李克特量表ppt课件
- 格式:ppt
- 大小:396.50 KB
- 文档页数:9

伦西斯·利克特 [Rensis Likert 1903.08.05-1981.09.03]美国教育家和组织心理学家。
他出生于美国怀俄明州夏延(Cheyenne),逝于美国密歇根州安阿伯(Ann Arbor)。
他的父亲是一名工程师。
利克特早先就读于密歇根大学,起初学的是工程学,但最后却在 1922 年获得了社会学和经济学专业的文学士学位。
后来在哥伦比亚大学学习,1932 年获得心理学博士学位,其里程碑式的学位论文《态度测量方法》发表于《心理学档案》杂志。
这篇学位论文成为利克特量表的基础(利克特量表是社会学家们的一种标准工具)。
在密歇根大学期间,他和简(Jane Gibson)相识,并于几年后在他攻读博士期间结婚,婚后他们有两个女儿。
1930-1935 年,利克特任纽约大学心理学教授,之后在康涅狄格州哈特福德任人寿保险机构管理研究协会董事,在此期间,他采用面谈和书面问答的形式对 10 家最佳的和 10 家最差的保险公司进行了比较研究,其研究结果发表在《信心与机构管理》(与 J.M.威利茨合著)丛书中。
这项研究为他后来继续开展组织领导问题的研究打下了基础。
1939 年,利克特受聘于农业经济局下属位于华盛顿的计划调查处,在该处工作时他发展了谈话、编码和取样调查等方法,成为当今社会基础。
第二次世界大战期间,他在战时情报处工作,研究公众态度、公众体验和公众行为等课题。
他与爱荷华州立大学合作研究制定了一套家庭取样调查的方法,即人们现在所知的概率取样调查。
他还与其他人一起对战争债券、外国侨民和战时轰炸的影响等开展了广泛的研究。
1946 年,利克特受密歇根大学之邀,为该校建立了社会调查研究中心。
不久,该中心与后来增加的三个中心一起合并为社会研究所,利克特担任该所所长,一直到他 1970 年退休为止。
在此期间,他出版了两本主要著作:《新型的管理》和《人类组织》,他的管理理论在日本极受欢迎,影响波及近代日本各地组织。


李克特量表10 量表(李克特量表、迦特曼量表、⾊斯頓量表、語意差異法)(⼀)李克特量表1.由⼀套態度項⽬構成,假設每⼀項⽬具有同等的態度數值,根據受試者反應同意與不同意的程度給予分數,所有項⽬分數的總合即為個⼈的態度分數,這個分數的⾼低即代表個⼈在量表上或連續函數上的位置,以⽰同意或不同意的程度。
2.因素量表可含不同構⾯,為多元量表,李克特亦屬於因素量表之⼀。
3.李克特量表即五點或七點尺度,但無六點尺度。
若採六點尺度則以六點量表稱之。
(⼆)Thurstone Differential Scale(差異量表)1.以等距表現法來編製⼀個測量態度差異的量表。
先由研究者列出許多題⽬,其次,由許多專家(⼀般50⼈以上)對這些項⽬評估。
計算每⼀題的四分位差及中位數。
例如:對每⼀題⽬同意程度分為11等,共對三個代表性的等級給予命名(⾮常喜歡、無所謂、⾮常不喜歡),以形成相對稱的區間。
2.四分位差太⼤,表⽰題⽬太過模糊不清,不適合放⼊最後的量表。
中位數類似的題⽬,可增加問卷的信度,因⽽可以重覆選⽤。
(三)古得曼量表譜(Guttman Scalogram)1.⼀組題⽬的題項所反應的態度都集中在某⼀⽅向上,可推估個⼈在某題⽬上是回答正向或負向。
2.為累計量表的⼀種。
3.嘗試建⽴⼀個同屬性的量表,較適⽤於評量⾼度結構化的⾏為特性,如組織層級等。
(四)語意差別法(Semantic Differential, SD)1.⽬的是想了解受測者對事物的認知程度。
2.假設事物的含意可具有多層⾯的意義,這些特質層⾯的空間,稱為語意空間。
⽽本法即是由⼀組題⽬所組成,每個題⽬皆由⼆極化的反應所組成,由受測者針對某個概念在每⼀題項上評估。


关于乐购(鞍山店)的意见调查李克特量表
社会发展学院
124班
李庆开
学号:16
请对下列看法发表意见
下面是对乐购(鞍山店,)的一些不同意见,请指出您对这些意见同意或不同意的程度:1=非常不同意、2=不同意、3=无所谓、4=同意、5=非常同意。
(请在对应数字上打钩)
非常不同意不同意无所谓同意非常同意
1)价格变动大 1 2 3 4 5
2)我喜欢在乐购买东西 1 2 3 4 5
3)提供足够的品牌选择 1 2 3 4 5
4)商品信用制度很差 1 2 3 4 5
5)出售商品种类很多 1 2 3 4 5
6)商品价格公道 1 2 3 4 5
7)购物环境很舒适 1 2 3 4 5
8)货架商品摆放不合理 1 2 3 4 5
9)出售的蔬菜质量差 1 2 3 4 5
10)工作人员服务质量差 1 2 3 4 5
11)结账等候时间过长 1 2 3 4 5
12)促销活动多 1 2 3 4 5
13)购物停车不方便 1 2 3 4 5
14)购物班车不方便 1 2 3 4 5
15)营业时间短 1 2 3 4 5
16)食品及时更新 1 2 3 4 5
谢谢合作
谢谢合作分辨力计算。
伦西斯·利克特 [Rensis Likert 1903.08.05-1981.09.03]美国教育家和组织心理学家。
他出生于美国怀俄明州夏延(Cheyenne),逝于美国密歇根州安阿伯(Ann Arbor)。
他的父亲是一名工程师。
利克特早先就读于密歇根大学,起初学的是工程学,但最后却在 1922 年获得了社会学和经济学专业的文学士学位。
后来在哥伦比亚大学学习,1932 年获得心理学博士学位,其里程碑式的学位论文《态度测量方法》发表于《心理学档案》杂志。
这篇学位论文成为利克特量表的基础(利克特量表是社会学家们的一种标准工具)。
在密歇根大学期间,他和简(Jane Gibson)相识,并于几年后在他攻读博士期间结婚,婚后他们有两个女儿。
1930-1935 年,利克特任纽约大学心理学教授,之后在康涅狄格州哈特福德任人寿保险机构管理研究协会董事,在此期间,他采用面谈和书面问答的形式对 10 家最佳的和 10 家最差的保险公司进行了比较研究,其研究结果发表在《信心与机构管理》(与 J.M.威利茨合著)丛书中。
这项研究为他后来继续开展组织领导问题的研究打下了基础。
1939 年,利克特受聘于农业经济局下属位于华盛顿的计划调查处,在该处工作时他发展了谈话、编码和取样调查等方法,成为当今社会基础。
第二次世界大战期间,他在战时情报处工作,研究公众态度、公众体验和公众行为等课题。
他与爱荷华州立大学合作研究制定了一套家庭取样调查的方法,即人们现在所知的概率取样调查。
他还与其他人一起对战争债券、外国侨民和战时轰炸的影响等开展了广泛的研究。
1946 年,利克特受密歇根大学之邀,为该校建立了社会调查研究中心。
不久,该中心与后来增加的三个中心一起合并为社会研究所,利克特担任该所所长,一直到他 1970 年退休为止。
在此期间,他出版了两本主要著作:《新型的管理》和《人类组织》,他的管理理论在日本极受欢迎,影响波及近代日本各地组织。

李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法;李克特量表的编制方法是由李克特Rensis A.Likert于1932年提出来的;量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句;这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个或七个等级;例如:十分同意、同意、未定、不同意、十分不同意;第二步:把所有语句分为积极态度的语句例如“这个品牌很合我的口味”和消极态度的语句例如“这个品牌冷冰冰的”这两类;对这两类语句的答案所给的分数不同;积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分;第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分;第四步:选择有鉴别力的语句,组成正式量表;选择语句的方法通常有两种:平均值差数法和内在一致法;平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组;求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准;差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除;入选语句即可组成量表;内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏;如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关;相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选;相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除;依照此法,对每一语句加以筛选,最后所有入选语句即可组成一个量表;量表制成后,其使用方法是:让应答者对每一语句作答复,然后转换成分数,并累加起来,这样就可以得到每一位应答者的态度分数,把所有应答者的得分平均起来,则可得出受调查者对该评价对象的总体态度;如果这些受调查者具有代表性,则可以推论出一般消费者的态度;在该量表中,被测试者对这些问题的态度不再是简单的同意或不同意两类,而是将赞成度分为若干类,范围从非常赞成到非常不赞成,中间为中性类,由于类型增多,人们在态度上的差别就能充分体现出来;另外,由于比较简单,被测试者完成起来也较为节省时间;因此,李克特量表是从事意见或态度研究较受欢迎、最常使用的一种量表之一;。

李克特L I K E R T五分量表法(总1页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选。

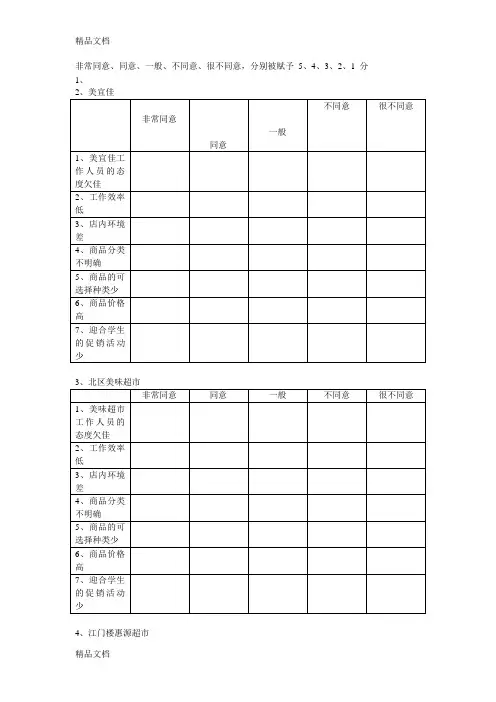
非常同意、同意、一般、不同意、很不同意,分别被赋予5、4、3、2、1 分1、
2、美宜佳
非常同意
同意一般
不同意很不同意
1、美宜佳工
作人员的态
度欠佳
2、工作效率
低
3、店内环境
差
4、商品分类
不明确
5、商品的可
选择种类少
6、商品价格
高
7、迎合学生
的促销活动
少
3、北区美味超市
非常同意同意一般不同意很不同意1、美味超市
工作人员的
态度欠佳
2、工作效率
低
3、店内环境
差
4、商品分类
不明确
5、商品的可
选择种类少
6、商品价格
高
7、迎合学生
的促销活动
少
4、江门楼惠源超市
非常同意同意一般不同意很不同意1、惠源超市
工作人员的
态度欠佳
2、工作效率
低
3、店内环境
差
4、商品分类
不明确
5、商品的可
选择种类少
6、商品价格
高
7、迎合学生
的促销活动
少。

10 量表(李克特量表、迦特曼量表、色斯頓量表、語意差異法)(一)李克特量表1.由一套態度項目構成,假設每一項目具有同等的態度數值,根據受試者反應同意與不同意的程度給予分數,所有項目分數的總合即為個人的態度分數,這個分數的高低即代表個人在量表上或連續函數上的位置,以示同意或不同意的程度。
2.因素量表可含不同構面,為多元量表,李克特亦屬於因素量表之一。
3.李克特量表即五點或七點尺度,但無六點尺度。
若採六點尺度則以六點量表稱之。
(二)Thurstone Differential Scale(差異量表)1.以等距表現法來編製一個測量態度差異的量表。
先由研究者列出許多題目,其次,由許多專家(一般50人以上)對這些項目評估。
計算每一題的四分位差及中位數。
例如:對每一題目同意程度分為11等,共對三個代表性的等級給予命名(非常喜歡、無所謂、非常不喜歡),以形成相對稱的區間。
2.四分位差太大,表示題目太過模糊不清,不適合放入最後的量表。
中位數類似的題目,可增加問卷的信度,因而可以重覆選用。
(三)古得曼量表譜(Guttman Scalogram)1.一組題目的題項所反應的態度都集中在某一方向上,可推估個人在某題目上是回答正向或負向。
2.為累計量表的一種。
3.嘗試建立一個同屬性的量表,較適用於評量高度結構化的行為特性,如組織層級等。
(四)語意差別法(Semantic Differential, SD)1.目的是想了解受測者對事物的認知程度。
2.假設事物的含意可具有多層面的意義,這些特質層面的空間,稱為語意空間。
而本法即是由一組題目所組成,每個題目皆由二極化的反應所組成,由受測者針對某個概念在每一題項上評估。
李克特LIKERT五分量表法李克特量表法是运用一个编制好的量表来测量人们对广告、产品等对象的态度的方法。
李克特量表的编制方法是由李克特(Rensis A.Likert)于1932年提出来的。
量表的编制过程可分为以下四个步骤:第一步:拟定若干条关于态度对象的语句。
这些语句所表达态度的倾向有积极的和消极的两个方面,每一语句的答案相同,均为五个(或七个)等级。
例如:十分同意、同意、未定、不同意、十分不同意。
第二步:把所有语句分为积极态度的语句(例如“这个品牌很合我的口味”)和消极态度的语句(例如“这个品牌冷冰冰的”)这两类。
对这两类语句的答案所给的分数不同。
积极态度语句的给分方法是:十分同意5分,同意4分,未定3分,不同意2分,十分不同意1分;消极语句的给分方法恰好相反:十分同意1分,同意2分,未定3分,不同意3分,十分不同意4分。
第三步:选定若干受调查者,要求他们针对态度,依据自己的看法,就所列出的每一语句一一评分。
第四步:选择有鉴别力的语句,组成正式量表。
选择语句的方法通常有两种:平均值差数法和内在一致法。
平均值差数法是先将应答者对每一句话所做的答案换成分数,然后将所有应答者按其总分由高到低顺序排列,截取最高分数端的25%为高分组,最低分数端的25%为低分组。
求出这两个组中每一语句的平均值,并以高低分组的平均值之差作为语句筛选的标准。
差值大者说明该语句的区分能力强,则入选;差值小者,说明语句区分度差,则剔除。
入选语句即可组成量表。
内在一致法是将各答应者的总分排列成一栏,将某一语句的分数排列为另外一栏。
如果语句的数量较多,直接求这两列数据的等级相关,如果语句数量不多,把应答者的总分分别减去该语句的得分,而后求等级相关。
相关系数大者则表示应答者对该语句的态度与总态度相一致,因此语句入选。
相反,如果相关系数小,说明该语句的态度与总态度缺乏一致性,则该语句剔除。
依照此法,对每一语句加以筛选,最后所有入选语句即可组成一个量表。