SAS EG数据统计分析题库
- 格式:doc
- 大小:43.00 KB
- 文档页数:12

sas测试题及答案1. SAS中,如何将一个数据集的所有变量的值增加10?A. data dataset; set dataset; +10; run;B. data dataset; set dataset; +10; quit;C. data dataset; set dataset; +10; run;D. data dataset; set dataset; +10;答案:C2. 在SAS中,如何创建一个新的数据集,并将原数据集中的变量`Var1`和`Var2`复制到新数据集中?A. data new_dataset; set old_dataset; Var1 =old_dataset.Var1; Var2 = old_dataset.Var2; run;B. data new_dataset; set old_dataset; Var1 = Var1; Var2 = Var2; run;C. data new_dataset / old_dataset; set old_dataset; Var1 = old_dataset.Var1; Var2 = old_dataset.Var2; run;D. data new_dataset; set old_dataset; Var1 = Var1; Var2 = Var2; quit;答案:A3. SAS中,如何使用`proc print`步骤打印数据集的前10行?A. proc print data=dataset firstobs=10;B. proc print data=dataset firstobs=1 obs=10;C. proc print data=dataset firstobs=10;D. proc print data=dataset firstobs=1 obs=10;答案:B4. 在SAS中,如何使用`if-then`语句来创建一个新的变量`NewVar`,当`Var1`大于10时,`NewVar`的值为`Var1`的两倍,否则为0?A. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; else NewVar = 0; run;B. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; NewVar = 0; run;C. data dataset; set dataset; if Var1 > 10 NewVar = 2 *Var1; else NewVar = 0; run;D. data dataset; set dataset; if Var1 > 10 then NewVar = 2 * Var1; else NewVar = 0; quit;答案:A5. SAS中,如何使用`proc means`步骤计算数据集中`Var1`的平均值?A. proc means data=dataset N mean of Var1;B. proc means data=dataset N mean Var1;C. proc means data=dataset N=mean Var1;D. proc means data=dataset N mean Var1;答案:D结束语:以上是SAS测试题及答案,希望能够帮助您更好地理解和掌握SAS编程的基础知识。

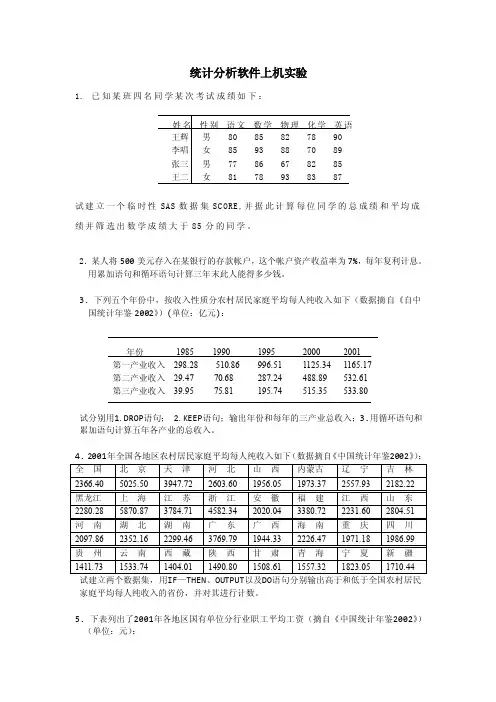
统计分析软件上机实验1. 已知某班四名同学某次考试成绩如下:姓名性别语文数学物理化学英语王辉男 80 85 82 78 90李唱女 85 93 88 70 89张三男 77 86 67 82 85王二女 81 78 93 83 87试建立一个临时性SAS数据集SC ORE,并据此计算每位同学的总成绩和平均成绩并筛选出数学成绩大于85分的同学。
2.某人将500美元存入在某银行的存款帐户,这个帐户资产收益率为7%,每年复利计息。
用累加语句和循环语句计算三年末此人能得多少钱。
3. 下列五个年份中,按收入性质分农村居民家庭平均每人纯收入如下(数据摘自《自中国统计年鉴2002》)(单位:亿元):年份1985 1990 1995 2000 2001第一产业收入298.28510.86996.511125.341165.17第二产业收入29.4770.68287.24488.89532.61第三产业收入39.9575.81195.74515.35533.80试分别用1.DROP语句; 2.KEEP语句;输出年份和每年的三产业总收入;3.用循环语句和累加语句计算五年各产业的总收入。
家庭平均每人纯收入的省份,并对其进行计数。
5. 下表列出了2001年各地区国有单位分行业职工平均工资(摘自《中国统计年鉴2002》)(单位:元):用DELETE语句输出年平均工资达到10000元的地区。
6. 表1、表2分别给出了我国农业和工业部分主要产品产量居世界位次(摘自《中国统计年鉴2002》):表1:7.下面是从1954-1998年我国的人均GDP,试根据所给出的数据计算这期间人均GDP的平均值、标准差、标准误差、变异系数、偏度和峰度。
年份 1954 1955 1956 1957 1958 1959 1960 1961 1962 1963 1964 1965 1966 1967 1968GDP 144 150 165 168 200 216 218 185 173 181 208 240 254 235 222年份 1969 1970 1971 1972 1973 1974 1975 1976 1977 1978 1979 1980 1981 1982 1983GDP 243 275 288 292 309 310 327 316 339 379 417 460 489 525 580年份 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998GDP 692 853 956 1104 1355 1512 1634 1879 2287 2939 3923 4854 5576 6053 63928.根据《我国各地区的支出法国内生产总值表》(摘自《中国统计年鉴2002》):地区国内生产总值(亿元)最终消费资本形成总额货物和服务净出口北京2845.651467.711775.3-397.36天津1840.1901.85934.48 3.77河北5577.782509.32511.57556.91山西1787.761046.43800.27-58.94内蒙古1545.326789936.1894062614.137383-5辽宁5033.082828.091625.5579.49吉林2087.871331.32790.99-34.44黑龙江3515.699822110.541130.53982274.62上海4950.842149.072294.46507.31江苏9403.34295.964239.17868.17浙江6749.183306.12891.02552.06安徽3290.1304142108.094751185.49566-3.46福建4218.312225.231939.6153.47江西2161.751357.47800.83 3.45山东9438.314582.614513.32342.38河南5640.113114.132329.32196.66湖北4557.022408.841963.46184.72湖南39832553.141426.47 3.39广东10647.715841.323860.81945.58广西2231.191597.05769.04-134.9海南546.62299.86254.79-8.03重庆1769.771078.06819.08-127.37四川4421.762691.471726.33 3.96贵州1084.9833.87599.95-348.92云南2074.711430.44929.73-285.46西藏138.3182.7949.72 5.8陕西1844.271004.5972.51-132.74甘肃1081.51674.42444.89-37.8青海294.83197.79207.39-110.35宁夏298.38223.52207.69-132.83新疆1485.48854.6771.42-140.54用PROC语句,(1)按国内生产总值排序;(2)对已创建的数据集进行转置;(3)对数据集的各变量求和;(4)计算各项经济指标平均值、标准差、标准差系数、偏度、峰度、置信区间并显示最大值与最小值。
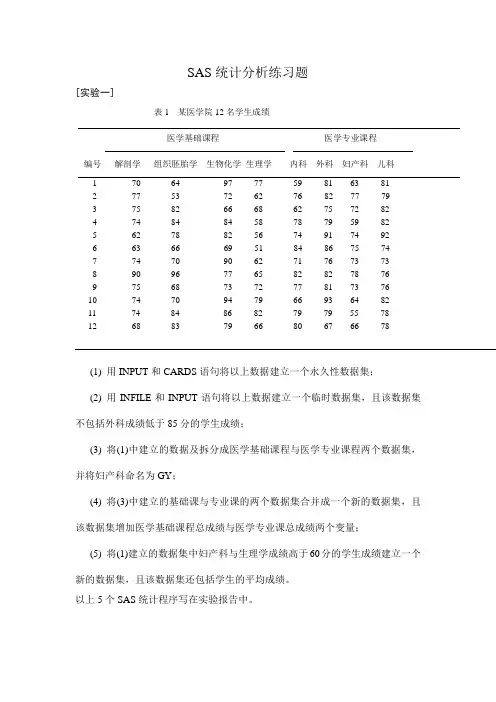
SAS统计分析练习题[实验一]表1 某医学院12名学生成绩医学基础课程医学专业课程编号解剖学组织胚胎学生物化学生理学内科外科妇产科儿科1 70 64 97 77 59 81 63 812 77 53 72 62 76 82 77 793 75 82 66 68 62 75 72 824 74 84 84 58 78 79 59 825 62 78 82 56 74 91 74 926 63 66 69 51 84 86 75 747 74 70 90 62 71 76 73 738 90 96 77 65 82 82 78 769 75 68 73 72 77 81 73 7610 74 70 94 79 66 93 64 8211 74 84 86 82 79 79 55 7812 68 83 79 66 80 67 66 78(1) 用INPUT和CARDS语句将以上数据建立一个永久性数据集;(2) 用INFILE和INPUT语句将以上数据建立一个临时数据集,且该数据集不包括外科成绩低于85分的学生成绩;(3) 将(1)中建立的数据及拆分成医学基础课程与医学专业课程两个数据集,并将妇产科命名为GY;(4) 将(3)中建立的基础课与专业课的两个数据集合并成一个新的数据集,且该数据集增加医学基础课程总成绩与医学专业课总成绩两个变量;(5) 将(1)建立的数据集中妇产科与生理学成绩高于60分的学生成绩建立一个新的数据集,且该数据集还包括学生的平均成绩。
以上5个SAS统计程序写在实验报告中。
[实验二]1. 某年某市120名12岁健康男孩身高资料如表2-1。
表2-1 某年某市120名12岁健康男孩身高(cm)测量资料142.3 156.6 142.7 145.7 138.2 141.6 142.5 130.5 132.1 135.5134.5 148.8 134.4 148.8 137.9 151.3 140.8 149.8 143.6 149.0145.2 141.8 146.8 135.1 150.3 133.1 142.7 143.9 142.4 139.6151.1 144.0 145.4 146.2 143.3 156.3 141.9 140.7 145.9 144.4141.2 141.5 148.8 140.1 150.6 139.5 146.4 143.8 150.0 142.1143.5 139.2 144.7 139.3 141.9 147.8 140.5 138.9 148.9 142.4134.7 147.3 138.1 140.2 137.4 145.1 145.8 147.9 146.7 143.4150.8 144.5 137.1 147.1 142.9 134.9 143.6 142.3 143.3 140.2125.9 132.7 152.9 147.9 141.8 141.4 140.9 141.4 146.7 138.7160.9 154.2 137.9 139.9 149.7 147.5 136.9 148.1 144.0 137.4134.7 138.5 138.9 137.7 138.5 139.6 143.5 142.9 146.5 145.4129.4 142.5 141.2 148.9 154.0 147.7 152.3 146.6 139.2 139.9要求:(1)编写SAS程序编制数据的频数表,绘制直方图。

spss统计分析期末考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,数据视图和变量视图分别对应于:A. 变量列表和数据表B. 数据表和变量列表C. 数据集和变量集D. 变量集和数据集答案:B2. SPSS中用于描述数据分布特征的统计量不包括:A. 平均值B. 中位数C. 众数D. 方差答案:D3. 在SPSS中进行独立样本T检验时,需要满足的假设条件不包括:A. 独立性B. 正态性C. 方差齐性D. 线性答案:D4. 下列哪个选项不是SPSS中的数据类型?A. 数值型B. 字符串型C. 日期型D. 图片型答案:D5. 在SPSS中,进行相关分析时,通常使用的统计方法是:A. 回归分析B. 方差分析C. 卡方检验D. 皮尔逊相关系数答案:D6. SPSS中,用于创建新变量的命令是:A. COMPUTEB. DESCRIPTIVESC. T-TESTD. FREQUENCIES答案:A7. 在SPSS中,执行因子分析时,通常使用的方法是:A. 主成分分析B. 聚类分析C. 回归分析D. 判别分析答案:A8. SPSS中,用于检验两个分类变量之间关系的统计方法是:A. 相关分析B. 回归分析C. 卡方检验D. 方差分析答案:C9. 在SPSS中,进行多变量回归分析时,需要满足的假设条件不包括:A. 线性关系B. 误差项独立C. 误差项同方差性D. 变量之间独立答案:D10. SPSS中,用于创建数据集的命令是:A. GET FILEB. SAVEC. OPEN DATAD. NEW答案:D二、简答题(每题10分,共40分)1. 简述SPSS中数据清洗的常用步骤。
答案:数据清洗的常用步骤包括:数据导入、数据预览、缺失值处理、异常值检测、数据转换和数据编码。
2. 解释SPSS中因子分析的目的和基本步骤。
答案:因子分析的目的是将多个变量简化为几个不相关的因子,以揭示变量之间的内在关系。
基本步骤包括:确定因子数量、提取因子、旋转因子和因子得分计算。

SAS 统计软件知识要点与试题库1. 试述SAS系统中PGM、EDITOR、OUTPUT、EXPLORER、RESULT和LOG窗口的功能。
2. 窗口切换(移至前台并击活)可用以下任一种做法实现:(1)点击窗口本身;(2)由菜单项“窗口(W)”可切换到已打开的窗口,或由查看(View)加入新窗口;(3) Ctrl + T ab 依次切换;(4) 用设置的热键; (5) 发布命令;(6) 点击窗口条中某一窗口图标.3. 发布命令有四种方式:在命令框直接键入命令;使用下拉菜单(弹出菜单);使用工具条;按功能键(KEYS命令显示功能键所表示的命令).4. SAS数据集可以读取的数据类型:数据行直接输入、流行的数据库、其它文件格式5. SAS数据集的描述部分(创建与修改日期,引擎,变量名,类型,长度,标题,格式等)6. 字符型变量的缺失值用空格符表示数值型变量的缺失值用句号“ . ”表示7. SAS逻辑库包括临时库、永久库两种,区别?8. ViewT able窗口提供两种打开数据的方式:Browse模式和Edit模式,区别?9. SAS数据集的变量属性有6个,哪六个?(变量名及标签,类型,长度,输入输出格式).10. 在SAS系统中浏览和编辑SAS数据集一般必须先设定SAS逻辑库(文件库),然后将要浏览和编辑的数据集存放在已设定的SAS逻辑库(文件库)中.11. 多个SAS逻辑库可与同一个物理位置项连接;一个SAS逻辑库也可与多个物理位置相连接.12. 新建逻辑库(New Library)的方法:1. 按工具条上图标(New Library)可进入设定新的SAS逻辑库的N ew Library窗口;2. 资源管理器(浏览器)窗口击活时,在下拉菜单中选:文件(File) ⇒新建(New… )⇒逻辑库=>可进入设定新建逻辑库(New Library)窗口.3. 在“SAS 环境”(Environment)处击右键,在弹出的菜单中选新建(New …)=>逻辑库,也可进入新建逻辑库(New Library)窗口.13. 上机试题(1).用菜单方法建立新库(库标志名为dsta),此库包含本课程所使用的sas数据集; (2).用两种方法(菜单或命令)进入ViewT able窗口,并浏览数据集class;(3)先浏览class中SEX=…F‟的观测及AGE>=14的观测,然后浏览全部观测;(4)浏览数据集class的描述信息和数据内容;(5)浏览SAS永久库SASUSER的属性和内容,并浏览数据集AIR的描述信息和数据内容.14. 数据集名应由字母或下划线开始且不超过32个(V6为8) 个字节的字符、数字或下划线构成. 变量名,数组名,库名15. 上机(1). 用VT命令进入ViewT able窗口,直接输入数据并进行编辑修改后存为sas数据集; (2). 使用Import窗口菜单系统,将*.txt 转换为sas数据集;(3). 用数据步建立SAS数据集.16. SAS的Import/Export菜单界面提供一个使用菜单的图形界面:17. SAS语句书写的格式较为灵活:语句可以在某一行的任何位置开始和结束;词间可任意加入空格和换行;一个语句可以写成几行,只要语句中的单词不被断开就可以;多个语句可写在一行;SAS语句用大写字母、小写字母或两者混合书写均可以.18. 通常用DAT A步产生SAS数据集,而用PROC步对SAS数据集中的数据进行分析处理并输出结果. 一个SAS程序可由一个DAT A步或一个PROC步组成;或者由DAT A 步和PROC步两部分组成;也可由多个DAT A步和PROC步组成.19. SAS的字符型变量缺省的长度是8个字符,可以用LENGTH语句直接指定变量长度。


北语2024春季《SPSS统计分析与应用》
完美答案文档
介绍
本文档旨在提供北语2024春季学期《SPSS统计分析与应用》课程的完美答案。
以下是该课程的相关内容。
课程概述
《SPSS统计分析与应用》是一门针对统计软件SPSS的应用课程。
通过研究本课程,学生将掌握SPSS软件的基本操作和常用统计分析方法,以及如何应用这些方法来解决实际问题。
课程目标
- 熟练掌握SPSS软件的基本操作
- 理解常用的统计分析方法,如描述统计、t检验、方差分析等- 学会如何应用SPSS软件进行数据处理和分析
- 掌握数据可视化和报告撰写的基本技巧
课程内容
1. SPSS软件介绍和安装
2. 数据输入和清洗
3. 描述统计分析
4. t检验
5. 方差分析
6. 相关分析
7. 回归分析
8. 数据可视化和报告撰写
研究建议
- 认真听课并参与课堂讨论
- 理解每个统计分析方法的原理和应用场景
- 多进行实践操作,熟练掌握SPSS软件的使用
- 阅读相关的统计学和研究方法的教材和参考书籍- 与同学进行讨论和互助,共同解决问题
考试准备
- 复课堂讲授的知识点和案例分析
- 完成课后题和作业
- 制作复笔记和思维导图
- 参考相关的统计学教材和参考书籍
- 进行模拟考试和答题练
结语
通过研究《SPSS统计分析与应用》,你将能够灵活应用SPSS 软件进行数据处理和统计分析,为你未来的研究和工作提供有力支持。
祝你在本课程中取得优异的成绩!。

一、单项选择题:(本大题小题,1分/每小题,共分)1.SPSS的数据文件后缀名是: A(A).sav (B).dbf (C).exe (D).com2.对数据的各种统计处理,SPSS是在下面哪一个选项中进行:A(A)数据编辑窗口;(B)数据显示窗口;(C)数据输出窗口;(D)任意一个窗口均可;3.在SPSS中,下面哪一个不是SPSS的运行方式 A(A)输入运行方式;(B)完全窗口菜单方式;(C)程序运行方式;(D)混合运行方式;4.下面哪一个选项不属于SPSS的数据分析步骤:D(A)定义数据文件结构;(B)录入、修改和编辑待分析数据;(C)进行统计分析;(D)数据扩展;5.在SPSS中,下面哪一个选项不属于对变量(列)的描述:B(A)变量名称;(B)变量名称大小;(C)变量宽度;(D)变量对齐方式6.在SPSS的定义中,下面哪一个变量名的定义是错误的:C(A)ABC_C;(B)ABC;(C)A_&_A;(C)A_BFG_;7.在SPSS的定义中,下面哪一个变量名的定义是错误的:C(A)AND;(B)A_BC;(C)B_&_A;(C)A_BFG;8.在SPSS数据文件中,下面那一项不属于数据的结构: D(A)变量类型;(B)变量值说明;(C)数据缺失值情况;(D)数据值;9.在SPSS数据文件中,下面那一项属于数据的内容:D(A)变量类型;(B)变量值说明;(C)数据缺失值情况;(D)数据值;10. 通常来说,发放了900份问卷,可直接得到的有效问卷有800份,则SPSS所建立的相关数据文件中的行数为 D(A)900;(B)600;(C)820 (D)800;11.下面那一项不属于SPSS的基本变量类型:D(A)数值型;(B)字符串型;(C)日期型;(D)整数型;12.当在SPSS数据文件中输入变量为“职工姓名”,则应选择的变量类型是:B(A)数值型;(B)字符串型;(C)日期型;(D)整数型;13.当在SPSS数据文件中输入变量为“职工工资数”,则应选择的变量类型是:A(A)数值型;(B)字符串型;(C)日期型;(D)整数型;13.当在SPSS数据文件中输入变量为“公司成立日期”,则应选择的变量类型是:C(A)数值型;(B)字符串型;(C)日期型;(D)整数型;14.在SPSS的数据结构中,下面那一项不是“缺失数据”的定义:D(A)数据缺失;(B)数据不合理;(C)数据明显错误;(D)数据不是科学计数法;15.统计学依据变量的计量尺度将变量分为三类,以下哪一类不属于这三类:D(A)数值型变量;(B)定序型变量;(C)定类型变量;(D)科学计数类型;16.在统计学中,变量“身高”属于计量尺度中的:A(A)数值型变量;(B)定序型变量;(C)定类型变量;(D)科学计数类型;17.在统计学中,将变量“年龄”分为“老年”、“中年”、“青年”三个取值,分别用1、2、3表示,则变量“年龄”属于计量尺度中的:B(A)数值型变量;(B)定序型变量;(C)定类型变量;(D)科学计数类型;18.在统计学中,将变量“性别”分为“男”、“女”、两个取值,分别用1、2表示,则变量“性别”属于计量尺度中的: C(A)数值型变量;(B)定序型变量;(C)定类型变量;(D)科学计数类型;19.下面哪一个选项不能被SPSS系统正常打开:D(A)SPSS文件格式;(B)excel文件格式;(C)文本文件格式;(D)可执行文件格式;20. 下面哪一个选项不能被SPSS系统正常打开:D(A).sav;(B).xls;(C).dat;(D).exe;21.在SPSS数据编辑窗口中,需要定义变量的数据结构,以下哪一项不属于变量的数据结构:D(A)变量名;(B)变量类型;(C)变量名标签;(D)变量值;22. 在SPSS数据结构中,下面哪一项不属于数据类型:D(A)数值型;(B)字符型;(C)日期型;(D)数值标签型;23.下面哪一个选项不是SPSS中定义的基本描述统计量:D(A)均值;(B)方差;(C)标准差;(D)回归函数;24.下面哪一个选项不是SPSS中定义的基本描述统计量:D(A)样本标准差;(B)全距;(C)偏度系数;(D)因子;25.下面那一项刻画了随机变量分布形态的对称性:D(A)均值;(B)方差;(C)标准差;(D)偏度系数;26.下面那一项刻画了随机变量分布形态陡缓程度:D(A)均值;(B)方差;(C)标准差;(D)峰度系数;27.对于SPSS来说,下面那一项不包括在变量的频数分布内容中:D(A)频数;(B)百分比;(C)有效百分比;(D)均值;27.对于SPSS来说,下面那一项不包括在变量的频数分布内容中:C(A)频数;(B)百分比;(C)标准差;(D)累积百分比;28.在SPSS中,下面那一项不是频数分析中常用的统计图形:D(A)柱状图或者条状图;(B)饼图;(C)直方图;(D)分类图;29.在SPSS中,当需要对变量进行频数分析时,需要选择下面那一项菜单:C(A)视图;(B)文件;(C)分析;(D)图形;30.在进行数据的统计分析之前,一般需要完成数据的预处理,以下哪一项不属于数据的预处理内容:B(A)缺失值和异常数据的处理;(B)峰度和偏度处理;(C)数据的转换处理;(D)数据抽样;31.在SPSS中,当我需要对原有某个变量的数据进行取对数运算时,应选取下面那一项进行处理:A(A)变量计算;(B)数据排序;(C)数据选取;(D)计数;32.在SPSS中,下面那一项不属于数据分组的目的:D(A)有利于连续数据的频数分析;(B)可实现连续数据的离散化;(C)更能概括和体现出数据的分布特征;(D)有利于进行因子分析;33.对于SPSS中的组距分组,下面那一项是正确的说法:A(A)分组数与数据本身特点和数据个数有关;(B)分组的目的是为了减少数据数目;(C)通常来说,组数少点更易于进行分析;(D)组数多点有利于观察数据分布的特征和规律;34.对于SPSS来说,能够快捷找到变量数据的最大值和最小值的数据预处理方法是:A(A)排序;(B)分类汇总;(C)变量计算;(D)分组;35.对于SPSS来说,能够快捷找到变量数据的异常值的数据预处理方法是:A(A)排序;(B)分类汇总;(C)变量计算;(D)分组;36.在学生的一张数据表中,有平时分数、实验分数和卷面分数,如使用SPSS计算最终得分,则需要使用SPSS预处理中的:C(A)排序;(B)分类汇总;(C)变量计算;(D)分组;37.在SPSS中,以下哪个选项可以完成如下功能:由收集的整体数据中抽取出年龄大于30的数据:A(A)数据选取;(B)分组;(C)排序;(D)计算;38.下面哪一个选项不是对数据的基本统计分析:C(A)编制单个变量的频数分布表;(B)计算单个变量的描述统计量;(C)编制多变量的交叉频数分布表;(D)实现变量的排序与合并;39.在SPSS中,当变量是数值型时,则频数分析所用图形为:A(A)直方图;(B)饼图;(C)柱状图;(D)条形图;40.在SPSS中,当需要选取出满足某一个条件的所有个案,则使用下面的那一项:A(A)个案选择;(B)个案排序;(C)变量计算;(D)个案计数;41.在SPSS中,均值的计算适合下面那一项:A(A)定距型;(B)定类型;(C)定序型;(D)全都适合;42.现有一批数据为(0,1,2,-2,3,-3,4),则这批数据的极差为:A(A)7;(B)6;(C)3(D)4;43.以下图是某随机变量的概率密度,请问其峰度是:(A)大于零;(B)小于零;(C)等于零;(D)全错;44. 以下图是某随机变量的概率密度,请问其峰度是:(A)大于零;(B)小于零;(C)等于零;(D)全错;45.以下图是某随机变量的概率密度,请问其峰度是:C(A)大于零;(B)小于零;(C)等于零;(D)全错;46.单因素方差分析的第一步是明确观测变量和控制变量,例如,当分析不同施肥量是否对农产品产量带来显著影响、地域差别是否对妇女生育率有关系和学历对工资的作用关系时,控制变量分别是:A (A)施肥量、地域和学历;(B)施肥量、生育率和学历;(C)施肥量、地域和工资;(D) 农产品产量、地域和学历;47. 单因素方差分析的第一步是明确观测变量和控制变量,例如,当分析不同施肥量是否对农产品产量带来显著影响、地域差别是否对妇女生育率有关系和学历对工资的作用关系时,观测变量分别是:A (A)农产品产量、妇女生育率和工资;(B)施肥量、生育率和学历;(C)施肥量、地域和妇女生育率;(D)妇女生育率、地域和学历;48.当需要分析多个随机变量之间的相互影响和关系时,在SPSS中应使用下面哪一个选项:D(A)方差;(B)均值;(C)峰度;(D)交叉分组下的频数分析;49.下面那一种情况下,可以使用交叉列联表中来进行卡方分布检验: A(A)列联表单元格的全部期望频数都大于6;(B)列联表中有1个单元格内的期望频数为1;(C)列联表中有30%单元格的期望频数小于5;(D)列联表中有2个单元格内期望频数为1;50.当需要分析某一个变量的分布情况时,采用下面那一个选项较为合适:A(A)频数分析;(B)方差分析;(C)列联表分析;(D)假设检验;51.在统计分析中,描述变量的数据离散程度的基本统计量是:A(A)标准差;(B)偏度;(C)峰度;(D)中位数;52.在统计分析中,描述变量数据分布的中心位置的基本统计量是:D(A)标准差;(B)偏度;(C)峰度;(D)均值;53.在统计分析中,描述变量数据分布的对称程度的基本统计量是:B(A)标准差;(B)偏度;(C)峰度;(D)均值;54.在统计分析中,描述变量的数据分布的陡峭程度的基本统计量是:C(A)标准差;(B)偏度;(C)峰度;(D)均值;55.下面那一种说法是正确的:A(A)偏度大于零,则数据分布的长尾巴在右边;(B)偏度大于零,则数据分布的长尾巴在左边;(C)偏度大于零,则数据分布没有尾巴;(D) 偏度等于零,则数据分布的长尾巴在左边;56.下图中右下角的问号应选择: C(A)均值;(B)方差;(C)参数检验;(D)峰度57.在得到一批未知其总体分布的数据后,可使用以下哪种方法验证其是否与某个已知理论分布相吻合:C(A)计算均值;(B)计算方差;(C)参数检验;(D)非参数检验;58. 需要检验一批未知的连续数值型随机单样本是否是正态分布,则需要下面的那一项:D(A)t 检验;(B)方差检验;(C)标准差检验;(D)K-S 检验;59.已知某一分布是正态分布的随机变量x 的均值为μ,方差为2σ,则将其转换成标准正态分布(即均值为0,标准差为1)的公式是:A (A)()x μσ-;(B)2()x μσ-;(C)()x n μ-;(D)()x σμ-; 60.下面那一项不是两独立样本t 检验的前提条件:D(A)样本来自的总体应服从或近似服从正态分布;(B)两样本相互独立;(C)从一个总体抽取一个样本对从另一总体抽取样本没有任何影响;(D)两个样本的方差必须相等;61.设待检验两个总体的均值分别为1μ、2μ,则相关的两独立样本t 检验的假设0H 是:A(A)012:0H μμ-=;(B)012:0H μμ-≠;(C)012:0H μμ-≥;(D)012:0H μμ-<;62.在交叉列联表检验中,行数为6,列数为7,则当变量间独立时所对应卡方分布的自由度是:A(A)30;(B)42;(C)13;(D)1;63.在交叉列联表检验中,当变量间独立时所对应检验统计量的分布是:A(A)开方分布;(B)F 分布;(C)t 分布;(D)s 分布;64.已知两批独立随机样本都服从正态分布,要检验这两批随机样本的方差是否相同,则需要采用:A(A)F 检验;(B)t 检验;(C)S 检验;(D)Q 检验;65. .已知两批独立随机样本都服从正态分布,要检验这两批随机样本的均值是否相同,则需要采用:B(A)单样本t 检验;(B)两独立样本t 检验;(C)S 检验;(D)Q 检验;66. 已知一批独立随机样本服从正态分布,要检验这批随机样本的均值是否与某总体分布的均值相同,则需要采用: A(A)单样本t 检验;(B)两独立样本t 检验;(C)S 检验;(D)Q 检验;67.下面那一项不属于假设检验的基本步骤:B(A)提出原假设和备择检验;(B)画出随机样本的直方图;(C)选择检验统计量;(D)计算检验统计量的概率,并将其与显著性水平的大小做出统计决策;68.当样本的分布未知,需要利用样本的数据推断出总体分布形态的方法是:A(A)非参数检验;(B)参数检验;(C)方差检验;(D)因子分解;69. 在总体分布未知的情况下,利用样本数据对所假定总体的分布进行显著性检验的方法是: B(A)参数检验;(B)非参数检验;(C)方差检验;(D)回归检验;70.现有两段独立样本数据,欲判断它们之间的分布是否存在显著性差异,则可采用:B(A)参数检验;(B)非参数检验;(C)方差检验;(D)回归检验;71.单样本的总体分布卡方检验属于:C(A)参数检验,用于比较均值;(B)非参数检验,用于比较方差;(C)非参数检验,用于了解样本的分布是否与某一已知的理论分布吻合;(D)方差检验;72. 单样本K-S检验属于:C(A)参数检验,用于比较均值;(B)非参数检验,用于比较方差;(C)非参数检验,用于了解连续数值型样本的分布是否与某一已知的理论分布吻合;(D)方差检验;73.两配对样本t检验的目的是:A(A)推导出来自于两个总体的配对样本的均值是否存在显著性差异;(B)推导出来自于两个总体的独立样本的均值是否存在显著性差异;(C)推导出来自于两个总体的配对样本的分布是否存在显著性差异;(D)推导出来自于两个总体的独立样本的均值是否存在显著性差异;74.以下是使用SPSS所做的非参数检验的结果图,根据所给图选择正确的一项:A:(A)接受假设H0;(B)拒绝假设H0;(C)不好说;(D)以上都不正确;75.样本值序列为1011011010011000101010000111,则整段样本值序列的游程数是:A(A)17;(B)20;(C)10;(D)16;75.样本值序列为男男女女女男女女男男男男,则整段样本值序列的游程数是:A(A)5;(B)7;(C)10;(D)3;76.样本值序列为男男男男男男男女女女女女,则整段样本值序列的游程数是:A(A)2;(B)7;(C)10;(D)3;77. 样本值序列为男男男男男男男女女女女女,则整段样本值序列的游程数是:A(A)2;(B)7;(C)10;(D)3;78. 样本值序列为男女男女男女男女男女男男,则整段样本值序列的游程数是:C(A)10;(B)7;(C)11;(D)9;79. 样本值序列为00110111000100100010,则整段样本值序列的游程数是:C(A)10;(B)7;(C)11;(D)9;80. 样本性质下面的那一项可适用于两独立样本的曼-惠特尼U检验:A(A)样本秩;(B)样本数值;(C)均值;(D)方差;81. 样本性质下面的那一项可适用于两独立样本的K-S检验:A(A)样本秩;(B)样本数值;(C)均值;(D)方差;82.下图是某两独立样本的游程检验示意图,请问图中数据的游程数是:A(A)6;(B)8;(C)5;(D)7;83.K-S检验可用于:B(A)均值检验;(B)非参数检验;(C)参数检验;(D)方差检验;84.下面那一选项是独立样本:A(A)分别对两批不同年级的大学生调查他们的学习兴趣;(B)对同一批人,观察他们服用减肥茶前后的体重;(C)对同一批运动员,观察一种新的训练方法对他们运动成绩的影响;(D)分析同一批商品使用不同的销售手段下的销售量;85.现有一批数据:2.3, 1.2, 3.8, 6, 9,则6的秩是:C(A)3;(B)2;(C)4,(D)686.观察某新开发的饲料对猪的影响:首先不用这个饲料,测量猪在一个月的体重;再在下一个月内使用新饲料喂养同一批猪,测量体重;实验者想知道前后两个月猪的体重的分布是否有差别,则可用以下哪一项进行检验:B(A)非参数检验;(B)参数检验;(C)方差检验;(D)均值检验;87.观察某新的营销手段对商品销售量的影响:首先不用这个营销手段,测量10种商品在一个月的销售量;再在下一个月内使用该新营销手段处理同样这10种商品,测量销售量;实验者想知道这新的营销手段是否对商品的销售量有显著性区别,则可用以下哪一项进行检验(销售量的分布未知):A(A) 非参数检验中的两配对样本检验;(B) 非参数检验中的两独立样本检验;(C) 参数检验中的两配对样本检验;(D) 参数检验中的两独立样本检验;88.观察性别是否对书籍种类的购买意愿有差别:随机选择20个男同学,随机选择30个女同学,分别调查他们对书籍的购买意愿,调查者想知道性别对数据种类的购买是否有影响,则可使用(男和女同学购买数据的分布是正态分布):D(A) 非参数检验中的两配对样本检验;(B) 非参数检验中的两独立样本检验;(C) 参数检验中的两配对样本检验;(D) 参数检验中的两独立样本检验;89.在假设检验中,秩的概念主要用在下面那一项中:B(A)参数检验;(B)非参数检验;(C)方差检验;(D)均值检验;90.现有一种饲料,使用不同的数量来喂养动物,测量出不同喂养量情况下动物的体重,现欲知道动物的体重是否与不同喂养量有关,则采用下面那一项:D(A)参数检验;(B)K-S检验;(C)卡方检验;(D)方差检验;91.使用某种肥料对10块玉米田的产量进行实验,分别在每块田内使用0公斤、1公斤、2公斤、3公斤、4公斤、5公斤该肥料,再测量出每种肥料使用量和每块田的产量,当使用方差分析时,下面哪一个说法是正确的:A (A)肥料量是控制变量,每块田的产量是观测变量;(B) 每块田的产量是控制变量,肥料量是观测变量;(C)所有田的产量之和是控制变量,肥料量是观测变量;(D)所有田的肥料量之和是控制变量,产量是观测变量;92.在制定某商品广告宣传策略时,广告效果可能会受到广告形式、地区规模、选择的栏目、播放的时间段、播放的频率等因素的影响。

SPSS统计练习题及答案一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:A Insert Variable;B Insert Case;C Go to Case;D Weight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:A Sort Cases;B Select Cases;C Compute;D Categorize Variables(C)3、Transpose菜单的功能是:A 对数据进行分类汇总;B 对数据进行加权处理;C 对数据进行行列转置;D 按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别;B. 三种城市身高没有差别的可能性是0.043;C. 三种城市身高有差别的可能性是0.043;D. 说明城市不是身高的一个影响因素(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C 服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。
8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。

SPSS数据分析与应用试题及答案一、单项选择题(本大题共15小题,每小题2分,共30分)1、下列用来描述一组数据的平均水平的是 [ ]A.均值 B.标准差 C.偏度 D.峰度2、下列用来描述数据的波动程度的是 [ ]A.中位数 B.均值 C. 方差 D.偏度3、在SPSS中双定性变量适合绘制下面那种图形 [ ]A.堆积百分比图 B.箱线图C. 直方图D.散点图4、在SPSS中双定量变量适合绘制下面那种图形 [ ]A.堆积百分比图B.箱线图C. 直方图D.散点图5、在SPSS中一个定性变量、一个定量变量适合绘制下面那种图形[ ] A.堆积百分比图B.箱线图C. 直方图D.散点图6、下列属于定性变量的是[ ]A.年龄B.驾龄C.性别D.销量7、以下不属于定量变量的是 [ ]A.婚姻B.收入C.工龄D.体重8、以下哪个变量适合做线性回归的因变量[ ]A.是否购买 B.是否出险 C.是否恋爱 D.房价9、以下哪个变量适合做逻辑回归的因变量 [ ]A.客户是否流失 B.酒店价格 C.二手房价 D.以上都不正确10、因子分析的作用是 [ ]A.分类 B.降维 C.回归D.以上都不正确11、关于聚类分析,下列说法错误的是 [ ]A.聚类就是把“类似”的对象聚到一起B.聚类分析首先要确定特征指标C.聚类分析中刻画相似度方法只有欧式距离D.层次聚类法是聚类分析的一种12“物以类聚,人以群分”与下列哪个模型特征相似 [ ]A.线性回归B.逻辑回归C.聚类分析D.因子分析13、以下哪个因变量可以用线性回归模型进行分析 [ ]A.大学生薪资影响因素分析B.信用卡是否逾期C.某用户是否患胃病的预测D.明天是否降雨的预测14、线性回归模型的整体评价,不包括以下哪一项 [ ]A.F检验的结果B.调整的R方C.AUC值D.R方的大小15、关于聚类分析的要点,错误的是 [ ]A.根据不同的特征指标聚出的类是不同的B.定义什么是“相似的研究对象”C.层次聚类就是k均值聚类D.如何归类二、多项选择题(本大题共5小题,每小题4分,共20分)在每小题列出的五个备用选项中至少有两个是符合题目要求的,请将其代码填写在题后的括号内。
数据统计分析师认证考试试题姓名:______________________身份证号:_____________________________总分:100分. 单选题40分,编程题40分,论述题20一、填空(20×2分)1. 下面哪一个是永久性的SAS文件?a. Sashelp.PrdSaleb. Sasuser.MySalesc. Profits.Quarter1d. all of the above2. 在一个DATA步中,如何引用一个名为Forecast的临时SAS数据集?a. Forecast;b. Work.Forecastc. Sales.Forecastd. a与b都正确3. 下面的SAS程序中包括了多少语句?proc print data = new.prodsale labeldouble; var state day price1 price2; where state='NC';label state='Name of State'; run;a.3;b. 4;c. 5;d. 64. SAS data library是什么?a. SAS文件集合,包括SAS数据集以及目录(catalogs)b. 某些环境下,SAS文件的物理集合c. 某些环境下,SAS文件的逻辑集合d. 以上都正确5. 选择WHERE语句同时实现两个功能:[1] 指标amount不超过$5000;[2] 指标account 为101–1092或者指标rate等于0.095。
a. where amount <= 5000 and account='101-1092' or rate = 0.095;b. where (amount le 5000 and account='101-1092') or rate = 0.095;c. where amount <= 5000 and (account='101-1092' or rate eq 0.095);d. where amount <= 5000 or account='101-1092' and rate = 0.095;6. 下面那个语句能够确认将要读入的、具有引用名Products的原始数据文件,并且能够指定DATA步读入第1到15条记录?a. infile products obs 15;b. infile products obs=15;c. input products obs=15;d. input products 1-15;7. 下面那条能够实现指标Income增长100%?a. income=income*1.00;b. income=income+(income*2.00);c. income=income*2;d. income= *2;8. 下面程序在什么地方有错误?data perm.update; infile inventinput Item $ 1-13 IDnum $ 15-19 Instock 21-22BackOrd 24-25; Total = instock+backord; run;a. 第二句少了分号;b. 第二行少了分号;c. 变量顺序有误;d. 变量类型有误9. 下面哪一个语句能够将你的自定义格式存入永久目录?1. libname library 'c:\sas\formats\lib';proc format lib=library ...;2. libname library 'c:\sas\formats\lib';format lib=library ...;3. library='c:\sas\formats\lib';proc format library ...;4. library='c:\sas\formats\lib';proc library ...;10. 下面哪一个FORMA T过程书写正确?1. proc format lib=library value colorfmt; 1='Red' 2='Green' 3='Blue' run;2. proc format lib=library; value colorfmt 1='Red' 2='Green' 3='Blue'; run;3. proc format lib=library; value colorfmt; 1='Red' 2='Green' 3='Blue' run;4. proc format lib=library; value colorfmt 1='Red'; 2='Green'; 3='Blue'; run;11. 如果提交了下面语句,那么REPORT过程的结果在哪里出现?proc report data=sasuser.houses nowd;column style sqfeet bedrooms price; define style / group; run;a. REPORT专用窗口;b. OUTPUT窗口;c. a与b都正确;d. 都不正确12. 在缺省条件下,MEANS过程产生的统计量包括计算所涉及指标的观测值数n、均值mean、最小值minimum、最大值maximum以及a. median.b. range.c. standard deviation.d. standard error of the mean.13. 下面哪一个语句限制MEANS过程的分析变量为Boarded、Transfer以及Deplane?a. by boarded transfer deplane;b. class boarded transfer deplane;c. output boarded transfer deplane;d. var boarded transfer deplane;14. 数据集Survey.Health包括以下变量。
1.随机取组有无重复试验的两种本题是无重复DATA PGM15G;DO A=1TO4; /*A为窝别*/DO B=1TO3; /*B为雌激素剂量*/INPUT X @@; /*X为子宫重量*/OUTPUT;END;END;CARDS;106 116 14542 68 11570 111 13342 63 87;RUN;ods html; /*将结果输出成网页格式,SAS9.0以后版本可用*/ PROC GLM DATA=PGM15G;CLASS A B;MODEL X=A B / SS3;MEANS A B; /*给出因素A、B各水平下的均值和标准差*/MEANS B / SNK; /*对因素B(即剂量)各水平下的均值进行两两比较*/ RUN;ODS HTML CLOSE;2.2*3析因设计两因素完全随机统计方法2*3析因设计tiff =f的开方DATA aaa;DO zs=125,200;DO repeat=1TO2; /*每种试验条件下有2次独立重复试验*/do js=0.015,0.030,0.045;INPUT cl @@;OUTPUT;END;END;END;CARDS;2.70 2.45 2.602.78 2.49 2.722.83 2.85 2.862.86 2.80 2.87;run;PROC GLM;CLASS zs js;MODEL cl=zs js zs*js / SS3;MEANS zs*js;LSMEANS zs*js / TDIFF PDIFF; /*对 zs和js各水平组合而成的试验条件进行均数进行两两比较*/RUN;ODS HTML CLOSE;练习一:2*2横断面研究列链表方法:卡方矫正卡方FISHERDATA PGM19A;DO A=1TO2;DO B=1TO2;INPUT F @@;OUTPUT;END;END;CARDS;2 268 21;run;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ;RUN;样本大小= 57练习二:对裂列连表结果变量换和不换三部曲1横断面研究P《0.05 RDATA PGM19B;DO A=1TO2;DO B=1TO2;INPUT F @@;OUTPUT;END;END;CARDS;40 34141 19252;run;ods html;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ cmh;RUN;ods html close;样本大小= 57练习三:病例对照2*2 病例组中有何没有那个基因是正常的3.8倍,则有可能导致痴呆要做前瞻性研究用对裂DATA PGM20;DO A=1TO2;DO B=1TO2;INPUT F @@;OUTPUT;END;END;CARDS;240 60360 340;run;ods html;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ cmh;RUN;ods html close;总样本大小= 1000练习四:配对设计隐含金标准2*2 MC卡方检验34和0在总体上(B+C《40 用矫正卡方)是否相等则可得甲培养基优于乙培养基一般都用矫正因卡方为近似计算DATA PGM19F;INPUT b c;chi=(ABS(b-c)-1)**2/(b+c);p=1-PROBCHI(chi,1);求概率 1减掉从左侧积分到卡方的值chi=ROUND(chi, 0.001);IF p>0.0001THEN p=ROUND(p,0.0001);FILE PRINT;PUT(打印在输出床口) #2 @10'Chisq' @30'P value'(#表示行)#4 @10 chi @30 p;CARDS;34 0;run;ods html close;练习五:双向有序R*C列连表用KPA data aaa;do a=1to3;do b=1to3;input f @@;output;end;end;cards;58 2 31 42 78 9 17;run;ods html;*简单kappa检验;proc freq data=aaa;weight f;(频数)tables a*b;test kappa;run;*加权kappa检验;proc freq;weight f;tables a*b;test wtkap;run;SASFREQ 过程a *b 表的统计量对称性检验指总体上主对角线的上三角数相加是否与下三角三个数相加对称性检验与KPA 检验是否一致是否一个可以代替另一个检验Pe理论观察一致率独立假设性基础上计算的相互独立总体的KPA 是否为0 KPA 大于0两种方法的一致性有统计学意义 小于0 不一致性有统计学意义置信区间不包括0 拒绝H0 但要看专业要求达到多少才可以 观测一致率达到多少才可以代替 样本大小 = 147FREQ 过程a *b 表的统计量对加权的KPA检验与简单的(利用对角线上的数据分析)加权还要利用对角线以外的数据分析样本大小= 147练习六:双向无序R*C 列连表用卡方理论频数小于5没有超过五分之一,一般用卡方实在不行用FISHER检验超过用KPA 两种血型都是按小中大排列相互不影响独立的接受H0 不一致行与列变量相互不影响DATA PGM20A;DO A=1TO4;DO B=1TO3;INPUT F @@;OUTPUT;END;END;CARDS;431 490 902388 410 800495 587 950137 179 325;run;ods html;PROC FREQ;WEIGHT F;TABLES A*B / CHISQ;*exact;RUN;ods html close;样本大小= 6094练习七:单向有序R*C 秩和检验*方法1;(单因素非参数 HO三个药物疗效相同 H1不完全相等)DATA PGM20C;DO A=1TO4;DO B=1TO3;INPUT F @@;OUTPUT;END;END;CARDS;15 4 149 9 1531 50 455 22 24;run;ods html;PROC NPAR1WAY WILCOXON;FREQ F;CLASS B;VAR A;RUN;*方法2;(FIQ CHIM)proc freq data=PGM20C;weight f;tables b*a/cmh scores=rank;run;ods html close;总样本大小= 270练习八:双向有序属性不同R*C 4种目的4种方法SPEARMAN秩相关分析DATA PGM20E;DO A=1TO3;DO B=1TO3;INPUT F @@;OUTPUT;END;END;CARDS;215 131 14867 101 12844 63 132;run;ods html;PROC CORR SPEARMAN;VAR A B;FREQ F;RUN;ods html close;统计分析与SAS实现第1次上机实习题一、定量资料上机实习题要求:(1)先判断定量资料所对应的实验设计类型;(2)假定资料满足参数检验的前提条件,请选用相应设计的定量资料的方差分析,并用SAS软件实现统计计算;(3)摘录主要计算结果并合理解释,给出统计学结论和专业结论。
spss统计试题及答案SPSS统计试题及答案1. 单项选择题- 1.1 SPSS中,用于进行数据描述性分析的命令是()。
- A. DESCRIPTIVES- B. FREQUENCIES- C. MEANS- D. T-TEST- 答案:A- 1.2 在SPSS中,要进行方差分析,应该使用以下哪个命令?() - A. DESCRIPTIVES- B. ANOVA- C. REGRESSION- D. CROSSTABS- 答案:B2. 多项选择题- 2.1 下列哪些选项是SPSS中的数据类型?()- A. Numeric- B. String- C. Date- D. Time- 答案:A、B、C、D- 2.2 在SPSS中,进行相关性分析可以使用以下哪些命令?()- A. CORRELATIONS- B. REGRESSION- C. CROSSTABS- D. MEANS- 答案:A、B3. 简答题- 3.1 简述SPSS中如何进行数据的导入和导出。
- 答案:在SPSS中,数据的导入可以通过“文件”菜单下的“打开”选项,选择“数据”并导入不同格式的数据文件。
数据的导出则可以通过“文件”菜单下的“另存为”选项,选择导出为SPSS、Excel、CSV等格式。
- 3.2 解释在SPSS中进行回归分析的步骤。
- 答案:在SPSS中进行回归分析的步骤包括:打开数据文件,选择“分析”菜单下的“回归”选项,选择“线性”或“逻辑”回归,指定因变量和自变量,点击“确定”进行分析。
4. 计算题- 4.1 假设有一组数据:10, 15, 20, 25, 30。
计算这组数据的平均值和标准差。
- 答案:平均值 = (10+15+20+25+30)/5 = 20;标准差 =√[(10-20)²+(15-20)²+(20-20)²+(25-20)²+(30-20)²]/5 =7.071。
附录A 习题答案习题1答案1.什么是观测值OBS?答:一份问卷、一个单一的整体、一个人、一个被测对象就是一个观测值,或称一个“个案”。
每个个案是由若干变量组成。
2. 什么是变量Variable?一份问卷一般有几个甚至几十个问答题,一个问答题就是一个变量。
如id、sex、age、location、income等。
3.下面的变量名哪些有效?哪些无效?sex、age、v1、location、_ab_、1age、1v、location1、@1、#1、%1、&2答:(1)有效的变量名是由1-8个有效字符组成且字母领头,后跟数字或有效的字母。
但字母@、#、$、%、^、&、*等是无效的字符。
比如:sex、age、v1、location、_ab_等变量名是正确的;(2)无效的变量名:1age、1v、location1、@1、#1、%1、&2等。
4.变量有哪些类型?答:变量有2种类型。
数字型:如INPUT id sex age;字符型:如“INPUT id sex $ age;”中的“sex $”表示性别是以m=男性,f=女性表示的。
5.给下面程序A.1a改错。
程序A.1a:DATA sj5; INPUT a b c @@; IF 4=<a<15 THEN GOTO OK; a=3; COUNT+1; RETURN; /*RETURN(返回)到DATA步执行它下面的语句*/ OK:SUMa+a; CARDS;3 6 9 10 22 15 12 10 14 ; PROC PRINT; RUN;解答:错在第3条语句上。
改错后的程序见程序A.1b。
程序A.1b:DATA sj5; INPUT a b c @@; IF a>=4 & a<15 THEN GOTO OK; a=3; COUNT+1; RETURN; /*RETURN(返回)到DATA步执行它下面的语句*/OK:SUMa+a; CARDS;3 6 9 10 22 15 12 10 14 ; PROC PRINT; RUN;习题2答案1.指出下列命令的作用。
《统计分析软件》试(题)卷班级姓名学号说明:1.本试卷分析结果写在每个题目下面(即所留空白处);2.考试时间为100分钟;3.每个试题20分。
一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。
要求:(1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.”(2)对所建立的数据文件“成绩.sav”进行以下处理:1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。
2)计算每个学生的总成绩、并按照总成绩的大小进行排序3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
男生数学的均值为82.25高于女生的均值78.5。
女生的的标准差7.09930高于男生的标准差3.77492。
2.3.优共有4人,良具有12人中有4人。
二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。
根据所给数据完成以下问题(1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。
(2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
分析:<1>(1)(2)(3)(4) (5)(6)(7)最后保存的文件“调查.sav”格式及内容如下:<2> 先对数据进行频数分析(1)(2)(3)三、(20分)入户推销有五种方法。
SPSS统计分析习题1 搜集数据,用spss建立一个数据文件记录你所在班级学生下列情况:学号、姓名、年龄、籍贯、民族、家庭电话号码、出生年月日、综合测评成绩,以及评定成绩等级(优、良、中、可、差)等,给出正确的变量名、变量类型、标签及值标签、测度水平。
2 下面的表,分别为某企业1991年~1995年5年中各季度计划完成和实际完成的产量(单位:万吨)数据资料,试建立一个SPSS数据文件保存这两个表中的季度和各年度的计划产量和实际完成的产量、平均产量。
最好能用统计图表显示。
(1)调用排序个案Sort Cases命令分别对年产值、职工人数和年工资总额进行排序。
许多SPSS文件中都定义一个表示观测量序号的id变量,按照自己的体会指出这个id变量的作用。
(2)调用Aggregate命令分别按部门和所有制类型作分类汇总。
(3)首先调用Sort Cases命令分别按部门:按所有制类型;按部门和所有制类型进行排序。
再执行Analyze →Descriptives Statistics →Descriptives,对年产值、职工人数和年工资总额进行描述。
(4)首先调用Split File命令分别按部门和所有制类型将文件分组,再重复(3)的操作,比较二者的差异。
4 如下图(局部)所示的文件中记录了某公司职工workage(工龄)、wage(月基本工资)、dutyday(出勤天数)、w_e_fee(应扣水电费)等项数据的资料,公(1)出满勤22天或以上者,按照“日基本工资×出勤天数+工龄×1.8-应扣水电费”计算;(2)出勤15天或以上,20天以下者,按照“日基本工资×出勤天数+工龄×1.2-应扣水电费”计算;(3)出勤15天以下者,按照“日基本工资×出勤天数+工龄-应扣水电费”计算。
其中“日基本工资=月基本工资/22.5”,试编写一个计算输出职工当月实发工资的SPSS语法程序。
《SAS EG数据统计分析题库》
单选题
1、分析教师和会计师之间收入的差异,选择什么分析方法最合适?
A、卡方分析
B、方差分析
C、两样本T检验
D、相关系数
答案C
2、分析购买不同产品的频次时,使用以下哪个任务?
A、列表数据
B、汇总表
C、汇总统计量
D、单因子频数
答案D
3、以下哪个语句可以将字符型数值date(示例:“2001-02-19”)转换为数值类型?
A、INPUT(date,YYMMDD10.)
B、PUT(date,YYMMDD10)
C、INPUT(date,YYMMDD10.)
D、PUT(date,YYMMDD10)
答案A
4、来自于总体的样本最主要的属性是什么?
A、随机
B、有代表性
C、正态分布
D、连续分布
答案B
5、D—W统计量用于检验?
A、异方差
B、自相关
C、解释变量线性相关
D、扰动项不服从正态分布
答案B
6、什么统计量用于检验解释变量之间线性相关
A、标准化的残差
B、D—W统计量
C、Cook's D
D、膨胀系数
答案D
7、连续变量右偏的情况下,中位数在均值的?
A、左边
B、右边
C、相等
D、无法判断
答案A
8、代表变量离散程度的指标是?
A、均值
B、标准差
C、最大值
D、中位数
答案B
9、解释变量是多分类变量,被解释变量是连续变量,使用什么分析方法?
A、卡方分析
B、方差分析
C、两样本T检验
D、相关系数
答案B
10、如果在方差分析中有20个观察值,你要计算残差。
那么以下哪个值会是残差和?
A、-20
B、0
C、400
D、从已知信息中无法推断
答案B
11、要进行一项研究,比较男女月均信用卡支出。
可能使用哪一种统计方法?
A、单样本T检验
B、双样本T检验
C、单因素方差分析
D、双因素方差分析
答案、C
12、你运用线性回归任务进行回归,Y是因变量,X1是唯一解释变量。
如果X1的参数估计(斜率)是0,那么当X1=13时,Y的最佳预测值是?
A、13
B、Y的均值
C、0
D、X1的均值
答案B
13、方差分析表中哪个统计量是用于检验总体模型假设的?
A、F
B、t
C、R2
D、Adjusted R2
答案A
14、当你用跑步时间(RunTime)、年龄(Age)、跑步时脉搏(Run_Pulse)以及最高脉搏(Maximum_Pulse)作为预测变量来对耗氧量(Oxygen_Consumption )进行回归时,年龄(Age)的参数估计是-2.78. 这意味着什么?
A、年龄每增加一岁,耗氧量就增大2.78.
B、年龄每增加一岁,耗氧量就降低2.78.
C、年龄每增加2.78岁,耗氧量就翻倍。
D、年龄每减少2.78岁,耗氧量就翻倍。
答案B
15、在不同解释变量数量不同的模型中,以下哪个指标对选择模型没有作用?
A、R2
B、Adjusted R2
C、Mallows’Cp
D、AIC
答案A
16、在线性回归模型中,假设预测变量是正态分布的。
A、对
B、错
C、不知道
答案B
17、在标准正态分布的属性下,预期95%的学生化残差处于哪两个值之间?
A、-3 和3
B、-2 和2
C、-1 和1
D、0 和1
答案B
18、共线性违反了以下哪一假设?
A、误差独立
B、方差不变
C、误差正态分布
D、以上均不是
答案D
19、当样本量减小时,以下哪个情况会发生?
A、卡方值增大。
B、P值增大。
C、Cramer’s V 增大。
D、Odds Ratio增大。
答案B
20、研究者想测量两个二元变量间的相关性强度。
他该使用以下哪个统计量?
A、Hansel 和Gretel 相关系数
B、Mantel-Haenszel 卡方检验
C、Pearson卡方检验
D、Spearman 相关系数
答案D
pearson相关系数和spearman相关系数的区别:
1.连续数据,正态分布,线性关系,用pearson相关系数是最恰当,当然用spearman相关系数也可以,就是效率没有pearson相关系数高。
2.上述任一条件不满足,就用spearman相关系数,不能用pearson相关系数。
3.两个定序测量数据之间也用spearman相关系数,不能用pearson相关系数。
21、ROC曲线凸向哪个角,代表模型约理想?
A、左上角
B、左下角
C、右上角
D、右下角
答案A
22、添加”分配项目逻辑库“在哪个菜单下?
A、文件
B、编辑
C、任务
D、工具
答案D
23、根据字符串的位置和长度取子字符串的函数是?
A、SCAN
B、SUBSTR
C、CATX
D、FIND
答案D
24、下面哪个符合日期常数的格式?
A、"2014-01-01"D
B、"01Jan2014"d
C、"2014-01-01"
D、"01Jan2014"
答案B
填空题(每空1分,共25):
1、追加表时,必须保障两个表中各个变量的名称和(变量类型)必须一致,否则会报错。
2、SAS EG中变量按测量类型,分为(名义)、(等级)和(连续)
3、SAS EG中变量按存储类型分为(字符型)和(数值型),其中日期类型属于(数值型)
4、展现连续变量的分布常用的两个图是(直方图)和(盒须图),检验连续变量是否服从正态分布,使用的图是(Q—Q图)或(P-P图)
5、大数定理使用的前提条件是随机变量必须(独立)且(同分布)。
(注:写均值和标准差相等也可以)
6、多变量线形回归的前提假设是(线形模型)、(解释变量和扰动项不相关)、(扰动项独立同分布)、(解释变量不线形相关)、(扰动项独立同分布)、(扰动项正态分布)
7、可以完成排序任务的菜单有(过滤和排序)、(查询生成器)、(对数据排序)
8、流程图改名为(AUTOEXEC)可以每次打开项目时自动运行该流程图。
9、(Work)逻辑库被称为临时逻辑库,里面存放的对象每次关闭SAS时被清空。
10、在(提示管理器)和查询生成器里面可以定义新的提示。
简答题(每题3分,共9分)
1、双样本T检验和单变量方差分析的异同点,为什么说方差分析是比较均值?
2、作列联表时,解释变量和被解释变量分别放在什么位置,单元格内放置行百分比还是列百分比?什么情况下不能使用渐进卡方统计量?
3、作样本T检验时,为什么要做方差齐性检验?
问答题(每题7分,共14分)
1、列出多变量线形回归的前提假设,并指出在作回归诊断时用什么方法进行检验?
2、假设在大数据量下(多变量、多观测)作逻辑回归的流程、每步完成的任务和用到的统计方法?。