第四节 非线性回归模型的参数估计 (赵)
- 格式:ppt
- 大小:422.00 KB
- 文档页数:2


(整理)计量经济学第四章⾮线性回归模型的线性化第四章⾮线性回归模型的线性化以上介绍了线性回归模型。
但有时候变量之间的关系是⾮线性的。
例如 y t = α 0 + α11βt x + u t y t = α 0 t x e 1α+ u t上述⾮线性回归模型是⽆法⽤最⼩⼆乘法估计参数的。
可采⽤⾮线性⽅法进⾏估计。
估计过程⾮常复杂和困难,在20世纪40年代之前⼏乎不可能实现。
计算机的出现⼤⼤⽅便了⾮线性回归模型的估计。
专⽤软件使这种计算变得⾮常容易。
但本章不是介绍这类模型的估计。
另外还有⼀类⾮线性回归模型。
其形式是⾮线性的,但可以通过适当的变换,转化为线性模型,然后利⽤线性回归模型的估计与检验⽅法进⾏处理。
称此类模型为可线性化的⾮线性模型。
下⾯介绍⼏种典型的可以线性化的⾮线性模型。
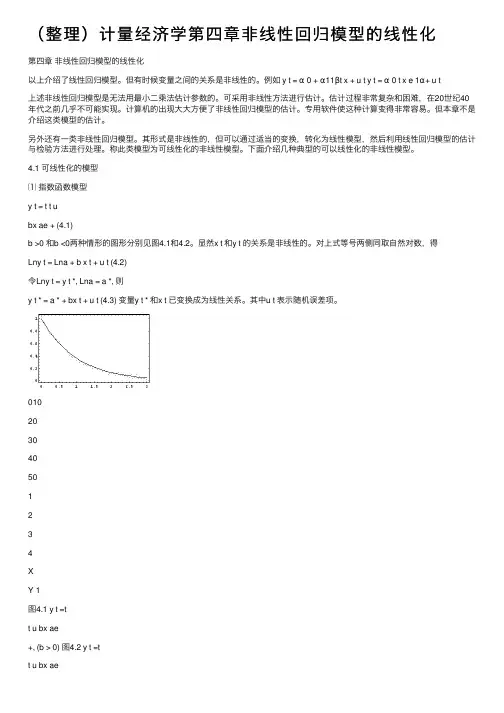
4.1 可线性化的模型⑴指数函数模型y t = t t ubx ae + (4.1)b >0 和b <0两种情形的图形分别见图4.1和4.2。
显然x t 和y t 的关系是⾮线性的。
对上式等号两侧同取⾃然对数,得Lny t = Lna + b x t + u t (4.2)令Lny t = y t *, Lna = a *, 则y t * = a * + bx t + u t (4.3) 变量y t * 和x t 已变换成为线性关系。
其中u t 表⽰随机误差项。
010203040501234XY 1图4.1 y t =tt u bx ae+, (b > 0) 图4.2 y t =t+, (b < 0)⑵对数函数模型y t = a + b Ln x t+ u t(4.4)b>0和b<0两种情形的图形分别见图4.3和4.4。
x t和y t的关系是⾮线性的。
令x t* = Lnx t, 则y t = a + b x t* + u t(4.5)变量y t和x t* 已变换成为线性关系。
图4.3 y t = a + b Lnx t + u t , (b > 0) 图4.4 y t = a + b Lnx t + u t , (b < 0)⑶幂函数模型y t= a x t b t u e(4.6) b取不同值的图形分别见图4.5和4.6。

非线性回归模型的拟合与评估非线性回归是统计学中常用的一种回归分析方法,用于描述自变量与因变量之间的非线性关系。
本文将介绍非线性回归模型的拟合与评估方法。
一、非线性回归模型的拟合方法1. 数据收集与准备拟合非线性回归模型首先需要收集与问题相关的数据。
数据的准备包括数据清洗、变量选择和数据变换等步骤,以确保数据的质量和适应非线性回归模型的要求。
2. 模型选择在准备好数据后,需要选择适合问题的非线性回归模型。
常见的非线性回归模型包括多项式回归模型、指数回归模型、对数回归模型等。
选择合适的模型需要根据问题的特点和理论的支持进行判断。
3. 模型拟合模型拟合是指通过最小化残差平方和或最大似然估计等方法,估计模型的参数。
对于非线性回归模型,常用的拟合方法有最小二乘法、非线性最小二乘法、广义最小二乘法等。
4. 拟合效果评估拟合效果评估是判断非线性回归模型拟合程度好坏的指标。
常用的评估方法有残差分析、决定系数、AIC和BIC等。
残差分析可以检验模型的拟合效果和残差的独立性、常数方差和正态性假设。
二、非线性回归模型的评估方法1. 决定系数(R-squared)决定系数是衡量模型拟合程度的指标,其取值范围为0到1之间。
决定系数越接近1,表示模型对观测数据的解释能力越强。
但需要注意,决定系数无法判断模型是否过拟合。
2. 调整决定系数(Adjusted R-squared)调整决定系数是对决定系数进行修正,考虑了自变量数目的影响。
调整决定系数比决定系数更能有效地评估模型的拟合效果。
3. Akaike信息准则(AIC)和贝叶斯信息准则(BIC)AIC和BIC是用于比较不同模型的拟合效果的统计准则。
AIC和BIC数值越小,表示模型越好。
这两个指标在非线性回归模型的选择和评估中广泛应用。
4. 拟合图形分析通过绘制拟合曲线与实际观测数据的对比图,可以直观地评估非线性回归模型的拟合效果。
拟合图形分析可以帮助发现模型的不足之处,从而进行进一步的改进。
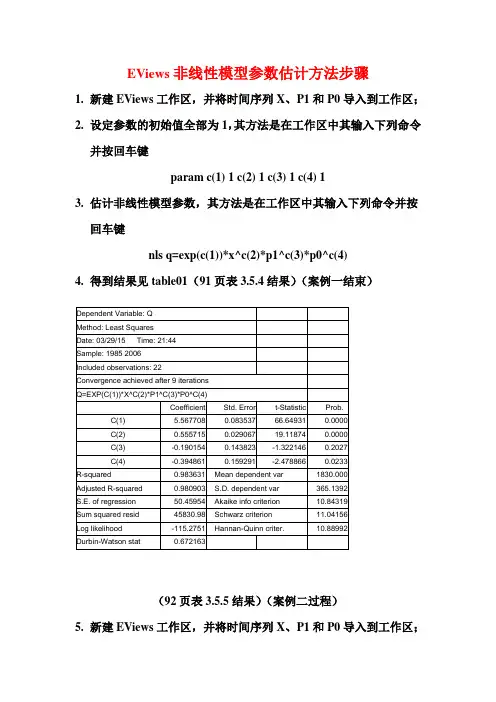
EViews非线性模型参数估计方法步骤1.新建EViews工作区,并将时间序列X、P1和P0导入到工作区;2.设定参数的初始值全部为1,其方法是在工作区中其输入下列命令并按回车键param c(1) 1 c(2) 1 c(3) 1 c(4) 13.估计非线性模型参数,其方法是在工作区中其输入下列命令并按回车键nls q=exp(c(1))*x^c(2)*p1^c(3)*p0^c(4)4.得到结果见table01(91页表3.5.4结果)(案例一结束)Dependent Variable: QMethod: Least SquaresDate: 03/29/15 Time: 21:44Sample: 1985 2006Included observations: 22Convergence achieved after 9 iterationsQ=EXP(C(1))*X^C(2)*P1^C(3)*P0^C(4)Coefficient Std. Error t-Statistic Prob.C(1) 5.567708 0.083537 66.64931 0.0000C(2) 0.555715 0.029067 19.11874 0.0000C(3) -0.190154 0.143823 -1.322146 0.2027C(4) -0.394861 0.159291 -2.478866 0.0233R-squared 0.983631 Mean dependent var 1830.000Adjusted R-squared 0.980903 S.D. dependent var 365.1392S.E. of regression 50.45954 Akaike info criterion 10.84319Sum squared resid 45830.98 Schwarz criterion 11.04156Log likelihood -115.2751 Hannan-Quinn criter. 10.88992Durbin-Watson stat 0.672163(92页表3.5.5结果)(案例二过程)5.新建EViews工作区,并将时间序列X、P1和P0导入到工作区;6.设定参数的初始值全部为1,其方法是在工作区中其输入下列命令并按回车键param c(1) 1 c(2) 1 c(3) 17.估计非线性模型参数,其方法是在工作区中其输入下列命令并按回车键nls q=exp(c(1))*(x/p0)^c(2)*(p1/p0)^c(3)8.得到结果见table02(92页表3.5.5结果)(案例二结束)Dependent Variable: QMethod: Least SquaresDate: 03/29/15 Time: 22:14Sample: 1985 2006Included observations: 22Convergence achieved after 4 iterationsQ=EXP(C(1))*(X/P0)^C(2)*(P1/P0)^C(3)Coefficient Std. Error t-Statistic Prob.C(1) 5.525965 0.072685 76.02666 0.0000C(2) 0.533824 0.019785 26.98163 0.0000C(3) -0.242862 0.134014 -1.812219 0.0858R-squared 0.982669 Mean dependent var 1830.000Adjusted R-squared 0.980845 S.D. dependent var 365.1392S.E. of regression 50.53638 Akaike info criterion 10.80939Sum squared resid 48524.59 Schwarz criterion 10.95817Log likelihood -115.9033 Hannan-Quinn criter. 10.84444Durbin-Watson stat 0.656740。

非线性回归模型及其应用一、引言非线性回归模型在数据分析和预测中具有广泛的应用。
与线性回归模型不同,非线性回归模型能够更好地描述数据之间的复杂关系,适用于解决一些实际问题中的非线性回归分析。
本文将介绍非线性回归模型的基本原理及其应用领域。
二、非线性回归模型的基本原理1. 模型表达式非线性回归模型的表达式一般形式为:Y = f(X, β) + ε其中,Y为因变量,X为自变量,β为参数向量,f(·)为非线性函数,ε为误差项。
通常,我们将模型的函数形式根据问题的实际情况进行选择。
2. 参数估计方法非线性回归模型的参数估计可以使用最小二乘法和最大似然法等方法。
最小二乘法通过最小化误差平方和来估计参数值,最大似然法则是通过最大化似然函数来估计参数值。
选择合适的参数估计方法需要根据具体情况进行判断。
三、非线性回归模型的应用1. 生物医学领域在诊断和治疗方面,非线性回归模型可以用来建立生物医学数据的模型,进而进行疾病的预测和治疗方案的优化。
例如,可以通过建立非线性回归模型来预测病人术后恢复的时间。
2. 经济学领域非线性回归模型在经济学研究中也有广泛的应用。
例如,可以通过非线性回归模型来研究消费者对商品价格的反应,以及对商品需求的影响因素等。
3. 工程领域在工程领域,非线性回归模型可以用来研究工程结构的变形、断裂等情况。
例如,在建筑工程中,可以通过非线性回归模型来估计建筑物的强度和稳定性。
4. 金融领域非线性回归模型在金融领域中也有广泛的应用。
例如,可以通过建立非线性回归模型来分析股票价格的波动,预测市场的走势等。
四、非线性回归模型的评估指标1. 残差分析残差分析是评估非线性回归模型拟合优度的重要方法。
通过对模型的残差进行分析,可以判断模型是否符合假设,进而进行模型的改进和优化。
2. 决定系数决定系数(R-squared)是评估非线性回归模型拟合优度的指标之一。
决定系数越接近1,表示模型对观测数据的拟合程度越好。

非线性回归分析简介非线性回归分析是一种用于建立非线性关系模型的统计方法。
与线性回归不同,非线性回归可以更好地拟合非线性数据,提供更准确的预测结果。
在许多实际问题中,数据往往呈现出非线性的趋势,因此非线性回归分析在实际应用中具有广泛的应用价值。
一、非线性回归模型的基本形式非线性回归模型的基本形式可以表示为:y = f(x, β) + ε其中,y是因变量,x是自变量,β是模型参数,f(x, β)是非线性函数,ε是误差项。
非线性函数可以是任意形式的函数,如指数函数、对数函数、幂函数等。
二、非线性回归模型的参数估计与线性回归不同,非线性回归模型的参数估计不能直接使用最小二乘法。
常见的非线性回归参数估计方法有以下几种:1. 非线性最小二乘法(NLS)非线性最小二乘法是一种常用的参数估计方法,它通过最小化残差平方和来估计模型参数。
具体而言,通过迭代的方式不断调整参数,使得残差平方和最小化。
2. 非线性广义最小二乘法(GNLS)非线性广义最小二乘法是对非线性最小二乘法的改进,它在最小化残差平方和的同时,还考虑了误差项的方差结构。
通过引入权重矩阵,可以更好地处理异方差性的数据。
3. 非线性加权最小二乘法(WNLS)非线性加权最小二乘法是对非线性广义最小二乘法的进一步改进,它通过引入加权矩阵,对不同数据点赋予不同的权重。
可以根据数据的特点,调整权重矩阵,提高模型的拟合效果。
三、非线性回归模型的评估指标在进行非线性回归分析时,需要对模型进行评估,以确定模型的拟合效果。
常见的评估指标有以下几种:1. 残差分析残差分析是一种常用的评估方法,通过分析残差的分布情况,判断模型是否符合数据的分布特征。
如果残差呈现随机分布,说明模型拟合效果较好;如果残差呈现一定的规律性,说明模型存在一定的问题。
2. 决定系数(R-squared)决定系数是衡量模型拟合优度的指标,其取值范围为0到1。
决定系数越接近1,说明模型对数据的解释能力越强;决定系数越接近0,说明模型对数据的解释能力越弱。

非线性回归模型的参数估计方法比较研究论文素材一、引言非线性回归模型是在实际问题中广泛应用的一种统计模型。
不同的非线性回归模型需要使用不同的参数估计方法,选择合适的方法对模型进行参数的估计对于模型的准确性和可靠性至关重要。
本文旨在比较不同的非线性回归模型参数估计方法的优劣,为实际应用提供参考。
二、参数估计方法1. 最小二乘法最小二乘法是一种经典的参数估计方法,适用于线性回归和部分非线性回归模型。
该方法通过最小化观测值与模型预测值之间的误差平方和来估计参数值。
然而,对于高度非线性的模型,最小二乘法可能存在无法收敛或者达到局部最优解的问题。
2. 最大似然估计法最大似然估计法是一种常用的参数估计方法,尤其适用于非线性回归模型。
该方法基于观测数据的概率分布,寻找最大化观测数据出现概率的参数值作为估计值。
最大似然估计法在理论上具有良好的性质,但在实际应用中可能需要迭代算法来求解。
3. 二阶导数估计法二阶导数估计法是一种基于牛顿法的参数估计方法,通过使用二阶导数矩阵估计参数值。
这种方法的优点是收敛速度较快,但需要较高的计算复杂度。
在实际应用中,二阶导数估计法可能会遇到矩阵奇异或计算不稳定的问题。
4. 贝叶斯估计法贝叶斯估计法是一种基于贝叶斯统计思想的参数估计方法,通过引入先验分布和后验分布来估计参数值。
该方法能够灵活地处理不确定性,但需要选择合适的先验分布和进行复杂的数值计算。
三、方法比较根据不同的非线性回归模型特点和数据情况,选择合适的参数估计方法对于模型准确性和可靠性至关重要。
下面对不同的参数估计方法进行比较:1. 参数估计准确性最小二乘法对于线性回归模型具有较好的估计准确性,但对于非线性回归模型的准确性可能较低。
最大似然估计和二阶导数估计法对于非线性回归模型具有较好的估计准确性,但可能需要较高的计算复杂度。
贝叶斯估计法考虑了不确定性,但需要选择合适的先验分布。
2. 参数估计稳定性最小二乘法对于线性回归模型具有较好的稳定性,但非线性回归模型的稳定性可能较差。


非线性成长模型的建立与参数估计非线性成长模型是一种用来描述非线性系统的变化过程的数学模型。
相比于线性模型,非线性成长模型可以更准确地反映实际问题中的非线性关系,因此在很多领域应用广泛,比如生物学、经济学和环境科学等。
在本篇文章中,我们将探讨如何建立非线性成长模型并进行参数估计的方法与步骤。
首先,建立非线性成长模型需要明确研究对象的特征以及模型的形式。
我们以生物学中的生长过程为例。
假设我们想要研究一种植物的生长过程,并希望建立一个非线性成长模型来描述其生长速度随时间的变化。
根据观察,我们发现该植物的生长速度在初始阶段比较快,逐渐减缓,最终接近一个稳定值。
基于这一观察,我们可以选择广义 logistic 函数作为非线性成长模型的形式:N(N) = N / (1 + N^−N(N−N₀))其中N(N)表示植物的生长速度,N表示最大生长速度,N表示生长速度的增长率,N₀表示生长速度达到一半最大值时的时间点。
该模型在初始时,生长速度较快,随着时间的推移,生长速度逐渐减缓。
当N→∞时,N(N)趋近于最大生长速度N。
其次,参数估计是建立非线性成长模型的关键步骤之一。
参数估计的目标是通过已知的数据来估计模型中的参数值,使得模型与实际观测值之间的拟合程度最好。
估计非线性成长模型的参数存在多种方法,其中最常用的方法是最小二乘法。
最小二乘法通过最小化观测值与模型预测值之间的残差平方和来确定最优参数值。
在参数估计过程中,需要选择合适的初始参数值,将问题转化为一个最优化问题。
采用迭代的方式,不断调整参数值,直到找到最小的残差平方和。
此外,为了保证参数估计的稳定性和准确性,常常需要采用统计方法来评估模型的拟合度与参数的显著性。
常见的统计指标包括确定系数(R^2)、AIC(Akaike information criterion)和BIC(Bayesian information criterion)等。
确定系数可以衡量模型拟合数据的好坏,范围从0到1,值越接近1表示拟合效果越好。

非线性模型的参数估计沈云中同济大学测量系E-mail: yzshen@提要•概述•非线性模型•线性化问题•参数估计问题•估值精度的评定问题•几种特殊的非线性模型•结论概述均值µ 方差σ² 的观测值l ,其二次型l² 的期望值为:非线性模型的估值往往是有偏的!E(l²) = var(l ) + {E(l )}² = σ² + µ²l非线性观测模型的假设在准则参数估值是唯的x1、在准则下,参数估值是唯一的2、在观测值的误差范围内,参数估值是稳定的非线性模型参数估计的现状1、顾及二次项的估计1、顾及次项的估计2、参数估值可采用全局优化方法解算3估值的精度没有给出3、估值的精度没有给出非线性观测方程非线性观测方程:约束条件:(,)0l x f l e x e ++=()0x g x e +≤估计准则:()0x h x e +=min :l l xx xe Pe e P e +T T Lagrange 函数:P T T ()()(,,,,)2(,) 22l x ll xx x l x x x L e e λμκe Pe e P e λf l e x e μg x e κh x e =++++++++TTT观测方程的简化形式•待估参数没有先验信息(,)0l f l e x +=参数x 从初值x 0出发迭代计算•可表示成观测值的显式()l l e f x +=T()()min : ()()()x l f x P l f x =−−S非线性方程的线性化•非线性观测方程直到二解的展开式()13ˆˆˆ()()()()T f x f xf x x x f x x O δδδ=+++&&&⎡2ˆx x xδ=−21ˆ()ˆ()T T T i i T n f x x f x x x x x f x x x δδδδδδ&&&&×⎤∂⎡⎤==⎢⎥⎣⎦∂∂⎣⎦22; T T T N TNx f xx f xfδδδδδδκκ&&&&&&==向fx x δδ切向分量法向分量顾及二次项的非线性估计•非线性估值的二次展开式非线性估值的次展开式1ˆ3xg l v g l g l v v g l v ′′′=+=+++TO •估值有偏()()()()()2l l l l ()1ˆ {}2l x x g D ′′=+⎡⎤⎣⎦i E tr •二次无偏估值()1ˆ 2l x x g D ′′=−⎡⎤⎣⎦)itr非线性模型的参数估计问题非线性模型的参数估计:1.局部极值点计算2.搜索更优极值点的区域Mountainshigher thanwhere I amwhere I am图引自徐培亮局部极值计算•BFGS 拟牛顿算法牛顿算(1)()k k k kα+=+xxd ()()d H x =−∇k k k S T T T=−−10()() k k k k k k k k k k kρρρ++=H E p q H E q p p p H E11)()k k +k Tk kρq p =()k =−p xx1)+∇k k ()()()()q xx =∇−k S S()k ()x ε∇<S 迭代停止条件:全局最优解算法•非线性、非凸目标函数的全局最优解步骤如下:1.由初值x 计算S(x ,寻找满足下面条件的可行集I xmin :()x S 0(0)20()()0x x −<S S 2.在某个子集I x i 内计算S (x )的局部极值S ﹡3. 寻找满足下面条件的更新可行集I x n()0, x x x∗−<∈S S I 4. 重复2与3步,直至更新的可行集为空集。
非线性回归数学知识点总结非线性回归分析通常基于统计原理和方法,通过对观测数据的分析来估计模型参数,从而找到自变量和因变量之间的关系。
对于不同类型的非线性关系,可以采用不同的非线性回归模型来进行分析。
本篇文章将从以下几个方面来总结非线性回归的相关数学知识点:非线性回归模型的基本概念、非线性回归模型的参数估计、非线性回归模型的假设检验、非线性回归模型的模型选择和验证等。
1. 非线性回归模型的基本概念非线性回归模型是一种描述自变量和因变量之间非线性关系的数学模型。
非线性回归模型通常可以表示为如下形式:Y = f(X,θ) + ε其中,Y是因变量,X是自变量,f()是非线性函数,θ是模型参数,ε是误差项。
在实际问题中,我们可以根据问题的特点选择合适的非线性函数f()来描述自变量和因变量之间的关系。
比如,如果我们观测到因变量Y与自变量X之间存在指数关系,那么我们可以选择指数函数来描述这种关系。
如果我们观测到因变量Y与自变量X之间存在对数关系,我们可以选择对数函数来描述这种关系。
2. 非线性回归模型的参数估计在实际问题中,我们通常需要通过观测数据来估计非线性回归模型的参数。
参数估计的目标是求解模型参数θ的值,使得模型与观测数据的拟合程度最好。
参数估计的方法通常包括最小二乘法、最大似然估计、贝叶斯方法等。
其中,最小二乘法是应用最广泛的一种参数估计方法。
最小二乘法的基本思想是求解参数θ,使得模型预测值与观测数据的残差平方和最小。
3. 非线性回归模型的假设检验在参数估计之后,我们通常需要对非线性回归模型的拟合效果进行假设检验。
假设检验的目的是判断模型的拟合程度是否显著。
在假设检验中,通常会进行F检验、t检验、残差分析等。
F检验是用来判断整个模型的符合程度,t检验是用来判断模型参数的显著性。
残差分析是用来检验模型对观测数据的拟合程度。
4. 非线性回归模型的模型选择和验证在实际问题中,我们通常会遇到多个可能的非线性回归模型。
非线性模型与参数估计方法研究1.引言非线性模型是现代统计学中一个重要的分支,随着计算机性能的不断提高和数据维度的不断增加,非线性模型的应用正在越来越广泛。
在实际应用中,参数估计是非线性模型不可避免的一部分,而参数估计的精度对模型预测的准确性起着至关重要的作用。
在本文中,我们将介绍非线性模型及其参数估计方法的研究现状,并讨论其应用价值和发展趋势。
2.非线性模型非线性模型是指模型中自变量与因变量之间不满足线性关系的模型。
非线性模型一般在目标函数中引入一些非线性项,以适应复杂的实际情况。
在实际应用中,非线性模型的种类繁多,常见的有曲线拟合、非线性回归、广义线性模型等。
非线性模型既可以用于描述现象,又可以用于预测未来,具有很高的应用价值。
在非线性模型中,很多模型的参数是需要估计的。
3.参数估计方法参数估计是非线性模型中一个至关重要的问题,其精度直接关系到模型的预测准确性。
常见的参数估计方法有极大似然估计、最小二乘估计、贝叶斯估计等。
极大似然估计是一种计算方便、精度较高的方法,最小二乘估计则是样本量较大时最优的方法,而贝叶斯估计则可以自然地引入先验信息,使得估计结果更加准确。
此外,基于神经网络的参数估计方法和贪心算法也获得了一定的应用。
4.应用价值非线性模型及其参数估计方法在各种领域中都有着广泛的应用。
在金融领域,非线性模型可以用于股票价格的预测和交易决策的制定。
在医学领域,非线性模型可以用于疾病的诊断和治疗方案的优化。
在物流领域,非线性模型可以用于路线优化和成本控制。
随着社会经济的发展,非线性模型的应用范围将越来越广泛。
5.发展趋势随着计算机性能的不断提高,大数据分析和人工智能技术的应用越来越普及,非线性模型的应用前景更加广阔。
同时,非线性模型及其参数估计方法也在不断发展。
例如,基于深度学习的非线性模型已经取得了许多研究和应用成果。
此外,混沌理论、粒子群算法、受限玻尔兹曼机等技术也为非线性模型提供了新的思路和手段。
目录一、预测解释变量的回顾 (1)二、增长模型的估计 (3)三、科布-道格拉斯生产函数的估计 (5)实验四非线性模型的估计实验目的:掌握一元和多元非线性模型的估计方法。
实验要求:估计增长模型,估计科布-道格拉斯生产函数。
实验原理:非线性最小二乘法(NLS)。
实验步骤:一、预测解释变量的回顾在实验二的一元线性回归模型的预测中,用于预测解释变量的时间序列模型GDPS=a+bT是线性的,实际上GDPS和T的关系是非线性的,看它们的散点图(图3-6)。
在散点图看它们显然是非线性的关系,一般的非线性模型是变量取对数,我们有双对数模型、对数-线性模型和线性-对数模型三种。
就图3-6看应该使用什么模型呢?给出一个实用的规则:哪个变量变化快哪个取对数。
图3-6显然GDPS变化快,所以GDPS取对数,即使用对数-线性模型。
看GDPS的自然对数lgdps与T的散点图(图3-7)。
可以看出lgdps与T却是是线性关系。
建立对数-线性模型lgdps=a+bT进行一元非线性回归(实际上进行的是lgdps对T的线性回归)如下:图3-6图3-7得到回归方程:lgdps = 0.1885795351 * T + 4.95074562823 显然,比下面的GDP对T的线性回归有很大的改善。
用这个一元非线性回归方程重新预测GDPS,预测值放在序列GDPSFF中,打开可以看见,也列出原预测值加以比较。
从预测数据(表3-1)可以看出预测结果也有很大的改善。
表3-1二、增长模型的估计根据广东数据,如果仅知财政收入CS的数据,又要预测CS,可用CS对趋势变量T进行回归分析。
看CS和T的散点图(图3-8)。
图3-8根据上面给出的规则,应该CS取对数建立对数-线性模型,为了估计CS的增长率,建立增长模型为CS t=a(1+r)t e t u,这里的参数r就是CS的增长率。
令b0=Ina,b1=In(1+r);模型可表示为:In CS t= b0+ b1t+u t对此模型进行非线性回归分析如下:得到回归方程lcs = 0.1591151106282 * T + 3.06161080381根据b0= Ina = 3.061611,b1= In(1+r) = 0.159151解出a = 21.36,r = 0.1725。