第3章 语法分析1
- 格式:ppt
- 大小:2.32 MB
- 文档页数:52


编译原理第三章练习题答案编译原理第三章练习题答案编译原理是计算机科学中的重要课程之一,它研究的是将高级语言程序转化为机器语言的过程。
在编译原理的学习过程中,练习题是提高理解和应用能力的重要途径。
本文将为大家提供编译原理第三章的练习题答案,希望能够对大家的学习有所帮助。
1. 什么是词法分析?请简要描述词法分析的过程。
词法分析是编译过程中的第一个阶段,它的主要任务是将源程序中的字符序列划分为有意义的词素(token)序列。
词法分析的过程包括以下几个步骤:1)扫描:从源程序中读取字符序列,并将其转化为内部表示形式。
2)识别:根据预先定义的词法规则,将字符序列划分为不同的词素。
3)分类:将识别出的词素进行分类,如关键字、标识符、常量等。
4)输出:将分类后的词素输出给语法分析器进行进一步处理。
2. 什么是正则表达式?请给出一个简单的正则表达式示例。
正则表达式是一种用于描述字符串模式的工具,它由一系列字符和操作符组成。
正则表达式可以用于词法分析中的词法规则定义。
以下是一个简单的正则表达式示例:[a-z]+该正则表达式表示匹配一个或多个小写字母。
3. 请简要描述DFA和NFA的区别。
DFA(Deterministic Finite Automaton)和NFA(Nondeterministic Finite Automaton)是有限状态自动机的两种形式。
它们在词法分析中常用于构建词法分析器。
DFA是一种确定性有限状态自动机,它的状态转换是确定的,每个输入符号只能对应一个状态转换。
相比之下,NFA是一种非确定性有限状态自动机,它的状态转换是非确定的,每个输入符号可以对应多个状态转换。
4. 请简要描述词法分析器的实现过程。
词法分析器的实现过程包括以下几个步骤:1)定义词法规则:根据编程语言的语法规范,定义词法规则,如关键字、标识符、常量等。
2)构建正则表达式:根据词法规则,使用正则表达式描述不同类型的词素。
3)构建有限状态自动机:根据正则表达式,构建DFA或NFA来识别词素。
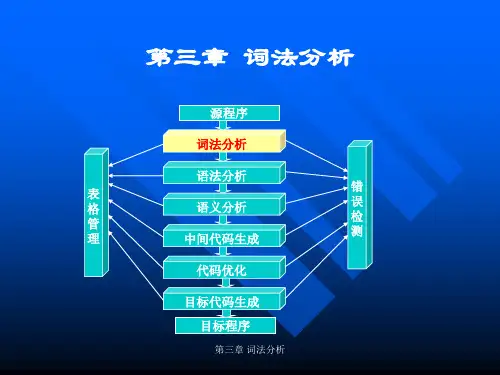

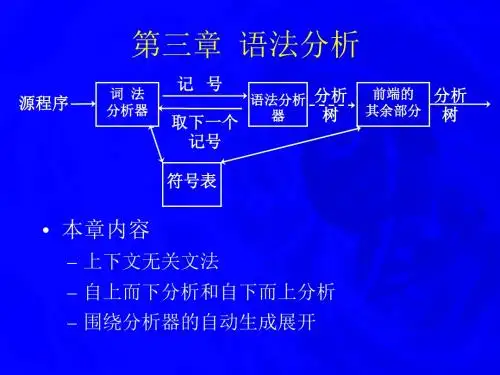
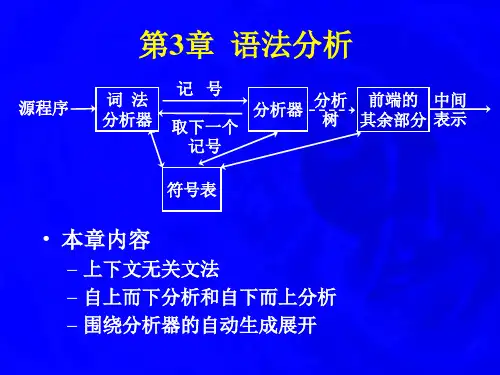
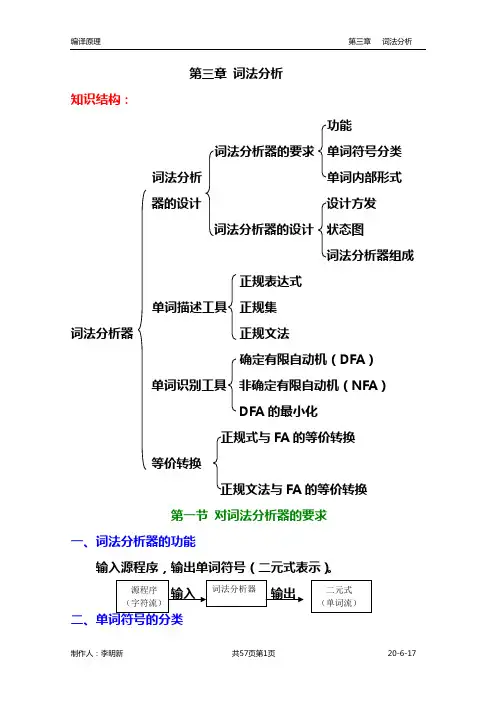
第三章 词法分析知识结构:功能 词法分析器的要求 单词符号分类 词法分析 单词内部形式器的设计 设计方发词法分析器的设计 状态图词法分析器组成正规表达式单词描述工具 正规集词法分析器 正规文法确定有限自动机(DFA )单词识别工具 非确定有限自动机(NFA )DFA 的最小化FA 的等价转换等价转换FA 的等价转换第一节 对词法分析器的要求一、词法分析器的功能输入源程序,输出单词符号(二元式表示)。
关键字:是由程序语言定义的具有固定意义的标识符。
标识符:用来表示各种名字,如变量等。
常数:常数的类型有整型,实型等。
运算符:算术运算符,关系运算符,逻辑运算符。
界限符:逗号,分号等。
三、单词符号内部的表示形式内部的单词符号TOKEN字(二元式),TOKEN字占用机器字的长度,依据信息量的多少而定。
1、TOKEN字结构CLASS:用整数表示。
VALUE:表示单词符号的属性(符号表指针)。
2、TOKEN的作用CLASS:用于语法分析器对源程序结构的分析。
VALUE:用于语义分析器对源程序具体操作的分析。
3、单词种别码划分原则CLASS:关键字,运算符,界限符(编译程序定义的符号)使用一字一种编码。
VALUE值省略。
VALUE:标识符,常数(用户定义的符号),存放符号表常数表的指针。
标识符,常数每一类为一种编码。
例:BEGIN A:= B END;词法分析结果:符号表(BEGIN,---- )Array(A ,K1 ) K1(:= ,--- )(B ,K3 ) K3(END ,--- )(;,--- )四、词法分析器的结构1、一遍扫描(交互式结构)。
2、多遍扫描(独立式结构)。
第二节词法分析器的设计一、设计步骤1、确定词法分析器的接口关系;2、确定单词分类和TOKEN字的结构;3、对每一类单词构造状态转换图;4、根据状态转换图设计算法。
二、功能描述1、组织源程序输入;2、按词法规则拼读单词符号,并转换成二元式;3、删除注解行,空格和无用符号;4、检查词法错误。




初中语法第三单元教案一、教学目标1. 让学生掌握第三单元的语法知识点,包括现在进行时、一般过去时和一般将来时。
2. 培养学生运用这些时态进行交际的能力。
3. 提高学生对英语语法的兴趣,培养他们的学习积极性。
二、教学内容1. 现在进行时:表示正在进行的动作或状态。
2. 一般过去时:表示过去发生的动作或状态。
3. 一般将来时:表示将来会发生的动作或状态。
三、教学重点与难点1. 重点:现在进行时、一般过去时和一般将来时的结构及用法。
2. 难点:如何正确运用这些时态进行交际。
四、教学方法1. 任务型教学法:通过完成各种任务,让学生在实践中学习和运用语法知识。
2. 情境教学法:创设各种情境,让学生在真实的环境中感受和理解语法知识。
3. 互动式教学法:鼓励学生积极参与,师生互动,共同探讨语法问题。
五、教学步骤1. 导入:通过图片或情景引入本节课的语法知识点。
2. 呈现:用PPT或黑板展示现在进行时、一般过去时和一般将来时的结构及用法。
3. 讲解:详细讲解每个时态的构成、意义和用法,并通过例句进行说明。
4. 练习:让学生进行不同类型的练习,如填空、选择、改写句子等,以巩固所学知识。
5. 互动:分组进行角色扮演或对话练习,让学生在实际语境中运用所学时态。
6. 总结:对本节课的语法知识点进行归纳和总结,强调重点和难点。
7. 作业:布置相关的家庭作业,让学生进一步巩固所学知识。
六、教学评价1. 课堂参与度:观察学生在课堂上的积极性、主动性和合作精神。
2. 练习正确率:检查学生练习题的正确率,了解他们对语法知识的掌握程度。
3. 交际运用:评估学生在角色扮演或对话中的语法运用情况,鼓励创新和灵活运用。
通过以上教学设计,希望能够帮助学生更好地掌握第三单元的语法知识点,提高他们的英语水平。
同时,注重培养学生的学习兴趣和积极性,使他们能够在愉快的氛围中学习英语。
《编译原理第三版》(选择题)详解第一章绪论【解答】(1) 编译程序可以将用高级语言编写的源程序转换成与之在逻辑上等价的目标程序,而目标程序可以是汇编语言程序或机器语言程序。
故选A。
(2) 分多遍完成编译过程可使整个编译程序的逻辑结构更加清晰。
故选B。
(3) 构造编译程序应掌握源程序、目标语言和编译方法这三方面内容。
故选D。
(4) 编译各阶段的工作都涉及到构造、查找或更新有关表格,即编译过程的绝大部分时间都用在造表、查表和更新表格的事务上。
故选D。
(5) 由(1)可知,编译程序实际上实现了对高级语言程序的翻译。
故选D。
第二章词法分析【解答】(1) 由教材第一章1.3节中的词法分析,可知词法分析所遵循的是语言的构词规则。
故选B。
(2) 词法分析器的功能是输入源程序,输出单词符号。
故选B。
(3) 词法分析器输出的单词符号通常表示为二元式:(单词种别,单词自身的值)。
故选B。
(4) 由S→xSx | y可知该文法所识别的语言一定是:y左边出现的x与y 右边出现的x相等。
故选C。
(5) 虽然选项A、B、D都满足题意,但选项D更准确。
故选D。
(6) 3型文法即正规文法,它的识别系统是有限状态自动机。
故选C。
(7) NFA可以有DFA与之等价,即两者描述能力相同;也即,对于任一给定的NFA M,一定存在一个DFA M',使L(M)=L(M′)。
故选B。
(8) DFA便于识别,易于计算机实现,而NFA便于定理的证明。
故选C。
(9) 本题虽然是第二章的题,但答案参见第三章3.1.3节。
即选C。
第三章语法分析【解答】(1) 参见第四章4.1.1节,语义分析不像词法分析和语法分析那样可以分别用正规文法和上下文无关文法描述,由于语义是上下文有关的,因此语义分析须用上下文有关文法描述。
即选B。
(2) 2型文法对应下推自动机。
故选C。
(3) 由于不存在:3型语言 2型语言 1型语言 0型语言。
故选D。
(4) 最左简单子树的末端结点组成的符号串为句柄。