sas笔记
- 格式:docx
- 大小:55.44 KB
- 文档页数:8

Range极差 mean(1,2,3)平均 std 标准差/**自动导入**/Libname cwb “”;proc importdatafile="E:\WORK\杂七杂八\SAS数据库\分期乐入池数据\明细数据(风险指标监控表&实际还款表)\荷包一期_风险指标监控表详细总表&today_date..xls"out=work.risk001dbms=excel replace;sheet='风险指标监控表总表';getnames=yes; 导入源文件字段名作为SAS数据集的字段名自动导入%macro chouc(today_date);datafile="C:\Users\抽查\一债权基础池报表&today_date..xls"out=work.chouc01dbms=excel replace;sheet="债权基础池";run;%mend;%chouc(20170116);导出:/4*先排序*/proc sort data=new_cy2;by _COL1 ;run;/***标题**打印*/proc print ;title'员工薪水';RUN;proc print data=cwb.result20170208 label;id package;var overdue_principal_za overdue_principal_fql;label overdue_principal_za="违法停车" overdue_principal_fql="林肯" ;run;proc print data=cwb.result20170208;where principal_sell > 20000000;run;/*统计表格*/1\proc tabulate data=work.risk005b;class _COL22; 分类变量var _COL5;分析变量table _COL22 _COL5;列维说明/选项(math chinese)*(mean var)反映男女生数学语文成绩的平均值方差run;2\proc tabulate data=work.risk005b;class _COL22;var _COL5 _COL4;table _COL22, (_COL4 _COL5)*(mean max min);run;table _COL22 all, (_COL4 _COL5)*(mean max min); 加个ALL,有求和,图2.也可写为例如table (_COL22 all)*(_COL4)*(mean);如图也可加标签 table (sex all), (math chinese)*(mean std);keylabel mean='平均值' std='标准差' all='总计';label sex='性别' math='数学' chinese='语文';run;/**复制*强制追加*把B加到A中*而SET是要新建一个的*/proc append base=chouc.chouc01 data=chouc.chouc02 force;/**force强制*/run;/**复制*强制追加*把B加到A中*而SET是要新建一个的*/proc sort data=chouc.chouc01 dupout=chouc.bb noduprecs;/**noduprecs一行完全相同的重复记录*/by descending _COL0 ;run;/**sql*联合查询**/Proc sql;Select * from aUnion /*多个查询结果合并成一个结果,并去掉重复** /Intersect /*查询公共部分数据*/Except /*把公共部分去掉的数据*/Outer union /*对多个查询结果横向合并*/Select * from b;Quit;/**去**重复**方法之一***/只显示nameselect name from tb group by name having count(*) > 1显示所有数据select * from name in (select name from tb group by name having count(*) > 1)*2、输出重复的观测值,使用nodupkey选项,注意:使用该选项后直接将原数据集中的重复值删除。

一、VAR语句VAR语句在很多过程中用来指定分析变量。
在VAR后面给出变量列表:VAR 变量名1 变量名2 …变量名n;变量名列表可以使用省略的形式,如X1-X3,MATH--CHINESE等。
VAR用法例如:var math chinese;WHERE 语句WHERE 语句的格式很简单,只要后面跟用于数据筛选的逻辑表达式即可:WHERE logical-expression(s);下面的例子基于 test1 数据表生成 test2 数据表,但是只选择满足 sex='F' 并且 age>20 的数据行:data test2; set test1; where sex='F' AND age>20; run;表面看来,WHERE 语句和数据步骤中的SAS IF 语句的功能相近,都是筛选数据和。
实际上WHERE 语句和IF语句的运作机制是不同的。
WHERE 语句相当于对数据集执行了一个 SQL Select 的操作。
也就是说,在进入到操作前数据已经被整体筛选过了,而IF 语句是在数据步骤的每个循环中单独执行的,WHERE 语句显然效率要提高很多。
如果数据表是索引过的,那么WHERE 语句能够更加显著地提高效率。
WHERE 语句也有其限制。
因为它是对现存的数据表的整体性操作,故而只能对该数据表中已有的变量进行筛选操作,不能对数据处理后生成的变量操作,也不能对INPUT 语句定义的变量操作。
WHERE 语句不但能用于数据步骤中还能用于过程语句中。
操作符除了一般的 SAS 操作符(见SAS 语法),WHERE 语句还支持一些特有的操作符。
between ... and。
比如:where x between 10 and 20;其实相当于:where 10<=x<=20;contains。
字符串包含。
可以用问号代替。
比如:where firstname contains 'john'; where firstname ? 'john';is null 或is missing。
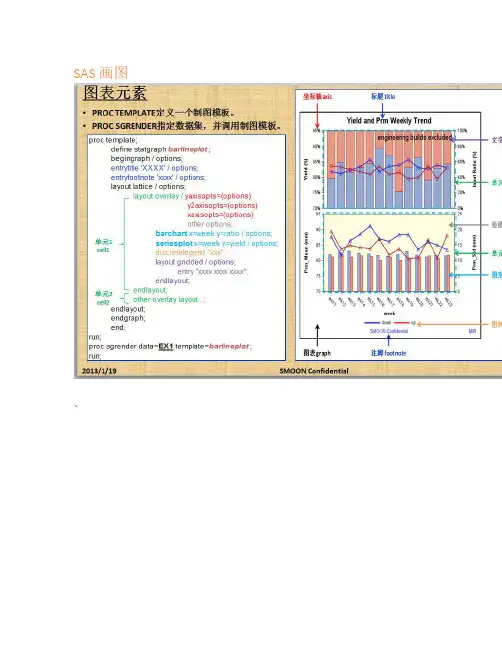
SAS 画图、proc template;define statgraph scatterplot;begingraph;entrytitle "Weight and Age by Sex";layout overlay;scatterplot x=age y=weight /group=sex name="abc";discretelegend "abc";endlayout;endgraph;end;run;ods html;proc sgrender data=sashelp.class template=scatterplot; run;proc template;define statgraph scatterplot;begingraph;entrytitle "Weight and Age by Sex";entrytitle halign=left "Weight and Age by Sex"/ border=true *是否加边框,ture 是加,false 是不加; opaque=true *透明度;backgroundcolor=lightgreen *背景的颜色;textattrs=(color=bluefamily='Arial'size=14style=italicweight=bold); * 文本的格式;entryfootnote halign=center 'SMOON Confidential'halign=right "MIB";layout overlay;scatterplot x=age y=weight /group=sex name="abc";discretelegend "abc";endlayout;endgraph;end;run;ods html;proc sgrender data=sashelp.class template=scatterplot; run;从图形可以看到,设置backgroundcolor=lightblue后,背景颜色变成淡蓝色了;设置border=true和borderattrs=(color=pink thickness=3)后,边框变成粉红色并且加粗了;设置designwidth=400px和designheight=400px后,图表大小改变并且变成正方形了;设置pad=(bottom=50 right=50)后,下边和右边空白区域变大了。

SAS 初识(学习笔记)1自顶向下的设计,自底向上的运行2 SAS程序由一个数据步data work.filenam ; ....... run;若干执行步proc print ....... run;proc KEYword ...... run;可归纳为DATA步和PROC步两个部分。
DATA步生产、整理数据报表编写,文件管理、信息检索等都在DATA中完成。
PROC步分析数据管理数据、生成报告和图表及对数据排序等在PROC中完成。
3 SAS语句通常以SAS关键字开头,以分号(;)结束4 SAS数据集是一个由SAS创建并且处理的文件,是一个包含数据值的特殊结构性文件。
数据必须以SAS数据集的形式存在才能用SAS程序和一些DA TA步语句处理。
SAS数据集由描述信息部分,包括一般信息和变量信息用contents 过程浏览proc contents DATA=SAS-data-set ;run;数据值部分是由字符或数字数据值组成的表格。
用PRINT过程浏览proc print DA TA=SAS-data-set;run;数据部分是一个由字符和/或数字数据值组成的矩形表格。
变量名称是描述部分的一部分,而不属于数据部分。
5 SAS逻辑厍是SAS文件的集合。
就是一个目录。
在使用中要通过一个引用名来识别。
SAS逻辑库分临时库和永久库,名为的work是临时库,由SAS 自动创建,随着SAS会话的结束,其中的数据文件将被删除;永久库则会保存下来。
当我们在磁盘上创建了一个文件目录并将使其做为SAS永久库时,需要使用LIBNAME语句分配一个逻辑库引用名libname x_name‘s:\workshop’;由此SAS建立了逻辑库(引用)名与操作系统上的文件目录的物理位置建立了连接。
当SAS会话结束后,逻揖库引用名与文件的物理位置之间的走接就会切断。
数据集是逻辑库中的一个SAS文件,在物理上是逻辑库对应的那个目录中的一个文件。
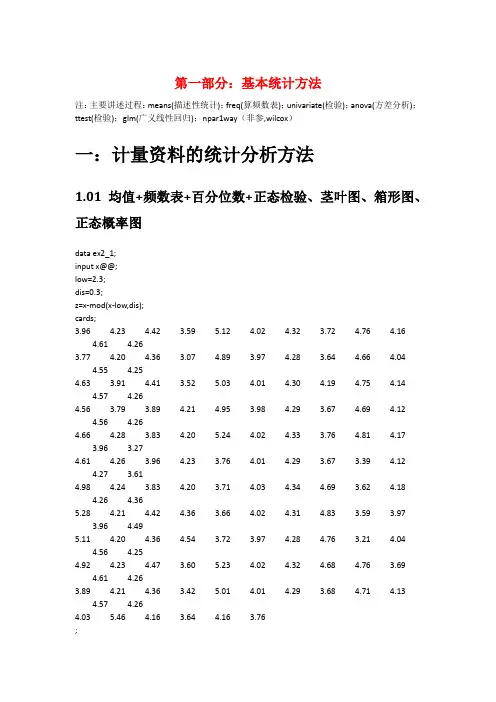
第一部分:基本统计方法注:主要讲述过程:means(描述性统计);freq(算频数表);univariate(检验);anova(方差分析);ttest(检验);glm(广义线性回归);npar1way(非参,wilcox)一:计量资料的统计分析方法1.01均值+频数表+百分位数+正态检验、茎叶图、箱形图、正态概率图data ex2_1;input x@@;low=2.3;dis=0.3;z=x-mod(x-low,dis);cards;3.964.23 4.42 3.595.12 4.02 4.32 3.72 4.76 4.164.61 4.263.774.20 4.36 3.07 4.89 3.97 4.28 3.64 4.66 4.044.55 4.254.63 3.91 4.41 3.525.03 4.01 4.30 4.19 4.75 4.144.57 4.264.56 3.79 3.89 4.21 4.95 3.98 4.29 3.67 4.69 4.124.56 4.264.66 4.28 3.83 4.205.24 4.02 4.33 3.76 4.81 4.173.96 3.274.61 4.26 3.96 4.23 3.76 4.01 4.29 3.67 3.39 4.124.27 3.614.98 4.24 3.83 4.20 3.71 4.03 4.34 4.69 3.62 4.184.26 4.365.28 4.21 4.42 4.36 3.66 4.02 4.31 4.83 3.59 3.973.964.495.11 4.20 4.36 4.54 3.72 3.97 4.28 4.76 3.21 4.044.56 4.254.92 4.23 4.47 3.605.23 4.02 4.32 4.68 4.76 3.694.61 4.263.894.21 4.36 3.425.01 4.01 4.29 3.68 4.71 4.134.57 4.264.035.46 4.16 3.64 4.16 3.76;/*freq语句,算频数表*/proc freq;tables z;run;proc means data=ex2_1n mean std stderr clm;var x;run;data ex2_1;input x f@@;cards;3.07 23.27 33.47 93.67 143.87 224.07 304.27 214.47 154.67 104.87 65.07 45.27 2;run;proc means;freq f;var x;run;/*把freq f改成weight f就是把f当权重或频数来算,f则在0,1之间*//*计算x的95%的置信区间*/proc univariate data=ex2_1;var x;output out=pctpctlpre=ppctlpts=2.5 97.5;run;proc print data=pct;run;/*正态检验、茎叶图、箱形图、正态概率图*/proc univariate data=ex2_1normalplot;var x;run;/*Extreme Observation显示的值是最小的5个极值和最大的5个极值*/1.02几何均值data ex2_5;input x f@@;y=log10(x);cards;10 420 340 1080 10160 11320 15640 141280 2;proc means noprint;/*调用means过程,不显示结果*/var y;freq f;output out=b/*结果输出到数据集b中*/mean=logmean;/*把数据集b中均数的变量名mean改为logmean*/run;data c;/*新建数据集c*/set b;/*调用数据集b*/g=10**logmean;/*计算变量logmean的反对数,该值就是x的几何均数,将该值赋值给变量g*/ proc print data=c;var g;run;/*这个是计算平通平均数的值*/proc means data=ex2_5;var x;freq f;run;1.03已知均值和方差求置信区间-单样本+单样本与总体/*单样本*/data ex3_2;n=10;mean=166.95;std=3.64;t=tinv(0.975,n-1);pts=t*std/sqrt(n);lclm=mean-pts;uclm=mean+pts;proc print;var lclm uclm;run;/*单样本与总体均值*/data ex3_5;n=36;/*样本量*/s_m=130.83;/*样本均值*/std=25.74;/*样本标准差*/p_m=140;/*总体均值*/df=n-1;/*自由度*/t=(s_m-p_m)/(std/sqrt(n));p=(1-probt(abs(t),df))*2;/*根据t值计算p值*/run;proc print;var t p;run;1.06双样本均值相等检验+两组分开+两组一起算+两组样本量不同/*双样本分开算*/data ex3_4;n1=29;n2=32;m1=20.10;m2=16.89;s1=7.02;s2=8.46;ss1=s1**2*(n1-1);ss2=s2**2*(n2-1);sc2=(ss1+ss2)/(n1+n2-2);se=sqrt(sc2*(1/n1+1/n2));t=tinv(0.975,n1+n2-2);lclm=(m1-m2)-t*se;uclm=(m1-m2)+t*se;proc print;var t se lclm uclm;run;/*双样本相减后再算*//*用MEANS作配对资料两个样本均数比较的t检验*/data ex3_6;input x1 x2 @@;d=x1-x2;cards;0.840 0.5800.591 0.5090.674 0.5000.632 0.3160.687 0.3370.978 0.5170.750 0.4540.730 0.5121.200 0.9970.870 0.506;proc means t prt;var d;run;/*用UNIVARIATE过程作配对资料两样本均数比较的t检验*/ proc univariate data=ex3_6;var d;run;/*双样本两组样本量不同*/data ex3_7;input x@@;if _n_<21 then c=1;/*当观测数小于21时,变量c的值为1,表示试验组*/else c=2;/*其余变量c的值为2,表示对照组*/cards;-0.70 -5.60 2.00 2.80 0.70 3.50 4.00 5.80 7.10 -0.502.50 -1.60 1.703.00 0.404.50 4.60 2.50 6.00 -1.403.70 6.50 5.00 5.20 0.80 0.20 0.60 3.40 6.60 -1.106.00 3.80 2.00 1.60 2.00 2.20 1.20 3.10 1.70 -2.00;proc ttest;/*调用ttest过程*/var x;/*定义分析变量为x*/class c;/*定义分组变量为c*/run;1.08-1.13anova方差分析过程+一维分组+二维分组+三维分组/*只有一组分组因素*/data ex4_2;input x c @@;cards;3.53 1 2.42 2 2.86 3 0.89 44.59 1 3.36 2 2.28 3 1.06 44.34 1 4.32 2 2.39 3 1.08 42.66 1 2.34 2 2.28 3 1.27 43.59 1 2.68 2 2.48 3 1.63 43.13 1 2.95 2 2.28 3 1.89 43.30 1 2.36 2 3.48 3 1.31 44.04 1 2.56 2 2.42 3 2.51 43.53 1 2.52 2 2.41 3 1.88 43.56 1 2.27 2 2.66 3 1.41 43.85 1 2.98 2 3.29 3 3.19 44.07 1 3.72 2 2.70 3 1.92 41.37 12.65 2 2.66 3 0.94 43.93 1 2.22 2 3.68 3 2.11 42.33 1 2.90 2 2.65 3 2.81 42.98 1 1.98 2 2.66 3 1.98 44.00 1 2.63 2 2.32 3 1.74 43.55 1 2.86 2 2.61 3 2.16 42.64 1 2.93 23.64 3 3.37 42.56 1 2.17 2 2.58 3 2.97 43.50 1 2.72 2 3.65 3 1.69 43.25 1 1.56 2 3.21 3 1.19 42.96 13.11 2 2.23 3 2.17 44.30 1 1.81 2 2.32 3 2.28 43.52 1 1.77 2 2.68 3 1.72 43.93 1 2.80 2 3.04 3 2.47 44.19 1 3.57 2 2.81 3 1.02 42.96 1 2.97 23.02 3 2.52 44.16 1 4.02 2 1.97 3 2.10 42.59 1 2.31 2 1.68 33.71 4;proc anova;/*调用anova过程*/class c;/*定义分组变量为c*/model x=c;/*定义模型,分析g对x的影响*/means c/dunnett;/*用LSD法对多组均数过行两两比较*/means c/hovtest;/*作方差齐性检验,默认levene法,p值大于0.05,则认为是g组方差相等*/run;quit;/*有两组分组因素*/data ex4_4;input x a b@@;cards;0.82 1 10.65 2 10.51 3 10.73 1 20.54 2 20.23 3 20.43 1 30.34 2 30.28 3 30.41 1 40.21 2 40.31 3 40.68 1 50.43 2 50.24 3 5;proc anova;class a b;/*定义分组变量a和b*/model x=a b;/*定义模型,分析a和b对x影响*/means a/snk;/*用SNK法对变量a的多组均数进行两两比较*/run;quit;1.15嵌套设计资料的方差分析glm过程一级因素+二组因素/*嵌套设计资料的方差分析*/data ex11_6;input x a b @@;cards;82 1 184 1 191 1 288 1 285 1 383 1 365 2 461 2 462 2 559 2 556 2 660 2 671 3 767 3 775 3 878 3 885 3 989 3 9;proc glm;/*调用glm过程*/class a b;/*定义分组变量为a和b*/model x=a a(b);/*定义模型,以a为一组因素,b为二级因素*/run;quit;1.17重复测量资料的方差分析data ex12_2;input t1 t2 g@@;/*确定变量名称,t1和t2分别为两个时间点的分析变量,g为处理因素变量,b为区组变量*/cards;130 114 1124 110 1136 126 1128 116 1122 102 1118 100 1116 98 1138 122 1126 108 1124 106 1118 124 2132 122 2134 132 2114 96 2118 124 2128 118 2118 116 2132 122 2120 124 2134 128 2;proc glm;/*调用glm过程*/class g;/*定义分组变量g*/model t1 t2=g;/*定义模型,分析g对变量t1和t2的影响*/repeated time 2/*命名重复因子为time,有2个水平*/contrast(1)/*表示以第一时间点为对照点*//summary;/*考察不同时间点与对照时间点比较的结果*/run;quit;data ex12_3;input t0-t4 g@@;cards;120 108 112 120 117 1118 109 115 126 123 1119 112 119 124 118 1121 112 119 126 120 1127 121 127 133 126 1121 120 118 131 137 2122 121 119 129 133 2128 129 126 135 142 2117 115 111 123 131 2118 114 116 123 133 2131 119 118 135 129 3129 128 121 148 132 3123 123 120 143 136 3123 121 116 145 126 3125 124 118 142 130 3;proc glm;class g;model t0-t4=g;repeated time 5/*命名重复因子为time,有2个水平*/contrast(1);run;quit;二:计数资料的统计分析方法2.1四格表资料的卡方检验data ex7_1;input r c f@@;/*确定变量名称,r为行变量,c为列变量,f为频数变量*/ cards;1 1 991 2 52 1 752 2 21;proc freq;/*调用freq过程*/weight f;/*定义f为频数变量*/tables r*c/*作r*c的列联表*//chisq/*对列联表作卡方检验*/expected;/*输出每个格的理论频数*/run;2.5阳性事件发生的概率(二项分布)data ex6_1;do x=6 to 8;/*建立循环,变量x从6到8*/p1=probbnml(0.7,10,x);/*计算二项分布随机变量不大于x的概率*/p2=probbnml(0.7,10,x-1);/*计算二项分布随机变量不大于x-1的概率*/p=p1-p2;*/计算出现x的概率*/output;/*结果输出*/end;proc print;var x p;run;2.6正态分布法计算总体率的可信区间data ex6_3;n=100;x=55;p=x/n;sp=sqrt(p*(1-p)/n);u=probit(0.975);usp=u*sp;lclm=p-usp;uclm=p+usp;proc print;var n p sp lclm uclm;run;2.7样本率与总体率的比较(直接法——单侧检验)data ex6_4;d=probbnml(0.55,10,8);p=1-d;proc print;var p;run;2.8样本率与总体率的比较(直接法——双侧检验)data ex6_5;p01=probbnml(0.6,10,9);p02=probbnml(0.6,10,8);p0=p01-p02;/*计算出现9的概率*/do i=0to10;/*建立循环,变量i从0到10*/p11=probbnml(0.6,10,i);p12=probbnml(0.6,10,i-1);p1=p11-p12;/*计算出现i的概率*/if i=0then p1=p11; /*定义出现0的概率*/if p1<=p0 then output; /*如果出现i的概率小于出现9的概率,则保留在数据集中*/ end;proc means sum;var p1;run;2.9两个样本率比较的z检验data ex6_7;n1=120;n2=110;x1=36;x2=22;p1=x1/n1;p2=x2/n2;pc=(x1+x2)/(n1+n2);/*计算合并发生率*/sp=sqrt(pc*(1-pc)*(1/n1+1/n2));/*计算两个率相差的标准误差*/u=(p1-p2)/sp;/*计算u值*/p=(1-probnorm(abs(u)))*2;/*计算p值*/format u p 5.4;/*输出格式为小数点后保留4位*/proc print;var pc sp u p;run;2.10.Poisson分布的样本均数与总体均数比较(直接法)data ex6_12;n=120;/*确定样本例数*/pai=0.008; /*确定总体率*/lam=n*pai; /*计算总体均数lamda*/x=4; /*确定实际发生数*/p=1-poisson(lam,x-1);/*计算实际发生数所对应的概率*/proc print;var lam p;run;2.11 Poisson分布的样本均数与总体均数比较(正态近似法)data ex6_12;n=25000;/*样本量*/x=123; /*样本均数*/pi=0.003; /*确定总体率*/lam=n*pi; /*计算总体均数*/u=(x-lam)/sqrt(lam*(1-pi)); /*计算u值*/p=1-probnorm(abs(u)); /*计算u值所对应的p值*/proc print;var lam u p;run;2.14负二项分布的参数估计data ex6_16;input x f@@;cards;0 301 142 83 44 25 06 2;proc univariate;var x;freq f;output out=mv2var=v;run;data k;set mv2;k=mu**2/(v-mu);proc print;var mu k;run;三、非参数统计方法3.2单个样本中位数和总体中位数比较data ex8_2;input x1@@;median=45.30;/*假设中位数为45.30*/d=x1-median; /*计算x1和假设中位数的差值*/cards;44.21 45.30 46.39 49.47 51.05 53.1653.26 54.37 57.16 67.37 71.05 87.37;proc univariate; /*调用univariate过程度*/var d;run;proc means median; /*调用means过程计算x1实际的中位数*/var x1;run;3.3两个独立样本比较的Wilcoxon秩和检验(R对应函数wilcox.test())data ex8_3;input x c @@;/*确定变量名称,x、c分别为分析变量和分组变量(类别多于两类一样的写法)*/2.78 13.23 14.20 14.87 15.12 16.21 17.18 18.05 18.56 19.60 13.23 23.50 24.04 24.15 24.28 24.34 24.47 24.64 24.75 24.82 24.95 25.10 2;proc npar1way wilcoxon;/*调用npar1way过程,进行wilcoxon分析*/var x;/*定义分析变量为x*/class c;/*定义分组变量为c*/run;3.4等级资料的两样本比较data ex8_4;input c g f@@;/*确定变量名称,f为频数,c为分类,g为要分析的变量(分类多种类似)*/ cards;1 1 11 2 81 3 161 4 101 5 42 1 22 2 232 3 112 5 0;proc npar1way wilcoxon;/*调用npar1way过程,进行wilcoxon分析*/freq f;/*确定频数变量为f*/var g;/*定义分析变量g*/class c;/*定义分组变量c*/run;第二部分:多元统计分析方法注:主要讲述过程:reg(回归),corr(相关分析),nlin(对数曲线回归),logistic(逻辑回归),phreg(条件logistic回归分析+cox回归),life test(生存分析),discrim(判别分析),stepdisc(逐步回归),cluster(聚类),varclus(指标聚类),princomp(主成分分析),factor(因子分析),cancorr(典型相关分析)一:回归和相关分析1.1两个变量的直线回归分析data ex9_1;input x y;/*确定变量名称*/cards;13 3.5411 3.019 3.096 2.488 2.5610 3.3612 3.187 2.65;proc reg;/*调用reg过程*/model y=x;/*定义模型,以y为应变量,以x为自变量*//*在model语句后面加上选项,得到一些有用的统计量,常用的有:stb(输出标准化偏回归系数)、p(输出每个观测的实际值、预测值和残差)、cli(输出每个观测预测值均数的双侧95%置信区间)、clm(输出每个观测预测值的双侧95%置信范围)*//*例如:model y=x /stb p cli */plot y*x;/*画出散点图*/run;1.2两个变量的直线相关分析data ex9_5;input x y;cards;43 217.2274 316.1851 231.1158 220.9650 254.7065 293.8454 263.2857 271.7367 263.4669 276.5380 341.1548 261.0038 213.2085 315.1254 252.08;proc corr;/*若要求作spearman相关分析,则可以写成proc corr spearman */ var x y;run;/*得到一个相关系数矩阵*/1.4加权直线加回data ex9_9;input x y;w=1/(x*x); /*设置权重变量w*/cards;0.11 4.000.12 5.100.21 9.500.30 9.000.34 17.200.44 14.000.56 18.900.60 29.400.69 22.100.80 41.50;proc reg;weight w;/*定义权重变量w*/model y=x;/*定义模型,以y为因变量,以x为自变量*/run;1.5两个直线回归系数的比较data ex9_12;input x y c@@;cards;13 3.54 111 3.01 19 3.09 16 2.48 18 2.56 110 3.36 112 3.18 17 2.65 110 3.01 29 2.83 211 2.92 212 3.09 215 3.98 216 3.89 28 2.21 27 2.39 210 2.74 215 3.36 2;proc glm;class c;model y=x c x*c;/*定义模型,分析x、c以及x和c的交互作用对y的影响,即判断两总体直线回归系数是否相同*/run;proc glm;class c;model y=x c;/*上一步已排除协变量的影响,然后再分析两分析变量是否来自同一总体*/run;1.6两个变量的对数曲线回归data ex9_13;input x y;cards;0.005 34.110.050 57.990.500 94.495.000 128.5025.000 169.98;proc nlin;/*调用nlin过程*/parms a=0 b=0; /*定义初始值*/model y=a+b*log10(x); /*定义对数模型,以y为因变以量,x为自变量*/ run;1.7两个变量的指数曲线回归分析data ex9_14;input x y;cards;2 545 507 4510 3714 3519 2526 2031 1634 1838 1345 852 1153 860 465 6;proc nlin;parms a=4 b=0.03;/*定义初始值*/model y=exp(a+b*x);/*定义指数模型,以y为因变量,x为自变量*/run;1.8多元回归data ex15_1;input x1-x4 y@@;/*确定变量名称,x1,x2,x3,x4分别为自变量,y为应变量*/ cards;5.68 1.90 4.53 8.20 11.203.79 1.64 7.32 6.90 8.806.02 3.56 6.95 10.80 12.304.85 1.075.88 8.30 11.604.60 2.32 4.05 7.50 13.406.05 0.64 1.42 13.60 18.304.90 8.50 12.60 8.50 11.107.08 3.00 6.75 11.50 12.103.85 2.11 16.28 7.90 9.604.65 0.63 6.59 7.10 8.404.59 1.97 3.61 8.70 9.304.29 1.97 6.61 7.80 10.607.97 1.93 7.57 9.90 8.406.19 1.18 1.42 6.90 9.606.13 2.06 10.35 10.50 10.905.71 1.78 8.53 8.00 10.106.40 2.40 4.53 10.30 14.806.06 3.67 12.797.10 9.105.09 1.03 2.53 8.90 10.806.13 1.71 5.28 9.90 10.205.78 3.36 2.96 8.00 13.605.43 1.13 4.31 11.30 14.906.50 6.21 3.47 12.30 16.007.98 7.92 3.37 9.80 13.2011.54 10.89 1.20 10.50 20.005.84 0.92 8.616.40 13.303.84 1.20 6.45 9.60 10.40;proc reg;model y=x1-x4;/*也可以写成model y=x1 x2 x3 x4;*/run;1.9逐步回归data ex12_2;input x1-x4 y@@;cards;5.68 1.90 4.53 8.20 11.203.79 1.64 7.32 6.90 8.806.02 3.56 6.95 10.80 12.304.85 1.075.88 8.30 11.604.60 2.32 4.05 7.50 13.406.05 0.64 1.42 13.60 18.304.90 8.50 12.60 8.50 11.107.08 3.00 6.75 11.50 12.103.85 2.11 16.28 7.90 9.604.65 0.63 6.59 7.10 8.404.59 1.97 3.61 8.70 9.304.29 1.97 6.61 7.80 10.607.97 1.93 7.57 9.90 8.406.19 1.18 1.42 6.90 9.606.13 2.06 10.35 10.50 10.905.71 1.78 8.53 8.00 10.106.40 2.40 4.53 10.30 14.806.06 3.67 12.797.10 9.105.09 1.03 2.53 8.90 10.806.13 1.71 5.28 9.90 10.205.78 3.36 2.96 8.00 13.605.43 1.13 4.31 11.30 14.906.50 6.21 3.47 12.30 16.007.98 7.92 3.37 9.80 13.2011.54 10.89 1.20 10.50 20.005.84 0.92 8.616.40 13.303.84 1.20 6.45 9.60 10.40;proc reg;model y=x1-x4/selection=stepwise/*定义模型,以y因变量,x1-x4为变量进行多元回归分析*/ sle=0.10/*定义入先变量的界值*/sls=0.10;/*定义剔除变量的界值*/run;三:logistic回归3.1 两个变量logistic回归分析data ex16_1;input y x1 x2 f@@;/*确定变量名称,y为发病情况,x1为吸烟情况,x2为饮酒情况,f为发生频数*/cards;1 0 0 631 0 1 631 1 0 441 1 1 2650 0 0 1360 0 1 1070 1 0 570 1 1 151;proc logistic;/*调用logistic过程*/freq f;/*定义频数变量f*/model y=x1 x2;/*定义模型,以y为因变量,x1和x2为自变量*/run;3.2 1:M配对资料的条件logistic回归分析data ex16_3;input i y x1-x6 @@;/*确定变量名称,i为区组变量,y为病人情况,1为病例,0为对照,x1-x6为危险因素*/t=2-y;/*定义时间变量*/cards;1 1 3 5 1 1 1 01 0 1 1 1 3 3 01 0 1 1 1 3 3 02 1 13 1 1 3 02 0 1 1 13 2 02 0 1 2 13 2 03 1 14 1 3 2 03 0 1 5 1 3 2 03 0 14 1 3 2 04 1 1 4 1 2 1 14 0 2 1 1 3 2 05 1 2 4 2 3 2 0 5 0 1 2 1 3 3 05 0 2 3 1 3 2 06 1 1 3 1 3 2 1 6 0 1 2 1 3 2 06 0 1 3 2 3 3 07 1 2 1 1 3 2 1 7 0 1 1 1 3 3 07 0 1 1 1 3 3 08 1 1 2 3 2 2 0 8 0 1 5 1 3 2 08 0 1 2 1 3 1 09 1 3 4 3 3 2 0 9 0 1 1 1 3 3 09 0 1 4 1 3 1 010 1 1 4 1 3 3 1 10 0 1 4 1 3 3 010 0 1 2 1 3 1 011 1 3 4 1 3 2 0 11 0 3 4 1 3 1 011 0 1 5 1 3 1 012 1 1 4 3 3 3 0 12 0 1 5 1 3 2 012 0 1 5 1 3 3 013 1 1 4 1 3 2 0 13 0 1 1 1 3 1 013 0 1 1 1 3 2 014 1 1 3 1 3 2 1 14 0 1 1 1 3 1 014 0 1 2 1 3 3 015 1 1 4 1 3 2 0 15 0 1 5 1 3 3 015 0 1 5 1 3 3 016 1 1 4 2 3 1 0 16 0 2 1 1 3 3 016 0 1 1 3 3 2 017 1 2 3 1 3 2 0 17 0 1 1 2 3 2 017 0 1 2 1 3 2 018 1 1 4 1 3 2 0 18 0 1 1 1 2 1 0 18 0 1 2 1 3 2 019 0 1 1 1 2 1 019 0 2 2 2 3 1 020 1 1 4 2 3 2 120 0 1 5 1 3 3 020 0 1 4 1 3 2 021 1 1 5 1 2 1 021 0 1 4 1 3 2 021 0 1 2 1 3 2 122 1 1 2 2 3 1 022 0 1 2 1 3 2 022 0 1 1 1 3 3 023 1 1 3 1 2 2 023 0 1 1 1 3 1 123 0 1 1 2 3 2 124 1 1 2 2 3 2 124 0 1 1 1 3 2 024 0 1 1 2 3 2 025 1 1 4 1 1 1 125 0 1 1 1 3 2 025 0 1 1 1 3 3 0;proc phreg;/*调用phreg过程*/model t*y(0)=x1-x6/*定义模型,以t为时间变量,y为截尾变量,x1-x6为自变量*//selection=stepwise/*选择逐步回归方法筛选变量*/sle=0.1sls=0.1/*入选和剔除的界值均为0.1*/ties=discrete;/*用离散logistic模型替代比例危险模型*/strata i;/*定义区组变量*/run;2.3 应变量为多分类资料的logistic回归data ex16_5;input x1 x2 y f;/*x1是两个社区,x2是性别,Y是获取健康知识途径(传统大众媒介=1,网络=2,社区宣传=3,f为频数)*/cards;0 0 1 200 0 2 350 0 3 260 1 1 100 1 2 270 1 3 571 0 1 421 02 171 1 1 161 12 121 1 3 26;proc logistic;freq f;/*定义频数变量为f*/model y(ref='3')/*定义模型,以y为因变量,ref语句指时参照的类别为“社区宣传”,最后得到结果均为与“社区宣传”相对应*/=x1 x2/*定义x1和x2为自变量*//link=glogit;/*指定多分类应变量回归模型*/run;四:生存分析4.1乘积极限法估计生存率,例17-2甲、乙两种手术方法的生存率估计data ex17_2;input t d@@;/*确定变量名称,t为时间变量,d为截尾变量*/cards;1 13 15 15 15 16 16 16 17 18 110 110 114 017 119 020 022 026 034 134 044 159 1;proc lifetest;/*调用lifetest过程*/time t*d(0);/*定义模型,以t为时间变量,d为截尾变量,变量值为0表示截尾数据*/ run;4.2寿命表法估计生存率data ex17_3;input t d f@@;cards;0 0 00 1 4561 0 391 1 2262 0 222 1 1523 0 233 1 1714 0 244 1 1355 0 1075 1 1256 0 1336 1 837 0 1027 1 748 0 688 1 519 0 649 1 4210 0 4510 1 4311 0 5311 1 3412 0 3312 1 1813 0 2714 0 3314 1 615 0 2015 1 0;proc lifetest method=life/*调用lifetest过程,指定用寿命表法估计生存率*/ width=1;/*表示每间隔1估计生存率*/freq f;/*表示以f为频数变量*/time t*d(0);/*定义模型,以t为时间变量,d为截尾变量,变量值为0表示截尾数据*/ run;4.3生存曲线比较的log-rank检验及制作生存曲线data ex17_4;input t d g @@;cards;1 1 13 1 15 1 15 1 15 1 16 1 16 1 16 1 17 1 18 1 110 1 110 1 114 0 117 1 119 0 120 0 122 0 126 0 131 0 134 1 134 0 144 1 159 1 11 1 21 1 22 1 23 1 23 1 24 1 24 1 24 1 26 1 26 1 28 1 29 1 29 1 210 1 211 1 212 1 213 1 215 1 217 1 218 1 2;proc lifetest plot=(s);/*调用lifetest过程并做生存曲线图*/ time t*d(0);strata g;/*定义变量g为分组变量*/run;4.4.cox回归分析data ex17_5;input x1-x6 t y @@;cards;54 0 0 1 1 0 52 057 0 1 0 0 0 51 058 0 0 0 1 1 35 143 1 1 1 1 0 103 048 0 1 0 0 0 7 140 0 1 0 0 0 60 044 0 1 0 0 0 58 036 0 0 0 1 1 29 139 1 1 1 0 1 70 042 0 1 0 0 1 67 042 0 1 0 0 0 66 042 1 0 1 1 0 87 051 1 1 1 0 0 85 055 0 1 0 0 1 82 052 1 1 1 0 1 74 0 48 1 1 1 0 0 63 0 54 1 0 1 1 1 101 0 38 0 1 0 0 0 100 0 40 1 1 1 0 1 66 1 38 0 0 0 1 0 93 0 19 0 0 0 1 0 24 1 67 1 0 1 1 0 93 0 37 0 0 1 1 0 90 0 43 1 0 0 1 0 15 149 0 0 0 1 0 3 150 1 1 1 1 1 87 0 53 1 1 1 0 0 120 0 32 1 1 1 0 0 120 0 46 0 1 0 0 1 120 043 1 0 1 1 0 120 044 1 0 1 1 0 120 0 62 0 0 0 1 0 120 0 40 1 1 1 0 1 40 1 50 1 0 0 1 0 26 1 33 1 1 0 0 0 120 0 57 1 1 1 0 0 120 0 48 1 0 0 1 0 120 0 28 0 0 0 1 0 3 1 54 1 0 1 1 0 120 1 35 0 1 0 1 1 7 1 47 0 0 0 1 0 18 1 49 1 0 1 1 0 120 0 43 0 1 0 0 0 120 0 48 1 1 0 0 0 15 1 44 0 0 0 1 0 4 1 60 1 1 1 0 0 120 0 40 0 0 0 1 0 16 1 32 0 1 0 0 1 24 1 44 0 0 0 1 1 19 1 48 1 0 0 1 0 120 0 72 0 1 0 1 0 24 1 42 0 0 0 1 0 2 1 63 1 0 1 1 0 120 0 55 0 1 1 0 0 12 1 39 0 0 0 1 0 5 1 44 0 0 0 1 0 120 0 42 1 1 1 0 0 120 061 0 1 0 1 0 40 145 1 0 1 1 0 108 038 0 1 0 0 0 24 162 0 0 0 1 0 16 1;proc phreg;model t*y(1)=x1-x6/*定义模型,以t为时间变量,y为截尾变量,变量值1表示截尾数据,x1-x6为危险因素*//selection=stepwisesle=0.05sls=0.05;run;五:判别和聚类分析5.1判别分析data ex18_4;input x1-x4 g; /*确定变量名称,x1-x4为用于进行判别分析的指标,g为分组变量*/ cards;6.0 -11.5 19 90 1-11.0 -18.5 25 -36 390.2 -17.0 17 3 2-4.0 -15.0 13 54 10.0 -14.0 20 35 20.5 -11.5 19 37 3-10.0 -19.0 21 -42 30.0 -23.0 5 -35 120.0 -22.0 8 -20 3-100.0 -21.4 7 -15 1-100.0 -21.5 15 -40 213.0 -17.2 18 2 2-5.0 -18.5 15 18 110.0 -18.0 14 50 1-8.0 -14.0 16 56 10.6 -13.0 26 21 3-40.0 -20.0 22 -50 3;proc discrim;class g;/*定义分组变量为g*/var x1-x4;/*定义用于分析的指标变量为x1-x4*/run;(结果横向是真实值,竖向的预测值)5.2逐步判别分析data ex18_5;input x1-x4 g;cards;6.0 -11.5 19 90 1-11.0 -18.5 25 -36 390.2 -17.0 17 3 2-4.0 -15.0 13 54 10.0 -14.0 20 35 20.5 -11.5 19 37 3-10.0 -19.0 21 -42 30.0 -23.0 5 -35 120.0 -22.0 8 -20 3-100.0 -21.4 7 -15 1-100.0 -21.5 15 -40 213.0 -17.2 18 2 2-5.0 -18.5 15 18 110.0 -18.0 14 50 1-8.0 -14.0 16 56 10.6 -13.0 26 21 3-40.0 -20.0 22 -50 3;proc stepdisc /*调用stepdisc过程*/slentry=0.2/*确定入选标准为0.2*/slstay=0.3;/*确定剔除标准为0.3*/class g;/*定义分组变量为g*/var x1-x4;/*定义用于分析的指标变量为x1-x4*/run;(筛选出变量后,调用discrim过程对筛选出的变量作判别分析,即先做5.2再做5.1)5.3作样品聚类和指标聚类data ex19_3;input x1-x9;cards;46 25 5 2138 1.68 0.35 8.11 4 4 35 12 20 3510 2.76 1.43 6.84 3 3 52 25 20 2784 2.19 0.54 4.11 3 3 32 7 20 2451 1.93 0.47 11.45 9 6 38 22 0 3247 2.56 0.80 11.68 5 5 51 31 30 3710 2.92 0.37 11.60 2 2 40 9 10 3194 2.51 0.40 11.40 5 5 34 17 20 4658 3.67 0.46 11.35 3 3 50 29 0 5019 3.95 0.47 13.45 10 8 42 20 20 7482 5.89 0.12 13.11 0 0 57 30 15 3800 2.99 0.19 10.76 2 236 15 20 2478 1.95 0.25 10.00 0 037 12 0 3827 3.01 0.82 10.50 4 4 52 32 0 2984 2.35 0.16 11.15 3 3 52 32 10 3749 2.95 0.72 11.45 11 10 42 27 30 4941 3.89 0.73 13.80 7 6 44 27 20 3948 3.11 0.33 13.65 16 14 40 21 5 3360 2.64 0.37 11.40 0 0 38 21 5 2936 2.31 0.69 11.40 1 1 44 27 20 6851 5.39 0.99 12.28 7 6 43 27 0 3926 3.09 0.47 11.95 0 0 26 10 3 4381 3.45 0.52 11.80 7 5 37 18 20 7142 5.62 0.85 11.81 5 5 28 9 20 2612 2.06 0.37 11.65 1 1 25 9 30 2638 2.08 0.78 12.25 1 1 34 14 20 4322 3.40 0.41 15.00 5 5 50 32 20 2862 2.25 0.69 8.80 2 2;proc cluster/*调用cluster过程*/method=average;/*采用类平均法进行聚类*/var x1-x9;/*定义用于分析的指标变量x1-x9*/run;proc treegraphics haxis=axis1 horizontal;/*调用tree过程输出聚类图,并将图横向输出*/ run;/*对各个指标聚类,即对9个变量聚类*/proc varclus;/*调用varclus过程*/var x1-x9;/*定义用于分析的指标变量x1-x9*/run;六、主成分分析和因子分析6.1主成分分析data ex20_1;input x1-x6;cards;92 77 80 95 99 12697 75 77 80 95 12595 80 70 78 89 12075 75 73 88 98 11092 68 72 79 88 11390 85 80 70 78 10372 93 75 77 80 10088 70 76 72 81 10264 70 69 85 93 10570 73 70 87 84 10078 69 75 73 89 9778 72 71 68 75 9675 64 63 76 73 9284 66 77 55 65 7670 64 51 60 67 8858 72 75 62 52 7582 73 40 50 48 6145 65 42 47 43 60;proc princomp;/*调用princomp过程,对6个变量做主成分分析,结果包括主成分累积贡献率,特征向量矩阵*/run;6.2因子分析data ex20_2;input x1-x9;cards;4.34 389 99.06 1.23 25.46 93.15 3.56 97.51 61.663.45 271 88.28 0.85 23.55 94.31 2.44 97.94 73.334.38 385 103.97 1.21 26.54 92.53 4.02 98.484.18 377 99.48 1.19 26.89 93.86 2.92 99.41 63.164.32 378 102.01 1.19 27.63 93.18 1.99 99.71 80.004.13 349 97.55 1.10 27.34 90.63 4.38 99.03 63.164.57 361 91.66 1.14 24.89 90.60 2.73 99.69 73.534.31 209 62.18 0.52 31.74 91.67 3.65 99.48 61.114.06 425 83.27 0.93 26.56 93.81 3.09 99.48 70.734.43 458 92.39 0.95 24.26 91.12 4.21 99.76 79.074.13 496 95.43 1.03 28.75 93.43 3.50 99.10 80.494.10 514 92.99 1.07 26.31 93.24 4.22 100.00 78.954.11 490 80.90 0.97 26.90 93.68 4.97 99.77 80.533.53 344 79.66 0.68 31.87 94.77 3.59 100.00 81.974.16 508 90.98 1.01 29.43 95.75 2.77 98.72 62.864.17 545 92.98 1.08 26.92 94.89 3.14 99.41 82.354.16 507 95.10 1.01 25.82 94.41 2.80 99.35 60.614.86 540 93.17 1.07 27.59 93.47 2.77 99.80 70.215.06 552 84.38 1.10 27.56 95.15 3.10 98.63 69.234.03 453 72.69 0.90 26.03 91.94 4.50 99.05 60.424.15 529 86.53 1.05 22.40 91.52 3.84 98.58 68.423.94 515 91.01 1.02 25.44 94.88 2.56 99.36 73.914.12 552 89.14 1.10 25.70 92.65 3.87 95.52 66.674.42 597 90.18 1.18 26.94 93.03 3.76 99.28 73.813.05 437 78.81 0.87 23.05 94.46 4.03 96.223.94 477 87.34 0.95 26.78 91.784.57 94.28 87.344.14 638 88.57 1.27 26.53 95.16 1.67 94.50 91.673.87 583 89.82 1.16 22.66 93.43 3.55 94.49 89.074.08 552 90.19 1.10 22.53 90.36 3.47 97.88 87.144.14 551 90.81 1.09 23.06 91.65 2.47 97.72 87.134.04 574 81.36 1.14 26.65 93.74 1.61 98.20 93.023.93 515 76.87 1.02 23.88 93.82 3.09 95.46 88.373.90 555 80.58 1.10 23.08 94.38 2.06 96.82 91.793.62 554 87.21 1.10 22.50 92.43 3.22 97.16 87.773.75 586 90.31 1.12 23.73 92.47 2.07 97.74 93.893.77 627 86.47 1.24 23.22 91.17 3.40 98.98 89.80;proc factor/*调用factor过程*/n=4;/*确定因子数为4,如果不写就默认为3*/run;proc factorn=4rotate=quartimax;/*因子旋转的方法为四次方最大正交旋转*/run;七、典型相关分析data ex21_1;input x1-x4 y1-y4;cards;1210 120.1 23.8 61.0 10.2 66.3 2.01 2.731210 120.7 23.4 59.8 11.3 67.6 1.92 2.711040 121.2 22.9 59.0 10.1 66.5 1.92 2.601620 121.5 24.6 59.5 9.5 67.8 1.95 2.641690 122.5 24.4 60.7 11.0 69.2 2.08 2.641150 122.7 27.2 64.5 10.5 69.1 2.19 2.841460 123.3 24.9 58.4 10.5 69.0 2.01 2.72 1190 123.4 21.8 59.0 10.6 67.4 1.90 2.71 1840 123.9 23.5 60.2 9.6 67.1 2.00 2.84 1250 124.5 25.2 63.0 11.2 67.8 2.05 2.78 1480 124.8 22.3 58.1 10.7 67.9 2.05 2.73 1310 124.9 22.0 58.0 10.5 67.8 1.98 2.68 1660 125.3 24.7 60.0 10.8 69.3 1.95 2.80 1580 125.6 22.8 59.0 9.4 69.1 2.00 2.65 1460 125.8 25.7 61.0 10.2 69.6 1.95 2.70 1240 126.0 30.2 68.0 9.2 67.1 2.14 2.88 1100 126.2 25.2 60.5 9.8 68.4 1.98 2.72 1250 126.8 23.6 58.5 10.2 67.5 1.94 2.74 1270 127.1 23.0 57.7 10.8 69.8 1.90 2.78 1300 127.6 24.3 59.0 10.3 67.9 1.93 2.84 1350 127.7 24.1 60.0 11.0 69.7 2.03 2.77 1250 128.3 21.6 55.5 10.4 68.5 1.83 2.70 1720 128.5 27.1 62.0 11.4 71.2 2.03 2.75 1480 128.5 22.6 57.4 10.0 67.3 2.04 2.83 1380 129.4 24.9 60.5 11.5 69.8 2.04 2.76 1170 129.0 26.7 63.7 9.6 67.4 2.13 2.98 1640 129.8 26.1 62.0 9.8 71.0 2.00 2.84 1640 131.6 28.7 62.8 9.7 70.7 1.89 2.89 1150 130.2 25.0 58.6 10.5 71.8 1.96 2.78 1430 130.5 26.1 60.7 10.8 68.6 2.05 2.77 1150 130.6 23.4 54.4 11.8 69.2 1.96 2.78 1150 131.4 25.5 63.2 10.2 70.4 2.05 2.84 1320 131.6 25.6 58.9 10.9 70.2 2.06 2.86 1360 131.7 27.4 62.0 10.9 73.5 1.99 2.70 1460 132.0 26.3 61.5 11.1 71.2 2.17 2.13 1380 132.2 25.7 61.4 10.1 70.1 1.96 2.83 1300 132.5 24.5 57.0 10.8 71.8 2.02 2.84 1220 132.7 27.0 61.3 10.1 72.2 2.08 2.80 1320 132.9 25.2 60.5 11.2 73.1 2.01 2.73 1910 133.1 30.1 67.0 9.0 87.1 2.15 2.97 1800 133.5 26.5 62.5 9.8 71.7 2.07 2.82 1560 133.6 24.8 58.5 10.3 72.2 1.93 2.79 1840 134.0 26.0 60.5 10.4 73.0 1.98 2.74 1470 134.3 28.2 62.0 11.3 87.2 2.66 4.03 1590 134.4 25.5 60.7 9.6 69.9 1.99 2.81 1430 134.1 26.6 63.0 11.2 72.2 2.06 2.90 1760 134.6 32.5 66.0 9.9 87.4 2.61 2.98 1470 135.3 27.9 61.8 10.1 73.3 2.20 2.78 1580 135.6 28.1 65.8 9.8 73.1 2.05 2.891840 137.1 27.6 62.8 9.5 72.4 2.11 2.91 1810 137.4 28.3 62.5 9.4 74.2 2.06 3.00 1850 138.1 29.5 62.4 9.7 72.3 2.12 4.02 2120 140.0 34.9 68.8 9.5 87.9 2.74 4.15 1760 140.7 32.0 64.4 10.2 74.0 2.17 4.05 1800 141.0 32.5 63.8 9.5 88.2 2.65 4.08 1260 141.7 29.1 65.0 9.7 88.2 2.68 2.90 1860 142.4 19.3 70.0 10.1 89.6 2.71 4.06 1800 144.7 27.0 58.3 10.8 74.8 2.10 2.82 1470 136.8 26.3 61.4 10.0 72.2 2.07 2.93 1260 121.1 22.9 59.0 10.6 66.3 2.05 2.76 1570 132.7 25.3 58.6 11.5 73.6 2.16 2.78 1290 125.0 25.7 60.5 10.1 68.8 2.00 2.69 1580 133.2 27.3 60.7 9.6 71.7 2.11 2.85 1690 132.8 28.6 64.7 9.6 72.9 2.19 4.08 1670 131.6 25.4 59.7 10.6 69.8 2.14 2.76 1300 133.1 25.9 58.0 10.1 69.7 2.12 2.83 1610 134.0 25.8 59.6 9.4 70.8 2.10 2.88 1580 134.3 26.3 61.2 10.2 72.2 2.14 2.84 1570 129.1 27.7 62.2 11.1 72.9 2.09 2.93 1660 140.1 32.1 67.0 9.3 87.1 2.15 4.03 1040 132.6 27.9 62.0 10.3 72.5 2.08 2.81 1290 128.3 23.6 58.5 9.3 69.0 1.97 2.76 1980 145.8 34.5 68.0 9.8 89.7 2.68 4.25 1210 133.3 25.6 61.5 9.9 71.0 2.11 2.82 1300 134.3 25.6 61.0 10.5 73.2 2.02 2.83 1310 138.1 27.8 61.2 9.9 73.5 2.09 2.78 1590 135.6 25.9 59.6 9.6 72.8 2.10 2.91 1270 128.3 24.1 58.5 10.3 69.2 1.92 2.77 1310 129.7 24.7 61.7 10.1 69.4 2.03 2.80 2280 143.6 37.6 70.0 9.7 88.8 2.17 4.18 1580 136.6 32.3 67.2 10.3 87.1 2.66 4.04 2370 147.4 38.8 73.0 10.8 90.7 2.82 4.38 ;proc cancorr;/*调用cancorr过程*/var x1-x4;/*定义一组变组变量*/with y1-y3;/*定义另一组变量*/run;。


目录1、数据导入(对于导入数据参见little sas book第二章) (2)1.1创建新逻辑库创建新逻辑库有两种方法: (2)1.2 将你的数据放入SAS*/ (3)1.3用LIBNAME语句使用永久数据集 (3)2、开发数据(参见little sas book第三章) (3)2.1 格式、输入、读取 (3)2.2 用IF THEN DO END 和else if选择数据或选取部分数据 (5)2.3 求取最大值和总值 (6)2.4 累加和累乘 (7)2.5数组处理 (7)练习计算某只股票某段时间的累计收益率和年化收益率(提取数据和计算) (8)3、函数- COMPBL & COMPRESS、 (11)3.1 COMPBL & COMPRESS去掉空格 (11)3.2 INDEX;是找寻后一个变量在前一个变量中的位置 (12)3.3 SCAN提取字串、SUBSTR替换字串 (12)3.4 VERIFY;核实某字符的存在 (13)3.5 UPCASE vs. LOWCASE; (13)3.6 日期时间的显示和计算 (14)3.7 Truncation 用函数处理具体数值 (16)3.8 数据转置 (18)3.9 概率统计与随机抽样函数 (18)练习计算A股股票在2014年的双周收益率序列 (21)4、对表的处理 (22)4.1 表的连接 (22)4.2 表的合并 (24)5、数据查询实例 (27)6、利用宏 (30)6.1 利用宏程序导入股票日交易数据 (30)6.2用宏程序导入两个文本文件的数据并计算两只股票的总收益率和(几何平均)年收益率 (32)6.3 求winners50和losers50(答案) (33)6.4.1定义宏变量 (35)6.4.2引用宏变量 (36)6.4.3 多次引用宏变量 (36)6.4.4 改变宏变量的值 (37)6.4.5 如何隔开宏变量引用和文本 (38)6.4.6 显示宏变量值 (38)6.4.7 间接引用宏变量&& (38)6.4.8 定义宏和调用宏(什么是宏?) (39)6.4.9 宏参数(定义在宏%MACRO语句内的宏变量) (40)6.4.10 宏程序语句和宏函数 (41)1、对于在CSMAR下载的数据,用foxpro格式下载,然后用Stat/Transfer转换成SAS格式;对于在RESSET数据库下载的数据,建议使用下载数据时自动生成的数据导入程序(可能要稍作修改)导入SAS。

sas学习笔记之四——infile常⽤指令使⽤总结infile指令使⽤总结1、FIRSTOBS和OBS指令,FIRSTOBS⽤于指定读⼊数据的起始⾏;OBS⽤于指定读⼊数据的终⽌⾏。
如infile 'c:\temp.txt' FIRSTOBS=2 OBS=100;2、FLOWOVER/MISSOVER/TRUNCOVER/STOPOVER 指令,该指令都⽤于读取记录末尾不完整的数据时使⽤,FLOWOVER是默认选项。
看下⾯的⼏个例⼦sas的help也有这个例⼦外部⽂件d:\test.log的数据为122333444455555分别⽤上⾯指令data num;infile 'd:\test.log' FLOWOVER ;input temp 5.;RUN;1 222 44443 55555结果为,读取时第⼀条不满⾜长度5,移到下⼀⾏数据22读取数据(这是这⾏数据事实上被读⼊),指针⾃然移到第三⾏不满⾜,移到下⼀⾏数据4444读取数据(这是这⾏数据事实上被读⼊),指针移到第5⾏读取55555。
--------------data num;infile 'd:\test.log' missover ;input temp 5.;proc print;RUN;结果1 .2 .3 .4 .5 55555结果为,读取时第⼀条⾄第4条不满⾜长度5,写⼊默认值.,第五条满⾜读⼊。
----------------data num;infile 'd:\test.log' truncover ;input temp 5.;proc print;RUN;结果1 12 223 3334 44445 55555结果为,读取时第⼀条⾄第4条不满⾜长度5,但是将数据读⼊。
----------------data num;infile 'd:\test.log' stopover ;input temp 5.;proc print;RUN;结果会出现错误,第⼀⾏不符合条件,就停⽌读⼊。

第一章sas是什么1.SAS系统是一个模块化的集成软件系统;——数据处理和统计领域的国际标准软件;——世界领先的数据分析和信息系统;SAS系统广泛应用于金融、医疗、运输、通迅、政府、科研和教育等领域;SAS含义Statistical Analysis System2.SAS系统的主要四大功能数据访问数据管理数据分析数据呈现3.SAS系统对50多种数据源提供了引擎,如:DB2 和Oracle-------------------------------------------第二章开始sas程序的讲解1.sas程序的介绍有两种程序步组成,数据步和过程步,每个步通常有若干个SAS语句组成;数据步:以data语句开始,用于创建和处理SAS数据集;过程步:以proc语句开始,主要用户处理SAS数据集;2.SAS数据集通常分为两个部分:描述部分(包含数据属性的信息)和数据部分(包含数值);数据集的列称为变量(Variable),行称为观测(Observation)。
查看数据集的描述部分:proc contents data=sas_data_set;run;查看数据集的数据部分:proc print data=sas_data_set;run;4.SAS变量的类型*字符型变量(Character Variable )(1-32767字节),均以字母、下划线开头;字符型变量的缺省数据用空格表示;*数值型变量(Numerical Variable )默认为8个字节的长度,数值型变量的缺省数据用点(.)表示;5.变量的命名规范:1-32个字符长度,不区分大小写,以下划线或字母开头-------------------------------------------第三章sas数据仓库1.每次SAS启动都自动生成三个库标记:WORK、SASUSER和SASHELP;2.库的分类永久性库:sasuser、sashelp、自定义的库临时性库:只有一个,名为WORK,可以省略库标记;每次启动SAS自动生成,结束SAS后库中的数据被自动删除;用libname指定库标记,如:libname temp“e:\temp\data”;3.使用关键词_ALL_列出数据仓库中所有的sas文件,使用NODS option来禁止对数据集的描述PROC CONTENTS DATA=libref._ALL_ NODS;RUN;注意:NODS选项只能和_ALL_一起联用-------------------------------------------第四章数据列表报表1.print过程语法格式:proc print data=SAS数据集noobs;var 分析变量1 分析变量2 ... 分析变量n;where 表达式;sum 求和变量;run;Noobs选项:在PRINT过程中可以用NOOBS选项去掉OBS列;VAR语句:控制变量的出现与否以及出现的顺序;WHERE语句:控制哪些观测将出现在报表中;它的表达式主要是操作数和操作符,SUM语句:计算变量的总合;2.观测的排序和分组§(sort)和(by)对数据进行分组并求每组小计,用PRINT过程的BY语句,但必须先对相应的变量进行排序;如:proc sort data=temp.empdata out=temp.empdata2;By JobCode;Run;proc print data=temp.empdata;by JobCode;sum Salary;pageby JobCode; /*使产生的报表按组分页*/run;-------------------------------------------第五章:输出1.标题和脚注:在所有的SAS报告中都可以加标题(Title)和脚注(Footnote):语法格式:TITLEn ‘text’;FOOTNOTEn ‘text’;特点:n 的取值范围是1-10;标题出现在每页的顶部;脚注出现在每页的底部;如果没有定义标题,缺省的标题是:“The SAS System”;如果没有脚注就不出现;没有n的标题和脚注就是:TITLE1、FOOTNOTE1;定义的标题和脚注一直有效,知道另一个语句被执行;带n的标题或脚注被执行后,替代了原先具有同样号码的标题和脚注;带n的标题或脚注被执行后,取消了更大号码的标题和脚注;BEL语句:产生用户化和容易阅读的表头:如:label 变量1=’标签’变量2=’标签’;属性:是最大长度为256个字符串;注意:在PRINT过程中必须用PRINT语句中的LABEL或SPLIT=选项才能被显示;在过程步中定义只在该过程中有效;在数据步中定义就被存在数据集的描述部分与数据集一直有效;3.format的使用分类:系统format和用户自定义format4.用户自定义format的使用format变量的语法格式:<$>format<w>.<d>在VALUE语句中,格式可以赋予为:A.单个数字:如:Proc format;Value gender 1=’Female’2=’Male’Other=’Miscoded’;Run;B.某数字范围:如:Proc format;Value boadfmt low-49=’Below’50-99=’Average’100-high=’Above Average’;Run;C.字符或字符串:如:Proc format;Value $grade ‘A’=’GOOD’‘B’-‘D’=’PAID’‘I’,’W’=’POOR’‘PILOT’=’pilot’Other=’Miscoded’;Run;format的使用步骤:第一步:用户创建formatPROC FORMAT;VALUE format-name range1='label 'range2='label '. . . ;RUN;第二步:应用所创建的formatproc print data=ia.empdata;format [$]varialble-name format-name;run;5.使用ODS创建html报表(利用ODS将SAS输出结果生成HTML格式文件)ODS--Output Delivery System语法格式:ODS HTML FILE='HTML-file-specification' <options>; 产生输出的sas代码ODS HTML CLOSE;第六章创建sas数据集1.列输入(column input)*此模式读入外部原始数据文件,适应文件为:数据固定在某些列中;数据只包含标准的数字和字符;*过程:a.开始一个数据步,并给数据步命名b.用infile指明原始数据的存放位置c.用input指明怎样读取原始数据*格式:data 库名.数据集名;infile '文件名(路径)' <选项>;input 变量名<$> 起始列-结束列;($用在变量是字符型) run;2.格式输入(formatted input)*适合用格式输入的外部原始数据文件数据是固定列;但含有标准或者不标准字符以及数字的文件;*语法格式:data SAS数据集;Infile ‘外部原始文件’;INPUT 指针控制变量名<$> 格式名;($表示字符型变量)Run;*指针的控制:@n 移动指针到第几列(绝对位置)+n 把指针移动几个位置(相对位置)3.输入格式informat<$>informat-namew.<d>说明:$ 如果是字符型,使用$informat-name是输入格式的格式名w 是变量总长度. 句点是必修的分隔符,不能缺少d 如果是数值型的话, d指定了小数位的长度4.分配变量属性变量的临时属性和永久属性:PROC步可赋予临时属性:其中的标签只在该步显示时有,并没存在数据集里;如:proc print data=temp.dfwlax label;Label Dest=’Destination’FirstClass=’First Class Passengers’;Run;DATA步可赋予永久属性:其中的标签被存在数据的描述部分,与数据集一起存在;如: data temp.dfwlax;Infile ‘‘c:\course\tempdata.dat’;Input @12 Dest $3. @15 FirstClass $3. ;Label Dest=’Destination’FirstClass=’First Class Passengers’;Run;---------------------------------------------------------------------------------------第七章数据步程序设计1.读sas数据集以及创建变量用DATA步产生SAS数据集的三种方法:A.数据在作业流中:DATA 语句;INPUT 语句;CARDS;数据行;;RUN;B.数据在磁盘上:DATA 语句;INFILE 语句;INPUT 语句;RUN;C.数据来自其它SAS数据集:DATA 语句;SET / MERGE / UPDATE / MODIFY语句;<DATA步中的其它SAS语句>;RUN;2.用已有的数据集创建另一个数据集[set的使用]DATA 新的数据集名;SET input-SAS-data-set;<additional SAS statements>RUN;3.sas操作符和函数的使用语法格式:function-name(argument1,argument2, . . .)函数:sum(argument1,argument2, . . .);TODAY();MDY(month,day,year);QTR(SAS-date);MONTH(SAS-date);WEEKDAY(SAS-date);4.有条件的程序语法结构:简单if语句IF expression THEN statement;ELSE statement;复杂if语句IF expression THEN DO;executable statementsEND;ELSE DO;executable statementsEND;设置变量长度LENGTH variable(s) $ length;取数据集子集a.WHERE语句b.DELETE语句IF expression THEN DELETE;c.子集IF语句IF expression;使用sas日期常数格式:'ddMMMyyyy'd例如:(example: '14dec2000'd)说明:'d是必须的,用来把引号里的字符串转换成sas日期-------------------------------------------------------------------------------------------- 第八章数据拼接1.使用set连接sas数据集语法格式:DATA SAS-data-set ;SET SAS-data-set1 SAS-data-set2 . . . ;<additional SAS statements>RUN;set中变量重命名语法格式:SAS-data-set(RENAME=(old-name-1=new-name-1old-name-2=new-name-2 ...old-name-n=new-name-n));交叉sas数据集,使用by语句BY语句:使用BY语句可使生成的数据集按某变量排序,但输入数据集必先按该变量排序过;语法格式:DATA SAS-data-set;SET SAS-data-set1 SAS-data-set2 . . . ;BY BY-variable;<other SAS statements>RUN;2.MERGE sas数据集(必先排序)MERGE语法格式:DATA SAS-data-set;MERGE SAS-data-sets;BY BY-variable(s);<additional SAS statements>RUN;IN= 选项格式:SAS-data-set(IN=variable)解释:一个临时的数字类型的变量,其值为0或者1IN选项,当读入多个SAS数据集时,用IN选项可确定本观测来自哪个数据集;variable=0表示观测不是来自本数据集variable=1表示观测是来自本数据集-------------------------------------------第九章制作汇总报表1.基本的汇总报表(freq、mean)freq报表默认的情况下:分析每一个变量,显示出每一个数据值,计算出数字类型的每列的百分比,指出每一个变量有多少条观测中有缺失值用此过程一般有两个目的:1:描述过程:产生频数表和交叉表,可简洁的描述数据;2:统计过程:产生各种统计量(频数、百分比),分析变量间关系;使用:A.单项频数表:PROC FREQ DATA=SAS数据集;TABLES 变量;RUN;B.双向交叉表:PROC FREQ DATA=SAS数据集;TABLES 行变量*列变量;RUN;C.n向交叉表:PROC FREQ DATA=SAS数据集;TABLES a*b*c*d;RUN;如果要一张三向(或n向)交叉表,只要在TABELS语句中用星号将3个(或n个)变量名连接起来。

目录第一章SAS宏功能 (2)一宏变量的定义和使用 (2)1. 宏变量的定义: (2)2. 宏变量的使用 (2)3. 进一步介绍 (2)二宏程序 (2)1. 简单宏定义 (2)2. 含参数的宏 (3)3. 宏中的语句 (3)三引用外部sas程序 (3)第二章SAS绘图 (4)一散点图和连线图 (4)1. 单线图 (4)2. 多个图形的画法 (4)3. 将多个图形放在一起 (5)①使用overlay (5)②使用plot2语句 (5)二柱状图和饼图 (5)1. 制作基本的汇总图 (5)①gchart的一般形式: (5)②设定分析变量和统计量 (6)③显示统计量的数值 (6)2.柱状图 (6)①坐标轴的修饰 (6)②花纹修饰 (7)3.饼图 (7)①颜色与花纹 (7)②加入分类变量以及统计量的值 (7)③突出与归并某些类 (8)第一章 SAS 宏功能一 宏变量的定义和使用1. 宏变量的定义:使用%put _automatic_显示所有自动宏变量。
2.用户自定义宏变量%let 变量名=值;注:数学表达式不进行赋值;带引号的字符串,引号作为字符串的一部分。
例:%let name=1;%let start=;2. 宏变量的使用&宏变量名例: &name3. 进一步介绍%str(自变量): 引用括号中的项.如: %str (data =dst.a;set dst.a;run ;); %eval(自变量):括号中的值计算后赋值。
二 宏程序1. 简单宏定义使用:%宏名称2. 含参数的宏引用:%宏名称(参数1,参数2,…);3. 宏中的语句1.文本中含多个语句,则2.3.4.三 引用外部sas 程序 %include 文件夹名(‘文件名’);如:%include dst(a.sas);这说明引用C:\windows\system32\dst\a.sas 这个文件。
第二章 SAS 绘图一 散点图和连线图1. 单线图v:符号,缺省为加号;c :符号和线的颜色cv :符号的颜色ci :线的颜色(black, red, green, blue, cyan, magenta, gray, pink, orange, brown, yellow) h :符号的大小(pt ,pct ,cm ,cell ),缺省值为1celll :先的序号,1:实线,2:虚线,最大为46.缺省值为1.w: 线的宽度pointlabel :点附近标明Y 轴变量值title n 选项 ‘标题字符串’;如:title f=swiss c=red ‘asdfaf ’; f/font :字体。

NOTE: 从数据集 DATA.HF000012 读取了 124 个观测。
WHERE (date>='01AUG2006'D) and (tvolume>=100000) and (tprice>0); NOTE: 数据集 EX.BLOCK 有 124 个观测和 31 个变量。
NOTE: "DATA 语句"所用时间(总处理时间):实际时间 0.15 秒CPU 时间 0.10 秒可见 if语句是先读取数据然后再选择符合要求的观测而where语句则是直接读入满足条件的观测〓★作业 3.2 先用select语句再用 where语句〓★作业3.4〓★第一题〓d d a a t t a a ex.hm3_4_1(keep=date prevclpr oppr clpr color fluctuate); informat color $6.;★老师加的默认长度是多少呢?〓se t data.stk000001;fluctuate=(clpr-prevclpr)/prevclpr;★可以放在if语句后〓if oppr>clpr then color='red';if oppr<clpr then color='green';run;★if还可以写成这样:proc sort data=ex.blocktrade;★老师的做法接在第一步后〓by date;run;d d a a t t a a num;set ex.blocktrade;by date;if first.date then num=0;num+1;if last.date;keep date num;run;merge ex.blocktrade num(in=id); by date;if id=1;run;do n=1to50;t=t*2*n;output;end;run;★作业3.5〓★第一题〓★第二题〓d d a a t t a a ex.derivative;array s(0:20) s_0-s_20;do i=1to1000;s_0=17.18;do j=0to19;s(j+1)=s(j)*exp((0.03-0.15**2/2)*0.05+0.15*sqrt(0.05)*rannor(0)); end;output;end;drop i j;run;d d a a t t a a ex.average_derivative;set ex.derivative;if min(of s_1-s_20)<15then value=(18- min(of s_1-s_20))*exp(-0.03*1);★这里不确定value中所用的t值是否应为1〓if min(of s_1-s_20)>=15then value=0;run;★作业3.5〓★老师的答案〓★a)〓d d a a t t a a ex.ex3_5_1;array S(0:20) S_0-S_20;do i=1to1000;S_0=17.18;do j=0to19;S(j+1)=S(j)*exp((0.03-0.15**2/2)*0.1+0.15*sqrt(0.05)*rannor(0));end;output;end;drop i j;run;run;★b)〓d d a a t t a a ex3_5_3;set ex3_5_1;array S(0:20) S_0-S_20;do j=0to20;if S(j)<=15then leave;end;if j=21then value=0;else do;payoff=18-S(j);value=payoff*exp(-0.03*j*0.05);end;drop j payoff;run;(注:可编辑下载,若有不当之处,请指正,谢谢!)。
SAS学习笔记30SAS各种常⽤随机函数
UNIFORM(seed)产⽣(0,1)区域均匀分布随机数,乘同余发⽣器
RANUNI(seed)产⽣(0,1)区域均匀分布随机数,素数模发⽣器
NORMAL(seed)产⽣标准正态分布随机数,利⽤中⼼极限定理近似公式RANNOR(seed)产⽣标准正态分布随机数,利⽤变换抽样法
RANEXP(seed)产⽣λ=1的指数分布随机数
RANGAM(seed, alpha)产⽣伽马分布随机数,alpha>0,seed为任意数值
RANTRI(seed, h)产⽣三⾓分布随机数,0<h<1,seed为任意数值
RANCAU(seed)产⽣标准柯西分布随机数
RANBIN(seed, n, p)产⽣⼆项分布随机数,n>0的整数,0<p<1,seed为任意数值RANPOI(seed, lambda)产⽣泊松分布随机数,lambda>0,seed为任意数值
RANTBL(seed, p1, …, …pn)产⽣离散分布随机数,0≤p i≤1,seed为任意数值。
SAS入门笔记SAS入门之一:SAS语言构成一、SAS语句:两类:●数据步:生成数据集、计算、整理数据和自编程计算。
自己用SAS编程序进行计算主要在数据步中进行。
以DATA语句开头,以RUN语句结尾。
DATA步中可以使用INPUT、CARDS、INFILE 、SET、MERGE等语句指定数据来源输入数据,也可以用赋值、分支、循环等编程结构直接生成数据或对输入的数据进行修改。
●过程步:调用SAS已编好的处理过程对数据进行处理,对数据进行分析、报告二、SAS表达式几种常量:●数值型:12,-7.5,2.5E-10 日期、时间等变量存为数值型●字符型:'Beijing',"Li Ming","李明"●日期型:'13JUL1998'd●时间型:'14:20't●日期时间型:'13JUL1998:14:20:32'dt●SAS中用一个单独的小数点来表示缺失值常量变量长度规定:LENGTH 变量名$ 长度;LENGTH name $ 20;运算符:●算术运算符:+-* / **●比较运算符:=^=> < >=<=INEQ NE GT LT GE LEIN的用法:prov in ('Beijing', 'Tianjin', 'Shanghai', 'Chongqing')●逻辑运算符:&(AND) |(OR) ^(NOT)复杂的逻辑表达式最好用括号表示其运算优先级以免误记优先规则并可利于阅读程序。
●其他运算符:|| 连接两个字符串<> 用于取两个运算值中较大一个(比如3<>5结果为5)用于取两个运算值中较小一个的>< (比如3><5结果为3)SAS入门之二:SAS用作一般高级语言(1)●DATA●赋值语句:isfem = (sex='女'); /*生成一个取值为0或1的变量,性别为女时为1,否则为0。
SAS数据分析笔记1.SASINSIGHT启动:方法1:Solution→Analysis→InteractiveDateAnalysis方法2:在命令栏内输入insight方法3:程序编辑窗口输入以下代码,然后单击Submit按钮;Procinsight;Run;1.1一维数据分析用sasinsight做直方图、盒形图、马赛克图。
直方图:Analysis→Histogram/BarChart盒形图:Analysis→Boxplot马赛克图:Analysis→Boxplot/Mosaicplot(Y)1.2二维数据分析散点图:Analysis→Scatteryplot(YX)曲线图:Analysis→Lineplot(YX)1.3三维数据分析旋转图:Analysis→RotationgPlot曲面图:Analysis→RotationgPlot设置FitSurface等高线图:Analysis→Countorplot1.4分布分析包括:直方图、盒形图、各阶矩、分位数表,直方图拟合密度曲线,对特定分布进行检验。
1.4.1Analysis→Distribution(Y)第一部分为盒形图,第二部分为直方图,第三部分为各阶矩,第四部分为分位数表。
1.4.2添加密度估计A:参数估计:给出各种已知分布(正态,指数等),只需要对其中参数进行估计;Curves→ParametricDensityB:核估计:对密度函数没有做假设,曲线性状完全依赖于数据;Curves→KernelDensity1.4.3分布检验Curves→CDFconfidencebandCurves→TestforDistribution1.5曲线拟合Analysis→Fit(YX):分析两个变量之间的关系1.6多变量回归Analysis→Fit(YX)1.7方差分析Analysis→Fit(YX)1.8相关系数计算Analysis→Multivariate1.9主成分分析Analysis→Multivariate2.SASANAL YST启动:方法1:Solution→Analysis→Analyst方法2:在命令栏内输入analyst2.1分类计算统计量:Data→Summarizebygroup2.2随机抽样:Data→RandomSample2.3生成报表:Report→Tables2.4变量计算:Date→Transform2.5绘制统计图2.5.1条形图:Graph→BarChart→Horizontal2.5.2饼图:Graph→PieChart2.5.3直方图:Graph→Histogram2.5.4概率图:Graph→Probalityplot2.5.5散点图:Graph→Scatterplot2.6统计分析与计算2.6.1计算描述性统计量Statistics→Descriptive→SummartStatistics只计算简单统计量Statistics→Descriptive→Distribution可计算一个变量的分布信息Statistics→Descriptive→Correlations可计算变量之间的相关关系Statistics→Descriptive→Frequencycounts可计算频数2.6.2列联表分析Statistics→TableAnalysis2.7假设检验2.7.1单样本均值Z检验:检验单样本均值与某个给定的数值之间的关系Statistics→Hypothesistests→One-SampleZ-testforamean2.7.2单样本均值t检验:适用于不了解变量的方差情形推断该样本来自的总体均数μ与已知的某一总体均属μ0是否相等Statistics→Hypothesistests→One-Samplet-testforamean2.7.3单样本比例检验:检验取离散值的变量取某个值的比例Statistics→Hypothesistests→One-Sampletestforaproportion2.7.4单样本方差检验:检验样本方差是否等于给定的值。
/●宏编程技术●/●怎样显示宏变量的值?解释下面的程序;/●注意在解释程序时每一句需要解释且结果要解释●/data_null_; /●通过数据步处理数据,但不建立数据集●/%let a=first; /●建立宏变量a,值为first●/%let b=macro variable; /●用宏程序语句%let定义宏变量,一个%let语句只能定义一个宏变量;%put &a !!! &b !!!; /●‘&宏变量名’引用宏变量的值;%put语句显示宏变量的值,将文本输出到 SAS的日志窗口;/●在log窗口输出 first !!! macro variable !!!●/ run; /●提交程序●/●答 %put是显示宏变量最简单的方法;/●9——解释并调用下面一段宏●/%macro names(name, number); ●定义含参数的宏,宏参数是一种特殊的宏变量;%do n=1%to &number; /●利用宏循环语句循环生成一系列字符串,循环宏变量n从1到&number●/&name&n /●调用宏变量name和宏变量n,生成字符串●/%end; /●结束宏循环语句●/%mend names; /●结束宏names的定义●/%names(sas,6); /●调用宏names●//●11.在数据步中变量x的值赋于给宏变量A时这两种程序都可以吗●/call symput('A',x); ●将变量的值赋于宏变量,一个子程序只能将一个变量的值赋于宏变量;%let A=x; ●%let语句定义的是宏变量的值,调用宏变量A时,相当于调用了字符串x;●答:不可以,应该用call symput('A',x)%let定义的宏变量,其值为赋值符号后面的字符串'X',不会进行变量运算;data a;set data.class nobs=nobs;call symput ('b',nobs);%let a=nobs;%put &a &b; ●从下面的日志窗口的结果可以看出宏变量a的值被定义为字符串‘nobs’而宏变量b的定义为变量nobs的值; run;/● data a;26 set data.class nobs=nobs;27 call symput ('b',nobs);28 %let a=nobs;29 %put &a &b;nobs 1930 run;NOTE: 数字值已转换为字符值,位置:(行:列)。
2013-08-11ice数据分析数据分析1. SAS INSIGHT启动:方法1:Solution→Analysis→Interactive Date Analysis方法2:在命令栏内输入insight方法3:程序编辑窗口输入以下代码,然后单击 Submit按钮;Proc insight;Run;1.1 一维数据分析用 sas insight做直方图、盒形图、马赛克图。
直方图:Analysis→Histogram/Bar Chart盒形图:Analysis→Box plot马赛克图:Analysis→Box plot/Mosaic plot(Y)1.2 二维数据分析散点图:Analysis→Scattery plot(Y X)曲线图:Analysis→Line plot( Y X)1.3 三维数据分析旋转图:Analysis→Rotationg Plot曲面图:Analysis→Rotationg Plot设置 Fit Surface等高线图:Analysis→Countor plot1.4 分布分析包括:直方图、盒形图、各阶矩、分位数表,直方图拟合密度曲线,对特定分布进行检验。
1.4. 1 Analysis→Distribution(Y)第一部分为盒形图,第二部分为直方图,第三部分为各阶矩,第四部分为分位数表。
1.4.2 添加密度估计A:参数估计:给出各种已知分布(正态,指数等),只需要对其中参数进行估计;Curves→Parametric DensityB:核估计:对密度函数没有做假设,曲线性状完全依赖于数据;Curves→Kernel Density1.4.3 分布检验Curves→CDF confidence bandCurves→Test for Distribution1.5 曲线拟合Analysis→Fit(Y X):分析两个变量之间的关系1.6 多变量回归Analysis→Fit(Y X)1.7 方差分析Analysis→Fit(Y X)1.8 相关系数计算Analysis→Multivariate1.9 主成分分析Analysis→Multivariate2.SAS ANALYST启动:方法1:Solution→Analysis→Analyst方法2:在命令栏内输入analyst2.1 分类计算统计量:Data→Summarize by group2.2 随机抽样:Data→Random Sample2.3 生成报表:Report→Tables2.4 变量计算:Date→Transform2.5 绘制统计图2.5.1 条形图:Graph→Bar Chart→Horizontal2.5.2 饼图:Graph→Pie Chart2.5.3 直方图:Graph→Histogram2.5.4 概率图:Graph→Probality plot2.5.5 散点图:Graph→Scatter plot2.6 统计分析与计算2.6.1 计算描述性统计量Statistics →Descriptive→Summart Statistics只计算简单统计量Statistics →Descriptive→Distribution可计算一个变量的分布信息Statistics →Descriptive→Correlations可计算变量之间的相关关系Statistics →Descriptive→Frequency counts可计算频数2.6.2 列联表分析Statistics →Table Analysis2.7假设检验2.7.1单样本均值Z检验:检验单样本均值与某个给定的数值之间的关系Statistics →Hypothesis tests→One-Sample Z-test for a mean2.7.2单样本均值t检验:适用于不了解变量的方差情形推断该样本来自的总体均数μ与已知的某一总体均属μ0是否相等Statistics →Hypothesis tests→ One-Sample t-test for a mean2.7.3单样本比例检验:检验取离散值的变量取某个值的比例Statistics →Hypothesis tests→One-Sample test for a proportion2.7.4单样本方差检验:检验样本方差是否等于给定的值。
1. cards与datalinesCards语句与datalines语句可以通用。
如果输入数据中含有分号,可用cards4语句或datalines4语句,同时,数据结尾用4个分号表示数据输入结束。
Cards4例data;input number citation $50.;cards4;1 Berry2 LIN ET AL., 1995; BRADY, 19933 BERG, 1990; ROA, 1994; WILLIAMS, 1992;;;;run;2. Transpose用过SPSS的人都知道,SPSS的数据转置功能还是很强大的,而且很直观,那么SAS 呢?想必SAS那么强大的统计软件也不会落后的。
TRANSPOSE这个功能就可以完成转置功能。
TRANSPOSE过程将一个数据集进行转置,使行变为列而列变为行,也就是使原数据集中样品的观测值变换成新数据集中变量的观测值,而原数据集中变量的观测值则变换成新数据集中样品的观测值。
TRANSPOSE过程的格式如下所示:PROC TRANSPOSE <DATA=input-data-set> <LET> <NAME=name> <OUT=output-data-set> <PREFIX=prefix>;BY <DESCENDING> variable-1 <...<DESCENDING> variable-n> <NOTSORTED>;COPY variable(s);ID variable;IDLABEL variable;VAR variable(s);在PROC TRANSPOSE语句中可能出现的选择项有:1)DA TA=数据集名,用来说明要转置的数据集名,如果省略这一选择,则指定最新建立的数据集。
2)OUT=数据集名,用来说明转置所建立的新数据集名,如果省略这一选择,SAS将按内部程式给出新的数据集名。
一、基本操作Editor窗口打开sas程序(扩展名*.sas)Log窗口Output窗口Explorer窗口Results窗口蓝色绿色SetMergeIf (if。
thendelete)Drop(keep)二、描述性统计1.Proc Formatvalue height 0-50=‘<50’50-60=‘50-60’60-high=‘>60’2. Proc freq data=名字order=freqTables 列表变量名/out=数据集名norow nocol nopercent(table y*x)FormatLabel weight=‘高度’By 变量3. Proc univariate data=名字Var 分析变量Histogram 变量/midpoints=7 to 29 by 24. Proc mens5. Proc gchartVbar竖直或hbar 横向Vbar math / group=sexPie sex/type=percent(以百分数显示)Block math/group=sex图形关键字绘制的图形类型图形关键字绘制的图形类型Block方块图pie饼形图Hbar水平的条形图pie3d三维饼形图6.Proc gplot Plot x*ySymbol value=star color=red 选项 意义取值V alue = 符号 表示点使用的符号 plus, x, star, square, diamond, triangle, hash, y, z, paw, point, dot, circleC olor = 颜色 表示点的符号及连线的颜色black, red, green, blue, cyan,magenta, gray, pink, orange, brown, yellow CV =颜色 专指点的符号的颜色H = n<单位> 指名符号的大小 单位有:cell, cm, pct, pt, in POINTLABEL 在点的附近表明Y 轴变量的值i = 连线方式 指明连线的方式 none, join, spline, needle CI = 颜色 专指连线的颜色L = n n 为线型的序号 0 – 空白线,1 - 实线,2 – 虚线 W idth = nn 表示线的宽度7.proc g3d data=名字 曲面图 Plot x*y=z8.proc gcontour data= 曲面图对应的等高线图 Plot x*y=z/nolegend autolabel三、T 检验 >0.05 接受H0(差异有统计学意义)用于检验两个样本总体均数是否相等 独立的,来自正态分布的总体 定量资料对于两组独立样本的定量资料,要求方差相等,两组资料来自正态总体 用proc univariate Proc meansProc ttest (能提供基本统计量的计算,对单样本资料、配对设计资料和两独立样本进行thbar3d 水平的三维条形图 donut 环形图 Vbar 竖立的条形图 star 星形图 vbar3d竖立的三维条形图检验)第一步,正态性检验 proc univariate normal (夏皮洛威尔克) Var 分析变量Freq 频数变量(频数分布资料时用)Class 分类变量(两组独立资料时用)第二步,proc ttest h0=30(已知的总体均数为30)Var 分析变量( paired x1*x2 配对设计资料时用,检验两组均值是否一致)Freq 频数变量(频数分布资料时用)Class 分类变量(两组独立资料时用)四、方差分析适用于多个样本均数的比较,资料独立,正态,各总体方差相等 方差分析可用于分析主效应,交互效应方差分析方法:完全随机设计方差分析(单因素方差分析)随机区组方差分析(双因素方差分析,无需方差齐性检验) 析因方差分析 重复测量方差分析使用 proc anova(各样本数一样)和proc glm (generalized linear model ) 第一步,正态检验 proc univariate normal Var class 第二步, proc glmClass g 分类变量 (分类变量即自变量,必须为离散型变量) Model x=g (因变量=自变量或自变量之间的交互效应)效应模型, Means g/hovtest snk(means 列出比较组的均数和标准差)(hovtest 各比较组的方差齐性检验,homogeneity of variance test ,默认levene )(snk 进行均数间的多重比较 student Newman keuls )变异来源 自由度 SSMSF组间k-121()ki i i n x x =-∑ SS 1k -组间MS组间组内Lsmeans a*b/tdiff(析因设计资料时用,列出变量或交互效应各水平的均值)(tdiff 表示对变量各水平均值或交互效应各水平均值进行两两比较的t检验)1与2、3、4有差别2与1、4有差别3与1、4有差别4与1、2、3有差别第三步,多重比较五、卡方检验卡方检验是检验观测值的频率分布与理论分布是否吻合的一种统计方法用法有卡方拟合优度检验(根据样本的频率分布检验总体分布是否吻合假定的分布,两个率或两个构成比比较的卡方检验)卡方独立性检验(一份随机样本按两种属性分类,其个体来自第一个变量某类别的概率与来自第二个变量某类别的概率是否独立)Proc freq可进行列联表资料的卡方检验Weight 权重变量(使每个量初始权重为1)Tables 行变量*列变量/expected chisq nocol norow nopercent (exact 表示用fisher’s确切概率法,理论频数小于5)Testp(0.1667,0.1667,0.1667,0.1667)(expected输出各个格子的理论频数)(chisq 进行卡方统计量的计算)N>=40 T>5 普通卡方检验T为理论频数(行*列/总)N>=40 1<=T<5 校正卡方检验N<40 T<1 fisher’s确切概率法卡方:卡方拟合优度检验df=(k-1)/(k-r-1)列联表独立性检验(2X2 2Xc rX2 rXc)配对设计资料的卡方检验( table r*c/agree )六、基于秩次的非参数统计参数统计方法(t检验、方差分析)对总体分布的参数进行估计或检验非参数统计方法不需要对总体分布形状做出任何假定,适用于总体不正态分布、分布未知、正态分布但方差不齐性、分析等级资料SAS过程:单样本、配对资料prco univariate中的signed rank 符号秩和检验(服从正态,t检验)完全随机设计两样本两独立样本proc npar1way中的wilcoxon (exact确切概率法,适用于样本量较少)完全随机设计多样本(单因素)proc npar1way中的kruskal-wallis随机区组设计(双因素)proc rank(计算秩得分)再proc glm(分析秩次)Exact在两样本量相同时,sas以秩和较大者作为统计量进行概率值的计算在两样本量不同时,sas以较小者的秩和进行概率值的计算Z includes a continuity correction of 0.5统计量包含了一个0.5的连续校正多个样本Average scores were used for ties在系列计算中使用了平均得分先用exact test,后用Z(n>50)七、线性相关与回归(因变量为连续型变量)线性相关:研究两个(或多个)随机变量间相互联系的一种统计方法。
(proc corr)为了了解变量间关系的密切程度及方向。
变量都正态分布时,用pearson相关系数r有一个不正态,用spearman等级相关系数rs(统计线性相关关系的存在,是由专业知识给出的,统计软件是根据数据找出具体的直线关系)步骤:绘制散点图计算相关系数对样本的相关系数进行假设检验(原假设:不存在相关关系)3根据p拒绝原假设,所以存在相关关系,且为正相关。
线性回归:研究变量与变量间是否存在线性依存关系。
(原假设:不存在线性关系)(proc reg)因变量为随机变量,自变量为随机、非随机变量。
要求资料满足线性、独立、正态、等方差(line条件)。
步骤:绘制散点图计算回归系数对样本回归系数进行假设检验写出回归方程的表达式方法:向前法,向后法,逐步回归法,全子集法Model y=x/selection=stepwise sle=0.10 sls=0.15 cli clm(值越小,选取变量的标准越严格)Clm总体均数%95的置信区间Cli 个体值%95的置信区间Clb 回归系数%95的置信区间Conf 总体均数%95的置信带Pred 个体值%95的预测带STUDENT.标准化残差八、logistic回归(因变量为分类变量,医学研究中用的比较多)原假设:模型无效Model y=x/selection=stepwise sle=0.10 sls=0.15 stb(要求输出标准化偏回归系数)非条件:Descending因变量由大到小Proc logistic desOR>1 危险因素条件:Strata 分层变量(匹配变量)Model outcome(event=‘1’)=gall hyper(因变量=自变量)(制定用gall hyper作为自变量,按outcomes=1即病例,拟合概率模型)Response profile响应变量的主要信息Model fit statistic模型拟合统计量九、生存分析生存率的估计有寿命表法(LT)和乘积极限法(PL)生存分析基本方法:统计描述非参数统计检验(总体分布形式已知)半参数模型回归分析(部分线性回归模型,经典线性模型和非参数回归模型的一个混合体)参数模型回归分析Cox模型(比例风险模型)Pdf probability denstiny function(概率密度函数)Testing Homogeneity of Survival Curves for days over Strata时间变量day分层曲线的一致性检验The marked survival times are censored observations标记的生存时间是删失观测值的生存时间。