五_语料库汇总
- 格式:ppt
- 大小:1012.50 KB
- 文档页数:164

语料库术语汇编语料库术语汇编:Aboutness 所言之事Absolute frequency 绝对频数Alignment (of parallel texts) (平行或对应)语料的对齐Alphanumeric 字母数字类的Annotate 标注(动词)Annotation 标注(名词)Annotation scheme 标注方案ANSI/American National Standards Institute 美国国家标准学会ASCII/American Standard Code for Information Exchange 美国信息交换标准码Associate (of keywords) (主题词的)联想词A WL/Academic word list 学术词表Balanced corpus 平衡语料库Base list 底表、基础词表Bigram 二元组、二元序列、二元结构Bi-hapax 两次词Bilingual corpus 双语语料库CA/Contrastive Analysis 对比分析Case-sensitive 大小写敏感、区分大小写Chi-square (χ2) test 卡方检验Chunk 词块CIA/Contrastive Interlanguage Analysis 中介语对比分析CLA WS/Constituent Likelihood Automatic Word-tagging System CLA WS词性赋码系统Clean text policy 干净文本原则Cluster 词簇、词丛Colligation 类联接、类连接、类联结Collocate n./v. 搭配词;搭配Collocability 搭配强度、搭配力Collocation 搭配、词语搭配Collocational strength 搭配强度Collocational framework/frame 搭配框架Comparable corpora 类比语料库、可比语料库ConcGram 同现词列、框合结构Concordance (line) 索引(行)Concordance plot (索引)词图Concordancer 索引工具Concordancing 索引生成、索引分析Context 语境、上下文Context word 语境词Contingency table 连列表、联列表、列连表、列联表Co-occurrence/Co-occurring 共现Corpora 语料库(复数)Corpus Linguistics 语料库语言学Corpus 语料库Corpus-based 基于语料库的Corpus-driven 语料库驱动的Corpus-informed 语料库指导的、参考了语料库的Co-select/Co-selection/Co-selectiveness 共选(机制)Co-text 共文DDL/Data Driven Learning 数据驱动学习Diachronic corpus 历时语料库Discourse 话语、语篇Discourse prosody 话语韵律Documentation 备检文件、文检报告EAGLES/Expert Advisory Groups on Language Engineering Standards EAGLES文本规格embedded annotation 嵌入式标注Empirical Linguistics 实证语言学Empiricism 经验主义Encoding 字符编码Error-tagging 错误标注、错误赋码Extended unit of meaning 扩展意义单位File-based search/concordancing 批量检索Formulaic sequence 程式化序列Frequency 频数、频率General (purpose) corpus 通用语料库Granularity 颗粒度Hapax legomenon/hapax 一次词Header/Text head 文本头、头标、头文件HMM/Hidden Markov Model 隐马尔科夫模型Idiom Principle 习语原则Index/Indexing (建)索引In-line annotation 文内标注、行内标注Key keyword 关键主题词Keyness 主题性、关键性Keyword 主题词KWIC/Key Word in Context 语境中的关键词、语境共现(方式)Learner corpus 学习者语料库Lemma 词目、原形词、词元Lemma list 词形还原对应表Lemmata 词目、原形词、词元(复数)Lemmatization 词形还原、词元化Lemmatizer 词形还原(词元化)工具Lexical bundle 词束Lexical density 词汇密度Lexical item 词项、词语项目Lexical priming 词汇触发理论Lexical richness 词汇丰富度Lexico-grammar/Lexical grammar 词汇语法Lexis 词语、词项LL/Log likelihood (ratio) 对数似然比、对数似然率Longitudinal/Developmental corpus 跟踪语料库、发展语料库、历时语料库Machine-readable 机读的Markup 标记、置标MDA/Multi-dimensional approach 多维度分析法Metadata 元信息Meta-metadata 元元信息MF/MD (Multi-feature/Multi-dimensional) approach 多特征/多维度分析法Mini-text 微型文本Misuse 误用Monitor corpus (动态)监察语料库Monolingual corpus 单语语料库Multilingual corpus 多语语料库Multimodal corpus 多模态语料库MWU/Multiword unit 多词单位MWE/Multiword expression 多词单位MI/Mutual information 互信息、互现信息N-gram N元组、N元序列、N元结构、N元词、多词序列NLP/Natural Language Processing 自然语言处理Node 节点(词)Normalization 标准化Normalized frequency 标准化频率、标称频率、归一频率Observed corpus 观察语料库Ontology 知识本体、本体Open Choice Principle 开放选择原则Overuse 超用、过多使用、使用过度、过度使用Paradigmatic 纵聚合(关系)的Parallel corpus 平行语料库、对应语料库Parole linguistics 言语语言学Parsed corpus 句法标注的语料库Parser 句法分析器Parsing 句法分析Pattern/patterning 型式Pattern grammar 型式语法Pedagogic corpus 教学语料库Phraseology 短语、短语学POSgram 赋码序列、码串POS tagging/Part-of-Speech tagging 词性赋码、词性标注、词性附码POS tagger 词性赋码器、词性赋码工具Prefab 预制语块Probabilistic (基于)概率的、概率性的、盖然的Probability 概率Rationalism 理性主义Raw text/Raw corpus 生文本(语料)Reference corpus 参照语料库Regex/RE/RegExp/Regular Expressions 正则表达式Register variation 语域变异Relative frequency 相对频率Representative/Representativeness 代表性(的)Rule-based 基于规则的Sample n./v. 样本;取样、采样、抽样Sampling 取样、采样、抽样Search term 检索项Search word 检索词Segmentation 切分、分词Semantic preference 语义倾向Semantic prosody 语义韵SGML/Standard Generalized Markup Language 标准通用标记语言Skipgram 跨词序列、跨词结构Span 跨距Special purpose corpus 专用语料库、专门用途语料库、专题语料库Specialized corpus 专用语料库Standardized TTR/Standardized type-token ratio 标准化类符/形符比、标准化类/形比、标准化型次比Stand-off annotation 分离式标注Stop list 停用词表、过滤词表Stop word 停用词、过滤词Synchronic corpus 共时语料库Syntagmatic 横组合(关系)的Tag 标记、码、标注码Tagger 赋码器、赋码工具、标注工具Tagging 赋码、标注、附码Tag sequence 赋码序列、码串Tagset 赋码集、码集Text 文本TEI/Text Encoding Initiative 文本编码计划The Lexical Approach 词汇中心教学法The Lexical Syllabus 词汇大纲Token 形符、词次Token definition 形符界定、单词界定Tokenization 分词Tokenizer 分词工具Transcription 转写Translational corpus 翻译语料库Treebank 树库Trigram 三元组、三元序列、三元结构T-score T值Type 类符、词型TTR/Type-token ratio 类符/形符比、类/形比、型次比Underuse 少用、使用不足Unicode 通用码Unit of meaning 意义单位WaC/Web as Corpus 网络语料库Wildcard 通配符Word definition 单词界定Word form 词形Word family 词族Word list 词表XML/EXtensible Markup Language 可扩展标记语言Zipf's Law 齐夫定律Z-score Z值。

国家语委现代汉语语料库介绍国家语委现代汉语语料库是一个大型的通用的语料库,以语言文字的信息处理、语言文字规范和标准的制定、语言文字的学术研究、语文教育和语言文字的社会应用为主要服务目标。
国家语委现代汉语语料库作为国家级语料库,在汉语语料库系统开发技术上具有国际领先水平,在语料可靠、标注准确等方面具有权威性。
国家语委现代汉语语料库面向国内外的长远需要,选材有足够的时间跨度,语料抽样合理、分布均匀、比例适当,能够比较科学地反映现代汉语全貌。
一、国家语委语料库的组成国家语委现代汉语语料库由人文与社会科学、自然科学及综合三个大类约40个小类组成。
具体类别如下:1.人文与社会科学类划分为8个大类和30个小类:(1)政法:哲学、政治、宗教、法律。
(2)历史:历史、考古、民族。
(3)社会:社会学、心理、语言文字、教育、文艺理论、新闻、民俗。
(4)经济:工业经济、农业经济、政治经济、财贸经济。
(5)艺术:音乐、美术、舞蹈、戏剧。
(6)文学:小说、散文、传记、报告文学、科幻、口语。
(7)军体:军事、体育。
(8)生活2.自然科学划分为6类:数理、生化、天文地理、海洋气象、农林、医药卫生。
3.综合类语料由应用文和难于归类的其他语料两部分组成。
应用文使用很广泛,主要及以下6类:(1)行政公文:请示、报告、批复、命令、指示、布告、纪要、通知等(2)章程法规:章程、条例、细则、制度、公约、办法、法律条文等(3)司法文书:诉讼、辩护词、控告信、委托书等(4)商业文告:说明、广告、调查报告、经济合同等(5)礼仪辞令:欢迎词、贺电、讣告、唁电、慰问信、祝酒词等(6)实用文书:请假条、检讨、申请书、请愿书等。
国家语委现代汉语语料库的数据量包括新增的1000万字新语料已经达到了1亿字,已经完成词语切分和标注加工的约5000万字语料是语料库中1919~1992时间段的大部分语料以及1992~2002时间段的部分语料。
二、国家语委语料库建设的主要科研成果如下:1)5000万字带有分词和词性标注的汉语语料2)语料库加工规范3)1000万字新语料,语料库总规模达到1亿字4)词语切分和词性标注软件5)100万字(5万句)句法树库6)树库加工规范8)树库标记集规范9)语料库词语切分和词性标注软件10)语料库校对加工工具软件11)语料库质量检查工具软件12)语料库例句检索工具软件13)语料查询与统计工具软件14)语料库管理工具软件15)树库句法分析器软件16)树库校对软件17)相关研究论文三、国家语委语料库的应用目前,国家语委语料库已经为国家语委规范汉字表、汉字属性库项目和科技部863计划课题智能中文信息处理平台、中文信息处理应用基础研究项目以及973计划课题中文语音语言资源联盟项目等多个科研项目提供了支持,为北京大学、北京师范大学、首都师范大学、厦门大学、中科院自动化研究所、中科院心理研究所等多个高校和科研院所提供了服务,也为东芝(中国)研发中心、富士通研究院等企业提供了高质量的汉语语料资源。
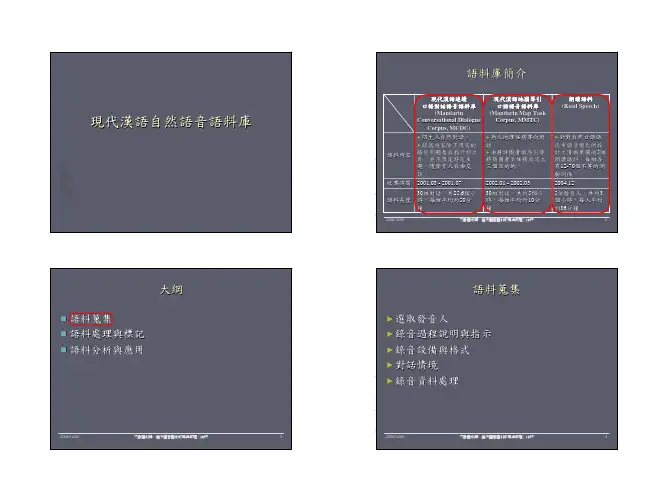


语言学常用语料库
语言学常用语料库有很多,以下是一些常用的语料库:
1. Brown语料库:美国布朗大学语言学部于1960年代编制的语料库,是英语语料库中最早的、最著名的语料库之一。
2. Penn Treebank语料库:由宾夕法尼亚大学开发的语料库,主要用于句法分析和语言学研究。
3. CoNLL语料库:共享任务(Conference on Computational Natural Language Learning)所使用的语料库,包括各种语言的语料。
4. Europarl语料库:包括欧洲议会会议的多种语言翻译版本,用于机器翻译和跨语言研究。
5. Google语料库:由Google搜索引擎收集的大规模网络文本语料库,可用于研究自然语言处理和文本挖掘等领域。
6. Corpus of Contemporary American English (COCA):包括当代美国英语的语料库,涵盖了各种不同类型的文本。
7. British National Corpus (BNC):出版物、广播和会话等来源的英国英语语料库,是英国英语的重要资源。
这些语料库提供了大量的文本数据,可用于研究不同语言的语
言学现象,如词汇使用、语法结构和语义等。
它们对于语言学研究和自然语言处理的发展起着重要作用。

语言学常用语料库
以下是一些语言学常用的语料库:
- Brown语料库:这是一个基于英语的语料库,包含了1961年至1979年间推广的1,000,000个单词的样本,覆盖了各种文体和题材。
- COCA(Corpus of Contemporary American English):这是一
个覆盖美国当代英语的语料库,包含了1990年至今的一亿多
个单词样本。
- BNC(British National Corpus):这是一个覆盖英国英语的
语料库,包含了1980年代至1993年间的一亿个单词样本。
- CHILDES(Child Language Data Exchange System):这是一
个收集婴儿和儿童语言数据的数据库,用于研究儿童语言发展。
- Penn Treebank:这是一个标注了句法和语义信息的英语语料库,用于自然语言处理研究。
- EuroParl语料库:这是一个包含欧洲议会会议记录的多语言
语料库,可以用于研究多语言对比和机器翻译。
- COrE(Corpus of English):这是一个以英语为基础的多样
化语料库,包含了来自不同国家和地区的语言样本,用于研究语言变体和语言接触。
- WALS(World Atlas of Language Structures):这是一个收集了世界各地不同语言结构的数据库,可以用于跨语言比较和语言学理论研究。
这些语料库可以通过在线平台或特定的研究机构访问和获取。
使用语料库可以帮助语言学家进行语言研究、语言分析和理论构建。

语料库的类型[作者:李文中转贴自:Corpora and the ELT点击数:97 文章录入:neilruan ]语料库来自拉丁词corpus,原意为“汇总”、“文集”等,复数形式为corpora或corpuses。
语料库是“作品汇集,以及任何有关主题的文本总集”(OED)是“书面语或口头语材料总集,为语言学分析提供基础”(OED)。
语料库是“按照明确的语言学标准选择并排序的语言运用材料汇集,旨在用作语言的样本”(Sinclair,1986:185-203)。
语料库是按照明确的设计标准,为某一具体目的而集成的大型文本库(Atkins and Clear,1992:1-16)。
Renouf认为,语料库是“由大量收集的书面语或口头语构成,并通过计算机储存和处理,用于语言学研究的文本库”(Renouf, 1987:1)。
Leech指出,大量收集的可机读的电子文本是概率研究方法中获得“必需的频率数据”的基础,“为获得必需的频率数据,我们必须分析足量的自然英语(或其它语言)文本,以便基于观测频率(observed frequency)进行合乎实际的预测。
因此,就需要依靠可机读的电子文本集,即可机读的语料库”(Leech, 1987:2)。
综上所述,语料库具有以下基本特征:1〕语料库的设计和建设是在系统的理论语言学原则指导下进行的,语料库的开发具有明确而具体的研究目标。
如二十世纪六十年代初的BROWN语料库主要目的是对美国英语进行语法分析,而随后的LOB语料库基本按照BROWN语料库的设计原则收集了同年代的英国英语,目的是进行美国英语和英国英语的对比分析和语法分析。
2〕语料库语料的构成和取样是按照明确的语言学原则并采取随机抽样方法收集语料的,而不是简单地堆积语料。
所收集的语料必须是语言运用的自然语料(naturally-occurred data)。
3)语料库作为自然语言运用的样本,就必须具有代表性(representativeness)。

1.英语学习者语料库(书面语及口语)中国学习者语料库 CLEC(100万)广外、上海交大2.大学英语学习者口语语料库 COLSEC (5万) 上海交大3.香港科技大学学习者语料库 HKUST Learner Corpus 香港科技大学4.中国英语专业语料库 CEME (148万) 南京大学5.中国英语学习者口语语料库 SECCL (100万) 南京大学6.国际外语学习者英语口语语料库中国部分 LINSEI-China (10万) 华南师大7.硕士写作语料库 MWC (12万) 华中科技大学9.平行语料库汉英平行语料库 PCCE 北外10.南大-国关平行语料库南京大学11.英汉文学作品语料库;外研社12.冯友兰《中国哲学史》汉英对照语料库13.李约瑟(Joself Needham)《中国科学技术史》英汉对照语料库14.计算机专业的双语语料库;国家语言文字工作委员会语言文字应用研究所15.柏拉图(Plato)哲学名著《理想国》的双语语料库16.英汉双语语料库(15万对) 中科院软件所17.英汉双语语料库:LDC香港新闻英汉双语对齐语料36294段以及香港法律英汉双语对齐语料31万句子对中国科学院自动化研究所18.英汉双语语料库(100万),网上英汉语段电子词典及网上电子英汉搭配词典(1000万) 东北大学19.英汉双语语料库(40-50万句子对) 哈尔滨工业大学20.双语语料库(5万多对) 北京大学计算语言学研究所21.对比语料库 LIVAC(Linguistic variety in Chinese communities) 香港城市理工大学22.平衡语料库(Sinica Corpus);树图语料库(Sinica Treebank) 台湾23.特殊英语语料库中国英语(China English)语料库河南师范大学24.军事英语语料库(Corpus of Military Texts) 解放军外语学院25.新视野大学英语教材语料库上海交通大学26.汉语语料库汉语现代文学作品语料库(1979年,527万字) 武汉大学27.现代汉语语料库(1983年,2000万字) 北京航空航天大学28.中学语文教材语料库(1983年,106万8000字) 北京师范大学29.现代汉语词频统计语料库(1983年,182万字) 北京语言学院30.国家级大型汉语均衡语料库(2000万字) 国家语言文字工作委员会31.《人民日报》语料库(2700万字) 北京大学计算机语言学研究所32.大型中文语料库(5亿字,10分库) 北京语言文化大学33.现代汉语语料库(1亿字) 清华大学34.汉语新闻语料库;(1988年,250万字) 山西大学35.标准语料库(2000年,70万字)36.生语料库(3000万字);《作家文摘》的标注语料库(100万字) 上海师范大学37.现代自然口语语料库中国社会科学院语言所38.旅游咨询口语对话语料库和旅馆预定口语对话语料库中国科学院自动化所39.北京大学汉语语言学研究中心的三个语料库现代汉语语料库/yuliao.asp?item=1古代汉语语料库/yuliao.asp?item=2汉英双语语料库/yuliao.asp?item=3/printthread.php?t=2742汉语语料库使用权限国家语委语料库(http://219.238.40.213:8080/CpsQrySv.srf)”虽说是通用型平衡语料库,但不能完全免费使用;北京语言大学的汉语语料库(http://202.112.195.8)语料产出时间较早,且不能完全免费使用;北京大学汉语语言学研究中心语料库(现代汉语子库)”(/YuLiao_Contents.Asp)规模最大,逾亿字,但取样极不均衡,多半为文学作品;台湾“中央研究院”Sinica Corpus也是可免费使用的平衡汉语语料库。

语料库研究与应用综述目录一概述二中国语料库建设的基本情况三语料库的加工、管理和规范四语料库在语言研究中的的应用五参考文献语料库研究与应用综述一概述语料库通常指为语言研究收集的、用电子形式保存的语言材料,由自然出现的书面语或口语的样本汇集而成,用来代表特定的语言或语言变体。
经过科学选材和标注、具有适当规模的语料库能够反映和记录语言的实际使用情况。
人们通过语料库观察和把握语言事实,分析和研究语言系统的规律。
语料库已经成为语言学理论研究、应用研究和语言工程不可缺少的基础资源。
语料库有多种类型,确定类型的主要依据是它的研究目的和用途,这一点往往能够体现在语料采集的原则和方式上。
有人曾经把语料库分成四种类型:(1)异质的(Heterogeneous):没有特定的语料收集原则,广泛收集并原样存储各种语料;(2)同质的(Homogeneous):只收集同一类内容的语料;(3)系统的(Systematic):根据预先确定的原则和比例收集语料,使语料具有平衡性和系统性,能够代表某一范围内的语言事实;(4)专用的(Specialized):只收集用于某一特定用途的语料。
除此之外,按照语料的语种,语料库也可以分成单语的(Monolingual)、双语的(Bilingual)和多语的(Multilingual)。
按照语料的采集单位,语料库又可以分为语篇的、语句的、短语的。
双语和多语语料库按照语料的组织形式,还可以分为平行(对齐)语料库和比较语料库,前者的语料构成译文关系,多用于机器翻译、双语词典编撰等应用领域,后者将表述同样内容的不同语言文本收集到一起,多用于语言对比研究。
语料库建设中涉及的主要问题包括:(1)设计和规划:主要考虑语料库的用途、类型、规模、实现手段、质量保证、可扩展性等。
(2)语料的采集:主要考虑语料获取、数据格式、字符编码、语料分类、文本描述,以及各类语料的比例以保持平衡性等。
(3)语料的加工:包括标注项目(词语单位、词性、句法、语义、语体、篇章结构等)标记集、标注规范和加工方式。

语料库在编纂或修订过程中,不同程度地使⽤语料库或电⼦⽂档收集词语数据,⽤于收词、释义、例句、属性标注等。
南京⼤学近年来开发了 NULEXID 语料库暨双语词典编纂系统,涉及英汉两种语⾔,在《新时代英汉⼤词典》的编纂过程中起了重要作⽤。
把语料库⽤于语⾔教学的⼀个例⼦是上海交通⼤学的 JDEST 英语语料库,利⽤这个语料库,通过语料⽐较、统计、筛选等⽅法为中国⼤学英语教学提供通⽤词汇和技术词汇的应⽤信息,为确定⼤学英语教学⼤纲的词表提供了可靠的量化依据。
这个语料库也在英语语⾔研究中发挥了作⽤,⽀持基于语料库的英语语法的频率特征、语料库驱动的词语搭配等项研究。
2003 年,中国学习者英语语料库由上海外语教育出版社正式发⾏。
这个语料库是⼀个 100多万词的书⾯英语语料库,涵盖我国中学⽣、⼤学英语 4级和 6 级、英语专业低年级和⾼年级的学习内容,并对所有的语料作了语法标注和⾔语失误标注。
根据这个语料库得到了词频排列表、拼写失误表、词⽬表、词频分布表、语法标注频数表、⾔语失误表等,还把这些数据与⼀些英语本族语语料库(如 BROWN,LOB,FROWN,FLOB)进⾏了某些⽐较。
这个语料库为词典编纂、教材编写和语⾔测试提供了必要的资源。
⽬前上海交通⼤学正在建设⼤学英语学习者⼝语英语语料库。
国外的主要语料库有:现在,美国Brown⼤学建⽴了BROWN语料库(布朗语料库),这是世界上第⼀个根据系统性原则采集样本的标准语料库,规模为 100 万词次,是⼀个代表当代美国英语的语料库。
英国Lancaster⼤学与挪威Oslo⼤学与Bergen⼤学联合建⽴了 LOB 语料库,规模与 Brown语料库相当,这是⼀个代表当代英国英语的语料库。
欧美各国学者利⽤这两个语料库开展了⼤规模的研究,其中最引⼈注⽬的是对语料库进⾏语法标注的研究。
他们设计了 CLAWS 系统来给 LOB 语料库的100万词的语料作⾃动标注,根据统计信息来建⽴算法,⾃动标注正确率达 96%。
语料库语言学术语汇编Aglossaryofcorpuslinguistics语料库语言学术语汇编(V2.0)Last updated 2012-10-08 by 许家金Aboutness 所言之事Absolute frequency 绝对频数Alignment (of parallel texts)(平行或对应)语料的对齐Alphanumeric 字母数字构成的Annotate标注(动词)Annotated text/corpus 标注文本/语料库、赋码文本/语料库Annotation标注(名词)Annotation scheme标注方案ANSI/American National Standards Institute美国国家标准学会ASCII/American Standard Code for Information Exchange美国信息交换标准码Associates (of keywords)(主题词的)联想词AWL/academic word list 学术词表Balanced corpus 平衡语料库Base list/baselist 底表、基础词表Bigram 二元组、二元序列、二元结构Bi-text/bitext双语合并文本、双语分行对齐文本(一句源语一句目标语对齐后的文本)Bi-hapax 两次词Bilingual corpus双语语料库Bootcamp debate/discourse/discussion (新手)训练营大辩论/话语/大探讨CA/Contrastive Analysis 对比分析Case-sensitive/case sensitivity 大小写敏感、区分大小写Category-based approach 基于类(范畴)的方法Chi-square test/χ2 卡方检验Chunk词块CIA/Contrastive Interlanguage Analysis中介语对比分析CLAWS/Constituent Likelihood Automatic Word-tagging System CLAWS 词性赋码系统Clean text policy 干净文本原则Cluster 词簇、词丛Colligation 类联接、类连接、类联结Collocate n./v.搭配词;搭配Collocability 搭配强度、搭配力Collocation搭配、词语搭配Collocational strength 搭配强度Collocational framework/frame 搭配框架Collocational profile搭配概貌、管路敷设技术通过管线不仅可以解决吊顶层配置不规范高中资料试卷问题,而且可保障各类管路习题到位。
语言翻译必备:国内外23个语料库推荐语料库通常指为语言研究收集的、用电子形式保存的语言材料,由自然出现的书面语或口语的样本汇集而成,用来代表特定的语言或语言变体。
经过科学选材和标注、具有适当规模的语料库能够反映和记录语言的实际使用情况。
下面推荐一些优质的语料库资源。
国内语料库资源1. 国家语委现代汉语语料库 现代汉语通用平衡语料库现在重新开放网络查询了。
重开后的在线检索速度更快,功能更强,同时提供检索结果下载。
现代汉语语料库在线提供免费检索的语料约2000万字,为分词和词性标注语料。
2. 国家语委古代汉语语料库 网站现在还增加了一亿字的古代汉语生语料,研究古代汉语的也可以去查询和下载。
同时,还提供了分词、词性标注软件、词频统计、字频统计软件,基于国家语委语料库的字频词频统计结果和发布的词表等,以供学习研究语言文字的老师同学使用。
3. 北京大学“《人民日报》标注语料库”4. 北大语料库——北京大学中国语言学研究中心 北大语料库由“现代汉语语料库”、“古代汉语语料库”、“汉英双语语料库”三个语料库组成。
其中,北大计算语言学研究所的双语语料库,英汉对齐的句子已有5万多对,并开发了相应的对齐工具和双语语料库管理软件。
正在此基础上做汉英对照短语库,预计规模将达数十万条。
(汉英双语语料库目前仅对北大校内用户开放)5. 北京语言大学高翻学院的“高翻记忆库”6. 清华大学汉语均衡语料库TH-ACorpus7. 中央研究院“现代汉语平衡语料库” 专门针对语言分析而设计的,每个文句都依词断开,并标示词类。
语料的搜集也尽量做到现代汉语分配在不同的主题和语式上,是现代汉语无穷多的语句中一个代表性的样本。
现有语料库主要针对语言分析而设计,由中央研究院信息所、语言所词库小组完成,内含有简介、使用说明,现行的语料库是4.0的版本。
8. 中央研究院“近代汉语标记语料库”9. 中央研究院汉籍电子文献(瀚典全文检索系统) 包含整部25史整部阮刻13经、超过2000万字的台湾史料、1000万字的大正藏以及其他典籍。