数据的概括性度量数据特征的描述
- 格式:ppt
- 大小:715.01 KB
- 文档页数:2

【统计学】4.数据的概括性度量【统计学】4.数据的概括性度量4.1 集中趋势的度量4.2 离散程度的度量4.3 偏态与峰态的度量学习⽬标1.集中趋势各测度值的计算⽅法2.集中趋势各测度值的特点及应⽤场合3.离散程度各测度值的计算⽅法4.离散程度各测度值的特点及应⽤场合5.偏态与峰态的测度⽅法6.⽤excel 计算描述统计量并进⾏统计4.1 集中趋势的度量集中趋势(central tendency )1.⼀组数据向其中⼼值靠拢的倾向和程度,反映了⼀组数据中⼼点位置所在2.测度集中趋势就是寻找数据⽔平的代表值或中⼼值3.不同类型的数据不同的集中趋势测度值4.低层次数据的测度值适⽤于⾼层次的测量数据,但⾼层次的数据的测度值并不适⽤于低层次的测量数据4.1.1 分类数据:众数众数(mode )1.⼀组数据中出现次数最多的变量值2.⼀般仅适合数据量较多时使⽤3.不受极端值得影响4.⼀组数据可能没有众数或有⼏个众数(众数可能不唯⼀也可能不存在)5.主要⽤于分类数据(分类数据只对应分类的频数),也可⽤于顺序数据和数值型数据4.1.2 顺序数据:中位数和分位数中位数(median )1.⼀组数据排序后处于中间位置上的值2.中位数不受极端值的影响3.中位数主要⽤于顺序数据,也可⽤于数值型数据,但不适⽤于分类数据中位数(位置和数值的确定)排序位置确定n +12数值确定M e =x (n +12),n 为奇数12[x (n2)+x (n2+1)],n 为偶数因此中位数不⼀定是原数据中的某个变量值四分位数(quartile)1.排序后处于25%和75%位置上的值2.不受极端值的影响3.计算公式Q L 位置=n4,Q U 位置=3n4,4.如果是在0.25或0.75的位置上,则四分位数等于该位置的下侧值加上按⽐例分摊位置两侧数值的差值(加权平均数概念){{4.1.3 数值型数据:平均数平均数(mean )1.也称为均值2.集中趋势的最常⽤测度值3.⼀组数据的均衡点所在4.体现了数据的必然性5.易受极端值的影响6.有简单平均数和加权平均数之分7.根据总体数据计算,称为平均数,即为µ,根据样本数据计算的,称为样本平均数,即为x 简单平均数(算数平均数)设⼀组数据为:x 1,x 2,...x n (总体数据x N )样本平均数¯x =x 1+x 2+...+x n n =∑n i =1x i n 总体平均数µ=x 1+x 2+...+x N N =∑Ni =1x iN加权平均数(Weighted mean )设各组的组中值为:M 1,M 2,...,M k 相应的频数为:f 1,f 2,...f k 样本加权平均¯x =M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑k i =1M i f in总体加权平均µ=M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑⼏何平均数(geometric mean )1. n 个变量值乘积的n 次⽅根2. 适⽤于对⽐率数据的平均3. 主要⽤于计算平均增长率4. 计算公式为G =nx 1×x 2×...×x n =nn∏i =1xi4.1.4众数、中位数和平均数的⽐较1. 众数不受极端值影响具有不唯⼀性数据量较⼤时众数才有意义数据分布偏斜程度较⼤且有明显峰值时应⽤2. 中位数不受极端值影响数据分布偏斜程度较⼤时应⽤3. 平均数利⽤了全部数据信息,数学性质优良易受极端值影响数据对称分布或接近对称分布时应⽤4.2 离散程度的度量离中趋势1.数据分布的⼀个重要特征2.反映各变量值远离其中⼼值的程度(离散程度)3.从另⼀个侧⾯说明了集中趋势测度值的代表程度4.不同类型的数据有不同的离散程度测度值4.2.1 分类数据:异众⽐率异众⽐率(variation ratio )1. 对分类数据离散程度的测度2. ⾮众数组的频数占总频数的⽐例3. 计算公式v r =∑f i −f m ∑f i=1−f m∑f i4.⽤于衡量众数是否具有代表性4.2.2 顺序数据:四分位差四分位差(quartile deviation )1. 对顺序数据离散程度的测度2. 也称为内距或四分间距3. 上四分位数与下四分位数之差Q d =Q U −Q L4. 反映了中间50%数据的离散程度5. 不受极端值影响√√6. ⽤于衡量中位数是否具有代表性4.2.3 数值型数据:⽅差和标准差极差(range)1. ⼀组数值型数据的最⼤值和最⼩值之差2. 离散程度的最简单测度值3. 易受极端值影响4. 未考虑数据的分布,数据利⽤率低5. 计算公式为R=max(x i)−min(x i)标准差(mean deviation)1. 各变量值与其平均数离差绝对值的平均数2. 能全⾯反映⼀组数据的离散程度3. 数学性质差,实际应⽤较少4. 计算公式未分组数据M d=∑n i=1|x i−¯x|n组距分组数据Md=∑k i=1|M i−¯x|fin⽅差和标准差(variance and standard deviation)1. 各变量与其平均数离差平⽅的平均数2. 数据离散程度的最常⽤测度值3. 反映了各变量与均值的平均差异4. 根据总体数据计算的,称为总体⽅差(标准差)σ2(σ)根据样本数据计算的,称为样本⽅差(标准差)s2(s)⽅差的计算公式未分组数据s2=∑n i=1(x i−¯x)2n−1组距分组数据s2=∑k i=1(M i−¯x)2fin−1标准差的计算公式未分组数据s=∑n i=1(x i−¯x)2n−1组距分组数据s=∑k i=1(M i−¯x)2fin−1为什么是除以n-1⽽不是n?⾃由度(degree of freedom)1. ⾃由度是指数据个数与附加给独⽴观测值的约束或限制的个数之差2. 从字⾯涵义看,⾃由度是指⼀组数据中可以⾃由取值的个数3. 当样本数据的个数为n时,若样本平均数确定后,则附加给n个观测值的约束个数就是1个,因此只有n-1个数据可以⾃由取值,其中必有⼀个数据不能⾃由取值。

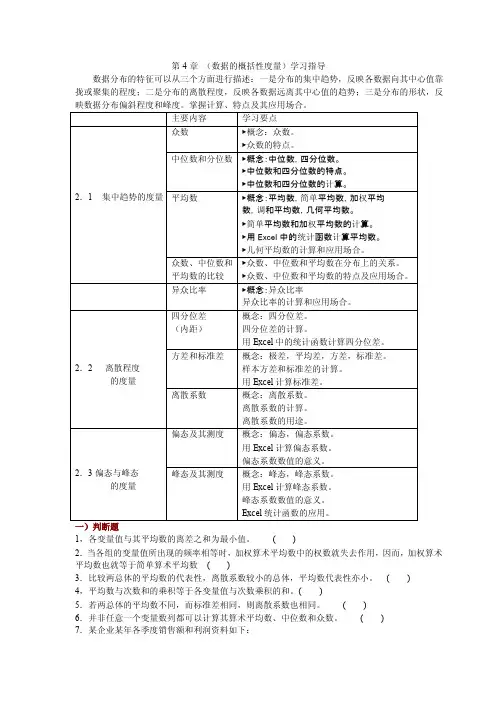
第4章(数据的概括性度量)学习指导数据分布的特征可以从三个方面进行描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布偏斜程度和峰度。
掌握计算、特点及其应用场合。
主要内容学习要点2.1 集中趋势的度量众数▶概念:众数。
▶众数的特点。
中位数和分位数▶概念:中位数,四分位数。
▶中位数和四分位数的特点。
▶中位数和四分位数的计算。
平均数▶概念:平均数,简单平均数,加权平均数,调和平均数,几何平均数。
▶简单平均数和加权平均数的计算。
▶用Excel中的统计函数计算平均数。
▶几何平均数的计算和应用场合。
众数、中位数和平均数的比较▶众数、中位数和平均数在分布上的关系。
▶众数、中位数和平均数的特点及应用场合。
异众比率▶概念:异众比率异众比率的计算和应用场合。
2.2离散程度的度量四分位差(内距)概念:四分位差。
四分位差的计算。
用Excel中的统计函数计算四分位差。
方差和标准差概念:极差,平均差,方差,标准差。
样本方差和标准差的计算。
用Excel计算标准差。
离散系数概念:离散系数。
离散系数的计算。
离散系数的用途。
2.3偏态与峰态的度量偏态及其测度概念:偏态,偏态系数。
用Excel计算偏态系数。
偏态系数数值的意义。
峰态及其测度概念:峰态,峰态系数。
用Excel计算峰态系数。
峰态系数数值的意义。
Excel统计函数的应用。
一)判断题1,各变量值与其平均数的离差之和为最小值。
( )2.当各组的变量值所出现的频率相等时,加权算术平均数中的权数就失去作用,因而,加权算术平均数也就等于简单算术平均数( )3.比较两总体的平均数的代表性,离散系数较小的总体,平均数代表性亦小。
( )4,平均数与次数和的乘积等于各变量值与次数乘积的和。
( )5.若两总体的平均数不同,而标准差相同,则离散系数也相同。
( )6.并非任意一个变量数列都可以计算其算术平均数、中位数和众数。


第一章导论1.什么是统计学?统计学是搜集、处理、分析、解释数据并从中得出结论的科学。
2.解释描述统计与推断统计。
描述统计研究的是数据搜集、处理、汇总、图表描述、概括与分析等统计方法。
推断统计研究的是如何利用样本数据来推断总体特征的统计方法。
3.统计数据可分为哪几种类型?不同类型的数据各有什么特点?按照计量尺度可分为分类数据、顺序数据和数值型数据;按照数据的搜集方法,可以分为观测数据和试验数据;按照被描述的现象与实践的关系,可以分为截面数据和时间序列数据。
4.解释分类数据、顺序数据和数值型数据的含义。
分类数据是只能归于某一类别的非数字型数据;顺序数据是只能归于某一有序类别的非数字型数据;数值型数据是按照数字尺度测量的观测值,其结果表现为具体的数值。
5.举例说明总体、样本、参数、统计量、变量这几个概念。
总体是包含所研究的全部个体的集合,样本是从总体中抽取的一部分元素的集合,参数是用来描述总体特征的概括性数字度量,统计量是用来描述样本特征的概括性数字度量,变量是用来说明现象某种特征的概念。
6.变量可分为哪几类?变量可分为分类变量、顺序变量和数值型变量。
分类变量是说明书屋类别的一个名称,其取值为分类数据;顺序变量是说明十五有序类别的一个名称,其取值是顺序数据;数值型变量是说明事物数字特征的一个名称,其取值是数值型数据。
7.举例说明离散型变量和连续型变量。
离散型变量是只能去可数值的变量,它只能取有限个值,而且其取值都以整位数断开,如“产品数量”;连续性变量是可以在一个或多个区间中取任何值的变量,它的取值是连续不断的,不能一一列举,如“温度”等。
第二章数据的搜集1.什么是二手资料?使用二手资料需要注意些什么?与研究内容有关、由别人调查和试验而来、已经存在并会被我们所利用的资料为二手资料。
使用时要评估资料的原始搜集人、搜集目的、搜集途径、搜集时间且使用时要注明数据来源。
2.比较概率抽样和非概率抽样的特点。
举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。

第四版统计学课后习题答案《统计学》第四版统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。



统计学基础(贾俊平)课后简答题第一章1.什么是统计学?统计方法可以分为哪两大类?统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。
统计方法可以分为描述统计和分类统计。
2、统计数据可分为哪几种类型?不同类型的数据各有什么特点?按照所采用的计量尺度不同,分为分类数据、顺序数据和数值型数据;按照统计数据的收集方法,分为观测的数据和实验的数据;按照被描述的对象与时间的关系,分为截面数据和时间序列数据。
按计量尺度分时:分类数据中各类别之间是平等的并列关系,各类别之间的顺序是可以任意改变的;顺序数据的类别之间是可以比较顺序的;数值型数据其结果表现为具体的数值。
按收集方法分时:观测数据是在没有对事物进行人为控制的条件下等到的;实验数据的在实验中控制实验对象而收集到的数据。
按被描述的对象与时间关系分时:截面数据所描述的是现象在某一时刻的变化情况;时间序列数据所描述的是现象随时间而变化的情况。
3.举例说明总体、样本、参数、统计量、变量这几个概念。
总体是包含所研究的全部个体(数据)的集合样本是从总体中抽取的一部分元素的集合参数是用来描述总体特征的概括性数字度量统计量是用来描述样本特征的概括性数字度量变量是说明现象某种特征的概念。
对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
4.什么是有限总体和无限总体?举例说明。
根据总体所包含的单位数目是否可数可以分为有限总体和无限总体。
总体的范围能够明确确定,而且元素的数目是有限可数的。
比如,由若干个企业构成的总体就是有限总体,一批待检验的灯泡也是有限总体。
无限总体是指总体所包括的元素是无限的,不可数的。
例如,在科学试验中,每一个试验数据可以看作是一个总体的一个元素,而试验可以无限地进行下去,因此由试验数据构成的总体就是一个无限总体。

用来描述总体特征的概括性数字度量统计量是指用来描述总体特征的概括性数字度量,它能够反映客观对象总体上所存在的各种差异程度。
从定义可知,统计量不同于统计指标,统计指标只具有名称、单位和数值,而统计量则必须包含事物本身的各种内容;再者,由于所选择的计量尺度不同,使得每个统计量都成为对相同对象的不同的比较尺度,因此,就形成了统计指标和统计量之间的区别。
由此看来,统计量是用来描述客观对象总体上存在的各种差异程度的数量标志。
统计工作正是借助于统计量及其组合来达到认识现象的目的。
另外,通常情况下,也把统计量当做事物某一种属性的具体量。
我们通过实践证明,事物发展过程中各阶段或时期的总体数量上的变化都可归结为三大类基本量:即绝对量(又叫自然数)、相对量(又叫平均数)和平均量(又叫平均数)。
统计量则正是作为对这三大类基本量进行抽象的量,起着统计研究总体的作用。
从定义可见,在任何一个统计指标中,其本身都隐藏着多种统计量的关系,这些统计量构成了综合评价指标。
统计工作就是利用上述原理去考察、认识客观事物并根据所获取的各种资料确定指标数值,使之更符合客观事物的真实面貌,以便决策。
问题:关于统计量在社会经济领域中的应用,请列举3个例子?—— A.企业的产品质量的统计; B.国家财政收入的统计; C.家庭消费水平的统计。
答案:国民经济核算,利润和折旧。
解析:从题干中的问题可知,该材料涉及统计量在社会经济领域中的应用,那么要求你列举3个例子,首先就需要找准方向,那么要求一般就针对该材料给出3-4个概念,既限制条件为第二次世界大战后美国对该领域投入巨额开支,但这样一来就超纲了,因此,建议采用排除法:先选择其他三个事项代替。
第1个选项,从中国古代科技史的角度出发考虑,已知道统计的范围仅仅局限于现实世界,对于该角度无疑最佳选择,因此该答案否定掉。
第2个选项,统计是一门专门的学科,适用于任何领域,所以很显然也可以排除。
第3个选项,虽然涵盖的领域广泛,却没有指出一个特殊点,就是国际贸易环节,故而也排除掉。

1.多重共线性:当回归模型中存在两个或两个以上的自变量彼此相关时,则称回归模型中存在多重共线性。
2.相关关系:变量之间存在的不确定的数量关系,称为相关关系。
3.五个相关关系:正线性相关,负线性相关,完全正线性相关,完全负线性相关,非线性相关,不相关。
若 0<r≤1,表明 x 与 y 之间存在正线性相关关系;若-1≤r <0,表明 x 与 y 之间存在负线性相关关系;若 r=+1,表明 x 与 y 之间为完全正线性相关关系;若 r=-1,表明 x 与 y 之间为完全负线性相关关系。
|r|→1 说明两个变量之间的线性关系越强;|r|→0 说明两个变量之间的线性关系越弱。
4.回归直线的拟合优度:回归直线与各观测点的接近程度称为回归直线对数据的拟合优度。
判定系数 R2测度了回归直线对观测数据的拟合程度。
5.最小二乘估计法:通过使因变量的观测值 yi 与估计值yi ∧之间的离差平方和,即残差平方和,达到最小来估计β0和β1的方法。
6. F 检验和 t 检验各有什么作用:F 检验是检验自变量 x 和因变量 y 之间的线性关系是否显著;t 检验是检验自变量对因变量的影响是否显著,也就是回归系数的检验。
7.8.正态分布—Z分布:大样本或小样本总体标准差σ已知。
9.N-1的T分布:小样本σ未知。
10.参数估计:点估计与区间估计11.置信区间:由样本统计量所构造的总体参数的估计区间。
12.置信水平:置信区间中包含总体参数真值的次数所占的比例。
置信水平越大,所需的样本量也就越大,置信区间越宽。
13.评价估计量的标准:无偏性:是指估计量抽样分布的数学期望等于被估计的总体参数有效性:是指对同一参数的两个无偏估计量,有更小方差的估计量越有效。
一致性:是指随着样本量n的增大,估计量的值越来越接近总体参数的真值。
14.样本量越大,样本均值的抽样标准差就越小。
15.总体数据的方差越大,估计时所需的样本量越大。
16.数据概括性度量:(数据分布特征的测量)集中趋势,离散程度,分布形态(偏态与峰态)17.三个分布:对称分布—众数=中位数=平均数左偏分布—平均数<中位数<众数右偏分布—众数<中位数<平均数18.标准分数的用途:①变量值与其平均数的离差除以标准差后的值称为标准分数,用Z表示。
统计学贾俊平考研知识点总结Pleasure Group Office【T985AB-B866SYT-B182C-BS682T-STT18】统计学重点笔记第一章导论一、比较描述统计和推断统计:数据分析是通过统计方法研究数据,其所用的方法可分为描述统计和推断统计。
(1)描述性统计:研究一组数据的组织、整理和描述的统计学分支,是社会科学实证研究中最常用的方法,也是统计分析中必不可少的一步。
内容包括取得研究所需要的数据、用图表形式对数据进行加工处理和显示,进而通过综合、概括与分析,得出反映所研究现象的一般性特征。
(2)推断统计学:是研究如何利用样本数据对总体的数量特征进行推断的统计学分支。
研究者所关心的是总体的某些特征,但许多总体太大,无法对每个个体进行测量,有时我们得到的数据往往需要破坏性试验,这就需要抽取部分个体即样本进行测量,然后根据样本数据对所研究的总体特征进行推断,这就是推断统计所要解决的问题。
其内容包括抽样分布理论,参数估计,假设检验,方差分析,回归分析,时间序列分析等等。
(3)两者的关系:描述统计是基础,推断统计是主体二、比较分类数据、顺序数据和数值型数据:根据所采用的计量尺度不同,可以将统计数据分为分类数据、顺序数据和数值型数据。
(1)分类数据是只能归于某一类别的非数字型数据。
它是对事物进行分类的结果,数据表现为类别,是用文字来表达的,它是由分类尺度计量形成的。
(2)顺序数量是只能归于某一有序类别的非数字型数据。
也是对事物进行分类的结果,但这些类别是有顺序的,它是由顺序尺度计量形成的。
(3)数值型数据是按数字尺度测量的观察值。
其结果表现为具体的数值,现实中我们所处理的大多数都是数值型数据。
总之,分类数据和顺序数据说明的是事物的本质特征,通常是用文字来表达的,其结果均表现为类别,因而也统称为定型数据或品质数据;数值型数据说明的是现象的数量特征,通常是用数值来表现的,因此可称为定量数据或数量数据。
统计学知识点(前四章)第1章导论1.统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。
2.按数据分析方法分类:↗描述统计—数据收集、处理、汇总、图表描述↘推断统计—利用样本数据推断总体特征3.统计数据是对现象进行测量的结果。
4.按照计量尺度的不同,将统计数据分为分类数据、顺序数据和数值型数据。
1)分类数据:对事物分类的结果,用文字表述,数据表现为类别(男女);2)顺序数据:有序的类别,如,一等品二等品、小学初中高中、同意;3)数值型数据:按数字尺度测量的观察值,具体的数值。
5.数据的计量尺度:1)定/分类尺度:数据表现为类别,按照事物的属性平行的分类,计量层次最低,具有“=”或“≠”的数学特性;2)定/顺序尺度:数据表现为有序的类别,具有“>”或“<”的数学特性;3)定距/间隔尺度:数据表现为数字,没有绝对零点;4)定比/比率尺度:数据表现为数字,有绝对零点。
3、4统称数值型数据。
6.定性/品质数据:分类数据和顺序数据统称。
定量/数量数据:数值型数据。
7.按照数据的收集方法:观测数据和实验数据。
按时间状况:截面数据和时间序列数据。
(统计数据的分类)8.总体:是包含所研究的全部个体(数据)的集合。
组成总体的每个元素成为个体。
按包含数目是否可数,分为有限总体和无限总体。
9.样本:是从总体中抽取的一部分元素的集合。
构成样本的元素的数目成为样本量。
抽样的目的是为了根据样本提供的信息推断总体的特征。
10.参数:是用来描述总体特征的概括性数字度量。
是研究者想要了解的总体的某种特征值,如,总体平均数μ、总体标准差σ。
11.统计量:是用来描述样本特征的概括性数字度量。
是根据样本数据计算出来的量,如,样本平均数χ 、样本标准差s。
12.变量:是说明现象某种特征的概念。
如,商品销售额、受教育程度。
变量的具体值称为变量值,比如商品的销售额可以是20万、30万。
13.变量的分类——分类变量:性别、行业;顺序变量:产品等级、受教育程度;数值型变量:↗离散型变量:产品数量、企业数(取值以整数位断开)↘连续性变量:年龄、温度、零件尺寸(取值连续不断)随机变量和非随机变量,经验变量和理论变量第2章数据的搜集1.数据的来源:间接来源和直接来源2.间接来源的数据:对原信息重新加工、整理,数据可以取自系统外部或内部。
统计学重点整理1、参数:是用来描述总体特征的概括性数字度量,它是研究者想要了解的总体的某种特征值。
通常有总体平均数、总体标准差、总体比例表示。
统计量:是用来描述样本特征的概括性数字度量。
它是根据样本数据计算出来的一个量。
通常有样本平均数、样本标准差、样本比例表示。
2、茎叶图:是反映原始数据分布的图形。
它由茎和叶两部分构成,其图形是数字组成的,通过其可以看出数据的分布形状及数据的离散状况。
箱线图:是由一组数据的最大值、最小值、中位数、两个四分位数这五个特征值绘制而成,它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较。
3、方差分析就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。
它所研究的是非类型自变量对数值型因变量的影响。
它是通过对数据误差来源的分析来判断不同总体的均值是否相等,进而分析自变量对因变量是否有显著影响. 假定前提:1、每个总体都应服从正态分布2、各个总体的方差必须相同3、观测值是独立的。
4、统计数据的分类(1)按计量尺度:分类的数据、顺序的数据、数值型数据(2)按收集方法:观察的数据、实验的数据(3)按时间状况:截面的数据、时序的数据5、饼图:是用圆形及圆内扇形的角度来表示数值大小的图形,它主要用于表示一个样本(或总体)中各组成部分的数据占全部数据的比例,对于研究结构性问题十分有用。
直方图和条形图:定义:直方图:是用于展示分组数据分布的一种图形,它是用矩形的宽度和高度来表示频数分布的。
条形图:是用宽度相同的条形的高度或长短来表示数据多少的图形。
区别:1、条形图使用图形的长度表示各类别频数的多少,其宽度固定,直方图用面积表示各组频数,矩形的高度表示每一组的频数或频率,宽度表示组距。
2、直方图各矩形连续排列,条形图分开排列,3、条形图主要展示分类数据,直方图主要展示数值型数据。
6、经验法则表明:当一组数据对称分布时,约有68%的数据在平均数加减1个标准差的范围之内,约有95%的数据在平均数加减2个标准差的范围之内,约有99%的数据在平均数加减3个标准差的范围之内。