小窗口,然后在下面选择你需要的统计方法,一般选择LSD, Turkey’s-b, Turkey, Duncan,任何一种方法在后面的数据中显示出显著性都可以使用该数据发表文章,不过需说明所用方法。
选择完成后点击Continue 返回上一窗口——点击Options, 将基因型数据导入右边窗口,选择Compare main effects, 然后在下面选择一些显示形,一般选择Descriptive statistics, Estimates of effect size, General estimable function 等,可根据需要尝试。
点击Continue返回上一页面——点击OK,出现数据分析结果窗口。
说明:数据格式当中,我只有一个位点的基因型,所以直接用基因型命名,如果是多个位点的话可以分别命名为G432A形式,便于后续分析和查看结果。
但是最好一次分析一个位点,不然不同位点间可能会存在相互作用,数据不好解释。
关联分析(笔记)事物之间的关联关系包括:简单关联关系、序列关联关系。
简单关联规则:属于无指导学习方法,不直接用于分类预测,只揭示事物内部的结构。
Spss modeler 提供了APriori、GRI、Carma等经典算法。
APriori和Carma 属于同类算法。
序列关联:关联具有前后顺序,通常与时间有关。
SPSS Modeler 提供了sequence算法;数据格式如下:按照事务表存储,同事需要时间变量。
简单关联规则要分析的对象是事务事务的储存方式有事务表和事实表两种方式。
事务表事实表两种表均表明,顾客1购买了AD两种物品,顾客2购买了BD两种物品,顾客三购买了AC两种物品。
关联规则有效性的测度指标1、支持度support:所有购买记录中,A、B同时被购买的比例。
2、置信度confidence:在购买A的事务中,购买B的比例。
关联规则实用性的测度指标1、提升度lift:(在购买A的事务中,购买B的比例)/(所有事务中,购买B的比例)2、置信差3、置信率、正态卡方、信息差等等简单关联关系实例例1数据格式:事实表算法:Apriori所有购买项目均选入前项antecedent和后项consequent。
输出结果的最低支持度是10%;本例设定的划分频繁项集的标准大于最小支持度10%。
最小置信度是80%;前项最多项目数:5本例中,三项以上没有超过10%的支持度,所以不能形成三项以上的频繁项集,最大的频繁项集大小是2。
结论解释:实例:包含前项beer、cannedveg的样本有167个,在1000个样本中前项支持度为16.7%。
规则支持度:同时购买beer、cannedveg、frozenmeal三项的支持度为14.6%。
规则置信度:购买beer、cannedveg的客户中,87.425%的人有购买frozenmeal。
规则2下,购买frozenmeal的可能性比购买frozenmeal的支持度提高2.895倍。