裂区和条区试验的方差分析
- 格式:doc
- 大小:334.00 KB
- 文档页数:14




3因素随机裂区试验设计及其统计分析提出一种新的3因素随机裂区试验设计,给出了自由度与平方和分解方案,以及固定模型、随机模型及2种混合模型的均方构成,同时提出了随机模型误差方差计算方法。
作物科学研究领域,常用3因素试验设计,一般3因素试验有完全随机区组试验、品种多年多点试验和再裂区试验,至今很少有其他的3因素试验设计报道,通用统计软件SPSS\SAS\STATA等也未提供相应分析方法[1-3]。
完全随机区组试验对于栽培研究很不适用,不同的栽培因素如密度、水分管理、施肥方式等,不适合小区操作,但试验面积又不能过大。
再裂区设计,3个因素误差精度不同,主区试验面积最大、误差较大,裂区试验面积较大、误差中等,再裂区试验面积小、误差小、精度高。
如2个栽培因素均要求较大小区,或重要程度均较高,则可以将这2个因素作完全随机组合排列,较适宜操作且有相同试验误差,将2个因素组合作为主区,另一因素对小区面积要求不高,或重要性高,则将其在主区内裂区排列,则该试验设计称为3因素随机裂区设计。
笔者提出了一种新的3因素随机裂区试验设计,给出了自由度与平方和分解方案,以及固定模型、随机模型及2种混合模型的均方构成,同时提出了随机模型误差方差计算方法,以期为生物统计提供新思路。
1 试验设计方法设A、B、C 3个试验因素,分别有a、b、c 3个水平,每水平重复r次。
A、B共ab个组合,将区组划分为a×b个主区,C为副区因素,在每个AB组合主区内裂区排列。
该设计遵循重复、随机排列及局部控制原则。
先按田间肥力梯度划分为r个区组,每个区组划分为a×b个主区,分别随机安排A、B因素的a×b 个组合,每个AB组合构成一个主区,对每个主区再随机排入C因素的c个水平,保证每个主区内均再随机裂区。
播种期、栽插期或水分管理及N、K肥运筹间的主区间以田埂区隔,密度主区间可以走道间隔,品种、种苗处理、药剂处理、移动性弱的P肥运筹适宜作副区因素,副区间以走道间隔。

裂区和条区试验的方差分析1 裂区试验的设计方法在有些多因素随机区组试验设计中,由于情况特殊,我们不能在区组内将所有处理完全随机排列,这些情况导致了随机区组设计的一些推广设计,如裂区设计和条区设计.裂区设计的原理是这样,区组包含一定数目的主小区,主小区又被划分成若干个次级小区.这样一个因素或几个因素的各水平首先配置给主小区,然后另外的一个因子或几个因子配置给次级小区.【例1】牧场试验中的裂区设计。
试验因素有两个,一是牧草品种B:B1、B2、B3,B4、B5、B6,另一个是放牧吃草方式A:A1、A2。
牧草可以在各区组内随机配置来种植,但放牧吃草方式却需要一大片土地,因为小了不够畜群吃。
这样我们采取下列设计方式:在试验设计中,把A1、A2占的区称为主小区,A称为主区因素,把每一个主小区分为6个子区(裂区或副小区),把6个品种随机配置进去,因而把品种B叫子区因素或副因素。
这种试验设计为二裂式裂区试验。
可以看出,在随机区组试验设计中,所有处理A i B j是在一个区组内随机配置的,而在裂区试验中,副因素是在主小区内随机配置的。
在生物科学和农林科学试验中,采用裂区试验设计的例子是不少的,譬如对某作物既要比较几种施肥法,又要比较几种灌溉法,以及这两个因素的交互作用。
各种施肥法可以在较小的副小区田上配置,但各种灌溉法需在较大的主小区上配置。
又如播种期和品种试验,适宜的方法是把同一播期的各品种种在一起,即播种期为主因素,安排在主小区上,而品种为副因素,应随机安排在副小区上。
如果副小区(裂区)内再划分小区,称为再裂区,在其中安排副副因素C,这种安排主因素(A)、副因素(B)和副副因素(C)的试验设计称为三裂式裂区试验。
裂区设计的主要优点在于:a.田间实施比较方便;b.能利用原有的试验地及试验材料,进行深一步的研究;c.某个因子可获得较高的精确度。
但裂区设计的还存在如下主要缺点:a.资料的统计分析比较复杂,不易掌握;b.次要因子的精确度较低。


裂区实验方差分析裂区设计(split–plot design)与两因素随机区组设计近似,但是两者不一样的。
不同点之一是后者在每一区组内A、B两因素的ab次处理是完全随机化的。
而裂区设计的每一区组内A因素先分为a个处理,在每一处理内B因素再分为b个处理。
随机化过程只能在A因素的a个处理和B 因素的b个处理之间进行。
由A因素所划分的A个部分称为主区或整区,每一主区再划分的b个部分称为裂区或副区。
不同点之二是方差分析计算时F值时误差项的选择,裂区设计方差分析时有两个误差项,区组和整区是同一个误差,而裂区和交互作用则用另一个误差项,而二因素随机区组设计方差分析时用一个误差项。
进行裂区试验设计时首先要分清主要因子和次要因子,主要因子是想要获得较高精确度的因子,次要因子是精确度可以低些的因子。
裂区设计的原则是:主要因子的各个水平随机安排在裂区,次要因子的各个水平随机安排在整区,只有这样,主要因子的各水平的重复数才会大大的多于次要因子的各个水平的重复数,才能获得较高的精确度。
1.在同一个区组的各个整区中,随机安排次要因子的各个水平,称为整区处理。
2.在每个整区的各个裂区上随机安排主要因子的各个水平,称为裂区处理。
适用范围: 1.复因子试验中,两个因子要求的精确度不一时,可用裂区设计。
2.各个因子的各个水平需要的面积大小不一时,亦可用裂区设计。
3.在原有的试验的基础上,临时加入一个研究因子时,可用裂区设计。
优点: 1.田间实施比较方便。
2.能利用原有的试验地及试验材料,进行深一步的研究。
3.某个因予可获得较高的精确度。
缺点: 1.资料的统计分析比较复杂,不易掌握。
2.次要因子的精确度较低。
下面以两个因素的裂区设计进行方差分析:设有A、B两个试验因素,A因素有a个水平,安排在整区,B因素有b个水平,安排在裂区,整个试验有n个重复区组。
总变异分解为整区部分和裂区部分,整区部分总平方和(SS1)可分解为区组平方和(SSr)、A因素水平间平方和(SS A)和整区误差平方和(SS eA);裂区部分分解为B因素水平间平方和(SS B)、交互作用AxB 平方和(SS AB)和裂区误差平方和(SS eB)。

132019年/第22期/8月(上)使用Excel 对裂区试验数据进行方差分析韦若勋*吴莉莉(遵义师范学院生物与农业科技学院贵州·遵义563006)摘要目前,使用SPSS 或Excel 对裂区试验的数据进行方差分析有一定的不足。
由此,在Excel 的基础上,将裂区试验的数据处理为主区和副区数据并对其进行有重复观测值的方差分析,并对平方和与自由度再次分解,得到各个主副区各项的方差,最后进行F 检验。
该方法分析的结果与使用SPSS 和传统方法的结果是一致的,但该方法不仅简便,且有助于使用者熟悉方差分析的原理和步骤。
关键词裂区试验方差分析Excle 数据中图分类号:TP319文献标识码:ADOI:10.16400/ki.kjdks.2019.08.007Analysis of Variance Analysis of Split Test Data Using ExcelWEI Ruoxun,WU Lili(College of Biology and Agriculture,Zunyi Normal University,Zunyi,Guizhou 563006)142019年/第22期/8月(上)1.2数据分析和结果分别用Excel 对表2和表3的数据进行有重复观测值的双因素方差分析,结果如表4和表5所示。
从表4方差分析的结果可知,副区部分是由副区B 因素效应、A×B 交互效应和副区误差效应三项构成。
由于平方和与自由度是加性的,因此,可在此基础上进一步分解表4中副区的平方和与自由度。
即将表4中副区分解为B 因素、A×B 以及副区误差三项。
其中,B 因素和A×B 的平方和与自由度可由表5得到;副区误差的平方和由副区总的平方和减去B 因素和A×B 的平方和,为71.500,副区误差的自由度也由副区总的自由度减去B 因素和A×B 的自由度,为18。

实验八、裂区试验设计结果资料的方差分析
一、实验目的:
练习使用电子表格软件(Excel)对裂区设计的试验结果资料进行方差分析。
二、方法和步骤:
(一)、裂区试验设计特点:
(注:上表中A1、A2、A3表示因素A的三个水平,B1、B2、B3、B4表示因素B的四个水平37、15……表示小区的产量。
)
(二)、自由度和平方和的分解:
(三)操作步骤:
例:有一果树试验,主处理为A,分为A1、A2、A3共3个水平,副处理为B,分为B1、B2、B3、B4共4个水平,裂区设计,重复3次(r=3),其田间排列和产量如下表所示,试对结果作方差分析。
具体操作步骤:
1、对原始数据表进行整理,得到两张新表
表-1 A处理和B处理两向表
表-2 区组和A处理两向表
2、“工具”→“数据分析”→“方差分析:可重复双因素分析”→选取
表-1→设置“输入”和“输出”选项
3、“工具”→“数据分析”→“方差分析:可重复双因素分析”→选取表-2→设置“输入”和“输出”选项
4、整理上面两次的结果得到最终方差分析结果
5、算出主处理的F值(F A)和副处理的F值(F B)进行F测验。
附:
1、设置输入单元格数据的有效性
2、自定义Excel的用户界面(工具栏、工具按钮、菜单)
3、工作簿和工作表的保护。

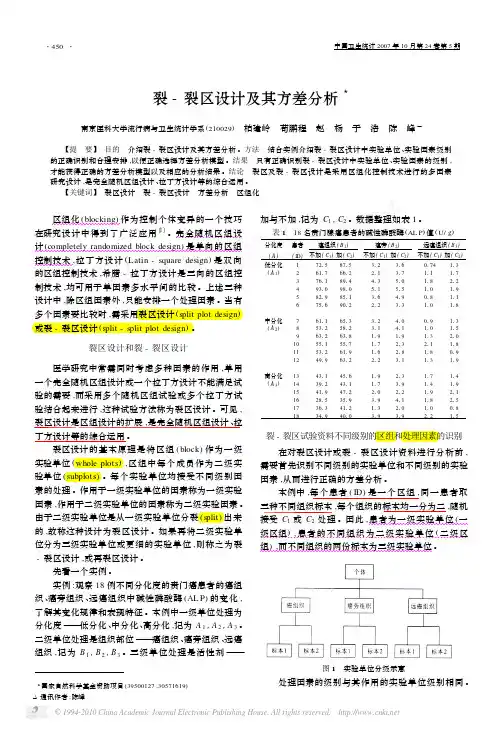
3国家自然科学基金资助项目(39500127,30571619)Δ通讯作者:陈峰裂-裂区设计及其方差分析3南京医科大学流行病与卫生统计学系(210029) 柏建岭 荀鹏程 赵 杨 于 浩 陈 峰△ 【提 要】 目的 介绍裂-裂区设计及其方差分析。
方法 结合实例介绍裂-裂区设计中实验单位、实验因素级别的正确识别和合理安排,以便正确选择方差分析模型。
结果 只有正确识别裂-裂区设计中实验单位、实验因素的级别,才能获得正确的方差分析模型以及相应的分析结果。
结论 裂区及裂-裂区设计是采用区组化控制技术进行的多因素研究设计,是完全随机区组设计、拉丁方设计等的综合运用。
【关键词】 裂区设计 裂-裂区设计 方差分析 区组化设计中,除区组因素外,只能安排一个处理因素。
当有多个因素要比较时,(split plot design )或裂-裂区设计(split -split plot design )。
裂区设计和裂-裂区设计医学研究中常需同时考虑多种因素的作用,单用一个完全随机区组设计或一个拉丁方设计不能满足试验的需要,而采用多个随机区组试验或多个拉丁方试验结合起来进行,这种试验方法称为裂区设计。
可见,裂区设计是区组设计的扩展,是完全随机区组设计、拉丁方设计等的综合运用。
裂区设计的基本原理是将区组(block )作为一级实验单位(whole plots ),区组中每个成员作为二级实验单位(subplots )。
每个实验单位均接受不同级别因素的处理。
作用于一级实验单位的因素称为一级实验因素,作用于二级实验单位的因素称为二级实验因素。
由于二级实验单位是从一级实验单位分裂(split )的,故称这种设计为裂区设计。
如果再将二级实验单位分为三级实验单位或更细的实验单位,则称之为裂-裂区设计,或再裂区设计。
先看一个实例。
实例:观察18例不同分化度的贲门癌患者的癌组织、癌旁组织、远癌组织中碱性磷酸酶(AL P )的变化,了解其变化规律和表现特征。
裂区试验设计与结果的统计分析裂区试验(split-plot design)是一种常用的设计方法,适用于在同一个实验中比较多个处理的效果,同时考虑到不同处理之间的相关性。
这种设计方法是多个因素的正交组合,通过将实验单位进行分区,以达到同时考虑多个因素的目的。
裂区试验包括两种类型的因素:主区因素(whole plot factor)和副区因素(sub plot factor)。
主区因素是指主要的实验处理,它在试验开始时就确定下来,并且针对每个实验区域进行随机分配。
副区因素是在主区因素设置完成后再确定的次要因素,它在主区因素内的每个实验区域中进行随机分配。
这种设计方法的优势在于可以同时考虑多个因素的影响,并通过分析不同因素之间的交互作用来提高实验效果。
裂区试验的设计步骤如下:1.确定主区因素和副区因素:根据实验目的确定需要考虑的因素,并确定它们的类型(定性或定量)和水平(多个水平或二元水平)。
2.确定实验单位:确定实验单位的大小和数量,这是根据研究对象和实验条件来确定的,在实验区域内进行分区。
3.随机分配主区因素:将主区因素随机分配给每个实验区域,确保每个实验区域都包含不同的主区因素水平组合。
4.随机分配副区因素:在每个实验区域内,将副区因素随机分配给各个实验单位。
5.数据收集:对实验单位进行观测与测量,记录主区因素和副区因素的水平以及观测结果。
6.数据分析:进行统计分析,根据实验设计的要求,使用适当的统计方法(方差分析、回归分析等)来分析主区因素和副区因素的效应,检验主效应和交互作用的显著性。
7.结果解释:根据统计分析的结果,对各个因素的效应进行解释和比较,得出结论。
裂区试验结果的统计分析主要包括方差分析和回归分析两种方法。
方差分析是一种用于比较多个处理效果的统计方法,通过计算各个因素的方差来判断它们的影响程度。
在裂区试验中,可以使用方差分析方法来分析主区因素和副区因素的效应,以及它们之间的交互作用。
裂区和条区试验的方差分析1 裂区试验的设计方法在有些多因素随机区组试验设计中,由于情况特殊,我们不能在区组内将所有处理完全随机排列,这些情况导致了随机区组设计的一些推广设计,如裂区设计和条区设计.裂区设计的原理是这样,区组包含一定数目的主小区,主小区又被划分成若干个次级小区.这样一个因素或几个因素的各水平首先配置给主小区,然后另外的一个因子或几个因子配置给次级小区.【例1】牧场试验中的裂区设计。
试验因素有两个,一是牧草品种B:B1、B2、B3,B4、B、B6,另一个是放牧吃草方式A:A1、A2。
牧草可以在各区组内随机配置来种植,但放5牧吃草方式却需要一大片土地,因为小了不够畜群吃。
这样我们采取下列设计方式:在试验设计中,把A1、A2占的区称为主小区,A称为主区因素,把每一个主小区分为6个子区(裂区或副小区),把6个品种随机配置进去,因而把品种B叫子区因素或副因素。
这种试验设计为二裂式裂区试验。
可以看出,在随机区组试验设计中,所有处理A i B j是在一个区组内随机配置的,而在裂区试验中,副因素是在主小区内随机配置的。
在生物科学和农林科学试验中,采用裂区试验设计的例子是不少的,譬如对某作物既要比较几种施肥法,又要比较几种灌溉法,以及这两个因素的交互作用。
各种施肥法可以在较小的副小区田上配置,但各种灌溉法需在较大的主小区上配置。
又如播种期和品种试验,适宜的方法是把同一播期的各品种种在一起,即播种期为主因素,安排在主小区上,而品种为副因素,应随机安排在副小区上。
如果副小区(裂区)内再划分小区,称为再裂区,在其中安排副副因素C,这种安排主因素(A)、副因素(B)和副副因素(C)的试验设计称为三裂式裂区试验。
裂区设计的主要优点在于:a .田间实施比较方便;b .能利用原有的试验地及试验材料,进行深一步的研究;c .某个因子可获得较高的精确度。
但裂区设计的还存在如下主要缺点:a .资料的统计分析比较复杂,不易掌握;b .次要因子的精确度较低。
裂区和条区试验的方差分析1 裂区试验的设计方法在有些多因素随机区组试验设计中,由于情况特殊,我们不能在区组内将所有处理完全随机排列,这些情况导致了随机区组设计的一些推广设计,如裂区设计和条区设计.裂区设计的原理是这样,区组包含一定数目的主小区,主小区又被划分成若干个次级小区.这样一个因素或几个因素的各水平首先配置给主小区,然后另外的一个因子或几个因子配置给次级小区.【例1】牧场试验中的裂区设计。
试验因素有两个,一是牧草品种B:B1、B2、B3,B4、B5、B6,另一个是放牧吃草方式A:A1、A2。
牧草可以在各区组内随机配置来种植,但放牧吃草方式却需要一大片土地,因为小了不够畜群吃。
这样我们采取下列设计方式:在试验设计中,把A1、A2占的区称为主小区,A称为主区因素,把每一个主小区分为6个子区(裂区或副小区),把6个品种随机配置进去,因而把品种B叫子区因素或副因素。
这种试验设计为二裂式裂区试验。
可以看出,在随机区组试验设计中,所有处理A i B j是在一个区组内随机配置的,而在裂区试验中,副因素是在主小区内随机配置的。
在生物科学和农林科学试验中,采用裂区试验设计的例子是不少的,譬如对某作物既要比较几种施肥法,又要比较几种灌溉法,以及这两个因素的交互作用。
各种施肥法可以在较小的副小区田上配置,但各种灌溉法需在较大的主小区上配置。
又如播种期和品种试验,适宜的方法是把同一播期的各品种种在一起,即播种期为主因素,安排在主小区上,而品种为副因素,应随机安排在副小区上。
如果副小区(裂区)内再划分小区,称为再裂区,在其中安排副副因素C,这种安排主因素(A)、副因素(B)和副副因素(C)的试验设计称为三裂式裂区试验。
裂区设计的主要优点在于:a.田间实施比较方便;b.能利用原有的试验地及试验材料,进行深一步的研究;c.某个因子可获得较高的精确度。
但裂区设计的还存在如下主要缺点:a.资料的统计分析比较复杂,不易掌握;b.次要因子的精确度较低。
另外要注意,裂区的面积大小同一般随机区组设计时小区面积相同,不能太小。
2 裂区试验的方差分析2.1 二裂式裂区试验的方差分析设主因素A有a个水平,副因素B有b个水平,有r个区组,则A i B j在第k个区组的观察值为x ijk。
二裂式裂区试验的方差分析特点表现在变异来源上分主区部分和副区部分,各有各的误差和相应的自由度。
具体见表1。
表1 二裂式裂区试验变异来源和自由度分解表1反映了二裂式裂区试验在方差分析上与二因素完全随机区组试验的区别:)1(1()1)(1()1)(1(--=--+--=+=ab r b r a a r f f f b a e e ef e 为二因素完全随机区组试验的误差自由度,把f e 分解为a e f 和b e f ,是因为每一主小区都包含一套副因素处理的特点而引起的。
二裂式裂区试验的线性统计模型为:)(;;1,,2,1,,2,1,,2,1)(rk b j a i x ijk ij j ik k i ijk ===++++++=εαββδγαμ 其中αi 为主区因素A i 的主效应,γk 为区组k 的主效应,δik 为A i 与区组k 的交互效应,为主区误差;βj 为副区因素B j 的主效应,(αβ)ij 为A i 与B j 的交互效应,εijk 为副区误差。
δik 间相互独立且均服从N (0,21σ),δijk 间相互独立且均服从N (0,22σ)。
下面用具体实例说明二裂式裂区试验的分析方法。
【例2】设有一小麦中耕次数(A )和施肥量(B )试验,主处理为A ,分A 1、A 2、A 3 3个水平,副处理为B ,分B 1、B 2、B 3、B 4 4个水平,裂区设计,重复3次(r =3),副区计产面积66 m 2,其田间排列和产量(kg )如下:试作方差分析。
将x ijk 整理成区组和处理A i B j 的双向表2、A 和B 的双向表3。
表2 区组和处理双向表主因素A 副因素B区 组T ij . T i ..Ⅰ Ⅱ ⅢA 1B 1 29 28 32 89B 2 37 32 31 100 B 3 18 14 17 49 B 4 17 16 15 48 T 1.k 101 90 95 286 A 2B 1 28 29 25 82 B 2 31 28 29 88 B 3 13 13 10 36 B 4 13 12 12 37 T 2.k 85 82 76 243 A 3B 1 30 27 26 83 B 2 31 28 31 90 B 3 15 14 11 40 B 4 16 15 13 44 T 3.k 92 84 81 257 T ..k 279 256 252786(T …)表3 A 和B 的双向表以上两表中,T ..k 为区组k 的和,平均值为k k T abx ⋅⋅⋅⋅=1;T ij .为A i B j 的和,平均值为⋅⋅=ij ij T r x 1;T i ..为A i 的和,平均值为⋅⋅⋅⋅=i i T br x 1;T .j .为B j 的和,平均值为⋅⋅⋅⋅=j j T arx 1;T i .k 为A i 主小区和,平均值为k i k i T b x ⋅⋅=1;T …为总和,平均值为⋅⋅⋅⋅⋅⋅=T abrx 1。
各参数的最小二乘估计为:由上述参数估计结果及计算偏差平方和的口诀可计算主副区各变因的平方和。
由模型(3-5-1)及参数估计易证总变异可分解成6个变因之和:①主区偏差平方和计算:事实上主区方差分析是单因素A的随机区组设计的方差分析。
其总变异SS Ta是区组与A处理组合A i R k的处理偏差平方和:②副区偏差平方和计算:由以上计算可得到平方和及相应自由度的分解:由式(3-5-4)可得到各平方和的均方,如MS A = SS A /f A 等。
与二因素随机区组试验一样,由A 、B 的固定还是随机假设,可得到EMS 。
这样就形成二裂式裂区试验的方差分析模式表3-5-4。
表3-5-4给出了正确进行F 检验所必需的依据。
由表3-5-4可见,在随机模型和A固定、B 随机的混合模型中,如果交互项显著,则对H0:02=A σ和H0:02=AK 难以作出直接检验。
这时需对有关项的均方相加以作近似检验。
例如在随机模型中,为检验H0:02=A σ,可先将A 和e b 项相加得再将A ×B 和e a 项相加得于是,由F = MS 1/MS 2可检验H002A σ:。
其自由度估计为:小麦中耕次数(A )和施肥量(B )的试验属固定模型,其方差分析结果见表3-5-5。
表3-5-5中,e a 是主区误差,e b 为副区误差。
当选用固定模型时,e a 可用以检验区组间和主处理(A )水平间均方的显著性;e b 可用以检验副处理(B )水平间和A ×B 均方的显著性。
由表3-5-5得到:区组间、A 因素水平间有显著差异,B 因素水平间有极显著差异,但A ×B 互作不存在。
由此说明:(1)本试验的区组在控制土壤肥力上有显著效果,从而显著地减小了误差;(2)不同的中耕次数间有显著差异;(3)不同的施肥量间有极显著差异;(4)中耕的效应不因施肥量多少而异,施肥量的效应也不因中耕次数多少而异。
下面进行多重比较:① 中耕次数间的多重比较 用SSR 法,4=a e f ,比较结果:② 施肥量间的多重比较 用SSR 法,比较结果:③ 处理均值间的比较 由于A ×B 不显著,说明A 与B 的作用是相互独立的,所以不需再作比较。
如果A ×B 显著,则需对处理均值进行多重比较。
由裂区试验的特点,对处理均值进行多重比较时,分两种情况:固定A i 对不同B j 作多重比较时,rMS S be EAB =;固定B j 对不同的A i 进行多重比较时,brMS MS b S ab e e EAB +-=)1(。
重比较结果说明,中耕次数A 1极显著地优于A 2,显著地优于A 2、A 3;施肥量B 2极显著地优于B 1,B 1极显著地优于B 3、B 4。
由于A ×B 不显著,故最优处理必为A 1B 2。
2.2 三裂式裂区试验的方差分析三裂式裂区试验为三因素试验,考察的因素有A 、B 、C 三个分别具有a 、b 、c 个水平。
A 为主区因素,B 为裂区因素,C 为再裂区因素。
试验按区组重复r 次。
每一区组内分a 个主小区,随机安排A 1、A 2、…、A a ;每一主小区分b 个裂区,随机安排B 1、B 2、…、B b ;每一裂区分c 个再裂区,随机安排C 1、C 2、…、C c 。
处理A i B j C k 共有abc 个。
处理A i B j C k 在区组l 中观察值为x ijkl ,共有观察值abcr 个。
方差分析的模型为:其中,αi + γl + (ε1)ij 为主区效应分析部分,αi 为A i 的主效应,γl 为区组l 的主效应,(ε1)ij 为主区的随机误差,服从),0(21σN ,实际上(ε1)ij 为A i 和区组l 的交互效应;βj + (αβ)ij + (ε2)ijl 为裂区分析部分,βj 为B j 的主效应,(αβ)ij 为A i 与B j 的交互效应,(ε2)ijl 为裂区的误差,服从),0(22σN ,实际上为主区内的B j 与区组l 的交互作用;θk + (αθ)ik + (βθ)jk +(αβθ)ijk +(ε3)ijkl 为再裂区分析部分,θk 为C k 的主效应,(αθ)ik 是A i 与C k 的交互效应,(βθ)jk 是B j 与C k 的交互效应,(αβθ)ijk 是A i 、B j 和C k 间的交互效应,(ε3)ijkl 是再裂区的随机误差,亦是A i B j 内的C k 和区组l 的交互效应,它服从),0(23σN 。
参数估计、平方和计算和试验因素的抽样值定随例题再说。
三裂式裂区试验的方差分析模式见表3-5-6。
表中未列混合模型,可参照三因素随机区组试验EMS 写出。
关于表3-5-6有如下几点说明:1.b e MS 可通过c e MS 检验,a e MS 可通过b e MS 来检验,如果都不显著,则试验变为三因素随机区组试验分析,这时SS e = a e MS + b e MS + c e MS ,fe =a e f + b e f + c e f = (abc-1)(r-1)。
2.如果b e MS 、a e MS 经检验都显著,必须严格按表3-5-6分析。
如果是固定模型,在多重比较时有关的均数标准差为:【例3】一位药物研究员研究一种特定类型的抗生素胶囊的吸收时间。
主区因素是A 1、A 2、A 3三位实验师,裂区因素是B 1、B 2和B 3三种剂量,再裂区因素是C 1、C 2、C 3和C 4四种胶囊糖衣厚度。