到达时间间隔与到达时刻的分布
- 格式:doc
- 大小:159.50 KB
- 文档页数:3

排队模型一 1. 一般的排队过程为:顾客由顾客源出发,到达服务机构(服务台、服务员)前,按排队规则排队等待接受服务,服务机构按服务规则给顾客服务,顾客接受完服务后就离开。
排队过程的一般过程可用下图表示。
我们所说的排队系统就是指图中方框所包括的部分:在现实生活中的排队现象是多种多样的,对上面所说的“顾客”和“服务员”要作广泛的理解。
它们可以是人,也可以是某种物质或设备。
排队可以是有形的,也可以是无形的。
尽管排队系统是多种多样的,但从决定排队系统进程的因素来看,它有三个基本的组成部分,这就是输入过程、排队规则及服务机构.1)输入过程:描述顾客来源以及顾客到达排队系统的规律。
包括:顾客源中顾客的数量是有限还是无限;顾客到达的方式是单个到达还是成批到达;顾客相继到达的间隔时间分布是确定型的还是随机型的,分布参数是什么,是否独立,是否平稳。
2)排队规则:描述顾客排队等待的队列和接受服务的次序。
包括:即时制还是等待制;等待制下队列的情况(是单列还是多列,顾客能不能中途退出,多列时各列间的顾客能不能相互转移);等待制下顾客接受服务的次序(先到先服务,后到先服务,随机服务,有优先权的服务)。
3)服务机构:描述服务台(员)的机构形式和工作情况。
包括:服务台(员)的数目和排列情况;服务台(员)的服务方式;服务时间是确定型的还是随机型的,分布参数是什么,是否独立,是否平稳。
2.到达和服务过程的模型2.1 到达过程的模型用表示第i 个顾客到达的时间,.i t 称为第i 个到达时间间隔.1i i T t t +=−i 我们用的特征来刻画顾客到达过程. 最常见的情况是独立同分布. 用X 表示这样的随机变量.12,,T T 12,,T T 如果X 服从参数为λ的指数分布.这时1()()i E T E X λ==即平均每隔1λ来一个顾客.换句话说,单位时间理平均有λ个顾客到来.称λ为到达速率. 用表示到时刻t 为止到达的顾客总数,则在上面的假设下()N t ()()N t P t λ∼.除了指数分布外,常用的还有爱尔朗分布,其密度函数为1()(), 0.(1)!k RxR Rx e f x x k −−=≥− 这时2(), ()i i k k E T D T R R==. k 叫形状参数, R 叫速率参数.当取λ使得R k λ=, 则爱尔朗分布可以看成是k 个独立的服从参数为λ的指数分布随机变量的和的分布.2.2服务过程的模型一般总是认为不同顾客接受服务占用的时间长短是相互独立的. 用Y表示一个客户接受服务的时间长短, 它是一个随机变量.若Y的分布是参数为μ的指数分布, 意味着一个顾客的服务时间平均为1μ. 单位时间里可以完成的平均顾客数为μ.若Y服从形状参数为k, 速率参数为R kμ=的爱尔朗分布, 则平均服务时间为1μ, 根据爱尔朗分布的性质, 可以将Y看作是k个相继子服务的总时间, 每个子服务都服从参数为1kμ的指数分布且相互独立.在排队论中,我们常用如下字母表示特定的到达时间间隔或服务时间分布:M: i.i.d. 指数分布D: i.i.d. 的确定分布E k: i.i.d. 的形参为k的爱尔朗分布GI: 到达时间间隔是i.i.d. 的某种一般分布G: 服务时间是i.i.d. 的某种一般分布在处理实际排队系统时,需要把有关的原始资料进行统计,确定顾客到达间隔和服务时间的经验分布,然后按照统计学的方法确定符合哪种理论分布。



行车时刻表要素解读总结行车时刻表是列车运行时的重要参考资料,它包含了车次、始发站、终到站、经停站和发车时间等关键信息。
准确地读懂行车时刻表有助于乘客了解列车的运行情况,合理安排行程。
以下是行车时刻表的要素解读总结。
1.车次:每个车次都有唯一的标识号码,用于区分不同的列车。
车次号通常由数字组成,例如G1、D2等。
2.始发站和终到站:始发站是列车出发的地点,终到站是列车的目的地。
这两项信息告诉乘客列车的运行方向和行程终点。
3.经停站:经停站是列车在途中停靠的站点。
行车时刻表通常会列出列车途经的主要车站,以方便乘客做出选择。
4.发车时间:发车时间是列车从始发站出发的具体时间。
行车时刻表按小时和分钟显示发车时间,例如13:30表示下午1点30分。
5.到达时间:到达时间是列车到达各站的具体时间。
行车时刻表通常会显示列车到达每个车站的预计时间,以便乘客合理安排行程。
6.时间间隔:时间间隔是指列车在各站之间的运行时间。
行车时刻表会列出列车在每个站点的停留时间和两个相邻站点之间的行车时间。
7.停靠站时间:停靠站时间是列车在每个车站停留的具体时间。
行车时刻表会标注列车在每个车站停靠的时间长度,以便乘客了解列车的停留时间。
8.班次间隔:班次间隔是指两个车次之间的时间间隔。
行车时刻表会显示不同车次之间的发车时间间隔,以便乘客选择合适的出行时机。
9.车票类型:行车时刻表通常会标注不同车次适用的车票类型,例如普通票、学生票、儿童票等。
10.备注:行车时刻表中可能会有一些特殊情况的备注,例如调整的发车时间、停运的车次等。
要正确读懂行车时刻表,乘客需要注意以下几点:1.确定乘车日期和始发站:行车时刻表根据日期和始发站不同而有所变化,乘客需要根据实际需要选择对应的时刻表。
2.关注车次和终到站:根据自己的出行需求,选择对应的车次和终到站,以确定列车的运行方向和终点。
3.计算到达时间:根据发车时间和时间间隔,计算出自己的到达时间。
5。
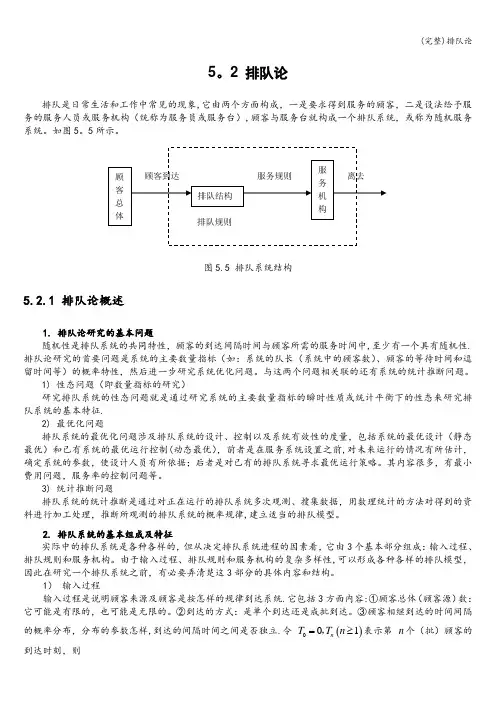
2 排队论排队是日常生活和工作中常见的现象,它由两个方面构成,一是要求得到服务的顾客,二是设法给予服务的服务人员或服务机构(统称为服务员或服务台),顾客与服务台就构成一个排队系统,或称为随机服务系统。
如图5。
5所示。
图5.5 排队系统结构5.2.1 排队论概述1. 排队论研究的基本问题随机性是排队系统的共同特性,顾客的到达间隔时间与顾客所需的服务时间中,至少有一个具有随机性.排队论研究的首要问题是系统的主要数量指标(如:系统的队长(系统中的顾客数)、顾客的等待时间和逗留时间等)的概率特性,然后进一步研究系统优化问题。
与这两个问题相关联的还有系统的统计推断问题。
1) 性态问题(即数量指标的研究)研究排队系统的性态问题就是通过研究系统的主要数量指标的瞬时性质或统计平衡下的性态来研究排队系统的基本特征.2) 最优化问题排队系统的最优化问题涉及排队系统的设计、控制以及系统有效性的度量,包括系统的最优设计(静态最优)和已有系统的最优运行控制(动态最优),前者是在服务系统设置之前,对未来运行的情况有所估计,确定系统的参数,使设计人员有所依据;后者是对已有的排队系统寻求最优运行策略。
其内容很多,有最小费用问题,服务率的控制问题等。
3) 统计推断问题排队系统的统计推断是通过对正在运行的排队系统多次观测、搜集数据,用数理统计的方法对得到的资料进行加工处理,推断所观测的排队系统的概率规律,建立适当的排队模型。
2. 排队系统的基本组成及特征实际中的排队系统是各种各样的,但从决定排队系统进程的因素看,它由3个基本部分组成:输入过程、排队规则和服务机构。
由于输入过程、排队规则和服务机构的复杂多样性,可以形成各种各样的排队模型,因此在研究一个排队系统之前,有必要弄清楚这3部分的具体内容和结构。
1) 输入过程输入过程是说明顾客来源及顾客是按怎样的规律到达系统.它包括3方面内容:①顾客总体(顾客源)数:它可能是有限的,也可能是无限的。



随机过程与排队论任课教师:魏静萱副教授wjx@曾勇副教授第一节排队现象例一:电话系统:主叫用户和被叫用户之间提供语音服务,该服务承载于某条通信信道之上,即两个用户c个通道。
地需要一条通道,3个用户需要3个通道,4个用户需要6个通道。
一般的,n个用户需要2n球人口60亿,需要?通道。
海量通信接近天文数字。
解决:信道“公用”导致拥挤排队现象例二:排队现象举例排队系统的三大要素:1. 输入过程 2. 排队规则:队列允许的最大长度 3. 服务窗:顾客是怎样接受服务的1.输入过程:顾客按什么规则进入系统?一个个?成批?到达过程和到达时间间隔符合一定的分布,称到达分布。
假设:到达过程和到达时间是独立同分布的。
到达过程假定为平稳的,对时间是齐次的。
注:Markov 齐次过程 如果一个过程只依赖于现在,而不是过去。
表1 输入过程的三种随机过程描述按顾客到达过程的不同概率特性分类: ① 定长输入(D ):顾客等间隔到达,nc τ=n τ的分布函数为 1()()0n t c F t P t t cτ≥⎧=≤=⎨<⎩②Poisson 流输入(M): 系统的输入过程{M(t)>0}是Poission 流 满足4个条件:a) M(t)取值为非负数b) P(M(0)=0)=1, 即时间间隔为0时到达系统 的人数为0 c) 过程{M(t)} 具有平稳独立增量性 d) 每一个增量M(a+t)-M(a)非负,且服从参数为tλ的泊松分布(){()()}!k a t P M t a M a k e K λλ-+-==③ k 阶Erlang 输入(Ek)④ 一般独立输入(G):顾客的到达过程{n τ}是独立同分布的随机变量序列,其分布函数可以是任意函数。
⑤ 成批到达系统:顾客一批批到达系统,每批相继到达的时间间隔为上述各种分布之一。
2.排队与服务规则① 损失制 (无排队队列):顾客到达时,系统被占用,顾客离去,不再回来。

高一物理必修一中的时间间隔与时刻常用的标志用语摘要:一、时间间隔与时刻的定义及区别二、时间间隔的常用标志用语三、时刻的常用标志用语四、实例解析正文:一、时间间隔与时刻的定义及区别在高一物理必修一中,我们学到了时间间隔和时刻这两个概念。
时间间隔是指两个时刻之间的时间长度,通常用秒、分钟、小时等单位表示。
时刻则是指某一瞬间的时间点,通常用具体的时间表示,如12:00、14:30 等。
时间间隔和时刻的区别在于,时间间隔是一个时间长度,而时刻是一个具体的时间点。
二、时间间隔的常用标志用语在描述时间间隔时,我们常用以下标志用语:1.“秒”:表示时间的基本单位,用于计量较短的时间间隔。
2.“分”:表示一分钟,用于计量较长的时间间隔。
3.“小时”:表示一小时,用于计量更长的时间间隔。
4.“天”:表示一天,用于计量较长的时间间隔。
5.“周”:表示一周,用于计量更长的时间间隔。
6.“月”:表示一个月,用于计量较长的时间间隔。
7.“年”:表示一年,用于计量较长的时间间隔。
三、时刻的常用标志用语在描述时刻时,我们常用以下标志用语:1.“点”:表示整点,如12:00、13:00 等。
2.“半”:表示半点,如12:30、13:30 等。
3.“刻”:表示一刻钟,如12:15、13:45 等。
4.“分”:表示分钟,如12:20、13:32 等。
四、实例解析假设有一个火车从甲站到乙站,甲、乙两站相距272 公里。
火车的行驶速度为每小时50 公里。
我们可以用时间间隔和时刻的标志用语来描述火车的行驶过程。
1.火车从甲站出发,行驶10 分钟后,火车到达了一个距离甲站25 公里的地方。
2.火车继续行驶20 分钟后,火车到达了乙站。
3.火车从甲站到乙站总共用了1 小时10 分钟。

定理2.2.1 到达时间间隔序列1,1,2,k k k T k ττ-=-= 相互独立同分布的,且服从参数为λ的指数分布.
这个命题应是在意料之中的. 事实上,泊松分布定义中的平稳独立增量的假定等于说在概率意义上过程是在任何时刻都重新开始,即从任何时刻起过程独立于先前已发生的一切(独立增量),且与原过程有完全同样的分布(平稳性),也就是通常讲的无后效性.
证明 1)求1T 的分布. 由于1T 表示第一次事件发生之前所需的时间,故
1{}T t >表示在[0,)t 时间段内事件还未出现,所以
111()()1()1(()0)1,0t T F t P T t P T t P N t e t λ-=≤=->=-==-∀≥
即1~()T E λ.
2)求2T 的分布. 由平稳增量性,在时间区间[,)s s t +内事件发生的次数与s 无关,而只与时间间隔的长度t 有关,即
21()(()()0)(()0),0t P T t T s P N s t N s P N t e t λ->==+-====∀≥
由全概率公式,()()()()1221210||t T P T t P T t T s f s ds e P T t T s λ∞
->=>===>=⎰
即2~()T E λ且与1T 独立.
3)求,2n T n >的分布.对于11,,,0n t s s -∀≥ ,有
11111111(,,)
(()()0)(()0)n n n n n t
P T t T s T s P N t s s N s s P N t e λ----->===+++-++====
即~(),2n T E n λ∀>,且相互独立.于是结论成立. □ 注意,定理2.2.1的逆命题也成立. 先研究到达时刻的分布,之后再来讨论这个问题.
定理2.2.2 到达时刻n τ服从参数为,n λ的Gamma 分布.
证明 由定理2.2.1,1,1,2,k k k T k ττ-=-= 相互独立且k T 的特征函数是 ()()()00012222cos sin 1itx x x x k t e e
dx tx e dx i tx e dx t t i i t t λλλϕλλλλ
λλλλλ∞∞∞
----==+⎛⎫=+=- ⎪++⎝⎭⎰⎰⎰
于是,1,1,2,n
n k k T n τ===∑ 的特征函数是
()111n n n k t t i it τλϕλλ-=⎛⎫⎛⎫=-= ⎪ ⎪-⎝⎭⎝⎭∏
而(),αβΓ分布的特征函数为()t it αβϕβ⎛⎫= ⎪-⎝⎭
,()~,n n τλ∴Γ 定理 2.2.3 若计数过程}0),({≥t t N 的到达时间间隔序列,1,2,k T k = 是相互独立同参数为λ的指数分布,则}0),({≥t t N 是参数为λ的泊松过程.
证明 由指数分布的无记忆性知, 过程}0),({≥t t N 具有平稳独立增量.于是只要证明()~()N t P t λ.
注意到n τ服从参数为,n λ的Gamma 分布,且
11{()}{}{}{}{}n n n n N t n t t t t ττττ++==>⋂≤=>->
所以
11100(())({})({})
({})({})
()()(1)!!n n n n n n t t x x P N t n P t P t P t P t x x e dx e dx n n λλττττλλλλ++---==>->=≤-≤=--⎰⎰
令y x λ=并由分部积分法得
()(()),0,0,1,2,!
n
t t P N t n e t n n λλ-==∀≥= 。
□ 由以上的结论可以看出,泊松分布和指数分布存在着紧密的联系,有人将定理2.2.1与定理2.2.3合起来作为泊松过程的定义,这种定义方法适宜于往更新过程乃至随机游动作进一步的推广;此外,这种定义实际上有助于读者理解泊松过程的无后效性并提供了模拟它的好方法,后面对此进行讨论.
例2.2.1 放射性物质在衰减过程平均每分钟放射出4个γ光子, 用)(t N 表示在观测时间区间(0,]t 内放射出γ光子的数目,且}0),({≥t t N 是泊松过程. 设计数器对检测到的γ光子只是每隔一个记录一次,令T 是两个相继被记录的光子之间的时间间隔(以分钟为单位),求T 的概率密度函数.
解 由题意,[](1)4E N λ==,故}0),({≥t t N 是参数4λ=的泊松过程。
设,1,2,k X k = 表示第1k -个与第k 个被记录的光子之间的时间间隔,且从放射出的第2个光子开始记录,显然212k k k X T T -=+,由定理2.2.1知,,1,2,k T k = 独立同指数分布,于是,1,2,k X k = 也是独立同分布的. 所以只要求出1X 的分布,即为T 的分布.注意到1{}X t >={在[0,)t 至多到达一个光子},故
112444()()(()1)(()0)(()1)4(14),0,t t t P X t P T T t P N t P N t P N t e te t e t --->=+>=≤==+==+=+∀≥ 所以T 的分布函数为
411(14),0()()0
,0t T t e t F t P X t t -⎧-+≥=≤=⎨<⎩ 概率密度函数为
416,0()()0
,0t T T te t f t F t t -⎧≥'==⎨<⎩.。