编译 第三章 语法分析
- 格式:ppt
- 大小:681.00 KB
- 文档页数:65




编译原理第三章练习题答案编译原理第三章练习题答案编译原理是计算机科学中的重要课程之一,它研究的是将高级语言程序转化为机器语言的过程。
在编译原理的学习过程中,练习题是提高理解和应用能力的重要途径。
本文将为大家提供编译原理第三章的练习题答案,希望能够对大家的学习有所帮助。
1. 什么是词法分析?请简要描述词法分析的过程。
词法分析是编译过程中的第一个阶段,它的主要任务是将源程序中的字符序列划分为有意义的词素(token)序列。
词法分析的过程包括以下几个步骤:1)扫描:从源程序中读取字符序列,并将其转化为内部表示形式。
2)识别:根据预先定义的词法规则,将字符序列划分为不同的词素。
3)分类:将识别出的词素进行分类,如关键字、标识符、常量等。
4)输出:将分类后的词素输出给语法分析器进行进一步处理。
2. 什么是正则表达式?请给出一个简单的正则表达式示例。
正则表达式是一种用于描述字符串模式的工具,它由一系列字符和操作符组成。
正则表达式可以用于词法分析中的词法规则定义。
以下是一个简单的正则表达式示例:[a-z]+该正则表达式表示匹配一个或多个小写字母。
3. 请简要描述DFA和NFA的区别。
DFA(Deterministic Finite Automaton)和NFA(Nondeterministic Finite Automaton)是有限状态自动机的两种形式。
它们在词法分析中常用于构建词法分析器。
DFA是一种确定性有限状态自动机,它的状态转换是确定的,每个输入符号只能对应一个状态转换。
相比之下,NFA是一种非确定性有限状态自动机,它的状态转换是非确定的,每个输入符号可以对应多个状态转换。
4. 请简要描述词法分析器的实现过程。
词法分析器的实现过程包括以下几个步骤:1)定义词法规则:根据编程语言的语法规范,定义词法规则,如关键字、标识符、常量等。
2)构建正则表达式:根据词法规则,使用正则表达式描述不同类型的词素。
3)构建有限状态自动机:根据正则表达式,构建DFA或NFA来识别词素。


编译原理第三版课后习题答案编译原理是计算机科学中的一门重要课程,它研究的是如何将高级程序语言转换为机器语言的过程。
而《编译原理》第三版是目前被广泛采用的教材之一。
在学习过程中,课后习题是巩固知识、提高能力的重要环节。
本文将为读者提供《编译原理》第三版课后习题的答案,希望能够帮助读者更好地理解和掌握这门课程。
第一章:引论习题1.1:编译器和解释器有什么区别?答案:编译器将整个源程序转换为目标代码,然后一次性执行目标代码;而解释器则逐行解释源程序,并即时执行。
习题1.2:编译器的主要任务是什么?答案:编译器的主要任务是将高级程序语言转换为目标代码,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等过程。
第二章:词法分析习题2.1:什么是词法分析?答案:词法分析是将源程序中的字符序列划分为有意义的词素(token)序列的过程。
习题2.2:请给出识别下列词素的正则表达式:(1)整数:[0-9]+(2)浮点数:[0-9]+\.[0-9]+(3)标识符:[a-zA-Z_][a-zA-Z_0-9]*第三章:语法分析习题3.1:什么是语法分析?答案:语法分析是将词法分析得到的词素序列转换为语法树的过程。
习题3.2:请给出下列文法的FIRST集和FOLLOW集:S -> aAbA -> cA | ε答案:FIRST(S) = {a}FIRST(A) = {c, ε}FOLLOW(S) = {$}FOLLOW(A) = {b}第四章:语义分析习题4.1:什么是语义分析?答案:语义分析是对源程序进行静态和动态语义检查的过程。
习题4.2:请给出下列文法的语义动作:S -> if E then S1 else S2答案:1. 计算E的值2. 如果E的值为真,则执行S1;否则执行S2。
第五章:中间代码生成习题5.1:什么是中间代码?答案:中间代码是一种介于源代码和目标代码之间的表示形式,它将源代码转换为一种更容易进行优化和转换的形式。

编译原理第三章练习题答案编译原理第三章练习题答案编译原理是计算机科学中的重要学科,它研究的是如何将高级语言代码转化为机器语言的过程。
在编译原理的学习过程中,练习题是不可或缺的一部分,通过完成练习题可以更好地理解和掌握编译原理的知识。
本文将为大家提供编译原理第三章练习题的答案,希望对大家的学习有所帮助。
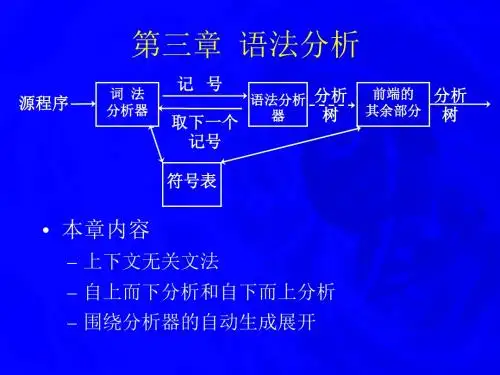
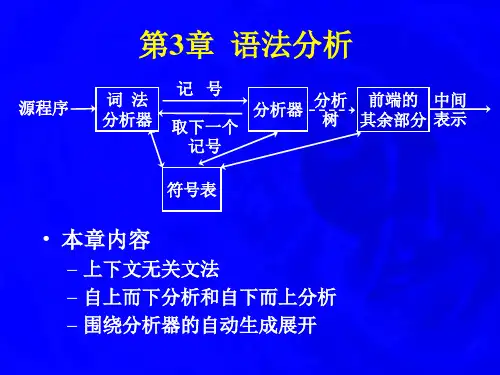
1. 什么是语法分析?语法分析是编译器中的一个重要模块,它的主要任务是根据给定的语法规则,对输入的源代码进行分析和解释。
语法分析器会根据语法规则构建一个语法树,用于表示源代码的结构和含义。
常用的语法分析方法有递归下降法、LL(1)分析法和LR分析法等。
2. 什么是LL(1)文法?LL(1)文法是一种特殊的上下文无关文法,它具有以下两个特点:(1) 对于任何一个句子,最左推导和最右推导是唯一的。
(2) 在预测分析过程中,只需要向前看一个输入符号就可以确定所采用的产生式。
LL(1)文法是一种常用的文法形式,它适用于递归下降法和LL(1)分析法。
3. 什么是FIRST集合和FOLLOW集合?FIRST集合是指对于一个文法符号,它能够推导出的终结符号的集合。
FOLLOW 集合是指在一个句型中,某个非终结符号的后继终结符号的集合。
计算FIRST集合和FOLLOW集合可以帮助我们进行语法分析,特别是LL(1)分析。
4. 什么是递归下降语法分析法?递归下降语法分析法是一种基于产生式的自顶向下的语法分析方法。
它的基本思想是从文法的开始符号开始,递归地根据产生式进行分析,直到推导出输入符号串或发现错误。
递归下降语法分析法的实现比较简单,但对于某些文法可能会出现回溯现象,影响分析效率。
5. 什么是LR分析法?LR分析法是一种自底向上的语法分析方法,它的基本思想是从输入符号串开始,逐步构建语法树,直到推导出文法的开始符号。
LR分析法具有较好的分析效率和广泛的适用性,常用的LR分析方法有LR(0)、SLR(1)、LR(1)和LALR(1)等。


《编译原理》教学大纲一、课程概述编译原理是计算机科学与技术专业的一门重要课程,也是软件工程领域的基础课程之一、本课程通过对编译器的原理和实现技术的学习,使学生掌握编译器的设计和实现方法,培养学生独立解决实际问题的能力。
二、教学目标1.理解编译器的基本原理和工作流程;2.掌握常见编译器的构建方法和技术;3.能够设计和实现简单的编译器;4.培养分析和解决实际问题的能力。
三、教学内容和教学进度1.第一章:引论1.1编译器的定义和分类1.2编译器的基本工作流程2.第二章:词法分析2.1编译器的基本结构2.2词法单元的定义和识别方法2.3正则表达式和有限自动机3.第三章:语法分析3.1语法分析的基本概念3.2语法规则的定义和表示方法3.3自顶向下的语法分析方法3.4自底向上的语法分析方法4.第四章:语义分析4.1语义分析的基本概念4.2属性文法和语法制导翻译4.3语义动作和符号表管理5.第五章:中间代码生成5.1中间代码的定义和表示方法5.2基本块和控制流图5.3三地址码的生成方法6.第六章:优化6.1优化的基本概念和原则6.2常见的优化技术和方法6.3编译器的优化策略7.第七章:目标代码生成7.1目标代码生成的基本原理7.2目标代码的表示方法和存储管理7.3基本块的划分和目标代码生成算法8.第八章:附加主题8.1解释器和编译器的比较8.2面向对象语言的编译8.3并行编译和动态编译四、教学方法1.理论教学与实践相结合,注重教学案例的分析和实践;2.引导学生主动探索,注重培养学生的自主学习能力;3.激发学生的兴趣,鼓励学生提问和讨论。
五、考核方式1.平时成绩:包括课堂测验、作业和实验报告等;2.期末考试:闭卷笔试,主要考查学生对编译原理的理论知识和实践能力的掌握程度。
六、参考教材1.《编译原理与技术》(第2版),龙书,机械工业出版社,2024年2.《现代编译原理-C语言描述》(第2版),谢路云,电子工业出版社,2024年七、参考资源1. 实验环境:Dev-C++、gcc、llvm等2.相关网站:编译原理教学网站、编译器开源项目等八、教学团队本课程由计算机科学与技术学院的相关教师负责教学,具体安排详见教务处发布的教学计划。
编译原理第三版答案编译原理是计算机科学中非常重要的一门课程,它涉及到程序设计语言的语法、语义和编译器的设计与实现等内容。
《编译原理》(Compilers: Principles, Techniques, and Tools)是编译原理领域的经典教材,由Alfred V. Aho、Monica S. Lam、Ravi Sethi和Jeffrey D. Ullman合著,已经出版了三个版本。
本文将针对《编译原理》第三版中的习题和答案进行整理和总结,以帮助学习者更好地理解和掌握编译原理相关知识。
第一章,引论。
1.1 什么是编译器?编译器是一种将源程序翻译成目标程序的程序,它包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等阶段。
1.2 编译器的主要任务是什么?编译器的主要任务是将高级语言程序翻译成等价的目标程序,同时保持程序的功能和性能。
1.3 编译器的结构包括哪些部分?编译器的结构包括前端和后端两部分,前端包括词法分析、语法分析和语义分析,后端包括中间代码生成、代码优化和目标代码生成。
第二章,词法分析。
2.1 什么是词法分析?词法分析是编译器中的第一个阶段,它将源程序中的字符序列转换成单词(Token)序列。
2.2 词法分析的主要任务是什么?词法分析的主要任务是识别源程序中的单词,并将其转换成单词符号表中的标识符。
2.3 词法分析中常见的错误有哪些?词法分析中常见的错误包括非法字符、非法注释、非法标识符等。
第三章,语法分析。
3.1 什么是语法分析?语法分析是编译器中的第二个阶段,它将词法分析得到的单词序列转换成抽象语法树。
3.2 语法分析的主要任务是什么?语法分析的主要任务是识别源程序中的语法结构,并检查语法的正确性。
3.3 语法分析中常见的错误有哪些?语法分析中常见的错误包括语法错误、缺失分号、缺失括号等。
第四章,语义分析。
4.1 什么是语义分析?语义分析是编译器中的第三个阶段,它对源程序的语义进行分析和处理。
编译原理教程第五版课后答案第一章:引言问题1答:编译器是一种将高级编程语言源代码转换为目标机器代码的软件工具。
它由多个阶段组成,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和代码生成等。
问题2答:编译器的主要任务包括以下几个方面: - 词法分析:将源代码划分为词法单元,如标识符、关键字、操作符等。
- 语法分析:根据语法规则,将词法单元组成语法树。
- 语义分析:对语法树进行语义检查,如类型匹配、变量声明等。
- 中间代码生成:将语法树转换为中间代码表示形式。
- 代码优化:对中间代码进行优化,以提高程序的效率。
- 代码生成:将优化后的中间代码转换为目标机器代码。
第二章:词法分析问题1答:词法单元是编译器在词法分析阶段识别的最小的语法单位,它由一个或多个字符组成。
常见的词法单元包括关键字、标识符、常量和运算符等。
问题2答:识别词法单元的方法包括以下几种: - 正则表达式:通过正则表达式匹配字符串,识别出各类词法单元。
- 有限自动机:构建有限状态自动机,根据输入字符的不同状态转移,最终确定词法单元。
- 递归下降法:使用递归下降的方式,根据语法规则划分出词法单元。
第三章:语法分析问题1答:语法分析是编译器的一个重要阶段,它的主要任务是根据给定的语法规则,将词法单元序列转换为语法树。
语法分析有两个主要的方法:自顶向下的分析和自底向上的分析。
问题2答:自顶向下的分析是从文法的起始符号开始,根据语法规则逐步向下展开,直到生成最终的语法树。
常见的自顶向下的分析方法包括LL(1)分析和递归下降分析。
问题3答:自底向上的分析是从输入串开始,逐步合并词法单元,最终生成语法树。
常见的自底向上的分析方法包括LR分析和LALR分析。
第四章:语义分析问题1答:语义分析的主要任务是对语法树进行语义检查和类型推断。
语义分析阶段会检查变量的声明和使用是否合法,以及类型是否匹配等。
问题2答:常见的语义错误包括变量未声明、类型不匹配、函数调用参数不匹配等。