《编译原理实践及应用》第3章词法分析 (2)
- 格式:pptx
- 大小:2.64 MB
- 文档页数:126










第3章词法分析习题答案1.判断下面的陈述是否正确。
(1)有穷自动机接受的语言是正规语言。
(√)(2)若r1和r2是Σ上的正规式,则r1|r2也是Σ上的正规式。
(√)(3)设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
(× )(4)设Σ={a,b},则Σ上所有以b为首的符号串构成的正规集的正规式为b*(a|b)*。
(× )(5)对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
(√)(6)对一个右线性文法G,必存在一个左线性文法G',使得L(G)=L(G'),反之亦然。
(√) (7)一个DFA,可以通过多条路识别一个符号串。
(× )(8)一个NFA,可以通过多条路识别一个符号串。
(√)(9)如果一个有穷自动机可以接受空符号串,则它的状态图一定含有 边。
(× )(10)DFA具有翻译单词的能力。
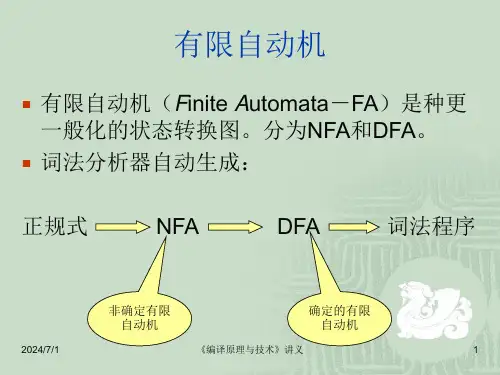
(× )2.指与出正规式匹配的串.(1)(ab|b)*c 与后面的那些串匹配?ababbc abab c babc aaabc(2)ab*c*(a|b)c 与后面的那些串匹配? acac acbbc abbcac abc acc(3)(a|b)a*(ba)* 与后面的那些串匹配? ba bba aa baa ababa答案(1) ababbc c babc(2) acac abbcac abc(3) ba bba aa baa ababa3. 为下边所描述的串写正规式,字母表是{0, 1}.(1)以01 结尾的所有串(2)只包含一个0的所有串(3) 包含偶数个1但不含0的所有串(4)包含偶数个1且含任意数目0的所有串(5)包含01子串的所有串(6)不包含01子串的所有串答案注意 正规式不唯一(1)(0|1)*01(2)1*01*(3)(11)*(4)(0*10*10*)*(5)(0|1)*01(0|1)*(6)1*0*4.请描述下面正规式定义的串. 字母表{x, y}.(1) x(x|y)*x(2)x*(yx)*x*(3) (x|y)*(xx|yy) (x|y)*答案(1)必须以 x 开头和x结尾的串(2)每个 y 至少有一个 x 跟在后边的串 (3)所有含两个相继的x或两个相继的y的串5.处于/* 和 */之间的串构成注解,注解中间没有*/。
北邮大三上-编译原理-词法分析实验报告编译原理第三章词法分析班级:2009211311学号:姓名:schnee目录1.实验题目和要求 (3)2.检测代码分析 (3)3.源代码 (4)1.实验题目和要求题目:词法分析程序的设计与实现。
实验内容:设计并实现C语言的词法分析程序,要求如下。
(1)、可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2)、可以识别并读取源程序中的注释。
(3)、可以统计源程序汇总的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果(4)、检查源程序中存在的错误,并可以报告错误所在的行列位置。
(5)、发现源程序中存在的错误后,进行适当的恢复,使词法分析可以继续进行,通过一次词法分析处理,可以检查并报告源程序中存在的所有错误。
实验要求:方法1:采用C/C++作为实现语言,手工编写词法分析程序。
方法2:通过编写LEX源程序,利用LEX软件工具自动生成词法分析程序。
2.检测代码分析1、Hello World简单程序输入:2、较复杂程序输入:3. 异常程序输入检测三,源代码#include <cmath>#include <cctype>#include <string>#include <vector>#include <cstdio>#include <cstdlib>#include <cstring>#include <fstream>#include <iostream>#include <algorithm>using namespace std;const int FILENAME=105;const int MAXBUF=82;const int L_END=40;const int R_END=81;const int START=0; //开始指针vector<string> Key; //C保留的关键字表class funtion //词法分析结构{public://变量声明char filename[FILENAME]; //需要词法分析的代码文件名ifstream f_in;char buffer[MAXBUF]; //输入缓冲区int l_end, r_end, forward; //左半区终点,右半区终点,前进指针,bool l_has, r_has; //辅助标记位,表示是否已经填充过缓冲区vector<string> Id; //标识符表char C; //当前读入的字符int linenum, wordnum, charnum; //行数,单词数,字符数string curword; //存放当前的字符串//函数声明void get_char(); //从输入缓冲区读一个字符,放入C中,forward指向下一个void get_nbc(); //检查当前字符是否为空字符,反复调用直到非空void retract(); //向前指针后退一位void initial(); //初始化要词法分析的文件void fillBuffer(int pos); //填充缓冲区,0表示左,1表示右void analyzer(); //词法分析void token_table(); //以记号的形式输出每个单词符号void note_print(); //识别并读取源程序中的注释void count_number(); //统计源程序汇总的语句行数、单词个数和字符个数void error_report(); //检查并报告源程序中存在的所有错误void solve(char* file); //主调用函数};void welcome(){printf("\n************************************** *******************\n");printf( "** Welcome to use LexicalAnalyzer **\n");printf( "** By schnee @BUPT Date: 2011/20/10 **\n");printf( "*********************************************************\n\n\n");}void initKey(){Key.clear();Key.push_back("auto"); Key.push_back("break"); Key.push_back("case"); Key.push_back("char");Key.push_back("const");Key.push_back("continue");Key.push_back("default"); Key.push_back("do");Key.push_back("double");Key.push_back("else"); Key.push_back("enum"); Key.push_back("extern");Key.push_back("float"); Key.push_back("for"); Key.push_back("goto"); Key.push_back("if");Key.push_back("int");Key.push_back("long");Key.push_back("register");Key.push_back("return");Key.push_back("short");Key.push_back("signed"); Key.push_back("static"); Key.push_back("sizeof");Key.push_back("struct");Key.push_back("switch"); Key.push_back("typedef"); Key.push_back("union");Key.push_back("unsigned");Key.push_back("void"); Key.push_back("volatile");Key.push_back("while");}void funtion::get_char(){C=buffer[forward];if(C==EOF)return ; //结束if(C=='\n')linenum++; //统计行数和字符数else if(isalnum(C)) charnum++;forward++;if(buffer[forward]==EOF){if(forward==l_end){fillBuffer(1);forward++;}else if(forward==r_end){fillBuffer(0);forward=START;}}}void funtion::get_nbc(){while(C==' ' || C=='\n' || C=='\t' || C=='\0') get_char();}void funtion::initial(char* file){Id.clear(); //清空标识符表l_end=L_END;r_end=R_END; //初始化缓冲区forward=0;l_has=r_has=false;buffer[l_end]=buffer[r_end]=EOF;fillBuffer(0);linenum=wordnum=charnum=0; //初始化行数,单词数,字符数}void funtion::fillBuffer(int pos){if(pos==0)//填充缓冲区的左半边{if(l_has==false){fin.read(buffer, l_end);if(fin.gcount()!=l_end)buffer[fin.gcount()]=EOF;}else l_has=false;}else //填充缓冲区的右半边{if(r_has==false){fin.read(buffer+l_end+1, l_end);if(fin.gcount()!=l_end)buffer[fin.gcount()+l_end+1]=EOF;}else r_has=false;}}void funtion::retract(){if(forward==0){l_has=true; //表示已经读取过文件,避免下次再次读取forward=l_end-1;}else{forward--;if(forward==l_end){r_add=true;forward--;}}}void funtion::analyzer(){FILE *token_file, *note_file, *count_file, *error_file;token_file=fopen("token_file.txt", "w");note_file=fopen("note_file.txt", "w");count_file=fopen("count_file.txt", "w");error_file=fopen("error_file.txt", "w");int i;curword.clear();get_char();get_nbc();if(C==EOF)return false;if(isalpha(C) || C=='_')//关键字和标识符的处理,以字母或下划线开头{curword.clear();while(isalnum(C) || C=='_'){curword.push_back(C);get_char();}retract();wordnum++;Id.push_back(curword);for(i=0; i<Key.size(); i++)if(Key[i]==curword)break;//输出每一个单词的标识符if(i<Key.size()) //关键字fprintf(token_file, "%8d----%20s %s\n", wordnum, "KEY WORD", curword);elsefprintf(token_file, "%8d----%20s %s\n", wordnum, "Identifier", curword);}else if(isdigit(C))//无符号数的处理{curword.clear();while(isdigit(C)){curword.push_back(C);get_char();}if(C=='.' || C=='E' || C=='e')//处理小数和指数形式{curword.push_back(C);get_char();while(isdigit()){curword.push_back(C);get_char();}}retract();wordnum++;Id.push_back(curword);fprintf(token_file, "%8d----%20s %s\n", wordnum, "Unsigned Number", curword);}else if(C=='#')//过滤掉以#开头的预处理{fprintf(note_file, "preproccess Line %d : ", linenum);get_char();fprintf(note_file, "%c", C);while(C!='\n'){get_char();fprintf(note_file, "%c", C);}fprintf(note_file, "%c", C);}else if(C=='"')//""内的句子当成整个串保存起来{curword.clear();get_char();while(C!='"'){curword.push_back(C);get_char();}fprintf(token_file, "*****string in ""----%s\n", curword);}else if(C=='/'){get_char();if(C=='/')//过滤掉//开头的行注释{fprintf(note_file, "single-line note Line %d : ", linenum);get_char();curword.clear();while(C!='\n'){curword.push_back(C);get_char();}fprintf(note_file, "%s\n", curword);}else if(C=='*')//过滤掉/**/之间的段注释{fprintf(note_file, "paragraph note Line %d : ", linenum);get_char();while(true){while(C!='/'){fprintf(note_file, "%c", C);get_char();}get_char();if(C=='*'){fprintf(note_file, "\nto Line %d\n", linenum);break;}fprintf(note_file, "%c", C);}}else if(C=='=')fprintf(token_file, "*****ASSIGN-OP, DIV\n");else{fprintf(token_file, "*****CAL-OP, DIV\n");retract();}} //处理各种比较,赋值,运算符号else if(C=='<'){get_char();if(C=='=')fprintf(token_file, "*****RELOP, LE\n");else{fprintf(token_file, "*****RELOP, LT\n");retract();}}else if(C=='>'){get_char();if(C=='=')fprintf(token_file, "*****RELOP, GE\n");else{fprintf(token_file, "*****RELOP, GT\n");retract();}}else if(C=='='){get_char();if(C=='=')fprintf(token_file, "*****RELOP, EQ\n");else{fprintf(token_file, "*****ASSIGN-OP, EASY\n");retract();}}else if(C=='+'){get_char();if(C=='=')fprintf(token_file, "*****ASSIGN-OP, ADD\n");else{fprintf(token_file, "*****CAL-OP, ADD\n");retract();}}else if(C=='-'){get_char();if(C=='=')fprintf(token_file, "*****ASSIGN-OP, SUB\n");else{fprintf(token_file, "*****CAL-OP, SUB\n");retract();}}else if(C=='*'){get_char();if(C=='=')fprintf(token_file, "*****ASSIGN-OP, MUL\n");else{fprintf(token_file, "*****CAL-OP, MUL\n");retract();}}else if(C=='!'){get_char();if(C=='=')fprintf(token_file, "*****RELOP, UE\n");else if(!isalpha(C) && C!='_'){fprintf(error_file, "Line %d: error: '!' was illegal char \n", linenum);}}else if(C==':' || C=='(' || C==')' || C==';' || C=='{' || C=='}' || C==',')fprintf(token_file, "*****Other char----%c\n", C);elsefprintf(error_file, "Line %d: error: '%c' was illegal char \n", linenum, C);fprintf(count_file, "The Line number is %d\n", linenum);fprintf(count_file, "The word number is %d\n", wordnum);fprintf(count_file, "The char number is %d\n",charnum);fclose(token_file);fclose(note_file);fclose(count_file);fclose(error_file);}void funtion::token_table(){fin.open("token_file.txt");printf("The token_table is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::note_print(){fin.open("note_file.txt");printf("The note is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::count_number(){fin.open("count_file.txt");printf("The count result is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::error_report(){fin.open("error_file.txt");printf("The error report is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::solve(char* file){filename=file;fin.open(filename);intitial();analyzer();int choice;printf("**** We have analyzed %s \n");printf("**0: To end\n");printf("**1: To get the token table\n");printf("**2: To get the note part of file\n");printf("**4: To report all the error of the file\n");printf("**3: To get the line num, word num and charter num\n\n");while(1){printf("****please input your choice: ");scanf("%d", &choice);if(choice==0)break;if(choice==1)token_table();else if(choice==2)note_print();else if(choice==3)count_number();else error_report();printf("\n");}}void LexicalAnaylzer(char* file){funtion test;test.solve(file);}int main(){welcome();initKey();char file[FILENAME];while(1){printf("\nDo you want to continue? ("YES" or "NO"): ");scanf("%s", file);if(strcmp(file, "NO")==0){printf("Thanks for your use! GoodBye next time!\n\n");break;}printf("Please type your C file name(for example: a.cpp): ");scanf("%s", file);LexicalAnalyzer(file);}return 0;}。