HMM(隐马尔可夫模型)及其应用
- 格式:doc
- 大小:27.00 KB
- 文档页数:5




/hmm-learn-best-practices-four-hidden-markov-modelswiki上一个比较好的HMM例子分类隐马尔科夫模型HMM(隐马尔科夫模型)是自然语言处理中的一个基本模型,用途比较广泛,如汉语分词、词性标注及语音识别等,在NLP中占有很重要的地位。
网上关于HMM的介绍讲解文档很多,我自己当时开始看的时候也有点稀里糊涂。
后来看到wiki上举得一个关于HMM的例子才如醍醐灌顶,忽然间明白HMM的三大问题是怎么回事了。
例子我借助中文wiki重新翻译了一下,并对三大基本问题进行说明,希望对读者朋友有所帮助:Alice 和Bob是好朋友,但是他们离得比较远,每天都是通过电话了解对方那天作了什么.Bob仅仅对三种活动感兴趣:公园散步,购物以及清理房间.他选择做什么事情只凭当天天气.Alice对于Bob所住的地方的天气情况并不了解,但是知道总的趋势.在Bob告诉Alice每天所做的事情基础上,Alice想要猜测Bob 所在地的天气情况.Alice认为天气的运行就像一个马尔可夫链. 其有两个状态“雨”和”晴”,但是无法直接观察它们,也就是说,它们对于Alice是隐藏的.每天,Bob有一定的概率进行下列活动:”散步”, “购物”, 或“清理”. 因为Bob会告诉Alice他的活动,所以这些活动就是Alice的观察数据.这整个系统就是一个隐马尔可夫模型HMM.Alice知道这个地区的总的天气趋势,并且平时知道Bob会做的事情.也就是说这个隐马尔可夫模型的参数是已知的.可以用程序语言(Python)写下来: // 状态数目,两个状态:雨或晴states = (‘Rainy’, ‘Sunny’)// 每个状态下可能的观察值obse rvations = (‘walk’, ’shop’, ‘clean’)//初始状态空间的概率分布start_probability = {‘Rainy’: 0.6, ‘Sunny’: 0.4}// 与时间无关的状态转移概率矩阵transition_probability = {’Rainy’ : {‘Rainy’: 0.7, ‘Sunny’: 0.3},’Sunny’ : {‘Rainy’: 0.4, ‘Sunny’: 0.6},}//给定状态下,观察值概率分布,发射概率emission_probability = {’Rainy’ : {‘walk’: 0.1, ’shop’: 0.4, ‘clean’: 0.5},’Sunny’ : {‘walk’: 0.6, ’shop’: 0.3, ‘clean’: 0.1},}在这些代码中,start_probability代表了Alice对于Bob第一次给她打电话时的天气情况的不确定性(Alice知道的只是那个地方平均起来下雨多些).在这里,这个特定的概率分布并非平衡的,平衡概率应该接近(在给定变迁概率的情况下){‘Rainy’: 0.571, ‘Sunny’: 0.429}。

HMM时间序列预测方法1. 引言在时间序列分析中,预测未来的数值是一个重要的任务。
HMM(隐马尔可夫模型)是一种常用的时间序列预测方法,它可以用于解决各种具有时序关系的问题,如语音识别、自然语言处理、股票市场预测等。
本文将详细介绍HMM时间序列预测方法的原理、应用以及实现过程。
2. HMM基本原理HMM是一种统计模型,用于描述由一个隐藏状态序列和一个可观察状态序列组成的过程。
隐藏状态是不可直接观察到的,而可观察状态则可以被观察到。
HMM假设隐藏状态之间存在马尔可夫性质,即当前隐藏状态只与前一个隐藏状态相关。
HMM由以下几个要素组成: - 隐藏状态集合:表示可能出现的所有隐藏状态。
-可观察状态集合:表示可能出现的所有可观察状态。
- 初始概率分布:表示初始时刻每个隐藏状态出现的概率。
- 状态转移概率矩阵:表示从一个隐藏状态转移到另一个隐藏状态的概率。
- 观测概率矩阵:表示在给定隐藏状态下,观测到某个可观察状态的概率。
HMM的基本思想是通过给定的观测序列,利用已知的模型参数来推断隐藏状态序列,并进一步预测未来的观测序列。
3. HMM时间序列预测方法步骤HMM时间序列预测方法包括以下几个步骤:步骤1:模型训练•收集历史数据:从过去的时间序列中收集足够数量的观测数据。
•确定隐藏状态和可观察状态:根据具体问题确定隐藏状态和可观察状态的集合。
•估计初始概率分布:根据历史数据统计每个隐藏状态出现的频率,并将其归一化得到初始概率分布。
•估计状态转移概率矩阵:根据历史数据统计每个隐藏状态之间转移的频率,并将其归一化得到状态转移概率矩阵。
•估计观测概率矩阵:根据历史数据统计在给定隐藏状态下,每个可观察状态出现的频率,并将其归一化得到观测概率矩阵。
步骤2:模型推断•给定观测序列:根据已有的观测序列,利用前面训练得到的模型参数,通过前向算法计算每个隐藏状态的前向概率。
•预测隐藏状态序列:利用维特比算法,根据前向概率计算最可能的隐藏状态序列。
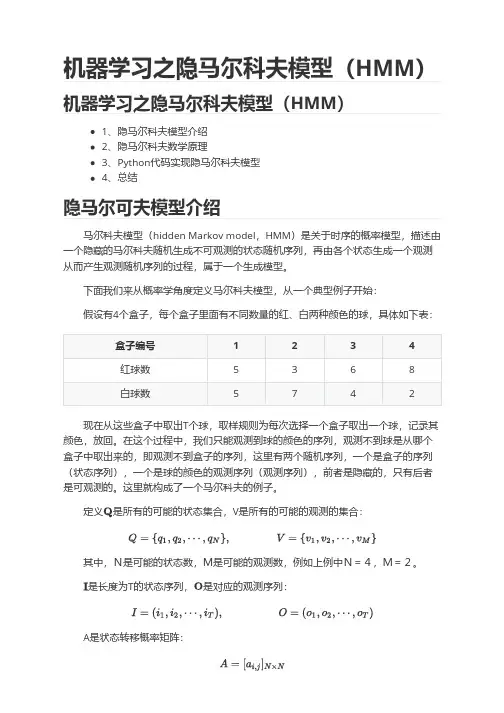
机器学习之隐马尔科夫模型(HMM)机器学习之隐马尔科夫模型(HMM)1、隐马尔科夫模型介绍2、隐马尔科夫数学原理3、Python代码实现隐马尔科夫模型4、总结隐马尔可夫模型介绍马尔科夫模型(hidden Markov model,HMM)是关于时序的概率模型,描述由一个隐藏的马尔科夫随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程,属于一个生成模型。
下面我们来从概率学角度定义马尔科夫模型,从一个典型例子开始:假设有4个盒子,每个盒子里面有不同数量的红、白两种颜色的球,具体如下表:盒子编号1234红球数5368白球数5742现在从这些盒子中取出T个球,取样规则为每次选择一个盒子取出一个球,记录其颜色,放回。
在这个过程中,我们只能观测到球的颜色的序列,观测不到球是从哪个盒子中取出来的,即观测不到盒子的序列,这里有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列),前者是隐藏的,只有后者是可观测的。
这里就构成了一个马尔科夫的例子。
定义是所有的可能的状态集合,V是所有的可能的观测的集合:其中,N是可能的状态数,M是可能的观测数,例如上例中N=4,M=2。
是长度为T的状态序列,是对应的观测序列:A是状态转移概率矩阵:其中, 是指在时刻处于状态的条件下在时刻转移到状态的概率。
B是观测概率矩阵:其中, 是指在时刻处于状态的条件下生成观测的概率。
是初始状态概率向量:其中, 是指在时刻=1处于状态的概率。
由此可得到,隐马尔可夫模型的三元符号表示,即称为隐马尔可夫模型的三要素。
由定义可知隐马尔可夫模型做了两个基本假设:(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻的状态只和-1状态有关;(2)观测独立性假设,观测只和当前时刻状态有关;仍以上面的盒子取球为例,假设我们定义盒子和球模型:状态集合: = {盒子1,盒子2,盒子3,盒子4}, N=4观测集合: = {红球,白球} M=2初始化概率分布:状态转移矩阵:观测矩阵:(1)转移概率的估计:假设样本中时刻t处于状态i,时刻t+1转移到状态j 的频数为那么转台转移概率的估计是:(2)观测概率的估计:设样本中状态为j并观测为k的频数是那么状态j观测为k的概率, (3)初始状态概率的估计为S个样本中初始状态为的频率。

HMM在基于参数的语音合成系统中的应用摘要语音合成是人机交互的关键技术之一。
随着电子计算机的迅猛发展,语音合成技术由早期的基于拼接调整合成,逐渐发展为目前基于参数的语音合成技术。
本文主要是对隐马尔可夫模型(HMM)在基于参数的语音合成系统中的应用方面进行了研究和探索。
本文的主要研究工作如下:首先,基于对现有语音自动切分技术框架的分析,提出了不定长单元模型,改善切分的精度。
目前,基于拼接的语音合成系统需要首先对语料库进行语音自动切分,基于隐马尔可夫模型的语音自动切分方法普遍采用的声学模型是三音子模型。
本文针对一些语音单元间的协同发音现象和音变现象对切分精度造成的不利影响,提出了基于不定长单元模型的语音自动切分方法。
具体定义了不定长语音单元,讨论了不定长单元的选取,并对建立相应的模型,在模型的训练方面也给出了解决的方案。
实验结果,长单元的边界切分精度比三音子模型有了很大的提高,精度从原先的79.55%提高到了89.13%,同时总体切分精度也有了一定的提高。
结果表明, 不定长单元模型对于语音自动切分,特别是对三音子模型表现较差的长单元边界上,能达到比三音子模型更好的效果本文首先介绍基于HMM的自动切分的基本流程,并通过分析由于不同音子间的紧密结合而产生的音变现象,提出一种基于不定长单元模型并给出其训练算法。
基于HMM的自动切分技术的分析和改进工作,为后面基于HMM的可训练语音合成的深入研究奠定一定的基础。
其次,基于现有的模型训练和参数生成技术,对基于参数的语音合成的技术框架中的一些关键技术进行分析,并根据需要构建了中文的基于参数的语音合成系统。
本文建立了一整套的基于参数的语音合成系统,包括模型的训练流程和相应的语音合成模块。
它可以根据原始的语音数据进行训练,并自动生成一个的合成系统。
同时,本文在此框架基础上进行了中文基于参数的语音合成系统的训练和构建,对基于参数的语音合成技术进行效果验证。
此外,本文根据基于最小化生成误差的训练准则,对模型进行了改进,在新的准则下优化合成语音的音质。

内蒙古科技大学本科生毕业设计说明书(毕业论文)题目:利用HMM技术实现基于文本相关的语音识别学生姓名:学号:专业:电子信息工程班级:信息2003-4班指导教师:摘要语音识别作为一个交叉学科,具有深远的研究价值。
语音识别和语音合成技术已经成为现代技术发展的一个标志,也是现代计算机技术研究和发展的一个重要领域。
虽然语音识别技术已经取得了一些成就,也有部分产品面世,但是,大多数语音识别系统仍局限于实验室,远没有达到实用化要求。
制约实用化的根本原因可以归为两类,识别精度和系统复杂度。
HMM是一种用参数表示的用于描述随机过程统计特性的概率模型,它是由马尔可夫链演变来的,所以它是基于参数模型的统计识别方法。
它是一个双重随机过程——具有一定状态数的隐马尔可夫链和显示随机函数集,每个函数都与链中一个状态相关联。
“隐”的过程通过显示过程所产生的观察符号序列来表示,这就是隐马尔可夫模型。
本文主要介绍了语音识别的预处理,隐马尔可夫模型(Hidden Markov Models,HMM)和语音识别的基础理论和发展方向。
对数字0~9的识别进行了详细的Matlab 语言实现。
关键词:HMM;文本相关;语音识别AbstractAs an interdisciplinary field, speech recognition is theoretically very valued .Speech recognition has become one of the important research fields and a mark of the development of science. Although speech technology has got some achievements, most speech recognition systems are still limited in lab and would have problems if migrated from lab which are much far from practicality. The ultimate reasons for restricting practicality can be classified to two kinds, one is precision for recognition and the other is complexity of the system.HMM is one kind expresses with the parameter uses in the description stochastic process statistical property probabilistic model, it is may the husband chain evolve by Mar, therefore it based on parameter model statistics recognition method. It is a dual stochastic process – has the certain condition number to hide type Markov to be possible the husband chain and the demonstration stochastic function collection, each function all a condition is connected with the chain in. Hidden Markov process the observation mark sequence which produces through the demonstration process to indicate that, this is hides type Markov to be possible the husband model.This article mainly introduced the speech recognition pretreatment, hides Mar to be possible the husband model (Hidden Markov Models, HMM) and the speech recognition basic theory and the development direction. Has carried on the detailed Matlab language realization to the number 0~9 recognitions.Key word: HMM; Text Correlation; Speech recognition目录摘要 (I)ABSTRACT ........................................................................................................................ I I 第一章绪论.. (1)1.1 背景、目的和意义 (1)1.2 发展历史和国内外现状 (1)1.3 语音识别系统概述 (3)1.3.1语音识别系统构成 (3)1.3.2语音识别的分类 (4)1.3.3 识别方法介绍 (5)第二章语音信号的预处理及特征提取 (8)2.1 语音信号的产生模型 (9)2.2 语音信号的数字化和预处理 (9)2.2.1 语音采样 (10)2.2.2 预加重 (10)2.2.3 语音信号分帧加窗 (11)2.3 端点检测 (13)2.3.1 短时能量 (13)2.3.2 短时平均过零率 (14)2.3.3 端点检测——“双门限”算法 (15)2.4 语音信号特征参数的提取 (16)2.4.1线性预测倒谱系数LPCC (16)2.4.2 Mel倒谱系数MFCC (17)2.4.3 LPCC系数和MFCC系数的比较 (18)第三章隐马尔可夫模型(HMM) (20)3.1 隐马尔可夫模型 (20)3.1.1 隐马尔可夫(HMM)基本思想 (20)3.1.2 语音识别中的HMM (24)3.1.3 隐马尔可夫的三个基本问题[10] (24)3.1.4 HMM的基本算法 (25)3.2 HMM模型的一些问题 (28)3.2.1 HMM溢出问题的解决方法 (28)3.2.2 参数的初始化问题 (29)3.2.3提高HMM描述语音动态特性的能力 (31)3.2.4直接利用状态持续时间分布概率的HMM系统 (31)第四章基于文本相关的语音识别 (33)4.1 引言 (33)4.2 HMM模型的语音实现方案 (33)4.2.1初始模型参数设定 (34)4.2.2 HMM模型状态分布B的估计 (34)4.2.3 多样本训练 (35)4.2.4 识别过程 (36)4.3 仿真过程及系统评估 (37)4.3.1 语音数据的采集及数据库的建立 (37)4.3.2 仿真实验——HMM用于语音识别 (38)4.3.3 Matlab编程实现 (40)4.4系统仿真中的若干问题 (43)总结展望 (44)参考文献 (45)附录 (46)致谢 (54)第一章绪论1.1 背景、目的和意义让计算机能听懂人类的语言,是人类自计算机诞生以来梦寐以求的想法。


马尔可夫模型简介马尔可夫模型(Markov Model)是一种描述随机过程的数学模型,它基于“马尔可夫性质”假设,即未来的状态只与当前状态有关,与过去的状态无关。
马尔可夫模型在许多领域中得到了广泛的应用,如自然语言处理、机器学习、金融等。
历史发展马尔可夫模型最早由俄国数学家马尔可夫在20世纪初提出。
马尔可夫通过研究字母在俄文中的出现概率,发现了一种有规律的模式,即某个字母出现的概率只与之前的字母有关。
他将这种模式抽象为数学模型,即马尔可夫模型。
后来,马尔可夫模型被广泛应用于其他领域,并得到了不断的发展和完善。
基本概念状态(State)在马尔可夫模型中,状态是指系统可能处于的一种情况或状态。
每个状态都有一个特定的概率,表示系统处于该状态的可能性。
状态可以是离散的,也可以是连续的。
例如,对于天气预测,状态可以是“晴天”、“阴天”、“雨天”等。
转移概率(Transition Probability)转移概率表示从一个状态转移到另一个状态的概率。
在马尔可夫模型中,转移概率可以用转移矩阵表示,其中每个元素表示从一个状态转移到另一个状态的概率。
例如,对于天气预测,转移概率可以表示为:晴天阴天雨天晴天0.6 0.3 0.1阴天0.4 0.4 0.2雨天0.2 0.3 0.5上述转移矩阵表示了从一个天气状态到另一个天气状态的转移概率。
初始概率(Initial Probability)初始概率表示系统在初始时刻处于每个状态的概率。
它可以用一个向量表示,向量中每个元素表示系统处于对应状态的概率。
例如,对于天气预测,初始概率可以表示为:晴天阴天雨天0.3 0.4 0.3上述向量表示了系统初始时刻处于不同天气状态的概率。
观测概率(Observation Probability)观测概率表示系统处于某个状态时观测到某个观测值的概率。
观测概率可以用观测矩阵表示,其中每个元素表示系统处于某个状态观测到某个观测值的概率。
例如,对于天气预测,观测概率可以表示为:晴天阴天雨天温度高0.7 0.2 0.1温度低0.3 0.6 0.1上述观测矩阵表示了在不同天气状态下观测到不同温度的概率。

混合模型公式混合高斯模型隐马尔可夫模型混合模型是一种统计模型,它结合了多个基本模型的特点,以适应数据的复杂性和多样性。
本文将重点介绍混合模型中常用的两种类型:混合高斯模型和隐马尔可夫模型。
一、混合高斯模型混合高斯模型是一种基于高斯分布的混合模型。
它假设数据点是从多个高斯分布中生成的,这些高斯分布具有不同的均值和方差,各自对应不同的类别或簇。
混合高斯模型通过考虑每个高斯分布的权重来描述不同类别或簇的重要性。
混合高斯模型可以使用以下公式进行表示:p(x) = ∑[i=1 to k] w[i] * N(x|μ[i],Σ[i])其中,p(x)表示给定数据点x的概率,k表示高斯分布的数量,w[i]表示第i个高斯分布的权重,N(x|μ[i],Σ[i])表示第i个高斯分布的概率密度函数。
通过调整权重和调整各个高斯分布的参数,可以根据实际情况对数据进行分类或聚类。
二、隐马尔可夫模型隐马尔可夫模型(Hidden Markov Model,简称HMM)是一种描述具有隐藏状态的序列数据的统计模型。
它假设系统的状态是一个马尔可夫链,即当前状态只依赖于前一状态,并且观测数据仅与当前状态有关。
隐马尔可夫模型可以使用以下公式进行表示:π(i) = P(q[i]) 初始状态概率a(ij) = P(q[j]|q[i]) 状态转移概率b(i) = P(x[i]|q[i]) 观测概率其中,π(i)表示初始状态概率,表示系统在时间序列的初始时刻处于状态i的概率;a(ij)表示状态转移概率,表示系统由状态i转移到状态j的概率;b(i)表示观测概率,表示系统处于状态i时,观测到某个具体观测值的概率。
隐马尔可夫模型广泛应用于语音识别、自然语言处理、生物信息学等领域。
通过调整初始状态概率、状态转移概率和观测概率,可以对序列数据进行建模与分析,包括状态预测、序列生成和序列估计等任务。
总结:混合模型是一种统计模型,可以适应数据的多样性和复杂性。
混合高斯模型和隐马尔可夫模型是混合模型的两种常见形式,分别适用于数据的分类和序列建模。
隐马尔科夫模型(HMM)第一章马尔科夫模型简介我们通常都习惯寻找一个事物在一段时间里的变化规律。
在很多领域我们都希望找到这个规律,比如计算机中的指令顺序,句子中的词顺序和语音中的词顺序等等。
一个最适用的例子就是天气的预测。
隐马尔可夫模型的理论基础是在1970年前后由Baum等人建立起来的,随后由CMU的Bakex和IBM的Jelinek等人将其应用到语音识别中。
由于Bell实验室的Rabine等人在80年代中期对HMM的深入浅出的介绍,才逐渐使HMM为世界各国的研究人员所了解和熟悉,进而在信息处理领域成为一个研究热点。
关于模型的建立有两种生成模式:确定性的和非确定性的。
确定性的生成模式:就好比日常生活中的红绿灯,我们知道每个灯的变化规律是固定的。
我们可以轻松的根据当前的灯的状态,判断出下一状态。
图1.1 确定性模型非确定性的生成模式:比如说天气晴、多云、和雨。
与红绿灯不同,我们不能确定下一时刻的天气状态,但是我们希望能够生成一个模式来得出天气的变化规律。
我们可以简单的假设当前的天气只与以前的天气情况有关,这被称为马尔科夫假设。
虽然这是一个大概的估计,会丢失一些信息。
但是这个方法非常适于分析。
马尔科夫过程就是当前的状态只与前n个状态有关。
这被称作n阶马尔科夫模型。
最简单的模型就当n=1时的一阶模型。
就当前的状态只与前一状态有关。
(这里要注意它和确定性生成模式的区别,这里我们得到的是一个概率模型)。
下图1.2是所有可能的天气转变情况:图1.2 天气转变图对于有M个状态的一阶马尔科夫模型,共有M*M个状态转移。
每一个状态转移都有其一定的概率,我们叫做转移概率,所有的转移概率可以用一个矩阵表示。
在整个建模的过程中,我们假设这个转移矩阵是不变的。
如图1.3所示:图1.3 天气转变矩阵HMM是一个输出符号序列的统计模型,有N个状态S1,S2,·····SN,它按一定的周期从一个状态转移到另一个状态,每次转移时,输出一个符号。
隐马尔可夫模型数学公式
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用
于描述一个隐藏的马尔可夫链的状态序列,该状态序列与可观测的输出序列相关联。
其数学公式可以表示为:
P(X,Y)=P(X1,Y1)P(X2,Y2)⋯P(XN,YN)P(X,Y) = P(X_1,Y_1)P(X_2,Y_2)\dots P(X_N,Y_N)P(X,Y)=P(X1,Y1)P(X2,Y2)⋯P(XN,YN)
其中,
X 表示可观测的状态序列,可以表示为一个离散随机变量序列
X1,X2,…,XN 。
Y 表示隐藏的状态序列,可以表示为一个离散随机变量序列Y1,Y2,…,YN 。
P(Xi,Yi) 表示在时刻 i ,状态为 Xi ,且输出为 Yi 的概率。
在隐马尔可夫模型中,隐藏的状态是不可观测的,只能通过可观测的状态序列来推断隐藏状态序列。
因此,隐马尔可夫模型可以用于解决许多实际问题,如语音识别、手写识别、自然语言处理等领域。
声学模型建模方法声学模型建模方法是指通过对声音信号进行分析和建模,以实现语音识别、语音合成和语音转换等任务。
声学模型建模方法在自然语言处理和人机交互领域具有重要的应用价值。
本文将介绍常见的声学模型建模方法,包括高斯混合模型(GMM)、隐马尔可夫模型(HMM)和深度神经网络(DNN)。
高斯混合模型是声学模型建模中最早被广泛使用的方法之一。
它假设声音信号是由多个高斯分布组成的,每个高斯分布对应一个语音单位(如音素或音节)。
通过对训练数据进行参数估计,可以得到每个语音单位的高斯分布参数。
在识别过程中,根据观测到的声音信号,通过计算不同语音单位的后验概率,选择概率最大的语音单位作为识别结果。
隐马尔可夫模型是一种常用的时序模型,也被广泛应用于声学模型建模。
隐马尔可夫模型假设声音信号是由一个隐藏的马尔可夫链和一个观测序列组成的。
隐藏的马尔可夫链表示语音单位的序列,观测序列表示相应的声音信号。
通过对训练数据进行参数估计,可以得到马尔可夫链的转移概率和观测序列的发射概率。
在识别过程中,根据观测到的声音信号,通过计算不同语音单位序列的概率,选择概率最大的语音单位序列作为识别结果。
深度神经网络是近年来在声学模型建模中取得显著进展的方法。
深度神经网络可以通过多层非线性变换来学习输入数据的高级表示。
在声学模型建模中,深度神经网络可以用于建模声音信号的时频特征。
通过对大量训练数据进行监督训练,可以得到深度神经网络的参数。
在识别过程中,通过前向计算,将声音信号映射到语音单位的概率分布,选择概率最大的语音单位作为识别结果。
除了上述方法,还有许多其他的声学模型建模方法,如最大似然线性回归(MLLR)、最大似然线性变换(MLLT)和最大互信息(MMI)等。
这些方法在建模声音信号时,各有特点和适用范围。
研究者们通过不断改进和融合这些方法,努力提高声学模型的准确性和鲁棒性。
声学模型建模方法在语音识别和语音合成等领域发挥着重要作用。
高斯混合模型、隐马尔可夫模型和深度神经网络是常用的声学模型建模方法。
隐马尔可夫链模型的递推-概述说明以及解释1.引言1.1 概述隐马尔可夫链模型是一种常用的概率统计模型,它广泛应用于自然语言处理、语音识别、模式识别等领域。
该模型由两个基本假设构成:一是假设系统的演变具有马尔可夫性质,即当前状态的变化只与前一个状态有关;二是假设在每个状态下,观测到的数据是相互独立的。
在隐马尔可夫链模型中,存在两个重要概念:隐含状态和观测数据。
隐含状态是指在系统中存在但无法直接观测到的状态,而观测数据是指我们通过观测手段能够直接获取到的数据。
隐含状态和观测数据之间通过概率函数进行联系,概率函数描述了在每个状态下观测数据出现的概率。
隐马尔可夫链模型的递推算法用于解决两个问题:一是给定模型参数和观测序列,求解最可能的隐含状态序列;二是给定模型参数和观测序列,求解模型参数的最大似然估计。
其中,递推算法主要包括前向算法和后向算法。
前向算法用于计算观测序列出现的概率,后向算法用于计算在某一隐含状态下观测数据的概率。
隐马尔可夫链模型在实际应用中具有广泛的应用价值。
在自然语言处理领域,它可以用于词性标注、语义解析等任务;在语音识别领域,它可以用于语音识别、语音分割等任务;在模式识别领域,它可以用于手写识别、人脸识别等任务。
通过对隐马尔可夫链模型的研究和应用,可以有效提高这些领域的性能和效果。
综上所述,隐马尔可夫链模型是一种重要的概率统计模型,具有广泛的应用前景。
通过递推算法,我们可以有效地解决模型参数和隐含状态序列的求解问题。
随着对该模型的深入研究和应用,相信它将在各个领域中发挥更大的作用,并取得更好的效果。
1.2 文章结构文章结构部分的内容可以包括以下要点:文章将分为引言、正文和结论三个部分。
引言部分包括概述、文章结构和目的三个子部分。
概述部分简要介绍了隐马尔可夫链模型的背景和重要性,指出了该模型在实际问题中的广泛应用。
文章结构部分说明了整篇文章的组织结构,明确了每个部分的内容和目的。
目的部分描述了本文的主要目的,即介绍隐马尔可夫链模型的递推算法和应用,并总结和展望其未来发展方向。
HMM(隐马尔可夫模型)及其应用
摘要:隐马尔可夫模型(Hidden Markov Model,HMM)作为一种统计分析
模型,创立于20世纪70年代。80年代得到了传播和发展,成为信号处理的一
个重要方向,现已成功地用于语音识别,行为识别,文字识别以及故障诊断等领
域。
本文先是简要介绍了HMM的由来和概念,之后重点介绍了3个隐马尔科夫
模型的核心问题。
关键词:HMM,三个核心问题
HMM的由来
1870年,俄国有机化学家Vladimir V. Markovnikov第一次提出马尔可夫模
型。马尔可夫在分析俄国文学家普希金的名著《叶夫盖尼•奥涅金》的文
字的过程中,提出了后来被称为马尔可夫框架的思想。而Baum及其同事则提出
了隐马尔可夫模型,这一思想后来在语音识别领域得到了异常成功的应用。同时,
隐马尔可夫模型在“统计语言学习”以及“序列符号识别”(比如DNA序列)等领
域也得到了应用。人们还把隐马尔可夫模型扩展到二维领域,用于光学字符识别。
而其中的解码算法则是由Viterbi和他的同事们发展起来的。
马尔可夫性和马尔可夫链
1. 马尔可夫性
如果一个过程的“将来”仅依赖“现在”而不依赖“过去”,则此过程具有马尔可
夫性,或称此过程为马尔可夫过程。马尔可夫性可用如下式子形象地表示:
X(t+1)=f(X(t))
2. 马尔可夫链
时间和状态都离散的马尔可夫过程称为马尔可夫链。
记作{Xn=X(n), n=0,1,2,…}
这是在时间集T1={0,1,2,…}上对离散状态的过程相继观察的结果。
链的状态空间记作I={a1, a2,…}, ai ∈R.
条件概率Pij(m, m+n)=P{ Xm+n = aj | Xm = aj }为马氏链在时刻m处于状态
ai条件下,在时刻m+n转移到状态aj的转移概率。
3. 转移概率矩阵
如下图所示,这是一个转移概率矩阵的例子。
由于链在时刻m从任何一个状态ai出发,到另一时刻m+n,必然转移到a1,
a2…,诸状态中的某一个,所以有
当 与m无关时,称马尔可夫链为齐次马尔可夫链,通常说的马尔可夫链都
是指齐次马尔可夫链。
对实例的描述:
设有N个缸,每个缸中装有很多彩球,球的颜色由一组概率分布描述。实
验进行方式如下:
—根据初始概率分布,随机选择N个缸中的一个开始实验;
—根据缸中球颜色的概率分布,随机选择一个球,记球的颜色为O1,并把
球放回缸中;
—根据描述缸的转移的概率分布,随机选择下一口缸,重复以上步骤。
最后得到一个描述球的颜色的序列O1, O2,…,称为观察值序列O。
在上述实验中,有几个要点需要注意:
不能被直接观察缸间的转移;
从缸中所选取的球的颜色和缸并不是一一对应的;
每次选取哪个缸由一组转移概率决定。
2. HMM概念
HMM的状态是不确定或不可见的,只有通过观测序列的随机过程才能表现
出来。
观察到的事件与状态并不是一一对应,而是通过一组概率分布相联系。
HMM是一个双重随机过程,两个组成部分:
—马尔可夫链:描述状态的转移,用转移概率描述。
—一般随机过程:描述状态与观察序列间的关系,用观察值概率描述。
3. HMM组成
通过上述例子可以看出,一个HMM由如下几个部分组成:
(1) 模型中状态的数目N(上例中缸的数目);
(2) 从每个状态可能输出的不同符号的数目M(上例中球的不同颜色的数
目);
(3) 状态转移概率矩阵A={aij}(aij为实验员从一个缸(状态si)转向另一个缸
(sj)取球的概率);
(4) 从状态sj观察到符号vk的概率分布矩阵B={bj(k)}(bj(k)为实验员从第j
个缸中取出第k种颜色的球的概率);
(5) 初始状态概率分布π={πi}。
4. HMM的基本要素
用模型五元组 =( N, M,π,A,B)用来描述HMM,或简写为 =(π,A,B)。
具体说明见下表所示:
定义了这些符号和术语之后,使得我们可以关注下列3个隐马尔可夫模型的
核心问题:
(1) 估值问题:假设我们有一个HMM,其转移概率aij和bij均已知。计算
这个模型产生某一个特定观测序列VT的概率。
(2) 解码问题:假设我们已经有了一个HMM和它所产生的一个观测序列,
决定最有可能产生这个可见观测序列的隐状态序列 。
(3) 学习问题:假设我们只知道一个HMM的大致的结构(比如隐状态数量
和可见状态数量),但aij和bjk军位置。如何从一组可见符号的训练序列中,决
定这些参数。
HMM的3个基本问题
针对以上三个问题,人们提出了相应的算法。
评估问题:向前向后算法。
解码问题:Viterbi算法。
学习问题:Baum-Welch算法。
1. Viterbi算法
维特比算法用来求解第二个问题。对“最优状态序列”的理解为:在给定模型
μ和观察序列O的条件下,使条件概率P(Q|O, μ)最大的状态序列,即
采用动态规划算法。复杂度O(K2L)。K和L分别为状态个数和序列长度。
2. 前向—后向算法
用来解决第一种问题。实际上我们可以采用前向算法和后向算法相结合的方
法来计算观察序列的概率。
前向算法:动态规划,复杂度同Viterbi。
HMM的应用
应用于语音识别,机器视觉(人脸检测,机器人足球),图像处理(图像去
噪,图像识别),生物医学分析(DNA/蛋白质序列分析)等各个领域。
注:文章内所有公式及图表请用PDF形式查看。