Eview60 手把手教你用eviews做panel模型(详细)
- 格式:ppt
- 大小:675.00 KB
- 文档页数:49


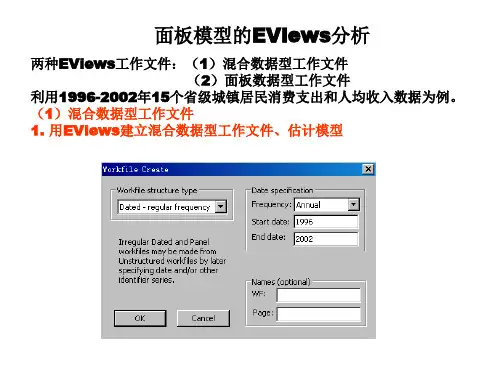
EViews 6.0在面板数据模型估计中的实验操作1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯2、建立面板数据工作文件workfile(1)最好不要选择EViews默认的blanaced panel 类型Moren_panel(2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件3、建立pool对象(1)新建对象(2)选择新建对象类型并命名(3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。
建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图关闭建立的pool对象,它就出现在当前工作文件中。
4、在pool对象中建立面板数据序列双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表)在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。
例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。
展开表(类似excel)中等待你输入、贴入数据。
(1)打开编辑(edit)窗口(2)贴入数据(3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验选择单位根检验设置单位根检验单位根检验结果注意检验方法和两种检验的零假设:Null: Unit root (assumes common unit root process)各截面有相同的单位根Null: Unit root (assumes individual unit root process)允许各截面有不同单位根其中,Levin, Lin & Chu t*检验拒绝含有单位根的零假设,即拒绝非平稳7、在pool窗口对面板数据组合进行协整检验选择进行协整检验协整检验设置对话框,注意有3种检验方法(test type)协整检验结果,同样要注意两种假定(含有AR,即含有单位根,非协整),两种零假设都是非协整,小概率事件发生拒绝非协整。
1.已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002CONSUMEAH 3607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52CONSUMEBJ 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6CONSUMEFJ 4248.47 4935.95 5181.45 5266.69 5638.74 6015.11 6631.68CONSUMEHB 3424.35 4003.71 3834.43 4026.3 4348.47 4479.75 5069.28CONSUMEHLJ 3110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08CONSUMEJL 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88CONSUMEJS 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6CONSUMEJX 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32CONSUMELN 3493.02 3719.91 3890.74 3989.93 4356.06 4654.42 5342.64CONSUMENMG 2767.84 3032.3 3105.74 3468.99 3927.75 4195.62 4859.88CONSUMESD 3770.99 4040.63 4143.96 4515.05 5022 5252.41 5596.32CONSUMESH 6763.12 6819.94 6866.41 8247.69 8868.19 9336.1 10464CONSUMESX 3035.59 3228.71 3267.7 3492.98 3941.87 4123.01 4710.96CONSUMETJ 4679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96CONSUMEZJ 5764.27 6170.14 6217.93 6521.54 7020.22 7952.39 8713.08表9.2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002INCOMEAH 4512.77 4599.27 4770.47 5064.6 5293.55 5668.8 6032.4INCOMEBJ 7332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92INCOMEFJ 5172.93 6143.64 6485.63 6859.81 7432.26 8313.08 9189.36INCOMEHB 4442.81 4958.67 5084.64 5365.03 5661.16 5984.82 6679.68INCOMEHLJ 3768.31 4090.72 4268.5 4595.14 4912.88 5425.87 6100.56INCOMEJL 3805.53 4190.58 4206.64 4480.01 4810 5340.46 6260.16INCOMEJS 5185.79 5765.2 6017.85 6538.2 6800.23 7375.1 8177.64INCOMEJX 3780.2 4071.32 4251.42 4720.58 5103.58 5506.02 6335.64INCOMELN 4207.23 4518.1 4617.24 4898.61 5357.79 5797.01 6524.52INCOMENMG 3431.81 3944.67 4353.02 4770.53 5129.05 5535.89 6051INCOMESD 4890.28 5190.79 5380.08 5808.96 6489.97 7101.08 7614.36INCOMESH 8178.48 8438.89 8773.1 10931.64 11718.01 12883.46 13249.8INCOMESX 3702.69 3989.92 4098.73 4342.61 4724.11 5391.05 6234.36INCOMETJ 5967.71 6608.39 7110.54 7649.83 8140.5 8958.7 9337.56INCOMEZJ 6955.79 7358.72 7836.76 8427.95 9279.16 10464.67 11715.6表9.3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996 1997 1998 1999 2000 2001 2002PAH 109.9 101.3 100 97.8 100.7 100.5 99PBJ 111.6 105.3 102.4 100.6 103.5 103.1 98.2PFJ 105.9 101.7 99.7 99.1 102.1 98.7 99.5PHB 107.1 103.5 98.4 98.1 99.7 100.5 99PHLJ 107.1 104.4 100.4 96.8 98.3 100.8 99.3PJL 107.2 103.7 99.2 98 98.6 101.3 99.5PJS 109.3 101.7 99.4 98.7 100.1 100.8 99.2PJX 108.4 102 101 98.6 100.3 99.5 100.1PLN 107.9 103.1 99.3 98.6 99.9 100 98.9PNMG 107.6 104.5 99.3 99.8 101.3 100.6 100.2PSD 109.6 102.8 99.4 99.3 100.2 101.8 99.3PSH 109.2 102.8 100 101.5 102.5 100 100.5PSX 107.9 103.1 98.6 99.6 103.9 99.8 98.4PTJ 109 103.1 99.5 98.9 99.6 101.2 99.6PZJ 107.9 102.8 99.7 98.8 101 99.8 99.1(1)建立面板数据工作文件首先建立工作文件。




Panel Data模型的EViews操作过程两种模式:Ⅰ. 关于Panel工作文件;Ⅱ. 关于Pool对象。
数据的预处理1.在EXCEL文件中,将每个变量各年的原始数据按照年份顺序排成一列,称之为堆积数据(见表“数据-年份”)。
2.输入截面单元的标识(表示地区的符号,前面加_;如:_HB、_NMG等)。
3.将数据按照地区分类(即按地区排序,见表“数据-地区”)。
Ⅰ. 关于Panel工作文件的操作过程案例1:我国农村居民消费函数(2000-2010年,27个省市数据,工作文件:NXF)一、输入数据1、创建Panel工作文件选择File / New / Workfile,在出现的创建工作文件对话框中:(1)在文件结构类型中,选择“平衡面板(Balanced Panel)”;(2)输入起始、终止期,截面单元个数。
2.更改截面标识(如果取默认的截面标示,此步可以省略)序列crossid 中是以数字1、2、…标记截面标识,为了便于区分,可以重新定义一个字符串序列。
(1)点击object / New object ,选择series Alpha 并输入序列名(设为dq ); (2)双击dq 序列,在打开的序列窗口中粘贴截面标识的字符串序列;(3)双击工作文件窗口中的Range ,在弹出的对话框中,将截面标识的的ID 序列改成新的标识序列:dq3.输入数据键入命令:DATA Y X ,然后用复制+粘贴方式从Excel 文件中将各个变量的堆积数据(注意:数据事先要按照截面单元堆积,本例中是按照“地区”)复制到工作文件之中;此时工作文件中各个变量都是堆积数据。
工作文件中将生成分别表示截面标识和时期标识的两个序列:Crossid — 截面标识 dateid — 时期标识二、模型估计过程1.估计混合模型直接在命令窗口键入命令:LS Y C X2.估计变截距模型在方程窗口中点击Estimate按钮,在弹出的方程描述框中选择Panel Options选项卡,此时可以在截面和时期列表中选择None、Fixed、Random,用来选择单因素(或双因素)固定效应、随机效应变截距模型;同时可以选择GMM、GLS、SUR等估计方法。
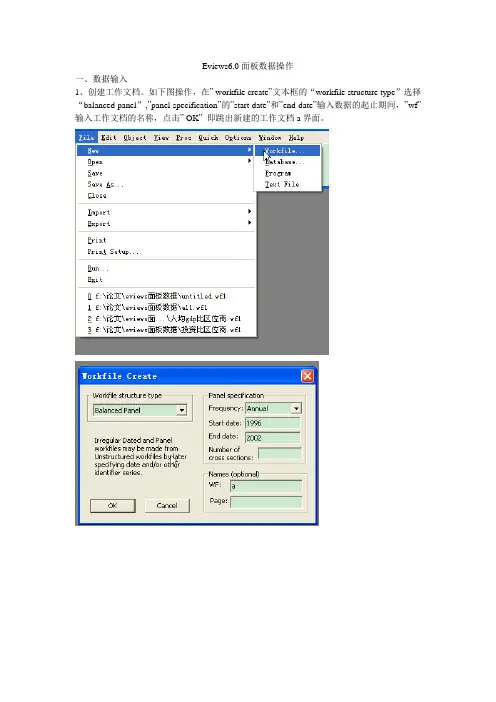
Eviews6.0面板数据操作一、数据输入1、创建工作文档。
如下图操作,在” workfile create”文本框的“workfile structure type”选择“balanced panel”,”panel specification”的”start date”和”end date”输入数据的起止期间,”wf”输入工作文档的名称,点击” OK”即跳出新建的工作文档a界面。
2、创建新对象。
操作如下图。
在”new object”文本框的”type of object”选择”pool”,”name for object ”输入新对象的名称。
创建成功后的界面如下面第3张图所示。
3、输入数据。
双击”workfile”界面的,跳出”pool”界面,输入个体。
一般输入方式为如下:若上海输入_sh,北京输入_bj,…。
个体输入完成后,点击该界面的键,在跳出的”series list”输入变量名称,注意变量后要加问号。
格式如下:y? x?。
点击”OK”后,跳出数据输入界面,如下面第4张图所示。
在这个界面上点击键,即可以输入或者从EXCEL处复制数据。
在输入数据后,记得保存数据。
保存操作如下:在跳出的“workfile save”文本框选择“ok”即可,则自动保存到我的文档。
然后在“workfile”界面如下会显示保存路径:d:\my documents\a.wf1。
若要保存到自己选择的路径下面,则在保存时选择“save as”,在跳出的文本框里选择自己要保存的路径以及命名文件名称。
4、单位根检验。
一般回归前要检验面板数据是否存在单位根,以检验数据的平稳性,避免伪回归,或虚假回归,确保估计的有效性。
单位根检验时要分变量检验。
(补充:网上对面板数据的单位根检验和协整检验存在不同意见,一般认为时间区间较小的面板数据无需进行这两个检验。
)(1)生成数据组。
如下图操作。
点击”make group”后在跳出的”series list”里输入要单位根检验的变量,完成后就会跳出如下图3所示的组数据。
E 【2 】views6.0面板数据操作一、数据输入1.创建工作文档.如下图操作,在”workfile create”文本框的“workfile structure type”选择“balanced panel”,”panel specification”的”start date”和”end date”输入数据的起止时代,”wf”输入工作文档的名称,点击”OK”即跳出新建的工作文档a界面.2.创建新对象.操作如下图.在”new object”文本框的”type of object”选择”pool”,”name for object ”输入新对象的名称.创建成功后的界面如下面第3张图所示.-3.输入数据.双击”workfile”界面的,跳出”pool”界面,输入个别.一般输入方法为如下:若上海输入_sh,北京输入_bj,….个别输入完成后,点击该界面的键,在跳出的”series list”输入变量名称,留意变量后要加问号.格局如下:y?x?.点击”OK”后,跳出数据输入界面,如下面第4张图所示.在这个界面上点击键,即可以输入或者从EXCEL处复制数据.在输入数据后,记得保存数据.保存操作如下:在跳出的“workfile save”文本框选择“ok”即可,则主动保存到我的文档.然后在“workfile”界面如下会显示保存路径:d:\my documents\a.wf1.若要保存到本身选择的路径下面,则在保存时选择“save as”,在跳出的文本框里选择本身要保存的路径以及定名文件名称.4.单位根磨练.一般回归前要磨练面板数据是否消失单位根,以磨练数据的安稳性,避免伪回归,或虚伪回归,确保估量的有用性.单位根磨练时要分变量磨练.(补充:网上对面板数据的单位根磨练和协整磨练消失不赞成见,一般以为时光区间较小的面板数据无需进行这两个磨练.)(1)生成数据组.如下图操作.点击”make group”后在跳出的”series list”里输入要单位根磨练的变量,完成后就会跳出如下图3所示的组数据.(2)生成时序图.如下图操作.在”graghoptions”界面的”specifi”下选择生成的时序图的外形,一般都默认设置,生成的时序图如下图3所示.不雅察时序图的趋向,以肯定单位根磨练的磨练模式.(3)单位根磨练.单位根磨练时,在”group unit root test”里的”test for root in”按磨练成果一步步磨练,假如原值”level”的磨练成果相符请求,即不消失单位根,则单位根磨练就不须要磨练下去了,假如不相符请求,则需持续磨练一阶差分”1stdifference”.二阶差分”2nd difference”.”include in test equation”是磨练模式的选择,依据上面时序图的外形来选择.从上面的时序图可以看出,原值的磨练模式应当选择含有截距项和趋向的磨练模式,即”include in test equation”选择”individual intercept and trend”.磨练成果如下图3所示.从磨练成果可以看出,磨练成果除了levin磨练办法外其他办法的成果都不相符请求(Prob.xx小于置信度(如0.05),则以为谢绝单位根的原假设,经由过程磨练).所以持续磨练一阶差分和二阶差分,直到磨练成果达到请求.假如变量原值序列经由过程单位根磨练,则称变量为0阶单整;假如变量一阶差分后的序列经由过程单位根磨练,则称变量为一阶单整,以此推之.留意:单位根磨练的办法(test type)较多,可以运用LLC.IPS.Breintung.ADF-Fisher 和PP-Fisher这5种办法进行面板单位根磨练.一般,为了便利起见,只采用雷同根单位根磨练LLC和不同根单位根磨练Fisher-ADF这两种磨练办法,假如它们都谢绝消失单位根的原假设,则可以以为此序列是安稳的,反之就长短安稳的.5.协整磨练.协整磨练磨练的是模子的变量之间是否消失长期稳固的关系,其前提是解释变量和被解释变量在单位根磨练时为同阶单整.操作如下图所示.6.回归估量面板数据模子依据常数项和系数向量是否为常数,分为3种类型:混杂回归模子(都为常数).变截距模子(系数项为常数)和变系数模子(皆异常数).混杂模子: itit it y x αβμ=++1,2,,;1,2,,i N t T == 变截距模子:iti it it y x αβμ=++1,2,,;1,2,,i N t T == 变系数模子:iti it i it y x αβμ=++1,2,,;1,2,,i N t T ==断定一个面板数据毕竟属于哪种模子,用F 统计统计量:()[]()2111()/11,(1)/(1)S S N K F F N K N T K S NT N K --⎡⎤⎣⎦=---⎡⎤⎣⎦-+()[]()3121()/1(1)1(1),(1)/(1)S S N K F F N K N T K S NT N K --+⎡⎤⎣⎦=-+--⎡⎤⎣⎦-+来磨练以下两个假设:121:N H βββ===,12122:,N N H αααβββ======.个中,1S .2S .3S 分离为变系数模子.变截距模子和混杂模子的残差平方和,K 为解释变量的个数,N 为截面个别数目,α为常数项,β为系数向量.若盘算得到的统计量2F 的值小于给定明显性程度下的响应临界值,则接收假设2H ,用混杂模子拟合样本.反之,则需用1F 磨练假设1H ,假如盘算得到的1F 值小于给定明显性程度下的响应临界值,则以为接收假设1H ,用变截距模子拟合,不然用变系数模子拟合.具体操作:1).分离对面板数据进行3种类型模子的回归,得到1S .2S .3S .此外,一般来说,用样本数据揣摸总体效应,运用随机效应回归模子;直接对样本数据进行剖析,采用固定效应回归模子. 起首回到面板数据表,假如是在如下这个界面时,点击按钮,在跳出的“series list”文本框里输入模子变量,如下图.也可以经由过程从新打开工作文件,如下图操作.选择本身当初保存的路径和文件名,点击打开.打开后,跳出工作文件双击,然后分离进行变系数.变截距和混杂模子的回归估量:点击,进行变系数回归(变系数)变截距回归混杂模子估量前面同2)操作,在“pool estimation”输入如下2).肯定模子情势把模子估量取得的s1.s2.s3数值代入前述公式(第13页),如下()[]()2111()/11,(1)/(1)S S N K F F N K N T K S NT N K --⎡⎤⎣⎦=---⎡⎤⎣⎦-+()[]()3121()/1(1)1(1),(1)/(1)S S N K F F N K N T K S NT N K --+⎡⎤⎣⎦=-+--⎡⎤⎣⎦-+盘算得到F1.F2值,磨练假设H1.H2,从而肯定采用何种模子情势(变系数.变截距.混杂效应).3).回归剖析若磨练成果表明应采用变系数模子,回到以下界面进行估量点击,进行变系数回归上图列示了回归成果,个中:①Coefficient为系数,比如AH的系数为0.760053,截距项为477.4820-315.8649②t-Statistic为t值,磨练每一个自变量的合理性.|t|大于临界值表示可谢绝系数为0的假设,即系数合理.Prob为系数的概率,若其小于置信度(如0.05)则表明|t|大于临界值,即以为系数合理.从成果可以看出,本例中系数合理.③R-squared为样本决议系数,表示总离差平方和中由回归方程可以解释部分的比例,比例越大解释回归方程可以解释的部分越多.值为0-1,越接近1表示拟合越好,>0.8以为可以接收,但是R2随因变量的增多而增大,所以可以经由过程增长自变量的个数来进步模子的R-squared.本例中R-squared0.995382,接近1,拟合度相当好.Adjust R-seqaured为修改的R-squared,与R-squared有类似意义.④F-statistic表示模子拟合样本的后果,即选择的所有自变量对因变量的解释力度.F大于临界值则解释谢绝0假设.若Prob(F-statistic)小于置信度(如0.05)则解释F大于临界值,方程明显性明显.本例中Prob(F-statistic)为0.000000, 模子方程明显.⑤Durbin-Watson stat:磨练残差序列的自相干性.其值在0-4之间._01_02_03_04_05_06_08 _09 _10 _11 _12 _13 _14 _15 _16 _17 _18 _19 _20 _21 _22 _23 _24 _25 _26 _27 _28 _29 _30 _31_33_34w? trade? ex? im? pr? mo? rc? tech? dex? dim? log(ex?) log(im?) log(pr?) log(mo?) rc? log(tech?)。
eviews面板数据模型详解1.已知1996―2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)和人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。
年人均消费(consume)和人均收入(income)数据以及消费者价格指数(p)分别见表9.1,9.2和9.3。
表9.1 1996―2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费 CONSUMEAH CONSUMEBJ CONSUMEFJ CONSUMEHB CONSUMEHLJ CONSUMEJL CONSUMEJS CONSUMEJX CONSUMELN CONSUMENMG CONSUMESD CONSUMESH CONSUMESX CONSUMETJ CONSUMEZJ19961997199819992000200120023607.43 3693.55 3777.41 3901.81 4232.98 4517.65 4736.52 5729.52 6531.81 6970.83 7498.48 8493.49 8922.72 10284.6 4248.47 4935.95 5181.45 5266.695638.74 6015.11 6631.68 3424.35 4003.71 3834.43 4026.34348.47 4479.75 5069.283110.92 3213.42 3303.15 3481.74 3824.44 4192.36 4462.08 3037.32 3408.03 3449.74 3661.68 4020.87 4337.22 4973.88 4057.5 4533.57 4889.43 5010.91 5323.18 5532.74 6042.6 2942.11 3199.61 3266.81 3482.33 3623.56 3894.51 4549.32 3493.02 3719.91 3890.74 3989.93 4356.06 4654.42 5342.64 2767.84 3032.33105.74 3468.99 3927.75 4195.62 4859.885022104643770.99 4040.63 4143.96 4515.056763.12 6819.94 6866.41 8247.69 8868.19 9336.1 3035.59 3228.713267.7 3492.98 3941.87 4123.01 4710.964679.61 5204.15 5471.01 5851.53 6121.04 6987.22 7191.96 5764.27 6170.14 6217.93 6521.54 7020.22 7952.39 8713.08表9.2 1996―2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入 INCOMEAH INCOMEBJ INCOMEFJ INCOMEHB1996199719981999 5064.62000 5293.55 7432.26 5661.16 4912.88 4810 6800.23 5103.58 5357.79 5129.05 6489.97 4724.11 8140.5 9279.162001 5668.8 8313.08 5984.82 5425.87 5340.46 7375.1 5506.02 5797.01 5535.89 7101.08 5391.05 8958.72002 6032.4 9189.36 6679.68 6100.56 6260.16 8177.64 6335.64 6524.52 6051 7614.36 6234.36 9337.564512.77 4599.27 4770.477332.01 7813.16 8471.98 9182.76 10349.69 11577.78 12463.92 5172.93 6143.64 6485.63 6859.81 4442.81 4958.67 5084.64 5365.034268.5 6017.854595.14 6538.2INCOMEHLJ 3768.31 4090.72 INCOMEJL INCOMEJS INCOMEJX INCOMELN3805.53 4190.58 4206.64 4480.01 3780.2 4071.32 4251.42 4720.58 4207.23 4518.14617.24 4898.61INCOMENMG 3431.81 3944.67 4353.02 4770.53 INCOMESD INCOMESH INCOMESX INCOMETJ INCOMEZJ4890.28 5190.79 5380.08 5808.96 8178.48 8438.893702.69 3989.92 4098.73 4342.61 5967.71 6608.39 7110.54 7649.83 6955.79 7358.72 7836.76 8427.958773.1 10931.64 11718.01 12883.46 13249.810464.67 11715.6表9.3 1996―2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数 1996 PAH PBJ PFJ PHB PHLJ PJL PJS PJX PLN PNMG PSD PSH PSX PTJ PZJ19971998 1001999200020012002 99 98.2 99.5 99 99.3 99.5 99.2 100.1 98.9109.9 101.397.8 100.7 100.5 99.1 102.1 98.7 98.1 96.8 9899.7 100.5 98.3 100.8 98.6 101.3111.6 105.3 102.4 100.6 103.5 103.1 105.9 101.7 99.7 107.1 103.5 98.4 107.1 104.4 100.4 107.2 103.7 99.2 109.3 101.7 99.4 108.410210198.7 100.1 100.8 98.6 100.3 99.5 98.699.9100107.9 103.1 99.3 107.6 104.5 99.3 109.6 102.8 99.4 109.2 102.8100107.9 103.1 98.6 109103.1 99.599.8 101.3 100.6 100.2 99.3 100.2 101.8 101.5 102.510099.6 103.9 99.8 98.9 98.899.6 101.2 10199.899.3 100.5 98.4 99.6 99.1107.9 102.8 99.7(1)建立面板数据工作文件首先建立工作文件。