sas卡方检验编程语句
- 格式:ppt
- 大小:750.50 KB
- 文档页数:30


卡方检验是用途很广的一种假设检验方法,它在分类资料统计推断中的应用,包括:两个率或两个构成比比较的卡方检验;多个率或多个构成比比较的卡方检验以及分类资料的相关分析等。
卡方检验基本思想在分类资料统计分析中我们常会遇到这样的资料,如两组大白鼠在不同致癌剂作用下的发癌率如下表,问两组发癌率有无差别?处理发癌数未发癌数合计发癌率%甲组52197173.24乙组3934292.86合计912211380.33 52 19 39 3 是表中最基本的数据,因此上表资料又被称之为四格表资料。
卡方检验的统计量是卡方值,它是每个格子实际频数A与理论频数T 差值平方与理论频数之比的累计和。
每个格子中的理论频数T是在假定两组的发癌率相等(均等于两组合计的发癌率)的情况下计算出来的,如第一行第一列的理论频数为71*91/113=57.18,故卡方值越大,说明实际频数与理论频数的差别越明显,两组发癌率不同的可能性越大。
利用统计学软件分析结果如下:data kafang; input row column number @@; cards; 1 1 52 1 2 19 2 1 39 2 2 3 ; run; proc freq; tables row*column/chisq; weight number; run;统计量自由度值概率卡方16.47770.0109(有统计学意义)似然比卡方17.31010.0069连续校正卡方15.28680.0215Mantel-Haenszel 卡方16.42030.0113Phi 系数-0.2394列联系数0.2328Cramer 的V-0.2394二联表的卡方检验方法假设有两个分类变量X和Y,它们的值域分另为{x1, x2}和{y1, y2},其样本频数列联表为:y1y2总计x1aba+bx2cdc+d总计a+cb+da+b+c+d 若要推断的论述为H1:“X与Y有关系”,可以利用独立性检验来考察两个变量是否有关系,并且能较精确地给出这种判断的可靠程度。

sas中freq的用法-回复在SAS中,`FREQ`是一个非常常用的过程,用于生成频率和交叉表。
它可以帮助数据分析师更好地理解数据并发现其中的模式和趋势。
本文将一步一步介绍`FREQ`过程的用法,并提供一个示例来说明其在数据分析中的重要性。
1. 首先,我们需要了解`FREQ`语句的基本结构。
一般而言,`FREQ`语句由以下三部分组成:`TABLES`子句、`/`符号和`OUT`子句。
`TABLES`子句用于指定要生成频率和交叉表的变量,`/`符号用于分隔`TABLES`子句和`OUT`子句,`OUT`子句用于指定输出结果的数据集和变量名。
2. 接下来,我们需要选择要生成频率和交叉表的变量。
在`TABLES`子句中,可以同时指定多个变量,用逗号分隔。
可以选择数值变量或字符变量,甚至可以组合使用两者。
例如,`TABLES var1 var2;`将生成变量`var1`和`var2`的频率和交叉表。
3. 在`TABLES`子句中,还可以使用一些选项来进一步定制输出结果。
例如,`TABLES var1 / NOPRINT MISSING;`将在输出中不显示缺失值。
这对于有效地处理缺失数据非常有用。
4. 当`FREQ`过程运行完毕后,可以使用`OUT`子句来指定输出结果的数据集名称和变量名。
例如,`OUT = outputdata;`将结果存储在名为`outputdata`的数据集中。
这样,我们可以在进一步分析时使用这些结果。
5. 另外,`FREQ`过程还可以生成卡方检验、精确检验和倾向分数。
这些统计指标可以帮助我们判断样本数据是否符合理论分布,并进行统计推断。
现在,让我们通过一个具体的示例来进一步说明`FREQ`过程的用法。
假设我们有一个数据集包含了学生的性别(gender)和考试成绩(score)两个变量。
我们希望通过`FREQ`过程来分析性别和考试成绩之间的关系。
首先,我们需要指定要生成频率和交叉表的变量。

卡方检验 python卡方检验,又称卡方分析,是一种统计检验,它可以用来检验:一组数据是否符合某个给定分布,以及两组数据之间是否存在某种统计学上的差异。
python语言是当今处于飞速发展的编程语言,它在统计分析领域受到许多研究者和企业家的青睐。
本文将详细介绍如何使用python进行卡方检验。
1.方检验的原理卡方检验的基本原理是,通过比较一组实际数据与一组理论数据的不一致情况,从而判断实际数据是否符合预定的统计分布。
卡方检验可以用于两种应用场景:一是检验一组数据是否符合某个给定分布;另一是检验两组数据之间是否存在某种统计学上的差异。
2. python进行卡方检验的方法(1)首先,准备好检验的两组数据,一组是实际数据,一组是理论数据。
(2)其次,在python中使用scipy.stats模块中的函数,如scipy.stats.chi2_contingency函数进行卡方检验,该函数的参数包括实际数据和理论数据。
(3)最后,通过比较函数返回的p-value与拟定的显著水平来判断实际数据是否符合预定的统计分布,也可以判断两组数据之间是否存在某种统计学上的差异。
3. python进行卡方检验的具体步骤(1)第一步,准备实际数据和理论数据。
实际数据是根据观察到的实际情况所记录的;理论数据是根据分析预设的模型,或者更一般而言,根据一般性的理论而预测出的结果。
(2)第二步,使用python中的scipy.stats模块,特别是chi2_contingency()函数,实现卡方检验。
该函数的参数包括:实际数据,理论数据以及指定的显著性水平。
(3)第三步,通过函数返回的p-value与显著性水平比较,判断实际数据是否符合预定的统计分布,也可以判断两组数据之间是否存在某种统计学上的差异。
结束语本文详细介绍了如何使用python进行卡方检验,从而实现统计数据的检验,从而对实际的观测数据进行验证和分析研究。
可以看出,python语言可以节省许多时间,并且可以提供更加深入的分析,这些都是其他语言难以企及的。

卡方检验是一种常用的假设检验方法,用于比较两个或更多变量之间的关系。
以下是卡方检验的一般写法:1. 假设:- H0:两个变量之间没有显著关系。
- H1:两个变量之间存在显著关系。
2. 计算卡方值:- 根据样本数据计算卡方值(X^2),使用下面的公式:X^2 = Σ (O - E)^2 / E其中,O表示观测频数,E表示期望频数。
3. 查找卡方分布表:- 根据自由度和显著性水平查找卡方分布表,找到对应的临界值。
4. 比较卡方值和临界值:- 如果卡方值大于临界值,则拒绝原假设,接受备择假设,即认为两个变量之间存在显著关系。
- 如果卡方值小于等于临界值,则无法拒绝原假设,认为两个变量之间没有显著关系。
当进行卡方检验时,需要按照以下步骤进行详细的操作:1. 假设设定:- 首先,明确原假设(H0)和备择假设(H1)。
原假设通常表明两个变量之间没有显著关系,备择假设则认为两个变量之间存在显著关系。
2. 构建观测频数表:- 将数据整理成一个观测频数表,以便计算期望频数。
表格包含两个或更多行和列,用于记录不同变量的观测频数。
3. 计算期望频数:- 根据观测频数表,计算期望频数(E)。
期望频数是在原假设下,根据总体比例计算出的预期值。
计算期望频数的方法取决于具体的卡方检验类型。
4. 计算卡方值:- 使用观测频数和期望频数,按照公式X^2 = Σ (O - E)^2 / E,计算卡方值(X^2)。
这个公式计算了观测频数与期望频数之间的差异,并将其标准化。
5. 确定自由度:- 自由度(df)是指可以自由变动的独立数据值的数量。
在卡方检验中,自由度的计算方法取决于观测频数表的大小和特征。
6. 查找临界值:- 根据所选择的显著性水平(通常为0.05),查找卡方分布表以确定对应的临界值。
临界值是在给定自由度下的临界点,用于判断卡方值是否显著。
7. 比较卡方值和临界值:- 将计算得到的卡方值与临界值进行比较。
如果卡方值大于临界值,则拒绝原假设,认为两个变量之间存在显著关系。
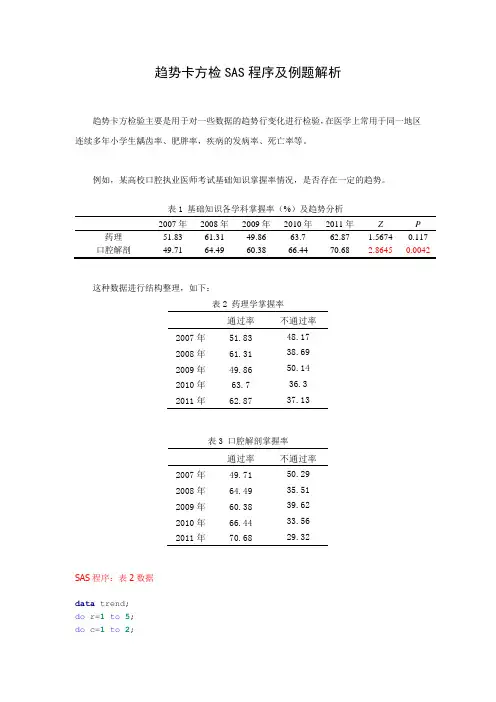
趋势卡方检SAS程序及例题解析趋势卡方检验主要是用于对一些数据的趋势行变化进行检验,在医学上常用于同一地区连续多年小学生龋齿率、肥胖率,疾病的发病率、死亡率等。
例如,某高校口腔执业医师考试基础知识掌握率情况,是否存在一定的趋势。
表1基础知识各学科掌握率(%)及趋势分析2007年2008年2009年2010年2011年Z P 药理51.83 61.31 49.86 63.7 62.87 1.5674 0.117 口腔解剖49.71 64.49 60.38 66.44 70.68 2.8645 0.0042这种数据进行结构整理,如下:表2 药理学掌握率通过率不通过率2007年51.83 48.172008年61.31 38.692009年49.86 50.142010年63.7 36.32011年62.87 37.13通过率不通过率2007年49.71 50.292008年64.49 35.512009年60.38 39.622010年66.44 33.562011年70.68 29.32SAS程序:表2数据data trend;do r=1to5;do c=1to2;input f@@;output;end;end;cards;51.83 48.1761.31 38.6949.86 50.1463.7 36.362.87 37.13;proc freq;weight f;tables r*c /trend nocol norow nopct(这三项可以不选择); run;表3结果FREQ 过程r * c 表r c频数| 1| 2| 合计--------+--------+--------+1 | 49.71 | 50.29 | 100--------+--------+--------+2 | 64.49 | 35.51 | 100--------+--------+--------+3 | 60.38 | 39.62 | 100--------+--------+--------+4 | 66.44 | 33.56 | 100--------+--------+--------+5 | 70.68 | 29.32 | 100--------+--------+--------+合计311.7 188.3 500r * c 表的统计量Cochran-Armitage 趋势检验-------------------统计量(Z) 2.8645 单侧Pr> Z 0.0021 双侧Pr>|Z| 0.0042样本大小= 500。

单样本的t检验配对t检验Data a;Input x1 x2@@;d=x1-x2;datalines;输入数据;run;proc ttest;var d;run;两组计量资料的t检验data a;do g=1 to 2;input x@@;output;end;datalines;输入数据;proc ttest;class g;var x;run;配伍设计的方差分析(随机区组设计)data a;do g=1 to 4;(g为处理因素横着的指标)do j=1 to 5;(j为区组个数竖着的指标)input x@@;output;end;end;datalines;输入数据;run;proc anova;class g j;model x=g j;means g/snk;(means为多组比较比较处理因素的作用,注意指标用处理因素的数量)run;完全随机设计的多组资料方差分析data a;do g=1 to 3;(g 为不同的处理水平)input x@@;output;end;datalines;输入数据;proc anova;class g;model x=g;means g/snk;(两两组多重比较)means g/hovtest;(方差齐性检验)run;四格表资料卡方检验data a;input r c f@@;(r c代表行和列,f代表中间的频数值)datalines;1 1 a (注意数据的输入格式)1 2 b2 1 c2 2 drun;proc freq;(计数资料全都用这个)weigjht f;table r*c/chisq expected;(chisq为卡方检验 expected为输出理论频数关联性分析时用agree)run;配对计四格表卡方检验data a;input r c f@@;datalines;1 1 a1 2 b2 1 c2 2 drun;proc freq;weight f;table r*c/chisq agree; (配对四格表用agree)run;多个样本率/多组r*c表卡方检验都一样的只是输入数据时在继续加上3 1 e3 2 f4 1 r4 2 t (等等的都是这样输下去) 两两比较proc freq;weight f;table r*c/chisq;where r in(1,2); (两两比较的方法把括号里的组数换了就好)构成比比较(注意都是手工编秩次)和上面的都一样,注意数据的输入(需要手工编组的,卡方检验和组数不同的)两两比较是也是在程序后面加where 和比较组号配对设计秩和检验data a;input x1 x2@@;d=x1-x2;datalines;输入数据;proc univariate normal mu0=0;(这个很特殊好好记住)var d;run;单样本的秩和检验和配对的秩和检验一样的,只是d=x-题中给出的中位数等值data a;input x@@;d=x-2.5;datalines;输入数据;proc univariate normal mu0=0;var d; run;两组计量资料的秩和检验两组人数相同的可以用do g=1 to 2 那种自动编组两组人数不同的要手工编组data a;input g x@@;datalines;1 a 1 b 1 c 1 d 1 e2 r 2 t 2 y 2 urun;proc apnr1way data=a wilcoxon;class g;var x;run;多组计量资料的秩和检验和两个组的都一样只是输入数据时手工多一个组或自动输入两组等级资料的秩和检验data a;do g=1 to 2;(g为不同观察组别有几个组就是几 g是非等级的)do x=1 to 4(x表示分了几个等级)input f@@;(f表示中间的频数值);output;end;end;datalines;直接输入中间那部分数据就好;proc npar1way data=a wilcoxon;class g;(分组情况)var x;(要分析的等级情况 x代表分了几个等级)freq f;(f为频数)run;多组等级资料的秩和检验data a;do x=1to4;(x代表有几个等级)do g=1to3;(g代表有几个组)input f@@;output;end;end;datalines;双向有序的等级资料相关分析。




为区分过程名称的拼写,故意部分小写,以便识别和记忆。
基本SAS程序代码结构:---------PROC MODE data=Arndata.moddat; /* 命令的解释*/var yx1-x6; /* 命令的解释 */model y = x1-x6;run;------------------------------------------正态性检验PROC UNIvariate---------PROC UNIvariate data=Arndata.unidat;var x1;run;------------------------------------------相关分析和回归分析PROC REG 回归---------PROC REG data=Arndata.regdat;var y x1-x6;model y = x1-x6 / selection=stepwise; /* 加入逐步回归选项 */printcli;/* 加入输出预测结果部分,还可以输出acov,all,cli,clm,collin,collinoint,cookd,corrb,covb,dw(时序检验统计量),i,influence,p,partial,pcorr1,pcorr2,r,scorr1,scorr2,seqb,spec,ss1,ss2,stb,tol,vif(异方差检验统计量),xpx*/plot y*x2 /conf95; /* 做散点图 */run;---------------------------------------------------DATA Arndata.regdat;x2x2 = x2*x2;x1x2 = x1*x2;PROC REG data=Arndata.regdat;var y x1 x2 x2x2x1x2 ; /* 多项式回归,非线性回归 */model y = x1 x2 x2x2 x1x2 / selection=stepwise; /* 加入逐步回归选项 */print cli;plot y*x2 /conf95; /* 做散点图 */run;------------------------------------------PROC RSreg 二次响应面回归PROC ORTHOreg 病态数据回归PROC NLIN 非线性回归PROC TRANSreg 变换回归PROC CALIS 线性结构方程和路径分析PROC GLM 一般线性模型PROC GENmod 广义线性模型方差分析PROC ANOVA 单因素均衡数据和非均衡数据---------PROC ANOVA data=Arndata.anovadat; /* 命令的解释 */classtyp; / * 命令的解释 */model y =typ; /* 可以看出此处是单因素方差分析(分类型自变量对数值型自变量的影响) */run;------------------------------------------PROC GLM 多因素非均衡数据:---------PROC GLM data=Arndata.glmdat; /* 命令的解释*/class typeatypeb; /* 命令的解释 */model y = typeatypeb; /* 可以看出此处是不考虑交互作用的多因素方差分析(分类型自变量对数值型自变量的影响) */run;---------------------------------------------------PROC GLM data=Arndata.glmdat; /* 命令的解释*/class typeatypeb; /* 命令的解释 */model y = typea typebtypea*typeb; /* 可以看出此处是考虑交互作用的多因素方差分析(分类型自变量对数值型自变量的影响) */run;------------------------------------------主成分分析PROC PRINcomp---------PROC PRINcomp data=Arndata.pmdat n=4 out=w1outstat=w2 ;varx1-x6;PROC print data=w1;PROC plot data=w1vpct=80;/* 一句话,其实print就是plot输出图形的文字形式而已 */plot prin1*prin2 $ districts='*'/haxis=-3.5 to 3 by 0.5 HREF=-2,0,2vaxis=-3 to 4.5 by 1.5HREF=-2,0,2; /* 主成分的散点图,也就是载荷图 */run;------------------------------------------因子分析PROC FACTOR---------PROC FACTOR data=Arndata.factordat simplecorr ;var yx1-x6;title'18个财务指标的分析';title2'主成分解';run;PROC FACTOR data=Arndata.factordatn=4 ; /* 选择4个公共因子 */var y x1-x6;run;PROC FACTOR data=Arndata.factordat n=4rotate=VARImaxREorder;/* 因子旋转:方差最大因子法 */var y x1-x6;run;------------------------------------------PROC SCORE---------PROC FACTOR data=Arndata.factordat n=4rotate=VARImax REorder score out=score_Out; /* 输出因子得分矩阵 */run;PROC print data=score_Out;var districts factor1 factor2 factor3 factor4;run;PROC plot data=score_Out;plot factor1*factor2 $ districts='*' / href=0 Vref=0; /* 因子的散点图,也就是载荷图 */run;------------------------------------------典型相关分析PROC CANcorr基本SAS程序代码结构:---------DATAjt(TYPE=CORR);/* TYPE=CORR 表明数据类型为相关矩阵,而不是原始数据, type还可以是cov,ucov,factor,sscp,ucorr等*/input names$ 1-2(x1 x2 y1-y3)(6.); /* name $ 表示读取左侧的变量名,1-2表示变量名的字符落在第1,2列上 */cards;x1 1 0.8 ……x2 ……y1 ……y2 ……y3 ……;PROC CANcorr data=Arndata.cancorrdatedf=70redundancy; /* 误差自由度的参考值,默认值是n=1000; redundancy表示输出冗余度分析的结果*/var x1 x2;with y1 y2 y3;run;------------------------------------------对应分析 /* 交叉表分析的拓展,寻找行和列的关系,一般行指代各种cases,而列代表各种visions */PROC CORResp---------PROC CORResp data=Arndata.correspdatout=result;varx1-x6;id Type;run;options ps=40;proc plot data=result;plot dim2*dim1="*" $ Type / boxhaxis=-0.2 to 0.3 by 0.1Vaxis=-0.1 to 0.3 by 0.1Href=0 Vref=0;run;------------------------------------------聚类分析PROC CLUSTER---------PROC CLUSTER data=Arndata.clusdatmethod=ave outtree=clusdat_Out;var x1-x6;id datid;run;proc tree horizontal; /* 做聚类树*/run;------------------------------------------PROC FASTclus---------PROC FASTclus data=Arndata.clusdatmaxclusters=3 list out=clusdat_Out;var x1-x6;id datid;run;------------------------------------------PROC ACEclusPROC VARCLUS---------PROC VARclus data=Arndata.clusdat; /* 系统默认使用主成分法聚类 */var x1-x6;run;---------PROC VARclus hierarchy data=Arndata.clusdat; /* 保证分析过程中不同水平的谱系结构 */var x1-x6;run;---------PROC VARclus centroid data=Arndata.clusdatouttree=clusdat_out; /* 使用重心法聚类 */var x1-x6;run;------------------------------------------PROC TREE---------PROC TREE data=Arndata.clusdat horizontal; /* 使用TREE过程绘制聚类谱系图 */var x1-x6;run;------------------------------------------判别分析PROC DISCRIM---------PROC DISCRIM data=Arndata.discrimdatlistout=discrimdat_Out distance pool=yes;class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */id iddiscrim; /* 标注样本的变量 */run;---------第二种方法,将需要判别的新样本放在testdata里:---------PROC DISCRIM data=Arndata.discrimdat1testdata=Arndata.discrimdat2testlisttestout=discrimdat_Out; /* 将原来的几个选项加注test标示*/class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */id iddiscrim; /* 标注样本的变量 */run;------------------------------------------PROC STEPdisc:逐步判别分析过程---------PROC STEPdisc method=stepwise data=Arndata.discrimdatSLentry=0.10 SLstay=0.10; /* 设定引入和剔除的显著性水平 */class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */run;------------------------------------------PROC CANdisc:Fisher判别分析过程---------PROC CANdisc data=Arndata.discrimdat out=discrimdat_Outdistance simple;class Typ; /* 指定分类变量 */var x1-x6; /* 用于建立判别识别函数的变量 */run;proc print data=discrimdat_Out;run;------------------------------------------。
常用sas语句总结第一篇:常用sas语句总结Engine(引擎)是一种访问架构,SAS系统通过它迅速地对其它数据库管理系统中文件进行读入和写出。
1.LIBNAME语句1.1解读定义 SAS 逻辑库。
具体地说,它可以(1)向 SAS 标识 SAS 逻辑库(2)将引擎与逻辑库关联(3)让您指定逻辑库的选项(4)为逻辑库指定逻辑库引用名通俗得讲,LIBNAME语句把一个libref(库标记名)和一个目录联系起来,使用户可以在SAS语句中使用库标记来指示这个目录。
提交该程序时自动引用该 SAS 逻辑库 1.2 语句格式1、LIBNAME libref ;2、LIBNAME libref Clear;3、LIBNAME libref |_ All_ List;三种格式反映了LIBNAME语句的三种用法选项说明LibrefEngineSas-Data-LibraryAccess=Readonly|TempClear_All_List规定逻辑库规定引擎规定主机系统下一个有效的物理地址规定逻辑库为只读或可修改属性清除与库标记的联系列出所有逻辑库的属性在Log窗口列出逻辑库的属性。
2.length语句SAS变量的基本类型有两种:数值型和字符型。
数值型变量在数据集中的存贮一般使用8个字节。
SAS的字符型变量缺省的长度是8个英文字符,可以使用LENGTH语句指定变量长度,LENGTH语句一般应出现在定义变量的Input语句之前,格式为: LENGTH 字符型变量名 $长度例如:length name $20 ;3.input 语句3.1解读INPUT语句用于向系统表明如何读入每一条记录。
它的主要功能有:读入由语句指定的数据列;为相应的数据域定义变量名;确定变量的读入模式(共有四种模式:column模式,formatted模式,list 模式及named模式)。
input语句执行后,SAS将读取的数据暂时先保存在内存缓冲区,然后执行后面的语句,后面的语句可以对暂存在内存缓冲区中的变量值进行修改,到最后才将整条数据写入数据集,写入数据集的数据就不能在当前data步中再修改。
卡方检验python卡方检验是统计学中常用的检验方法之一,它可以判断实际观测数据和理论分布的差异是否是由于偶然出现的假设概率而导致的。
它可以用于区分各个群体之间的差异,观察观测值和理论值之间的耦合程度,以及检验数据的完整性和拟合性。
在统计学中,使用卡方检验的目的是检验所选定的样本是否来自特定的分布。
此检验可以应用于特定统计模型,查看样本是否符合从模型来分布的数据可能性。
Python是一种实用性强、易于上手的高级编程语言,用来分析数据和解决实际问题。
这里我们将介绍如何使用Python来进行卡方检验。
首先需要安装Python,可以使用Python的多种发行版本,比如Anaconda,PyCharm,或者在命令行下使用Python。
其次,使用Python进行卡方检验,需要以下模块:NumPy(用于处理数组)和Scipy(用于计算卡方统计)。
接下来,使用Python检验数据时,需要先准备观测数据和理论分布,或者实际观测和经过模拟的理论分布。
将这些数据输入Python 程序,用NumPy和Scipy模块计算卡方统计量,以及相应的自由度。
最后,使用计算的卡方统计量和自由度,通过Python的 Scipy 计算卡方检验的P值,来判断观测数据和理论分布具有多大差异,以及它们之间的相关程度。
从上述示例可以看出,使用Python进行卡方检验是一个简单有效的过程,不仅可以节约大量时间,而且还可以在节省成本的情况下,以合理的方式来检验数据的完整性和拟合性。
卡方检验提供了一种有效的方法来验证样本分布是否满足从模型得到的理论分布,同时它也提供了一种简单易行的过程来检验数据的完整性和拟合性,从而更好地控制假设概率,准确地评估统计模型和数据的准确性。
此外,使用Python进行卡方检验的简便性,将帮助更多的统计专业人士快速准确地进行检验,帮助他们获得有用的结果。