概率论常用统计分布
- 格式:ppt
- 大小:4.03 MB
- 文档页数:60


概率论与数理统计各种分布总结概率论与数理统计中有许多不同的概率分布,每个分布都具有不同的特征和应用。
下面是一些常见的概率分布的总结:1. 均匀分布(Uniform Distribution):在一个区间内的所有取值都具有相等的概率。
它可以是离散的(离散均匀分布)或连续的(连续均匀分布)。
2. 二项分布(Binomial Distribution):描述了在一系列独立的伯努利试验中成功次数的概率分布。
每个试验只有两个可能结果(成功和失败),并且成功的概率保持不变。
3. 泊松分布(Poisson Distribution):用于描述在给定时间或空间单位内发生某事件的次数的概率分布。
它通常用于模拟稀有事件的发生情况。
4. 正态分布(Normal Distribution):也称为高斯分布,是最常见的连续概率分布之一。
它具有钟形曲线的形状,对称且具有明确的均值和标准差。
许多自然现象和测量数据都可以近似地用正态分布来描述。
5. 指数分布(Exponential Distribution):描述了连续随机事件之间的时间间隔的概率分布。
它通常用于模拟无记忆性事件的发生情况,如设备故障、到达时间等。
6. 卡方分布(Chi-Square Distribution):由正态分布的平方和构成的概率分布。
它在统计推断中广泛应用,特别是在假设检验和信赖区间的计算中。
7. t分布(Student's t-Distribution):用于小样本量情况下参数估计和假设检验。
与正态分布相比,t分布具有更宽的尾部,因此更适用于小样本数据。
8. F分布(F-Distribution):用于比较两个或多个样本方差是否显著不同的概率分布。
它经常用于方差分析和回归分析中。
这只是一些常见的概率分布的总结,还有其他许多分布,每个都在不同的领域和应用中起着重要的作用。

概率论与统计分布公式总结【已整理可直接打印】概率论与统计分布公式总结概率论和统计分布是数学中重要的分支。
本文将总结一些常见的概率论和统计分布公式,以便帮助读者更好地理解和应用这些知识。
一、概率论公式1. 概率计算公式- 条件概率公式:P(A|B) = P(A ∩ B) / P(B)- 乘法法则:P(A ∩ B) = P(A) * P(B|A)- 加法法则:P(A ∪ B) = P(A) + P(B) - P(A ∩ B)- 全概率公式:P(A) = ΣP(A|B) * P(B)2. 期望值和方差- 期望值公式:E(X) = Σx * P(X = x)- 方差公式:Var(X) = Σ(x - E(X))^2 * P(X = x)二、统计分布公式1. 正态分布- 概率密度函数:f(x) = (1 / (σ * √(2π))) * exp(-(x - μ)^2 / (2σ^2)) - 累积分布函数:F(x) = (1 / 2) * (1 + erf((x - μ) / (σ * √2)))2. 泊松分布- 概率质量函数:P(X = k) = (e^(-λ) * λ^k) / k!3. 指数分布- 概率密度函数:f(x) = λ * e^(-λx)4. 二项分布- 概率质量函数:P(X = k) = C(n, k) * p^k * (1 - p)^(n - k)5. t分布- 概率密度函数:f(x) = (Γ((v + 1) / 2) / (√(v * π) * Γ(v / 2))) * (1 + (x^2 / v))^(-(v + 1) / 2)以上是一些常见的概率论和统计分布公式。
希望本文能对您对概率论和统计分布的研究和应用有所帮助。
如需更深入了解,请参考相关教材或咨询专业人士。

概率论与数理统计中的三种重要分布摘要:在概率论与数理统计课程中,我们研究了随机变量的分布,具体地研究了离散型随机变量的分布和连续型随机变量的分布,并简单的介绍了常见的离散型分布和连续型分布,其中二项分布、Poisson 分布、正态分布是概率论中三大重要的分布。
因此,在这篇文章中重点介绍二项分布、Poisson 分布和正态分布以及它们的性质、数学期望与方差,以此来进行一次比较完整的概率论分布的学习。
关键词:二项分布;Poisson 分布;正态分布;定义;性质一、二项分布二项分布是重要的离散型分布之一,它在理论上和应用上都占有很重要的地位,产生这种分布的重要现实源泉是所谓的伯努利试验。
(一)泊努利分布[Bernoulli distribution ] (两点分布、0-1分布)1.泊努利试验在许多实际问题中,我们感兴趣的是某事件A 是否发生。
例如在产品抽样检验中,关心的是抽到正品还是废品;掷硬币时,关心的是出现正面还是反面,等。
在这一类随机试验中,只有两个基本事件A 与A ,这种只有两种可能结果的随机试验称为伯努利试验。
为方便起见,在一次试验中,把出现A 称为“成功”,出现A 称为“失败” 通常记(),p A P = ()q p A P =-=1。
2.泊努利分布定义:在一次试验中,设p A P =)(,p q A P -==1)(,若以ξ记事件A 发生的次数,则⎪⎪⎭⎫⎝⎛ξp q 10~,称ξ服从参数为)10(<<p p 的Bernoulli 分布或两点分布,记为:),1(~p B ξ。
(二)二项分布[Binomial distribution]把一重Bernoulli 试验E 独立地重复地进行n 次得到n 重Bernoulli 试验。
定义:在n 重Bernoulli 试验中,设(),()1P A p P A q p ===-若以ξ记事件A 发生的次数,则ξ为一随机变量,且其可能取值为n ,,2,1,0 ,其对应的概率由二项分布给出:{}k n kk n p p C k P --==)1(ξ,n k ,,3,2,1,0 =,则称ξ服从参数为)10(,<<p p n 的二项分布,记为),(~p n B ξ。

概率论分布函数概率论分布函数是概率论中的重要概念,它描述了一个随机变量取值的概率分布情况。
在统计学和概率论中,有许多常见的概率分布函数,如正态分布、均匀分布、泊松分布等。
本文将针对这些常见的概率分布函数进行介绍和解释。
一、正态分布(Normal Distribution)正态分布是自然界中最常见的分布之一。
它以钟形曲线形式展现,其分布函数描述了随机变量在不同取值上的概率密度。
正态分布的特点是对称且呈现出标准差的影响,标准差越大,曲线越平缓。
正态分布广泛应用于自然科学、社会科学等领域,用于描述各种现象的分布情况。
二、均匀分布(Uniform Distribution)均匀分布是最简单的概率分布之一,它描述了随机变量在一定范围内各个取值出现的概率是相等的。
均匀分布的分布函数是一个常数函数,其特点是在一定范围内的取值概率是相等的。
均匀分布常用于模拟随机事件或生成随机数,广泛应用于数值计算和概率统计等领域。
三、泊松分布(Poisson Distribution)泊松分布是用于描述单位时间(或空间)内随机事件发生次数的概率分布。
泊松分布的分布函数可以表示在一段时间或空间内发生某种事件的次数的概率。
泊松分布的特点是具有独立性和稀有性,适用于描述稀有事件的发生情况,如电话交换机接听电话的次数、汽车在某路段通过的次数等。
四、指数分布(Exponential Distribution)指数分布是一种连续概率分布函数,描述了随机事件发生的时间间隔的概率分布。
指数分布的分布函数具有单峰性,随着时间的推移,事件发生的概率逐渐减小。
指数分布常用于描述随机事件的间隔时间,如人们等待公交车的时间、网络传输数据包到达的时间等。
五、二项分布(Binomial Distribution)二项分布是描述在一次试验中成功次数的概率分布函数。
二项分布的分布函数描述了在一定次数的独立重复试验中成功次数的概率分布情况。
二项分布的特点是具有两个参数,成功概率和试验次数,常用于描述二元随机事件的发生情况,如硬币正反面的次数、投篮命中的次数等。

概率论八大分布概率论是统计学的一个重要分支,它探究随机变量及其关联性,研究不同的现象的结果和概率分布之间的关系,提供量化的度量工具以确保实际应用的准确性。
概率论八大分布是概率论中应用最为广泛的几个分布,它们提供了研究各种随机现象的基础,影响了大量的现实问题的解决方案,其实质是根据大量试验获得的数据来拟合出不同类型的概率分布。
首先,概率论八大分布中首先涉及的是正态分布。
是一种最常见的概率分布,也称作高斯分布。
正态分布的图形可以表示为一个双峰的曲线,其特点是只有两个参数:均值μ和标准差σ,它可以用来描述平均值的概率密度分布情况,即随机变量的取值可能会靠近均值μ。
其次,另一个重要的概率分布是均匀分布。
均匀分布是一种两个参数(下限a和上限b)的概率分布,这两个参数分别代表了随机变量可能取值的范围,即该变量只能在a和b之间取值,其中每一个结果都有相同的概率。
第三,指数分布是另一种广泛使用的分布,它具有唯一的参数λ,该参数代表了随机变量的变化率。
指数分布的特性是,它可以用来衡量发生某种事件的时间间隔,以及研究受试者遭受某种不利影响的持续时间。
接下来,椭圆分布(又称偏态分布)是一种广泛应用的概率分布,它可以用来描述数据集中对称性差异。
椭圆分布有三个参数:均值μ、标准差σ和偏度γ,其中偏度γ决定了数据集中偏斜程度。
接着,卡方分布是一种常常用来拟合实验数据的分布,它用一个参数k来描述数据的分布形状。
卡方分布是一种双峰分布,它的参数k决定了其双峰形状陡峭程度。
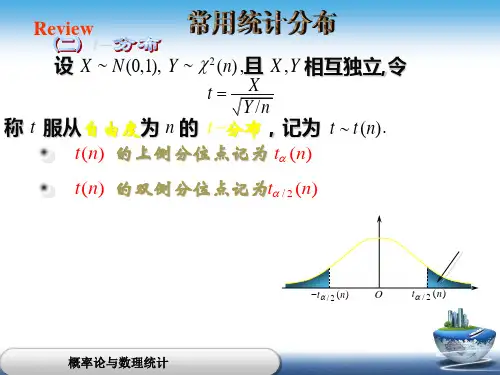
此外,t-分布是一种密度比较大的分布,它是一种卡方分布的变种,但具有更大的连续性。
t-分布有两个参数,即自由度ν和不同的中心值μ,它主要用于检验两个样本之间的差异和单样本的参数估计。
接着,F-分布是t-分布的多变量拓展,如果两个样本是来自不同的总体,那么可以使用F-分布来检验这两个样本的差异。
F-分布的参数为两个自由度,即自由度1和自由度2,它最常用于在两个样本之间检验方差的差异。

概率论与数理统计期末复习重要知识点第二章知识点:1.离散型随机变量:设X 是一个随机变量,如果它全部可能的取值只有有限个或可数无穷个,则称X 为一个离散随机变量。
2.常用离散型分布:(1)两点分布(0-1分布):若一个随机变量X 只有两个可能取值,且其分布为12{},{}1(01)P X x p P X x pp ====-<<,则称X 服从12,x x 处参数为p 的两点分布。
两点分布的概率分布:12{},{}1(01)P X x p P X x pp ====-<<两点分布的期望:()E X p =;两点分布的方差:()(1)D X p p =-(2)二项分布:若一个随机变量X 的概率分布由式{}(1),0,1,...,.k kn k n P x k C p p k n -==-=给出,则称X 服从参数为n,p 的二项分布。
记为X~b(n,p)(或B(n,p)). 两点分布的概率分布:{}(1),0,1,...,.k kn k n P x k C p p k n -==-=二项分布的期望:()E X np =;二项分布的方差:()(1)D X np p =-(3)泊松分布:若一个随机变量X 的概率分布为{},0,0,1,2,...!kP X k ek k λλλ-==>=,则称X 服从参数为λ的泊松分布,记为X~P (λ)泊松分布的概率分布:{},0,0,1,2,...!kP X k ek k λλλ-==>=泊松分布的期望:()E X λ=;泊松分布的方差:()D X λ=4.连续型随机变量:如果对随机变量X 的分布函数F(x),存在非负可积函数()f x ,使得对于任意实数x ,有(){}()xF x P X x f t dt-∞=≤=⎰,则称X 为连续型随机变量,称()f x 为X 的概率密度函数,简称为概率密度函数。
5.常用的连续型分布:(1)均匀分布:若连续型随机变量X 的概率密度为⎪⎩⎪⎨⎧<<-=其它,0,1)(bx a a b x f ,则称X 在区间(a,b )上服从均匀分布,记为X~U(a,b)均匀分布的概率密度:⎪⎩⎪⎨⎧<<-=其它,0,1)(b x a a b x f 均匀分布的期望:()2a bE X +=;均匀分布的方差:2()()12b a D X -= (2)指数分布:若连续型随机变量X 的概率密度为00()0xe xf x λλλ-⎧>>=⎨⎩,则称X 服从参数为λ的指数分布,记为X~e (λ)指数分布的概率密度:00()0xe xf x λλλ-⎧>>=⎨⎩指数分布的期望:1()E X λ=;指数分布的方差:21()D X λ=(3)正态分布:若连续型随机变量X的概率密度为22()2()x f x x μσ--=-∞<<+∞则称X 服从参数为μ和2σ的正态分布,记为X~N(μ,2σ)正态分布的概率密度:22()2()x f x x μσ--=-∞<<+∞正态分布的期望:()E X μ=;正态分布的方差:2()D X σ=(4)标准正态分布:20,1μσ==,2222()()x t xx x e dtϕφ---∞=⎰标准正态分布表的使用: (1)()1()x x x φφ<=--(2)~(0,1){}{}{}{}()()X N P a x b P a x b P a x b P a x b b a φφ<≤=≤≤=≤<=<<=-(3)2~(,),~(0,1),X X N Y N μμσσ-=故(){}{}()X x x F x P X x P μμμφσσσ---=≤=≤={}{}()()a b b a P a X b P Y μμμμφφσσσσ----<≤=≤≤=-定理1: 设X~N(μ,2σ),则~(0,1)X Y N μσ-=6.随机变量的分布函数: 设X 是一个随机变量,称(){}F x P X x =≤为X 的分布函数。

常见概率分布类型解析概率分布是描述随机变量可能取值的概率的函数。
在统计学和概率论中,有许多常见的概率分布类型,它们在不同的情境下具有不同的特点和应用。
本文将对几种常见的概率分布类型进行解析,包括二项分布、泊松分布、正态分布和指数分布。
一、二项分布二项分布是最常见的离散概率分布之一,描述了在一系列独立重复的同一试验中成功的次数的概率分布。
在每次试验中,事件只有两种可能的结果,通常用“成功”和“失败”来表示。
二项分布的概率质量函数可以用以下公式表示:P(X=k) = C(n,k) * p^k * (1-p)^(n-k)其中,P(X=k)表示成功的次数为k的概率,n表示试验的总次数,p表示每次试验成功的概率,C(n,k)表示组合数。
二项分布常用于描述二元随机变量的分布,例如抛硬币、赌博游戏等。
在实际应用中,二项分布可以用来估计二元事件发生的概率,进行假设检验等。
二、泊松分布泊松分布是描述单位时间(或单位空间)内随机事件发生次数的概率分布。
泊松分布适用于事件发生的次数是独立的且平均发生率是恒定的情况。
泊松分布的概率质量函数可以用以下公式表示:P(X=k) = (λ^k * e^(-λ)) / k!其中,P(X=k)表示事件发生次数为k的概率,λ表示单位时间(或单位空间)内事件平均发生率。
泊松分布常用于描述稀有事件的发生情况,例如电话交换机接到的电话数、一天内发生的交通事故数等。
在实际应用中,泊松分布可以用来预测未来一段时间内事件发生的概率。
三、正态分布正态分布是最常见的连续概率分布之一,也称为高斯分布。
正态分布具有钟形曲线的特点,均值、方差完全决定了正态分布的形状。
正态分布的概率密度函数可以用以下公式表示:f(x) = (1 / (σ * sqrt(2π))) * e^(-(x-μ)^2 / (2σ^2))其中,f(x)表示随机变量X的概率密度函数,μ表示均值,σ表示标准差。
正态分布在自然界和社会现象中广泛存在,例如身高、体重、考试成绩等。

统计分布公式数据统计分布是描述一组数据的集中趋势和分散程度的重要工具,它是对大量随机现象的抽象和概括。
在数据分析中,我们常常会遇到各种各样的统计分布,如正态分布、泊松分布、卡方分布等。
这些分布都有其特定的公式和特性,可以帮助我们更好地理解和解释数据。
一、正态分布正态分布,又称为高斯分布,是最常见的一种连续型概率分布。
它的特点是所有的模式值都集中在均值附近,且离均值越远,概率密度越小。
正态分布的公式如下:f(x) = 1/σ√(2π) * e^[-(x-μ)^2 / (2σ^2)]其中,μ为均值,σ为标准差,e为自然对数的底数,约为2.71828。
这个公式描述了任意一个x值出现的概率。
二、泊松分布泊松分布是一种离散型概率分布,通常用于描述单位时间内随机事件发生的次数。
例如,电话交换机接到呼叫的次数、汽车通过路口的次数等。
泊松分布的公式如下:P(X=k) = (λ^k * e^-λ) / k!其中,λ为平均发生率,k为发生的次数,!表示阶乘。
这个公式描述了在给定时间内,事件发生k次的概率。
三、卡方分布卡方分布是一种连续型概率分布,主要用于检验样本是否符合某种理论分布,或者比较两个样本的差异。
卡方分布的自由度(df)等于构成卡方统计量的独立变量的个数减1。
卡方分布的公式如下:f(x) = (1/2^(df/2) * Γ(df/2)) / √(x) * e^(-x/2)其中,Γ为伽马函数,x为卡方统计量的值,df为自由度。
这个公式描述了在给定自由度下,卡方统计量取某个值的概率。
四、t分布t分布是一种连续型概率分布,主要用于小样本的均值检验和方差分析。
t分布的形状取决于自由度,当自由度趋于无穷时,t分布接近正态分布。
t分布的公式如下:f(t) = Γ((ν+1)/2) / (√(νπ) * Γ(ν/2)) * (1+t^2/ν)^(-(ν+1)/2)其中,t为t统计量的值,ν为自由度。
这个公式描述了在给定自由度下,t统计量取某个值的概率。

概率论八大分布的期望和方差
概率论是数学中一个很重要的分支,它通过概率来研究不确定性事件发生的规律。
其中,概率论8大分布描述了多次实验和事件中,可能出现的概率位置及其期望等统计量,被广泛用于对数据的拟合和预测。
首先说明的是正态分布,即平均数和方差成正比的分布,它的期望为μ,标准差为σ,因此它的方差为σ²。
接下来介绍的是指数分布,它是描述数据发生在某一时刻及其之前的分布,其期望是1/λ,方差也为1/λ²,其中λ>0。
三角分布是描述一个实验发生三次时的分布,其期望是a+b+c/3,方差为abcb/36。
威布尔分布的期望是α/(1+α),方差为α/((1+α)²(1+2α))。
泊松分布是按概率论中常用的概率模型,其期望是λ,方差也为λ。
F比例的期望依赖于自由度的不同,给定两个自由度为m和n的差异,它的期望为m/n,方差为2m²n²/((m+n)²(m+n+2))。
相间分布是另一种概率模型,它描述了一个试验出现在某个位置的概率,它的期望为μ+σ/2,及其方差为(σ/2)²。
最后要介绍的是Gamma分布,它由α和β决定,其期望为αβ,方差为
αβ²。
以上是概率论8种分布的期望和方差。
科学家们利用这些概念,处理概率性事件作出合理的决策,从而取得成果。
从长远来看,熟悉概率论8大分布的期望和方差,对于科学家精确处理概率性问题有着至关重要的作用。
概率论——常⽤分布伯努利试验 伯努利试验(Bernoulli experiment)是在同样的条件下重复地、相互独⽴地进⾏的⼀种随机试验,其特点是该随机试验只有两种可能结果:发⽣或者不发⽣。
我们假设该项试验独⽴重复地进⾏了 n 次,那么就称这⼀系列重复独⽴的随机试验为 n 重伯努利试验,或称为伯努利概型。
单个伯努利试验是没有多⼤意义的,然⽽,当我们反复进⾏伯努利试验,去观察这些试验有多少是成功的,多少是失败的,事情就变得有意义了,这些累计记录包含了很多潜在的⾮常有⽤的信息。
如果⽆穷随机变量序列 X1,X2,… 是独⽴同分布 (i.i.d.) 的,⽽且每个随机变量 X i 都服从参数为 p 的伯努利分布, 那么 随机变量 X1,X2,… 就形成参数为 p 的⼀系列伯努利试验。
同样,如果 n 个随机变量 X1,X2,…,X n 独⽴同分布,并且都服从参数为 p 的伯努利分布,则随机变量 X1,X2,…,X n 形成参数为 p 的 n 重伯努利试验。
下⾯举⼏个例⼦加以说明,假定重复抛掷⼀枚均匀硬币,如果在第 i 次抛掷中出现正⾯,令 X i=1 ;如果出现反⾯X i=0,那么,随机变量 X1,X2,… 就形成参数为 p=12 的⼀系列伯努利试验,同样,假定由⼀个特定机器⽣产的零件中 10% 是有缺陷的,随机抽取n 个进⾏观测,如果第 1 个零件有缺陷,令 X i=1 ; 如果没有缺陷,令 X i=0,i=1,2,…,n , 那么,随机变量 X1,X2,…,X n 就形成参数为 p=110 的 n 重伯努利试验。
离散分布⼆项分布 定义:在 n 次独⽴重复的伯努利试验中,设每次试验中事件 A 发⽣的概率为 p。
⽤ X 表⽰ n 重伯努利试验中事件 A 发⽣的次数,则 X 的可能取值为 0,1,…,n ,且对每⼀个 k(0≤k≤n),事件 X=k 即为 “ n 次试验中事件 A 恰好发⽣ k 次”,随机变量 X 的离散概率分布即为⼆项分布(Binomial Distribution)。
概率论八大分布公式概率论中的八大分布公式是指常见的概率分布函数,它们在统计学和概率分析中有着广泛的应用。
这些分布包括:二项分布、泊松分布、均匀分布、正态分布、指数分布、伽玛分布、贝塔分布和卡方分布。
下面将对这八个分布公式进行简要介绍。
1. 二项分布二项分布是离散概率分布的一种,适用于只有两种可能结果的事件,如投掷硬币的结果。
它的概率分布函数可以用来计算在n次独立重复试验中,成功事件发生k次的概率。
2. 泊松分布泊松分布是一种离散概率分布,用于描述单位时间或空间内事件发生的次数。
它的概率分布函数可以用来计算在一个固定时间或空间单位内,事件发生k次的概率。
3. 均匀分布均匀分布是一种连续概率分布,它的概率密度函数在一个区间内的取值相等。
例如,投掷一个均匀骰子的结果就符合均匀分布。
4. 正态分布正态分布是一种连续概率分布,也被称为高斯分布。
它的概率密度函数呈钟形曲线,对称分布在均值附近。
许多自然界的现象都可以用正态分布来描述,如身高、体重等。
5. 指数分布指数分布是一种连续概率分布,用于描述事件发生的间隔时间。
它的概率密度函数呈指数下降的形式,适用于模拟一些随机事件的发生。
6. 伽玛分布伽玛分布是一种连续概率分布,它的概率密度函数呈正偏态分布。
伽玛分布常用于描述一些随机变量的持续时间,如寿命、等待时间等。
7. 贝塔分布贝塔分布是一种连续概率分布,它的概率密度函数呈S形曲线。
贝塔分布常用于描述概率或比率的分布,如投掷硬币的概率、产品的可靠性等。
8. 卡方分布卡方分布是一种连续概率分布,它的概率密度函数呈非对称形状。
卡方分布常用于统计推断中的假设检验和置信区间估计,如样本方差的分布。
概率论八大分布公式涵盖了离散分布和连续分布的常见情况。
这些分布公式在实际应用中具有重要的意义,可用于模拟随机事件、进行统计推断以及进行风险评估等。
熟练掌握这些分布公式,对于数据分析和决策制定都具有重要的帮助。
概率论常见的几种分布常见的概率论分布有:均匀分布、正态分布、泊松分布和指数分布。
1. 均匀分布均匀分布是指在一段区间内,各个取值的概率是相等的。
比如在一个骰子的例子中,每个面出现的概率是相等的,为1/6。
均匀分布在实际应用中常用于随机数生成、样本抽取等场景。
2. 正态分布正态分布又被称为高斯分布,是最常见的概率分布之一。
正态分布的特点是呈钟形曲线,数据集中在均值周围,并且具有对称性。
正态分布在自然界中广泛存在,比如人的身高、体重等都近似服从正态分布。
在统计学和数据分析中,正态分布的应用非常广泛,例如在建模、假设检验和置信区间估计等方面。
3. 泊松分布泊松分布是一种离散概率分布,描述了在一段时间或空间内,某事件发生的次数的概率分布。
泊松分布的特点是事件之间是独立的,并且事件发生的平均速率是恒定的。
泊松分布在实际应用中常用于描述稀有事件的发生概率,比如电话呼叫中心的接听次数、交通事故的发生次数等。
4. 指数分布指数分布是描述连续随机变量的概率分布,用于描述时间间隔的概率分布。
指数分布的特点是事件之间是独立的,并且事件发生的速率是恒定的。
指数分布在实际应用中常用于描述如等待时间、寿命等连续性事件的概率分布。
这四种分布在概率论和统计学中都有广泛的应用。
它们分别适用于不同的场景和问题,能够帮助人们理解和分析数据。
在实际应用中,我们常常需要通过对数据进行建模和分析来确定数据的分布类型,从而更好地理解数据的特征和规律。
除了这四种常见的分布外,还有其他许多概率分布,例如二项分布、伽玛分布、贝塔分布等。
每种分布都有其独特的特点和应用领域。
在实际应用中,选择合适的分布模型对数据进行建模和分析是非常重要的,可以帮助我们更好地理解数据,做出准确的推断和预测。
概率论中常见的几种分布包括均匀分布、正态分布、泊松分布和指数分布。
每种分布都有其特点和应用场景,在实际问题中选择合适的分布模型对数据进行建模和分析是非常重要的。
通过对数据的分布进行研究,我们能够更好地理解数据的规律和特征,为决策提供科学依据。
概率统计频率分布【概率统计频率分布】概率统计是数学中重要的概念之一,用于研究随机事件出现的规律性。
概率统计的核心是频率分布,即某个事件发生的次数的统计结果。
本文将详细介绍概率统计的频率分布。
概率统计的频率分布指的是统计一个事件发生的次数,然后将这些次数进行分类统计,得到各个次数所占的比例。
这样就可以了解事件发生的规律性,并可以对未来事件的发生进行预测。
在概率统计中,常用的频率分布有离散分布和连续分布两种类型。
一、离散分布离散分布是指事件发生的结果是离散的、有限的,且每个结果之间是互斥的。
常见的离散分布有伯努利分布、二项分布和泊松分布等。
1. 伯努利分布:用于描述一次试验只有两个可能结果的情况,如抛硬币的结果只有正面和反面两种可能。
伯努利分布只有一个参数p,表示事件发生的概率。
2. 二项分布:用于描述n次独立的伯努利试验中事件发生k次的概率分布,其中n表示试验次数,k表示事件发生的次数。
二项分布有两个参数n和p,分别表示试验次数和事件发生的概率。
3. 泊松分布:用于描述在一定时间或空间内,事件发生的次数的概率分布。
泊松分布有一个参数λ,表示单位时间或单位空间内事件发生的平均次数。
二、连续分布连续分布是指事件发生的结果是连续的,不是有限个的点。
常见的连续分布有正态分布、指数分布和均匀分布等。
1. 正态分布:也称为高斯分布,是最常见的连续分布之一。
其概率密度函数呈钟形曲线,对称以均值为中心。
正态分布具有两个参数,均值μ和方差σ²。
2. 指数分布:用于描述随机事件之间的间隔时间,如等车的等待时间、设备的寿命等。
指数分布具有一个参数λ,表示单位时间内事件发生的平均次数。
3. 均匀分布:也称为矩形分布,是最简单的连续分布之一。
其概率密度函数在一个区间内是常数,区间外为零。
均匀分布具有两个参数,最小值a和最大值b。
概率统计的频率分布在现实生活中有广泛的应用,例如用于银行窗口的等待时间、产品的寿命、销售额的分布等。