第三章词法分析
- 格式:ppt
- 大小:447.50 KB
- 文档页数:30




第3章--词法分析第三章词法分析知识结构:功能词法分析器的要求单词符号分类词法分析单词内部形式器的设计设计⽅发词法分析器的设计状态图词法分析器组成正规表达式单词描述⼯具正规集词法分析器正规⽂法确定有限⾃动机(DFA )单词识别⼯具⾮确定有限⾃动机(NFA )DFA 的最⼩化正规式与FA 的等价转换等价转换正规⽂法与FA 的等价转换第⼀节对词法分析器的要求⼀、词法分析器的功能输⼊源程序,输出单词符号(⼆元式表⽰)。
关键字:是由程序语⾔定义的具有固定意义的标识符。
标识符:⽤来表⽰各种名字,如变量等。
常数:常数的类型有整型,实型等。
运算符:算术运算符,关系运算符,逻辑运算符。
界限符:逗号,分号等。
三、单词符号内部的表⽰形式内部的单词符号TOKEN字(⼆元式),TOKEN字占⽤机器字的长度,依据信息量的多少⽽定。
1、TOKEN字结构VALUE:表⽰单词符号的属性(符号表指针)。
2、TOKEN的作⽤CLASS:⽤于语法分析器对源程序结构的分析。
VALUE:⽤于语义分析器对源程序具体操作的分析。
3、单词种别码划分原则CLASS:关键字,运算符,界限符(编译程序定义的符号)使⽤⼀字⼀种编码。
VALUE值省略。
VALUE:标识符,常数(⽤户定义的符号),存放符号表常数表的指针。
标识符,常数每⼀类为⼀种编码。
例:BEGIN A:= B END;词法分析结果:符号表(BEGIN,---- )Array(A ,K1 ) K1(:= ,--- )(B ,K3 ) K3(END ,--- )(;,--- )四、词法分析器的结构1、⼀遍扫描(交互式结构)。
2、多遍扫描(独⽴式结构)。
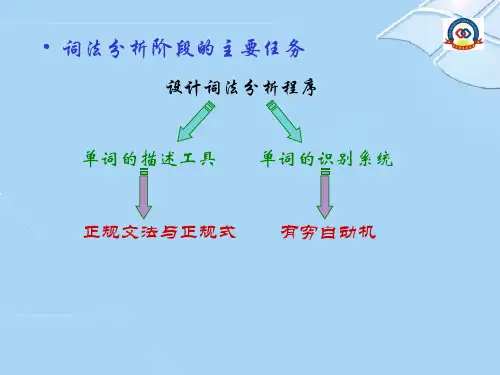
第⼆节词法分析器的设计⼀、设计步骤1、确定词法分析器的接⼝关系;2、确定单词分类和TOKEN字的结构;3、对每⼀类单词构造状态转换图;4、根据状态转换图设计算法。
⼆、功能描述1、组织源程序输⼊;2、按词法规则拼读单词符号,并转换成⼆元式;3、删除注解⾏,空格和⽆⽤符号;4、检查词法错误。



第三章词法分析前两章为研究编译技术作了一些概念和技术上的先期铺垫,在本章的词法分析内容里将开始介绍编译技术的第一个重要技术点:词法分析。
本章的重点与难点是:词法分析器的任务与设计、状态转换图的实现、由正规表达式(正规式)构造非确定有限自动机、非确定有限自动机的确定化、确定有限自动机的最小化,正规式,正规集;词法分析器自动生成。
本章主要内容是:词法分析器任务,词法分析器设计,正规表达式与有限自动机,词法分析器自动生成。
对于本章,读者应该掌握:词法分析器的作用与设计,状态转换图的实现;正规式,正规集,正规定义;确定有限自动机,非确定有限自动机,NFA到DFA的转化;从正规式构造自动机;词法分析器自动生成。
3.1学习指导3.1.1词法分析器的功能词法分析的任务是识别源程序中具有独立含义的最小语法单位——符号或单词,如标识符,无正负号常数和界符等等。
并把源程序转换为等价的内部表示形式。
功能:读入源程序字符串;识别单词(符号);转换成属性字;并实现一些其他的简单工作:删除注解,预加工处理等等。
执行词法分析的程序称为词法分析程序,或词法分析器,或扫描器。
词法分析的实现有两种方式:相对独立:词法分析作为子程序。
当语法分析程序需要读下一个符号的时候,调用这个子程序。
完全独立:词法分析程序作为单独的一遍来实现。
常用的做法:将词法分析程序安排成一个子程序(过程),每当语法分析需要一个单词时就调用这个子程序;每调用一次,就向语法分析程序提供一个单词的二元组。
词法分析器的功能是输入源程序,输出单词符号。
单词符号是一个程序语言的基本语法符号。
程序语言的单词符号一般可以分为5类:(1)基本字(关键字、保留字):具有特殊含义的标识符,不作它用,有分隔语法的作用;(2)标识符:表示各种名字;(3)常量:整型、实型、布尔型、字符型;(4)运算符:算术、逻辑、关系运算符;(5)界符:包括,;,(,),:,等等。
扫描器的输出格式:输出格式为二元组序列,每个单词对应一个二元组,形式为(类号,内码)。



【编译原理】第三章词法分析⼀,词法分析器的作⽤词法分析是编译的第⼀阶段。
词法分析器主要任务是读⼊源程序的输⼊字符、将他们组成词素,⽣成并输出⼀个词法单元序列,每个词法单元对应于⼀个词素。
分析部分:词法分析、语法分析(简化编译器设计、提⾼编译器效率、增强编译器可移植性)1)词法单元:词法单元名和可选的属性值组成。
关键字、操作符……2)模式:词法单元词素可能具有的形式,当词法单元是关键字时,模式就是这个关键字的字符序列3)词素:源程序中的⼀个字符序列,它和某个词法单元模式匹配。
4)词法错误:识别出某个错误词素,继续判断下⼀个词素⼆,输⼊缓冲1)我们⾄少向前看⼀个字符,才能判断当前词素是否到头。
2)对付⼤型源程序,需要处理⼤量字符。
处理往往需要很多时间,我们采⽤两个交替读⼊的缓冲区。
(详见73)三,词法单元的规约1)我们会不会⽤完缓冲区?通常对于⽐较长的字符串我们采⽤ ”+“的形式链接起来。
2)正则表达式:letter_(letter_ | digit) * 表⽰字母开头 0个或多个字母或数字3)正则表达式例⼦a |b {a, b}(a | b) (a | b ) {aa, ab, ba, bb}aa | ab | ba | bb {aa, ab, ba, bb}a* 由字母a构成的所有串集(a | b)* 由a和b构成的所有串集复杂的例⼦( 00 | 11 | ( (01 | 10) (00 | 11) * (01 | 10) ) ) * 010011010000100000101110013)正则表达式扩展1>⼀个或多个实例⼀元后缀算符“+”的意思是“⼀个或多个实例”,即正规式a+表⽰⼀个或多个a的所有串的集合。
算符+和算符*有同样的优先级和结合性。
代数恒等式 r* = r+ | 和r+ = rr*表达了这两个算符之间的关系。
2>零个或⼀个实例⼀元后缀算符?的意思是“零个或⼀个实例”,r?是r | 的缩写。