两种空间插值方法的比较研究
- 格式:doc
- 大小:255.51 KB
- 文档页数:8


arcgis反距离权重法与样条函数法实验感悟近年来,地理信息系统(GIS)在空间分析和建模中得到了广泛应用。
在GIS中,距离权重法和样条函数法是常用的空间插值方法,用于分析和模拟地理现象的空间分布规律。
本文将重点讨论两种方法的理论基础、实验设计和结果分析,并对它们的优缺点进行比较和总结。
一、arcgis反距离权重法距离权重法是一种基于距离的插值方法,它假设地理现象与距离远近相关,距离越近权重越大。
在arcgis中,距离权重法是通过计算邻近观测点到插值点的距离并赋予不同权重,然后根据各个权重对观测点值进行加权平均来估计插值点的数值。
距离权重法简单易行,无需分布假设,适用于各种地理现象的分析和模拟。
本文选取了某城市的气温观测数据,利用arcgis进行反距离权重法插值实验。
首先,我们收集了城市各个气温观测点的数据和位置信息,然后将插值点网格化,计算每个插值点到观测点的距离和权重。
最后,根据距离和权重对观测点值进行加权平均,得到了插值点的气温估计值。
实验结果表明,反距福权重法可以较好地模拟城市气温的空间分布规律,同时反映了城市气温的热岛效应和地形起伏对气温分布的影响。
二、arcgis样条函数法样条函数法是一种光滑插值方法,它利用数学函数模拟地理现象的空间变化过程。
在arcgis中,样条函数法是通过拟合和求解插值点之间的数学函数来估计插值点的数值。
样条函数法灵活性强,可以拟合各种复杂的空间现象,但也需要事先确定插值函数的形式和参数,可能导致过拟合和模型不确定性。
本文同样利用arcgis进行样条函数法插值实验,对比了线性、二次和三次样条插值函数。
实验结果显示,三次样条插值函数可以较好地拟合城市气温的空间变化规律,不仅能够准确反映气温的空间趋势,还可以光滑地处理气温变化过程中的极值和异常值,为城市气温的模拟和预测提供了重要依据。
三、感悟和总结距离权重法和样条函数法作为常用的空间插值方法,各自具有独特的优势和劣势。

1. 克里金法(Kriging)克里金法是通过一组具有z 值的分散点生成估计表面的高级地统计过程。
与其他插值方法不同,选择用于生成输出表面的最佳估算方法之前应对由z 值表示的现象的空间行为进行全面研究。
克里金插值与IDW插值的区别在于权重的选择,IDW仅仅将距离的倒数作为权重,而克里金考虑到了空间相关性的问题。
它首先将每两个点进行配对,这样就能产生一个自变量为两点之间距离的函数。
对于这种方法,原始的输入点可能会发生变化.在数据点多时,结果更加可靠。
该方法通常用在土壤科学和地质中。
2. 反距离权重法(Inverse Distance Weighted,IDW)反距离权重法(反距离权重法)工具所使用的插值方法可通过对各个待处理像元邻域中的样本数据点取平均值来估计像元值。
点到要估计的像元的中心越近,则其在平均过程中的影响或权重越大.此方法假定所映射的变量因受到与其采样位置间的距离的影响而减小。
例如,为分析零售网点而对购电消费者的表面进行插值处理时,在较远位置购电影响较小,这是因为人们更倾向于在家附近购物.反距离权重法主要依赖于反距离的幂值。
幂参数可基于距输出点的距离来控制已知点对内插值的影响。
幂参数是一个正实数,默认值为2。
通过定义更高的幂值,可进一步强调最近点.因此,邻近数据将受到最大影响,表面会变得更加详细(更不平滑)。
随着幂数的增大,内插值将逐渐接近最近采样点的值。
指定较小的幂值将对距离较远的周围点产生更大影响,从而导致更加平滑的表面。
由于反距离权重公式与任何实际物理过程都不关联,因此无法确定特定幂值是否过大。
作为常规准则,认为值为30 的幂是超大幂,因此不建议使用.此外还需牢记一点,如果距离或幂值较大,则可能生成错误结果。
3。
含障碍的样条函数(Spline with Barriers)含障碍的样条函数工具使用的方法类似于样条函数法工具中使用的技术,其主要差异是此工具兼顾在输入障碍和输入点数据中编码的不连续性.含障碍的样条函数工具应用了最小曲率方法,其实现方式为通过单向多格网技术,以初始的粗糙格网(在本例中是已按输入数据的平均间距进行初始化的格网)为起点在一系列精细格网间移动,直至目标行和目标列的间距足以使表面曲率接近最小值为止。

GIS空间数据插值方法优劣比较分析GIS(地理信息系统)是一种以地理坐标为基础,用于存储、处理、分析和可视化地理数据的强大工具。
在GIS中,空间数据插值是一种常用的技术,用于根据已知的点数据来估计未知地点的属性值。
本文将对常见的GIS空间数据插值方法进行优劣比较分析,以帮助用户选择适合自己需求的方法。
1. Kriging插值法Kriging是一种基于统计模型的插值方法,其基本思想是用已知点的值的权重的线性和来估计未知点的值。
Kriging方法考虑了空间数据的空间相关性,针对空间上的各点给予不同的权重,可以得到较为准确的预测结果。
相比于其他插值方法,Kriging在保持空间一致性和稳定性方面具有优势,但其计算复杂度较高,对于大规模数据和计算资源有要求。
2. 反距离加权插值法反距离加权法是一种简单而直观的插值方法。
其基本思想是根据已知点到未知点的距离的倒数来给予权重,在插值时对已知点的值进行加权平均。
反距离加权插值法对于局部数据的变化敏感,对离插值点较近的点给予较大的权重,因此适用于局部变化较为明显的情况。
然而,反距离加权法没有考虑空间相关性,容易受到离群点的影响。
3. 最近邻插值法最近邻插值法是一种简单而快速的插值方法。
其基本思想是在已知点中找到最近的邻居点,将其值作为未知点的值。
最近邻插值法适用于空间数据较为离散、空间相关性较小的情况。
然而,最近邻插值法无法提供流畅的表面,结果可能是一个由离散点组成的表面。
4. 样条插值法样条插值法是一种平滑而连续的插值方法。
其基本思想是通过插值节点处的多项式函数来逼近已知点的形态。
样条插值法能够提供流畅的表面,并在插值点周围具有较高的精度。
但样条插值法对于大规模数据的计算较为复杂,且对插值节点选取较为敏感,需要合适的节点密度来平衡平滑性与精度。
综上所述,不同的GIS空间数据插值方法具有各自的优势和劣势。
Kriging插值法在保持空间一致性和稳定性方面具有优势,但计算复杂度较高;反距离加权法适用于局部变化较为明显的情况,但容易受到离群点的影响;最近邻插值法简单而快速,适用于空间数据较为离散的情况,但无法提供流畅的表面;样条插值法能够提供流畅的表面,具有较高的精度,但计算复杂度较高,对插值节点选取敏感。

基于反距离加权法和克里金法的土壤养分空间插值方法土壤养分是农业生产中的关键指标之一,对于合理施肥和优化农田管理具有重要意义。
而准确估计土壤养分的分布则是实现精准农业的基础。
基于反距离加权法和克里金法的土壤养分空间插值方法是一种常用的空间插值方法,可以有效预测土壤养分的空间分布。
反距离加权法是一种基于距离的插值方法。
该方法假设一个样点的值受其周围样点的影响程度与距离的倒数成正比。
换句话说,距离越近的样点对目标样点的影响越大。
因此,反距离加权法通过计算目标样点与附近样点之间的距离和权重,来对目标样点的值进行估计。
这种方法简单直观,适用于光滑变量的插值。
克里金法是一种基于地统计学原理的插值方法。
它利用样点的空间相关性对目标样点的值进行估计。
克里金法考虑了空间上的相关性,即假设距离越近的样点对目标样点的影响越大,同时还考虑了样点之间的方向相关性。
通过建立样点之间的半变函数模型,克里金法可以通过插值预测目标样点的值,并给出预测误差的估计。
基于反距离加权法和克里金法的土壤养分空间插值方法结合了两种方法的优势,能够更准确地估计土壤养分的空间分布。
首先,反距离加权法可以捕捉近邻样点对目标样点的影响,对小尺度的土壤养分变化有很好的表达能力。
其次,克里金法考虑了样点之间的空间相关性,并能利用方向相关性提高估计精度,对大尺度的土壤养分分布具有很好的预测能力。
在实际应用中,基于反距离加权法和克里金法的土壤养分空间插值方法需要先收集一定数量的土壤样本数据,并测量样点的养分含量。
然后,根据样点之间的空间关系和养分含量,建立适当的数学模型。
最后,利用模型对未知区域的土壤养分进行插值预测。
同时,为了评估插值结果的准确性,可以使用交叉验证等方法进行验证。
总而言之,基于反距离加权法和克里金法的土壤养分空间插值方法是一种有效的预测土壤养分空间分布的技术。
将这两种方法结合在一起,能够充分利用样点的空间相关性和距离信息,提高土壤养分的预测精度,为农田管理和施肥决策提供科学依据。

一、空间数据的插值用各种方法采集的空间数据往往是按用户自己的要求获取的采样观测值,亦既数据集合是由感兴趣的区 域内的随机点或规则网点上的观测值组成的。
但有时用户却需要获取未观测点上的数据,而已观测点上的数 据的空间分布使我们有可能从已知点的数据推算岀未知点的数据值。
在已观测点的区域内估算未观测点的数据的过程称为内插;在已观测点的区域外估算未观测点的数据的 过程称为外推。
空间数据的内插和外推在 GIS 中使用十分普遍。
一般情况下,空间位置越靠近的点越有可能获得与 实际值相似的数据,而空间位置越远的点则获得与实际值相似的数据的可能性越小。
下面介绍一些常用的内 插方法。
1、边界内插使用边界内插法时,首先要假定任何重要的变化都发生在区域的边界上,边界内的变化则是均匀的、同质的。
边界内插的方法之一是泰森多边形法。
泰森多边形法的基本原理是,未知点的最佳值由最邻近的观测值产生。
如图4-6-1所示。
泰森多边形的生成算法见§ 5.7。
2、趋势面分析趋势面分析是一种多项式回归分析技术。
多项式回归的基本思想是用多项式表示线或面,按最小二乘法原理对数据点进行拟合, 拟合时假定数据点的空间坐标 X 、Y 为独立变量,而表示特征值的Z 坐标为因变 量。
当数据为一维时,可用回归线近似表示为:-其中,Sb 、a i 为多项式的系数。
当n 个采样点方差和为最小时,则认为线性回归方程与被拟合曲线达工(N -乳〕之-min到了最佳配准,如图4-6-2左图所示,即: 一当数据以更为复杂的方式变化时,如图 4-6-2右图所示。
在这种情况下,需要用到二次或高次多项式:在GIS 中,数据往往是二维的,在这种情况下,需要用到二元二次或高次多项式:£ 二 % + a x X + a^X(二次曲线)7 1= +O,JV 2 +a 4J¥y4多项式的次数并非越高越好,超过 3次的多元多项式往往会导致奇异解,因此,通常使用二次多项 式。

空间曲线插值
空间曲线插值是指通过一系列已知的空间点,推导出两个或多个点之间的中间位置,从而形成一条平滑的曲线。
这种插值方法广泛应用于计算机图形学、计算机辅助设计以及三维动画等领域。
在空间曲线插值中,常用的方法包括线性插值、贝塞尔曲线插值和样条曲线插值。
1. 线性插值:线性插值是最简单的插值方法,它假设两个点之间的曲线段为一条直线。
通过计算两个点之间的距离和方向,可以得到中间点的位置。
线性插值适用于需要简单粗暴的连接两个点的情况,但不能提供更复杂的曲线形状。
2. 贝塞尔曲线插值:贝塞尔曲线插值是通过控制点来定义曲线形状的一种方法。
贝塞尔曲线可以通过调整控制点的位置和权重来改变曲线的形状。
常见的贝塞尔曲线包括二次贝塞尔曲线和三次贝塞尔曲线,它们分别由2个和3个控制点定义。
贝塞尔曲线插值可以提供更加自由和灵活的曲线形状。
3. 样条曲线插值:样条曲线插值是一种基于局部控制的插值方法,它通过一系列的支撑点和控制点来定义曲线。
样条曲线可以保持平滑,并且可以通过调整控制点的位置来改变曲线的形状。
常见的样条曲线包括B样条曲线和NURBS曲线。
样条曲线插值适用于需要精确控制曲线形状的情况,例如在计算机辅助设计中绘制曲线路径。
总之,空间曲线插值是一种通过已知点推导出中间点位置的方法,可以通过线性插值、贝塞尔曲线插值和样条曲线插值等方法实现。
选
择合适的插值方法取决于需要的曲线形状和应用场景。


空间插值方法1.反距离权重插值:通过与样本点距离大小赋予权重,距离近的样本点被赋予较大的权重,受该样本点的影响越大,同时可以限制插值点的个数、范围,通过幂值来决定样本点对插值点的影响程度,灵活性大,准确性高,但不太适用规则排列的插值点2.克里金插值:克里金插值与IDW插值的区别在于权重的选择,IDW仅仅将距离的倒数作为权重,而克里金考虑到了空间相关性的问题。
它首先将每两个点进行配对,这样就能产生一个自变量为两点之间距离的函数。
使用克里金插值需确定半变异函数的类型、步长、步数。
对于这种方法,原始的输入点可能会发生变化。
在数据点多时,结果更加可靠。
该插值方法对规则排列、较密集的点插值较适用,而离散的插值点则需进行多次调试才可达到较为理想的效果3.自然邻域插值:原理是构建voronoi多边形,也就是泰森多边形。
首先将所有的空间点构建成voronoi多边形,然后将待求点也构建一个voronoi多边形,这样就与圆多边形有很多相交的地方,根据每一块的面积按比例设置权重,这样就能够求得待求点的值了。
该方法不是通过数据模型来进行插值,不需要设置多于的参数,简便但不灵活,不适合离散点进行插值,因为会形成不规则插值边界,但插值结果相对符合实际数值、准确,适合规则排列、较密集的点插值。
4.样条函数插值:这种方法使用样条函数来对空间点进行插值,它有两个基本条件:1.表面必须完全通过样本点2.表面的二阶曲率是最小的。
插值主要受插值类型(Regularized 或Tension)和weight值的影响,一般Regularize 插值结果比Tension插值结果光滑,在Regularized Spline 插值中,weight 值越高生成的表面越光滑,Tension Spline 插值则相反;适合那些空间连续变化且光滑的表面的生成。
该方法虽可生成平滑的插值结果,但其结果会在原有样点值进行数值延伸,产生于实际不符的结果,不建议一般插值使用。
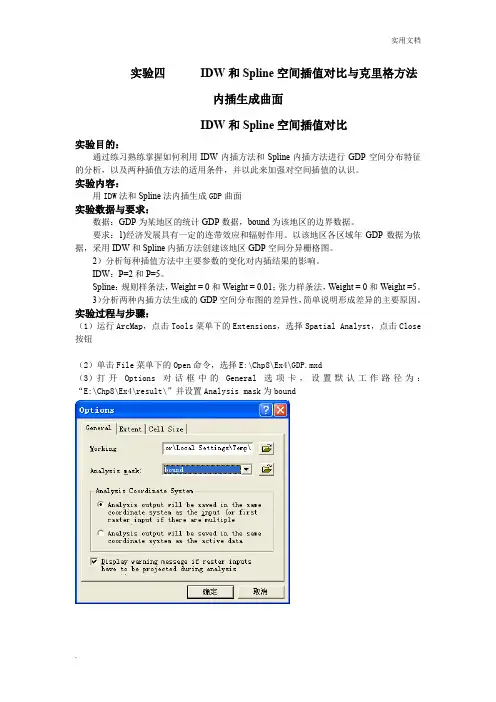
实验四IDW和Spline空间插值对比与克里格方法内插生成曲面IDW和Spline空间插值对比实验目的:通过练习熟练掌握如何利用IDW内插方法和Spline内插方法进行GDP空间分布特征的分析,以及两种插值方法的适用条件,并以此来加强对空间插值的认识。
实验内容:用IDW法和Spline法内插生成GDP曲面实验数据与要求:数据:GDP为某地区的统计GDP数据,bound为该地区的边界数据。
要求:1)经济发展具有一定的连带效应和辐射作用。
以该地区各区域年GDP数据为依据,采用IDW和Spline内插方法创建该地区GDP空间分异栅格图。
2)分析每种插值方法中主要参数的变化对内插结果的影响。
IDW:P=2和P=5。
Spline:规则样条法,Weight = 0和Weight = 0.01;张力样条法,Weight = 0和Weight =5。
3)分析两种内插方法生成的GDP空间分布图的差异性,简单说明形成差异的主要原因。
实验过程与步骤:(1)运行ArcMap,点击Tools菜单下的Extensions,选择Spatial Analyst,点击Close 按钮(2)单击File菜单下的Open命令,选择E:\Chp8\Ex4\GDP.mxd(3)打开Options对话框中的General选项卡,设置默认工作路径为:“E:\Chp8\Ex4\result\”并设置Analysis mask为bound(4)在Spatial Analyst下拉菜单中选择Interpolate to Raster, 在弹出的下一级菜单中点击Inverse Distance Weighted,弹出如下图所示的对话框,设置Z value field为GDP;设置Power为2;设置Output cell size为500;其他参数不变,点击OK,进行计算Power=2时,生成的结果将Power值改为5,重复上述步骤。
下图为Power=5时,生成的结果(5)在Spatial Analyst下拉菜单中选择Raster Calculator,求Abs((Power=2)—(Power=5))2、Spline内插法(1)在Spatial Analyst下拉菜单中选择Interpolate to Raster, 在弹出的下一级菜单中点击Spline。

两种空间插值方法的比较研究摘要:距离倒数加权法算法简单,容易实现,适合分布较均匀的采样点集,但容易出现“牛眼”现象;克里金法是一种无偏最优估计法,精度较高,适合空间自相关程度高的数据,但其算法复杂,实现较难。
这两种方法各有其适用情形,本文比较了这两种方法的优劣并提出算法优化的思路。
关键字:距离倒数加权,克里金,优化1引言空间插值是根据一组已知的离散数据或分区数据,按照某种假设推求出其他未知点或未知区域的数据的过程,简单的说就是由已知空间特性推求未知空间特性。
它是地学研究中的基本问题,也是GIS 数据处理的重要内容。
在利用GIS 处理空间数据的过程中,需要进行空间插值的场合很多,如采样密度不够、采样分布不合理、采样存在空白区、等值线的自动绘制、数字高程模型的建立、区域边界分析、曲线光滑处理、空间趋势预测、采样结果的2.5维可视化等[1]。
通过归纳,空间插值可以简化为以下三种情形:(1)现有离散曲面的分辨率、像元大小或方向与所要求的不符,需要重新插值。
例如将一个扫描影像(航空像片、遥感影像)从一种分辨率或方向转换为另一种分辨率或方向的影像。
(2)现有连续曲面的数据模型与所需的数据模型不符,需要重新插值。
如将一个连续曲面从一种空间切分方式变为另一种空间切分方式,从TIN 到栅格、栅格到TIN 或矢量多边形到栅格。
(3)现有数据不能完全覆盖所要求的区域范围,需要插值。
如将离散的采样点数据内插为连续的数据表面[2]。
现有的空间插值方法多种多样,但每一种方法都有其适用情形和无法避免的缺陷,本文分析了距离倒数加权法和克里金法的插值结果,并提出改进的思路。
2方法距离倒数加权法和克里金法都是建立在地理学第一定律之上的,即:空间距离越近,地理事物的相似性越大[3]。
它们都是通过确定待插点周围采样点的权重来求取待插点的估计值,可统一表示。
设n x x ,,1 为区域上的一系列观测点,)(,),(1n x Z x Z 为相应的观测值。
空间内插方法比较一、本文概述空间内插方法是一种在地理信息系统(GIS)和遥感技术中广泛使用的技术,用于根据已知的数据点推测未知区域的值。
这种方法在环境科学、气象学、城市规划、资源管理等众多领域都有着重要的应用。
本文旨在探讨和比较几种常见的空间内插方法,包括反距离权重法(IDW)、克里金插值法(Kriging)、自然邻点插值法(Natural Neighbors)以及多项式插值法等。
我们将首先简要介绍这些空间内插方法的基本原理和实施步骤,然后通过一个具体的案例或数据集来比较它们的性能。
我们将评估插值结果的精度、平滑度以及在不同应用场景下的适用性。
我们还将讨论这些方法的优缺点,以便读者能够根据自己的需求选择合适的空间内插方法。
通过本文的阅读,读者将对空间内插方法有更加深入的理解,能够掌握其基本原理和实施步骤,了解不同方法之间的差异和优缺点,并能够在实践中选择合适的空间内插方法。
二、空间内插方法概述空间内插是一种重要的地理信息系统(GIS)技术,用于估算在已知数据点之间或之外的未知地理位置的值。
它是通过分析和理解空间数据的分布模式,使用数学算法来预测和模拟这些模式在空间上的变化。
这种技术广泛应用于各种领域,包括环境科学、气象学、地质学、城市规划等。
空间内插方法大致可以分为两类:确定性方法和统计性方法。
确定性方法,如反距离权重法(IDW)、样条函数法(Spline)等,主要基于空间数据的物理特性和已知点之间的空间关系进行插值。
这类方法通常假设空间数据具有某种连续性和平滑性,通过最小化插值误差或最大化平滑度来得到预测值。
统计性方法,如克里金插值(Kriging)、协方差法等,则更多地依赖于对空间数据分布模式的统计分析和理解。
这类方法认为空间数据不仅具有空间相关性,而且可能存在某种潜在的随机性。
因此,它们通过构建和拟合空间统计模型,如变异函数或协方差函数,来估算未知位置的值。
每种空间内插方法都有其独特的优缺点和适用范围。
地理信息系统中不同空间插值方法的比较研究修思玉,吕泓辰,康世伦,周晓晴,吕名昊,王维芳*( 东北林业大学 林学院,哈尔滨 150040)摘 要: 对黑龙江省 2010 年 32 个气象站点的年降雨量数据分别利用距离倒数插值、样条插值和克里格插值等方法进 行插值,得到不同方法下黑龙江省范围内的降雨量空间分布数据。
对不同方法得到的插值结果进行对比分析,采用平均误 差、平均绝对误差、平均相对误差、平均绝对相对误差、系统误差等指标进行优度检验,比较各个插值方法的优劣性。
结 果表明,样条插值所得到降雨量的最大值与最小值与原始降雨量数据最为接近,反距离插值所得到的降雨量的最大值与最 小值与原始降雨量数据相差最大。
各种插值结果没有显著的差异,样条插值相对于其他两种插值方法误差较小,并且简单 易行。
关键词: 距离倒数插值; 样条插值; 克里格插值; 降雨量 中图分类号: S 771文献标识码: A文章编号: 1001 - 005X (2014) 05 - 0110 - 04C o mp a r a t i v e Study onD i ff e r e n t S p a t i a l I n t e r p o l a t i o n M e t h o d s in G I SXiu Siyu ,Lv H o n g ch e n ,K an g Sh il un ,Zh o u X i a oq i n g ,L v M i n g ha o ,Wan g W e i fan g *( Sch o o l of F o restry ,N o rtheast F o rest ry U niv ers ity ,H arbin 150040)Ab s tr ac t : I n th i s paper ,t he annua l rainfall d ata of 32 mete o r o l og i ca l s i tes of the H e il o n g ji an g pr o v i nce in 2010 were i nterp o l ated by us i n g d i fferent methods suc h as i nverse d i stance i nterp o l at i o n ,sp li ne i nterp o l at i o n ,and K r i g i n g i nterp o l at i o n m ethod ,and the spa - t ial d i st r i but i o n of rainfall w as o bta i ned . The i nterp o l at i o n res u l ts by d i ff erent methods were compared in terms of the average err o r , m ean abs o l ute error ,m ean re l at i ve error ,m ean abs o l ute re l at i ve error ,and s ystemat i c err o r . The adv antages and d i s adv anta g es o f these i nterp o l at i o n m ethods were o bta i ned . The res u l ts showed that the max i m um and m i n i m um va l ues of rainfall o bta i ned by the spline i nterp o l at i o n method were the c l o s est to the o r i g i na l rainfall data ; however the d i fferenc es of the rainfall's m ax i mum and m i n i mum v a l - ues to the o r i g i na l va l ues by the i nv ers e d i stance i nterp o l at i o n were the b i g g est in t he rainf all data . T here were no s i g n i f i c ant differences among var i o us i nterp o l at i o n res u l t s . Com pared w i th other two methods of i nterp o l at i o n ,the error of the spline i nterp o l at i o n was sm a l - ler ,eas y ,and feas i b l e .K e yw o r d s : i nv ers e d i stance i nterp o l at i o n ; s pline i nterp o l at i o n ;K r i g i n g i nterp o l at i o n ,prec i p i tat i o n降雨量是水资源的重要组成部分,研究降雨量 的空间分布特征和规律,对于发展高效农业、特色农业和农牧业产业结构调整有很好的指导作用[1], 但因气象站点稀少,难以得到区域的整体数据。
空间插值模型的评价与对比空间插值是地理信息科学中重要的研究领域,它通过利用已知的空间数据点来估计未知位置的值。
空间插值模型的评价与对比对于提高空间数据的精确性和可靠性至关重要。
本文将探讨空间插值模型的评价方法,并对比常用的插值算法。
一、评价空间插值模型的指标1. 精度指标精度是评价插值模型的重要指标之一。
常用的精度指标包括均方根误差(RMSE)、平均绝对误差(MAE)和平均百分比误差(MAPE)。
RMSE衡量了观测值与插值值之间的差异,值越小表示模型精度越高;MAE计算了观测值与插值值的绝对差异的平均值,同样,值越小表示模型精度越高;MAPE则用百分比表示了观测值与插值值的误差程度,同样,值越小表示模型精度越高。
2. 空间自相关指标空间自相关指标可以反映插值结果的空间分布特征。
其中,Moran's I和Geary's C是常用的空间自相关指标。
Moran's I衡量了观测值与其邻近观测值之间的空间相关性,值介于-1和1之间,其中正值表示正相关,负值表示负相关;Geary's C则衡量了观测值与其邻近观测值之间的差异,值越接近1表示空间自相关性越强。
二、常用的插值算法对比1. 克里金插值法克里金插值法是一种基于统计学原理的插值方法,它通过对已知数据点的空间关系进行分析,建立空间变异模型,从而对未知位置进行估计。
克里金插值法具有较好的精度和稳定性,但对于大规模数据集计算较为耗时。
2. 反距离加权插值法反距离加权插值法是一种简单而常用的插值方法,它假设未知位置的值与其邻近已知点的距离成反比。
该方法简单易懂,计算速度较快,但对于稀疏数据集和局部变异性较大的情况下,插值结果可能较差。
3. 全局插值法全局插值法是一种基于全局模型的插值方法,如径向基函数插值(RBF)和普通克里金插值。
全局插值法通过对整个数据集进行拟合,建立全局模型来估计未知位置的值。
这种方法适用于数据集较为均匀的情况,但对于大规模数据集计算较为耗时。
克里金法和高斯过程回归模型是地统计学和空间统计学中常用的两种空间插值方法。
它们在空间数据分析和地理信息系统中有着广泛的应用,对地球科学、环境科学、农业科学等领域的研究和应用具有重要意义。
本文将对克里金法和高斯过程回归模型进行比较,分析它们的优缺点和适用范围,以期能够更好地指导实际的应用和研究。
1. 简介克里金法和高斯过程回归模型都是空间插值方法,它们的目的都是通过已知的点数据对未知的位置进行推断。
克里金法起源于法国地质学家D.克里金(M. G. Kriging)于20世纪50年代提出,并在地质学、矿产勘探和地球物理学等领域得到了广泛的应用。
高斯过程回归模型则源自于统计学中的高斯过程,近年来在机器学习和空间统计学中备受关注。
2. 理论原理2.1 克里金法克里金法是一种基于空间相关性的插值方法,它的核心思想是通过已知点的空间协方差函数来推断未知位置的值。
在克里金法中,常用的协方差函数包括指数函数、高斯函数、球状模型等,它们描述了不同点之间的空间相关性。
通过对已知数据的半变异函数进行拟合,可以得到最优的插值预测值。
2.2 高斯过程回归模型高斯过程是一种随机过程,它可以被看作是无限维高斯分布的一种推广。
在高斯过程回归模型中,假设需要插值的数据服从多元高斯分布,并且通过已知数据的条件概率来推断未知位置的值。
高斯过程回归模型不仅可以进行点估计,还可以给出估计的不确定性,这使得它成为一种强大的空间插值方法。
3. 应用范围3.1 克里金法克里金法适用于点数据或区域数据的插值,常用于地质勘探、地球物理勘探、污染物扩散分析等领域。
在实际应用中,克里金法对数据的空间相关性要求较高,需要根据实际情况选择合适的协方差函数。
3.2 高斯过程回归模型高斯过程回归模型在空间数据分析和机器学习中有广泛的应用,尤其对于大样本、高维度的数据具有优势。
高斯过程回归模型还可以用于空间预测和空间优化设计等领域,被认为是一种强大的空间统计模型。
插值算法(一):各种插值方法比较整体拟合利用现有的所有已知点来估算未知点的值。
局部插值使用已知点的样本来估算位置点的值。
确定性插值方法不提供预测值的误差检验。
随机性插值方法则用估计变异提供预测误差的评价。
对于某个数据已知的点,精确插值法在该点位置的估算值与该点已知值相同。
也就是,精确插值所生成的面通过所有控制点,而非精确插值或叫做近似插值,估算的点值与该点已知值不同。
1、反距离加权法(Inverse Distance Weighted)反距离加权法是一种常用而简单的空间插值方法,IDW是基于“地理第一定律”的基本假设:即两个物体相似性随他们见的距离增大而减少。
它以插值点与样本点间的距离为权重进行加权平均,离插值点越近的样本赋予的权重越大,此种方法简单易行,直观并且效率高,在已知点分布均匀的情况下插值效果好,插值结果在用于插值数据的最大值和最小值之间,但缺点是易受极值的影响。
2、样条插值法(Spline)样条插值是使用一种数学函数,对一些限定的点值,通过控制估计方差,利用一些特征节点,用多项式拟合的方法来产生平滑的插值曲线。
这种方法适用于逐渐变化的曲面,如温度、高程、地下水位高度或污染浓度等。
该方法优点是易操作,计算量不大,缺点是难以对误差进行估计,采样点稀少时效果不好。
样条插值法又分为•张力样条插值法(Spline with Tension)•规则样条插值法(Regularized Spline)•薄板样条插值法 (Thin-Plate Splin)3、克里金法(Kriging)克里金方法最早是由法国地理学家Matheron和南非矿山工程师Krige提出的,用于矿山勘探。
这种方法认为在空间连续变化的属性是非常不规则的,用简单的平滑函数进行模拟将出现误差,用随机表面函数给予描述会比较恰当。
(克里金中包括几个因子:变化图模型、漂移类型和矿块效应)克里金方法的关键在于权重系数的确定,该方法在插值过程中根据某种优化准则函数来动态地决定变量的数值,从而使内插函数处于最佳状态。
两种空间插值方法的比较研究摘要:距离倒数加权法算法简单,容易实现,适合分布较均匀的采样点集,但容易出现“牛眼”现象;克里金法是一种无偏最优估计法,精度较高,适合空间自相关程度高的数据,但其算法复杂,实现较难。
这两种方法各有其适用情形,本文比较了这两种方法的优劣并提出算法优化的思路。
关键字:距离倒数加权,克里金,优化1引言空间插值是根据一组已知的离散数据或分区数据,按照某种假设推求出其他未知点或未知区域的数据的过程,简单的说就是由已知空间特性推求未知空间特性。
它是地学研究中的基本问题,也是GIS 数据处理的重要内容。
在利用GIS 处理空间数据的过程中,需要进行空间插值的场合很多,如采样密度不够、采样分布不合理、采样存在空白区、等值线的自动绘制、数字高程模型的建立、区域边界分析、曲线光滑处理、空间趋势预测、采样结果的2.5维可视化等[1]。
通过归纳,空间插值可以简化为以下三种情形:(1)现有离散曲面的分辨率、像元大小或方向与所要求的不符,需要重新插值。
例如将一个扫描影像(航空像片、遥感影像)从一种分辨率或方向转换为另一种分辨率或方向的影像。
(2)现有连续曲面的数据模型与所需的数据模型不符,需要重新插值。
如将一个连续曲面从一种空间切分方式变为另一种空间切分方式,从TIN 到栅格、栅格到TIN 或矢量多边形到栅格。
(3)现有数据不能完全覆盖所要求的区域范围,需要插值。
如将离散的采样点数据内插为连续的数据表面[2]。
现有的空间插值方法多种多样,但每一种方法都有其适用情形和无法避免的缺陷,本文分析了距离倒数加权法和克里金法的插值结果,并提出改进的思路。
2方法距离倒数加权法和克里金法都是建立在地理学第一定律之上的,即:空间距离越近,地理事物的相似性越大[3]。
它们都是通过确定待插点周围采样点的权重来求取待插点的估计值,可统一表示。
设n x x ,,1 为区域上的一系列观测点,)(,),(1n x Z x Z 为相应的观测值。
待插点0x 处的值)(0x Z 可采用一个线性组合来估计:∑==ni i i x Z x Z 10)()(λ (1)但距离倒数加权法只考虑采样点与待插点之间的距离,而克里金法不仅考虑距离,还要考虑采样点的空间分布及其与待插点的空间方位关系[4]。
2.1距离倒数加权法距离倒数加权权重i λ的赋值表达式为[][]0;,,2,1),(),(100>==∑=--αλααm i x x d x x d m i i i i (2)式中,幂指数α越小,权重越趋向取平均值;α越大,越近的点权重越大,越远的点权重越小[5]。
当α为零时,就是等权模型,即m i /1=λ,等权虽然简单易操作,但忽略了地理学第一定律。
有的文献[6]采用下列方案确定权值i λ[]⎩⎨⎧==else x x d x x d x x d x x d n i i ,0),(),...,,(),,(min ),(,121λ (3)它相当于待插点取最邻近点的值,即泰森多边形法(最近邻点插值法)。
2.2克里金法地质统计学是以区域化变量为基础,借助变异函数,研究既具有随机性又具有结构性,或空间相关性和依赖性的自然现象的一门科学[4]。
克里金插值法是地质统计学的重要组成部分,也是地质统计学的核心。
2.2.1区域化变量能用空间分布来表征一个自然现象的变量称为区域化变量,它反映了区域内的某种特征或现象。
区域化变量根据区域内位置的不同而取不同的值,可以说,它是与位置有关的随机变量。
在进行采样观测以后,可以将其表示为一个空间点函数),,()(w v u x x x Z x Z = (4)式中, w v u x x x ,, 为三维直角坐标系中的三轴。
区域化变量具有以下几个特性:随机性:区域化变量是一个随机变量,它具有局部的、随机的、异常的特征;结构性:区域化变量在一定范围内具有某种程度的相似性,即自相关性,当超出这一范围时,自相关性消失;空间局限性:即这种结构性的表现被限定在一定的空间内;连续性:不同的区域化变量具有不同程度的连续性,其连续性是有变异函数来表示的;异向性:区域化变量可能表现为各向同性,也可能表现为各向异性[4,7]。
2.2.2平稳假设克里金插值法是一种无偏最优估计法[8],其中,无偏是指偏差为0,即要服从二阶平稳或本证假设。
1.二阶平稳当区域化变量)(x Z 满足下列两个条件时,称其为二阶平稳或弱平稳,在整个研究区内有)(x Z 的数学期望存在,且等于常数,即:m h x Z E x Z E =+=)]([)]([ (5)在整个研究区内,)(x Z 的协方差函数存在且平稳,即只依赖于滞后h ,而与x 无关:)()]()([)]([)]([)]()([)}(),({2h C m h x Z x Z E h x Z E x Z E h x Z x Z E h x Z x Z Cov =-+=+-+=+ (6)特殊的,当0=h 时,上式变为)0()]([C x Z Var =,即方差存在且为常数。
2.本征假设是比二阶平稳更弱的平稳假设,当区域化变量)(x Z 的增量)()(h x Z x Z +-满足下列两条件时,称其为满足本征假设或内蕴假设。
在整个研究区内有0)]()([=+-h x Z x Z E (7)增量)()(h x Z x Z +-的方差函数存在且平稳(即不依赖于x ):)(2),(2)]()([)]}()([{)]()([)]()([222h h x h x Z x Z E h x Z x Z E h x Z x Z E h x Z x Z Var γγ==+-=+--+-=+- (8)2.2.3变异函数变异函数是地统计学特有的基本工具,它既能描述区域化变量的空间结构性变化,又能描述其随机性变化。
区域化变量)(x Z 在点x 和h x +处的值)(x Z 与)(h x Z +差的方差的一半称为区域化变量)(x Z 的变异函数,记为),(h x γ。
在二阶平稳假设或本征假设的条件下,有222)]()([21)]}([)([{)]()([21)]()([21),(h x Z x Z E h x Z E x Z E h x Z x Z E h x Z x Z Var h x +-=+--+-=+-=γ (9) 由上式可知,变异函数依赖于自变量x 和h ,当变异函数),(h x γ仅仅依赖于距离h 而与位置x 无关时,),(h x γ可改写为)(h γ,即2)]()([21)(h x Z x Z E h +-=γ (10) 具体表示为∑=+-=)(12)]()([)(21)(h N i i i h x Z x Z h N h γ (11) 在变异函数中有四个参数,它们的定义如下。
变程(range ):指区域化变量在空间上具有相关性的范围。
在变程范围之内,数据具有相关性;而在变程之外,数据之间互不相关,即在变程以外的观测值不对估计结果产生影响。
块金值(nugget):变异函数如果在原点间断,在地质统计学中称为“块金效应”,表现为在很短的距离内有较大的空间变异性,无论h 多小,两个随机变量都不相关。
测量误差与自然现象的微观变异性任意一方或两者共同作用产生了块金值。
基台值(sill):代表变量在空间上的总变异性大小。
即为变差函数在h 大于变程时的值,为块金值和拱高之和。
拱高(partial sill):基台值与块金值之差。
当块金值等于0时,基台值即为拱高。
当变异函数确定之后,执行克里金系统就只是一个简单的计算过程。
变异函数的理论模型主要有以下三个[9,10]。
球状模型()⎪⎪⎩⎪⎪⎨⎧≥≤⎥⎥⎦⎤⎢⎢⎣⎡⎪⎭⎫ ⎝⎛-⋅==⎪⎭⎫ ⎝⎛⋅=ah c a h a h a h c h a h Sph c h ,,2123003γ (12) 指数模型 ()⎥⎦⎤⎢⎣⎡⎪⎭⎫ ⎝⎛--⋅=⎪⎭⎫ ⎝⎛⋅=a h c a h Exp c h 3exp 1γ (13) 高斯模型 ()()⎥⎥⎦⎤⎢⎢⎣⎡⎪⎪⎭⎫ ⎝⎛--⋅=223ex p 1a h c h γ (14) 式中,c 为基台值,a 为变程,h 为滞后距变异函数的形式是内插质量的关键,需要注意的是,由于不同的区域有不同的空间模式,因而也就有不同的变异函数,而空间内插都有一个隐含的假定,即空间是连续的,因此,在选择变异函数模型之前,检查数据以确定空间连续性是十分必要的[11]。
2.2.4普通克里金依据本征假设和无偏性要求,有∑==n i i 11λ(15)在以上的条件下要达到估计方差最小[10],即()()()()()(){}[]()()()[]min 200*200*00*2=-=---=x Z x Z E x Z x Z E x Z x Z E k σ (16)再应用拉格朗日乘数法求极值,进一步推导可得()()()⎪⎪⎩⎪⎪⎨⎧==-=--∑∑==n i i j ni i j i n j x x C x x C 1011,,1λμλ (17)最小的估计方差,即克里金方差可用以下公式求解 ()()∑=--+-=-=n i i i k x x C x x C x Z x Z Var 100000*2)]()([λμσ (18)或()()00102x x x x ni i i k --+-=∑=γμγλσ (19) 3实验3.1实验数据福建地处我国东南部,山地、丘陵占陆域的80%,属温暖湿润的亚热带海洋性季风气候[12],其地形复杂,降雨丰富,本文选取福建省为空间插值的实验区,收集该省67个气象站点的历史数据,以2005年12月月平均降水为试验指标,进行内插分析比较研究。
3.2距离倒数加权法应用ArcGIS9.2 Geostatistcal Analyst 功能模块进行插值,搜索半径取1.2,幂指数取2, 从CrossValidation 的统计来看,最大误差高达-200.667774109(武夷山),最小误差只有-1.14440513614(龙海),出现这一结果的原因是在武夷山站周围气象观测站点分布较稀疏,可选点较少;而在龙海站周围的分布较均匀,可选点较多。
在结果图中“牛眼”现象比较明显的是九仙山站(269)(见图1),与它相邻的站点分别是永春站(120)、大田站(182)、尤溪站(182)、永泰站(124),产生这一现象的原因是距离倒数加权法在站点数据较少时容易受采样极值点的影响,会在网络区域产生围绕采样点位置的“靶心”,即所谓的“牛眼”现象[13]。
图1 距离倒数加权法,九仙山站及其周围四县市的插值结果图3.3克里金法在克里金精度评价系统中,符合下列标准的结果是最优的:标准平均值(Mean Standardized)最接近于0,均方根预测误差(Root-Mean-Square)最小,平均标准误差(Average Mean Error)最接近于均方根预测误差(Root-Mean-Square),标准均方根预测误差(Root-Mean-Square Standardized)最接近于1[4]。