资料统计分析——单变量描述统计解析
- 格式:ppt
- 大小:1016.50 KB
- 文档页数:56


【实验名称】实验一、变量的描述性统计分析【实验目的】1、掌握在Eviews中建立工作文件的方法;2、掌握单变量序列的描述统计分析;3、利用有关命令,进行多变量的相关分布,会绘制多变量的散点图。
【实验内容】P42-练习题2:查找近二十年来我国财政收入和国内生产总值的数据,利用EViews软件分别以菜单方式和命令方式建立EViews文件,并进行初步的描述性分析。
【实验步骤及结果】一、查找原始数据:在网上查找到1978年-2008年我国财政收入和国内生产总值的数据,将其复制粘贴制作成EXCEL。
EXCEL如下所示:二、导入数据:打开Eviews,点击菜单中的下拉依次选择,,如下图所示。
输出如下图对话框,选择相应的文件,点击打开,再点击finish按钮即可。
得到如下的财政收入y和国内生产总值gdp的数据表:三、单个序列的分析:(1)、折线图:在对话框内输入line语句:依次得到如下财政收入y和国内生产总值gdp单个和合起来的折线图如下所示:从上图中我们可以看出财政收入y和国内生产总值gdp都随着时间不断增长,且存在一定的趋势性。
(2)、直方图:在对话框内输入bar语句:得到如下财政收入y和国内生产总值gdp的直方图如下所示:从上图中我们同样可以看出财政收入y和国内生产总值gdp都随着时间不断增长,且存在一定的趋势性。
(3)、P值:在对话框内输入hist语句:得到如下财政收入y和国内生产总值gdp的描述性统计图:从上图中可知财政收入y的均值是11703.27,中位数是4348.95,最大值是61330.35,最小值是1132.26,标准差是15425.52,偏度是1.86,峰度是5.74,P值接近于0。
从P值可知,序列在99%的置信水平下拒绝原假设,即财政收入y不服从正态分布。
从上图中可知国内生产总值gdp的均值是72289.11,中位数是35333.9,最大值是314045.4,最小值是3645.2,标准差是82654.74,偏度是1.40,峰度是4.22,P值接近于0。

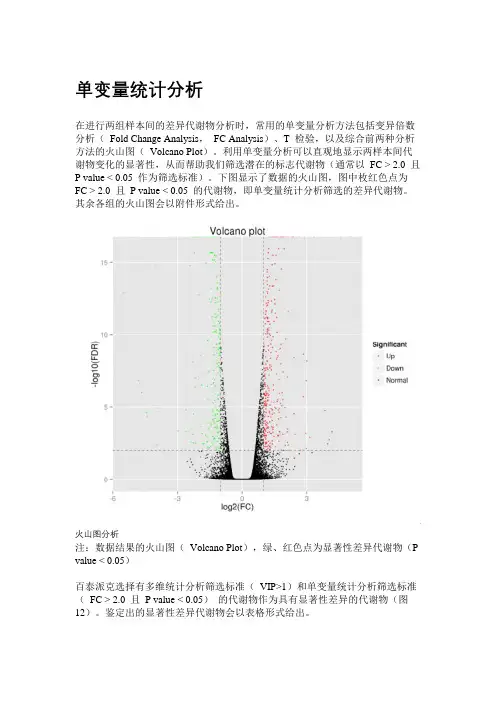
单变量统计分析在进行两组样本间的差异代谢物分析时,常用的单变量分析方法包括变异倍数分析(Fold Change Analysis,FC Analysis)、T 检验,以及综合前两种分析方法的火山图(Volcano Plot)。
利用单变量分析可以直观地显示两样本间代谢物变化的显著性,从而帮助我们筛选潜在的标志代谢物(通常以FC > 2.0 且P value < 0.05 作为筛选标准)。
下图显示了数据的火山图,图中枚红色点为FC > 2.0 且P value < 0.05 的代谢物,即单变量统计分析筛选的差异代谢物。
其余各组的火山图会以附件形式给出。
火山图分析注:数据结果的火山图(Volcano Plot),绿、红色点为显著性差异代谢物(P value < 0.05)百泰派克选择有多维统计分析筛选标准(VIP>1)和单变量统计分析筛选标准(FC > 2.0 且P value < 0.05)的代谢物作为具有显著性差异的代谢物(图12)。
鉴定出的显著性差异代谢物会以表格形式给出。
显著性差异的代谢物How to order?关于百泰派克北京百泰派克生物科技有限公司(Beijing Bio-Tech Pack Technology Company Ltd. 简称BTP)成立于2015年,是国家级高新技术企业,业务范围主要围绕蛋白和小分子代谢物检测两大板块,从事蛋白质和小分子代谢物的理化性质分析及结构解析等相关技术服务,为客户提供高性价比、高效率的技术服务。
深耕蛋白鉴定、定量蛋白组(iTRAQ/TMT、label free、DIA/SWATCH)、PRM靶蛋白定量、蛋白和抗体测序、蛋白修饰(二硫键、糖基化、磷酸化、乙酰化、泛素化等)、靶向和非靶向代谢物检测。
百泰派克生物科技检测平台包括:检测分析平台、蛋白质组学分析平台、代谢组学分析平台、蛋白质从头测序平台、生物制药分析平台和流式细胞多因子检测平台。




第⼆章单变量统计描述分析第⼆章单变量统计描述分析第⼀节单变量统计描述基本技术⼀、变量的计量尺度/层次1、定类变量——最低层次的变量类型。
只有类别属性之分,⽆⼤⼩程度之分。
根据变量值,只能知道研究对象的异同。
从数学运算特性来看,定类变量只有等于或不等于的性质。
2、定序变量——层次⾼于定类变量。
取值除类别属性外,还有等级、次序之分。
数学运算特性除等于或不等于外,还有⼤于或⼩于。
3、定距变量——层次⾼于定序变量。
取值除类别属性、次序之外,取值之间的距离可以⽤标准化的举例度量。
数学运算特性除等于不等于,⼤于⼩于之外,还可以加减。
如收⼊,以1元为标准化距离,则2000元⽐1500元多了500元。
4、定⽐变量——最⾼层次变量。
除了上述三种属性外,可以进⾏乘除运算。
1、社会学研究中,能够满⾜定距⽽不能同时满⾜定⽐要求的变量不多。
如智商,因为智商0分只有相对的意义,0分不等于没有智商,且0值不固定。
当前社会统计⽅法很少要求达到定⽐层测,所以只介绍前三种层次变量。
2、在社会学研究当中,有些变量的层次是不统⼀可变的,可⽤定序层次也可⽤定距层次,根据研究需要。
⾼层次变量可以降低层次来使⽤。
⼀般来说,测量层次越⾼越好,数学特性就越多,统计分析就越⽅便,能了解资料的程度就越深⼊。
⼆、基本技术1、次数分布(定类)——针对定类变量最基本的统计分析⽅法。
⾯对⼤量的数据资料,⾸先要组织整理,第⼀步就是要采⽤次数分布来简化资料,看某变量的每⼀个值出现的次数是多少。
定类变量的取值要求:变量取值必须完备,使得每个各观察值都有所归类;必须互斥,⼀个观察值只能归⼊⼀类,对于分组数据遵循上限不包括在内原则。
次数分布可简化资料,但不能⽐较样本,因为样本量不同。
2、⽐、⽐例和⽐率(通常保留⼀位或两位⼩数)⽐:某两类的次数相除,如性别⽐=男性/⼥性⽐例:某类次数除以总数,⽼年⼈⼝⽐例=⽼年⼈⼝数/总⼈⼝数×100%⽐率:某⼀确定变量相对应的某些事件发⽣的频率。

单变量统计分析方法总结一、计量资料1.两组独立样本比较1.1资料符合正态分布,且两组方差齐性,及独立性,可直接采用t检验。
1.2资料不符合正态分布(1)数据转换(如对数转换等)→使之服从正态分布→转换后的数据采用t检验;(2)直接采用非参数检验(如Wilcoxon检验)。
1.3资料方差不齐(1)t’检验(前提是资料满足正态性);(2)采用非参数检验(如Wilcoxon检验)。
2.两组配对样本的比较2.1 两组差值服从正态分布,采用配对t检验。
2.2 两组差值不服从正态分布,采用wilcoxon的符号配对秩和检验。
3.多组完全随机样本比较3.1资料符合正态分布,且各组方差齐性,直接采用完全随机的方差分析。
如检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,SNK法,Bonferroni法,tukey法,Scheffe法等。
3.2资料不符合正态分布,或各组方差不齐(1)数据转换(如对数转换等)→使之服从正态分布或方差齐性→转换后数据采用F检验;(2)直接采用非参数检验(如Kruscal-Wallis法)。
如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用两组的Wilcoxon检验,或秩变换方法。
4.多组随机区组样本比较4.1资料符合正态分布,且各组方差齐性,直接采用随机区组的方差分析。
如果检验结果为有统计学意义,则进一步作两两比较,两两比较的方法有LSD检验,Bonferroni法,tukey法,Scheffe法,SNK法等。
4.2资料不符合正态分布,或各组方差不齐,则采用非参数检验的Fridman检验法。
如果检验结果为有统计学意义,则进一步作两两比较,一般采用Bonferroni法校正P值,然后用符号配对的Wilcoxon检验。
★需要注意的问题:(1)一般来说,如果是大样本,比如各组例数大于50,可以不作正态性检验,直接采用t检验或方差分析。