第7章 非线性模型参数估值
- 格式:doc
- 大小:349.51 KB
- 文档页数:10

《统计学》习题集及答案《统计学》习题集及答案主编:杨群I / 43目录习题部分 ................................................ . (2)第1章导论 ................................................ .............. 1 第2章数据的搜集 ................................................ ........ 2 第3章数据的整理与显示 ................................................ .. 3 第4章数据的概括性度量 ................................................ .. 4 第5章概率与概率分布 ................................................ .... 7 第6章统计量及其抽样分布 ................................................8 第7章参数估计 ................................................ .......... 9 第8章假设检验 ................................................ ......... 11 第9章分类数据分析 ................................................ ..... 12 第10章方差分析 ................................................ ........ 14 第11章一元线性回归 ................................................ .... 15 第12章多元线性回归 ................................................ .... 17 第13章时间序列分析和预测 . (xx)年龄 B.工资C.汽车产量D.购买商品的支付方式 2.指出下面的数据哪一个属于顺序数据 A.年龄 B.工资C.汽车产量D.员工对企业某项制度改革措施的态度3.某研究部门准备在全市xx年人均收入,这项研究的统计量是个家庭万个家庭个家庭的人均收入万个家庭的人均收入 4.了解居民的消费支出情况,则A.居民的消费支出情况是总体B.所有居民是总体C.居民的消费支出情况是总体单位D.所有居民是总体单位 5.统计学研究的基本特点是 A.从数量上认识总体单位的特征和规律 B.从数量上认识总体的特征和规律 C.从性质上认识总体单位的特征和规律 D.从性质上认识总体的特征和规律6.一家研究机构从IT从业者中随机抽取500人作为样本进行调查,其中60%的人回答他们的月收入在5000元以上,50%的回答他们的消费支付方式是使用信用卡。
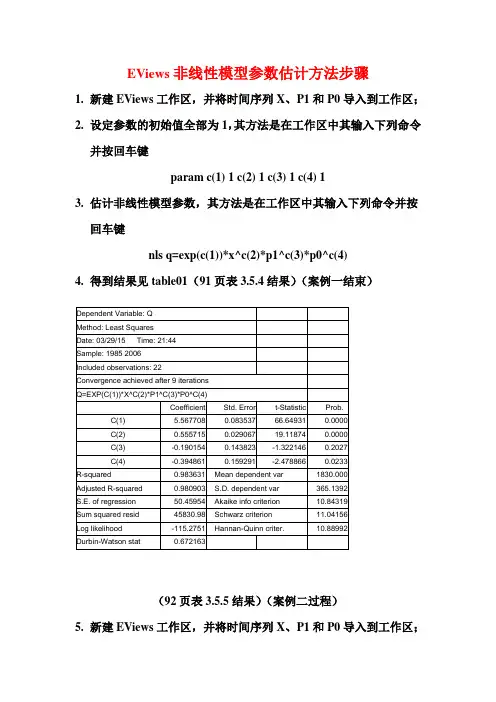
EViews非线性模型参数估计方法步骤1.新建EViews工作区,并将时间序列X、P1和P0导入到工作区;2.设定参数的初始值全部为1,其方法是在工作区中其输入下列命令并按回车键param c(1) 1 c(2) 1 c(3) 1 c(4) 13.估计非线性模型参数,其方法是在工作区中其输入下列命令并按回车键nls q=exp(c(1))*x^c(2)*p1^c(3)*p0^c(4)4.得到结果见table01(91页表3.5.4结果)(案例一结束)Dependent Variable: QMethod: Least SquaresDate: 03/29/15 Time: 21:44Sample: 1985 2006Included observations: 22Convergence achieved after 9 iterationsQ=EXP(C(1))*X^C(2)*P1^C(3)*P0^C(4)Coefficient Std. Error t-Statistic Prob.C(1) 5.567708 0.083537 66.64931 0.0000C(2) 0.555715 0.029067 19.11874 0.0000C(3) -0.190154 0.143823 -1.322146 0.2027C(4) -0.394861 0.159291 -2.478866 0.0233R-squared 0.983631 Mean dependent var 1830.000Adjusted R-squared 0.980903 S.D. dependent var 365.1392S.E. of regression 50.45954 Akaike info criterion 10.84319Sum squared resid 45830.98 Schwarz criterion 11.04156Log likelihood -115.2751 Hannan-Quinn criter. 10.88992Durbin-Watson stat 0.672163(92页表3.5.5结果)(案例二过程)5.新建EViews工作区,并将时间序列X、P1和P0导入到工作区;6.设定参数的初始值全部为1,其方法是在工作区中其输入下列命令并按回车键param c(1) 1 c(2) 1 c(3) 17.估计非线性模型参数,其方法是在工作区中其输入下列命令并按回车键nls q=exp(c(1))*(x/p0)^c(2)*(p1/p0)^c(3)8.得到结果见table02(92页表3.5.5结果)(案例二结束)Dependent Variable: QMethod: Least SquaresDate: 03/29/15 Time: 22:14Sample: 1985 2006Included observations: 22Convergence achieved after 4 iterationsQ=EXP(C(1))*(X/P0)^C(2)*(P1/P0)^C(3)Coefficient Std. Error t-Statistic Prob.C(1) 5.525965 0.072685 76.02666 0.0000C(2) 0.533824 0.019785 26.98163 0.0000C(3) -0.242862 0.134014 -1.812219 0.0858R-squared 0.982669 Mean dependent var 1830.000Adjusted R-squared 0.980845 S.D. dependent var 365.1392S.E. of regression 50.53638 Akaike info criterion 10.80939Sum squared resid 48524.59 Schwarz criterion 10.95817Log likelihood -115.9033 Hannan-Quinn criter. 10.84444Durbin-Watson stat 0.656740。

非线性回归模型的拟合与评估非线性回归是统计学中常用的一种回归分析方法,用于描述自变量与因变量之间的非线性关系。
本文将介绍非线性回归模型的拟合与评估方法。
一、非线性回归模型的拟合方法1. 数据收集与准备拟合非线性回归模型首先需要收集与问题相关的数据。
数据的准备包括数据清洗、变量选择和数据变换等步骤,以确保数据的质量和适应非线性回归模型的要求。
2. 模型选择在准备好数据后,需要选择适合问题的非线性回归模型。
常见的非线性回归模型包括多项式回归模型、指数回归模型、对数回归模型等。
选择合适的模型需要根据问题的特点和理论的支持进行判断。
3. 模型拟合模型拟合是指通过最小化残差平方和或最大似然估计等方法,估计模型的参数。
对于非线性回归模型,常用的拟合方法有最小二乘法、非线性最小二乘法、广义最小二乘法等。
4. 拟合效果评估拟合效果评估是判断非线性回归模型拟合程度好坏的指标。
常用的评估方法有残差分析、决定系数、AIC和BIC等。
残差分析可以检验模型的拟合效果和残差的独立性、常数方差和正态性假设。
二、非线性回归模型的评估方法1. 决定系数(R-squared)决定系数是衡量模型拟合程度的指标,其取值范围为0到1之间。
决定系数越接近1,表示模型对观测数据的解释能力越强。
但需要注意,决定系数无法判断模型是否过拟合。
2. 调整决定系数(Adjusted R-squared)调整决定系数是对决定系数进行修正,考虑了自变量数目的影响。
调整决定系数比决定系数更能有效地评估模型的拟合效果。
3. Akaike信息准则(AIC)和贝叶斯信息准则(BIC)AIC和BIC是用于比较不同模型的拟合效果的统计准则。
AIC和BIC数值越小,表示模型越好。
这两个指标在非线性回归模型的选择和评估中广泛应用。
4. 拟合图形分析通过绘制拟合曲线与实际观测数据的对比图,可以直观地评估非线性回归模型的拟合效果。
拟合图形分析可以帮助发现模型的不足之处,从而进行进一步的改进。


非线性面板数据模型的估计与解释面板数据模型是研究经济和社会现象的重要工具之一,它能够捕捉个体和时间维度上的变化。
然而,在传统的线性面板数据模型中,往往无法准确地反映出现实世界中的非线性关系。
为了解决这个问题,研究者们提出了非线性面板数据模型的估计与解释方法。
一、非线性面板数据模型的基本框架在非线性面板数据模型中,我们需要考虑个体和时间维度上的非线性关系,并且在估计与解释时需采用相应的方法。
该模型可表示为:y_it = f(x_it; β) + u_it其中,y_it表示个体i在时间t的观测值,x_it为自变量,β为待估参数,f为非线性函数,u_it为误差项。
二、非线性面板数据模型的估计方法1. 非线性最小二乘法(NLS)非线性最小二乘法是一种常用的参数估计方法,它通过最小化观测值与模型预测值之间的误差平方和来估计参数。
通过迭代求解,求得模型的最优解。
2. 一阶差分法一阶差分法是一种非参数估计方法,它通过对面板数据进行差分运算,将非线性模型转化为线性模型来估计参数。
该方法不需要对非线性函数进行具体的形式假设,因此更加灵活。
3. 广义矩估计法(GMM)广义矩估计法是一种基于矩条件的估计方法,它通过最大化待估参数的矩条件下的似然函数来估计参数。
该方法对非线性模型的形式不做具体要求,适用于各种复杂的非线性关系。
三、非线性面板数据模型的解释与应用非线性面板数据模型的估计结果可以用来解释个体和时间维度上的非线性关系,并且应用于实际问题中。
例如,在经济学领域,可以利用非线性面板数据模型来研究收入与消费之间的非线性关系,以及产出与就业之间的非线性关系;在社会学领域,可以利用非线性面板数据模型来研究教育对于个体收入的非线性影响等。
此外,非线性面板数据模型的解释还可以提供决策者与政策制定者有关个体和时间维度上的非线性关系的重要信息,以指导实际工作。
结论非线性面板数据模型的估计与解释在经济学和社会科学领域具有重要的应用价值。


非线性回归模型的参数估计方法比较研究论文素材一、引言非线性回归模型是在实际问题中广泛应用的一种统计模型。
不同的非线性回归模型需要使用不同的参数估计方法,选择合适的方法对模型进行参数的估计对于模型的准确性和可靠性至关重要。
本文旨在比较不同的非线性回归模型参数估计方法的优劣,为实际应用提供参考。
二、参数估计方法1. 最小二乘法最小二乘法是一种经典的参数估计方法,适用于线性回归和部分非线性回归模型。
该方法通过最小化观测值与模型预测值之间的误差平方和来估计参数值。
然而,对于高度非线性的模型,最小二乘法可能存在无法收敛或者达到局部最优解的问题。
2. 最大似然估计法最大似然估计法是一种常用的参数估计方法,尤其适用于非线性回归模型。
该方法基于观测数据的概率分布,寻找最大化观测数据出现概率的参数值作为估计值。
最大似然估计法在理论上具有良好的性质,但在实际应用中可能需要迭代算法来求解。
3. 二阶导数估计法二阶导数估计法是一种基于牛顿法的参数估计方法,通过使用二阶导数矩阵估计参数值。
这种方法的优点是收敛速度较快,但需要较高的计算复杂度。
在实际应用中,二阶导数估计法可能会遇到矩阵奇异或计算不稳定的问题。
4. 贝叶斯估计法贝叶斯估计法是一种基于贝叶斯统计思想的参数估计方法,通过引入先验分布和后验分布来估计参数值。
该方法能够灵活地处理不确定性,但需要选择合适的先验分布和进行复杂的数值计算。
三、方法比较根据不同的非线性回归模型特点和数据情况,选择合适的参数估计方法对于模型准确性和可靠性至关重要。
下面对不同的参数估计方法进行比较:1. 参数估计准确性最小二乘法对于线性回归模型具有较好的估计准确性,但对于非线性回归模型的准确性可能较低。
最大似然估计和二阶导数估计法对于非线性回归模型具有较好的估计准确性,但可能需要较高的计算复杂度。
贝叶斯估计法考虑了不确定性,但需要选择合适的先验分布。
2. 参数估计稳定性最小二乘法对于线性回归模型具有较好的稳定性,但非线性回归模型的稳定性可能较差。

第七章 非参数回归模型与半参数回归模型第一节 非参数回归与权函数法;一、非参数回归概念前面介绍的回归模型,无论是线性回归还是非线性回归,其回归函数形式都是已知的,只是其中参数待定,所以可称为参数回归。
参数回归的最大优点是回归结果可以外延,但其缺点也不可忽视,就是回归形式一旦固定,就比较呆板,往往拟合效果较差。
另一类回归,非参数回归,则与参数回归正好相反。
它的回归函数形式是不确定的,其结果外延困难,但拟合效果却比较好。
设Y 是一维观测随机向量,X 是m 维随机自变量。
在第四章我们曾引进过条件期望作回归函数,即称g (X ) = E (Y |X ) ()【为Y 对X 的回归函数。
我们证明了这样的回归函数可使误差平方和最小,即22)]([min )]|([X L Y E X Y E Y E L-=-()这里L 是关于X 的一切函数类。
当然,如果限定L 是线性函数类,那么g (X )就是线性回归函数了。
细心的读者会在这里立即提出一个问题。
既然对拟合函数类L (X )没有任何限制,那么可以使误差平方和等于0。
实际上,你只要作一条折线(曲面)通过所有观测点(Y i ,X i )就可以了是的,对拟合函数类不作任何限制是完全没有意义的。
正象世界上没有绝对的自由一样,我们实际上从来就没有说放弃对L(X)的一切限制。
在下面要研究的具体非参数回归方法,不管是核函数法,最近邻法,样条法,小波法,实际都有参数选择问题(比如窗宽选择,平滑参数选择)。
所以我们知道,参数回归与非参数回归的区分是相对的。
用一个多项式去拟合(Y i ,X i ),属于参数回归;用多个低次多项式去分段拟合(Y i ,X i ),叫样条回归,属于非参数回归。
&二、权函数方法非参数回归的基本方法有核函数法,最近邻函数法,样条函数法,小波函数法。
这些方法尽管起源不一样,数学形式相距甚远,但都可以视为关于Y i 的线性组合的某种权函数。
也就是说,回归函数g (X )的估计g n (X )总可以表为下述形式:∑==ni i i n Y X W X g 1)()(()其中{W i (X )}称为权函数。

非线性成长模型的建立与参数估计非线性成长模型是一种用来描述非线性系统的变化过程的数学模型。
相比于线性模型,非线性成长模型可以更准确地反映实际问题中的非线性关系,因此在很多领域应用广泛,比如生物学、经济学和环境科学等。
在本篇文章中,我们将探讨如何建立非线性成长模型并进行参数估计的方法与步骤。
首先,建立非线性成长模型需要明确研究对象的特征以及模型的形式。
我们以生物学中的生长过程为例。
假设我们想要研究一种植物的生长过程,并希望建立一个非线性成长模型来描述其生长速度随时间的变化。
根据观察,我们发现该植物的生长速度在初始阶段比较快,逐渐减缓,最终接近一个稳定值。
基于这一观察,我们可以选择广义 logistic 函数作为非线性成长模型的形式:N(N) = N / (1 + N^−N(N−N₀))其中N(N)表示植物的生长速度,N表示最大生长速度,N表示生长速度的增长率,N₀表示生长速度达到一半最大值时的时间点。
该模型在初始时,生长速度较快,随着时间的推移,生长速度逐渐减缓。
当N→∞时,N(N)趋近于最大生长速度N。
其次,参数估计是建立非线性成长模型的关键步骤之一。
参数估计的目标是通过已知的数据来估计模型中的参数值,使得模型与实际观测值之间的拟合程度最好。
估计非线性成长模型的参数存在多种方法,其中最常用的方法是最小二乘法。
最小二乘法通过最小化观测值与模型预测值之间的残差平方和来确定最优参数值。
在参数估计过程中,需要选择合适的初始参数值,将问题转化为一个最优化问题。
采用迭代的方式,不断调整参数值,直到找到最小的残差平方和。
此外,为了保证参数估计的稳定性和准确性,常常需要采用统计方法来评估模型的拟合度与参数的显著性。
常见的统计指标包括确定系数(R^2)、AIC(Akaike information criterion)和BIC(Bayesian information criterion)等。
确定系数可以衡量模型拟合数据的好坏,范围从0到1,值越接近1表示拟合效果越好。

非线性模型的参数估计沈云中同济大学测量系E-mail: yzshen@提要•概述•非线性模型•线性化问题•参数估计问题•估值精度的评定问题•几种特殊的非线性模型•结论概述均值µ 方差σ² 的观测值l ,其二次型l² 的期望值为:非线性模型的估值往往是有偏的!E(l²) = var(l ) + {E(l )}² = σ² + µ²l非线性观测模型的假设在准则参数估值是唯的x1、在准则下,参数估值是唯一的2、在观测值的误差范围内,参数估值是稳定的非线性模型参数估计的现状1、顾及二次项的估计1、顾及次项的估计2、参数估值可采用全局优化方法解算3估值的精度没有给出3、估值的精度没有给出非线性观测方程非线性观测方程:约束条件:(,)0l x f l e x e ++=()0x g x e +≤估计准则:()0x h x e +=min :l l xx xe Pe e P e +T T Lagrange 函数:P T T ()()(,,,,)2(,) 22l x ll xx x l x x x L e e λμκe Pe e P e λf l e x e μg x e κh x e =++++++++TTT观测方程的简化形式•待估参数没有先验信息(,)0l f l e x +=参数x 从初值x 0出发迭代计算•可表示成观测值的显式()l l e f x +=T()()min : ()()()x l f x P l f x =−−S非线性方程的线性化•非线性观测方程直到二解的展开式()13ˆˆˆ()()()()T f x f xf x x x f x x O δδδ=+++&&&⎡2ˆx x xδ=−21ˆ()ˆ()T T T i i T n f x x f x x x x x f x x x δδδδδδ&&&&×⎤∂⎡⎤==⎢⎥⎣⎦∂∂⎣⎦22; T T T N TNx f xx f xfδδδδδδκκ&&&&&&==向fx x δδ切向分量法向分量顾及二次项的非线性估计•非线性估值的二次展开式非线性估值的次展开式1ˆ3xg l v g l g l v v g l v ′′′=+=+++TO •估值有偏()()()()()2l l l l ()1ˆ {}2l x x g D ′′=+⎡⎤⎣⎦i E tr •二次无偏估值()1ˆ 2l x x g D ′′=−⎡⎤⎣⎦)itr非线性模型的参数估计问题非线性模型的参数估计:1.局部极值点计算2.搜索更优极值点的区域Mountainshigher thanwhere I amwhere I am图引自徐培亮局部极值计算•BFGS 拟牛顿算法牛顿算(1)()k k k kα+=+xxd ()()d H x =−∇k k k S T T T=−−10()() k k k k k k k k k k kρρρ++=H E p q H E q p p p H E11)()k k +k Tk kρq p =()k =−p xx1)+∇k k ()()()()q xx =∇−k S S()k ()x ε∇<S 迭代停止条件:全局最优解算法•非线性、非凸目标函数的全局最优解步骤如下:1.由初值x 计算S(x ,寻找满足下面条件的可行集I xmin :()x S 0(0)20()()0x x −<S S 2.在某个子集I x i 内计算S (x )的局部极值S ﹡3. 寻找满足下面条件的更新可行集I x n()0, x x x∗−<∈S S I 4. 重复2与3步,直至更新的可行集为空集。

非线性模型与参数估计方法研究1.引言非线性模型是现代统计学中一个重要的分支,随着计算机性能的不断提高和数据维度的不断增加,非线性模型的应用正在越来越广泛。
在实际应用中,参数估计是非线性模型不可避免的一部分,而参数估计的精度对模型预测的准确性起着至关重要的作用。
在本文中,我们将介绍非线性模型及其参数估计方法的研究现状,并讨论其应用价值和发展趋势。
2.非线性模型非线性模型是指模型中自变量与因变量之间不满足线性关系的模型。
非线性模型一般在目标函数中引入一些非线性项,以适应复杂的实际情况。
在实际应用中,非线性模型的种类繁多,常见的有曲线拟合、非线性回归、广义线性模型等。
非线性模型既可以用于描述现象,又可以用于预测未来,具有很高的应用价值。
在非线性模型中,很多模型的参数是需要估计的。
3.参数估计方法参数估计是非线性模型中一个至关重要的问题,其精度直接关系到模型的预测准确性。
常见的参数估计方法有极大似然估计、最小二乘估计、贝叶斯估计等。
极大似然估计是一种计算方便、精度较高的方法,最小二乘估计则是样本量较大时最优的方法,而贝叶斯估计则可以自然地引入先验信息,使得估计结果更加准确。
此外,基于神经网络的参数估计方法和贪心算法也获得了一定的应用。
4.应用价值非线性模型及其参数估计方法在各种领域中都有着广泛的应用。
在金融领域,非线性模型可以用于股票价格的预测和交易决策的制定。
在医学领域,非线性模型可以用于疾病的诊断和治疗方案的优化。
在物流领域,非线性模型可以用于路线优化和成本控制。
随着社会经济的发展,非线性模型的应用范围将越来越广泛。
5.发展趋势随着计算机性能的不断提高,大数据分析和人工智能技术的应用越来越普及,非线性模型的应用前景更加广阔。
同时,非线性模型及其参数估计方法也在不断发展。
例如,基于深度学习的非线性模型已经取得了许多研究和应用成果。
此外,混沌理论、粒子群算法、受限玻尔兹曼机等技术也为非线性模型提供了新的思路和手段。
第7章 非线性时间序列模型经济理论建议:许多重要的时间序列显示出非线性行为。
工资有向下刚性是许多宏观经济模型的关键特征。
在经济周期中,衰退比恢复更明显,如重要的宏观经济变量:产出和就业,下降比上升更明显。
由于标准的ARMA 模型依赖于线性差分方程,需要新的动态设定来捕捉非线性行为。
本章有三个目的:1.比较ARMA 模型与各种非线性模型。
几个非线性形式是非常有用的。
这些非线性模型可用OLS 方法、非线性OLS 、最大似然方法来估计。
2.给出一些检验,确定非线性调整的存在。
检验非线性的存在比建立非线性要简单得多。
3.介绍了非线性形式的单位根和协整。
7.1 ARMA 模型的简单扩充非线性自回归(NLAR )的最简单形式是1()t t t y f y ε-=+这是一个一阶非线性自回归模型,也可以用更有趣的方式 111()t t t t y a y y ε--=+ (7.1.1) 这里1111()()t t t a y y f y ---=方程(7.1.1)与AR(1)模型很象,除了系数11()t a y -是1t y -的函数。
如果我们不知道()f ⋅的形式,非线性和时变参数就很难确定。
一般的,p 阶非线性自回归模型12(,,,)t t t t p t y f y y y ε---=+ (7.1.2) 表示为()NLAR p 。
估计(7.1.2)的困难在于函数()f ⋅的形式是未知的。
一种方式是利用Taylor 展开。
如,对于(2)NLAR 模型12(,)t t t t y f y y ε--=+不高于3阶的Taylor 级数展开是22011221212111222t t t t t t t y a a y a y a y y a y a y ------=+++++22331112121211112222t t t t t t t a y y a y y a y a y ε------+++++对于更一般的()NLAR p 有广义自回归(GAR )模型011111p p p r sk l ti t i ijkl t i t j t i i j k l y a a y a y y ε---======+++∑∑∑∑∑ (7.1.3) 通常选取,4r s ≤。
非线性模型参数估值的Excel方法
时景荣;罗传义;季玉茹
【期刊名称】《吉林化工学院学报》
【年(卷),期】2002(019)003
【摘要】给出了非线性模型参数估值的Excel方法,不用编程,特别简便,速度快,具有较强的实用性.
【总页数】3页(P46-47,50)
【作者】时景荣;罗传义;季玉茹
【作者单位】吉林化工学院,自动化系,吉林,吉林,132022;吉林化工学院,化学工程系,吉林,吉林,132022;吉林化工学院,自动化系,吉林,吉林,132022
【正文语种】中文
【中图分类】TP311.1
【相关文献】
1.软件可靠性模型的两种参数估值方法、估值结果一致性分析 [J], 李德银;张宁虹
2.河流水质模型参数估值方法探讨 [J], 陈光明
3.改进遗传算法在高非线性水质模型参数估值中的应用研究 [J], 冯良记;唐军
4.一类动态非线性系统模型频率域参数估值—维纳及准维纳模型 [J], 张平;宋亚民
5.改进Marquardt法在催化反应动力学模型非线性参数估值中的应用 [J], 曾乐;刘庆
因版权原因,仅展示原文概要,查看原文内容请购买。
实验一用线性回归进行一元非线性模型的参数估计【实验目的】通过编写具有一定通用型的可转化为现行的医院非线性模型程序,学习线性回归这种参数估计方法,体会作为经验模型主要形式之一的拟合模型的建立方法。
【实验内容】试用线性回归分析建立某无烟煤的粒度模型。
其粒度试验结果见下表:【实验要求】绘制详细流程图,编写程序并上机验证,最后撰写实验报告。
【实验程序】#inclede<stdio.h>#include<math.h>void main(){Int n, j,k;float x[],y[],z[],u[],v[],p[],e=0,f=0,g=0,l=0,m=0,a,b,c,d,q=0,sm;printf(“请输入样本容量n=”);scanf(“%f”,&n);printf(“请输入粒度试验结果\n”);for(j=0;j<n;j++){scanf(“%f%f”,&x[j],&y[j]);}printf(“请选择模型:\n1.y=a+bx\n2.y=100e^(-ax^b)\n3.y=ax^b\n4.y=ae^(bx)\n5.y=ae^(b/x)\n6.y=a+lgx\n7.y=1/(a+be^ (-x))\n8.y=ab^x\n”);scanf(“%d”,&k);switch(k) /*选择模型*/{case 1:for(i=0;i<n;i++){u[i]=x[i];v[i]=y[i];}break;case 2:for(i=0;i<n;i++){u[i]=x[i];v[i]=log(log(100/y[i]));}break;case 3:for(i=0;i<n;i++){u[i]=log10(x[i]);v[i]=log10(y[i]);}break;case 4:for(i=0;i<n;i++){u[i]=x[i];v[i]=log(y[i]);}break;case 5:for(i=0;i<n;i++){u[i]=1/x[i];v[i]=log(y[i]);}break;case 6:for(i=0;i<n;i++){u[i]=log10(x[i]);v[i]=1/y[i];}break;case 7:for(i=0;i<n;i++){u[i]=exp(-x[i]);v[i]=1/y[i];}break;case 8:for(i=0;i<n;i++){u[i]=x[i];v[i]=log(y[i]);}break;default:printf(“不合法的模型号!\n”);break;}for(j=0;j<n;j++) /*线性回归计算*/ {e=e+u[j]; /*∑x*/f=f+v[j]; /*∑y*/g=g+u[i]*u[i];l=l+u[i]*v[i];m=m+v[i]*v[i];}g=g-n*e*e; /*∑x^2*/l=l-n*e*f; /*∑xy*/m=m-n*f*f; /*∑y^2*/e=e/n;f=f/n;h=sqrt(g*m);h=l/h;c=l/g;d=f-c*e;switch(k){case 1:case 6:case 7:a=d;b=c;break;case 2:case 3:case 4:case 5:a=exp(d);b=c;break;case 8:a=exp(d);b=exp©;break;default:printf(“非法模型号!\n”);break;}for(i=0;i<n;i++) /*计算理论值,并输出公式*/{switch(k){case 1:p[i]=a+b*x[i];printf(“拟合结果为:y=%f+%fx\n”,&a,&b);break;case 2:p[i]=100*exp(-a*pow(x[i],b)); printf(“拟合结果为:y=100e^(-%fx^%f)\n”,a,b);break; case 3:p[i]=a*pow(x[i],b); printf(“拟合结果为:y=%fx^%f\n”,a,b);break;case 4:p[i]=a*exp(b*x[i]); printf(“拟合结果为:y=%fe^(%f x)\n”,a,b);break;case 5:p[i]=a*exp(b/x[i]); printf(“拟合结果为:.y=%f e^(%f/x)\n”,a,b);break;case 6:p[i]=a+b*log10(x[i]); printf(“拟合结果为:y=%f+%flgx \n”,a,b);break;case 7:p[i]=1/(a+b*exp(-x[i])); printf(“拟合结果为:y=1/(%f+%fe^(-x))\n”,a,b);breakcase 8:p[i]=a*pow(b,x[i]); printf(“拟合结果为:y=%f%f^x \n”,a,b);break;default:printf(“非法模型号!\n”);break;}}for(i=0;i<n;i++) /*计算剩余标准差*/{q=q+(y[i]-p[i])*(y[i]-p[i]);}sm=sqrt(q/(n-2));}printf{“a=%f b=%f 标准差=%f\n”,a,b,sm};printf(“***********************************\n);printf(“x y y的估计y-(y的估计”);for(j=0;j<n;j++){printf(“%f %f %f %f”,x[j],y[j],p[j],y[j]-p[j]);}}【实验结果】。
非线性模型参数估计的EViews 操作例3.5.2建立中国城镇居民食品消费需求函数模型。
根据需求理论,居民对食品的消费需求函数大致为: ()01,,f P P X Q =。
其中,Q 为居民对食品的需求量,X 为消费者的消费支出总额,P1为食品价格指数,P0为居民消费价格总指数。
表3.5.1 中国城镇居民消费支出及价格指数单位:元资料来源:《中国统计年鉴》(1990~2007)估计双对数线性回归模型μββββ++++=031210n n n P L LnP X L Q L 对应的非线性模型:32101βββP P AX Q =这里需要将等式右边的A 改写为0e β。
取0β,1β,2β,3β的初值均为1。
Eviews操作:1、打开EViews,建立新的工作文档:File-New-Workfile,在Frequency选择Annual,在Start date输入“1985”,End date输入“2006”,确认OK。
2、输入样本数据:Object-New Object-Group,确认OK,输入样本数据。
图13、设置参数初始值:在命令窗口输入“param c(1) 1 c(2) 1 c(3) 1 c(4) 1”,回车确认。
4、非线性最小二乘法估计(NLS):Proc-Make Equation,在NLS估计的方程中写入Q=EXP(C(1))*X^C(2)*P1^C(3)*P0^C(4),方程必须写完整,不能写成Q C(1) X P1 P0。
确定输出估计结果:图2NLS注意事项:1).参数初始值:如果参数估计值出现分母为0等情况将导致错误,解决办法是:手工设定参数的初始值及范围,比如生产函数中的c(2)肯定是介于0-1之间的数字。
eviews6.0中并没有start 的选项,只有iteration的次数和累进值得选择。
只能通过param c(1) 0.5 c(2) 0.5来设置。
2).迭代及收敛eviews用Gauss Seidel迭代法求参数的估计值。
第7章 非线性模型参数估值7.1 引言数学模型是观测对象各影响因素相互关系的定量描述。
在获得实验数据并做了整理之后,就要建立数学模型。
这一工作在科学研究中有着十分重要的意义。
人们选用的模型函数可以是经验的,可以是半经验的,也可以是理论的。
模型函数选定之后,需要对其中的参数进行估值并确定该估值的可靠程度。
对于线性模型,待求参数可用线性最小二乘法求得,即用前一章中介绍的确定线性回归方程的方法。
对于非线性模型,通常是通过线性化处理而化为线性模型,用线性最小二乘法求出新的参数,从而再还原为原参数。
这种方法在处理经验模型时,简便易行,具有一定的实用价值。
但要注意到,这样做是使变换后的新变量y '的残差平方和(即剩余平方和)最小,这并不能保证做到使原变量y 的残差平方和也达最小值。
因此,得到的参数估计值就不一定是最佳的估计值。
可见在求理论模型的参数时,这种线性化的方法尚有其不足之处。
此外,还有些数学模型无法线性化,所以用线性化的方法是行不通的。
为此,需要一种对非线性模型通用的(不管是经验模型还是理论模型,不管这个模型能否线性化),能够得到参数最佳估计值的参数估计方法。
在工程中,特别是在化学工程中的数学模型大多是非线性、多变量的。
设y ˆ为变量x 1,x 2,…,x p ,的函数,含有m 个参数b 1,b 2,…,b m ,则非线性模型的一般形式可表示为:=y ˆf (x 1,x 2,…,x p ;b 1,b 2,…,b m ) (7.1) 或写为 ),(ˆb x f y= (7.2) 式中x 为p 维自变量向量,b 为m 维参数向量。
设给出n 组观测数据x 1 ,x 2 ,… ,x n y 1 ,y 2 ,… ,y n我们的目的是由此给出模型式(7.2)中的参数b 的最佳估计值。
可以证明,这个最佳估计值就是最小二乘估计值。
按最小二乘法原理,b 应使Q 值为最小,即∑==-=ni i i yy Q 12min )ˆ( 或写成 ∑==-=ni i i f y Q 12min )],([b x (7.3)现在的问题是根据已知的数学模型和实验数据,求出使残差平方和最小,即目标函数式(7.3)取极小值时的模型参数向量b 。
这显然是一个最优化的数学问题,可以采用逐次逼近法求解。
这种处理方法实质上是逐次线性化法或某种模式的搜索法。
在下面各节中将介绍几个适用方法。
7.2 高斯——牛顿法高斯——牛顿法是非线性最小二乘法的最基本方法。
其基本思想是把非线性模型函数在一局部范围内进行泰勒一阶展开,作为原函数的线性近似,代入目标函数则成为线性最小二乘法,因为它有解析解,所以可求出它的精确的极小值,以此点作为下一次线性近似的出发点。
这样反复采用同样方法逐次逼近真正的极小点,从而得到最佳的估计参数向量b 。
所以此法实质是逐次线性化法。
参数估计的目标函数为式(7.3)。
求解参数向量b 的思路是这样的,先给定初值b (0),然后一次次修正)()()1(k k k Δb b +=+ (7.4) 式中角标k 代表迭代回次,Δ(k )代表第k 次的修正量,每次修正须保证Q 值下降,这样一步步逼近目标函数的极小值min Q ,最后得到b 的解。
为确定Δ,对非线性函数,在初值点b (0)处进行泰勒一阶展开得:∑=∂∂+≈+mj j j i i i b f f f 1)0()0()0(Δ),(),(b x Δb x (7.5)或简记为 ∑=∆∂∂+≈mj j ji ii b f f f 1)0()0( (7.6)代入式(7.3),得 ∑∑==∆∂∂--=ni mj j ji ii b f f y Q 121)0()0(][ (7.7) 当b (0)给定后,)0(i f 和]/[)0(j i b f ∂∂都是自变量x 的函数,根据实验点均可计算求得。
因此目标函数化为对未知的Δ的线性函数,并可用线性最小二乘法求得Q (Δ)的极小点。
由极值条件0)/(=∂∂ΔQ ,对式(7.7)求导数,并令其为零,得∑∑===∂∂∆∂∂---n i m j k i j j ii i b f b f f y 11)0()0()0(0][2 (k=1,2,…,m)由此得∑∑∑===∂∂-=∆∂∂∂∂ni mj ni kii i j k i j i b f f y b f b f 111)0()0()0()0()( (k=1,2,…,m) (7.8) 令⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡∂∂⋯∂∂∂∂⋯⋯⋯⋯∂∂⋯∂∂∂∂∂∂⋯∂∂∂∂=m n n n m m b f b f b f b f b f b f b f b f b f )0(2)0(1)0()0(22)0(21)0(2)0(12)0(11)0(10A (7.9) )0(i i i f y r -= (7.10) ],,,[21n T r r r ⋯=r (7.11)代入式(7.8)则有r A ΔA A TT 000= (7.12) 令00A A A T = (7.13) r A D T 0= (7.14)则有线性方程组D A Δ= (7.15)解之便得Δ,从而代入式(7.4),得到修正的b 。
经过反复迭代直至Δ的值很小,满足误差要求为止,这时的b 即为所求。
以上计算过程归纳如下: (1)人为地给定初值b (0);(2)求偏导值j i b f ∂∂/)0(,构成矩阵0A ; (3)计算并构成向量r ;(4)计算并构成矩阵A 和向量D ; (5)求解线性方程组得到Δ; (6)按式(7.4)修正b ;(7)若Δ满足误差要求则结束,否则返回步骤(2)。
在求解过程中之所以需要反复地迭代和修正,是因为泰勒级数展开式(7.6)只是近似的式子,故得到的b 也是近似的。
高斯——牛顿法对初值的要求是比较严格的,若初值选取不当,很可能得不到结果,即“发散”。
7.3 单纯形法及其Excel 程序高斯——牛顿法或麦夸特法都需要一阶导数矩阵0A ,当函数关系复杂时,就会给运算带来很大的困难。
这时可以采用不需要利用一阶导数矩阵的单纯形法。
我们的目的是寻求一组参数b 使目标函数Q 值为最小,寻求到的b 值称为最优估计值,简称最优值。
单纯形法的思路是先算出若干点处的目标函数值,然后进行比较,从它们之间的大小情况来判断函数的变化趋势,按照一定的模式确定搜索方向。
这个模式就是利用单纯形进行反射、扩张、压缩和收缩等方法进行搜索,不断形成新的单纯形,直到单纯形缩得很小时,便得到最优值。
那么,什么是单纯形呢?所谓单纯形就是一定的空间中的最简单的图形。
如二维空间(平面上),单纯形为三角形,三维空间为四面体,m 维空间为由m +1个顶点而构成的最简单的图形。
如果m +1个顶点的距离都相等,则称为正规的单纯形,简称正单纯形。
为了讨论的方便,把式(7.3)表示为)(b Q Q = (7.22) 下面给出单纯形法的计算步骤及公式。
1.初始单纯形的生成给定初始点T m b b b ],,,[210⋯=b (7.23)其余几个点为⎪⎪⎭⎪⎪⎬⎫+⋯++=⋯⋯⋯+⋯++=+⋯++=T m m T m T m p b q b q b q b p b q b q b q b p b ],,,[],,,[],,,[21212211b b b (7.24)式中⎪⎪⎭⎪⎪⎬⎫-+=-++=h m m q h m m m p 211211 (7.25)式中h 为单纯形边长,一般取0.5≤h ≤15。
对于二维情况,有h q h p m 2588.0,9659.0,2=== 这样形成的初始单纯形为正单纯形。
2.反射计算单纯形各顶点的目标函数值)(i i Q Q b = (i=0,2,…,m ) (7.26) 比较这m +1个点的目标函数值的大小,先找出Q 的最大、最小及次最大点的b 值,分别记为H b 、L b 、G b 即)(max )(i H H Q Q Q b b == (i =0,1,…,m ) (7.27) )(min )(i L L Q Q Q b b == (i =0,1,…,m ) (7.28) )(max )(i G G Q Q Q b b == (i =0,1,…,m ;i ≠H ) (7.29) 计算除H b 外m 个点的重心,即反射中心C b ,即∑=-=mi H i C m 0)(1b b b (7.30)求出H b 的反射点R b ,即)(H C C R b b b b -+=α(7.31) 式中α为反射系数,一般为对称反射,取α=1。
3.扩张计算反射点的目标函数值)(R R Q Q b = (7.32)若R Q <G Q ,则进行扩张。
令)(H R H E b b b b -+=μ (7.33) 式中μ>1,称为扩张系数,一般取μ=1.2~2.0。
计算扩张点的目标函数值)(E E Q Q b = (7.34) 若E Q <R Q ,则扩张成功。
令E S E S Q Q ==,b b (7.35) 否则扩张失败。
令R S R S Q Q ==,b b (7.36)总之,总可得一新点S b ,用S b 代替H b 构成新的单纯形返回第二步,再次搜索。
4.压缩和收缩若R Q ≥G Q ,则反射失败,进行压缩。
令)(H R H S b b b b -+=λ (7.37) 式中0<λ<1和λ≠0.5,λ称为压缩系数,一般取λ=0.25或0.75,若λ=0.5,则S b =C b ,造成降维。
计算)(S S Q Q b = (7.38)若S Q <G Q ,则压缩成功。
用S b 代替H b 构成新的单纯形返回第二步,再次搜索。
若S Q ≥G Q ,则反射压缩都失败,则要进行收缩。
收缩的公式为2/)()()()1(k L k i k i b b b +=+ i =0,1,…,m (7.39)式中上角标k 表示计算i b 的次数。
以)1(+k i b 代替i b 构成新的单纯形返回第二步再次搜索。
5.收敛要求 继续上述过程,直至121)(ε<+-∑=m Q Q mL ii (7.40)或22)(ε<-∑=mQ Q mii (7.41)为止。
式中1ε、2ε为充分小的正数。
单纯形法需要的总搜索步数较多,但每一步计算中除计算一次目标函数值外,只是一些简单的代数运算。
若使用计算机,运算时间就能大大缩短。
单纯形法对初值的要求不是很严,即使所选用的初值远离真值也可以收敛。
这一点是单纯形法的突出优点。
关于初始单纯形边长的选取,需根据具体问题由经验给出。
在使用单纯形法进行参数估值时应注意下面几个问题:第一,估计参数开始时,单纯形的边长应与估计的参数具有相近的数量级,保证参数估计有较大的空间。