一元回归模型-102页精品文档
- 格式:ppt
- 大小:774.50 KB
- 文档页数:102

第2章一元线性回归模型§2.1 模型的建立及其假定条件1. 回归分析的概念回归分析是处理变量与变量之间关系的一种数学方法。
1)关系分类(1)确定的函数关系。
例如某企业的销售收入Y i等于产品价格P与销售量X i的乘积,用数学表达式表示为:Y i = P X i(2)非确定的依赖关系。
例如某企业资金的投人X i与产出Y i,一般来讲,资金投入越多,产出也相应提高。
但是由于生产过程中各种条件的变化,使得不同时间内同样的资金投入会有不同的产出。
这些造成了资金的投入与产出之间关系的不确定性,因而不能给出类似于函数的精确表达式。
用u i表示其他影响因素,将这两个变量之间非确定的依赖关系表示成下列形式:Y i = f(X i )+ u i(3)回归分析。
为了分析和利用变量之间非确定的依赖关系,人们建立了各种统计分析方法,其中回归分析方法是最常用的经典方法之一。
回归分析的理论和方法是计量经济模型估计理论和估计方法的主要内容。
2.一元线性回归模型1)概念。
为了说明一元线性回归模型,举一个某商品需求函数的例子。
为了研究某市城镇每年鲜蛋的需求量,首先考察消费者年人均可支配收入对年人均鲜蛋需求量的影响。
由经济理论知,当人均可支配收入提高时,鲜蛋需求量也相应增加。
但是,鲜蛋需求量除受消费者可支配收入影响外,还要受到其自身价格、人们的消费习惯及其他一些随机因素的影响。
为了表示鲜蛋需求量与消费者可支配收入之间非确定的依赖关系,设Y i为鲜蛋需求量,X i为可支配收入,我们将影响鲜蛋需求量的其他因素归并到随机变量吨中,建立这两个变量之间的数学模型:Y i = β0 + β1 X i + u i (2.1)其中Y i——称作被解释变量;X i——称作解释变量;u i——随机误差项(随机扰动项或随机项、误差项);β0 、β1——回归系数(待定系数或待定参数)。
在数学模型(2.1)式中,当X i发生变化时,按照一定规律影响另一变量Y i,而Y i的变化并不影响X i 。

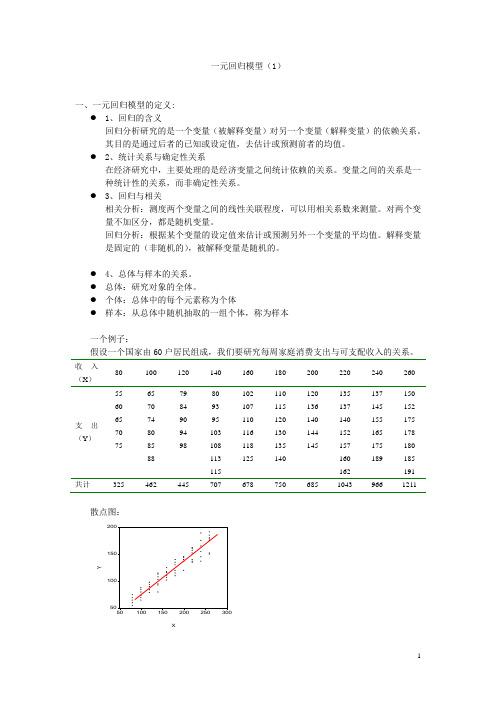
一元回归模型(1)一、一元回归模型的定义:● 1、回归的含义回归分析研究的是一个变量(被解释变量)对另一个变量(解释变量)的依赖关系。
其目的是通过后者的已知或设定值,去估计或预测前者的均值。
● 2、统计关系与确定性关系在经济研究中,主要处理的是经济变量之间统计依赖的关系。
变量之间的关系是一种统计性的关系,而非确定性关系。
● 3、回归与相关相关分析:测度两个变量之间的线性关联程度,可以用相关系数来测量。
对两个变量不加区分,都是随机变量。
回归分析:根据某个变量的设定值来估计或预测另外一个变量的平均值。
解释变量是固定的(非随机的),被解释变量是随机的。
● 4、总体与样本的关系。
● 总体:研究对象的全体。
● 个体:总体中的每个元素称为个体● 样本:从总体中随机抽取的一组个体,称为样本一个例子:假设一个国家由60户居民组成,我们要研究每周家庭消费支出与可支配收入的关系。
收入(X )80 100 120 140 160 180 200 220 240 260 支出(Y )55 65 79 80 102 110 120 135 137 150 6070 84 93 107 115 136 137 145 152 65 74 90 95 110 120 140 140 155 175 70 80 94 103 116 130 144 152 165 178 75 85 98 108 118 135 145 157 175 180 88 113 125 140 160 189 185115 162 191 共计32546244570767875068510439661211散点图:5010015020050100150200250300XY总体回归曲线(population regression curve ):当解释变量取给定值时被解释变量的条件均值或期望值的轨迹。
(一)总体回归函数(population regression function,PRF ):)()(i i X f X Y E = 一元回归的总体回归函数:i i i X X f X Y E 21)()(ββ+== 计量分析的随机设定: 随机干扰(随机误差)项:)(i i i X Y E Y u -=有:i i i u X Y E Y +=)(,上式中,)(i X Y E 称为系统性(确定性)成分,i u 称为非系统性成分。


一.一元线性回归模型1. 一元线性回归模型的基本假设有哪些?违背假设是否能估计?为什么? 答:①E(i V |i X )=0 随机项i V 的数学期望为0 ②Var(i V |i X )=E{[i V —E(i V )]2}=E (2i V )=2u σ③COV(i V ,j V )=E{[i V —E(i V )][j V —E(j V )]}=0 i V ,j V 相互独立不相关 ④COV(i V ,i X )=0 解释变量i X 与误差项i V 同期独立无关 ⑤i V ~N(0,2u σ) i X ,i V 服从正态分布的随机变量 违背的话可以估计 但是要对原数据适当的处理 2. 方差分析表与参数估计表的结构变差来源 平方和 自由度 均方F统计量回归 残差 ESS RSS 12n - ESS22e RSS n S -= 1(2)ESSF RSSn =-总变差 TSS1n -21y TSS n S -=―2R =ESS TSS =1—RSSTSS=2212211[()()]()()ni i i n niii i x x y y x x y y ===----∑∑∑TSS=21()nii yy =-∑ ESS=21ˆ()ni yy =-∑ RSS=21ˆ()ni i y y =-∑ Eviews 输出结果 参数估计值 估计值标准差 F 检验 Variable Coefficient Std. Error t-Statistic Prob.C (0β) (S(0ˆβ)) 0β<对0β显著 X 1β>非线性不通过R-squared Adjusted R-squaredProb(F-statistic) >方程本身不是线性的 结论:该案例结果不理想 无论从个别还是总体上原因:(1) 0β,1β个别检验不通过 (2)F 检验远远超过期望的值(>5%or>10%) (3) 2R =拟合度特别差<50%(注:2R >80%or>70%认为拟合度好)3. 回归方程的标准记法ˆi y=0β+1βi x Se=(S(0ˆβ)) (S(1ˆβ)) 22211ˆ()ˆ22nni i i i uey yn n σ==-==--∑∑2221121ˆ()2()ni u i nii e s n x x σβ===--∑∑222211ˆ()[]()Xn ii x s nx x βσ==+-∑ 111ˆˆ()t s ββ= *代表显著性大小 **代表1%下显著 *代表5%下显著 无*代表5%下不显著 4. t 检验与F 检验的步骤(1) t 检验:01:0H β=11:0H β≠Next 111ˆˆ()t s ββ=~t(n-2) Next 查t 分布表临界值2(2)t n α- α取1%或5% Next 当|t|≥2(2)t n α-拒绝原假设10β≠说明y 对x 的一元线性相关显著当|t|<2(2)t n α-不拒绝原假设10β≠说明y 对x 的一元线性相关不显著(2) F 检验:01:0H β=11:0H β≠ Next 12ESSF RSS n =-(上:回归 下:残差)=?(假设=100)Next 查F α(1,n-2) Next 当100≥F α(1,n-2)拒绝0H 说明y 对x 的一元线性相关显著当100<F α(1,n-2)不拒绝0H 说明y 对x 的一元线性相关不显著(注:统计软件用P 值进行检验P>α等价F<F α(1,n-2)此时不拒绝0H 当P<αF>F α(1,n-2)此时拒绝0H ) 二.多元线性回归模型1. 基本假设:(1) 随机误差项i V 的条件期望值为0 即E(i V |1i X …ki X )=0 (2) 随机误差项i V 的条件方差相同Var(i V |1i X …ki X )=2u σ (3) i V 之间无序列相关COV(i V ,j V )=0 (4) i V ~N(0,2u σ)(5)各种解释变量之间不存在显著的线性相关关系 2.矩阵表达式12ˆˆˆ.ˆn y y y y ⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭ 11112211...1.....1...k k n kn x x x x x x x ⎫⎛⎪⎪ =⎪ ⎪ ⎝⎭0ˆˆ.ˆk βββ⎛⎫ ⎪= ⎪ ⎪⎝⎭ 1ˆ()()x x x y β-''= 参见P51 例3-1 3随机误差项u 的方差2u σ的最小二乘估计量221ˆ1nii X en k σ==--∑=21ˆ()1niii y yn k =---∑随机误差项i U 同方差且无序列相关 则方差协方差矩阵Var-COV(u)=E(uu ')=)(112.,...n n u E u u u u ⎛⎫⎪ ⎪ ⎪⎝⎭=2u σI4.方差分析表变差来源 平方和 自由度 均方F统计量回归 残差 ESSRSS 12n - ESS22e RSS n S -= 1(2)ESSF RSSn =-总变差 TSS1n -21y TSS n S -=―2R =ESS TSS TSS=21()n i i y y =-∑ ESS=21ˆ()n i y y =-∑ RSS=21ˆ()ni i y y =-∑ 221111(1)11RSSn n k R R TSS n k n ---=-=----- 222211ˆ()ˆ11nniiii i u ey ySe n k n k σ==-===----∑∑5. P69 8(1) 0β1β3β的个别检验不通过,2β的个别检验通过 (2)F 检验通过 对结果不满意三.违背古典假定的计量经济模型 2. 自相关D-W 检验 (1)d< L d ,u 存在一阶正自相关(2)d>4-L d ,u 存在一阶负自相关 (3)u d <d<4-u d ,不存在自相关(4)L d <d<u d ,或4-u d <d<4-L d 时,u 是否存在自相关,不能确定 4.异方差的white 检验(以二元线性模型为例) 二元线性回归模型:01122i i i i y x x u βββ=+++ ① 异方差与解释变量12,x x 的一般线性关系为:2i σ=0α+11i x α+22i x α+231i x α+242i x α+512i i x x α+i V ②<1>运用OLS 估计的式① <2>计算残差序列i并求2i<3>做2i对1i x ,2i x ,21i x ,22i x ,12i i x x 的辅助回归,即222011223142312ˆˆˆˆˆˆˆi i i i i i i e x x x x x x αααααα=+++++ ③其中2ˆi e 为2i e 的估计<4>计算估计量2nR ,n 为样本容量2R 为辅助回归的可决定系数<5>在不存在异方差的原假设下2nR 服从自由度为5的2χ分布,给定显著性水平α查2χ分布表得临界值2αχ(5) 如果2nR >2αχ(5)则拒绝原假设,表明模型中随机误差存在异方差 5.杜宾二步法:第一步求出自相关系数的估计值ˆ第二步利用ˆ进行广义差分变换 对差分模型利用OLS 求的参数0β和1β的估计值0ˆβ和1ˆβ 6.方差扩大因子检验多元回归模型中多重共线性:1x =f(x2,x3….xk) x2=f(x1,x3…xk) …xj=(x1,x2...1j x -…xk) xk=f(x1,x2….1k x -)对每个回归方程求其决定系数分别为12R ,22R (2)j R (2)k R ,在决定系数中寻求最大而接近者,比如2x R 最大,则可判定解释变量Xj 与其他解释变量的一个或多个相关程度高,因此就使回归方程式y=f(x1,x2….xk)表现高度多重共线性,计量经济学中检验多重共线性时,往往称(1-2j R )为自变量Xj 的容忍度,其倒数为方差扩大因子,记为211j jVIF R =- 当模型中全部k 个自变量所对应的方差扩大因子平均数远远大于1时就表明存在严重的多重共线性。
一元线性回归模型1.一元线性回归模型有一元线性回归模型(统计模型)如下,y t = 0 + 1 x t + u t上式表示变量y t 和x t之间的真实关系。
其中y t 称被解释变量(因变量),x t称解释变量(自变量),u t称随机误差项,0称常数项,1称回归系数(通常未知)。
上模型可以分为两部分。
(1)回归函数部分,E(y t) = 0 + 1 x t,(2)随机部分,u t。
图2.1 真实的回归直线这种模型可以赋予各种实际意义,收入与支出的关系;如脉搏与血压的关系;商品价格与供给量的关系;文件容量与保存时间的关系;林区木材采伐量与木材剩余物的关系;身高与体重的关系等。
以收入与支出的关系为例。
假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。
但实际上数据来自各个家庭,来自各个不同收入水平,使其他条件不变成为不可能,所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。
随机误差项u t中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。
所以在经济问题上“控制其他因素不变”是不可能的。
回归模型的随机误差项中一般包括如下几项内容,(1)非重要解释变量的省略,(2)人的随机行为,(3)数学模型形式欠妥,(4)归并误差(粮食的归并)(5)测量误差等。
回归模型存在两个特点。
(1)建立在某些假定条件不变前提下抽象出来的回归函数不能百分之百地再现所研究的经济过程。
(2)也正是由于这些假定与抽象,才使我们能够透过复杂的经济现象,深刻认识到该经济过程的本质。
通常线性回归函数E(y t) = 0 + 1 x t是观察不到的,利用样本得到的只是对E(y t) = 0 + 1 x t 的估计,即对0和1的估计。
在对回归函数进行估计之前应该对随机误差项u t做出如下假定。
(1) u t 是一个随机变量,u t 的取值服从概率分布。