粗粒度并行遗传算法的MapReduce并行化实现
- 格式:pdf
- 大小:319.62 KB
- 文档页数:6


基于Hadoop MapReduce和粗粒度并行遗传算法的大数据
聚类方法改进
郭晨晨;朱红康
【期刊名称】《黑龙江大学工程学报》
【年(卷),期】2016(007)003
【摘要】为了提高并行遗传算法在大数据聚类问题中的时间效率,通过利用粗粒度遗传算法的并行化思想,提出了Hadoop平台上基于MapReduce计算框架的粗粒度遗传算法的并行化设计。
该思想主要来源于大数据体量庞大的特点,聚类算法时
间消耗巨大。
并行是解决算力不足的一个较为有效的方法,实验结果表明,并行化的
遗传算法在处理大数据聚类时相比传统的串行化处理在时间消耗方面有明显的降低。
【总页数】5页(P87-91)
【作者】郭晨晨;朱红康
【作者单位】山西师范大学数学与计算机科学学院,山西临汾041000
【正文语种】中文
【中图分类】TP18
【相关文献】
1.基于MapReduce和并行遗传算法的大数据聚类问题研究 [J], 郭晨晨;朱红康
2.基于Hadoop MapReduce和粗粒度并行遗传算法的大数据聚类方法改进 [J], 郭晨晨;朱红康
3.GOP-MRPGA:基于MapReduce大数据计算模型的遗传算子前置并行遗传算法
[J], 任刚;狄文辉;郜广兰;王鲜芳;吴长茂;武文佳;赵开新
4.基于Hadoop和MapReduce的大数据处理系统设计与实现 [J], 董楠楠;单晓欢;牟有静
5.GOP-MRPGA:基于MapReduce大数据计算模型的遗传算子前置并行遗传算法[J], 任刚;狄文辉;郜广兰;王鲜芳;吴长茂;武文佳;赵开新
因版权原因,仅展示原文概要,查看原文内容请购买。

mapreduce并行编程原理-回复为什么需要并行编程?随着计算机系统的发展,数据量的爆炸性增长推动了对计算能力的巨大需求。
然而,传统的单线程编程模型已经无法满足这一需求,因为它们无法充分利用现代计算机系统中的多核处理器和分布式计算资源。
为了提高计算效率,人们开始使用并行编程来实现任务的并发执行。
并行编程是一种编程模式,它可以在多个处理单元或计算资源上同时执行不同的任务。
这种模式允许任务之间以并行方式协同工作,从而提高整体系统的处理能力。
并行编程的一个重要应用领域是数据处理,而MapReduce是一种常用的并行编程框架。
MapReduce是一种用于大规模数据处理的并行编程框架,它由Google 提出,并被广泛应用于分布式计算领域。
它提供了一种简单而有效的方式来处理大量的数据,无论是在单机还是分布式环境中。
MapReduce的核心原理是将任务分解为两个阶段:映射(Map)和归约(Reduce)。
在映射阶段中,系统将输入数据集分割为若干个小块,并对每个小块应用相同的映射函数。
映射函数将输入数据转换为键值对的形式,并输出中间结果。
在归约阶段中,系统将相同键的中间结果进行合并,并通过归约函数将它们转换为最终结果。
为了实现MapReduce,并行处理框架需要进行任务的分配和调度。
在分布式环境中,MapReduce框架可以自动将数据和任务分配到可用的计算资源上,从而实现任务的并行执行。
这种分布式任务调度可以大大提高数据处理的效率,充分利用了计算资源的并行性。
为了更好地理解MapReduce,并行编程的原理,我们可以通过一个例子来说明。
假设我们有一个包含1亿条日志记录的文件,我们希望统计每个IP地址出现的次数。
传统的单线程方法可能需要花费很长时间来处理这么大的数据集,而使用MapReduce并行编程框架可以有效地加快处理速度。
首先,我们需要将输入数据集分割为若干个小块,并将它们分发给不同的节点进行处理。
每个节点将接收到的数据块应用映射函数,将其中的IP 地址作为键,并将出现的次数作为值输出。

并行MapReduce PLS算法及其在光谱分析中的应用杨辉华;杜玲玲;李灵巧;唐天彪;郭拓;梁琼麟;王义明;罗国安【期刊名称】《光谱学与光谱分析》【年(卷),期】2012(32)9【摘要】偏最小二乘(PLS)算法是常用的光谱建模算法,然而对于海量光谱处理情形,在单台计算机上建模及优化时间开销很大.基于MapReduce编程模式,提出了并行MapReduce PLS回归算法,包括并行数据标准化和并行主成分提取两个过程.在多台普通计算机上搭建Hadoop云计算集群平台,以近红外光谱处理为例,开展了算法验证实验.实验结果表明,基于MapReduce编程模式的并行PLS算法对海量近红外光谱数据集进行回归建模时,能有效提高建模速度,随计算机台数的增多可得到接近线性的加速比,并具有良好的扩展性.%Partial least squares (PLS) has been widely used in spectral analysis and modeling, and it is computation-intensive and time-demanding when dealing with massive data. To solve this problem effectively, a novel parallel PLS using MapReduce is proposed, which consists of two procedures, the parallelization of data standardizing and the parallelization of principal component computing. Using NIR spectral modeling as an example, experiments were conducted on a Hadoop cluster, which is a collection of ordinary computers. The experimental results demonstrate that the parallel PLS algorithm proposed can handle massive spectra, can significantly cut down the modeling time, and gains a basically linear speedup, and can be easily scaled up.【总页数】6页(P2399-2404)【作者】杨辉华;杜玲玲;李灵巧;唐天彪;郭拓;梁琼麟;王义明;罗国安【作者单位】桂林电子科技大学电子工程与自动化学院,广西桂林541004;桂林电子科技大学计算机科学与工程学院,广西桂林541004;桂林电子科技大学计算机科学与工程学院,广西桂林541004;桂林电子科技大学计算机科学与工程学院,广西桂林541004;桂林电子科技大学计算机科学与工程学院,广西桂林541004;清华大学分析中心, 北京100084;清华大学分析中心, 北京100084;清华大学分析中心, 北京100084【正文语种】中文【中图分类】O657.3【相关文献】1.粗粒度并行遗传算法的MapReduce并行化实现 [J], 程兴国;肖南峰2.双层PLS算法及其在近红外光谱分析中的应用 [J], 成忠3.基于MapReduce的并行PLSA算法及在文本挖掘中的应用 [J], 李宁;罗文娟;庄福振;何清;史忠植4.基于MapReduce的并行PLS过程监控算法实现 [J], 王德政;张益农;杨帆5.PLS算法在激光诱导击穿光谱分析炉渣成分中的应用 [J], 陈兴龙;董凤忠;王静鸽;倪志波;贺文干;付洪波;徐骏因版权原因,仅展示原文概要,查看原文内容请购买。

阐述mapreduce并行计算模式MapReduce是一种并行计算模式,它被广泛应用于大规模数据处理和分析。
本文将阐述MapReduce的工作原理和并行计算模式,并探讨其在实际应用中的优缺点。
一、MapReduce的工作原理1.1 Map阶段Map阶段是MapReduce任务的第一阶段,其主要作用是将输入数据集中的每个数据项映射为一组键值对。
在这个阶段中,MapReduce 将输入数据集分成M个小的数据片段,并将这些数据片段交给多个Map任务并行处理。
每个Map任务会对其分配的数据片段进行处理,将其转化为一组键值对,并将这些键值对暂时存储在内存中。
1.2 Shuffle阶段Shuffle阶段是MapReduce任务的第二阶段,其主要作用是将Map 阶段产生的键值对按照键的值进行排序,并将相同键值的键值对分配到同一个Reduce任务中进行处理。
在这个阶段中,MapReduce会将所有Map任务产生的键值对进行合并,并按照键的值进行排序。
排序后的键值对会被分配到相应的Reduce任务中进行处理。
1.3 Reduce阶段Reduce阶段是MapReduce任务的第三阶段,其主要作用是对Shuffle阶段产生的键值对进行聚合计算。
在这个阶段中,每个Reduce任务会对其分配的键值对进行聚合计算,并将计算结果输出到磁盘上。
二、MapReduce的并行计算模式MapReduce的并行计算模式主要包括Map并行计算和Reduce并行计算两种模式。
2.1 Map并行计算Map并行计算是指将输入数据集中的每个数据项映射为一组键值对的过程。
在Map并行计算中,MapReduce将输入数据集分成M个小的数据片段,并将这些数据片段交给多个Map任务并行处理。
每个Map任务会对其分配的数据片段进行处理,将其转化为一组键值对,并将这些键值对暂时存储在内存中。
Map并行计算的优点是可以充分利用多核CPU的计算能力,提高计算效率。

MapReduce并行计算技术发展综述摘要:经过几年的发展,并行编程模型MapReduce产生了若干个改进框架,它们都是针对传统MapReduce的不足进行的修正或重写.本文阐述和分析了这些研究成果,包括:以HaLoop为代表的迭代计算框架、以Twitter为代表的实时计算框架、以ApacheHama为代表的图计算框架以及以ApacheY ARN为代表的框架管理平台.这些专用系统在大数据领域发挥着越来越重要的作用.MapReduce[1]是Google公司于2004年提出的能并发处理海量数据的并行编程模型,其特点是简单易学、适用广泛,能够降低并行编程难度,让程序员从繁杂的并行编程工作中解脱出来,轻松地编写简单、高效的并行程序.针对上述问题,MapReduce并行编程模型的最大优势在于能够屏蔽底层实现细节,有效降低并行编程难度,提高编程效率.其主要贡献在于: 使用廉价的商用机器组成集群,费用较低,同时又能具有较高的性能; 松耦合和无共享结构使之具有良好的可扩展性; 用户可根据需要自定义Map、Reduce和Partition等函数; 提供了一个运行时支持库,它支持任务的自动并行执行.提供的接口便于用户高效地进行任务调度、负载均衡、容错和一致性管理等; MapReduce适用范围广泛,不仅适用于搜索领域,也适用于满足MapReduce要求的其它领域计算任务2 MapReduce总体研究状况最近几年,在处理TB和PB级数据方面,MapReduce已经成为使用最为广泛的并行编程模型之一.国内外MapReduce相关的研究成果主要有以下几方面:(1)在编程模型改进方面:MapReduce存在诸多不足.目前,典型研究成果有Barrier-lessMapReduce[6]、MapReduceMerge[7]、Oivos[8]、Kahnprocessnetworks[9]等.但这些模型均仅针对MapReduce某方面的不足,研究片面,并且都没有得到广泛应用,部分模型也不成熟(2)在模型针对不同平台的实现方面:典型研究成果包括:Hadoop[10]、Phoenix[11,12]、Mars13]、CellMapRe-duce[14]、Misco[15]和Ussop[16]部分平台(例如:GPUs和Cell/B.E.)由于底层硬件比较复杂,造成编程难度较大,增加了用户编程的负担.\(3)在运行时支持库(包括:任务调度、负载均衡和容错)方面:常用的任务调度策略是任务窃取,但该策略有时会加大通信开销.典型的研究成果包括:延迟调度策略[17]、LATE调度策略[18]和基于性能驱动的任务调度策略[19]等.在容错方面的典型研究成果是reduce对象[20].目前,运行时支持库中针对一致性管理和资源分配等方面的研究相对较少.(4)在性能分析与优化方面: 目前, 文献[ 21]主要研究在全虚拟环境下MapReduce 性能分析, 文献[ 22]则提出了名为MRBench 的性能分析评价指标. 性能优化典型成果包括: 几何规划[ 23]、动态优先级管理[ 24]和硬件加速器[ 25]等. 着眼于性能, 结合运行时支持库, 将是MapReduce研究的热点之一.(5)在安全性和节能方面: 安全性方面典型研究成果是Sec ureMR模型[ 2 6]. 文献[ 27]和文献[ 28] 则在节能方面做了相应的研究. 目前国内外在安全性和节能方面的研究成果相对较少, 但是这方面研究的重要性已经得到了越来越多的重视. 如果一个模型没有很高的安全性, 同时也没有很好地考虑功耗问题, 那对其大范围推广将产生致命的影响.(6)在实际应用方面: MapReduce 应用范围广泛,Google 等诸多公司都在使用MapReduce 来加速或者简化各自公司的业务[ 29]. MapReduce 还广泛应用于云计算[ 3 0]和图像处理[ 31]等领域. 随着科技的进步, MapRe -duc e 将会得到越来越广泛的应用.国内学者MapReduce 相关研究成果主要集中在实际应用方面. 例如, 把MapReduce 应用于模式发现[ 32]和数据挖掘[ 3 3]等领域. 部分研究成果涉及模型针对不同平台的实现、任务调度、容错和性能评估优化. 例如, 文献[ 34]提出了名为FPMR 的基于FPGA 平台的MapRe -duc e 实现, 文献[ 35]提出了基于已知数据分布的任务调度策略, 文献[ 36]提出了名为SAMR的异构环境下自适应任务调度策略, 文献[ 37]提出了基于目录的双阶段错误恢复机制, 文献[ 38]提出了名为The HiBench Bench -mark Sui te 的性能评估指标, 文献[ 39]提出利用分布式的研究起步稍晚, 绝大部分研究集中在应用方面. 对MapReduce 关键技术也进行了研究. 但是相对于国外,国内在这些方面的研究成果较少.3 MapReduce模型及其改进Google 公司最早提出了MapReduce 并行编程模型,当用户程序调用MapReduce运行时支持库时, 其执行过程如下(如图1 所示) :( 1)首先, 用户程序把输入数据分割成M 份, 每份为16MB到64MB大小的数据块(可通过参数来设定) .然后, 开始在集群上进行程序的拷贝. 这些程序拷贝中有一份是Master,其余都是向Maste r 请求任务的Worker;( 2)一旦分配到Map任务,Worke r 便从相应的输入数据中分析出ke y/ value 对, 并把每个key/ value 对作为用户定义的Map函数的输入. Map函数产生的中间值key/ value 对被存储在内存中;( 3)存储在内存里的中间值key/ value 对会被定期写入本地磁盘中, 用户定义的Parti tion函数将其划分为多个部分,Master 负责把这些中间值key/ value对在本地磁盘上的存储位置传送给执行Reduce 任务的Worker;( 4)通过远程过程调用, 执行Reduce 任务的Worker从执行Map任务的Worker 的本地磁盘读取中间值ke y/value对;( 5)当一个执行Reduce 任务的Worker 从远程读取到所有所需的中间值key/ value 对之后, 通过排序将具有相同key的中间值key/ value对聚合在一起, 形成ke y/value s 对, 作为Reduce 函数的输入;( 6)每个Reduc e 函数的输出分别放到相应的输出文件中. 当所有的Map和Reduce 任务都执行完毕,Mas -ter 唤醒用户程序. 此时, 用户程序中的MapReduce 调用返回用户代码. MapReduce 可以处理TB和PB量级的数据, 能很方便地在许多机器上实现数据密集型计算的并行化. 算法1 给出基于MapReduce 的单词统计程序伪代码, 程序功能是统计文本中所有单词出现的次数.Map函数产生每个词和这个词的出现次数(在本例中就是1) . Reduce函数把产生的每一个特定词的计数加在一起.上述要求MapReduce 缺乏支持处理多个相关异构数据集的能力. 为此, 文献[ 7] 提出了MapReduceMerge 并行编程模型, 对多个异构数据集分别执行Map和Reduce 操作,之后在Merge 阶段把Reduce 阶段已分割和分类融合的数据进行有效地合并.MapReduceMerge尽管能够处理多个相关异构数据集, 但是并不支持自动执行多次MapReduceMerge 过程.当用户手动执行多次MapReduce 或者MapReduceMe rge过程时, 用户需要解决任务调度、同步性和容错等问题, 编程负担过重. 为此, 文献[ 8] 提出了Oivos 并行编程模型, Oivos 利用抽象层来实现自动管理执行多次MapReduce 或者MapReduceMe rge过程. Oivos需要用户指定处理多个相关异构数据集所需MapReduce 或者MapReduceMe rge过程的个数, 并通过检测逻辑时间戳来自动发现哪些任务需要重新执行.MapReduce 并行编程模型死板, 且不能很好地适应小规模集群. 为此, 基于消息传递和无共享模型, 文献[ 9]提出了名为KPNs ( Kahn process ne tworks)的并行编程模型. KPNs可自动执行迭代计算, 且编程灵活(例如:KPNs的输入不必抽象成key/ value 对的形式) . 同时, 把串行算法改写成KPNs 形式仅需在恰当的地方插入通信状态. 但是该模型仍需大量的实验来验证其性能与可扩展性.表1显示了MapReduce 并行编程模型及其改进研究对比. 通过比较不难看出, 以Google公司提出的MapReduce为基础, 针对其不足, 很多研究学者进行了相关研究, 并取得了一定的研究成果. 但是仍存在着一些不足: 首先, 这些模型均仅针对MapReduce 某个方面的不足, 研究较为片面, 并且都没有得到广泛的应用.其次, 部分模型并不成熟, 仍需要进一步的实验来验证其性能与可扩展性.最后, 没有研究结合不同模型的特点, 得出一个全面优化的并行编程模型3. 2 针对不同平台实现方面的研究受到Google 公司提出的MapReduce 并行编程模型启发, 目前被广泛使用的代表是Hadoop. 它是一个开源的可运行于大型分布式集群上的并行编程框架, 提供了一个支持MapReduce 并行编程模型的部件.Hadoop具有良好的存储和计算可扩展性; 具有分布式处理的可靠性和高效性; 具有良好的经济性(运行在普通PC 机上) .Hadoop也存在一些不足: 小块数据处理由于系统开销等原因处理速度并不一定比串行程序快; 如果计算产生的中间结果文件非常巨大, Reduce 过程需要通过远程过程调用来获取这些中间结果文件, 会加大网络传输的开销; Hadoop 作为一个比较新的项目,性能和稳定性的提升还需一定时间.随着科技的进步与硬件平台的发展, 许多研究学者在不同的实验平台上实现了MapReduce, 并取得了一定的研究成果. 其主要的研究成果包括:(1)在共享内存平台上: 斯坦福大学计算机系统实验室在共享内存系统上实现了MapReduce, 被称为Phoenix. Phoenix 采用线程来实现Map和Reduce任务, 同时利用共享内存缓冲区实现通信, 从而避免了因数据拷贝产生的开销. 但Phoenix 也存在不能自动执行迭代计算、没有高效的错误发现机制等不足.(2)在GPUs 平台上: Mars 是基于GPUs( 图形处理器)的MapReduce 实现.Ma rs也具有Map与Reduce 这两个步骤. 在每个步骤开始之前, Mars对线程配置进行初始化(包括:线程组的个数、每个线程组中线程的个数等) . 由于GPU线程不支持运行时动态调度, 所以给每个GPU 线程分配的任务是固定的. 若输入数据划分不均匀, 必将导致Map或者Reduce 阶段的负载不均衡, 使得整个系统性能急剧降低. 同时由于GPU 不支持运行时在设备内存中分配空间, 需要预先在设备内存中分配好输入数据和输出数据的存放空间. 但是在Map 和Reduce阶段输出数据大小是未知的, 并且当多个GPU线程同时向共享输出区域中写数据时, 易造成写冲突.另外, 由于Mars的编程接口是为图形处理而专门设计的, 因此用户编程较为复杂.(3) 在Cell / B. E. 平台上: Cell MapReduce 是基于Cell / B. E. (Cell宽带引擎)的MapReduce 实现. 将MapRe -duc e 移植到Cell / B. E. 架构主要存在三个问题: 必须实现全局内存与SP E 内存之间的内存管理和交换; 由于主要负责Map和Reduce 任务执行的SPE 内存是由软件管理的, 因此需要通过内存交换来解决计算重叠问题; 在Map和Reduce 阶段之间存在一个逻辑聚合阶段, 该阶段需要在各SPE 之间高效执行. 为此, CellMapReduce提出: 通过块DMA 传输来预先分配Map和Reduce 任务的输出区域, 以达到解决内存管理的目的; 提出通过双缓冲区和流数据的内存交换来实现计算并行化; 提出通过双阶段Parti tion 和Sort处理来实现逻辑聚合. 综上, 该模型为用户提供了一个简单的机器抽象, 隐藏了并行实现与硬件的细节. 而且还提供了一套API和运行时系统来自动管理同步性、调度、分块和内存交换等工作. 然而, 虽然Cell/B. E. 处理单元之间有很高的带宽, 但是Cel l/ B. E. 没有为协同处理单元提供一致性的存储器, 同时程序员必须仔细管理进出于各个SPE的数据移动, 编程难度太大.( 4)在FPGA 平台上: 近年来, FPGA(现场可编程门阵列)开始应用于高性能计算应用中[ 40]. 相对于其它并行计算平台, FPGA 具有可重构性、高灵活性和严格遵守摩尔定律的优势. 但是, 基于FPGA 的计算亦受到硬件结构的设计开发和寄存器级数据传输的限制, 导致编程效率较低. 为此, 文献[ 34]提出了名为FPMR的基于FPGA的MapReduce实现. 首先, 利用FPGA的可重构性, 在片上实现多个Map与Reduce任务, 以实现较好的性能. 其次, 通过片上动态调度策略来实现较好的资源利用率和负载均衡, 以达到把编程人员从具体任务控制和通信操作中解放出来的目的. 最后, 通过高效的数据获取策略来实现最大化数据的重利用和解决带宽瓶颈. 但是FPMR 不支持利用页式硬件进行动态内存管理, 同时也需要更多的实验来验证FPMR的效率和生产力.( 5)在分布式移动平台上: 功能强大的移动设备的不断普及, 便于提供一个功能强大的分布式移动计算环境. 但是, 在这样的环境中, 软件开发和应用部署都面临着易出错、同步性困难、资源分配复杂、缺少编程模型支持等问题. 同时, 若把MapReduce 应用于移动网络将具有很差的计算连通性. 为此, 文献[ 15] 提出了名为Misco 的基于分布式移动平台的MapReduce 实现.Misc o 由一个Ma ste r Server 和一系列Worker Nodes 组成.其中,Master 和Worker 之间采用基于轮询[ 41]的通信机制, 使用HTTP的方式来传输数据.Master Server 时刻跟踪用户应用, 负责其任务调度与分配, 保存与应用相关的输入数据、中间值和最终结果. Worke r Nodes 则负责执行Map与Reduce 任务. 但是由于轮询的时间间隔不好确定, 若时间间隔设置不当, 会显著降低程序的执行性能.(6) 在公共资源网格平台上: 文献[ 16] 提出名为Ussop 的基于公共资源网格环境的MapReduce 实现. 针对网格资源的异变性和广域网中进行数据交换开销大的特点,Ussop 提出了两个任务调度算法, 一个能根据网格节点的计算能力, 自适应Map 输入的粒度. 另一个能最小化在广域网传输中间数据的开销. 但是Ussop 缺乏高效的容错机制, 当一个节点因处于过载状态而无法给Map任务分配资源时, 只能在其它节点重新执行该任务, 无法做到资源的重新分配或者任务迁移.表2显示了MapReduce 针对不同平台的实现研究对比. 由表2可知, 除了Hadoop 之外, 其它的实现都没有得到广泛的应用. 同时一些实现(例如: Mars 和Cel lMapReduce)由于底层硬件比较复杂或者底层硬件架构的限制, 造成用户编程难度较大, 增加了用户负担, 不利于其大范围推广.4 运行时支持库及其改进 MapReduce 运行时支持库是MapReduce 实现的基础,它能有效进行任务调度、负载均衡、容错和一致性管理等, 能够隐藏底层细节, 降低用户编程的难度.4 1 任务调度及负载均衡方面的研究MapReduce并行编程模型采用基于数据存储位置的任务窃取调度策略. 如果某个Worke r 的本地任务列表非空, 则首先执行该列表的第一个任务; 如果某个Worker 的本地任务列表为空, 则从与之最近的Worker窃取任务来执行. 这样能够减少通信开销, 提高系统性能. 但是,该策略也存在如下几点不足:(1)如果数据分布不均匀, 会有更多的Map 任务不能在本地执行. 此时, 该策略反而会增大通信开销, 导致性能下降. 为此, 文献[ 35]提出了基于已知数据分布的MapReduce 任务调度策略. 该调度策略基于节点和任务的优先级, 充分考虑系统中数据的分布, 将任务调度给合适的节点. 这样就能实现以较高的概率将Map 任务分配给本地有数据的节点, 从而减少通信开销, 提高系统性能.(2)MapReduce 任务调度策略存在调度的公平性和数据存储位置(即为具有输入数据的节点分配任务)之间的冲突. 即依照严格的任务队列顺序, 一个没有本地数据的任务会被强制调度, 这会增加通信开销. 为此,文献[ 17]提出了延迟调度算法. 当节点请求任务时, 如果任务列表中的第一个任务不能在本地启动, 则系统自动跳过该任务, 查询下一个任务, 直至找到一个能在本地启动的任务. 当然, 如果一个节点请求任务时跳过的任务过多, 系统将允许其启动数据不在本地的任务.( 3)有时候, 多个MapReduce 任务需要共享相同的物理资源. 这就有必要预测和管理每个任务的性能, 据此为每个任务分配合适的资源. 为此, 文献[ 19]提出了基于性能驱动的任务调度策略. 该策略能动态预测当前MapReduce任务的性能, 并且能够为该任务调整资源分配, 使之既能达到应用的性能目标, 又不会占用过多的资源.( 4) MapReduce 为节约响应时间采用预测执行机制, 即若一个节点可获得但是性能很差, 那么MapRe -duce 会把运行在该节点上任务作为备份任务在其它节点上运行. 但是这种机制在异构环境中会导致程序性能的降低, 为此, 文献[ 18]提出了名为LATE( Longest Ap -proxima te Time to End)的任务调度策略. LATE 通过计算所有任务的剩余时间来找到执行最慢的任务作为备份任务, 这样就能有效缩短MapReduce在异构环境中的响应时间. 但是LATE 并不能正确计算任务的剩余时间,因而不能找到真正执行最慢的任务, 同时也不能适应异构环境的动态变化. 为此, 文献[ 36] 提出了名为SAMR( Sel - f Adaptive MapReduce) 的任务调度策略, 通过记录在每个节点上的任务执行历史信息, SAMR能动态找到真正执行最慢的任务作为备份任务. 但是SAMR在执行备份任务时, 并没有考虑数据的存储位置, 同时SAMR仍需在不同的平台下进行评估测试综上, 针对MapReduce 并行编程模型采用的任务调度策略的特点, 很多学者进行了相关研究, 并取得了一定的研究成果. 但是这些研究成果没有充分考虑数据存储位置及其动态变化, 不能根据数据划分的粒度, 自动选择合适的任务调度策略.4 2 容错方面的研究MapReduce并行编程模型被设计用于使用数目众多的机器处理海量数据, 因此MapReduce 运行时支持库必须能够很好地处理发生的机器故障.在MapReduce 并行编程模型中,Worke r 节点采用基于响应的错误恢复机制.Master节点周期性地ping 每个Worker 节点. 如果在一个时间段内Worke r 节点没有返回信息,Master 节点就会标注该Worke r 节点失效. 由该失效Worker 完成的所有任务将被重新设置成初始空闲状态, 并被分配给其它Worke r 执行.Master节点采用基于检查点的错误恢复机制. Mas -ter节点周期性地写入检查点. 如果Master 任务失效了,则可从最后一个检查点来启动另一个Master 进程检查点和日志[ 4 2]是两种被广泛使用的错误回滚恢复机制. 在MapReduce 并行编程模型中, Worker 节点采用基于响应的错误恢复机制, Master 节点采用基于检查点的错误恢复机制.但是, 基于响应的错误恢复机制不能实现低开销和高效性, 基于检查点的错误恢复机制在创建检查点时开销较大. 同时基于日志的错误恢复机制虽然较简单(错误恢复时所需的所有信息都在日志中) , 但是在跨网络传输较大的日志文件时, 会造成较大的网络带宽浪费, 并可能延迟应用数据的传输. 为此,文献[ 37]提出基于日志的双阶段错误恢复机制, 把日志分为basic和e xtra 两部分, 同时把恢复机制分成两阶段, 以减少状态信息的传输, 该机制在节省网络带宽的同时能够优化全局性能.在MapReduce并行编程模型中, 如果Worke r 节点发生错误, 需要重启该节点上运行的所有Map 或Reduce任务, 不能实现低开销和高效性. 为此, 文献[ 20]提出了基于选择性的API 来实现数据密集型应用的并行化. 该API提供了一个由用户声明的reduce 对象, 该对象是任何节点的计算状态集合. 当某个节点出错时, 该节点未处理的数据可被其它节点处理. 从出错节点上拷贝过来的reduce 对象与其它节点上的reduce 对象一起来产生最终的正确结果. 这样就能实现低开销和高效的容错机制.综上, 针对MapReduce 并行编程模型, Google 公司提出的容错策略不够完善, Master 节点容错开销过大,Worker 节点容错很容易产生重复计算, 造成计算资源的浪费. 对此许多研究学者进行了相关研究, 并取得了一定的研究成果. 但这些研究主要是针对Worke r 节点的容错, 针对Master节点容错的研究较少.5 总结及未来的发展趋势目前, 国内外众多研究人员已对MapReduce 并行编程模型所涉及的关键技术( 包括: 模型改进、模型针对不同平台的实现、任务调度、负载均衡和容错) 进行了卓有成效的研究. 预计在今后的一段时期内, 与MapRe -duce 并行编程模型相关的研究可能会朝着以下几方面进行:( 1)逐步形成完善的MapReduce 并行编程模型规范. 它统一定义MapReduce并行编程模型的各个组成部分(例如:Map、Parti tion、Sort、Reduc e 和Me rge等) , 将现存的多种定义一致起来, 形成能够长期有效的统一定义规范. 它支持并行计算和分布式应用, 具有良好的自适应能力与性能预测能力, 能够满足较高的性能要求.( 2)由于MapReduce并行编程模型主要用于大规模数据集(TB甚至PB级)的并行处理. 因此, 性能问题将成为研究的重点之一.可着眼于性能, 研究MapRe duc e 并行编程模型, 在Ma pReduce 并行编程模型的实现中采取多种提高性能的手段(例如: 减少数据拷贝, 改进节点间数据传输方法, 改进运行时支持库的任务调度机制, 改进内存管理, 采用高效的同步机制和性能预测等) .(3) 随着云计算的兴起与进一步发展, MapReduce并行编程模型的大规模底层基础设施建设(例如: Ama -zon 的EC2与S3[ 43]等) 将成为研究的热点, 这也是基于MapReduce 并行编程模型的各种应用(例如: 云计算等)的实现根本.( 4)针对不同的实验平台实现MapReduce并行编程模型. 已有学者将MapReduce并行编程模型从最初的普通多核分布式系统, 移植到共享内存和Cell / B. E. 架构等环境中. 将来MapReduce并行编程模型会被移植到更多的实验平台上(例如: 物联网[ 44- 45]等) . 同时已有平台上的实现会进一步优化.( 5)MapReduce并行编程模型的应用领域将进一步扩大. 目前MapReduce 已被各大互联网公司所采用, 并且在云计算和图像处理等领域得到了广泛的应用. 相信将来更多的公司会采用MapReduce并行编程模型, 同时针对不同的应用领域, 开发出更多的专用模型.综上所述,MapReduce 并行编程模型的研究是一个充满前途和挑战的领域, 它改变着大规模数据集的并行计算方式, 必将在并行计算领域发挥越来越重要的作用。

mapreduce并行编程原理MapReduce并行编程是一种用于大规模数据处理的编程模型。
它的核心思想是将数据分成若干块,然后并行处理每一块数据,最后将结果合并起来。
MapReduce模型具有以下两个阶段:1. Map阶段:在这个阶段,输入数据被映射为一系列的键值对。
每个键值对由一个映射函数处理,这个函数可以是用户定义的。
映射函数接收输入数据作为参数,并根据需求将其转化为键值对。
映射函数执行的结果会生成一个中间键值对列表。
2. Reduce阶段:在这个阶段,中间键值对列表被合并为输出结果。
用户定义的归约函数(reduce函数)接收相同键的键值对列表,并输出归约结果。
MapReduce编程模型的核心特点是可扩展性和容错性。
它可以在一个集群中运行,将数据分布在多个节点上进行处理,并在需要时进行数据重新分配以实现负载均衡。
此外,当某个节点失败时,MapReduce能够自动将任务重新分配给其他可用的节点,从而保证任务的完成性。
MapReduce编程模型可以应用于各种各样的数据处理任务,包括文本分析、数据挖掘、网页排名等。
下面是MapReduce编程模型的一些关键原理:1.数据切片:MapReduce将输入数据分成若干块,并将每个块分配给不同的节点进行处理。
这样可以实现数据的并行处理,提高处理效率。
2.映射函数:映射函数将输入数据转换为一系列的键值对。
用户可以根据任务的需求自定义映射函数。
3.归约函数:归约函数将相同键的键值对列表合并为一个结果。
归约函数也是用户自定义的,它可以根据任务的需求来实现不同的合并逻辑。
4.分布式存储:MapReduce使用分布式文件系统来存储数据。
这样可以将数据分布在多个节点上,实现数据的可靠性和高效访问。
5.任务调度和分配:MapReduce使用主节点来进行任务的调度和分配。
主节点负责将输入数据分配给不同的节点,并协调它们的执行。
6.容错处理:MapReduce能够在节点失败时进行容错处理。

基于MapReduce的改进K-Medoids并行算法李静滨;杨柳;陈宁江【摘要】K-Medoids算法具有不同层次的并行性,计算粒度不同对并行算法效率有较大影响。
基于K-Me doids的并行计算特点,提出了一个改进的K-Medoids 并行算法,该算法基于MapReduce模型,通过适当增加计算粒度,降低了通信消耗占比。
实验结果表明,改进的并行算法与其他已有算法相比,加速比与运行效率有显著提高。
%K-Me doids algorithm has different levels of parallelism, and the computing grain has im-portant impact on the efficiency of the parallel algorithm. With the consideration of the parallelism features, an improved parallel K-Medoids algorithm is presented. Based on the MapReduce model, the improved algorithm has bigger computing grain and reduces the percentage of communication cost. The experimental results show that the new algorithm obtains better speedup and efficiency comparing with other algorithms.【期刊名称】《广西大学学报(自然科学版)》【年(卷),期】2014(000)002【总页数】5页(P341-345)【关键词】K-Medoids算法;并行算法;计算粒度;MapReduce【作者】李静滨;杨柳;陈宁江【作者单位】广西大学计算机与电子信息学院,广西南宁 530004;广西大学计算机与电子信息学院,广西南宁 530004;广西大学计算机与电子信息学院,广西南宁 530004【正文语种】中文【中图分类】TP393K-Medoids是一类基于划分的聚类算法,PAM是被最早提出的K-Medoids算法[1-2]。

摘要车辆路径问题广泛应用于各个领域,不论是机器人自主无碰运动、服务网络规划等学术研究领域,还是数字地图导航、仓库AGV无导引小车运作等工业生产环境,甚至是与人们生活息息相关的快递配送业,都要用到车辆路径问题的优化理论。
车辆路径问题的研究,不仅具有重要的学术研究意义,而且有重要的生产实用价值。
带有时间窗的车辆路径问题在车辆路径问题的基础上考虑了时间成本的影响,更加符合实际需求。
针对带有时间窗的车辆路径问题的研究已经比较成熟,包括精确算法、启发式算法、元启发式算法等,但这些算法基本都是串行的集中式算法,大都只能求解中小规模的车辆路径问题,然而现在的车辆路径问题动辄就是上千个节点的规模,加上时间窗的约束,传统串行算法求解效率比较低,短时间内很难求解出可接受解。
当今大数据、云计算等计算机技术的蓬勃发展,为并行计算提供了技术支持,也为并行化解决大规模带有时间窗的车辆路径问题提供了新的思路。
针对集群式并行计算具有高容错性、高扩展性、高可用性和廉价性等方面的优势,本研究选用了经典的集群分布式并行计算平台----Hadoop作为并行计算的基础架构,基于此使用MapReduce并行框架进行分布式并行算法的设计与优化,用以解决大规模带有时间窗的车辆路径问题。
本研究在基础算法的设计上,选取了具有天然并行特性的遗传算法。
为了最大限度地降低遗传算法的巨大计算开销,本文选择并改进了比较优秀的选择、交叉、变异算子。
在MapReduce框架中,map和reduce阶段的设计上,充分考虑了大规模车辆路径问题的遗传基因的长度带来的影响,同时考虑了如何降低集群间信息传输的压力,最终采用粗粒度并行模型----遗传算法岛屿模型嵌入MapReduce框架。
在键值对的处理上,利用键值对中“键”的不变性保持遗传算法解个体和适应度值的一致性,并将迁徙操作与shuffle阶段结合起来,保证迁徙过程顺利执行。
本文使用带有时间窗的车辆路径问题的大规模标准算例----Gehring & Homberger (1999)算例进行了算法验证,分别从并行算法的有效性、串行和并行算法的对比、集群处理器数量对算法的影响和处理器配置对算法的影响等四个方面进行了数值实验与精确的分析,并论述了本文研究的有效性和重要价值。
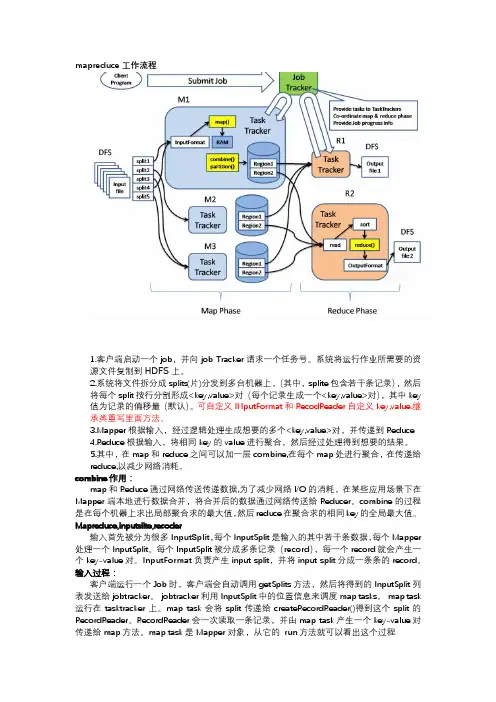
mapreduce工作流程1.客户端启动一个job,并向job Tracker请求一个任务号。
系统将运行作业所需要的资源文件复制到HDFS上。
2.系统将文件拆分成splits(片)分发到多台机器上,(其中,splite包含若干条记录),然后将每个split按行分割形成<key,value>对(每个记录生成一个<key,value>对),其中key值为记录的偏移量(默认)。
可自定义INputFormat和RecodReader自定义key,value.继承类重写里面方法。
3.Mapper根据输入,经过逻辑处理生成想要的多个<key,value>对,并传递到Reduce4.Reduce根据输入,将相同key的value进行聚合,然后经过处理得到想要的结果。
5.其中,在map和reduce之间可以加一层combine,在每个map处进行聚合,在传递给reduce,以减少网络消耗。
combine作用:map和Reduce通过网络传送传递数据,为了减少网络I/O的消耗,在某些应用场景下在Mapper端本地进行数据合并,将合并后的数据通过网络传送给Reducer。
combine的过程是在每个机器上求出局部聚合求的最大值,然后reduce在聚合求的相同key的全局最大值。
Mapreduce,inputslite,recoder输入首先被分为很多InputSplit,每个InputSplit是输入的其中若干条数据,每个Mapper 处理一个InputSplit。
每个InputSplit被分成多条记录(record),每一个record就会产生一个key-value对。
InputFormat负责产生input split,并将input split分成一条条的record。
输入过程:客户端运行一个Job时,客户端会自动调用getSplits方法,然后将得到的InputSplit 列表发送给jobtracker。

遗传算法(基于遗传算法求函数最大值)指导老师:刘建丽学号:S201007156姓名:杨平班级:研10级1班遗传算法一、 遗传算法的基本描述遗传算法(Genetic Algorithm ,GA )是通过模拟自然界生物进化过程来求解优化问题的一类自组织、自适应的人工智能技术。
它主要基于达尔文的自然进化论和孟德尔的遗传变异理论。
多数遗传算法的应用是处理一个由许多个体组成的群体,其中每个个体表示问题的一个潜在解。
对个体存在一个评估函数来评判其对环境的适应度。
为反映适者生存的思想,算法中设计一个选择机制,使得:适应度好的个体有更多的机会生存。
在种群的进化过程中,主要存在两种类型的遗传算子:杂交和变异。
这些算子作用于个体对应的染色体,产生新的染色体,从而构成下一代种群中的个体。
该过程不断进行,直到找到满足精度要求的解,或者达到设定的进化代数。
显然,这样的思想适合于现实世界中的一大类问题,因而具有广泛的应用价值。
遗传算法的每一次进化过程中的,各个体之间的操作大多可以并列进行,因此,一个非常自然的想法就是将遗传算法并行化,以提高计算速度。
本报告中试图得到一个并行遗传算法的框架,并考察并行化之后的一些特性。
为简单起见(本来应该考虑更复杂的问题,如TSP 。
因时间有些紧张,做如TSP 等复杂问题怕时间不够,做不出来,请老师原谅),考虑的具有问题是:对给定的正整数n 、n 元函数f ,以及定义域D ,求函数f 在D 内的最大值。
二、 串行遗传算法1. 染色体与适应度函数对函数优化问题,一个潜在的解就是定义域D 中的一个点011(,,...,)n x x x -,因此,我们只需用一个长度为n 的实数数组来表示一个个体的染色体。
由于问题中要求求函数f 的最大值,我们可以以个体所代表点011(,,...,)n x x x -在f 函数下的值来判断该个体的好坏。
因此,我们直接用函数f 作为个体的适应度函数。
2. 选择机制选择是遗传算法中最主要的机制,也是影响遗传算法性能最主要的因素。
遗传算法的并行实现遗传算法(Genetic Algorithm,GA)是一种模拟自然进化过程的优化算法。
它模拟了生物进化的基本原理,通过迭代的方式不断优化空间中的解,以找到最优解或者接近最优解。
在遗传算法的实现中,可以采用并行计算的方式来提高算法的效率和性能。
并行计算将任务拆分成多个子任务,同时进行处理,并通过协同工作来加速计算过程。
并行实现遗传算法的主要思路有以下几种方式:1. 池式并行(Pool-Based Parallelism):多个遗传算法进程同时运行,并且每个进程都具有自己的种群和繁殖操作。
这些进程可以根据需要交换信息,例如交换最佳个体,以进一步加速过程。
2. 岛模型并行(Island Model Parallelism):将种群划分为多个子种群,每个子种群在独立的进程中进行演化。
定期地选择一些个体进行迁移,使得不同子种群的个体可以交流基因信息。
这种方式类似于地理上的岛屿,每个岛屿代表一个子种群,岛屿之间的迁移模拟了个体在不同岛屿之间的迁徙。
3. 数据并行(Data Parallelism):将种群的每个个体划分成多个部分,每个部分在不同的处理器上进行计算。
这种方法将空间分割成多个子空间,以加速算法的收敛过程。
4. 任务并行(Task Parallelism):将遗传算法的各个操作(例如选择、交叉、变异等)分解为多个任务,并行执行这些任务。
每个任务可以在不同的处理器上同时进行,从而加速算法的执行。
并行实现遗传算法的优势在于它可以通过利用多个处理单元,同时处理并行化的任务,使得算法的过程更加高效。
并行计算可以加速算法的收敛速度,减少空间中的局部最优解,并提供更好的全局能力。
然而,并行实现也会带来一些挑战和注意事项。
例如,如何划分任务以达到最佳的负载均衡,如何设计通信、同步和数据共享机制等等,都需要仔细考虑和解决。
总之,遗传算法的并行实现是一个非常广泛且复杂的课题,需要综合考虑问题的特性、硬件的条件和算法设计的需求。
人工智能基础(试卷编号1191)1.[单选题]以下不是贝叶斯回归的优点的是哪一项A)它能根据已有的数据进行改变B)它能在估计过程中引入正则项C)贝叶斯回归的推断速度快答案:C解析:2.[单选题]人工神经网络是一种模仿生物神经网络行为特征,进行信息处理的数学模型。
A、正确A)错误B)正确C)错误答案:A解析:3.[单选题]RNN作为图灵机使用时,需要一个( )序列作为输入,输出必须离散化以提供( )输出。
A)二进制B)八进制C)十进制D)十六进制答案:A解析:4.[单选题]Spark比MapReduce快的原因不包括()。
A)Spark基于内存迭代,而MapReduce基于磁盘迭代B)DAG计算模型相比MapReduce更有效率C)Spark是粗粒度的资源调度,而MapReduce是细粒度的资源调度D)Spark支持交互式处理,MapReduce善于处理流计算答案:D解析:A、B、C是Spark比MapReduce快的原因。
MapReduce不善于处理除批处理计 算模式之外的其他计算模式,如流计算、交互式计算和图计算等。
5.[单选题]L1正则和L2正则的共同点是什么?A)都会让数据集中的特征数量减少B)都会增大模型的偏差C)都会增大模型方差D)没有正确选项答案:D解析:6.[单选题]无轨导航规划的主要研究内容不包括( )。
A)路径规划B)轨迹规划C)自主定位D)避障规划答案:C解析:7.[单选题]声码器是由编码器和( )组成。
A)解码器B)特征提取器C)预处理器D)滤波器答案:A解析:8.[单选题]pandas从CSV文件导入数据的方法是A)pd.read_csv()B)pd.read_table()C)pd.read_excel()D)pd.read_sql()答案:A解析:9.[单选题]平滑图像处理可以釆用RGB彩色()模型。
A)直方图均衡化B)直方图均衡化C)加权均值滤波D)中值滤波答案:C解析:平滑图像处理可以采用RGB彩色加权均值滤波模型。
基于用户的协同过滤推荐算法MapReduce 并行化实现作者:李冲来源:《软件导刊》2018年第10期摘要:基于用户的协同过滤推荐算法是应用范围广且应用效果较好的推荐算法之一。
传统单机模式下运行的基于用户的协同过滤推荐算法在面对海量数据时存在严重的性能瓶颈问题,很难满足实际计算需求,而基于MapReduce的并行计算框架为解决该问题提供了新思路。
MapReduce是Hadoop开源框架的核心计算编程模型, MapReduce的设计目标是方便编程人员在不熟悉分布式并行编程的情况下,可将自己的程序运行在分布式系统上。
根据基于用户的协同过滤推荐算法特点,提出MapReduce并行化实现方法。
实验结果表明,在MapReduce并行计算框架下实现的基于用户的协同过滤推荐算法在算法性能及稳定性方面都取得了理想效果。
关键词:MapReduce;Hadoop;分布式计算;推荐算法DOIDOI:10.11907/rjdk.181108中图分类号:TP312文献标识码:A 文章编号:1672-7800(2018)010-0076-05英文摘要Abstract:The recommended algorithm based on collaborative filtering of users is a recommended algorithm which has a wide range of applications and is effective in practical applications. However, the traditional recommendation algorithm based on user-based collaborative filtering running in stand-alone mode encounters a serious performance bottleneck in the case of massive data and is difficult to meet the actual computing requirements. The MapReduce-based parallel computing framework provides a new solution to this problem. MapReduce is a kernel computing programming model of Hadoop open source framework. MapReduce is designed to facilitate programmers to run their own programs on distributed systems without being familiar with distributed parallel programming. Based on the research of the characteristics of user-based collaborative filtering recommendation algorithm, this paper proposes a method based on MapReduce parallel computing framework. The experimental results show that the proposed user-based collaborative filtering algorithm based on MapReduce parallel computing framework achieves the desired performance in terms of performance and stability of the algorithm.英文关键词Key Words:MapReduce;Hadoop;distributed computing;recommendation algorithm0 引言如今人们生活在一个信息超载的时代,生活各领域充斥着大量信息资源,如何从海量信息资源中快速高效地获取有用信息一直是研究人员的研究热点[1]。
大数据挖掘中的MapReduce并行聚类优化算法研究吕国;肖瑞雪;白振荣;孟凡兴【摘要】针对传统数据挖掘算法只适用于小规模数据挖掘处理,由于数据规模不断增大,其存在计算效率低、内存不足等问题,文中将MapReduce用于数据挖掘领域,对大数据挖掘中的MapReduce进行了并行化改进,并设计相应的并行化实现模型,以期满足大数据分析需求,完成低成本、高性能的数据并行挖掘与处理.【期刊名称】《现代电子技术》【年(卷),期】2019(042)011【总页数】4页(P161-164)【关键词】大数据;MapReduce;并行化处理;聚类算法;数据挖掘;Map任务【作者】吕国;肖瑞雪;白振荣;孟凡兴【作者单位】河北建筑工程学院现代教育技术中心,河北张家口 075000;河北建筑工程学院现代教育技术中心,河北张家口 075000;河北建筑工程学院现代教育技术中心,河北张家口 075000;河北建筑工程学院现代教育技术中心,河北张家口075000【正文语种】中文【中图分类】TN911.1-34;TP311.140 引言随着大数据时代的来临,互联网的数据量正呈现出爆炸式的增长,采用传统数据分析法对其进行分析和研究,已经无法满足海量数据处理的需求。
基于此,数据挖掘技术随之产生。
数据挖掘就是从大量、随机、模糊、有噪声的数据内提取有价值的信息。
数据挖掘技术是指从大量数据中利用算法对隐藏信息进行搜索的过程,目前被广泛应用于金融、网络、决策及教育等行业中。
数据挖掘技术以统计学作为基础,增设模式识别、机器学习、数理统计、人工智能等多种技术,通过流数据及数据库完成工作[1]。
在数据技术不断发展的过程中,还融入了数据安全、数据结构算法、信息检索、信号处理、信息论等多种技术。
聚类分析则是一项比较实用的数据挖掘技术,因其能有效分析数据并发现其中的有用信息,被广泛用于文本搜索、人工智能、图像分析等领域[2]。
聚类分析把数据对象划分为多个簇,虽然同一个簇内的数据对象相似,但不同簇内的对象存在一定的差异。
MapReduce是一种分布式计算框架,可以用于大规模数据处理,它的实现机制主要包括以下几个方面。
1. 数据分片在MapReduce中,数据会被分成多个数据块,并且这些数据块会被复制到不同的节点上。
这样做的目的是为了提高数据的可靠性,同时也可以避免单节点故障导致的数据丢失。
2. Map阶段在Map阶段中,每个节点会同时执行Map函数,将输入的数据块转换为键值对的形式。
Map函数的输出结果会被分配到不同的Reducer节点上,这里需要注意的是,Map函数的输出结果必须是无状态的,即输出结果只能依赖于输入参数,而不能依赖于其他状态信息。
3. Shuffle阶段在Shuffle阶段中,Map函数的输出结果按照键的哈希值进行排序,并将相同键的值归并到一起。
这个过程需要消耗大量的网络带宽和磁盘I/O,因此Shuffle阶段是整个MapReduce计算中的瓶颈之一。
4. Reduce阶段在Reduce阶段中,每个Reducer节点会对Map函数输出结果中相同键的数据进行聚合操作。
Reduce函数的输入参数由Map函数输出结果中相同键的数据组成,而Reduce函数的输出结果是最终结果,MapReduce框架会将所有Reducer节点的输出结果合并为一个最终结果。
5. 容错机制在分布式计算中,可能会出现节点故障、网络异常等问题,这些问题会导致数据丢失或者计算结果错误。
因此,MapReduce框架需要具备一定的容错机制,比如在Shuffle阶段中,如果某个节点的输出结果没有及时到达目标节点,MapReduce框架会自动重新发送数据。
6. 优化策略为了提高MapReduce计算的性能和效率,MapReduce框架还可以采用多种优化策略,比如合并小文件、增加Map和Reduce的任务并行度、调整数据分片大小等。
总的来说,MapReduce框架通过数据分片、Map函数、Shuffle 阶段、Reduce函数等组件的协同工作,实现了大规模数据的分布式处理。