数据的概括性度量
- 格式:pptx
- 大小:1.14 MB
- 文档页数:61

【统计学】4.数据的概括性度量【统计学】4.数据的概括性度量4.1 集中趋势的度量4.2 离散程度的度量4.3 偏态与峰态的度量学习⽬标1.集中趋势各测度值的计算⽅法2.集中趋势各测度值的特点及应⽤场合3.离散程度各测度值的计算⽅法4.离散程度各测度值的特点及应⽤场合5.偏态与峰态的测度⽅法6.⽤excel 计算描述统计量并进⾏统计4.1 集中趋势的度量集中趋势(central tendency )1.⼀组数据向其中⼼值靠拢的倾向和程度,反映了⼀组数据中⼼点位置所在2.测度集中趋势就是寻找数据⽔平的代表值或中⼼值3.不同类型的数据不同的集中趋势测度值4.低层次数据的测度值适⽤于⾼层次的测量数据,但⾼层次的数据的测度值并不适⽤于低层次的测量数据4.1.1 分类数据:众数众数(mode )1.⼀组数据中出现次数最多的变量值2.⼀般仅适合数据量较多时使⽤3.不受极端值得影响4.⼀组数据可能没有众数或有⼏个众数(众数可能不唯⼀也可能不存在)5.主要⽤于分类数据(分类数据只对应分类的频数),也可⽤于顺序数据和数值型数据4.1.2 顺序数据:中位数和分位数中位数(median )1.⼀组数据排序后处于中间位置上的值2.中位数不受极端值的影响3.中位数主要⽤于顺序数据,也可⽤于数值型数据,但不适⽤于分类数据中位数(位置和数值的确定)排序位置确定n +12数值确定M e =x (n +12),n 为奇数12[x (n2)+x (n2+1)],n 为偶数因此中位数不⼀定是原数据中的某个变量值四分位数(quartile)1.排序后处于25%和75%位置上的值2.不受极端值的影响3.计算公式Q L 位置=n4,Q U 位置=3n4,4.如果是在0.25或0.75的位置上,则四分位数等于该位置的下侧值加上按⽐例分摊位置两侧数值的差值(加权平均数概念){{4.1.3 数值型数据:平均数平均数(mean )1.也称为均值2.集中趋势的最常⽤测度值3.⼀组数据的均衡点所在4.体现了数据的必然性5.易受极端值的影响6.有简单平均数和加权平均数之分7.根据总体数据计算,称为平均数,即为µ,根据样本数据计算的,称为样本平均数,即为x 简单平均数(算数平均数)设⼀组数据为:x 1,x 2,...x n (总体数据x N )样本平均数¯x =x 1+x 2+...+x n n =∑n i =1x i n 总体平均数µ=x 1+x 2+...+x N N =∑Ni =1x iN加权平均数(Weighted mean )设各组的组中值为:M 1,M 2,...,M k 相应的频数为:f 1,f 2,...f k 样本加权平均¯x =M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑k i =1M i f in总体加权平均µ=M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑⼏何平均数(geometric mean )1. n 个变量值乘积的n 次⽅根2. 适⽤于对⽐率数据的平均3. 主要⽤于计算平均增长率4. 计算公式为G =nx 1×x 2×...×x n =nn∏i =1xi4.1.4众数、中位数和平均数的⽐较1. 众数不受极端值影响具有不唯⼀性数据量较⼤时众数才有意义数据分布偏斜程度较⼤且有明显峰值时应⽤2. 中位数不受极端值影响数据分布偏斜程度较⼤时应⽤3. 平均数利⽤了全部数据信息,数学性质优良易受极端值影响数据对称分布或接近对称分布时应⽤4.2 离散程度的度量离中趋势1.数据分布的⼀个重要特征2.反映各变量值远离其中⼼值的程度(离散程度)3.从另⼀个侧⾯说明了集中趋势测度值的代表程度4.不同类型的数据有不同的离散程度测度值4.2.1 分类数据:异众⽐率异众⽐率(variation ratio )1. 对分类数据离散程度的测度2. ⾮众数组的频数占总频数的⽐例3. 计算公式v r =∑f i −f m ∑f i=1−f m∑f i4.⽤于衡量众数是否具有代表性4.2.2 顺序数据:四分位差四分位差(quartile deviation )1. 对顺序数据离散程度的测度2. 也称为内距或四分间距3. 上四分位数与下四分位数之差Q d =Q U −Q L4. 反映了中间50%数据的离散程度5. 不受极端值影响√√6. ⽤于衡量中位数是否具有代表性4.2.3 数值型数据:⽅差和标准差极差(range)1. ⼀组数值型数据的最⼤值和最⼩值之差2. 离散程度的最简单测度值3. 易受极端值影响4. 未考虑数据的分布,数据利⽤率低5. 计算公式为R=max(x i)−min(x i)标准差(mean deviation)1. 各变量值与其平均数离差绝对值的平均数2. 能全⾯反映⼀组数据的离散程度3. 数学性质差,实际应⽤较少4. 计算公式未分组数据M d=∑n i=1|x i−¯x|n组距分组数据Md=∑k i=1|M i−¯x|fin⽅差和标准差(variance and standard deviation)1. 各变量与其平均数离差平⽅的平均数2. 数据离散程度的最常⽤测度值3. 反映了各变量与均值的平均差异4. 根据总体数据计算的,称为总体⽅差(标准差)σ2(σ)根据样本数据计算的,称为样本⽅差(标准差)s2(s)⽅差的计算公式未分组数据s2=∑n i=1(x i−¯x)2n−1组距分组数据s2=∑k i=1(M i−¯x)2fin−1标准差的计算公式未分组数据s=∑n i=1(x i−¯x)2n−1组距分组数据s=∑k i=1(M i−¯x)2fin−1为什么是除以n-1⽽不是n?⾃由度(degree of freedom)1. ⾃由度是指数据个数与附加给独⽴观测值的约束或限制的个数之差2. 从字⾯涵义看,⾃由度是指⼀组数据中可以⾃由取值的个数3. 当样本数据的个数为n时,若样本平均数确定后,则附加给n个观测值的约束个数就是1个,因此只有n-1个数据可以⾃由取值,其中必有⼀个数据不能⾃由取值。

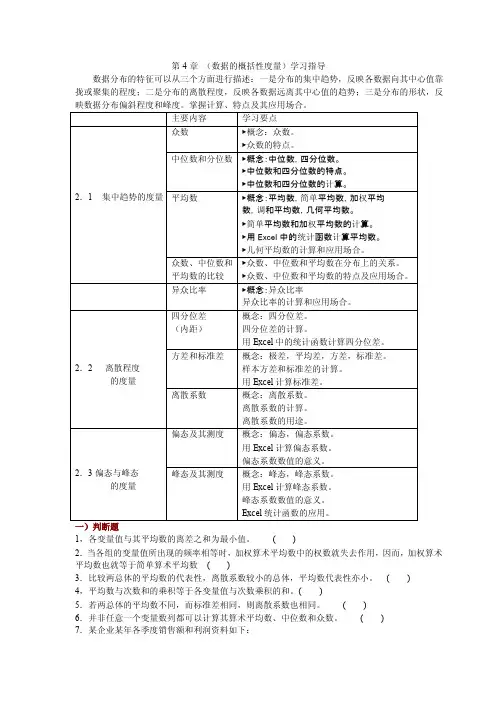
第4章(数据的概括性度量)学习指导数据分布的特征可以从三个方面进行描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布偏斜程度和峰度。
掌握计算、特点及其应用场合。
主要内容学习要点2.1 集中趋势的度量众数▶概念:众数。
▶众数的特点。
中位数和分位数▶概念:中位数,四分位数。
▶中位数和四分位数的特点。
▶中位数和四分位数的计算。
平均数▶概念:平均数,简单平均数,加权平均数,调和平均数,几何平均数。
▶简单平均数和加权平均数的计算。
▶用Excel中的统计函数计算平均数。
▶几何平均数的计算和应用场合。
众数、中位数和平均数的比较▶众数、中位数和平均数在分布上的关系。
▶众数、中位数和平均数的特点及应用场合。
异众比率▶概念:异众比率异众比率的计算和应用场合。
2.2离散程度的度量四分位差(内距)概念:四分位差。
四分位差的计算。
用Excel中的统计函数计算四分位差。
方差和标准差概念:极差,平均差,方差,标准差。
样本方差和标准差的计算。
用Excel计算标准差。
离散系数概念:离散系数。
离散系数的计算。
离散系数的用途。
2.3偏态与峰态的度量偏态及其测度概念:偏态,偏态系数。
用Excel计算偏态系数。
偏态系数数值的意义。
峰态及其测度概念:峰态,峰态系数。
用Excel计算峰态系数。
峰态系数数值的意义。
Excel统计函数的应用。
一)判断题1,各变量值与其平均数的离差之和为最小值。
( )2.当各组的变量值所出现的频率相等时,加权算术平均数中的权数就失去作用,因而,加权算术平均数也就等于简单算术平均数( )3.比较两总体的平均数的代表性,离散系数较小的总体,平均数代表性亦小。
( )4,平均数与次数和的乘积等于各变量值与次数乘积的和。
( )5.若两总体的平均数不同,而标准差相同,则离散系数也相同。
( )6.并非任意一个变量数列都可以计算其算术平均数、中位数和众数。


统计学各章计算题公式及解题方法第四章数据的概括性度量1.组距式数值型数据众数的计算:确定众数组后代入公式计算:下限公式:;上限公式:,其中,L为众数所在组下限,U为众数所在组上限,为众数所在组次数与前一组次数之差,为众数所在组次数与后一组次数之差,d为众数所在组组距2.中位数位置的确定:未分组数据为;组距分组数据为3.未分组数据中位数计算公式:4.单变量数列的中位数:先计算各组的累积次数(或累积频率)—根据位置公式确定中位数所在的组-对照累积次数(或累积频率)确定中位数(该公式假定中位数组的频数在该组内均匀分布)5.组距式数列的中位数计算公式:下限公式:;上限公式:,其中,为中位数所在组的频数,为中位数所在组前一组的累积频数,为中位数所在组后一组的累积频数6.四分位数位置的确定:未分组数据:;组距分组数据:7.简单均值:8.加权均值:,其中,为各组组中值统计学各章计算题公式及解题方法9.几何均值(用于计算平均发展速度):10.四分位差(用于衡量中位数的代表性):11.异众比率(用于衡量众数的代表性):12.极差:未分组数据:;组距分组数据:13.平均差(离散程度):未分组数据:;组距分组数据:14.总体方差:未分组数据:;分组数据:15.总体标准差:未分组数据:;分组数据:16.样本方差:未分组数据:;分组数据:17.样本标准差:未分组数据:;分组数据:18.标准分数:19.离散系数:第七章参数估计1.的估计值:置信水平α90%0.1 0。
05 1.65495% 0。
05 0.025 1.9699% 0.01 0。
005 2。
58统计学各章计算题公式及解题方法2.不同情况下总体均值的区间估计:总体分布样本量σ已知σ未知大样本(n≥30)正态分布小样本(n<30)非正态分布大样本(n≥30)其中,查p448 ,查找时需查n—1的数值3.大样本总体比例的区间估计:4.总体方差在置信水平下的置信区间为:5.估计总体均值的样本量:,其中,E为估计误差6.重复抽样或无限总体抽样条件下的样本量:,其中π为总体比例第八章假设检验1.总体均值的检验(已知或未知的大样本)[总体服从正态分布,不服从正态分布的用正态分布近似]假设双侧检验左侧检验右侧检验假设形式已知统计量未知拒绝域值决策,拒绝2.总体均值检验(未知,小样本,总体正态分布)假设双侧检验左侧检验右侧检验统计学各章计算题公式及解题方法假设形式已知统计量未知拒绝域值决策,拒绝注:已知的拒绝域同大样本3.一个总体比例的检验(两类结果,总体服从二项分布,可用正态分布近似)(其中为假设的总体比例)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝4.总体方差的检验(检验)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝5.统计量的参考数值0.1 0。


第四章数据的概括性度量第四章 数据的概括性度量一.填空题 1. 是一组数据中出现次数最多的变量值。
2.一组数据排序后处于中间位置上的变量值称 。
3.不受极端值影响的集中趋势度量指标有 . 和 。
4.一组数据的最大值与最小值之差称 。
5. 是一组数据的标准差与其相应的平均数之比。
6.Excel 中计算中位数时选用的函数为 。
7. 某工厂13名工人某日生产零件数分别为(单位:件)10.11.13.11.14.11.12.11.15.16.12.11.13 ,则中位数为 ;众数为 。
8.某百货公司连续几天的销售额如下:257.276.297.252.238.310.240.236.265,则其下四分位数是 。
9.若一组数据的e oX M M 〈〈,则其属于_______________分布(左偏.右偏)。
10.如果一组数据服从标准正态分布,则峰态系数为___________。
11.假定一个总体由5个数据组成:3.7.8.9.13,该总体的方差为。
13.某班共有25名学生,期末统计学课程的考试分数分别为:68.73.66.76.86.74.61.89.65.90.69.67.76.62.81.63.68.81.70.73.60.87.75.64.56,该班考试分数的下四分位数和上四分位数分别是和。
14.在某行业中随机抽取10家企业,第一季度的利润额(单位:万元)分别为72.63.1.54.7.54.3.29.26.9.25.23.9.23.20,该组数据的极差为。
二.单项选择题1.对于对称分布的数据,众数.中位数和平均数的关系是:()。
A.众数>中位数>平均数B.众数=中位数=平均数C.平均数>中位数>众数D.中位数>众数>平均数2.可以计算平均数的数据类型有:()。
A.分类型数据B.顺序型数据C.数据型数据D.所有数据类型3.数值型数据的离散程度测度方法中,受极端变量值影响最大的是()。
A.极差B.方差C.均方差D.平均差4.当偏态系数为正数时,说明数据的分布是()。



第4章数据的概括性度量一、单项选择题1.一组数据的峰度系数为3.5,则该数据的统计分布应具有的特征是()。
[中央财经大学2018研]A.扁平分布B.尖峰分布C.左偏分布D.右偏分布【答案】B【解析】峰度系数用来度量数据在中心的聚集程度。
在正态分布情况下,峰度系数值是3。
大于3的峰度系数说明观察量更集中,有比正态分布更短的尾部;小于3的峰度系数说明观测量不那么集中,有比正态分布更长的尾部,类似于矩形的均匀分布。
2.某企业男性职工占80%,月平均工资为450元,女性职工占20%,月平均工资为400元,该企业全部职工的平均工资为()。
[中央财经大学2015研] A.425元B.430元C.435元D.440元【答案】D【解析】企业全部职工的平均工资=男性职工比例×男性月平均工资+女性职工比例×女性月平均工资=80%×450+20%×400=440(元)。
3.15位同学的某门课程考试成绩中,70分出现3次,80分出现4次,85分出现6次,90分出现2次,则他们成绩的众数为()。
[华中农业大学2015研] A.80B.85C.81.3D.90【答案】B【解析】众数是一组数据中出现次数最多的变量值。
题中,85分出现次数最多,故成绩的众数为85分。
4.一组样本的变异系数(CV)等于10,样本均值为5,则样本方差为()。
[厦门大学2014研]A.2B.4C.0.5D.2500【答案】D【解析】变异系数是一组数据的标准差与其相应的平均数之比,因而样本标准差=样本均值×变异系数=5×10=50,样本方差=50×50=2500。
5.现抽取了10个同学,每个同学的月生活费数据排序后为:660,750,780,850,960,1080,1250,1500,1630,2000。
则中位数的位置为()。
[重庆大学2013研]A.5.5B.5C.4D.6【答案】A【解析】中位数是将样本排序后处于中间位置的数据,总共有10个样本,因此中位数的位次=(1+10)/2=5.5。

第4章 数据的概括性度量一、单项选择题1.一组数据中出现频数最多的变量值称为( )。
A.众数B.中位数C.四分位数D.平均数【答案】A【解析】众数是一组数据中出现次数最多的变量值。
众数主要用于测度分类数据的集中趋势。
一般情况下,只有在数据量较大的情况下,众数才有意义。
2.下列关于众数的叙述,不正确的是( )。
A.一组数据可能存在多个众数B.众数主要适用于分类数据C.一组数据的众数是唯一的D.众数不受极端值的影响【答案】C【解析】众数是一组数据中出现次数最多的变量值。
众数主要用于测度分类数据的集中趋势,当然也适用于作为顺序数据以及数值型数据集中趋势的测度值。
一般情况下,只有在数据量较大的情况下,众数才有意义。
一组数据可能存在多个众数,由于众数是一个位置代表值,因此它不受数据中极端值的影响。
3.一组数据排序后处于中间位置上的变量值称为( )。
A.众数B.中位数C.四分位数D.平均数【答案】B【解析】中位数是一组数据排序后处于中间位置上的变量值。
中位数将全部数据等分成两部分,每部分包含50%的数据,一部分数据比中位数大,另一部分则比中位数小。
4.一组数据排序后处于25%和75%位置上的值称为( )。
A.众数B.中位数C.四分位数D.平均数【答案】C【解析】四分位数也称四分位点,它是一组数据排序后处于25%和75%位置上的值。
四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据。
5.非众数组的频数占总频数的比例称为( )。
A.异众比率B.离散系数C.平均差D.标准差【答案】A【解析】异众比率是指非众数组的频数占总频数的比例。
主要用于衡量众数对一组数据的代表程度。
6.四分位差是( )。
A.上四分位数减下四分位数的结果B.下四分位数减上四分位数的结果C.下四分位数加上四分位数D.四分位数与上四分位数的中间值【答案】A【解析】四分位差也称内距或四分间距,它是上四分位数与下四分位数之差。
四分位差反映了中间50%数据的离散程度,其数值越小,说明中间的数据越集中;其数值越大,说明中间的数据越分散。