数理统计第四章 方差分析
- 格式:ppt
- 大小:1.31 MB
- 文档页数:31



第一节方差分析的基本思想1、方差分析的意义前述的t检验和u检验适用于两个样本均数的比较,对于k个样本均数的比较,如果仍用t检验或u检验,需比较次,如四个样本均数需比较次。
假设每次比较所确定的检验水准=0.05,则每次检验拒绝H0不犯第一类错误的概率为1-0.05=0.95;那么6次检验都不犯第一类错误的概率为(1-0.05)6=0.7351,而犯第一类错误的概率为0.2649,因而t检验和u检验不适用于多个样本均数的比较。
用方差分析比较多个样本均数,可有效地控制第一类错误。
方差分析(analysis of variance,ANOVA)由英国统计学家R.A.Fisher首先提出,以F命名其统计量,故方差分析又称F检验。
2、方差分析的基本思想下面通过表5.1资料介绍方差分析的基本思想。
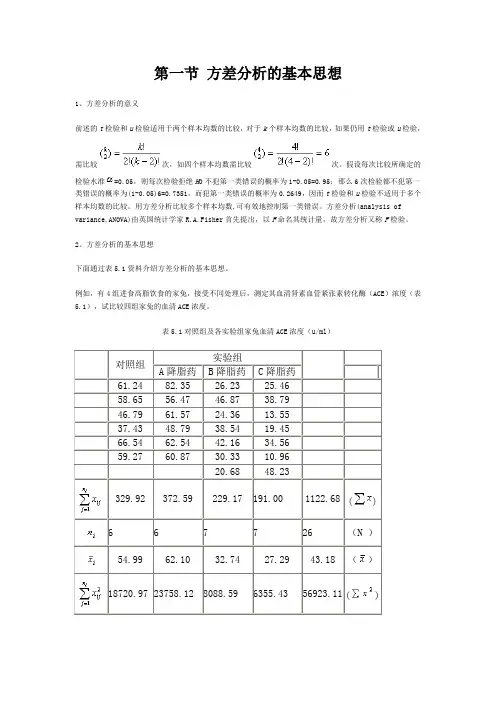
例如,有4组进食高脂饮食的家兔,接受不同处理后,测定其血清肾素血管紧张素转化酶(ACE)浓度(表5.1),试比较四组家兔的血清ACE浓度。
表5.1对照组及各实验组家兔血清ACE浓度(u/ml)对照组实验组A降脂药B降脂药C降脂药61.24 82.35 26.23 25.4658.65 56.47 46.87 38.7946.79 61.57 24.36 13.5537.43 48.79 38.54 19.4566.54 62.54 42.16 34.5659.27 60.87 30.33 10.9620.68 48.23329.92 372.59 229.17 191.00 1122.68 () 6 6 7 7 26 (N )54.99 62.10 32.74 27.29 43.18 ()18720.97 23758.12 8088.59 6355.43 56923.11 ()由表5.1可见,26只家兔的血清ACE浓度各不相同,称为总变异;四组家兔的血清ACE浓度均数也各不相同,称为组间变异;即使同一组内部的家兔血清ACE 浓度相互间也不相同,称为组内变异。







研究生教材《应用数理统计》——课后习题答案详解学号:3113312042姓名:齐以年班级:硕3079班目录第一章数理统计的基本概念 (1)第二章参数估计 (18)第三章假设检验 (36)第四章方差分析与正交试验设计 (46)第五章回归分析 (51)第六章统计决策与贝叶斯推断 (56)对应书目:《应用数理统计》施雨编著西安交通大学出版第一章 数理统计的基本概念1.1 解:∵ 2~(,)X N μσ∴ 2~(,)n X N σμ∴~(0,1)N 分布∴(1)0.95P X P μ-<=<=又∵ 查表可得0.025 1.96u = ∴ 221.96n σ=1.2 解:(1) ∵ ~(0.0015)X Exp∴ 每个元件至800个小时没有失效的概率为:8000.001501.2(800)1(800)10.0015x P X P X e dxe -->==-<=-=⎰∴ 6个元件都没失效的概率为: 1.267.2()P e e --==(2) ∵ ~(0.0015)X Exp∴ 每个元件至3000个小时失效的概率为:30000.001504.5(3000)0.00151x P X e dxe--<===-⎰∴ 6个元件没失效的概率为: 4.56(1)P e -=-1.3解:(1) X ={(x 1,x 2,x 3)|x k =0,1,2,…,k =1,2,3},p (x 1,x 2,x 3)=λx 1+x 2+x 3x 1!x 2!x 3!e −3λ,x k =0,1,2,…;k =1,2,3(2) X ={(x 1,x 2,x 3)|x k ≥0;k =1,2,3},f (x 1,x 2,x 3)=λ3e −λ(x 1+x 2+x 3), x k ≥0;k =1,2,3(3) X ={(x 1,x 2,x 3)|a ≤x k ≤b;k =1,2,3},f (x 1,x 2,x 3)=1(b−a)3, a ≤x k ≤b;k =1,2,3(4) X ={(x 1,x 2,x 3)|−∞<x k <+∞;k =1,2,3}=R 3,f (x 1,x 2,x 3)=1(2π)3/2e −12∑(x k −μ)23k=1,−∞<x k <+∞;k =1,2,31.4 解:ini n x n x ex x x P ni i 122)(ln 2121)2(),.....,(122=--∏∑==πσμσ1.5证:21122)(na a x n x a x n i ni i i +-=-∑∑==∑∑∑===-+-=+-+-=ni i ni i n i i a x n x x na a x n x x x x 1222211)()(2221.6证明 (1) ∵22112211221()()()2()()()()()nnii i i nni i i i ni i XX X X X X X X X n X X X n X μμμμμ=====-=-+-=-+--+-=-+-∑∑∑∑∑(2) ∵2221112221221()22ii i nn ni i i i i ni ni XX X X X nX X nX nX X nX =====-=-+=-+=-∑∑∑∑∑1.7证明:a) 证:)(11111+=+++=∑n n i i n x x n x)(11)(1111n n n n n x x n x x x n n -++=++=++b )证:221111()1nn n i i S x x n ++==-+∑ 221112211121111[()]11121[()()()()]11(1)n n n i n i nn n n n n i i n n i i x x x x n n n x x x x x x x x n n n +=++++===---+++=----+-+++∑∑∑221112112[()()((1))111() ]1n n n n n n n n n nS x x x x nx x n x n n x x n ++++=+---+-+++-+22n122n 11[nS ()] 111[S ()]11n n n n n x x n n n x x n n ++=+-++=+-++ 1.8证明:显然: Zm+n ̅̅̅̅̅̅̅=nX ̅+mY ̅m+nS Z2=1m +n[∑(X i −Z m+n ̅̅̅̅̅̅̅)2n i=1+∑(Y i −Z m+n ̅̅̅̅̅̅̅)2mi=1] =1m +n[∑X i 2ni=1−2Zm+n ̅̅̅̅̅̅̅∗nX ̅+∑Y i 2−2Z m+n ̅̅̅̅̅̅̅∗mY ̅+(m +n)mi=1Zm+n ̅̅̅̅̅̅̅2] 因为: nS X 2=∑X i 2n i=1−nX ̅2 nS Y 2=∑Y i 2n i=1−nY ̅2所以:S Z2=nS X2+nS Y2m+n+1m+n[nX̅2+nY̅2−(nX̅+mY̅)2m+n] =nS X2+nS Y2m+n+m∗n(n+m)2(X̅−Y̅)21.10解:(1).∑∑====niiniixEnxnEXE11)(1)1()(=1n∙n∙mp=mpnpmpxDnxnDXDniinii)1()(1)1()(121-===∑∑==))(1()(122∑=-=niixxnESE)1(1)])1(1())1(([1)])()(())()(([1])()([1])([12222212212212p mp nn p m p mp n n p m p mp n n x E x D n x E x D n x nE x E n x x E n n i i i n i i n i i --=+--+-=+-+=-=-=∑∑∑=== 同理,(2).λ===∑∑==ni i n i i x E n x n E X E 11)(1)1()(λnx D n x n D X D ni ini i 1)(1)1()(121===∑∑==λnn x E x D n x E x D n x nE x E n S E n i i i n i i 1)])()(())()(([1])()([1)(2122122-=+-+=-=∑∑==(3).2)(1)1()(11ba x E n x n E X E n i i n i i +===∑∑==na b x D nx n D X D ni in i i 12)()(1)1()(2121-===∑∑==12)(1)])()(())()(([1])()([1)(22122122a b n n x E x D n x E x D n x nE x E n S E ni i i n i i -⋅-=+-+=-=∑∑==(4).λ===∑∑==ni i n i i x E n x n E X E 11)(1)1()(nx D nx n D X D ni in i i 2121)(1)1()(λ===∑∑==221221221)])()(())()(([1])()([1)(λnn x E x D n x E x D n x nE x E n S E n i i i n i i -=+-+=-=∑∑==(5).μ===∑∑==ni i n i i x E n x n E X E 11)(1)1()(nx D nx n D X D ni in i i 2121)(1)1()(σ===∑∑==221221221)])()(())()(([1])()([1)(σ⋅-=+-+=-=∑∑==nn x E x D n x E x D n x nE x E n S E n i i i n i i1.11 解:由统计量的定义知,1,3,4,5,6,7为统计量,5为顺序统计量 1.12 解:顺序统计量:-4,-2.1,-2.1,-0.1,-0.1,0,0,1.2,1.2,2.01,2.22,3.2,3.21中位数Me=0 极差R=(3.21+4)=7.21 再抽一个样本2.7,则顺序统计量变为:-4,-2.1,-2.1,-0.1,-0.1,0,0,1.2,1.2,2.01,2.22,2.7,3.2,3.21 此时,样本中位数Me=(0+1.2)/2=0.61.13解: F 20x={ 0 , x <0620, 0≪x <11320, 1≪x <21620, 2≪x <31820, 3≪x <41 , x ≫41.14解:利用伽马分布的可加性 X~Γ(α,λ) 则Y =∑X i ~Γ(nα,λ)n i=1X ̅=Y nf Y (y )=λnαy nα−1Γ(nα)e −λy,y >0根据随机变量函数的概率密度公式得:f X ̅(x )=λnα(nx)nα−1Γ(nα)e −λnx∗n =λnαn nαx nα−1Γ(nα)e −λnx ,x >01.15解:运用顺序统计量的概率密度公式 (1) f (m)(x )=n!(m−1)!(n−m )![F (x )]m−1[1−F (x )]n−m f(x) 1≪m ≪n (2) f (k)(j)(x )=n!(k−1)!(j−k−1)!(n−j )![F (x )]k−1[F (y )−F (x )]j−k−1[1−F (y )]n−j f(x)f(y) 1≪k<j ≪n (3) 样本极差R =X (n)−X (1), 其中X (n)和X (1)的概率密度可由(1)得到,再根据函数关系可推出R 的概率密度函数 1.16解:X i −μσ~N(0,1)(X i −μσ)2~χ2(1)故:∑(X i −μσ)2~ni=1χ2(n )1.17 证:),(~ λαΓXx ex x f λαααλ--Γ=∴1)()( 令kXY =ke ky kke ky yf ky ky⋅Γ=⋅Γ=∴----λαααλαααλαλ11)()( )()()(即 ),(~ky Y αΓ1.18 证:),(~ b a X β),()1()( 11b a B x xx f b a ---=∴),(),( ),()1()( 11b a B b k a B b a B x x x X E b a k k +=-=∴⎰∞+∞---),(),1()( b a B b a B X E +=∴ba a ab a b a b a a a a b a b a a a b b a b a b a +=Γ+Γ++ΓΓ=Γ++Γ+Γ+Γ=ΓΓ+Γ⋅++ΓΓ+Γ=)()()()()()()1()()1()()()()1()()1(),(),2()(2b a B b a B X E +=))(1()1()()()()2()()2(b a b a a a a b b a b a b a ++++=ΓΓ+Γ⋅++ΓΓ+Γ= 22)]([)()( X E X E X D -=∴2))(1())(1()1(b a b a ab ba ab a b a a a +++=+-++++=1.19 解:∵ ~(,)X F n m 分布2212(1)022()((1))()(1)()()()(1)()()n n m n mn m yn m y n mn nP Y y P X X y m myP X y n n n x x dx m m m++--+≤=+≤=<-Γ=+ΓΓ⎰2222122221122()()()1()(1)()()11(1)(1)(,)n n m n m n mn m n mf y P Y y y y y y y yy B ++----'=≤Γ=+ΓΓ----=∴ 22(1)(,)n mn n Y X X m mβ=+分布1.20 解:∵ ~()X t n 分布122212()()(()2)n n P Y y P X y P X xdxn ++-≤=≤=≤≤Γ=+112211221212122()()()(1)()1()(1)()()()n n n n n f y P Y y y y n y y n n n+++--+--'=≤Γ=+Γ=+ΓΓ∴ 2~(1,)2nY X F =分布1.21 解: (1) ∵ ~(8,4)X N 分布∴ 4~(8,)25X N 分布,即5(8)~(0,1)2X N - ∴ 样本均值落在7.8~8.2分钟之间的概率为:5(7.88)5(8)5(8.28)(7.88.2)()2220.383X P X P ---≤≤=≤≤=(2) 样本均值落在7.5~8分钟之间的概率为:5(7.58)5(8)5(88)(7.58)()2225(8)(0 1.25)20.3944X P X P X P ---≤≤=≤≤-=≤≤=若取100个样品,样本均值落在7.5~8分钟之间的概率为:10(7.88)10(8)10(8.28)(7.88.2)()2222*(0.84130.5)0.6826X P X P ---≤≤=≤≤=-= 单个样品大于11分钟的概率为:P 1=1−0.9333=0.0667 25个样品的均值大于9分钟的概率为: P 2=1−0.9938=0.0062 100个样品的均值大于8.6分钟的概率为P 3=1−0.9987=0.0013 所以第一种情况更有可能发生1.22 解:μ=2.5 2σ=36 n=5 (1)44302<<s ⇔)955,625(22∈σns 而)1(~222-n ns χσ即 )4(36522χ∈s通过查表可得 P =0.1929(2)样本方差落在30~40的概率为0.1929 样品均值-x 落在1.3~3.5的概率即:P{1.3<-x <3.5} ⇔P{-0.4472<σμ)(--x n <0.3727}又σμ)(--x n ~N(0,1)查标准正态分布表可得:P{1.3<-x <3.5}=0.3179 由于样本均值与样本方差相互独立,故:这样两者同时成立的概率为P =0.1929⨯0.3179=0.06131.23 解:(1) ∵2~(0,)X N σ分布 ∴ 2~(0,)X N nσ分布∴ 22()~(1)nXχσ∵ 22221()()ni i a X an X an σσ===∑∴ 21a n σ=同理 21b m σ= (2) ∵ 2~(0,)X N σ分布 ∴222~(1)X χσ分布由2χ分布是可加性得:2221~()ni i X n χσ=∑()nic X t m ==∑ ∴c =(3) 由(2)可知2221~()ni i X n χσ=∑ 2221122211~(,)nni ii i n mn mi ii n i n X d Xnn dF n m XmXmσσ==++=+=+=∑∑∑∑∴ m d n =1.24证明:X n+1~N(μ,σ2) X̅~N(μ,σ2/n) X n+1−X ̅~N(0,n +1n σ2)X n+1−X̅√n +1nσ2~N(0,1)(n −1)S n∗2σ2~χ2(n −1) 所以:Y =X n+1−X ̅S n ∗√n n +1~t(n −1) 1.25 证明:∵ 211~(,)X N μσ分布∴2211()~(1)i X μχσ-∴ 1221111()~()n i i X n μχσ=-∑同理 2222212()~()n i i Y n μχσ=-∑ 1122222112211111222221122112()()~(,)()()n n i i i i n n i i i i X n n X F n n Y n Y n μσμσμσμσ====--=--∑∑∑∑第二章 参数估计2.1 (1) ∵ ~()X Exp λ分布∴ ()1E X λ=令 ˆ1X λ= 解得λ的矩估计为:ˆ1X λ= (2) ∵ (,)X U a b 分布∴ ()2a bE X +=2()()12b a D X -=令 1ˆˆ2ab A X +==22221ˆˆˆˆ()()1124n i i b a a b A X n =-++==∑ (22211n i i X X S n =-=∑)解得a 和b 的矩估计为:ˆˆaX bX =-=(3) 110()1E X x x dx θθθθ-=*=+⎰令 1ˆˆ1A X θθ==+ ∴ˆ1XXθ=- (4) 110()(1)!kk x kE X x x e dx k βββ--=*=-⎰令 ˆkX β=∴ ˆkXβ=(5) 根据密度函数有2221()22()E X a aE X a λλλ=+=++根据矩估计有1222221ˆˆˆ22ˆˆˆa A X aa A S X λλλ+==++==+解得λ和a 的矩估计为:ˆˆaX λ==(6) ∵ (,)X B m p∴ ()E X mp =令 1ˆmpA X == 解得p 的矩估计为:ˆX pm= 2.2解:(1)X 服从指数分布,λ的似然函数为:L (λ)=λn e −λ∑x i n i=1, x i>0,i =1,2,⋯,nlnL (λ)=nlnλ−λ∑x i ni=1∂lnL (λ)∂λ=nλ−∑x i ni=1解得:λ̂=1x̅(2)f (x )=1b−a,a <x <b似然函数为:L (a,b )=1(b −a)n,a <x i <b显然:a ̂=X (1) b ̂=X (n) (3)f (x )={θ x θ−1 ,0<x <10, 其他似然函数为:L (θ)=θn ∗∏x i θ−1ni=1,0<x i <1lnL (θ)=nlnθ+(θ−1)∑lnx i ni=1∂lnL (θ)∂θ=nθ+∑lnx i ni=1=0 解得:θ̂=−n ∑lnx in i=1(4) f (x )={βk(k−1)!x k−1e −βx ,x >00, x ≤0似然函数为:L (β)=(βk(k −1)!)n ∗∏x i k−1ni=1∗e −β∑x i n i=1 ,x i >0 i =1,2,⋯,n lnL (β)=nk ∗lnβ−n ∗ln (k −1)!+(k −1)∑lnx i ni=1−β∑x i ni=1∂lnL (β)∂β=nkβ−∑x i ni=1=0解得:θ̂=−kx̅(5) f (x )={λ x −λ(x−a),x >a 0, x ≤a似然函数为:L (a,λ)=λn x −λ∑(x i ni=1−a) ,x i >a,i =1,2,⋯,nlnL (a,λ)=n ∗lnλ−λ∑x i ni=1+nλa ∂lnL (a,λ)∂λ=nλ−∑(x i ni=1−a)=0 解得:a ̂=X (1) , λ̂=−1X ̅−X (1)(6) X~B(m , P)P {X =k }=(m k)P k(1−P)m−k ,k =0,1,⋯,m似然函数为:L (p )=(m k)n P ∑xi n i=1(1−P)∑(m−x i )n i=1,x i =0,1,2,⋯,nlnL (p )=n ∗ln (mk)+∑x i n i=1∗lnp +∑(m −x i )ni=1∗ln (1−p)∂lnL (p )∂p=∑x in i=1p−∑(m −x i )n i=11−p=0解得:p ̂=−X̅m2.3解:∵ X 服从几何分布,其概率分布为:1()(1)k P X k p p -==-故p 的似然函数为: 1()(1)ni i x nnL p p p =-∑=-对数似然函数为:1ln ()ln ()ln(1)ni i L p n p x n p ==+--∑令 1ln ()1()01nii L p n x n p p p=∂=--=∂-∑ ∴ 1ˆpX= 2.4 解:由题知X 应服从离散均匀分布,⎪⎩⎪⎨⎧≤≤==其它01 1)(Nk N k x pE (X )=N+12矩估计: 令N ̂+12=710 ∴N̂=1419 极大似然估计:⎪⎩⎪⎨⎧≤≤=其它07101 1)(NN N L要使)(N L 最大,则710=N710=∴∧N2.5 解:由题中等式知:2196.196.196.1)025.01(025.0)(1S X +=+=∴+=+-Φ=∴=-Φ-∧∧∧-σμθσμμσθσμθ2.6 解:(1) 05.009.214.2=-=R0215.005.04299.05=⨯==∴∧d Rσ(2)将所有数据分为三组如下所示:0197.005.03946.005.0)05.005.005.0(316=⨯==∴=++=∴∧d R R σ 2.7 解:(1)⎩⎨⎧+<<=其它 01x 1)(θθx f θθθθθθ≠+==+=++=∴∧21)()(2121)(X E E X E ∴ X =∧θ不是θ的无偏估计,偏差为21=-∧θθ(2) θ=-)21(X E 21-=∴∧X θ是θ的无偏估计(3) 22))(()())(()(θθθθ-+=-+=∧∧X E X D E D M S E41121+=n 2.8 证:由例2.24,令2211x a x a +=∧μ,则∧μ 为μ无偏估计应 满足121=+a a因此1μ,2μ,3μ都是μ的无偏估计)()()()(21)()(2513)()(95)9491)(()())(()()(1233212221212∧∧∧∧∧∧=∧<<===+=∴+==∑μμμμμμμD D D X D D X D D X D X D D a a X D X D a D i i i2132121X X +=∴∧μ最有效2.9 证: )(~λp X λλ==∴)( )(X D X EX 是λ=)(X E 的无偏估计,2*S 是λ=)( X D 的无偏估计 )()1()())1((2*2*S E X E S X E αααα-+=-+∴λλααλ=-+=)1(∴ 2*)1(SX αα-+是λ的无偏估计2.10 解:因为2222((1))()(1)()(1)()1(1)()11(1)1E X S E X E S na E S n n a E S n n n a n nααααλαλαλαλλ**+-=+-=+--=+---=+-=- 所以 2(1)X S αα*+-是λ的无偏估计量2.11证明:X~P (λ)假设T(X 1)为θ=e −2λ的无偏估计,即: E[T(X 1)]= θ, E [T (X1)]=∑T (X )∞x=0∗λx x!e−λ=e −2λ=∑T (X )∞x=0∗λx x!=e−λ=∑(−λ)xx!∞x=0=∑(−1)x λx x!∞x=0(泰勒展开)所以T (X 1)=(−1)X 1是θ=e −2λ的唯一无偏估计。