landmark属性提取方法与技术
- 格式:doc
- 大小:303.50 KB
- 文档页数:4

LandMark 地震解释及油藏描述一体化方案兰德马克公司的地震解释及油藏描述一体化解决方案,是利用OpenWorks 数据平台,把大量丰富的地震数据,地球物理测井数据,研究地区的地质信息有机地结合在一起,通过共享于OpenWorks 数据平台上的各种应用软件,使各个领域的专家可灵活、方便地对这些不同类型的数据实现多学科协同解释。
油田地处地质构造复杂、构造幅度变化大,岩性、岩相变化快,逆断层发育的柴达木盆地。
本着从油田勘探开发生产工作的实际出发,并结合该地区的地质构造特点,兰德马克公司提出了如下具有针对性的地震解释及油藏描述解决方案。
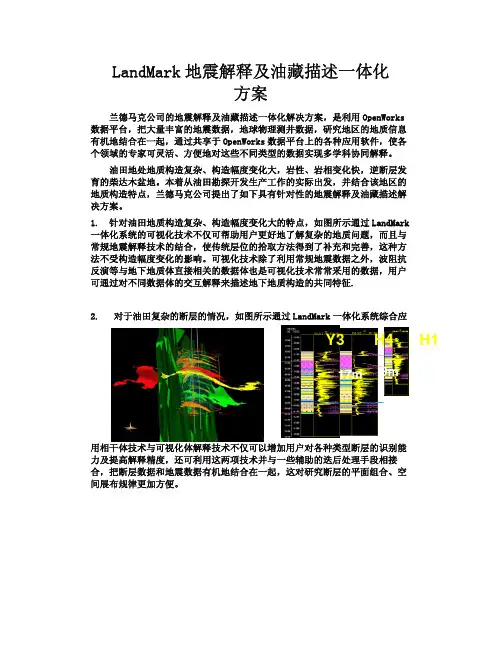
1. 针对油田地质构造复杂、构造幅度变化大的特点,如图所示通过LandMark 一体化系统的可视化技术不仅可帮助用户更好地了解复杂的地质问题,而且与常规地震解释技术的结合,使传统层位的拾取方法得到了补充和完善,这种方法不受构造幅度变化的影响。
可视化技术除了利用常规地震数据之外,波阻抗反演等与地下地质体直接相关的数据体也是可视化技术常常采用的数据,用户可通过对不同数据体的交互解释来描述地下地质构造的共同特征.2. 对于油田复杂的断层的情况,如图所示通过LandMark 一体化系统综合应用相干体技术与可视化体解释技术不仅可以增加用户对各种类型断层的识别能力及提高解释精度,还可利用这两项技术并与一些辅助的迭后处理手段相接合,把断层数据和地震数据有机地结合在一起,这对研究断层的平面组合、空间展布规律更加方便。
Y3H4H19marthCubeComplex Faulting Ex.3复杂断裂带相干体中的断层显示E arthCubeC om plex FaultingEx.3Surface visualization on ESP is used to trace fault plans复杂断裂带相干体中的自动断层追踪3. 对于复杂的岩性、岩相变化问题,如图所示通过LandMark 一体化系统可通过可视化技术浏览其岩性、岩相的空间变化规律,对这些有意义的研究对象进行自动体标识并对其标识结果进行层位转换输出;同时还可将标识好的目标体输出为*.3dv 文件,为井间小层对比提供岩性变化依据。



Landmark软件培训手册目录一、数据加载(GeoDataLoading) (3)1、建立投影系统 (6)2、建立OpenWorks数据库 (6)3、加载钻井平面位置和地质分层(pick) (6)4、加载钻井垂直位置、时深表、测井曲线和合成地震记录 (9)二、常规解释流程(SeisWorks、TDQ、ZmapPlus) (15)1、SeisWorks解释模块的功能 (16)(1)、三维震工区中常见的文件类型 (16)(2)、用HrzUtil对层位进行管理 (17)2、TDQ时深转换模块 (18)(1)、建速度模型 (18)①、用OpenWorks的时深表做速度模型 (18)②、用速度函数做速度模型 (19)③、用数学方程计算ACSII速度函数文件 (21)(2)、时深(深时)转换 (22)(3)、速度模型的输出及其应用 (28)(4)、基准面的类型 (29)(5)、如何调整不同的基准面 (30)3 、ZmapPlus地质绘图模块 (30)(1)、做图前的准备工作 (32)(2)、用ASCII磁盘文件绘制平面图 (32)(3)、用SeisWorks解释数据绘制平面图................................. (33)(4)、网格运算 (37)(5)、井点处深度校正 (37)三、合成记录制作(Syntool) (37)1 、准备工作 (37)2 、启动Syntool (37)3 、基准面信息 (38)4 、子波提取 (39)5 、应用Checkshot (41)6 、合成地震记录的存储 (44)7 、SeisWelll (45)四、迭后处理/属性提取、聚类分析(PostStack/PAL、Rave (50)1、数据处理模块 (52)2 、相似性预测 (60)(1)、Fscan 相似性分析原理 (61)(2)、导致不相似的因素.... .. (62)3 、属性提取 (63)4 、储层特征可视化与油气预测技术 (73)(1)、数据输入................ .. (74)①、ASCII文件的输入 (74)②、OpenWorks井数据的输入 (74)③、SeisWorks Horizons数据的输入 (75)④、回归模型的输入 (76)(2)、数据分析................ .. (77)五、分频解释(SpecDecomp) (82)1 、分频技术的原理.............................................................. .. (82)2 、分频技术的特点 (83)3 、应用 (84)附:OpenWorks数据库的有关知识 (86)1 、关系数据库的概念………....………………………………………… ..862 、数据库的备份 (87)3 、OpenWorks的文件数据及外设………....…………………………… ..89(1)、用户管理及环境变量 (83)(2)、外部数据文件的存放 (91)(3)、磁带机的配置 (91)一、数据加载(GeoDataLoading)(一)、建立投影系统下面以建立TM投影系统为例:图 (1-4-4e )(二)、建立OpenWorks数据库(三)、加载钻井平面位置和地质分层(Pick)加载的钻井数据类型:钻井平面位置、地质分层、时深表、井轨迹、测井曲线、合成地震记录等。

dlib的landmark算法摘要:一、dlib 简介1.dlib 的背景和作用2.dlib 的主要模块和功能二、landmark 算法概述ndmark 算法的定义ndmark 算法的作用和应用三、dlib 中的landmark 算法实现1.dlib 中的landmark 算法原理2.dlib 中的landmark 算法流程3.dlib 中的landmark 算法应用示例四、landmark 算法与其他算法的比较ndmark 算法与传统特征点匹配算法的比较ndmark 算法与深度学习算法的比较五、dlib 的landmark 算法在实际应用中的优势和局限1.dlib 的landmark 算法在实际应用中的优势2.dlib 的landmark 算法在实际应用中的局限正文:一、dlib 简介dlib 是一个开源的计算机视觉库,它包含了大量的图像处理和计算机视觉方面的算法。
这些算法被广泛应用于人脸识别、物体识别、姿态估计、文本识别等领域。
dlib 库提供了丰富的函数和接口,方便开发人员快速实现图像处理和计算机视觉方面的功能。
dlib 的主要模块包括:1.特征提取模块:包括HOG、LBP、LRE 等特征提取算法。
2.分类器模块:包括SVM、Ridge、Lasso 等分类器算法。
3.物体检测模块:包括基于深度学习的物体检测算法。
4.姿态估计模块:包括基于关键点和基于轮廓的的姿态估计算法。
5.文本识别模块:包括基于模板匹配和基于深度学习的文本识别算法。
二、landmark 算法概述landmark 算法是一种用于人脸关键点定位的方法。
它通过定位面部特征点,如眼睛、鼻子、嘴巴等,来确定人脸的姿态和形状。
landmark 算法可以用于人脸识别、人脸跟踪、表情识别等领域。
landmark 算法的主要步骤如下:1.提取图像特征:通过提取图像中的特征点,如眼睛、鼻子、嘴巴等,来确定人脸的位置和姿态。
2.建立模型:通过训练模型,来学习特征点和人脸姿态之间的关系。
LandMark——Pal/PostStack软件介绍流程工作流程如下:1、首先启动ow2003,启动命令为:startow2、键入口令,如:123453、窗口中显示了ow2003的主窗口4、打开如下菜单:5、点击图上模块6、出现7、打开,选择工区,并且激活poststack esp和pal两项选项。
点击8、选择解释员后,出现窗口选择选择工区内的地震数据,选择重新键入新的输出地震名,在图上位置区域内按MB3(鼠标右键),出现,9、增益:选择第一项增益10、滤波:选择第二项选择滤波方式11、反褶积:选择第三项进行反褶积计算12、三瞬:选择,选择三瞬,即瞬时相位,瞬时频率,瞬时振幅。
13、选择合适的处理方法后,需要选择相应的参数,如图中显示位置点MB1出现参数选项,选择合适的参数,然后按OK。
其他处理方法如同。
14、最后选择菜单中的RUN按扭,运行。
此时可以检测程序的运行情况,点击主菜单中的job------下面的view进行查看。
到这里叠后处理中的反褶积,滤波,增益,三瞬就讲完了。
接下来介绍地震资料的相干处理和地震资料的属性提取:14、相干处理,仍然在上面的主菜单中选择第10项的,选择一种相干方式,现举一例进行演示,如然后点击鼠标MB1参数选项,出现参数菜单,选择好分析时窗方式后,选取层位和合适的时窗,键入输出名,选择扫描模式之后,点击ok按扭。
回到主菜单,RUN。
15、属性提取:选择菜单中的第8项后,在上按鼠标MB1,选择分析时窗方式,选取层位和合适的时窗,然后选择提取的地震资料的属性参数,包括有:(1)振幅类属性常用的振幅类属性有:1):2)Average Absolute Amplitude 平均绝对振幅:此外,还包括了3)、、、、4)::::::::(2)复地震道统计类:复地震道包括5种属性,1)2)在复地震道计算中,瞬时频率是相位随时间的变化率,或者说是相位的导数。
实际计算时,先算出瞬时频率道,然后计算时窗内的平均值。

![Landmark软件培训手册part[2]](https://uimg.taocdn.com/311ab02852d380eb62946dae.webp)
(一)、PostStack 数据处理模块重采样(二)、相似性预测1、Fscan相似性分析原理2、导致不相似的因素3、Fscan 3D(三)、属性提取下面将PAL提取的39种属性分成5类加以说明:该属性对振幅变化非常敏感。
,它比能量半衰时更敏感。
(四)、储层特征可视化与油气预测技术1、数据准备File下。
如图:(1)、ASCII文件的输入(2)、OpenWorks 井数据在完成上图的操作后,可对RA VE表进行替代、扩展和合并,如下图:值的平均。
(3)、SeisWorks Horizon(s) 地震解释层位和属性参数多种参数。
面上。
(4)、回归模型的输入(2)、数据分析本部分比较重要,包括对属性的数学运算,聚类,回归分析,相似性计算,2D,3D交会图及群类的映射等。
交互性能及可视化手段极大地提高了上述操作的效率和精度。
数据分析在RA VE种分成两部分,Edit和View。
下面分别介绍各菜单项的功能:①、2D Crossplot(Histogram)。
②、3D Crossplot✧3D交会图的旋转通过旋转不同的角度,可以分离出多属性的聚群特征,从而找出有意义的聚类群。
✧特征群圈定与映射如下图所示✧从已知井预测。
✧其他辅助功能③2D Matrix ……2D 交会图阵列出现如下窗口:④各参数间的相关系数列于下图中:用户只需点击相关系数表,即可得到两属性的2D 交会图,从而检查参数间的实际相关程度。
⑤ Summary Statistics 统计参数概括,出现如下窗口:⑥属性运算 明了。
⑦ Subsets ……子集操作 ⑧Model ……模型回归分析⑨……聚类分析分频技术基于如下的概念,即来自薄层的反射在频率域具有指示时间地层厚度的特征性表现。
例如,一个简单的各向同性的薄层能把可预测的、具有周期性的带陷序列引入到复合反射的振幅谱中。
如下图(5-1、5-2):分类数量图 5-1 薄层频谱干涉模式短时窗分析,由于时窗内只包括几个薄层反射界面,这时的反射系数序列Rt 不再是随机的,振幅谱中由于薄层顶底反射界面的干涉结果出现了频陷,这代表地质体局部变化的特点。

自己总结的属性提取步骤(LANDMARK OpenWorks 2003.12.1.2)一、层位管理(删除)进入Startow后,Data——→Management——→Seismic Project Manager——→Horizons——→HrzUtil——→用List选择要管理的项目数据——→选择Horizon Choise List 里面的要删除的项目——→Add to List——→Delete——→……——→Quit二、解释层加密Applications——→Seisworks——→3D或者3D3D工区——→Session——→Open 平面图和地震剖面图——→在地震剖面菜单上选择Horizons——→Interpolate——→Input List 选择要加密的层——→Output List 选择(或Create)一个层名,注意后面的“Minimum”改成“Maximum”——→选择Spatial——→下面的Filter Size 改成“5”(只是一个经验值,可以变化)——→左下角Interpolate,即完成一个层的加密,加密后的文件名即为新的加密层。
可以连续做多个层的加密。
三、属性提取在OpenWorks菜单选择Applications——→PostStack/PAL——→3D——→List 选择数据体——→把PostStack ESP 和PAL 都选中——→Launch…(可能等待时间稍长)——→OutPut Data…什么都不选——→Input Data…——→SeisWorks Seismic 后面的Parameters——→Input Files 用List选择数据体——→OK(一般默认参数不变)——→OK——→Processes——→Attribute Maps(PAL) ——→Standard Maps——→窗口中间的Parameters…(出现PAL Attribute Maps)——→选中Horizontal Interval 下面的Paramerters…——→选择要提取属性层的顶、底——→OK——→在Output Horizon Prefix里面输入提取属性的成果文件名(相当于层名文件)——→一般做“Amplitude Statistics”的“RMS Amplitude”和“Complex Trace Statistics”的“Average Reflection Strength”——→右下角Options…——→选中Normalize Values(最小最大值用1和1000即可)——→OK——→选中Clear Existing Output Horizons——→OK——→Run在运行期间可以监视运行过程,如果发现错误,也可以知道哪里出现的错误。
充分利用LandMark 软件的一体化优势SeisWorks 中解释的层位和断层可以在StratWorks进行显示, 然后你以此为基础进行地质解释.以层位为例,步骤如下:1. 将解释的层位通过作图的办法来求取网格数据, 可在SeisWorks中的Map it 完成, 也可以在ZMAP中通过point gridding plus 求得网格数据.2. 将此网格数据写入数据库, 从SeisWorks中MAP VIEW-mapping file write to database.3. 如果在ZMAP中,你可以直接将网格数据写入数据库中:或用file—copy, 将MFD 中的网格写入数据库。
注意确保是StratWorks要用的同一个OW project.4. 将此数据文件进行时深转化,用TDQ或depth-team,因为StratWorks 中显示的是深度域的数据。
而且它是以海拔0为基准面的,如果你是用其他数据进行的时深转化,而不是用T0网格数据,那末,切记要将你的数据转化为以海拔0为基准面的数据,即你将调用的层位数据应是负数。
再者,该层位网格数据必须在数据库中。
5. 在StratWorks中cross-section - overlay –surface grid intersections下选择相应的数据文件,OK。
6. 与此同时,你还激活该属性所属的SURFACE:cross-section-file—setup—surface active list.7. display cross-secion ,这是你就能看到在SeisWorks中解释的层位。
8. 那末以下你就可以根据地震解释的构造层位指导你的地质解释了。
9. 但是值得注意的是地质解释的结果放在surface grid segments选项里。
关于DepthTeam-Express它的最大优点是它建立速度模型时能够根据构造层进行插值,而且可以逐级标定,直到与地质分层相匹配,那末,用这样的速度模型进行时深转化时,最终的构造层与井点处的分层数据应该是完全吻合的,从而可以省掉许多后期作图时繁琐的校正工作。
Landmarc的基本算法流程1. 简介Landmarc是一个用于绘制地理标记的算法,它可以根据给定的地理坐标数据,在地图上生成标记物。
该算法的基本流程包括数据预处理、特征提取、标记生成和结果输出四个主要步骤。
本文将详细介绍每个步骤的具体操作。
2. 数据预处理数据预处理是Landmarc算法的第一步,其目的是将原始的地理坐标数据进行处理和清洗,以提高后续步骤的准确性和效果。
数据预处理的主要步骤包括:2.1 数据清洗数据清洗是为了去除无效或冗余的地理坐标数据。
通常会对数据进行去重、去噪和异常值处理等操作,以确保数据的准确性和有效性。
2.2 数据格式转换有些地理坐标数据可能以不同的格式存在,如经纬度、UTM坐标等。
为了方便后续的处理,需要将所有数据转换为统一的格式。
2.3 数据分割如果数据集较大,可以考虑将数据分割为多个子集进行处理,以提高算法的运行效率。
3. 特征提取特征提取是Landmarc算法的核心步骤,其目的是从经纬度数据中提取有用的特征信息,以便生成地理标记。
常用的特征提取方法包括:3.1 距离特征距离特征是根据地理坐标之间的距离计算得到的,可以表示两个地点之间的相对位置关系。
常见的距离特征包括欧氏距离、曼哈顿距离等。
3.2 方向特征方向特征是根据地理坐标之间的方向计算得到的,可以表示两个地点之间的朝向关系。
常见的方向特征包括角度、方位角等。
3.3 地理特征地理特征是根据地理坐标所对应的地理实体属性进行提取的,如海拔高度、地形等。
可以通过地理信息系统(GIS)等工具获取这些信息。
3.4 统计特征统计特征是对一组地理坐标数据进行统计分析得到的,可以反映数据的聚类程度、分布规律等。
常见的统计特征包括平均值、方差、标准差等。
4. 标记生成标记生成是Landmarc算法的关键步骤,其目的是根据提取的特征信息,在地图上生成地理标记。
标记生成的具体方法取决于应用场景和需求,常用的方法包括:4.1 地理聚类地理聚类是将具有相似特征的地理坐标点聚集在一起,形成一个地理标记。
属性提取可以帮助解释员验证解释结果的正确性和充分认识工区的地质情况。
属性提取工作比较烦杂,并具有相当强的经验性。
一、选择地震数据体Command Menu——Applications——Poststack/PAL弹出窗口。
图7-1Project Type选择“3D”;选择所建立的地震工区mbs;在Product Selection的选项中,选择所有项。
点击Launch弹出窗口,如图7-2。
点击Input Data按钮――在B窗口中选择SeisWorks Seismic――点击Parameters――进入C窗口――选择所要输入的三维地震数据体(例如mig,其他各项可用默认设置)。
OK.。
图7-2进行属性提取时,将Output Data 项设为空。
图7-3二、属性选择Processes――Attribute Extraction;点击Attribute Extraction的Parameters,进行属性的选择。
建议选择所有B窗口中的Attribute Selection的项;以及各属性项后Options列出的子项。
键入Output Horizon Prefix输出层位的前缀名(任意)。
图7-4图7-5图7-6OK――Run。
此时所有的的属性数据便产生了。
三、显示、编辑属性属性生成之后以层位的形式存在。
进入SeisWorks/Map View窗口。
View――Contents。
弹出Map View Contents窗口。
在层列表中选择生成的属性文件。
OK。
效果如图7-8所示。
图 7-7。
Landmarc的基本算法Landmarc是一种基于地标的定位算法,用于在没有GPS信号的室内环境中确定用户的位置。
该算法使用了计算机视觉和机器学习的技术,在建筑物内部的地标点上建立了一个视觉地图,并利用这个地图来确定用户的位置。
1. 概述Landmarc的基本算法包括以下几个主要步骤:1.建立视觉地图:通过收集建筑物内部的视觉数据,包括图像和深度信息,利用计算机视觉技术建立一个视觉地图。
这个地图包含了建筑物内部的各种地标点,比如门、窗户、柱子等。
2.特征提取:从视觉数据中提取特征点,这些特征点具有鲁棒性和独特性,可以用来匹配和识别地标点。
3.匹配与识别:利用特征点匹配算法,在视觉地图和实时图像之间进行匹配,识别出用户所处的地标点。
4.位置推测:根据用户所处的地标点,通过一系列推理过程来估计用户的位置。
下面将详细介绍每个步骤的原理和具体实现方法。
2. 建立视觉地图建立视觉地图的过程可以分为两个主要步骤:数据采集和地标点提取。
2.1 数据采集为了建立视觉地图,需要在建筑物内部采集大量的视觉数据。
可以使用RGB-D摄像头,如Microsoft Kinect,在建筑物的各个位置拍摄图像,并获取深度信息。
2.2 地标点提取从采集到的视觉数据中提取地标点是建立视觉地图的关键步骤。
常用的方法是使用特征点提取算法,如SIFT(尺度不变特征变换)或ORB(Oriented FAST and Rotated BRIEF)算法。
这些算法可以从图像中提取出具有鲁棒性和独特性的特征点。
3. 特征提取特征提取是Landmarc算法中的核心步骤,它用于从实时图像中提取特征点,并与视觉地图中的地标点进行匹配。
常用的特征提取算法有SIFT和ORB算法。
这些算法可以在图像中检测到关键点,并计算这些关键点的描述子。
这些描述子具有鲁棒性和独特性,可以用于匹配和识别地标点。
4. 匹配与识别在Landmarc算法中,匹配和识别是利用特征点进行的,目标是将实时图像中的特征点与视觉地图中的地标点进行匹配和识别。