粗粒度并行遗传算法的 MapReduce 并行化实现
- 格式:pdf
- 大小:1.08 MB
- 文档页数:6


mapreduce并行编程原理-回复为什么需要并行编程?随着计算机系统的发展,数据量的爆炸性增长推动了对计算能力的巨大需求。
然而,传统的单线程编程模型已经无法满足这一需求,因为它们无法充分利用现代计算机系统中的多核处理器和分布式计算资源。
为了提高计算效率,人们开始使用并行编程来实现任务的并发执行。
并行编程是一种编程模式,它可以在多个处理单元或计算资源上同时执行不同的任务。
这种模式允许任务之间以并行方式协同工作,从而提高整体系统的处理能力。
并行编程的一个重要应用领域是数据处理,而MapReduce是一种常用的并行编程框架。
MapReduce是一种用于大规模数据处理的并行编程框架,它由Google 提出,并被广泛应用于分布式计算领域。
它提供了一种简单而有效的方式来处理大量的数据,无论是在单机还是分布式环境中。
MapReduce的核心原理是将任务分解为两个阶段:映射(Map)和归约(Reduce)。
在映射阶段中,系统将输入数据集分割为若干个小块,并对每个小块应用相同的映射函数。
映射函数将输入数据转换为键值对的形式,并输出中间结果。
在归约阶段中,系统将相同键的中间结果进行合并,并通过归约函数将它们转换为最终结果。
为了实现MapReduce,并行处理框架需要进行任务的分配和调度。
在分布式环境中,MapReduce框架可以自动将数据和任务分配到可用的计算资源上,从而实现任务的并行执行。
这种分布式任务调度可以大大提高数据处理的效率,充分利用了计算资源的并行性。
为了更好地理解MapReduce,并行编程的原理,我们可以通过一个例子来说明。
假设我们有一个包含1亿条日志记录的文件,我们希望统计每个IP地址出现的次数。
传统的单线程方法可能需要花费很长时间来处理这么大的数据集,而使用MapReduce并行编程框架可以有效地加快处理速度。
首先,我们需要将输入数据集分割为若干个小块,并将它们分发给不同的节点进行处理。
每个节点将接收到的数据块应用映射函数,将其中的IP 地址作为键,并将出现的次数作为值输出。

大数据分析领域中基于MapReduce技术的并行处理方法研究一、引言大数据是当今社会中的重要问题之一,随着大数据的快速增长,对数据的处理和分析变得越来越困难。
因此,为了解决这一问题,大数据分析技术变得越来越重要和热门。
MapReduce技术是解决大数据分析的一种有效方法,它可以将大数据分成许多小数据块,这些小数据块可以并行处理。
因此,在此篇文章中,我们将详细介绍基于MapReduce技术的并行处理方法。
二、MapReduce技术的基本概念MapReduce技术是一种用于处理大数据的并行计算模型,它采用了两个不同的阶段:Map阶段和Reduce阶段。
Map阶段:该阶段的目的是将输入数据分成小块,并将其分成键-值对。
然后,计算节点将对每个键-值对进行操作,并生成一个临时的键-值对列表。
Reduce阶段:该阶段的目的是将Map阶段产生的临时键-值对列表合并到一个更小的列表,并产生一个最终的输出结果。
三、MapReduce技术的主要优点1. MapReduce技术可以在大规模数据处理中实现高度的扩展性和性能。
2. MapReduce技术采用分布式计算模型,允许在集群中的多个计算节点上并行处理数据。
3. MapReduce技术可以通过多次迭代和优化提高系统的效率和可靠性。
4. MapReduce技术可以在不消耗大量系统资源的情况下解决大规模数据处理和分析的问题。
四、基于MapReduce技术的并行计算模型基于MapReduce技术的并行计算模型包括以下几个步骤:1.数据划分:在MapReduce模型中,数据被分成多个数据块,每个数据块被分配给一个计算节点,以便并行处理。
2.映射函数:映射函数负责将输入的数据块转换成键-值对,生成一个键-值对的列表。
3.排序函数:排序函数将Map阶段产生的键-值对按照键进行排序,以便在Reduce阶段进行进一步的处理。
4.合并函数:合并函数负责将具有相同键的键-值对合并并生成减小的键-值对列表。

阐述mapreduce并行计算模式MapReduce是一种并行计算模式,它被广泛应用于大规模数据处理和分析。
本文将阐述MapReduce的工作原理和并行计算模式,并探讨其在实际应用中的优缺点。
一、MapReduce的工作原理1.1 Map阶段Map阶段是MapReduce任务的第一阶段,其主要作用是将输入数据集中的每个数据项映射为一组键值对。
在这个阶段中,MapReduce 将输入数据集分成M个小的数据片段,并将这些数据片段交给多个Map任务并行处理。
每个Map任务会对其分配的数据片段进行处理,将其转化为一组键值对,并将这些键值对暂时存储在内存中。
1.2 Shuffle阶段Shuffle阶段是MapReduce任务的第二阶段,其主要作用是将Map 阶段产生的键值对按照键的值进行排序,并将相同键值的键值对分配到同一个Reduce任务中进行处理。
在这个阶段中,MapReduce会将所有Map任务产生的键值对进行合并,并按照键的值进行排序。
排序后的键值对会被分配到相应的Reduce任务中进行处理。
1.3 Reduce阶段Reduce阶段是MapReduce任务的第三阶段,其主要作用是对Shuffle阶段产生的键值对进行聚合计算。
在这个阶段中,每个Reduce任务会对其分配的键值对进行聚合计算,并将计算结果输出到磁盘上。
二、MapReduce的并行计算模式MapReduce的并行计算模式主要包括Map并行计算和Reduce并行计算两种模式。
2.1 Map并行计算Map并行计算是指将输入数据集中的每个数据项映射为一组键值对的过程。
在Map并行计算中,MapReduce将输入数据集分成M个小的数据片段,并将这些数据片段交给多个Map任务并行处理。
每个Map任务会对其分配的数据片段进行处理,将其转化为一组键值对,并将这些键值对暂时存储在内存中。
Map并行计算的优点是可以充分利用多核CPU的计算能力,提高计算效率。

mapreduce并行编程原理MapReduce并行编程是一种用于大规模数据处理的编程模型。
它的核心思想是将数据分成若干块,然后并行处理每一块数据,最后将结果合并起来。
MapReduce模型具有以下两个阶段:1. Map阶段:在这个阶段,输入数据被映射为一系列的键值对。
每个键值对由一个映射函数处理,这个函数可以是用户定义的。
映射函数接收输入数据作为参数,并根据需求将其转化为键值对。
映射函数执行的结果会生成一个中间键值对列表。
2. Reduce阶段:在这个阶段,中间键值对列表被合并为输出结果。
用户定义的归约函数(reduce函数)接收相同键的键值对列表,并输出归约结果。
MapReduce编程模型的核心特点是可扩展性和容错性。
它可以在一个集群中运行,将数据分布在多个节点上进行处理,并在需要时进行数据重新分配以实现负载均衡。
此外,当某个节点失败时,MapReduce能够自动将任务重新分配给其他可用的节点,从而保证任务的完成性。
MapReduce编程模型可以应用于各种各样的数据处理任务,包括文本分析、数据挖掘、网页排名等。
下面是MapReduce编程模型的一些关键原理:1.数据切片:MapReduce将输入数据分成若干块,并将每个块分配给不同的节点进行处理。
这样可以实现数据的并行处理,提高处理效率。
2.映射函数:映射函数将输入数据转换为一系列的键值对。
用户可以根据任务的需求自定义映射函数。
3.归约函数:归约函数将相同键的键值对列表合并为一个结果。
归约函数也是用户自定义的,它可以根据任务的需求来实现不同的合并逻辑。
4.分布式存储:MapReduce使用分布式文件系统来存储数据。
这样可以将数据分布在多个节点上,实现数据的可靠性和高效访问。
5.任务调度和分配:MapReduce使用主节点来进行任务的调度和分配。
主节点负责将输入数据分配给不同的节点,并协调它们的执行。
6.容错处理:MapReduce能够在节点失败时进行容错处理。
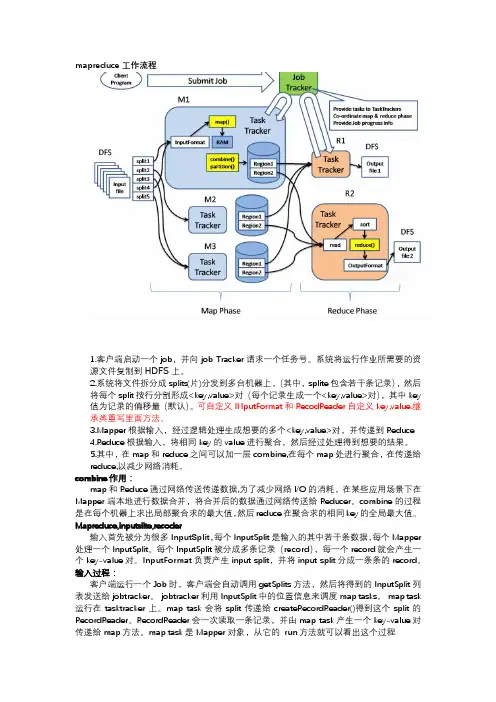
mapreduce工作流程1.客户端启动一个job,并向job Tracker请求一个任务号。
系统将运行作业所需要的资源文件复制到HDFS上。
2.系统将文件拆分成splits(片)分发到多台机器上,(其中,splite包含若干条记录),然后将每个split按行分割形成<key,value>对(每个记录生成一个<key,value>对),其中key值为记录的偏移量(默认)。
可自定义INputFormat和RecodReader自定义key,value.继承类重写里面方法。
3.Mapper根据输入,经过逻辑处理生成想要的多个<key,value>对,并传递到Reduce4.Reduce根据输入,将相同key的value进行聚合,然后经过处理得到想要的结果。
5.其中,在map和reduce之间可以加一层combine,在每个map处进行聚合,在传递给reduce,以减少网络消耗。
combine作用:map和Reduce通过网络传送传递数据,为了减少网络I/O的消耗,在某些应用场景下在Mapper端本地进行数据合并,将合并后的数据通过网络传送给Reducer。
combine的过程是在每个机器上求出局部聚合求的最大值,然后reduce在聚合求的相同key的全局最大值。
Mapreduce,inputslite,recoder输入首先被分为很多InputSplit,每个InputSplit是输入的其中若干条数据,每个Mapper 处理一个InputSplit。
每个InputSplit被分成多条记录(record),每一个record就会产生一个key-value对。
InputFormat负责产生input split,并将input split分成一条条的record。
输入过程:客户端运行一个Job时,客户端会自动调用getSplits方法,然后将得到的InputSplit 列表发送给jobtracker。

遗传算法的并行实现遗传算法(Genetic Algorithm,GA)是一种模拟自然进化过程的优化算法。
它模拟了生物进化的基本原理,通过迭代的方式不断优化空间中的解,以找到最优解或者接近最优解。
在遗传算法的实现中,可以采用并行计算的方式来提高算法的效率和性能。
并行计算将任务拆分成多个子任务,同时进行处理,并通过协同工作来加速计算过程。
并行实现遗传算法的主要思路有以下几种方式:1. 池式并行(Pool-Based Parallelism):多个遗传算法进程同时运行,并且每个进程都具有自己的种群和繁殖操作。
这些进程可以根据需要交换信息,例如交换最佳个体,以进一步加速过程。
2. 岛模型并行(Island Model Parallelism):将种群划分为多个子种群,每个子种群在独立的进程中进行演化。
定期地选择一些个体进行迁移,使得不同子种群的个体可以交流基因信息。
这种方式类似于地理上的岛屿,每个岛屿代表一个子种群,岛屿之间的迁移模拟了个体在不同岛屿之间的迁徙。
3. 数据并行(Data Parallelism):将种群的每个个体划分成多个部分,每个部分在不同的处理器上进行计算。
这种方法将空间分割成多个子空间,以加速算法的收敛过程。
4. 任务并行(Task Parallelism):将遗传算法的各个操作(例如选择、交叉、变异等)分解为多个任务,并行执行这些任务。
每个任务可以在不同的处理器上同时进行,从而加速算法的执行。
并行实现遗传算法的优势在于它可以通过利用多个处理单元,同时处理并行化的任务,使得算法的过程更加高效。
并行计算可以加速算法的收敛速度,减少空间中的局部最优解,并提供更好的全局能力。
然而,并行实现也会带来一些挑战和注意事项。
例如,如何划分任务以达到最佳的负载均衡,如何设计通信、同步和数据共享机制等等,都需要仔细考虑和解决。
总之,遗传算法的并行实现是一个非常广泛且复杂的课题,需要综合考虑问题的特性、硬件的条件和算法设计的需求。

人工智能基础(试卷编号1191)1.[单选题]以下不是贝叶斯回归的优点的是哪一项A)它能根据已有的数据进行改变B)它能在估计过程中引入正则项C)贝叶斯回归的推断速度快答案:C解析:2.[单选题]人工神经网络是一种模仿生物神经网络行为特征,进行信息处理的数学模型。
A、正确A)错误B)正确C)错误答案:A解析:3.[单选题]RNN作为图灵机使用时,需要一个( )序列作为输入,输出必须离散化以提供( )输出。
A)二进制B)八进制C)十进制D)十六进制答案:A解析:4.[单选题]Spark比MapReduce快的原因不包括()。
A)Spark基于内存迭代,而MapReduce基于磁盘迭代B)DAG计算模型相比MapReduce更有效率C)Spark是粗粒度的资源调度,而MapReduce是细粒度的资源调度D)Spark支持交互式处理,MapReduce善于处理流计算答案:D解析:A、B、C是Spark比MapReduce快的原因。
MapReduce不善于处理除批处理计 算模式之外的其他计算模式,如流计算、交互式计算和图计算等。
5.[单选题]L1正则和L2正则的共同点是什么?A)都会让数据集中的特征数量减少B)都会增大模型的偏差C)都会增大模型方差D)没有正确选项答案:D解析:6.[单选题]无轨导航规划的主要研究内容不包括( )。
A)路径规划B)轨迹规划C)自主定位D)避障规划答案:C解析:7.[单选题]声码器是由编码器和( )组成。
A)解码器B)特征提取器C)预处理器D)滤波器答案:A解析:8.[单选题]pandas从CSV文件导入数据的方法是A)pd.read_csv()B)pd.read_table()C)pd.read_excel()D)pd.read_sql()答案:A解析:9.[单选题]平滑图像处理可以釆用RGB彩色()模型。
A)直方图均衡化B)直方图均衡化C)加权均值滤波D)中值滤波答案:C解析:平滑图像处理可以采用RGB彩色加权均值滤波模型。

大数据挖掘中的MapReduce并行聚类优化算法研究吕国;肖瑞雪;白振荣;孟凡兴【摘要】针对传统数据挖掘算法只适用于小规模数据挖掘处理,由于数据规模不断增大,其存在计算效率低、内存不足等问题,文中将MapReduce用于数据挖掘领域,对大数据挖掘中的MapReduce进行了并行化改进,并设计相应的并行化实现模型,以期满足大数据分析需求,完成低成本、高性能的数据并行挖掘与处理.【期刊名称】《现代电子技术》【年(卷),期】2019(042)011【总页数】4页(P161-164)【关键词】大数据;MapReduce;并行化处理;聚类算法;数据挖掘;Map任务【作者】吕国;肖瑞雪;白振荣;孟凡兴【作者单位】河北建筑工程学院现代教育技术中心,河北张家口 075000;河北建筑工程学院现代教育技术中心,河北张家口 075000;河北建筑工程学院现代教育技术中心,河北张家口 075000;河北建筑工程学院现代教育技术中心,河北张家口075000【正文语种】中文【中图分类】TN911.1-34;TP311.140 引言随着大数据时代的来临,互联网的数据量正呈现出爆炸式的增长,采用传统数据分析法对其进行分析和研究,已经无法满足海量数据处理的需求。
基于此,数据挖掘技术随之产生。
数据挖掘就是从大量、随机、模糊、有噪声的数据内提取有价值的信息。
数据挖掘技术是指从大量数据中利用算法对隐藏信息进行搜索的过程,目前被广泛应用于金融、网络、决策及教育等行业中。
数据挖掘技术以统计学作为基础,增设模式识别、机器学习、数理统计、人工智能等多种技术,通过流数据及数据库完成工作[1]。
在数据技术不断发展的过程中,还融入了数据安全、数据结构算法、信息检索、信号处理、信息论等多种技术。
聚类分析则是一项比较实用的数据挖掘技术,因其能有效分析数据并发现其中的有用信息,被广泛用于文本搜索、人工智能、图像分析等领域[2]。
聚类分析把数据对象划分为多个簇,虽然同一个簇内的数据对象相似,但不同簇内的对象存在一定的差异。

MapReduce是一种分布式计算框架,可以用于大规模数据处理,它的实现机制主要包括以下几个方面。
1. 数据分片在MapReduce中,数据会被分成多个数据块,并且这些数据块会被复制到不同的节点上。
这样做的目的是为了提高数据的可靠性,同时也可以避免单节点故障导致的数据丢失。
2. Map阶段在Map阶段中,每个节点会同时执行Map函数,将输入的数据块转换为键值对的形式。
Map函数的输出结果会被分配到不同的Reducer节点上,这里需要注意的是,Map函数的输出结果必须是无状态的,即输出结果只能依赖于输入参数,而不能依赖于其他状态信息。
3. Shuffle阶段在Shuffle阶段中,Map函数的输出结果按照键的哈希值进行排序,并将相同键的值归并到一起。
这个过程需要消耗大量的网络带宽和磁盘I/O,因此Shuffle阶段是整个MapReduce计算中的瓶颈之一。
4. Reduce阶段在Reduce阶段中,每个Reducer节点会对Map函数输出结果中相同键的数据进行聚合操作。
Reduce函数的输入参数由Map函数输出结果中相同键的数据组成,而Reduce函数的输出结果是最终结果,MapReduce框架会将所有Reducer节点的输出结果合并为一个最终结果。
5. 容错机制在分布式计算中,可能会出现节点故障、网络异常等问题,这些问题会导致数据丢失或者计算结果错误。
因此,MapReduce框架需要具备一定的容错机制,比如在Shuffle阶段中,如果某个节点的输出结果没有及时到达目标节点,MapReduce框架会自动重新发送数据。
6. 优化策略为了提高MapReduce计算的性能和效率,MapReduce框架还可以采用多种优化策略,比如合并小文件、增加Map和Reduce的任务并行度、调整数据分片大小等。
总的来说,MapReduce框架通过数据分片、Map函数、Shuffle 阶段、Reduce函数等组件的协同工作,实现了大规模数据的分布式处理。

【关键词】并行计算大数据处理序列比对 MapReduce优化【英文关键词】parallel computing big data processing sequence alignment MapReduce optimization并行计算论文:MapReduce并行计算应用案例及其执行框架性能优化研究【中文摘要】当前,商业领域、科学领域以及社会生活中所产生的数据都在以惊人的速度增长。
以关系型数据库为代表的传统数据存储、处理技术和工具,已无法存储、管理和处理如此大规模急速增长的数据。
大数据包含了的有用信息,也带来了的挑战。
大数据处理技术已成为当前的研究热点。
在此背景下,通过并行计算技术解决大数据处理问题已成为学术界和工业界的普遍共识。
然而并行计算技术与应用问题紧密相关,且应用问题本身具有不同的复杂性和多样性,这使得大数据的处理具有很大的技术挑战,需要寻找和研究有效的大数据处理并行计算模型和系统。
由Google公司所发表的MapReduce并行计算技术,因其高可扩展性和高易用性而成为目前最成功的大数据处理技术,得到广泛应用。
Hadoop作为当前主流的开源MapReduce框架实现,已成为大数据处理应用事实上的工业标准。
但是,现有的MapReduce执行框架的实现主要面向大规模数据批处理作业,而目前各行业出现了越来越多的对作业响应性能有较高要求的在线数据处理或查询应用,现有的MapReduce并行计算框架在处理这类应用时,其响应性能存在明显的不足。
为了解该问题,本文从MapReduce上层应用到底层框架逐步深入,以MapReduce并行计算应用案例的研究工作为基础,研究并实现了对现有MapReduce执行框架的性能优化。
本文的研究工作主要分为以下两部分:(1) MapReduce并行计算应用案例研究,以生物信息学中的著名序列比对工具BLAST为研究案例,对BLAST算法并行化所涉及到的数据划分和计算划分的难点加以分析,提出并实现了基于MapReduce的两种并行化方案,通过多组实验测试对两种方案作了评估和比较。
MapReduce并行编程模型研究综述李建江1崔健1王聃1严林1黄义双21.北京科技大学计算机与通信工程学院计算机科学与技术系,北京100083;2.中国石油化工股份有限公司勘探南方分公司研究院,四川成都610041 摘 要:MapReduce并行编程模型通过定义良好的接口和运行时支持库,能够自动并行执行大规模计算任务,隐藏底层实现细节,降低并行编程的难度.本文对MapReduce的国内外相关研究现状进行了综述,阐述和分析了当前国内外与MapReduce相关的典型研究成果的特点和不足,重点对MapReduce涉及的关键技术(包括:模型改进、模型针对不同平台的实现、任务调度、负载均衡和容错)的研究现状进行了深入的分析.本文最后还对MapReduce未来的发展趋势进行了展望.MapReduce;并行编程模型;运行时支持库;海量数据处理TP316.4A0372-2112 ( 2011 ) 11-2635-08Survey of MapReduce Parallel Programming ModelLI Jian-jiangCUI JianWANG DanYAN LinHUANG Yi-shuang2011-01-122011-03-17基金项目:教育部重点基金(No. 108008);国家863高技术研究发展计划(No. 2008AA01Z109);北京市教育重点学科计算机系统结构(No.XK100080537)函数把Hadoop也利于其SAMR仍@@[ 1 ] J Dean, S Ghemawat. MapReduce: Simplified data processing on large clusters[ J]. Communications of the ACM, 2008, 51 (1):107- 113.@@[ 2 ] J L Wagener. High performance fortran [ J ]. Computer Stan dards & Interfaces,Elsevier, 1996,18(4) :371 - 377.@@[ 3 ] W Gropp, E Lusk, et al. Using MPI: Portable Parallel Program ming with the Message Passing Interface[ M]. Cambddge: MIT Press, 1999.1 - 350.@@[4] A Geist, A Beguelin, et al. PVM: Parallel Virtual Machine: A Users' Guide and Tutorial for Networked Parallel Computing [M]. Cambridge: MIT Press, 1995.1 - 299.@@[5]廖名学,范植华.MPI程序同步通信基本模型死锁检测 [J].电子学报,2008,36(2):402 - 407. Liao Ming-xue,Fan Zhi-hua. Deadlock detection in basic mod els of MPI synchronization communication programs [ J ]. Acta Electronica Sinica,2008,36(2) :402 - 407. (in Chinese)@@[6] A Verma, N Zea, et al. Breaking the mapreduce stage barrier [ A]. Proc of IEEE International Conference on Cluster Com puting[ C] .Los Alamitos: IEEE Computer Society,2010.235- 244.@@[7] H C Yang,A Dasdan,et al.Map-Reduce-Merge: Simplified re lational data processing[ A ]. Proc of ACM SIGMOD Interna tional Conference on Management of Data [ C ]. New York: ACM,2007. 1029 - 1040.@@[ 8 ] S V Valvag, D Johansen. Oivos: Simple and efficient distributed data processing[A] .Proc of IEEE International Conference on High Performance Con-puting and Communications[ C]. Piscat away: IEEE,2008.113 - 122.@@[9] Z Vrba,P Halvorsen,et al.Kahn process networks are a flexi ble alternative to mapreduce [ A ]. Proc of IEEE International Conference on High Performance Computing and Communica tions[ C]. Piscataway: IEEE,2009.154- 162.@@[ 10 ] Apache hadoop [ EB/OL ]. http://lucene. apache. org/ hadoop/, 2010-10-15/2010-12-28.@@[ 11 ] C Ranger, R Raghuraman, et al. Evaluating mapreduce for multi-core and multiprocessor systems[ A]. Proc of Interna tional Symposium on High Performance Computer Architec ture[C]. Piscataway: IEEE,2007.13 - 24.@@[ 12] R M Yoo,A Romano, et al. Phoenix rebirth:Scalable mapre duce on a large-scale shared-memory system [ A ]. Proe of IEEE International Symposium on Workload Characterization [C]. Piscataway: IEEE, 2009.198- 207.@@[ 13] He Bingsheng, Fang Wenbin,et al.Mars:A rnapreduce frame work on graphics processors[ A]. Proc of International Confer ence on Parallel Architectures and Compilation Techniques [ C]. Piscataway: IEEE, 2008.260 - 269.@@[14] M d Kmijf, K Sankaralingam. MapReduce for the cell broad band engine architecture[ J]. IBM Journal of Research and De velopment,2009,53 (5) :747 - 758.@@[15] A Dou, V Kalogeraki,et al. Misco:A mapreduce framework for mobile systems [ A ]. Proc of International Conference on PErvasive Technologies Related to Assistive Environments [C]. New York: ACM,2010.@@[ 16 ] Su Y L, Chen P C, et al. Variable-sized map and locality aware reduce on public-resonrce grids[ A]. Proe of Advances in Grid and Pervasive Computing. [ C ]. Berlin: Springer, 2010.234 - 243.@@[17] M Zabaria, D Borthakur, et al. Delay scheduling: A simple technique for achieving locality and fairness in cluster scheduling[ A]. Proc of EuroSys 2010 Conference[C]. New York: ACM,2010.265 - 278.@@[18] M Zaharia,A Konwinski,et al. Improving mapreduce perfor mance in heterogeneous environments [ A ]. Proc of USENIX conference on Operating systems design and implementation [ C]. Berkeley: USENIX Association, 2008.29 - 42.@@[ 19] J Polo,D Carrera,et al. Performance-driven task co-scheduling for mapreduce environments[ A]. Proe of IEEE/IFIP Network Operations and Management Symposium [ C ]. Piscataway: IEEE,2010.373 - 380.@@[ 20 ] T Bicer, W Jiang, et al. Supporting fault tolerance in a data-in tensive computing middieware[ A]. Proc of IEEE Intemational Symposium on Parallel & Distributed Processing[ C]. Piscat away: IEEE, 2010.1 - 12.@@[ 21 ] M Kontagora, H G Velez. Benchmarking a mapreduce envi ronment on a full virtualization platform[ A]. Proc of Interna tional Conference on Complex, Intelligent and Software Inten sive Systems[ C]. Piscataway: IEEE,2010.433 - 438.@@[22] K Kim, K Jeon, et al. MRBench: A benchmark for mapreduce framework[ A]. Proc of International Conference on Parallel and Distributed Systems[ C]. Piscataway: IEEE computer soci ety,2008.11 - 18.@@[ 23 ] Q Liu, T Todman, et al. Automatic optimization of mapreduce designs by geometric programming[ A]. Proe of International Conference on Field-Programmable Technology [ C ]. Piscat away: IEEE, 2009.215 - 222.@@[ 24] T Sandholm, K Lai. MapReduce optimization using regulated dynamic prioritization [ J ]. Performance Evaluation Review, 2009,37(1) :299- 310.@@[ 25 ] Y Becerra, V Beltran,et al. Speeding up distributed mapreduce applications using hardware accelerators[ A ]. Proc of Interna tional Conference on Parallel Processing [ C ]. Piscataway: IEEE,2009.42 - 49.@@[26] Wei Wei,Du Juan,et al.SecureMR:A service integrity assur ance framework for mapreduce[ A] .Proc of Annual Computer Security Applications Conference [ C ]. Piscataway: IEEE, 2009.73 - 82.@@[27] Liu Qiang,T Todman,et al. Combining optimizafions in auto mated low power design[ A]. Proc of Design, Automation & Test in Europe Conference & Exhibition [ C ]. Piscataway: IEEE,2010.1791 - 1796.@@[28] N Vasic,M Barisits,et al.Making cluster applications energy aware[ A]. Proc of Workshop on Automated Control for Data centers and Clouds[ C] .New York:ACM,2009.37 - 42.@@[29] Institutions and companies using hadoop[EB/OL]. http:// wiki. apache. org/hadoop/PoweredBy, 2010-12-25/2010-12-28.@@[30]陈康,郑纬民.云计算:系统实例与研究现状[J].软件学 报,2009,20(5):1337 - 1348. Chen Kang, Zheng Wei-min. Cloud computing: System in stances and current research[J]. Journal of Software, 2009,20 (5):1337- 1348. (in Chinese)@@[31 ] U Kang, C E Tsourakakis, et al. PEGASUS: A peta-scale graph mining system-implementation and observations [ A ]. Proc of IEEE International Conference on Data Mining[C]. Piscataway: IEEE, 2009.229 - 238.@@[32] Liu Yang, Jiang Xiao-hong, et al. MapReduce-based pattern finding algorithm applied in motif detection for prescription compatibility network[ A]. Proc of International Symposium on Advanced Parallel Processing Technologies [ C]. Berlin: Springer, 2009.341 - 355.@@[33] Yang Lai,Shi Zhong-zhi.An efficient data mining framework on hadoop using java persistence api[A]. Proc of IEEE Inter national Conference on Computer and Information Technology [C]. Los Alamitos: IEEE Computer Society,2010.203- 209.@@[34] Shah Yi,Wang Bo,et al. FPMR: MapReduce framework on FPGA a case study of rankboost acceleration [ A ]. Proc of ACM SIGDA International Symposium on Field-Pro grammable Gate Arrays[C]. New York: ACM, 2010.93 - 102.@@[35] Guo Lei-tao, Sun Hong-wei, et al. A data distribution aware task scheduling strategy for mapreduce system[ A]. First Inter national Conference on Cloud Computing [ C ]. Berlin: Springer,2009,694 - 699.@@[36] Chen Quan, Zhang Da-qiang, et al. SAMR: A self-adaptive mapreduce scheduling algorithm in heterogeneous environment [A] .Proc of IEEE International Conference on Computer and Information Technology[ C]. Los Alamitos: IEEE computer society, 2010.2736 - 2743.@@[37] Chen Ting, Wang Yong-jian, et al. A two-phase log-based fault recovery mechanism in master/worker based computing environment[A]. Proc of IEEE International Symposium on Parallel and Distributed Processing with Applications[ C]. Pis cataway: IEEE, 2009.290 - 297.@@[38] Huang Sheng-sheng,Huang Jie,et al. The hibench benchmark suite: characterization of the mapreduce-based data analysis [A]. Proc of IEEE Intematioanl Conference on Data Engi neering Workshops [ C]. Piscataway: IEEE, 2010.41 - 45.@@[39] Zhang Shu-bin, Han Ji-zhong, et al. Accelerating mapreduce with disffibuted memory cache[ A]. Proc of IEEE Intemational Conference on Parallel and Distributed Systems[ C]. Piscat away: IEEE, 2009.472 - 478.@@[40] M C Herbordt,T V Court, et al. Achieving high performance with FPGA-based computing [ J ]. Computer, 2007,40 ( 3 ) : 50 - 57.@@[41 ] K Langendoen, J Romein, et al. Integrating polling, interrupts, and thread management[A]. Proc of Symposium on the Fron tiers of Massively Parallel Computation [ C]. Los Alamitos: IEEE computer society, 1996.13 - 22.@@[42 ] M Treaster. A survey of fault-tolerance and fault-recovery techniques in parallel systems[ EB/OL]. http://arxiv. org/ abs/cs/0501002,2005-01-01/2010-12-28.@@[43] A Muni, J Hansen. Amazon web services[J]. Dr. Dobb' s Journal, 2005,30(12) :66 - 67.@@[44]宁焕生,徐群玉.全球物联网发展及中国物联网建设若 干思考[J].电子学报,2010,38(11):2590-2599.Ning Huan-sheng,Xu Qun-yu. Research on global hitemet of things' developments and it's construction in china[J]. Acta Electronica Sinica, 2010,38 ( 11 ) : 2590 - 2599. ( in Chinese )@@[45]宁焕生,张瑜,等.中国物联网信息服务系统研究[J].电 子学报,2006,34(12A):2514 - 2517.Ning Hua.r-sheng,Zhang Yu,et al. Research on China internet of things' services and management[ J] .Acta Electrohica Sinica, 2006,34(12A) : 2514 - 2517. ( hi Chinese) 李建江 男,1971年生于四川广安,博士,副教授,CCF会员,主要研究方向为高性能计算、并行编译和并行软件工程E- mail:jianjiangli@ gmail. com 崔健 男,1986年生于江苏苏州,硕士生,主要研究方向为高性能计算、并行软件工程.E-mail: cuijian613@ yahoo.com.cnMapReduce并行编程模型研究综述作者:李建江, 崔健, 王聃, 严林, 黄义双, LI Jian-jiang, CUI Jian, WANG Dan, YAN Lin, HUANG Yi-shuang作者单位:李建江,崔健,王聃,严林,LI Jian-jiang,CUI Jian,WANG Dan,YAN Lin(北京科技大学计算机与通信工程学院计算机科学与技术系,北京,100083), 黄义双,HUANG Yi-shuang(中国石油化工股份有限公司勘探南方分公司研究院,四川成都,610041)刊名:电子学报英文刊名:Acta Electronica Sinica年,卷(期):2011,39(11)本文链接:/Periodical_dianzixb201111026.aspx。
基于SPark的并行遗传算法研究作者:余涛刘泽檠来源:《计算机时代》2017年第01期摘要:当前Spark分布式编程框架由于内存计算得到了快速发展,相对于传统MapReduce 并行编程模型在迭代运算上有明显优势。
针对串行遗传算法处理大规模问题能力有限的现状,提出了一种基于Spark平台的粗粒度并行遗传算法(sPGA)。
该方法利用Spark框架并行实现了遗传算法的选择、交叉和变异操作,并对并行操作算子的性能进行了分析,优化了算法并行化实现方案,极大地提高了遗传算法全局搜索效率。
实验结果表明,新的并行遗传算法在收敛速度上有显著的提高,能够很好地提高优化效率。
关键词:Spark;RDD;并行遗传算法;多目标优化;大规模变量中图分类号:TP18文献标志码:A文章编号:1006-8228(2017)01-43-030.引言遗传算法是一种模拟生物进化的随机学习方法,主要包括选择、交叉和变异三种遗传操作。
面对大规模复杂优化问题时,遗传算法的寻优时间长,所以有人提出了并行遗传算法,主要将遗传算法的天然并行性跟并行编程模型相结合,加快搜索优化过程。
近年来,机器学习领域的众多专家做了许多加快并行遗传算法寻优速度的研究和探索。
郭肇禄在并行遗传算法中提出了自适应迁移策略,降低了通信开销。
李建明等人实现了一种基于GPU的细粒度并行遗传算法,抑制了种群的早熟,提高了搜索效率。
Verma A等人则从数据处理规模的角度实现了MapReduce跟遗传算法的结合。
这些基于GPU或者MapReduce实现的并行遗传算法,虽然取得了一定的进展,但是GPU可扩展能力欠佳,MapReduce的迭代速度较慢,这些缺陷都制约了并行遗传算法对大规模复杂优化问题的快速求解。
近期快速发展的Spark并行计算引擎能够提供内存计算机制,被普遍认为是下一代大数据并行处理框架,但是基于Spark计算模型实现并行遗传算法需要尝试不同的Spark算子和参数来对比分析其性能。
遗传算法的并行实现章衡 2007310437一、 问题描述遗传算法是通过模拟自然界生物进化过程来求解优化问题的一类自组织、自适应的人工智能技术。
它主要基于达尔文的自然进化论和孟德尔的遗传变异理论。
多数遗传算法的应用是处理一个由许多个体组成的群体,其中每个个体表示问题的一个潜在解。
对个体存在一个评估函数来评判其对环境的适应度。
为反映适者生存的思想,算法中设计一个选择机制,使得:适应度好的个体有更多的机会生存。
在种群的进化过程中,主要存在两种类型的遗传算子:杂交和变异。
这些算子作用于个体对应的染色体,产生新的染色体,从而构成下一代种群中的个体。
该过程不断进行,直到找到满足精度要求的解,或者达到设定的进化代数。
显然,这样的思想适合于现实世界中的一大类问题,因而具有广泛的应用价值。
遗传算法的每一次进化过程中的,各个体之间的操作大多可以并列进行,因此,一个非常自然的想法就是将遗传算法并行化,以提高计算速度。
本报告中试图得到一个并行遗传算法的框架,并考察并行化之后的一些特性。
为简单起见(本来应该考虑更复杂的问题,如TSP 。
因时间有些紧张,请老师原谅),考虑的具有问题是:对给定的正整数n 、n 元函数f ,以及定义域D ,求函数f 在D 内的最大值。
二、 串行遗传算法 1. 染色体与适应度函数对函数优化问题,一个潜在的解就是定义域D 中的一个点011(,,...,)n x x x -,因此,我们只需用一个长度为n 的实数数组来表示一个个体的染色体。
由于问题中要求求函数f 的最大值,我们可以以个体所代表点011(,,...,)n x x x -在f 函数下的值来判断该个体的好坏。
因此,我们直接用函数f 作为个体的适应度函数。
2. 选择机制选择是遗传算法中最主要的机制,也是影响遗传算法性能最主要的因素。
若选择过程中适应度好的个体生存的概率过大,会造成几个较好的可行解迅速占据种群,从而收敛于局部最优解;反之,若适应度对生存概率的影响过小,则会使算法呈现出纯粹的随机徘徊行为,算法无法收敛。
大讲台分享:五种基于MapReduce 的并行计算框架介绍及性能测试当使用 Hadoop 技术架构集群,集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值时,都会造成集群内数据分布不均匀、数据丢失风险增加等问题出现。
本文对 HDFS 内部的数据平衡方式做了介绍,通过实验案例的方式向读者解释内部数据平衡的解决办法。
并行计算模型和框架目前开源社区有许多并行计算模型和框架可供选择,按照实现方式、运行机制、依附的产品生态圈等可以被划分为几个类型,每个类型各有优缺点,如果能够对各类型的并行计算框架都进行深入研究及适当的缺点修复,就可以为不同硬件环境下的海量数据分析需求提供不同的软件层面的解决方案。
•并行计算框架并行计算或称平行计算是相对于串行计算来说的。
它是一种一次可执行多个指令的算法,目的是提高计算速度,以及通过扩大问题求解规模,解决大型而复杂的计算问题。
所谓并行计算可分为时间上的并行和空间上的并行。
时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并发的执行计算。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。
它的基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。
并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台的独立计算机构成的集群。
通过并行计算集群完成数据的处理,再将处理的结果返回给用户。
•国内外研究欧美发达国家对于并行计算技术的研究要远远早于我国,从最初的并行计算逐渐过渡到网格计算,随着 Internet 网络资源的迅速膨胀,因特网容纳了海量的各种类型的数据和信息。
海量数据的处理对服务器 CPU、IO 的吞吐都是严峻的考验,不论是处理速度、存储空间、容错性,还是在访问速度等方面,传统的技术架构和仅靠单台计算机基于串行的方式越来越不适应当前海量数据处理的要求。
mapreduce编程模型的实现过程实现MapReduce编程模型的过程包括以下几个步骤:1. 数据划分:将输入数据划分为多个小的数据块,每个数据块称为一个输入分片。
输入分片的大小通常由系统自动确定。
2. Map阶段:在Map阶段中,将输入数据分片传递给多个Map任务。
每个Map任务将输入分片的一部分数据进行处理,并生成中间键/值对(key/value pairs)。
Map任务可以是并行执行的,每个任务都是独立的。
3. Shuffle阶段:在Shuffle阶段中,系统对中间键/值对进行重新排序和分组,以便将相同key的数据发送给同一个Reduce任务。
Shuffle阶段通常涉及网络传输和磁盘读写等操作。
4. Reduce阶段:在Reduce阶段中,将相同key的中间值传递给对应的Reduce任务。
每个Reduce任务对传入的中间值进行处理,并生成最终的输出数据。
Reduce任务可以是并行执行的,每个任务都是独立的。
5. 结果收集与输出:最后,系统将所有Reduce任务的输出结果收集起来,并以适当的形式进行输出,如存储到文件系统中或发送给用户。
实现MapReduce编程模型的具体步骤可以依据所使用的具体框架进行。
例如,Hadoop是一个常用的大数据处理框架,它提供了MapReduce编程模型的实现。
在Hadoop中,可以使用Java编写Map和Reduce函数,并通过Hadoop提供的API来调度和执行MapReduce任务。
此外,还可以使用其他编程语言和框架,如Python和Apache Spark等,来实现MapReduce 编程模型。