第十一讲 回归分析和卡方检验剖析
- 格式:ppt
- 大小:2.16 MB
- 文档页数:18

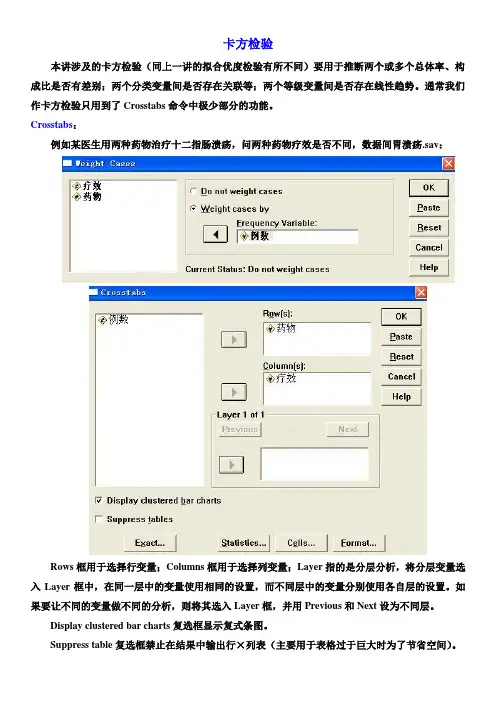
卡方检验本讲涉及的卡方检验(同上一讲的拟合优度检验有所不同)要用于推断两个或多个总体率、构成比是否有差别;两个分类变量间是否存在关联等;两个等级变量间是否存在线性趋势。
通常我们作卡方检验只用到了Crosstabs命令中极少部分的功能。
Crosstabs:例如某医生用两种药物治疗十二指肠溃疡,问两种药物疗效是否不同,数据间胃溃疡.sav:Rows框用于选择行变量;Columns框用于选择列变量;Layer指的是分层分析,将分层变量选入Layer框中,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。
如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next设为不同层。
Display clustered bar charts复选框显示复式条图。
Suppress table复选框禁止在结果中输出行×列表(主要用于表格过于巨大时为了节省空间)。
Exact 选项含义同前Statistics 对话框,用于定义所需计算的统计量。
接着要在statistics 中定义如何分析,以及如果相了解两变量间关联应该如何选关联指标:Chi-square 复选框:计算Pearson χ2值。
请注意作卡方检验时一定要满足总例数与理论数足够大的要求 ,系统会在卡方检验表格下提示有多少格子的理论数小于5Correlations 复选框:计算行、列两变量的Pearson 相关系数(主要用于行、列变量都是计量资料的两变量相关分析,并计算Pearson 关联系数r 又称为ρ)和Spearman 等级相关系数(主要用于分析行、列变量均为等级变量,计算Spearman 等级相关系数又称为秩相关系数r s 或又称为ρs )。
*比如两正态变量间的Pearson 相关系数可以用crosstab 过程计算,只要将correlations 勾上即可 在列联表的分析中,除了计算卡方值外,有时还要了解行列变量间的关联密切程度;SPSS 为我们提供了针对行列变量均为无序分类(Nominal )、等级变量(Ordinal )的列联表关联程度的衡量指标:Nominal 表示是否分析两个分类(通常指无序分类)变量间关联性,其下可计算4个指标:1)Contingency coefficient 复选框:即列联系数,在分析行列变量间关联性时使用;其值为n C +=22χχ界于0~1之间(但是如果行列数较少比如仅有2行2列,该系数最大只能到0.707;而四行四列则可以达到0.87,所以它的大小除了放映两个变量间的关联性还和表格的维度有关,因此该指标较少用于不同维度列联表间关联性比较);该系数越大表示两变量间关联性越大,反之则较小。


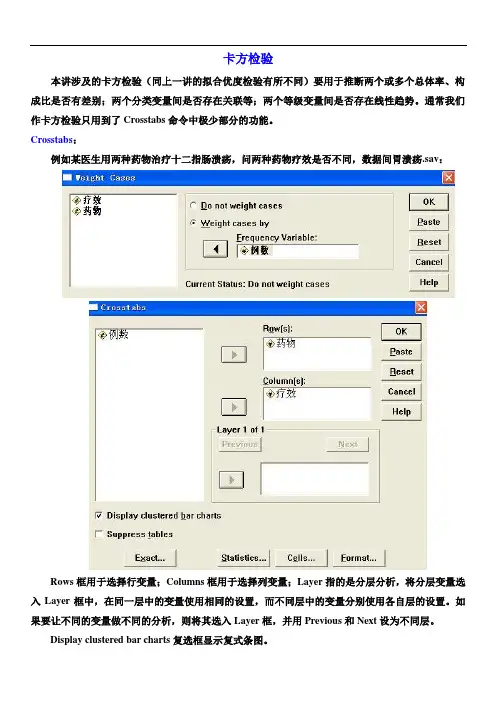
卡方检验本讲涉及的卡方检验(同上一讲的拟合优度检验有所不同)要用于推断两个或多个总体率、构成比是否有差别;两个分类变量间是否存在关联等;两个等级变量间是否存在线性趋势。
通常我们作卡方检验只用到了Crosstabs命令中极少部分的功能。
Crosstabs:例如某医生用两种药物治疗十二指肠溃疡,问两种药物疗效是否不同,数据间胃溃疡.sav:Rows框用于选择行变量;Columns框用于选择列变量;Layer指的是分层分析,将分层变量选入Layer框中,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。
如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next设为不同层。
Display clustered bar charts复选框显示复式条图。
Suppress table 复选框禁止在结果中输出行×列表(主要用于表格过于巨大时为了节省空间)。
Exact 选项含义同前Statistics 对话框,用于定义所需计算的统计量。
接着要在statistics 中定义如何分析,以及如果相了解两变量间关联应该如何选关联指标:Chi-square 复选框:计算Pearson χ2值。
请注意作卡方检验时一定要满足总例数与理论数足够大的要求 ,系统会在卡方检验表格下提示有多少格子的理论数小于5Correlations 复选框:计算行、列两变量的Pearson 相关系数(主要用于行、列变量都是计量资料的两变量相关分析,并计算Pearson 关联系数r 又称为ρ)和Spearman 等级相关系数(主要用于分析行、列变量均为等级变量,计算Spearman 等级相关系数又称为秩相关系数r s 或又称为ρs )。
*比如两正态变量间的Pearson 相关系数可以用crosstab 过程计算,只要将correlations 勾上即可 在列联表的分析中,除了计算卡方值外,有时还要了解行列变量间的关联密切程度;SPSS 为我们提供了针对行列变量均为无序分类(Nominal )、等级变量(Ordinal )的列联表关联程度的衡量指标:Nominal 表示是否分析两个分类(通常指无序分类)变量间关联性,其下可计算4个指标:1)Contingency coefficient 复选框:即列联系数,在分析行列变量间关联性时使用;其值为n C +=22χχ界于0~1之间(但是如果行列数较少比如仅有2行2列,该系数最大只能到0.707;而四行四列则可以达到0.87,所以它的大小除了放映两个变量间的关联性还和表格的维度有关,因此该指标较少用于不同维度列联表间关联性比较);该系数越大表示两变量间关联性越大,反之则较小。
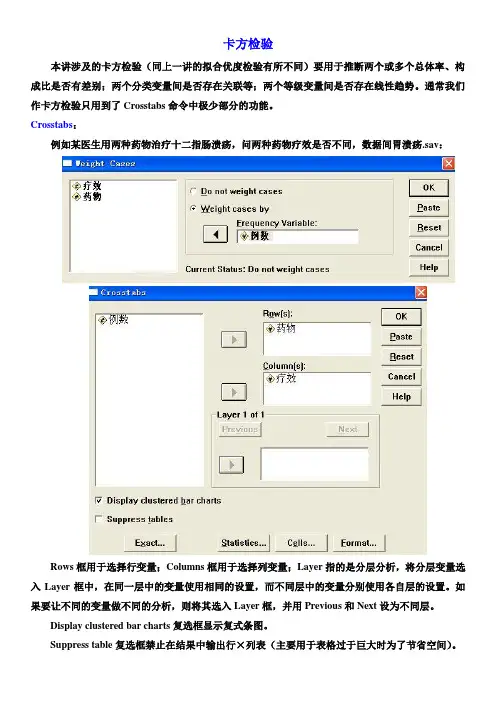
卡方检验本讲涉及的卡方检验(同上一讲的拟合优度检验有所不同)要用于推断两个或多个总体率、构成比是否有差别;两个分类变量间是否存在关联等;两个等级变量间是否存在线性趋势。
通常我们作卡方检验只用到了Crosstabs命令中极少部分的功能。
Crosstabs:例如某医生用两种药物治疗十二指肠溃疡,问两种药物疗效是否不同,数据间胃溃疡.sav:Rows框用于选择行变量;Columns框用于选择列变量;Layer指的是分层分析,将分层变量选入Layer框中,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。
如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next设为不同层。
Display clustered bar charts复选框显示复式条图。
Suppress table复选框禁止在结果中输出行×列表(主要用于表格过于巨大时为了节省空间)。
Exact 选项含义同前Statistics 对话框,用于定义所需计算的统计量。
接着要在statistics 中定义如何分析,以及如果相了解两变量间关联应该如何选关联指标:Chi-square 复选框:计算Pearson χ2值。
请注意作卡方检验时一定要满足总例数与理论数足够大的要求 ,系统会在卡方检验表格下提示有多少格子的理论数小于5Correlations 复选框:计算行、列两变量的Pearson 相关系数(主要用于行、列变量都是计量资料的两变量相关分析,并计算Pearson 关联系数r 又称为ρ)和Spearman 等级相关系数(主要用于分析行、列变量均为等级变量,计算Spearman 等级相关系数又称为秩相关系数r s 或又称为ρs )。
*比如两正态变量间的Pearson 相关系数可以用crosstab 过程计算,只要将correlations 勾上即可 在列联表的分析中,除了计算卡方值外,有时还要了解行列变量间的关联密切程度;SPSS 为我们提供了针对行列变量均为无序分类(Nominal )、等级变量(Ordinal )的列联表关联程度的衡量指标:Nominal 表示是否分析两个分类(通常指无序分类)变量间关联性,其下可计算4个指标:1)Contingency coefficient 复选框:即列联系数,在分析行列变量间关联性时使用;其值为n C +=22χχ界于0~1之间(但是如果行列数较少比如仅有2行2列,该系数最大只能到0.707;而四行四列则可以达到0.87,所以它的大小除了放映两个变量间的关联性还和表格的维度有关,因此该指标较少用于不同维度列联表间关联性比较);该系数越大表示两变量间关联性越大,反之则较小。





【转载】深⼊理解逻辑回归与卡⽅检验的区别Logistic回归分析的结果和卡⽅检验的结果不⼀样?这种情况是正常的,是由于分别使⽤单因素分析和多因素分析造成的。
卡⽅检验相对于Logistic回归⽽⾔⼀次只能考虑⼀个因素,因此在卡⽅检验中你的性别、专业是分开做的(单因素分析)。
如果在Logistic回归中你也分开做性别、专业(单因素分析),那么结果就会与卡⽅检验完全⼀样。
但是,如果你在Logistic回归中同时使⽤性别、专业等多个因素(多因素分析),那么模型中的各个因素是可以产⽣相互影响的,有可能产⽣共线性。
如果性别、专业存在共线性的话,那么Logistic逐步回归就会⾃动放弃其中⼀个模型影响⼒较⼩的因素(即使这个因素在单因素分析中有显著性也会被放弃)以防⽌共线性的产⽣。
补充:多重共线性的处理的⽅法(⼀)删除不重要的⾃变量⾃变量之间存在共线性,说明⾃变量所提供的信息是重叠的,可以删除不重要的⾃变量减少重复信息。
但从模型中删去⾃变量时应该注意:从实际经济分析确定为相对不重要并从偏相关系数检验证实为共线性原因的那些变量中删除。
如果删除不当,会产⽣模型设定误差,造成参数估计严重有偏的后果。
(⼆)追加样本信息多重共线性问题的实质是样本信息的不充分⽽导致模型参数的不能精确估计,因此追加样本信息是解决该问题的⼀条有效途径。
但是,由于资料收集及调查的困难,要追加样本信息在实践中有时并不容易。
(三)利⽤⾮样本先验信息⾮样本先验信息主要来⾃经济理论分析和经验认识。
充分利⽤这些先验的信息,往往有助于解决多重共线性问题。
(四)改变解释变量的形式改变解释变量的形式是解决多重共线性的⼀种简易⽅法,例如对于横截⾯数据采⽤相对数变量,对于时间序列数据采⽤增量型变量。
(五)逐步回归法逐步回归(Stepwise Regression)是⼀种常⽤的消除多重共线性、选取“最优”回归⽅程的⽅法。
其做法是逐个引⼊⾃变量,引⼊的条件是该⾃变量经F检验是显著的,每引⼊⼀个⾃变量后,对已选⼊的变量进⾏逐个检验,如果原来引⼊的变量由于后⾯变量的引⼊⽽变得不再显著,那么就将其剔除。
二元逻辑回归与卡方检验引言:在统计学和机器学习领域中,二元逻辑回归和卡方检验是两个重要的概念和方法。
二元逻辑回归用于建立一个预测某个二元变量的模型,而卡方检验用于检验两个分类变量之间的关联程度。
本文将介绍二元逻辑回归和卡方检验的原理、应用及其在实际问题中的意义。
一、二元逻辑回归1. 原理二元逻辑回归是一种广义线性模型,用于建立一个预测二元变量的概率的模型。
它基于线性回归模型的基础上,通过将线性回归模型的输出值经过一个逻辑函数(如sigmoid函数)进行转换,得到一个0到1之间的概率值,从而进行分类。
2. 应用二元逻辑回归广泛应用于各个领域,例如医学、金融、市场营销等。
在医学领域中,可以将二元逻辑回归应用于疾病的预测和诊断,通过分析患者的病历数据,建立一个模型来预测患者是否患有某种疾病。
在金融领域中,可以将二元逻辑回归应用于信用评分模型的建立,通过分析借款人的个人信息和财务数据,预测其违约概率。
在市场营销领域中,可以将二元逻辑回归应用于客户流失预测,通过分析客户的消费行为和偏好,预测客户是否会流失。
3. 意义二元逻辑回归在实际问题中具有重要的意义。
首先,它可以帮助我们理解不同变量对于某个二元变量的影响程度。
通过分析回归系数,我们可以判断某个变量对于预测结果的贡献程度。
其次,二元逻辑回归可以用于预测和分类,帮助我们做出决策。
例如,在医学领域中,我们可以根据患者的病历数据,预测其是否患有某种疾病,从而制定相应的治疗方案。
二、卡方检验1. 原理卡方检验是一种用于检验两个分类变量之间的关联程度的统计方法。
它基于观察频数和期望频数之间的差异,通过计算卡方统计量来判断两个变量是否独立。
2. 应用卡方检验广泛应用于各个领域,例如生物学、社会科学、市场研究等。
在生物学领域中,可以将卡方检验应用于遗传学研究,用于检验两个基因型之间的关联程度。
在社会科学领域中,可以将卡方检验应用于调查研究,用于检验两个变量之间的关联程度,例如性别和职业之间的关系。